 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Vision Transformer Unrolling Fixed-Point Algorithm: a Case Study on Image Restoration
Jan 29, 2023
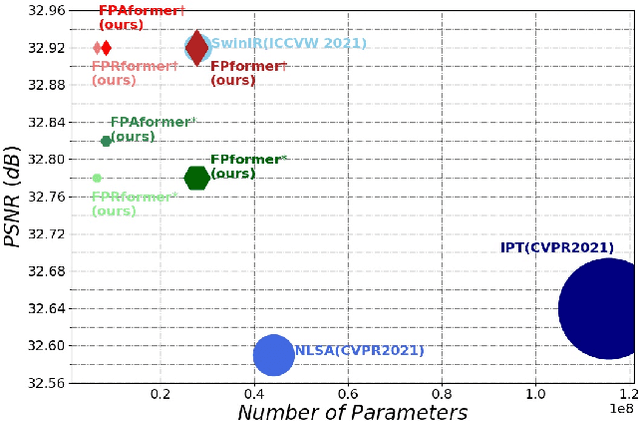



The great success of Deep Neural Networks (DNNs) has inspired the algorithmic development of DNN-based Fixed-Point (DNN-FP) for computer vision tasks. DNN-FP methods, trained by Back-Propagation Through Time or computing the inaccurate inversion of the Jacobian, suffer from inferior representation ability. Motivated by the representation power of the Transformer, we propose a framework to unroll the FP and approximate each unrolled process via Transformer blocks, called FPformer. To reduce the high consumption of memory and computation, we come up with FPRformer by sharing parameters between the successive blocks. We further design a module to adapt Anderson acceleration to FPRformer to enlarge the unrolled iterations and improve the performance, called FPAformer. In order to fully exploit the capability of the Transformer, we apply the proposed model to image restoration, using self-supervised pre-training and supervised fine-tuning. 161 tasks from 4 categories of image restoration problems are used in the pre-training phase. Hereafter, the pre-trained FPformer, FPRformer, and FPAformer are further fine-tuned for the comparison scenarios. Using self-supervised pre-training and supervised fine-tuning, the proposed FPformer, FPRformer, and FPAformer achieve competitive performance with state-of-the-art image restoration methods and better training efficiency. FPAformer employs only 29.82% parameters used in SwinIR models, and provides superior performance after fine-tuning. To train these comparison models, it takes only 26.9% time used for training SwinIR models. It provides a promising way to introduce the Transformer in low-level vision tasks.
Weakly Supervised Image Segmentation Beyond Tight Bounding Box Annotations
Jan 28, 2023



Weakly supervised image segmentation approaches in the literature usually achieve high segmentation performance using tight bounding box supervision and decrease the performance greatly when supervised by loose bounding boxes. However, compared with loose bounding box, it is much more difficult to acquire tight bounding box due to its strict requirements on the precise locations of the four sides of the box. To resolve this issue, this study investigates whether it is possible to maintain good segmentation performance when loose bounding boxes are used as supervision. For this purpose, this work extends our previous parallel transformation based multiple instance learning (MIL) for tight bounding box supervision by integrating an MIL strategy based on polar transformation to assist image segmentation. The proposed polar transformation based MIL formulation works for both tight and loose bounding boxes, in which a positive bag is defined as pixels in a polar line of a bounding box with one endpoint located inside the object enclosed by the box and the other endpoint located at one of the four sides of the box. Moreover, a weighted smooth maximum approximation is introduced to incorporate the observation that pixels closer to the origin of the polar transformation are more likely to belong to the object in the box. The proposed approach was evaluated on two public datasets using dice coefficient when bounding boxes at different precision levels were considered in the experiments. The results demonstrate that the proposed approach achieves state-of-the-art performance for bounding boxes at all precision levels and is robust to mild and moderate errors in the loose bounding box annotations. The codes are available at \url{https://github.com/wangjuan313/wsis-beyond-tightBB}.
Maximum Spherical Mean Value (mSMV) Filtering for Whole Brain Quantitative Susceptibility Mapping
Apr 22, 2023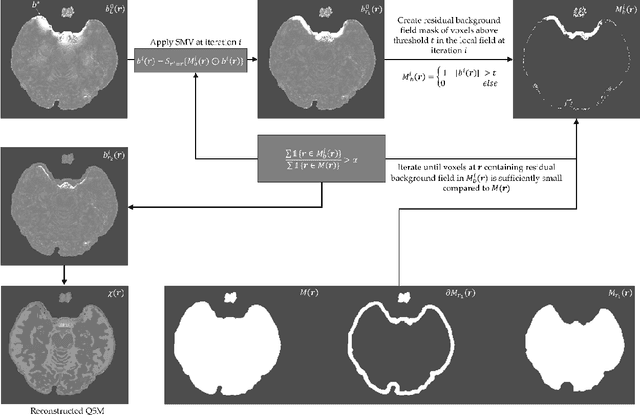
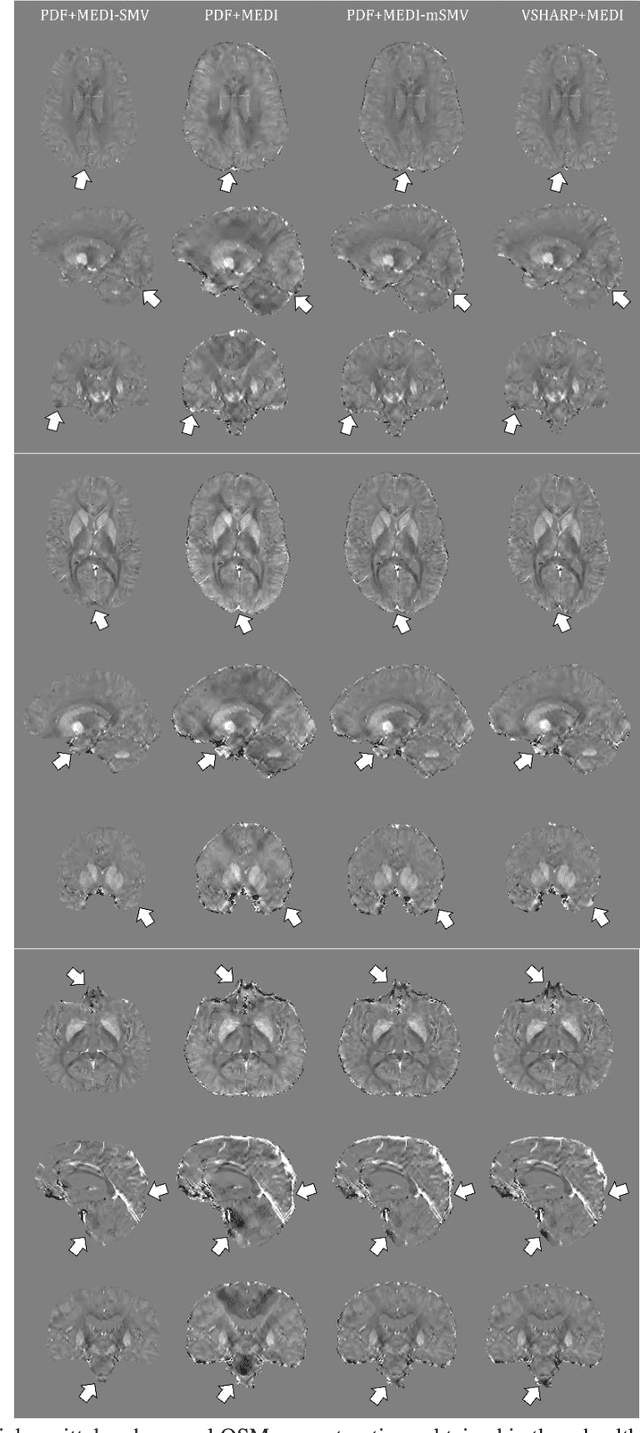
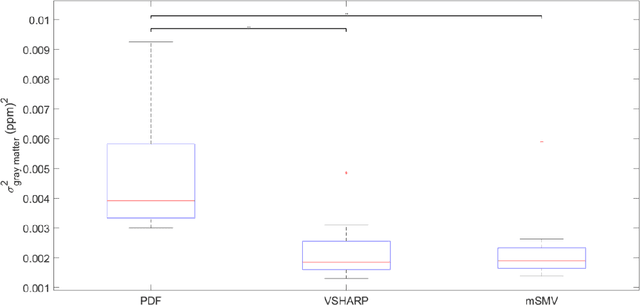
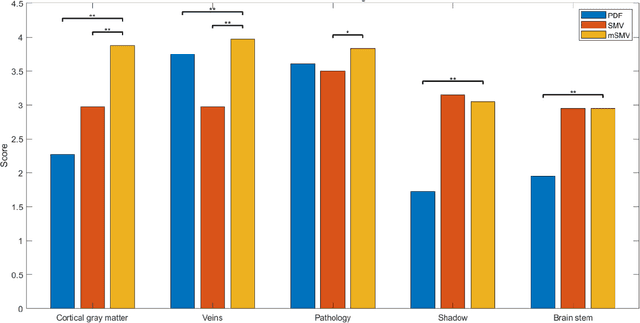
To develop a tissue field filtering algorithm, called maximum Spherical Mean Value (mSMV), for reducing shadow artifacts in quantitative susceptibility mapping (QSM) of the brain without requiring brain tissue erosion. Residual background field is a major source of shadow artifacts in QSM. The mSMV algorithm filters large field values near the border, where the maximum value of the harmonic background field is located. The effectiveness of mSMV for artifact removal was evaluated by comparing with existing QSM algorithms in a simulated numerical brain, 11 healthy volunteers, by assessing image quality in routine clinical patient study $(n=43)$, and by measuring lesion susceptibility values in multiple sclerosis patients $(n=50)$, a total of $n=93$ patients. Numerical simulation showed that mSMV reduces shadow artifacts and improves QSM accuracy. Better shadow reduction, as demonstrated by lower QSM variation in the gray matter and higher QSM image quality score, was also observed in healthy subjects and in patients with hemorrhages, stroke and multiple sclerosis. The mSMV algorithm allows reconstruction of QSMs that are equivalent to those obtained using SMV-filtered dipole inversion without eroding the volume of interest.
Crowd3D: Towards Hundreds of People Reconstruction from a Single Image
Jan 23, 2023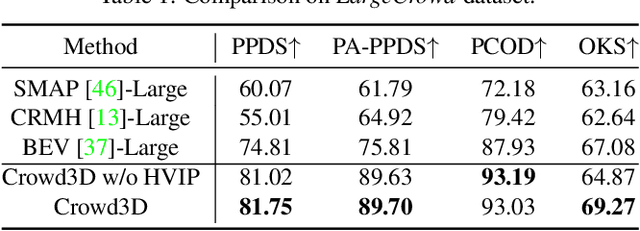
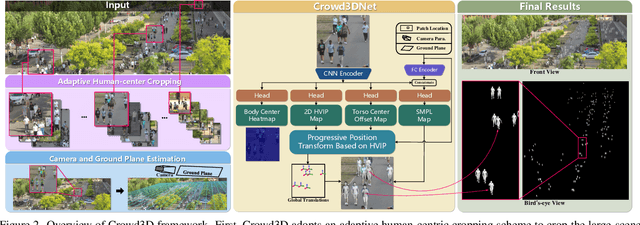
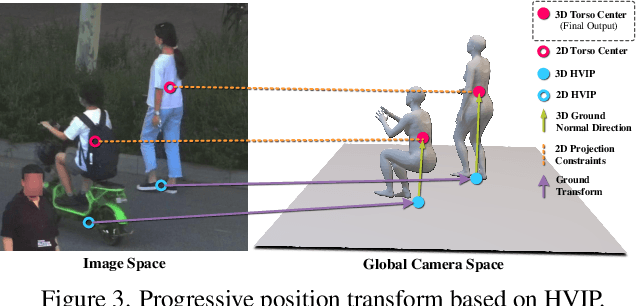
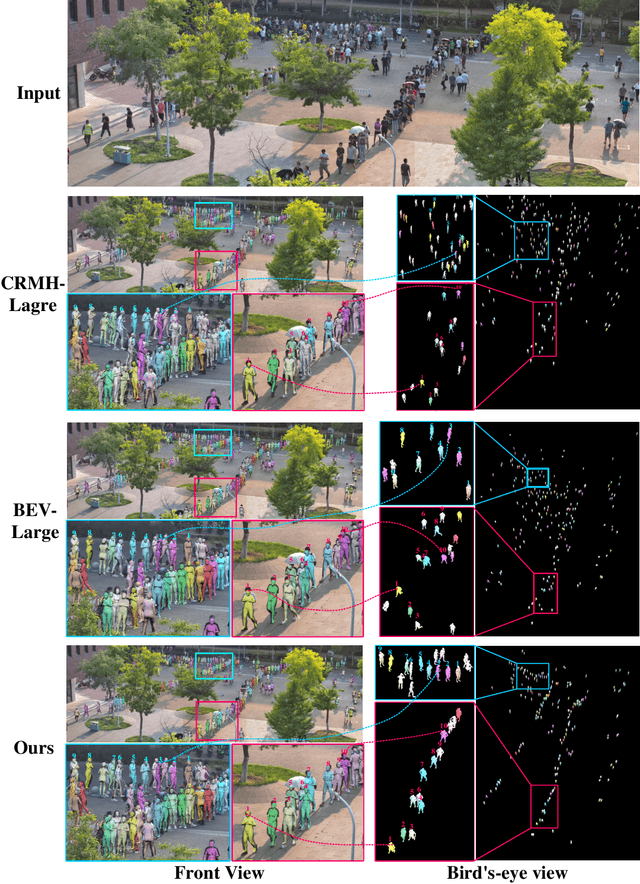
Image-based multi-person reconstruction in wide-field large scenes is critical for crowd analysis and security alert. However, existing methods cannot deal with large scenes containing hundreds of people, which encounter the challenges of large number of people, large variations in human scale, and complex spatial distribution. In this paper, we propose Crowd3D, the first framework to reconstruct the 3D poses, shapes and locations of hundreds of people with global consistency from a single large-scene image. The core of our approach is to convert the problem of complex crowd localization into pixel localization with the help of our newly defined concept, Human-scene Virtual Interaction Point (HVIP). To reconstruct the crowd with global consistency, we propose a progressive reconstruction network based on HVIP by pre-estimating a scene-level camera and a ground plane. To deal with a large number of persons and various human sizes, we also design an adaptive human-centric cropping scheme. Besides, we contribute a benchmark dataset, LargeCrowd, for crowd reconstruction in a large scene. Experimental results demonstrate the effectiveness of the proposed method. The code and datasets will be made public.
Experimental Realization of Convolution Processing in Photonic Synthetic Frequency Dimensions
May 05, 2023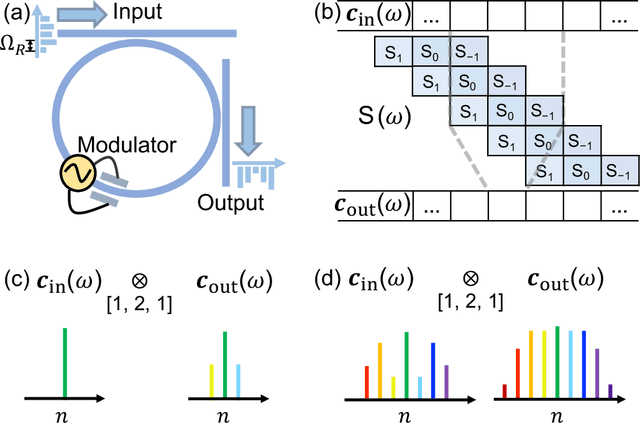
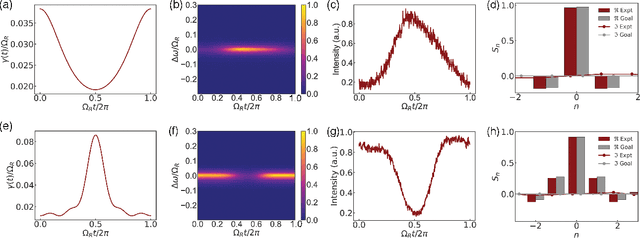
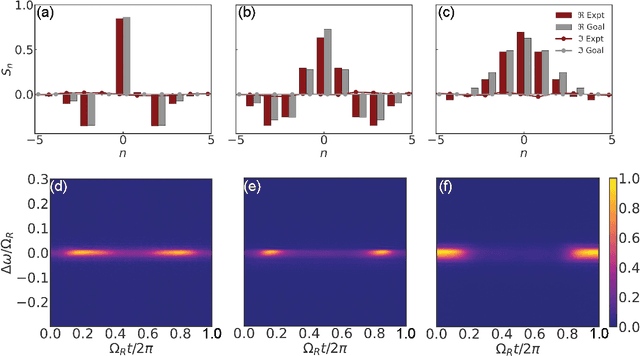
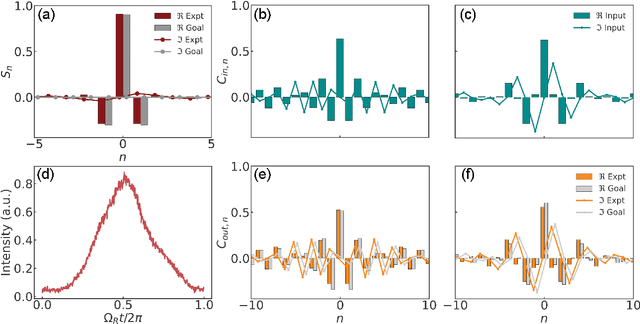
Convolution is an essential operation in signal and image processing and consumes most of the computing power in convolutional neural networks. Photonic convolution has the promise of addressing computational bottlenecks and outperforming electronic implementations. Performing photonic convolution in the synthetic frequency dimension, which harnesses the dynamics of light in the spectral degrees of freedom for photons, can lead to highly compact devices. Here we experimentally realize convolution operations in the synthetic frequency dimension. Using a modulated ring resonator, we synthesize arbitrary convolution kernels using a pre-determined modulation waveform with high accuracy. We demonstrate the convolution computation between input frequency combs and synthesized kernels. We also introduce the idea of an additive offset to broaden the kinds of kernels that can be implemented experimentally when the modulation strength is limited. Our work demonstrate the use of synthetic frequency dimension to efficiently encode data and implement computation tasks, leading to a compact and scalable photonic computation architecture.
Synthesizing Cough Audio with GAN for COVID-19 Detection
May 05, 2023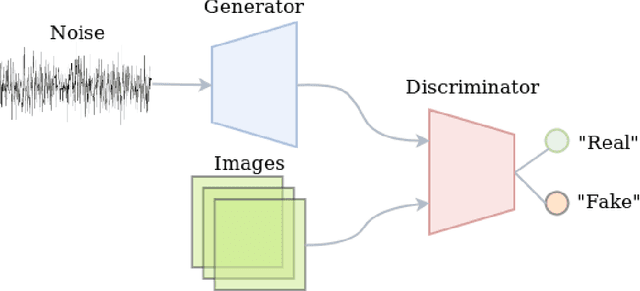


For this final year project, the goal is to add to the published works within data synthesis for health care. The end product of this project is a trained model that generates synthesized images that can be used to expand a medical dataset (Pierre, 2021). The chosen domain for this project is the Covid-19 cough recording which is have been proven to be a viable data source for detecting Covid. This is an under-explored domain despite its huge importance because of the limited dataset available for the task. Once this model is developed its impact will be illustrated by training state-of-the-art models with and without the expanded dataset and measuring the difference in performance. Lastly, everything will be put together by embedding the model within a web application to illustrate its power. To achieve the said goals, an extensive literature review will be conducted into the recent innovations for image synthesis using generative models.
SAM vs BET: A Comparative Study for Brain Extraction and Segmentation of Magnetic Resonance Images using Deep Learning
Apr 19, 2023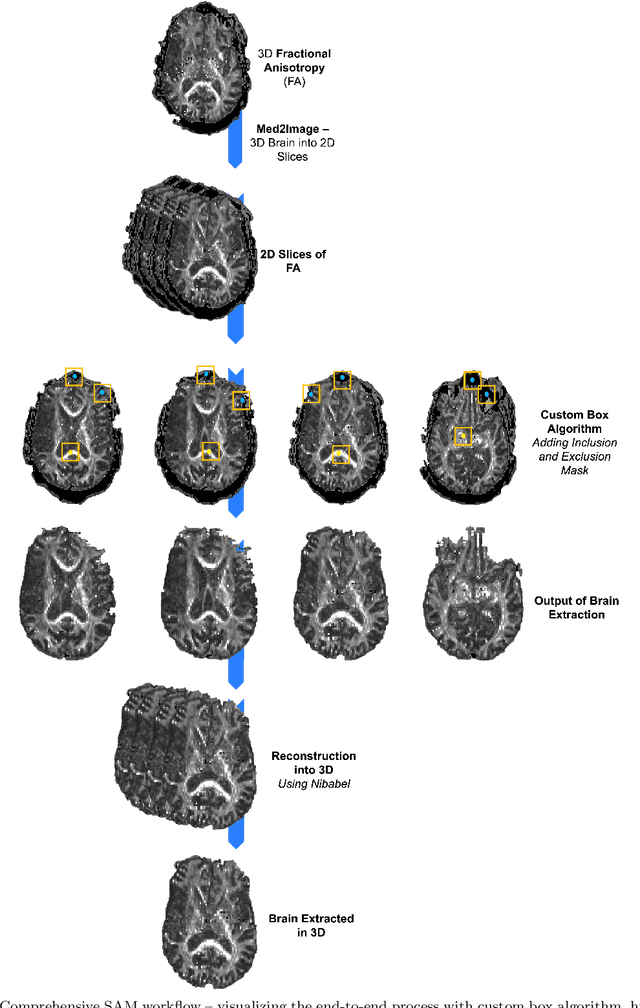
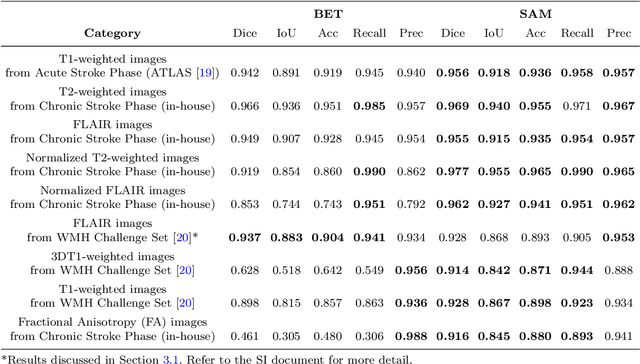
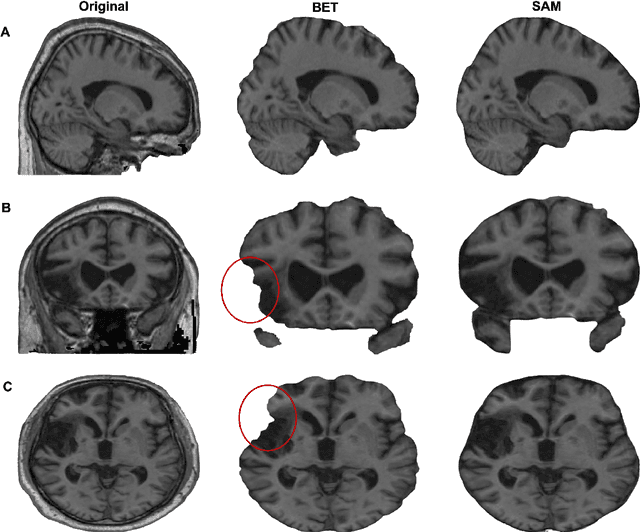
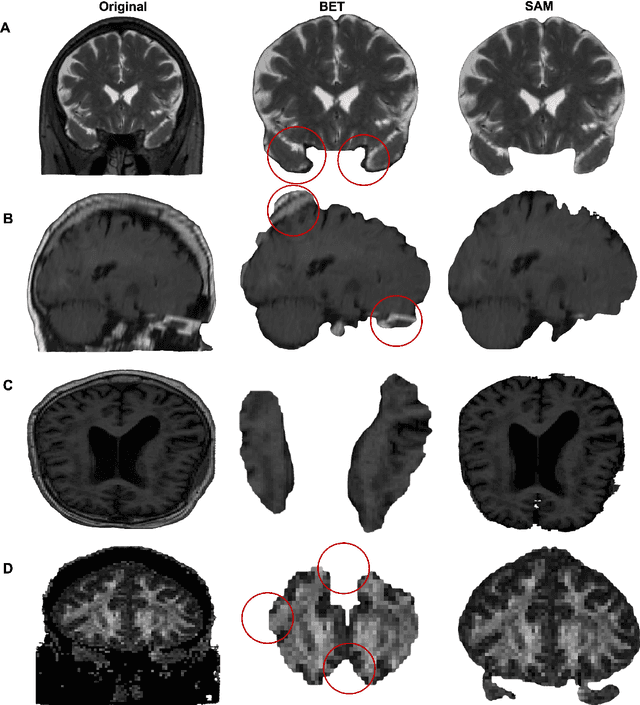
Brain extraction is a critical preprocessing step in various neuroimaging studies, particularly enabling accurate separation of brain from non-brain tissue and segmentation of relevant within-brain tissue compartments and structures using Magnetic Resonance Imaging (MRI) data. FSL's Brain Extraction Tool (BET), although considered the current gold standard for automatic brain extraction, presents limitations and can lead to errors such as over-extraction in brains with lesions affecting the outer parts of the brain, inaccurate differentiation between brain tissue and surrounding meninges, and susceptibility to image quality issues. Recent advances in computer vision research have led to the development of the Segment Anything Model (SAM) by Meta AI, which has demonstrated remarkable potential in zero-shot segmentation of objects in real-world scenarios. In the current paper, we present a comparative analysis of brain extraction techniques comparing SAM with a widely used and current gold standard technique called BET on a variety of brain scans with varying image qualities, MR sequences, and brain lesions affecting different brain regions. We find that SAM outperforms BET based on average Dice coefficient, IoU and accuracy metrics, particularly in cases where image quality is compromised by signal inhomogeneities, non-isotropic voxel resolutions, or the presence of brain lesions that are located near (or involve) the outer regions of the brain and the meninges. In addition, SAM has also unsurpassed segmentation properties allowing a fine grain separation of different issue compartments and different brain structures. These results suggest that SAM has the potential to emerge as a more accurate, robust and versatile tool for a broad range of brain extraction and segmentation applications.
Robust thalamic nuclei segmentation from T1-weighted MRI
Apr 14, 2023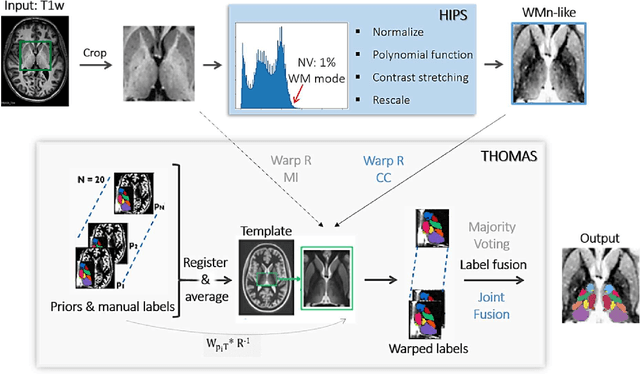
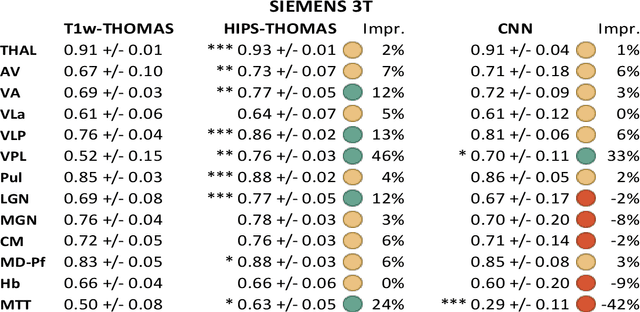
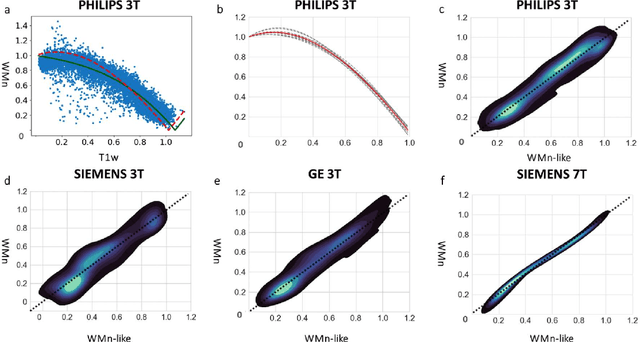

Accurate segmentation of thalamic nuclei, crucial for understanding their role in healthy cognition and in pathologies, is challenging to achieve on standard T1-weighted (T1w) magnetic resonance imaging (MRI) due to poor image contrast. White-matter-nulled (WMn) MRI sequences improve intrathalamic contrast but are not part of clinical protocols or extant databases. Here, we introduce Histogram-based polynomial synthesis (HIPS), a fast preprocessing step that synthesizes WMn-like image contrast from standard T1w MRI using a polynomial approximation. HIPS was incorporated into our Thalamus Optimized Multi-Atlas Segmentation (THOMAS) pipeline, developed and optimized for WMn MRI. HIPS-THOMAS was compared to a convolutional neural network (CNN)-based segmentation method and THOMAS modified for T1w images (T1w-THOMAS). The robustness and accuracy of the three methods were tested across different image contrasts, scanner manufacturers, and field strength. HIPS-synthesized images improved intra-thalamic contrast and thalamic boundaries, and their segmentations yielded significantly better mean Dice, lower percentage of volume error, and lower standard deviations compared to both the CNN method and T1w-THOMAS. Finally, using THOMAS, HIPS-synthesized images were as effective as WMn images for identifying thalamic nuclei atrophy in alcohol use disorders subjects relative to healthy controls, with a higher area under the ROC curve compared to T1w-THOMAS (0.79 vs 0.73).
A Comprehensive Study on Robustness of Image Classification Models: Benchmarking and Rethinking
Feb 28, 2023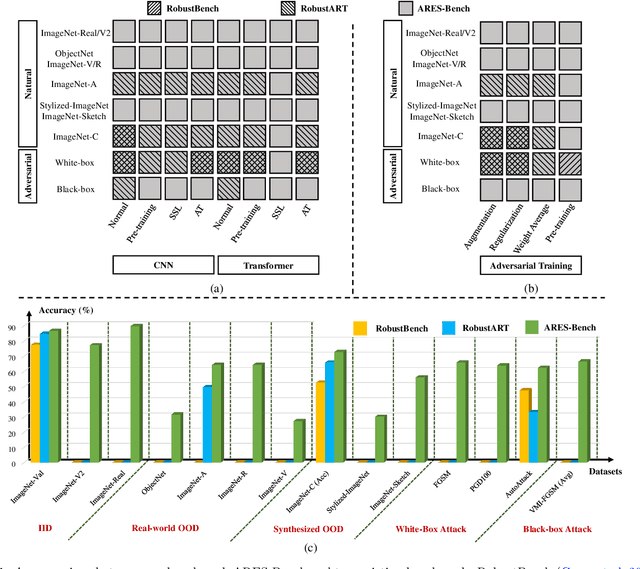

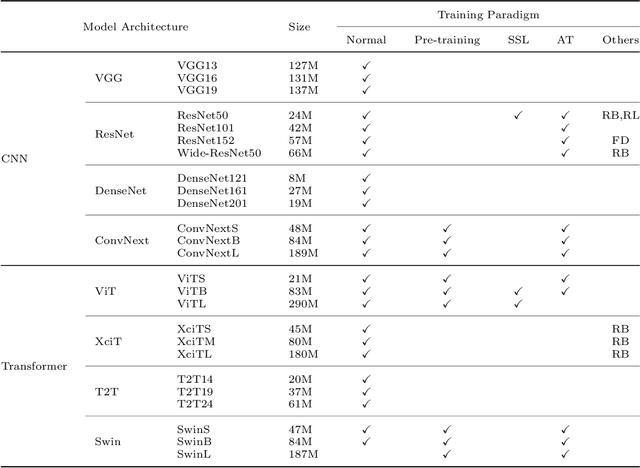
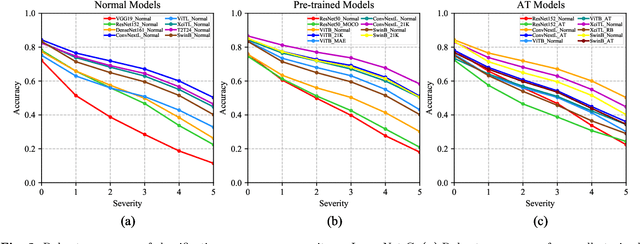
The robustness of deep neural networks is usually lacking under adversarial examples, common corruptions, and distribution shifts, which becomes an important research problem in the development of deep learning. Although new deep learning methods and robustness improvement techniques have been constantly proposed, the robustness evaluations of existing methods are often inadequate due to their rapid development, diverse noise patterns, and simple evaluation metrics. Without thorough robustness evaluations, it is hard to understand the advances in the field and identify the effective methods. In this paper, we establish a comprehensive robustness benchmark called \textbf{ARES-Bench} on the image classification task. In our benchmark, we evaluate the robustness of 55 typical deep learning models on ImageNet with diverse architectures (e.g., CNNs, Transformers) and learning algorithms (e.g., normal supervised training, pre-training, adversarial training) under numerous adversarial attacks and out-of-distribution (OOD) datasets. Using robustness curves as the major evaluation criteria, we conduct large-scale experiments and draw several important findings, including: 1) there is an inherent trade-off between adversarial and natural robustness for the same model architecture; 2) adversarial training effectively improves adversarial robustness, especially when performed on Transformer architectures; 3) pre-training significantly improves natural robustness based on more training data or self-supervised learning. Based on ARES-Bench, we further analyze the training tricks in large-scale adversarial training on ImageNet. By designing the training settings accordingly, we achieve the new state-of-the-art adversarial robustness. We have made the benchmarking results and code platform publicly available.
Text Reading Order in Uncontrolled Conditions by Sparse Graph Segmentation
May 04, 2023
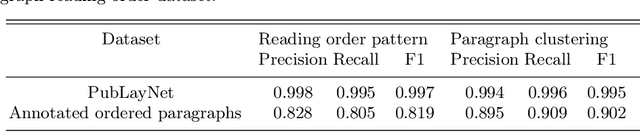


Text reading order is a crucial aspect in the output of an OCR engine, with a large impact on downstream tasks. Its difficulty lies in the large variation of domain specific layout structures, and is further exacerbated by real-world image degradations such as perspective distortions. We propose a lightweight, scalable and generalizable approach to identify text reading order with a multi-modal, multi-task graph convolutional network (GCN) running on a sparse layout based graph. Predictions from the model provide hints of bidimensional relations among text lines and layout region structures, upon which a post-processing cluster-and-sort algorithm generates an ordered sequence of all the text lines. The model is language-agnostic and runs effectively across multi-language datasets that contain various types of images taken in uncontrolled conditions, and it is small enough to be deployed on virtually any platform including mobile devices.