 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Calibration Assessment and Boldness-Recalibration for Binary Events
May 09, 2023
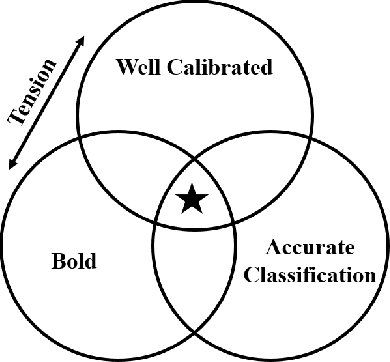
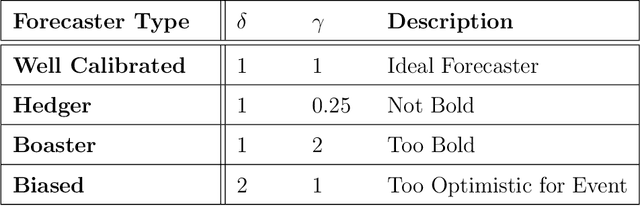
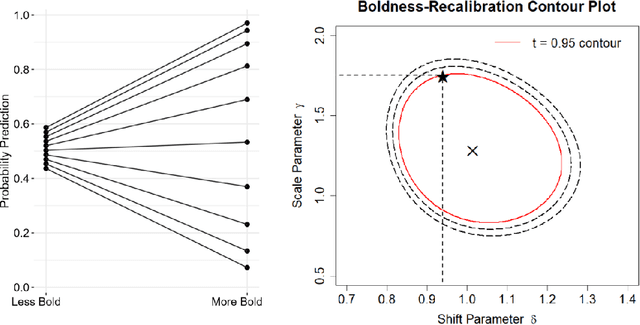

Probability predictions are essential to inform decision making in medicine, economics, image classification, sports analytics, entertainment, and many other fields. Ideally, probability predictions are (i) well calibrated, (ii) accurate, and (iii) bold, i.e., far from the base rate of the event. Predictions that satisfy these three criteria are informative for decision making. However, there is a fundamental tension between calibration and boldness, since calibration metrics can be high when predictions are overly cautious, i.e., non-bold. The purpose of this work is to develop a hypothesis test and Bayesian model selection approach to assess calibration, and a strategy for boldness-recalibration that enables practitioners to responsibly embolden predictions subject to their required level of calibration. Specifically, we allow the user to pre-specify their desired posterior probability of calibration, then maximally embolden predictions subject to this constraint. We verify the performance of our procedures via simulation, then demonstrate the breadth of applicability by applying these methods to real world case studies in each of the fields mentioned above. We find that very slight relaxation of calibration probability (e.g., from 0.99 to 0.95) can often substantially embolden predictions (e.g., widening Hockey predictions' range from .25-.75 to .10-.90)
Seeing Through the Grass: Semantic Pointcloud Filter for Support Surface Learning
May 13, 2023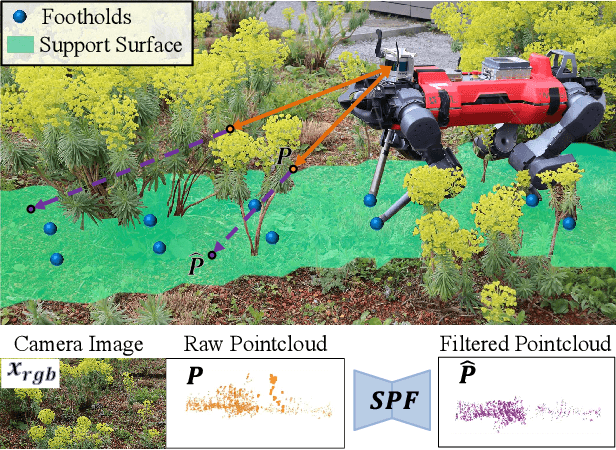
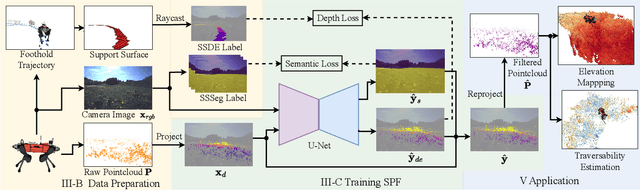
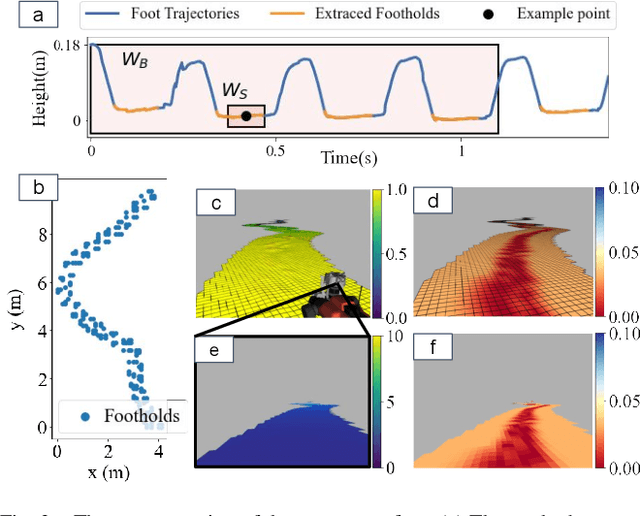

Mobile ground robots require perceiving and understanding their surrounding support surface to move around autonomously and safely. The support surface is commonly estimated based on exteroceptive depth measurements, e.g., from LiDARs. However, the measured depth fails to align with the true support surface in the presence of high grass or other penetrable vegetation. In this work, we present the Semantic Pointcloud Filter (SPF), a Convolutional Neural Network (CNN) that learns to adjust LiDAR measurements to align with the underlying support surface. The SPF is trained in a semi-self-supervised manner and takes as an input a LiDAR pointcloud and RGB image. The network predicts a binary segmentation mask that identifies the specific points requiring adjustment, along with estimating their corresponding depth values. To train the segmentation task, 300 distinct images are manually labeled into rigid and non-rigid terrain. The depth estimation task is trained in a self-supervised manner by utilizing the future footholds of the robot to estimate the support surface based on a Gaussian process. Our method can correctly adjust the support surface prior to interacting with the terrain and is extensively tested on the quadruped robot ANYmal. We show the qualitative benefits of SPF in natural environments for elevation mapping and traversability estimation compared to using raw sensor measurements and existing smoothing methods. Quantitative analysis is performed in various natural environments, and an improvement by 48% RMSE is achieved within a meadow terrain.
WordStylist: Styled Verbatim Handwritten Text Generation with Latent Diffusion Models
Mar 29, 2023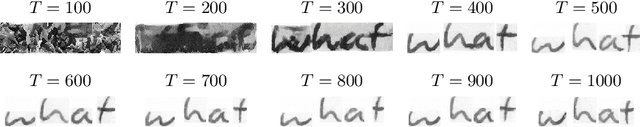
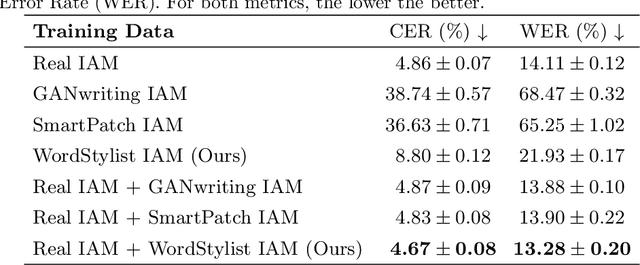

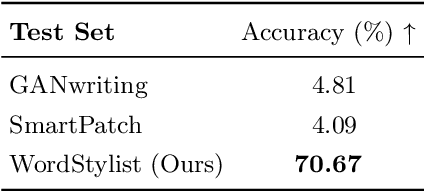
Text-to-Image synthesis is the task of generating an image according to a specific text description. Generative Adversarial Networks have been considered the standard method for image synthesis virtually since their introduction; today, Denoising Diffusion Probabilistic Models are recently setting a new baseline, with remarkable results in Text-to-Image synthesis, among other fields. Aside its usefulness per se, it can also be particularly relevant as a tool for data augmentation to aid training models for other document image processing tasks. In this work, we present a latent diffusion-based method for styled text-to-text-content-image generation on word-level. Our proposed method manages to generate realistic word image samples from different writer styles, by using class index styles and text content prompts without the need of adversarial training, writer recognition, or text recognition. We gauge system performance with Frechet Inception Distance, writer recognition accuracy, and writer retrieval. We show that the proposed model produces samples that are aesthetically pleasing, help boosting text recognition performance, and gets similar writer retrieval score as real data.
Discriminator-free Unsupervised Domain Adaptation for Multi-label Image Classification
Jan 25, 2023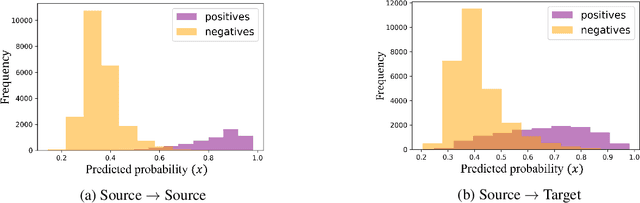

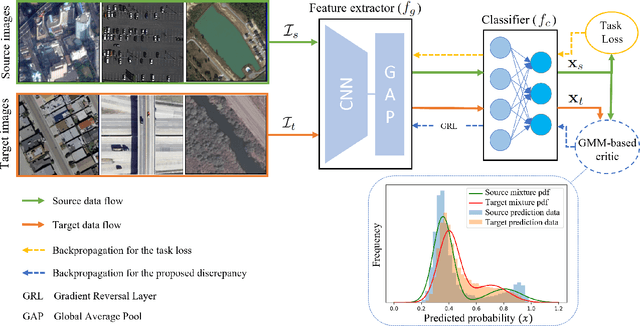
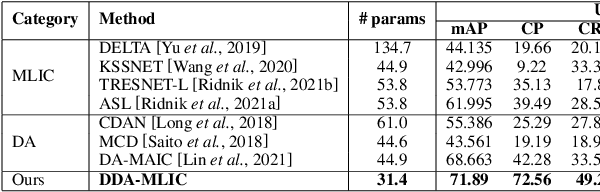
In this paper, a discriminator-free adversarial-based Unsupervised Domain Adaptation (UDA) for Multi-Label Image Classification (MLIC) referred to as DDA-MLIC is proposed. Over the last two years, some attempts have been made for introducing adversarial-based UDA methods in the context of MLIC. However, these methods which rely on an additional discriminator subnet present two shortcomings. First, the learning of domain-invariant features may harm their task-specific discriminative power, since the classification and discrimination tasks are decoupled. Moreover, the use of an additional discriminator usually induces an increase of the network size. Herein, we propose to overcome these issues by introducing a novel adversarial critic that is directly deduced from the task-specific classifier. Specifically, a two-component Gaussian Mixture Model (GMM) is fitted on the source and target predictions, allowing the distinction of two clusters. This allows extracting a Gaussian distribution for each component. The resulting Gaussian distributions are then used for formulating an adversarial loss based on a Frechet distance. The proposed method is evaluated on three multi-label image datasets. The obtained results demonstrate that DDA-MLIC outperforms existing state-of-the-art methods while requiring a lower number of parameters.
A Comprehensive Survey on Segment Anything Model for Vision and Beyond
May 14, 2023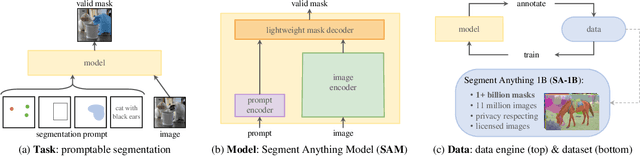
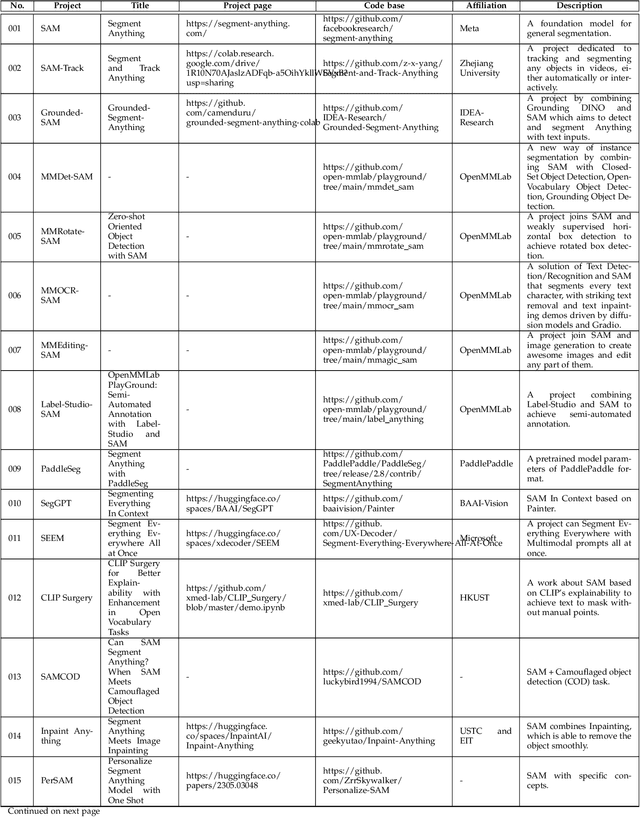

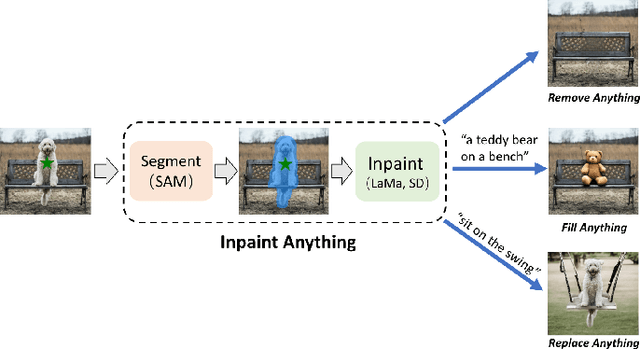
Artificial intelligence (AI) is evolving towards artificial general intelligence, which refers to the ability of an AI system to perform a wide range of tasks and exhibit a level of intelligence similar to that of a human being. This is in contrast to narrow or specialized AI, which is designed to perform specific tasks with a high degree of efficiency. Therefore, it is urgent to design a general class of models, which we term foundation models, trained on broad data that can be adapted to various downstream tasks. The recently proposed segment anything model (SAM) has made significant progress in breaking the boundaries of segmentation, greatly promoting the development of foundation models for computer vision. To fully comprehend SAM, we conduct a survey study. As the first to comprehensively review the progress of segmenting anything task for vision and beyond based on the foundation model of SAM, this work focuses on its applications to various tasks and data types by discussing its historical development, recent progress, and profound impact on broad applications. We first introduce the background and terminology for foundation models including SAM, as well as state-of-the-art methods contemporaneous with SAM that are significant for segmenting anything task. Then, we analyze and summarize the advantages and limitations of SAM across various image processing applications, including software scenes, real-world scenes, and complex scenes. Importantly, some insights are drawn to guide future research to develop more versatile foundation models and improve the architecture of SAM. We also summarize massive other amazing applications of SAM in vision and beyond.
StyleRes: Transforming the Residuals for Real Image Editing with StyleGAN
Dec 29, 2022
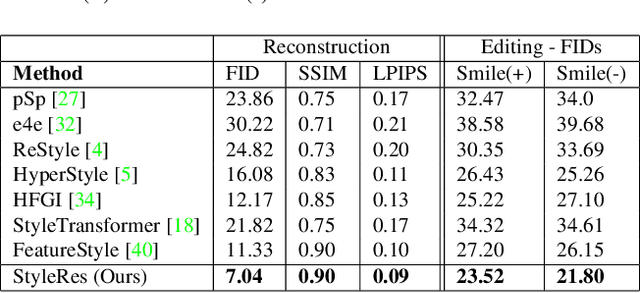

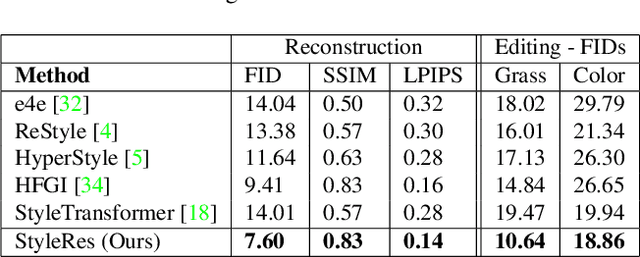
We present a novel image inversion framework and a training pipeline to achieve high-fidelity image inversion with high-quality attribute editing. Inverting real images into StyleGAN's latent space is an extensively studied problem, yet the trade-off between the image reconstruction fidelity and image editing quality remains an open challenge. The low-rate latent spaces are limited in their expressiveness power for high-fidelity reconstruction. On the other hand, high-rate latent spaces result in degradation in editing quality. In this work, to achieve high-fidelity inversion, we learn residual features in higher latent codes that lower latent codes were not able to encode. This enables preserving image details in reconstruction. To achieve high-quality editing, we learn how to transform the residual features for adapting to manipulations in latent codes. We train the framework to extract residual features and transform them via a novel architecture pipeline and cycle consistency losses. We run extensive experiments and compare our method with state-of-the-art inversion methods. Qualitative metrics and visual comparisons show significant improvements. Code: https://github.com/hamzapehlivan/StyleRes
Population-based JPEG Image Compression: Problem Re-Formulation
Dec 13, 2022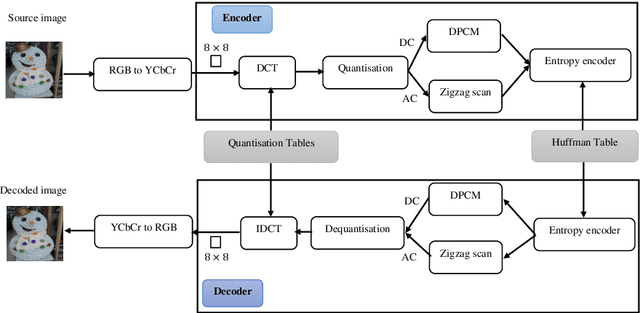
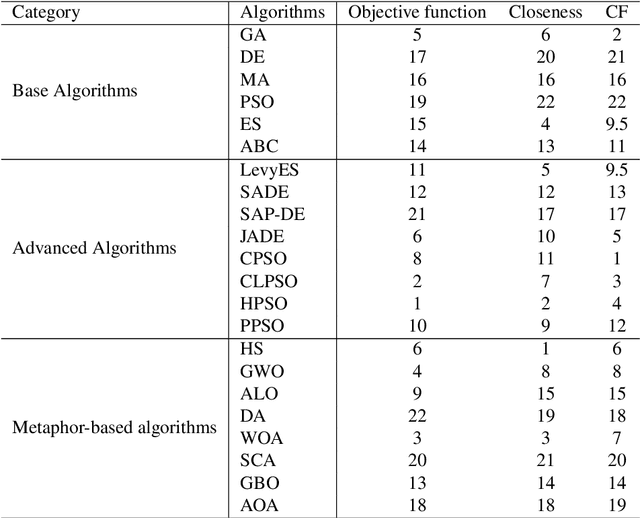
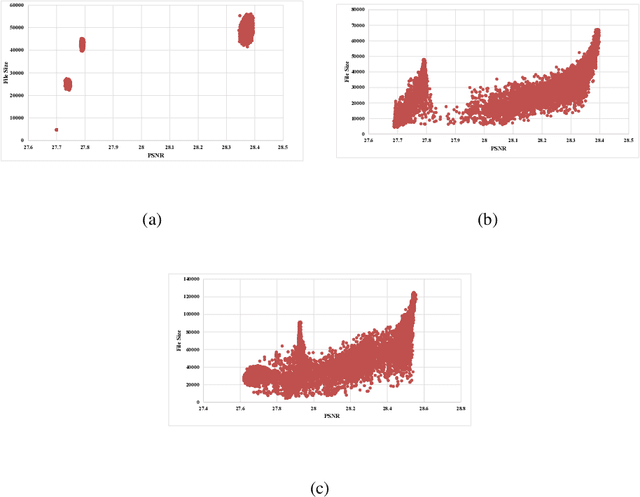

The JPEG standard is widely used in different image processing applications. One of the main components of the JPEG standard is the quantisation table (QT) since it plays a vital role in the image properties such as image quality and file size. In recent years, several efforts based on population-based metaheuristic (PBMH) algorithms have been performed to find the proper QT(s) for a specific image, although they do not take into consideration the user's opinion. Take an android developer as an example, who prefers a small-size image, while the optimisation process results in a high-quality image, leading to a huge file size. Another pitfall of the current works is a lack of comprehensive coverage, meaning that the QT(s) can not provide all possible combinations of file size and quality. Therefore, this paper aims to propose three distinct contributions. First, to include the user's opinion in the compression process, the file size of the output image can be controlled by a user in advance. Second, to tackle the lack of comprehensive coverage, we suggest a novel representation. Our proposed representation can not only provide more comprehensive coverage but also find the proper value for the quality factor for a specific image without any background knowledge. Both changes in representation and objective function are independent of the search strategies and can be used with any type of population-based metaheuristic (PBMH) algorithm. Therefore, as the third contribution, we also provide a comprehensive benchmark on 22 state-of-the-art and recently-introduced PBMH algorithms on our new formulation of JPEG image compression. Our extensive experiments on different benchmark images and in terms of different criteria show that our novel formulation for JPEG image compression can work effectively.
Towards Equitable Representation in Text-to-Image Synthesis Models with the Cross-Cultural Understanding Benchmark (CCUB) Dataset
Jan 28, 2023
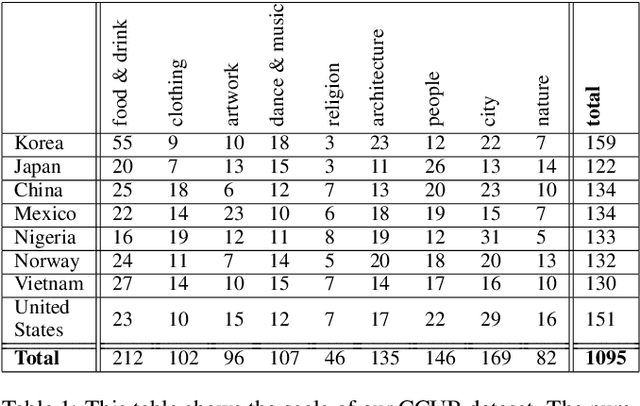


It has been shown that accurate representation in media improves the well-being of the people who consume it. By contrast, inaccurate representations can negatively affect viewers and lead to harmful perceptions of other cultures. To achieve inclusive representation in generated images, we propose a culturally-aware priming approach for text-to-image synthesis using a small but culturally curated dataset that we collected, known here as Cross-Cultural Understanding Benchmark (CCUB) Dataset, to fight the bias prevalent in giant datasets. Our proposed approach is comprised of two fine-tuning techniques: (1) Adding visual context via fine-tuning a pre-trained text-to-image synthesis model, Stable Diffusion, on the CCUB text-image pairs, and (2) Adding semantic context via automated prompt engineering using the fine-tuned large language model, GPT-3, trained on our CCUB culturally-aware text data. CCUB dataset is curated and our approach is evaluated by people who have a personal relationship with that particular culture. Our experiments indicate that priming using both text and image is effective in improving the cultural relevance and decreasing the offensiveness of generated images while maintaining quality.
CORE: Learning Consistent Ordinal REpresentations for Image Ordinal Estimation
Jan 15, 2023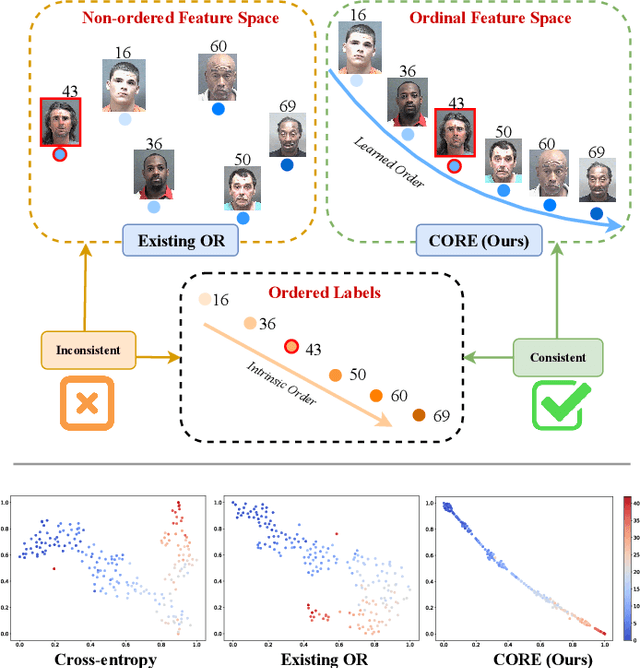
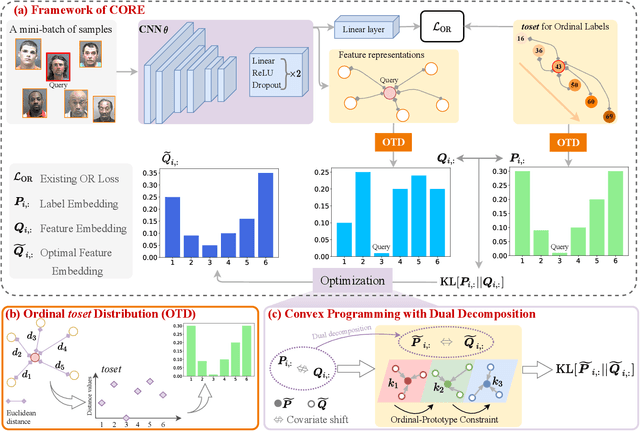
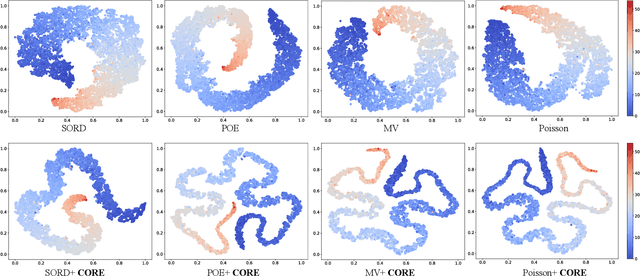
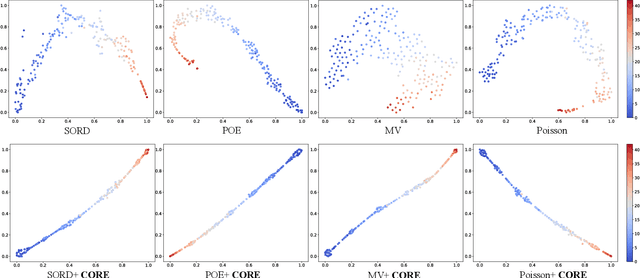
The goal of image ordinal estimation is to estimate the ordinal label of a given image with a convolutional neural network. Existing methods are mainly based on ordinal regression and particularly focus on modeling the ordinal mapping from the feature representation of the input to the ordinal label space. However, the manifold of the resultant feature representations does not maintain the intrinsic ordinal relations of interest, which hinders the effectiveness of the image ordinal estimation. Therefore, this paper proposes learning intrinsic Consistent Ordinal REpresentations (CORE) from ordinal relations residing in groundtruth labels while encouraging the feature representations to embody the ordinal low-dimensional manifold. First, we develop an ordinal totally ordered set (toset) distribution (OTD), which can (i) model the label embeddings to inherit ordinal information and measure distances between ordered labels of samples in a neighborhood, and (ii) model the feature embeddings to infer numerical magnitude with unknown ordinal information among the features of different samples. Second, through OTD, we convert the feature representations and labels into the same embedding space for better alignment, and then compute the Kullback Leibler (KL) divergence between the ordinal labels and feature representations to endow the latent space with consistent ordinal relations. Third, we optimize the KL divergence through ordinal prototype-constrained convex programming with dual decomposition; our theoretical analysis shows that we can obtain the optimal solutions via gradient backpropagation. Extensive experimental results demonstrate that the proposed CORE can accurately construct an ordinal latent space and significantly enhance existing deep ordinal regression methods to achieve better results.
RECLIP: Resource-efficient CLIP by Training with Small Images
Apr 12, 2023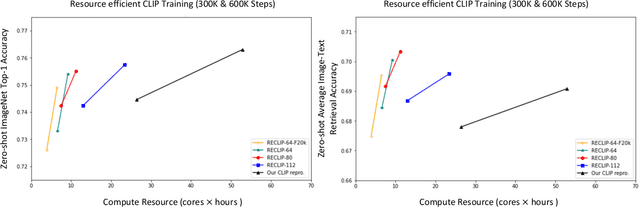
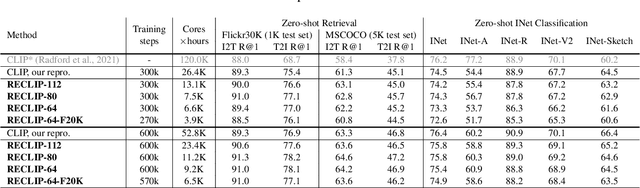
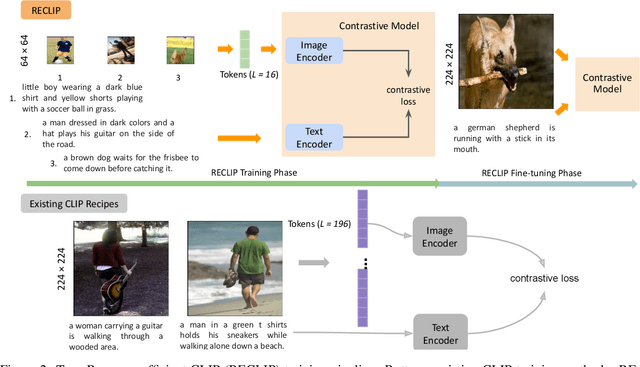

We present RECLIP (Resource-efficient CLIP), a simple method that minimizes computational resource footprint for CLIP (Contrastive Language Image Pretraining). Inspired by the notion of coarse-to-fine in computer vision, we leverage small images to learn from large-scale language supervision efficiently, and finetune the model with high-resolution data in the end. Since the complexity of the vision transformer heavily depends on input image size, our approach significantly reduces the training resource requirements both in theory and in practice. Using the same batch size and training epoch, RECLIP achieves highly competitive zero-shot classification and image text retrieval accuracy with 6 to 8$\times$ less computational resources and 7 to 9$\times$ fewer FLOPs than the baseline. Compared to the state-of-the-art contrastive learning methods, RECLIP demonstrates 5 to 59$\times$ training resource savings while maintaining highly competitive zero-shot classification and retrieval performance. We hope this work will pave the path for the broader research community to explore language supervised pretraining in more resource-friendly settings.