 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Face Feature Visualisation of Single Morphing Attack Detection
Apr 25, 2023
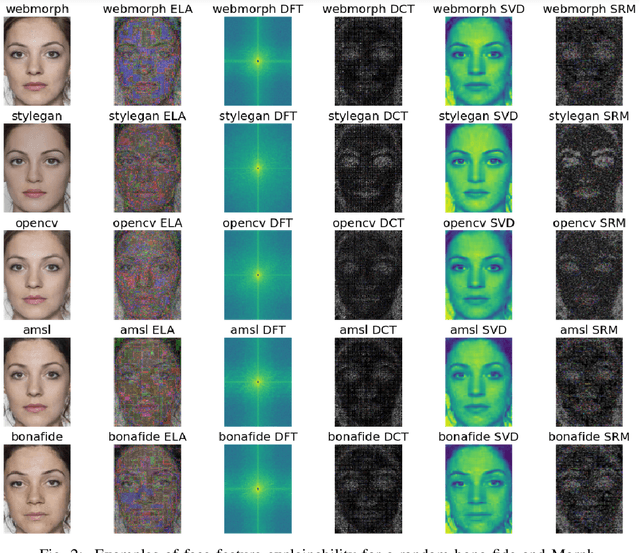
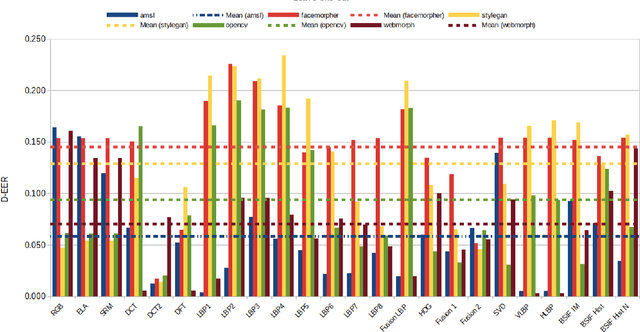
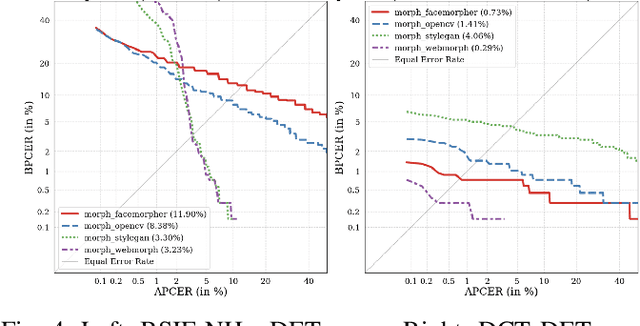
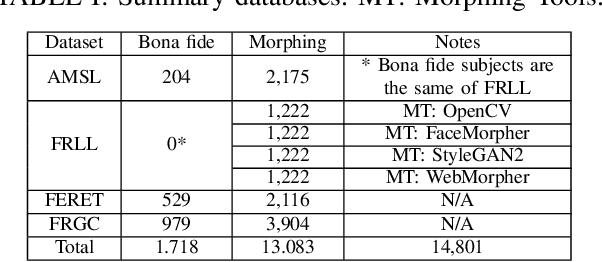
This paper proposes an explainable visualisation of different face feature extraction algorithms that enable the detection of bona fide and morphing images for single morphing attack detection. The feature extraction is based on raw image, shape, texture, frequency and compression. This visualisation may help to develop a Graphical User Interface for border policies and specifically for border guard personnel that have to investigate details of suspect images. A Random forest classifier was trained in a leave-one-out protocol on three landmarks-based face morphing methods and a StyleGAN-based morphing method for which morphed images are available in the FRLL database. For morphing attack detection, the Discrete Cosine-Transformation-based method obtained the best results for synthetic images and BSIF for landmark-based image features.
Translating Simulation Images to X-ray Images via Multi-Scale Semantic Matching
Apr 16, 2023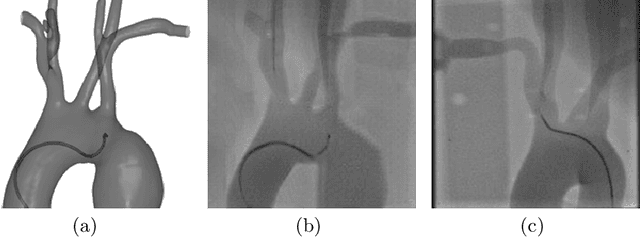
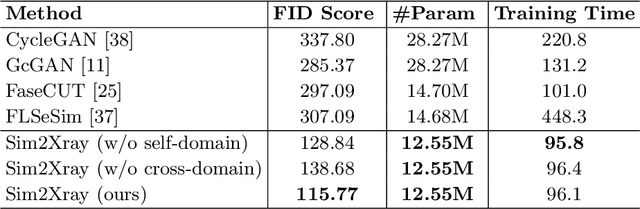
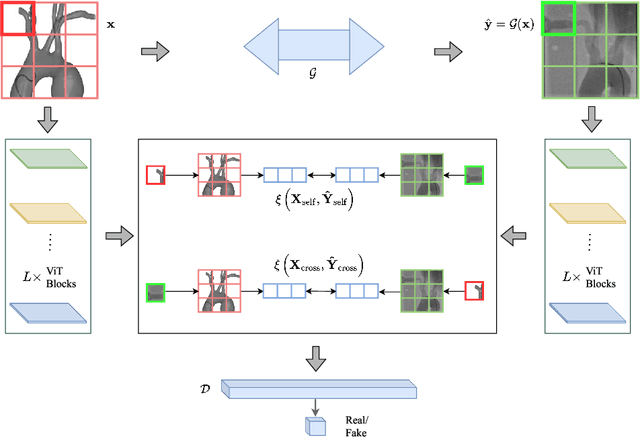
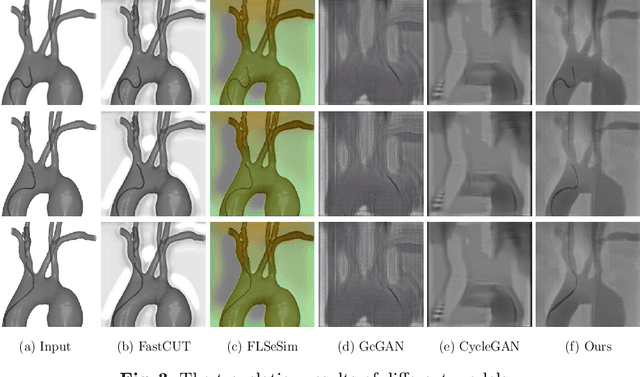
Endovascular intervention training is increasingly being conducted in virtual simulators. However, transferring the experience from endovascular simulators to the real world remains an open problem. The key challenge is the virtual environments are usually not realistically simulated, especially the simulation images. In this paper, we propose a new method to translate simulation images from an endovascular simulator to X-ray images. Previous image-to-image translation methods often focus on visual effects and neglect structure information, which is critical for medical images. To address this gap, we propose a new method that utilizes multi-scale semantic matching. We apply self-domain semantic matching to ensure that the input image and the generated image have the same positional semantic relationships. We further apply cross-domain matching to eliminate the effects of different styles. The intensive experiment shows that our method generates realistic X-ray images and outperforms other state-of-the-art approaches by a large margin. We also collect a new large-scale dataset to serve as the new benchmark for this task. Our source code and dataset will be made publicly available.
ArtiFact: A Large-Scale Dataset with Artificial and Factual Images for Generalizable and Robust Synthetic Image Detection
Feb 24, 2023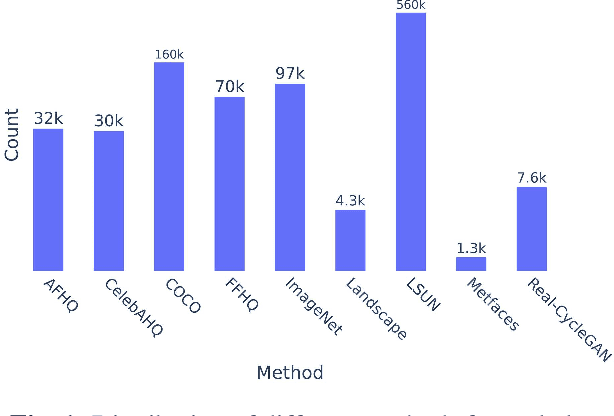

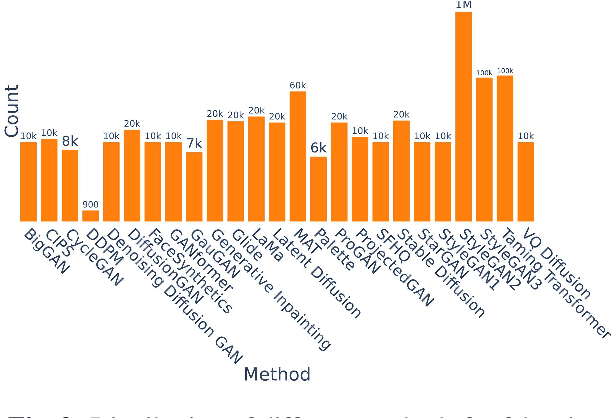

Synthetic image generation has opened up new opportunities but has also created threats in regard to privacy, authenticity, and security. Detecting fake images is of paramount importance to prevent illegal activities, and previous research has shown that generative models leave unique patterns in their synthetic images that can be exploited to detect them. However, the fundamental problem of generalization remains, as even state-of-the-art detectors encounter difficulty when facing generators never seen during training. To assess the generalizability and robustness of synthetic image detectors in the face of real-world impairments, this paper presents a large-scale dataset named ArtiFact, comprising diverse generators, object categories, and real-world challenges. Moreover, the proposed multi-class classification scheme, combined with a filter stride reduction strategy addresses social platform impairments and effectively detects synthetic images from both seen and unseen generators. The proposed solution significantly outperforms other top teams by 8.34% on Test 1, 1.26% on Test 2, and 15.08% on Test 3 in the IEEE VIP Cup challenge at ICIP 2022, as measured by the accuracy metric.
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
Nov 22, 2022
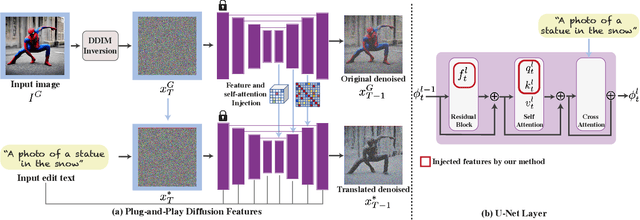

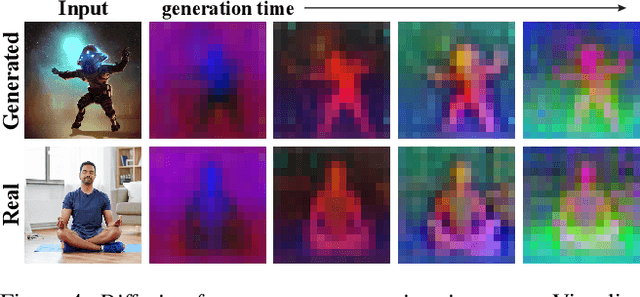
Large-scale text-to-image generative models have been a revolutionary breakthrough in the evolution of generative AI, allowing us to synthesize diverse images that convey highly complex visual concepts. However, a pivotal challenge in leveraging such models for real-world content creation tasks is providing users with control over the generated content. In this paper, we present a new framework that takes text-to-image synthesis to the realm of image-to-image translation -- given a guidance image and a target text prompt, our method harnesses the power of a pre-trained text-to-image diffusion model to generate a new image that complies with the target text, while preserving the semantic layout of the source image. Specifically, we observe and empirically demonstrate that fine-grained control over the generated structure can be achieved by manipulating spatial features and their self-attention inside the model. This results in a simple and effective approach, where features extracted from the guidance image are directly injected into the generation process of the target image, requiring no training or fine-tuning and applicable for both real or generated guidance images. We demonstrate high-quality results on versatile text-guided image translation tasks, including translating sketches, rough drawings and animations into realistic images, changing of the class and appearance of objects in a given image, and modifications of global qualities such as lighting and color.
Adapting Pre-trained Vision Transformers from 2D to 3D through Weight Inflation Improves Medical Image Segmentation
Feb 08, 2023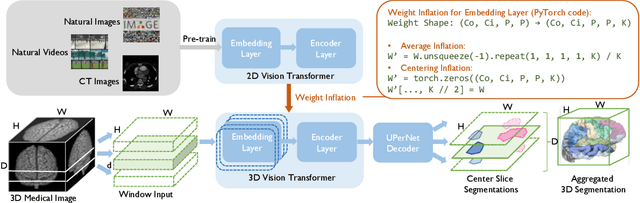
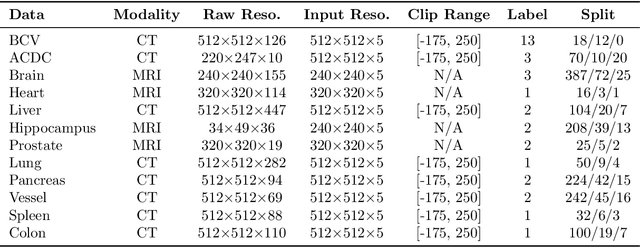
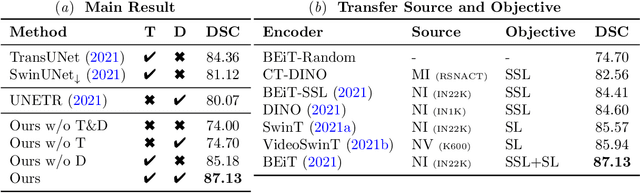
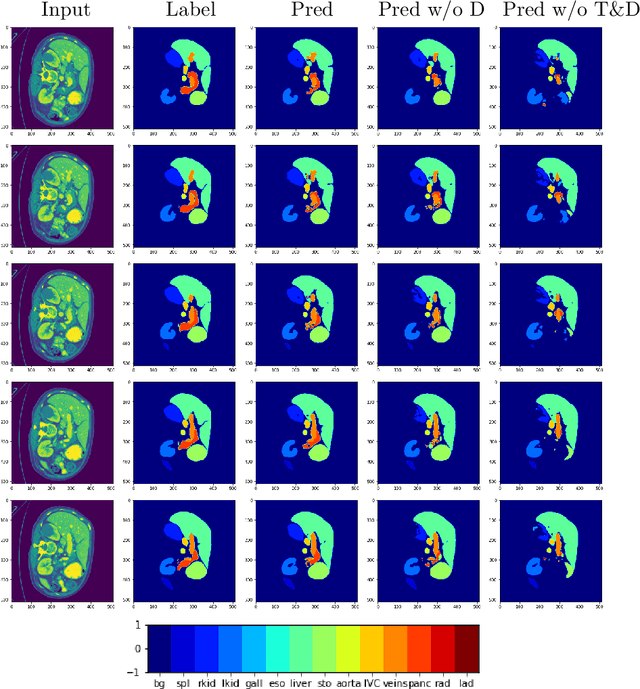
Given the prevalence of 3D medical imaging technologies such as MRI and CT that are widely used in diagnosing and treating diverse diseases, 3D segmentation is one of the fundamental tasks of medical image analysis. Recently, Transformer-based models have started to achieve state-of-the-art performances across many vision tasks, through pre-training on large-scale natural image benchmark datasets. While works on medical image analysis have also begun to explore Transformer-based models, there is currently no optimal strategy to effectively leverage pre-trained Transformers, primarily due to the difference in dimensionality between 2D natural images and 3D medical images. Existing solutions either split 3D images into 2D slices and predict each slice independently, thereby losing crucial depth-wise information, or modify the Transformer architecture to support 3D inputs without leveraging pre-trained weights. In this work, we use a simple yet effective weight inflation strategy to adapt pre-trained Transformers from 2D to 3D, retaining the benefit of both transfer learning and depth information. We further investigate the effectiveness of transfer from different pre-training sources and objectives. Our approach achieves state-of-the-art performances across a broad range of 3D medical image datasets, and can become a standard strategy easily utilized by all work on Transformer-based models for 3D medical images, to maximize performance.
FICE: Text-Conditioned Fashion Image Editing With Guided GAN Inversion
Jan 05, 2023


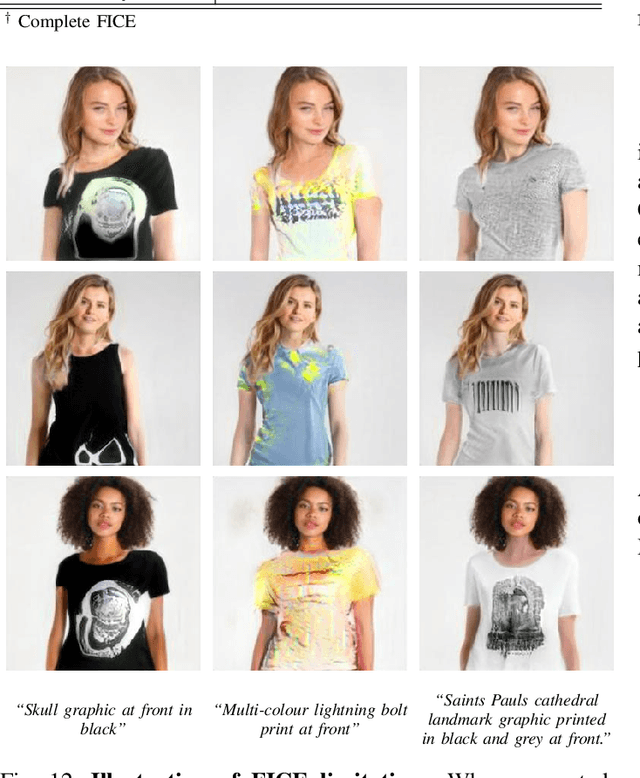
Fashion-image editing represents a challenging computer vision task, where the goal is to incorporate selected apparel into a given input image. Most existing techniques, known as Virtual Try-On methods, deal with this task by first selecting an example image of the desired apparel and then transferring the clothing onto the target person. Conversely, in this paper, we consider editing fashion images with text descriptions. Such an approach has several advantages over example-based virtual try-on techniques, e.g.: (i) it does not require an image of the target fashion item, and (ii) it allows the expression of a wide variety of visual concepts through the use of natural language. Existing image-editing methods that work with language inputs are heavily constrained by their requirement for training sets with rich attribute annotations or they are only able to handle simple text descriptions. We address these constraints by proposing a novel text-conditioned editing model, called FICE (Fashion Image CLIP Editing), capable of handling a wide variety of diverse text descriptions to guide the editing procedure. Specifically with FICE, we augment the common GAN inversion process by including semantic, pose-related, and image-level constraints when generating images. We leverage the capabilities of the CLIP model to enforce the semantics, due to its impressive image-text association capabilities. We furthermore propose a latent-code regularization technique that provides the means to better control the fidelity of the synthesized images. We validate FICE through rigorous experiments on a combination of VITON images and Fashion-Gen text descriptions and in comparison with several state-of-the-art text-conditioned image editing approaches. Experimental results demonstrate FICE generates highly realistic fashion images and leads to stronger editing performance than existing competing approaches.
SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections
Feb 02, 2023
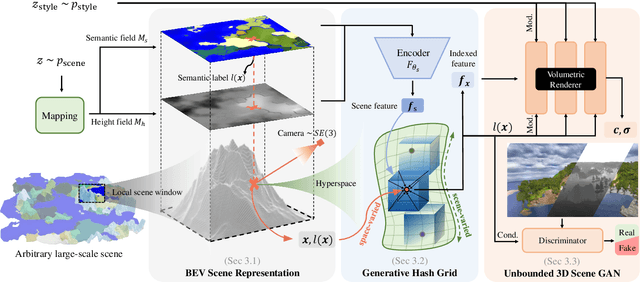
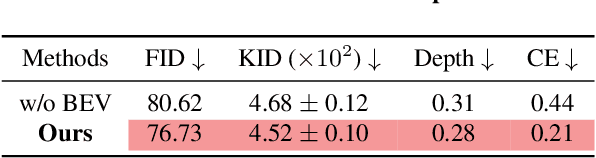
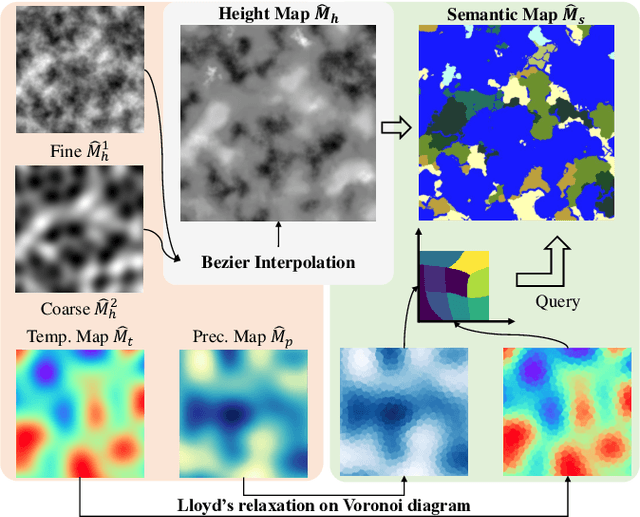
In this work, we present SceneDreamer, an unconditional generative model for unbounded 3D scenes, which synthesizes large-scale 3D landscapes from random noises. Our framework is learned from in-the-wild 2D image collections only, without any 3D annotations. At the core of SceneDreamer is a principled learning paradigm comprising 1) an efficient yet expressive 3D scene representation, 2) a generative scene parameterization, and 3) an effective renderer that can leverage the knowledge from 2D images. Our framework starts from an efficient bird's-eye-view (BEV) representation generated from simplex noise, which consists of a height field and a semantic field. The height field represents the surface elevation of 3D scenes, while the semantic field provides detailed scene semantics. This BEV scene representation enables 1) representing a 3D scene with quadratic complexity, 2) disentangled geometry and semantics, and 3) efficient training. Furthermore, we propose a novel generative neural hash grid to parameterize the latent space given 3D positions and the scene semantics, which aims to encode generalizable features across scenes. Lastly, a neural volumetric renderer, learned from 2D image collections through adversarial training, is employed to produce photorealistic images. Extensive experiments demonstrate the effectiveness of SceneDreamer and superiority over state-of-the-art methods in generating vivid yet diverse unbounded 3D worlds.
Few-Shot Image-to-Semantics Translation for Policy Transfer in Reinforcement Learning
Jan 31, 2023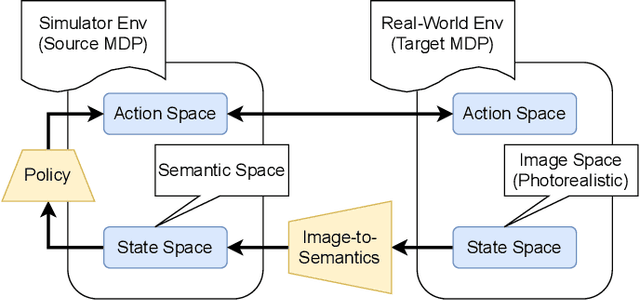
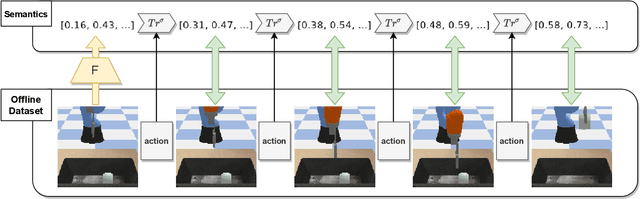

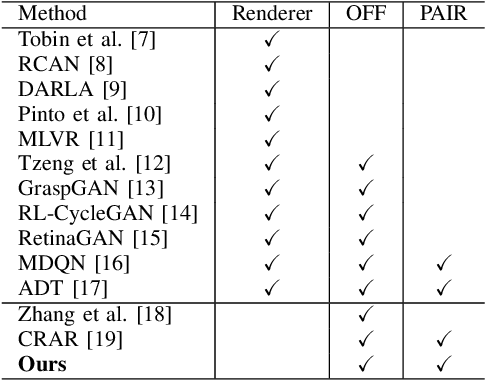
We investigate policy transfer using image-to-semantics translation to mitigate learning difficulties in vision-based robotics control agents. This problem assumes two environments: a simulator environment with semantics, that is, low-dimensional and essential information, as the state space, and a real-world environment with images as the state space. By learning mapping from images to semantics, we can transfer a policy, pre-trained in the simulator, to the real world, thereby eliminating real-world on-policy agent interactions to learn, which are costly and risky. In addition, using image-to-semantics mapping is advantageous in terms of the computational efficiency to train the policy and the interpretability of the obtained policy over other types of sim-to-real transfer strategies. To tackle the main difficulty in learning image-to-semantics mapping, namely the human annotation cost for producing a training dataset, we propose two techniques: pair augmentation with the transition function in the simulator environment and active learning. We observed a reduction in the annotation cost without a decline in the performance of the transfer, and the proposed approach outperformed the existing approach without annotation.
Explaining Image Classifiers with Multiscale Directional Image Representation
Nov 24, 2022
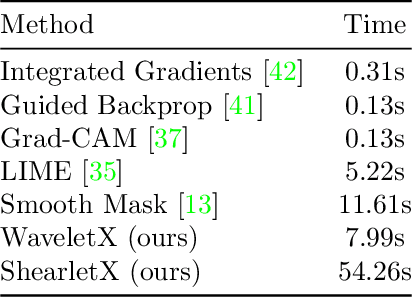


Image classifiers are known to be difficult to interpret and therefore require explanation methods to understand their decisions. We present ShearletX, a novel mask explanation method for image classifiers based on the shearlet transform -- a multiscale directional image representation. Current mask explanation methods are regularized by smoothness constraints that protect against undesirable fine-grained explanation artifacts. However, the smoothness of a mask limits its ability to separate fine-detail patterns, that are relevant for the classifier, from nearby nuisance patterns, that do not affect the classifier. ShearletX solves this problem by avoiding smoothness regularization all together, replacing it by shearlet sparsity constraints. The resulting explanations consist of a few edges, textures, and smooth parts of the original image, that are the most relevant for the decision of the classifier. To support our method, we propose a mathematical definition for explanation artifacts and an information theoretic score to evaluate the quality of mask explanations. We demonstrate the superiority of ShearletX over previous mask based explanation methods using these new metrics, and present exemplary situations where separating fine-detail patterns allows explaining phenomena that were not explainable before.
LDMIC: Learning-based Distributed Multi-view Image Coding
Jan 24, 2023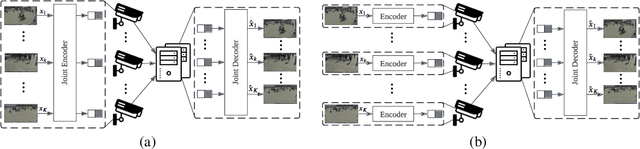
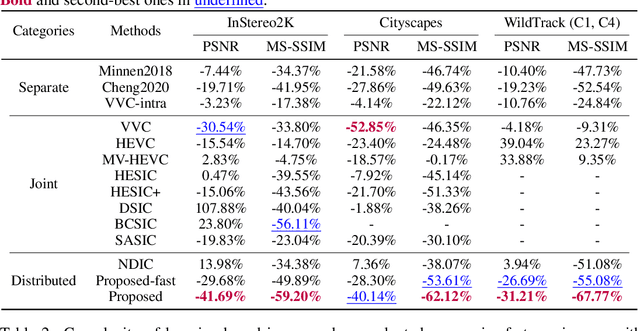
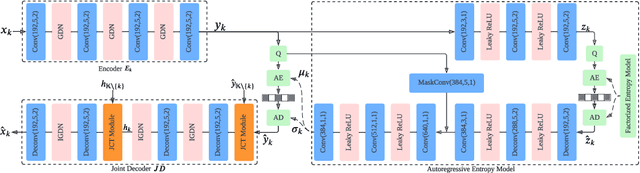
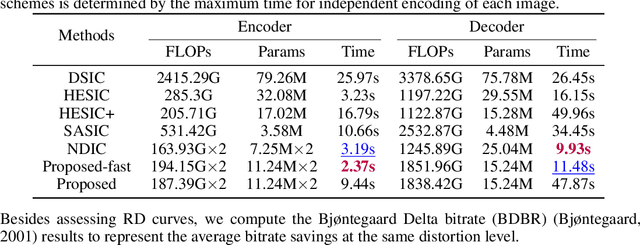
Multi-view image compression plays a critical role in 3D-related applications. Existing methods adopt a predictive coding architecture, which requires joint encoding to compress the corresponding disparity as well as residual information. This demands collaboration among cameras and enforces the epipolar geometric constraint between different views, which makes it challenging to deploy these methods in distributed camera systems with randomly overlapping fields of view. Meanwhile, distributed source coding theory indicates that efficient data compression of correlated sources can be achieved by independent encoding and joint decoding, which motivates us to design a learning-based distributed multi-view image coding (LDMIC) framework. With independent encoders, LDMIC introduces a simple yet effective joint context transfer module based on the cross-attention mechanism at the decoder to effectively capture the global inter-view correlations, which is insensitive to the geometric relationships between images. Experimental results show that LDMIC significantly outperforms both traditional and learning-based MIC methods while enjoying fast encoding speed. Code will be released at https://github.com/Xinjie-Q/LDMIC.