 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-supervised Photographic Image Layout Representation Learning
Mar 06, 2024

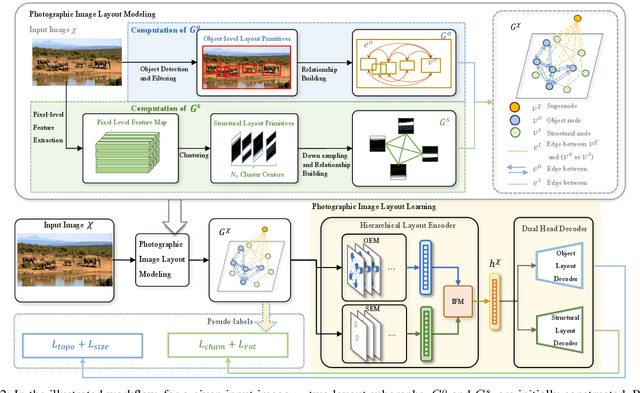
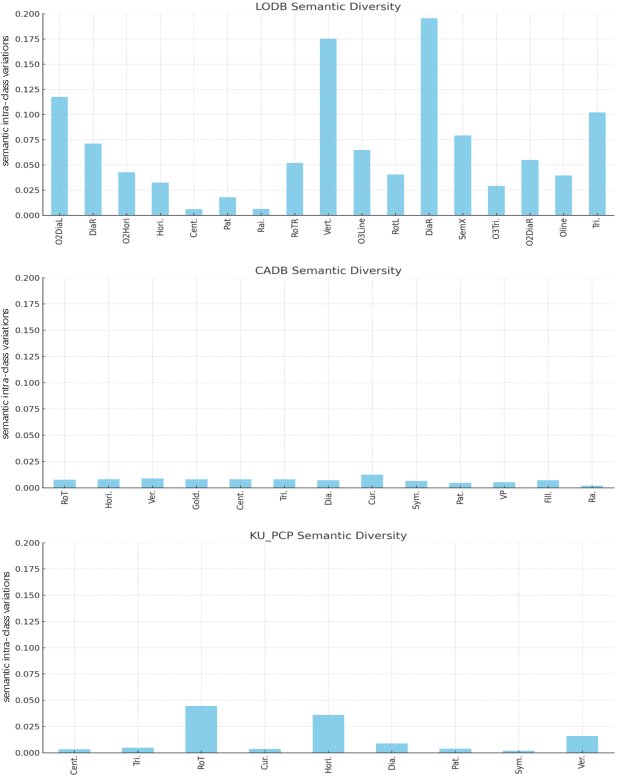

In the domain of image layout representation learning, the critical process of translating image layouts into succinct vector forms is increasingly significant across diverse applications, such as image retrieval, manipulation, and generation. Most approaches in this area heavily rely on costly labeled datasets and notably lack in adapting their modeling and learning methods to the specific nuances of photographic image layouts. This shortfall makes the learning process for photographic image layouts suboptimal. In our research, we directly address these challenges. We innovate by defining basic layout primitives that encapsulate various levels of layout information and by mapping these, along with their interconnections, onto a heterogeneous graph structure. This graph is meticulously engineered to capture the intricate layout information within the pixel domain explicitly. Advancing further, we introduce novel pretext tasks coupled with customized loss functions, strategically designed for effective self-supervised learning of these layout graphs. Building on this foundation, we develop an autoencoder-based network architecture skilled in compressing these heterogeneous layout graphs into precise, dimensionally-reduced layout representations. Additionally, we introduce the LODB dataset, which features a broader range of layout categories and richer semantics, serving as a comprehensive benchmark for evaluating the effectiveness of layout representation learning methods. Our extensive experimentation on this dataset demonstrates the superior performance of our approach in the realm of photographic image layout representation learning.
Ground-A-Score: Scaling Up the Score Distillation for Multi-Attribute Editing
Mar 20, 2024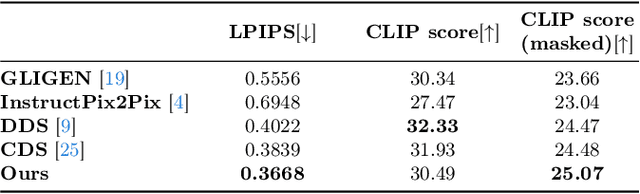
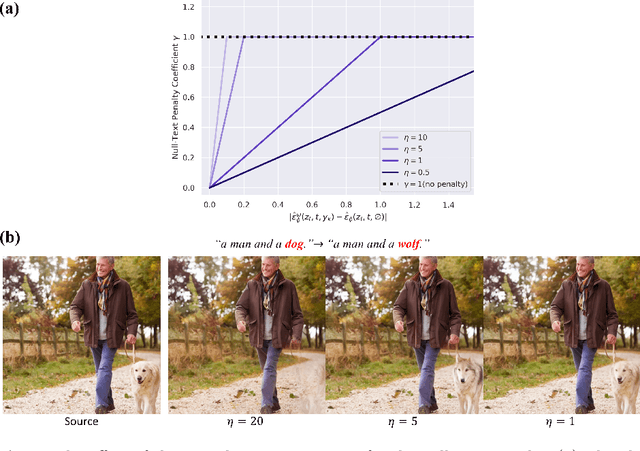


Despite recent advancements in text-to-image diffusion models facilitating various image editing techniques, complex text prompts often lead to an oversight of some requests due to a bottleneck in processing text information. To tackle this challenge, we present Ground-A-Score, a simple yet powerful model-agnostic image editing method by incorporating grounding during score distillation. This approach ensures a precise reflection of intricate prompt requirements in the editing outcomes, taking into account the prior knowledge of the object locations within the image. Moreover, the selective application with a new penalty coefficient and contrastive loss helps to precisely target editing areas while preserving the integrity of the objects in the source image. Both qualitative assessments and quantitative analyses confirm that Ground-A-Score successfully adheres to the intricate details of extended and multifaceted prompts, ensuring high-quality outcomes that respect the original image attributes.
Leveraging Near-Field Lighting for Monocular Depth Estimation from Endoscopy Videos
Mar 26, 2024Monocular depth estimation in endoscopy videos can enable assistive and robotic surgery to obtain better coverage of the organ and detection of various health issues. Despite promising progress on mainstream, natural image depth estimation, techniques perform poorly on endoscopy images due to a lack of strong geometric features and challenging illumination effects. In this paper, we utilize the photometric cues, i.e., the light emitted from an endoscope and reflected by the surface, to improve monocular depth estimation. We first create two novel loss functions with supervised and self-supervised variants that utilize a per-pixel shading representation. We then propose a novel depth refinement network (PPSNet) that leverages the same per-pixel shading representation. Finally, we introduce teacher-student transfer learning to produce better depth maps from both synthetic data with supervision and clinical data with self-supervision. We achieve state-of-the-art results on the C3VD dataset while estimating high-quality depth maps from clinical data. Our code, pre-trained models, and supplementary materials can be found on our project page: https://ppsnet.github.io/
Boosting Diffusion Models with Moving Average Sampling in Frequency Domain
Mar 26, 2024Diffusion models have recently brought a powerful revolution in image generation. Despite showing impressive generative capabilities, most of these models rely on the current sample to denoise the next one, possibly resulting in denoising instability. In this paper, we reinterpret the iterative denoising process as model optimization and leverage a moving average mechanism to ensemble all the prior samples. Instead of simply applying moving average to the denoised samples at different timesteps, we first map the denoised samples to data space and then perform moving average to avoid distribution shift across timesteps. In view that diffusion models evolve the recovery from low-frequency components to high-frequency details, we further decompose the samples into different frequency components and execute moving average separately on each component. We name the complete approach "Moving Average Sampling in Frequency domain (MASF)". MASF could be seamlessly integrated into mainstream pre-trained diffusion models and sampling schedules. Extensive experiments on both unconditional and conditional diffusion models demonstrate that our MASF leads to superior performances compared to the baselines, with almost negligible additional complexity cost.
To Supervise or Not to Supervise: Understanding and Addressing the Key Challenges of 3D Transfer Learning
Mar 26, 2024Transfer learning has long been a key factor in the advancement of many fields including 2D image analysis. Unfortunately, its applicability in 3D data processing has been relatively limited. While several approaches for 3D transfer learning have been proposed in recent literature, with contrastive learning gaining particular prominence, most existing methods in this domain have only been studied and evaluated in limited scenarios. Most importantly, there is currently a lack of principled understanding of both when and why 3D transfer learning methods are applicable. Remarkably, even the applicability of standard supervised pre-training is poorly understood. In this work, we conduct the first in-depth quantitative and qualitative investigation of supervised and contrastive pre-training strategies and their utility in downstream 3D tasks. We demonstrate that layer-wise analysis of learned features provides significant insight into the downstream utility of trained networks. Informed by this analysis, we propose a simple geometric regularization strategy, which improves the transferability of supervised pre-training. Our work thus sheds light onto both the specific challenges of 3D transfer learning, as well as strategies to overcome them.
A foundation model utilizing chest CT volumes and radiology reports for supervised-level zero-shot detection of abnormalities
Mar 26, 2024A major challenge in computational research in 3D medical imaging is the lack of comprehensive datasets. Addressing this issue, our study introduces CT-RATE, the first 3D medical imaging dataset that pairs images with textual reports. CT-RATE consists of 25,692 non-contrast chest CT volumes, expanded to 50,188 through various reconstructions, from 21,304 unique patients, along with corresponding radiology text reports. Leveraging CT-RATE, we developed CT-CLIP, a CT-focused contrastive language-image pre-training framework. As a versatile, self-supervised model, CT-CLIP is designed for broad application and does not require task-specific training. Remarkably, CT-CLIP outperforms state-of-the-art, fully supervised methods in multi-abnormality detection across all key metrics, thus eliminating the need for manual annotation. We also demonstrate its utility in case retrieval, whether using imagery or textual queries, thereby advancing knowledge dissemination. The open-source release of CT-RATE and CT-CLIP marks a significant advancement in medical AI, enhancing 3D imaging analysis and fostering innovation in healthcare.
Waveform Design for Joint Communication and SAR Imaging Under Random Signaling
Mar 26, 2024Conventional synthetic aperture radar (SAR) imaging systems typically employ deterministic signal designs, which lack the capability to convey communication information and are thus not suitable for integrated sensing and communication (ISAC) scenarios. In this letter, we propose a joint communication and SAR imaging (JCASAR) system based on orthogonal frequency-division multiplexing (OFDM) signal with cyclic prefix (CP), which is capable of reconstructing the target profile while serving a communication user. In contrast to traditional matched filters, we propose a least squares (LS) estimator for range profiling. Then the SAR image is obtained followed by range cell migration correction (RCMC) and azimuth processing. By minimizing the mean squared error (MSE) of the proposed LS estimator, we investigate the optimal waveform design for SAR imaging, and JCASAR under random signaling, where power allocation strategies are conceived for Gaussian-distributed ISAC signals, in an effort to strike a flexible performance tradeoff between the communication and SAR imaging tasks. Numerical results are provided to validate the effectiveness of the proposed ISAC waveform design for JCASAR systems.
DiffGaze: A Diffusion Model for Continuous Gaze Sequence Generation on 360° Images
Mar 26, 2024We present DiffGaze, a novel method for generating realistic and diverse continuous human gaze sequences on 360{\deg} images based on a conditional score-based denoising diffusion model. Generating human gaze on 360{\deg} images is important for various human-computer interaction and computer graphics applications, e.g. for creating large-scale eye tracking datasets or for realistic animation of virtual humans. However, existing methods are limited to predicting discrete fixation sequences or aggregated saliency maps, thereby neglecting crucial parts of natural gaze behaviour. Our method uses features extracted from 360{\deg} images as condition and uses two transformers to model the temporal and spatial dependencies of continuous human gaze. We evaluate DiffGaze on two 360{\deg} image benchmarks for gaze sequence generation as well as scanpath prediction and saliency prediction. Our evaluations show that DiffGaze outperforms state-of-the-art methods on all tasks on both benchmarks. We also report a 21-participant user study showing that our method generates gaze sequences that are indistinguishable from real human sequences.
Pensieve: Retrospect-then-Compare Mitigates Visual Hallucination
Mar 21, 2024
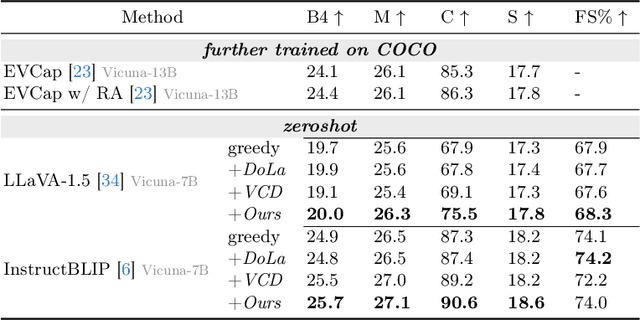
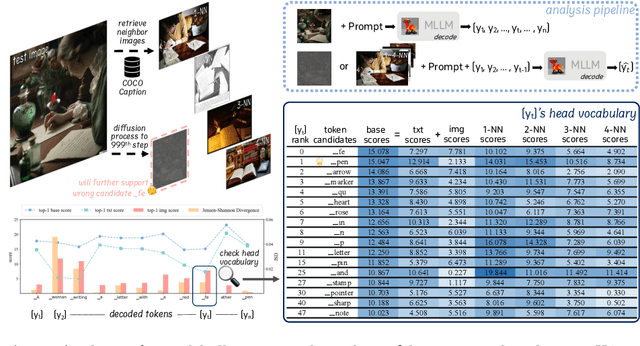
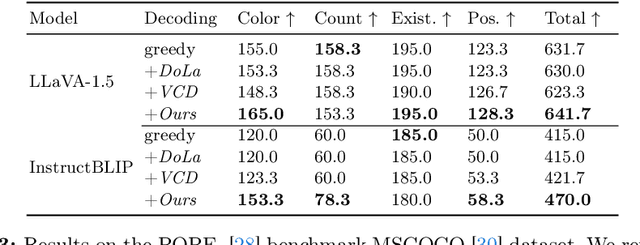
Multi-modal Large Language Models (MLLMs) demonstrate remarkable success across various vision-language tasks. However, they suffer from visual hallucination, where the generated responses diverge from the provided image. Are MLLMs completely oblivious to accurate visual cues when they hallucinate? Our investigation reveals that the visual branch may simultaneously advocate both accurate and non-existent content. To address this issue, we propose Pensieve, a training-free method inspired by our observation that analogous visual hallucinations can arise among images sharing common semantic and appearance characteristics. During inference, Pensieve enables MLLMs to retrospect relevant images as references and compare them with the test image. This paradigm assists MLLMs in downgrading hallucinatory content mistakenly supported by the visual input. Experiments on Whoops, MME, POPE, and LLaVA Bench demonstrate the efficacy of Pensieve in mitigating visual hallucination, surpassing other advanced decoding strategies. Additionally, Pensieve aids MLLMs in identifying details in the image and enhancing the specificity of image descriptions.
QSMDiff: Unsupervised 3D Diffusion Models for Quantitative Susceptibility Mapping
Mar 21, 2024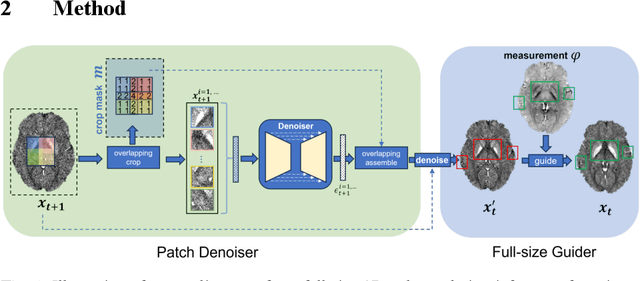
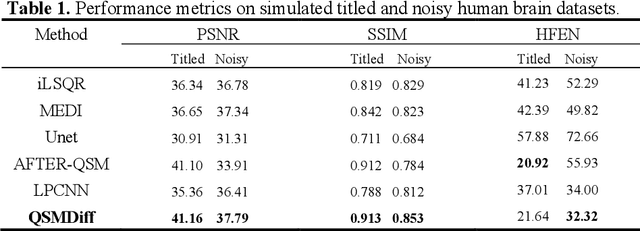
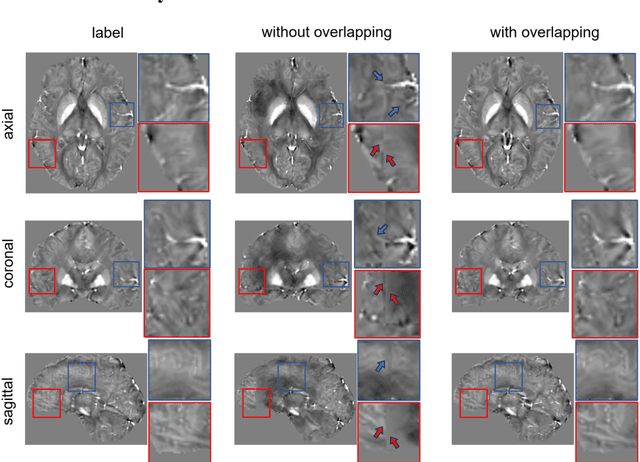
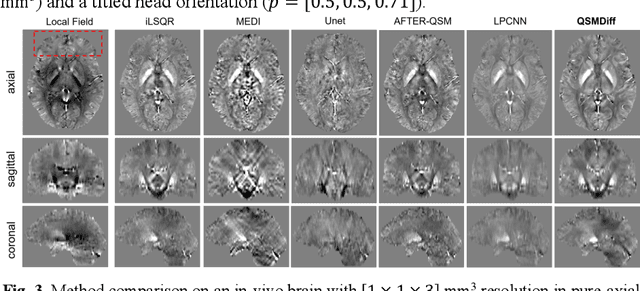
Quantitative Susceptibility Mapping (QSM) dipole inversion is an ill-posed inverse problem for quantifying magnetic susceptibility distributions from MRI tissue phases. While supervised deep learning methods have shown success in specific QSM tasks, their generalizability across different acquisition scenarios remains constrained. Recent developments in diffusion models have demonstrated potential for solving 2D medical imaging inverse problems. However, their application to 3D modalities, such as QSM, remains challenging due to high computational demands. In this work, we developed a 3D image patch-based diffusion model, namely QSMDiff, for robust QSM reconstruction across different scan parameters, alongside simultaneous super-resolution and image-denoising tasks. QSMDiff adopts unsupervised 3D image patch training and full-size measurement guidance during inference for controlled image generation. Evaluation on simulated and in-vivo human brains, using gradient-echo and echo-planar imaging sequences across different acquisition parameters, demonstrates superior performance. The method proposed in QSMDiff also holds promise for impacting other 3D medical imaging applications beyond QSM.