 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Efficient Ensemble Explainable AI (XAI) Approach for Morphed Face Detection
Apr 23, 2023
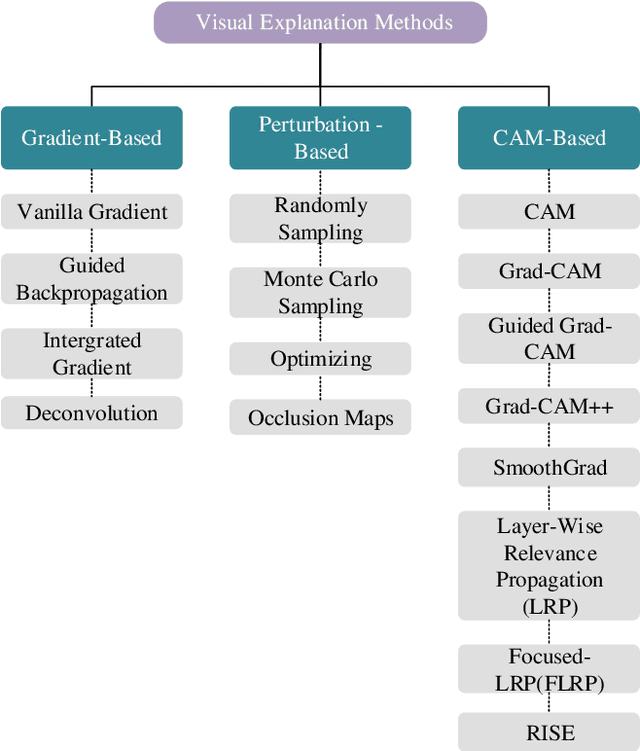

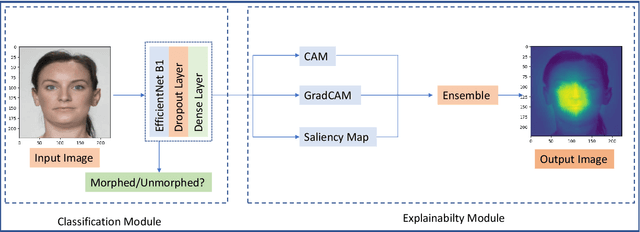
The extensive utilization of biometric authentication systems have emanated attackers / imposters to forge user identity based on morphed images. In this attack, a synthetic image is produced and merged with genuine. Next, the resultant image is user for authentication. Numerous deep neural convolutional architectures have been proposed in literature for face Morphing Attack Detection (MADs) to prevent such attacks and lessen the risks associated with them. Although, deep learning models achieved optimal results in terms of performance, it is difficult to understand and analyse these networks since they are black box/opaque in nature. As a consequence, incorrect judgments may be made. There is, however, a dearth of literature that explains decision-making methods of black box deep learning models for biometric Presentation Attack Detection (PADs) or MADs that can aid the biometric community to have trust in deep learning-based biometric systems for identification and authentication in various security applications such as border control, criminal database establishment etc. In this work, we present a novel visual explanation approach named Ensemble XAI integrating Saliency maps, Class Activation Maps (CAM) and Gradient-CAM (Grad-CAM) to provide a more comprehensive visual explanation for a deep learning prognostic model (EfficientNet-B1) that we have employed to predict whether the input presented to a biometric authentication system is morphed or genuine. The experimentations have been performed on three publicly available datasets namely Face Research Lab London Set, Wide Multi-Channel Presentation Attack (WMCA), and Makeup Induced Face Spoofing (MIFS). The experimental evaluations affirms that the resultant visual explanations highlight more fine-grained details of image features/areas focused by EfficientNet-B1 to reach decisions along with appropriate reasoning.
What does CLIP know about a red circle? Visual prompt engineering for VLMs
Apr 13, 2023
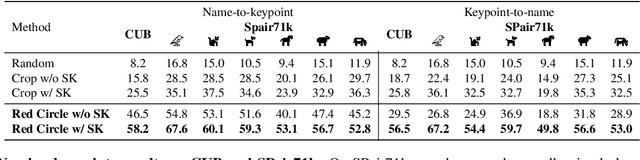
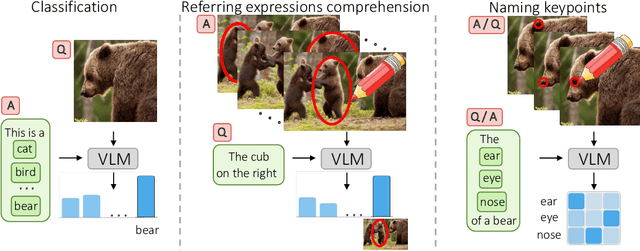

Large-scale Vision-Language Models, such as CLIP, learn powerful image-text representations that have found numerous applications, from zero-shot classification to text-to-image generation. Despite that, their capabilities for solving novel discriminative tasks via prompting fall behind those of large language models, such as GPT-3. Here we explore the idea of visual prompt engineering for solving computer vision tasks beyond classification by editing in image space instead of text. In particular, we discover an emergent ability of CLIP, where, by simply drawing a red circle around an object, we can direct the model's attention to that region, while also maintaining global information. We show the power of this simple approach by achieving state-of-the-art in zero-shot referring expressions comprehension and strong performance in keypoint localization tasks. Finally, we draw attention to some potential ethical concerns of large language-vision models.
CECT: Controllable Ensemble CNN and Transformer for COVID-19 image classification by capturing both local and global image features
Feb 05, 2023
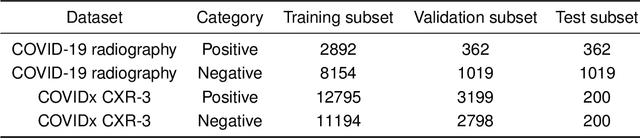
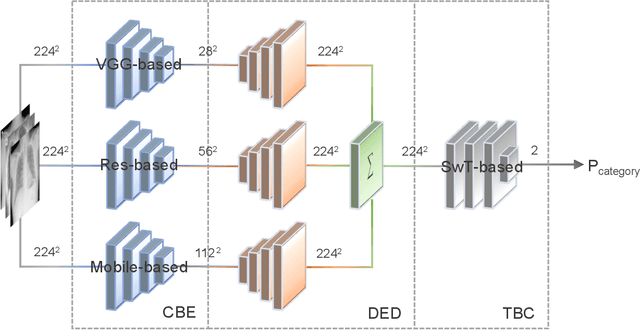
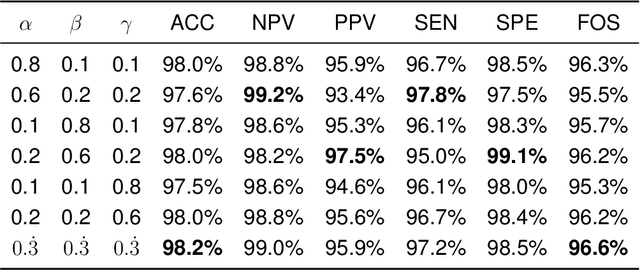
Purpose: Most computer vision models are developed based on either convolutional neural network (CNN) or transformer, while the former (latter) method captures local (global) features. To relieve model performance limitations due to the lack of global (local) features, we develop a novel classification network named CECT by controllable ensemble CNN and transformer. Methods: The proposed CECT is composed of a CNN-based encoder block, a deconvolution-ensemble decoder block, and a transformer-based classification block. Different from conventional CNN- or transformer-based methods, our CECT can capture features at both multi-local and global scales, and the contribution of local features at different scales can be controlled with the proposed ensemble coefficients. Results: We evaluate CECT on two public COVID-19 datasets and it outperforms other state-of-the-art methods on all evaluation metrics. Conclusion: With remarkable feature capture ability, we believe CECT can also be used in other medical image classification scenarios to assist the diagnosis.
Accuracy Improvement of Object Detection in VVC Coded Video Using YOLO-v7 Features
Apr 03, 2023
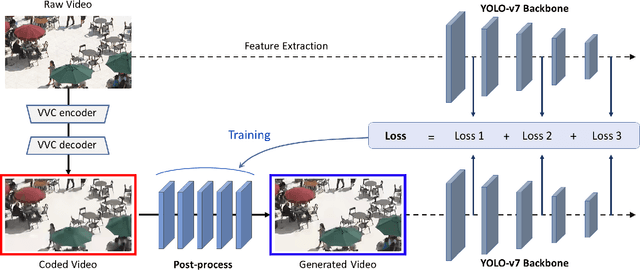
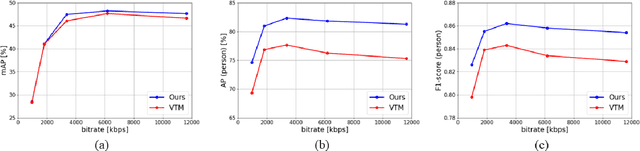

With advances in image recognition technology based on deep learning, automatic video analysis by Artificial Intelligence is becoming more widespread. As the amount of video used for image recognition increases, efficient compression methods for such video data are necessary. In general, when the image quality deteriorates due to image encoding, the image recognition accuracy also falls. Therefore, in this paper, we propose a neural-network-based approach to improve image recognition accuracy, especially the object detection accuracy by applying post-processing to the encoded video. Versatile Video Coding (VVC) will be used for the video compression method, since it is the latest video coding method with the best encoding performance. The neural network is trained using the features of YOLO-v7, the latest object detection model. By using VVC as the video coding method and YOLO-v7 as the detection model, high object detection accuracy is achieved even at low bit rates. Experimental results show that the combination of the proposed method and VVC achieves better coding performance than regular VVC in object detection accuracy.
Learning Monocular Depth in Dynamic Environment via Context-aware Temporal Attention
May 12, 2023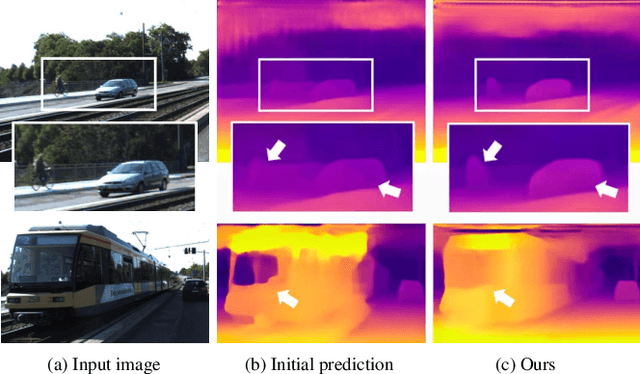

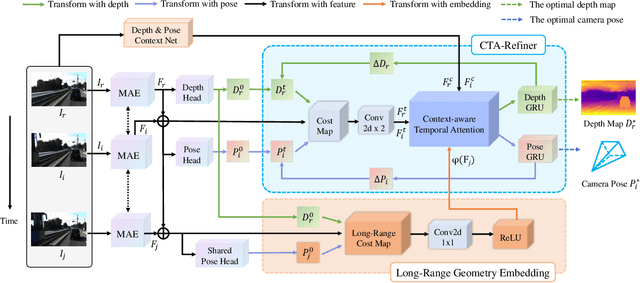
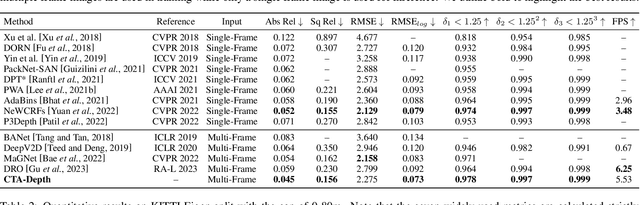
The monocular depth estimation task has recently revealed encouraging prospects, especially for the autonomous driving task. To tackle the ill-posed problem of 3D geometric reasoning from 2D monocular images, multi-frame monocular methods are developed to leverage the perspective correlation information from sequential temporal frames. However, moving objects such as cars and trains usually violate the static scene assumption, leading to feature inconsistency deviation and misaligned cost values, which would mislead the optimization algorithm. In this work, we present CTA-Depth, a Context-aware Temporal Attention guided network for multi-frame monocular Depth estimation. Specifically, we first apply a multi-level attention enhancement module to integrate multi-level image features to obtain an initial depth and pose estimation. Then the proposed CTA-Refiner is adopted to alternatively optimize the depth and pose. During the refinement process, context-aware temporal attention (CTA) is developed to capture the global temporal-context correlations to maintain the feature consistency and estimation integrity of moving objects. In particular, we propose a long-range geometry embedding (LGE) module to produce a long-range temporal geometry prior. Our approach achieves significant improvements over state-of-the-art approaches on three benchmark datasets.
Ship-D: Ship Hull Dataset for Design Optimization using Machine Learning
May 16, 2023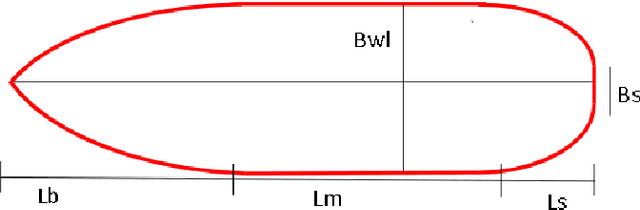


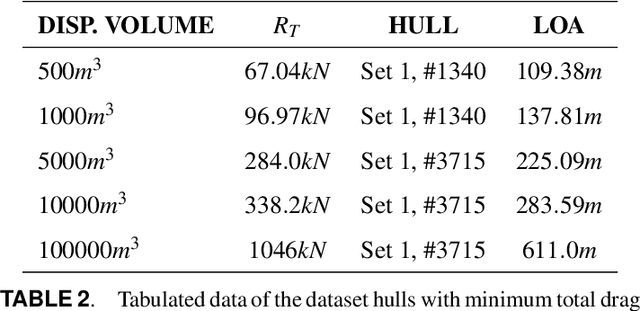
Machine learning has recently made significant strides in reducing design cycle time for complex products. Ship design, which currently involves years long cycles and small batch production, could greatly benefit from these advancements. By developing a machine learning tool for ship design that learns from the design of many different types of ships, tradeoffs in ship design could be identified and optimized. However, the lack of publicly available ship design datasets currently limits the potential for leveraging machine learning in generalized ship design. To address this gap, this paper presents a large dataset of thirty thousand ship hulls, each with design and functional performance information, including parameterization, mesh, point cloud, and image representations, as well as thirty two hydrodynamic drag measures under different operating conditions. The dataset is structured to allow human input and is also designed for computational methods. Additionally, the paper introduces a set of twelve ship hulls from publicly available CAD repositories to showcase the proposed parameterizations ability to accurately reconstruct existing hulls. A surrogate model was developed to predict the thirty two wave drag coefficients, which was then implemented in a genetic algorithm case study to reduce the total drag of a hull by sixty percent while maintaining the shape of the hulls cross section and the length of the parallel midbody. Our work provides a comprehensive dataset and application examples for other researchers to use in advancing data driven ship design.
Image-and-Language Understanding from Pixels Only
Dec 15, 2022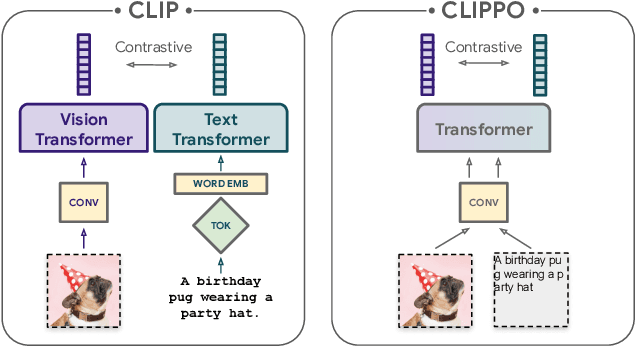
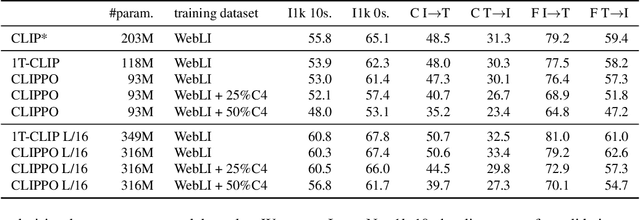
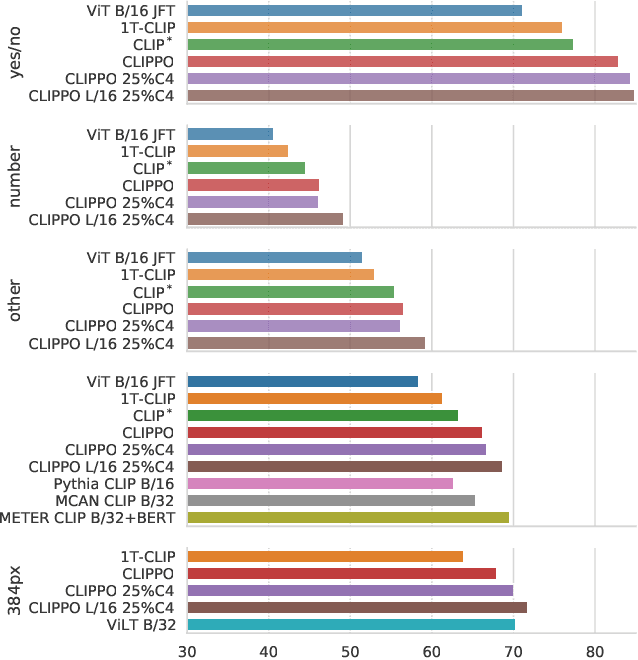
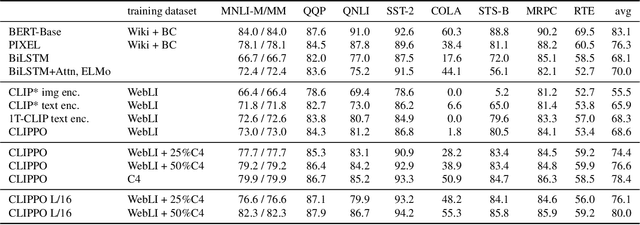
Multimodal models are becoming increasingly effective, in part due to unified components, such as the Transformer architecture. However, multimodal models still often consist of many task- and modality-specific pieces and training procedures. For example, CLIP (Radford et al., 2021) trains independent text and image towers via a contrastive loss. We explore an additional unification: the use of a pure pixel-based model to perform image, text, and multimodal tasks. Our model is trained with contrastive loss alone, so we call it CLIP-Pixels Only (CLIPPO). CLIPPO uses a single encoder that processes both regular images and text rendered as images. CLIPPO performs image-based tasks such as retrieval and zero-shot image classification almost as well as CLIP, with half the number of parameters and no text-specific tower or embedding. When trained jointly via image-text contrastive learning and next-sentence contrastive learning, CLIPPO can perform well on natural language understanding tasks, without any word-level loss (language modelling or masked language modelling), outperforming pixel-based prior work. Surprisingly, CLIPPO can obtain good accuracy in visual question answering, simply by rendering the question and image together. Finally, we exploit the fact that CLIPPO does not require a tokenizer to show that it can achieve strong performance on multilingual multimodal retrieval without
Are Multimodal Models Robust to Image and Text Perturbations?
Dec 15, 2022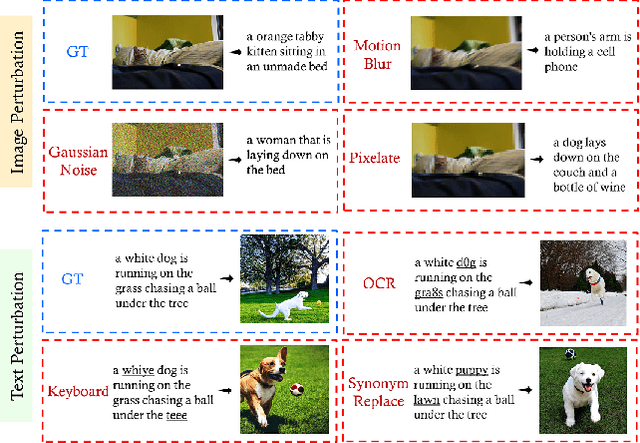
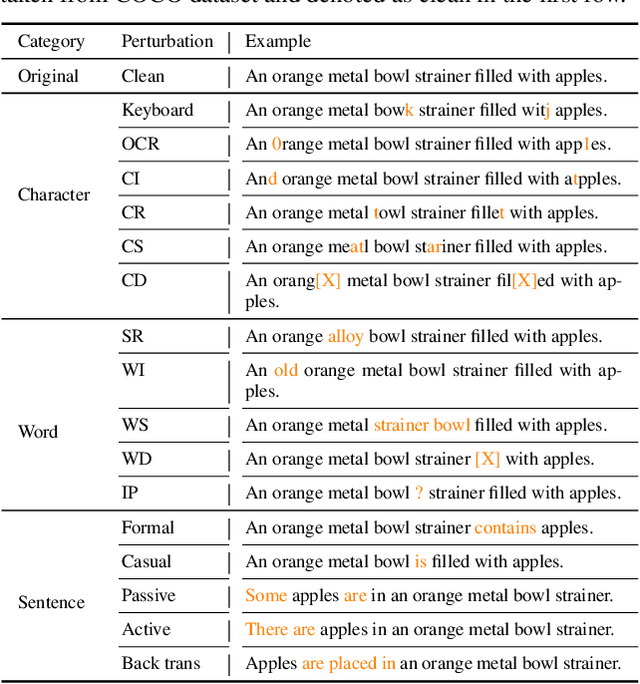


Multimodal image-text models have shown remarkable performance in the past few years. However, evaluating their robustness against distribution shifts is crucial before adopting them in real-world applications. In this paper, we investigate the robustness of 9 popular open-sourced image-text models under common perturbations on five tasks (image-text retrieval, visual reasoning, visual entailment, image captioning, and text-to-image generation). In particular, we propose several new multimodal robustness benchmarks by applying 17 image perturbation and 16 text perturbation techniques on top of existing datasets. We observe that multimodal models are not robust to image and text perturbations, especially to image perturbations. Among the tested perturbation methods, character-level perturbations constitute the most severe distribution shift for text, and zoom blur is the most severe shift for image data. We also introduce two new robustness metrics (MMI and MOR) for proper evaluations of multimodal models. We hope our extensive study sheds light on new directions for the development of robust multimodal models.
Improving Diffusion Models for Scene Text Editing with Dual Encoders
Apr 12, 2023
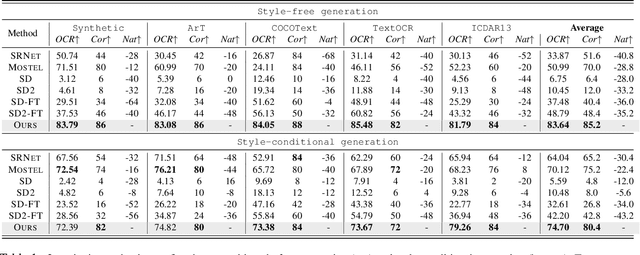

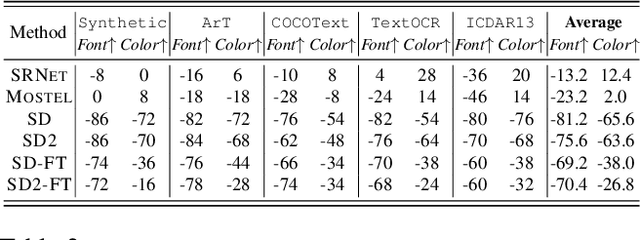
Scene text editing is a challenging task that involves modifying or inserting specified texts in an image while maintaining its natural and realistic appearance. Most previous approaches to this task rely on style-transfer models that crop out text regions and feed them into image transfer models, such as GANs. However, these methods are limited in their ability to change text style and are unable to insert texts into images. Recent advances in diffusion models have shown promise in overcoming these limitations with text-conditional image editing. However, our empirical analysis reveals that state-of-the-art diffusion models struggle with rendering correct text and controlling text style. To address these problems, we propose DIFFSTE to improve pre-trained diffusion models with a dual encoder design, which includes a character encoder for better text legibility and an instruction encoder for better style control. An instruction tuning framework is introduced to train our model to learn the mapping from the text instruction to the corresponding image with either the specified style or the style of the surrounding texts in the background. Such a training method further brings our method the zero-shot generalization ability to the following three scenarios: generating text with unseen font variation, e.g., italic and bold, mixing different fonts to construct a new font, and using more relaxed forms of natural language as the instructions to guide the generation task. We evaluate our approach on five datasets and demonstrate its superior performance in terms of text correctness, image naturalness, and style controllability. Our code is publicly available. https://github.com/UCSB-NLP-Chang/DiffSTE
ShadowFormer: Global Context Helps Image Shadow Removal
Feb 03, 2023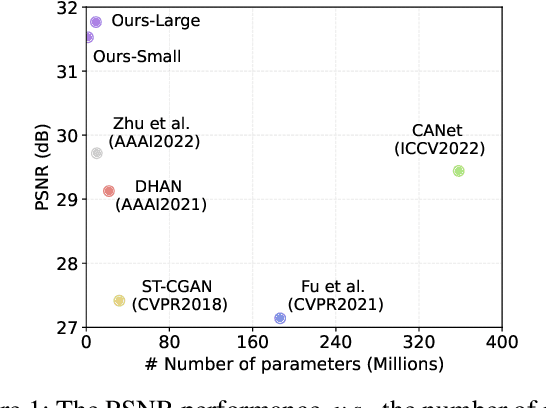
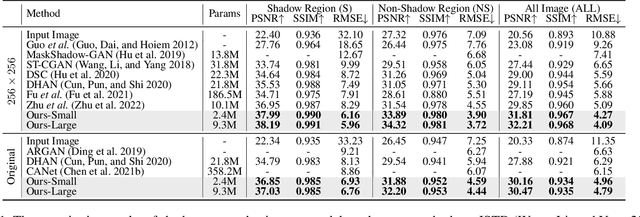
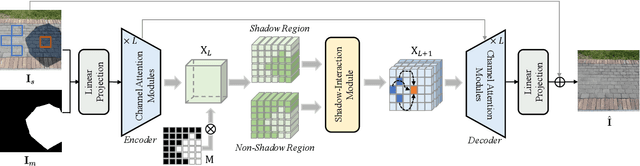
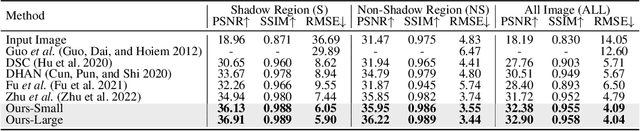
Recent deep learning methods have achieved promising results in image shadow removal. However, most of the existing approaches focus on working locally within shadow and non-shadow regions, resulting in severe artifacts around the shadow boundaries as well as inconsistent illumination between shadow and non-shadow regions. It is still challenging for the deep shadow removal model to exploit the global contextual correlation between shadow and non-shadow regions. In this work, we first propose a Retinex-based shadow model, from which we derive a novel transformer-based network, dubbed ShandowFormer, to exploit non-shadow regions to help shadow region restoration. A multi-scale channel attention framework is employed to hierarchically capture the global information. Based on that, we propose a Shadow-Interaction Module (SIM) with Shadow-Interaction Attention (SIA) in the bottleneck stage to effectively model the context correlation between shadow and non-shadow regions. We conduct extensive experiments on three popular public datasets, including ISTD, ISTD+, and SRD, to evaluate the proposed method. Our method achieves state-of-the-art performance by using up to 150X fewer model parameters.