 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Muse: Text-To-Image Generation via Masked Generative Transformers
Jan 02, 2023



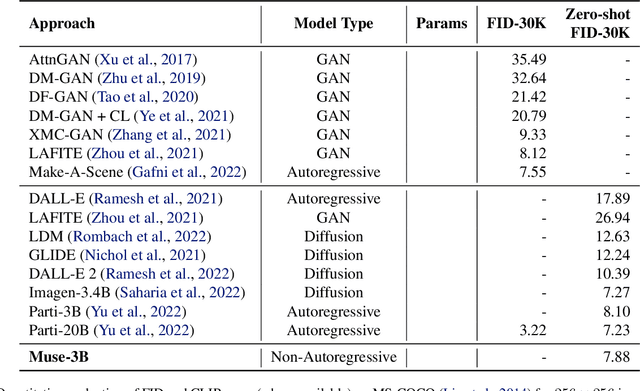
We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing. More results are available at https://muse-model.github.io
What Affects Learned Equivariance in Deep Image Recognition Models?
Apr 07, 2023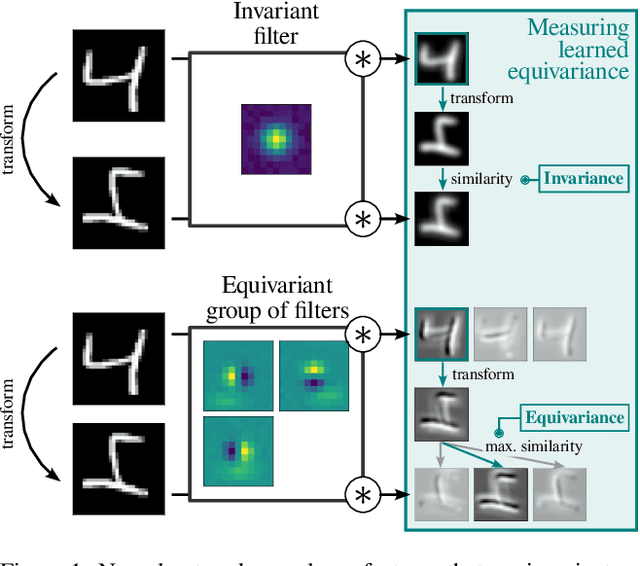
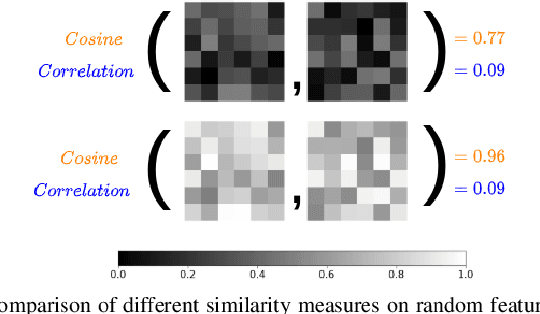
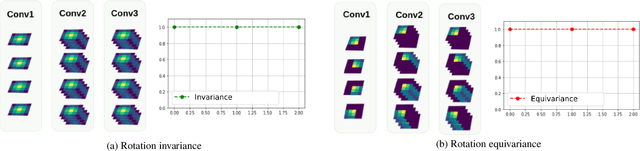
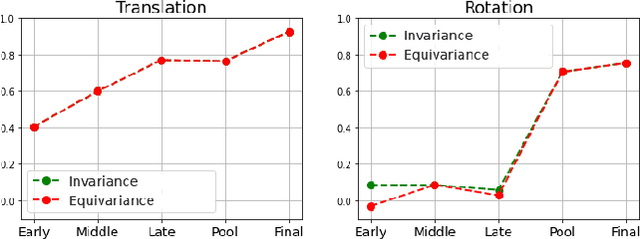
Equivariance w.r.t. geometric transformations in neural networks improves data efficiency, parameter efficiency and robustness to out-of-domain perspective shifts. When equivariance is not designed into a neural network, the network can still learn equivariant functions from the data. We quantify this learned equivariance, by proposing an improved measure for equivariance. We find evidence for a correlation between learned translation equivariance and validation accuracy on ImageNet. We therefore investigate what can increase the learned equivariance in neural networks, and find that data augmentation, reduced model capacity and inductive bias in the form of convolutions induce higher learned equivariance in neural networks.
A Comprehensive Survey on Segment Anything Model for Vision and Beyond
May 19, 2023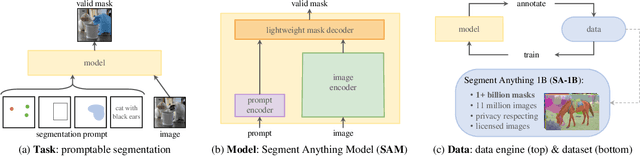

Artificial intelligence (AI) is evolving towards artificial general intelligence, which refers to the ability of an AI system to perform a wide range of tasks and exhibit a level of intelligence similar to that of a human being. This is in contrast to narrow or specialized AI, which is designed to perform specific tasks with a high degree of efficiency. Therefore, it is urgent to design a general class of models, which we term foundation models, trained on broad data that can be adapted to various downstream tasks. The recently proposed segment anything model (SAM) has made significant progress in breaking the boundaries of segmentation, greatly promoting the development of foundation models for computer vision. To fully comprehend SAM, we conduct a survey study. As the first to comprehensively review the progress of segmenting anything task for vision and beyond based on the foundation model of SAM, this work focuses on its applications to various tasks and data types by discussing its historical development, recent progress, and profound impact on broad applications. We first introduce the background and terminology for foundation models including SAM, as well as state-of-the-art methods contemporaneous with SAM that are significant for segmenting anything task. Then, we analyze and summarize the advantages and limitations of SAM across various image processing applications, including software scenes, real-world scenes, and complex scenes. Importantly, many insights are drawn to guide future research to develop more versatile foundation models and improve the architecture of SAM. We also summarize massive other amazing applications of SAM in vision and beyond. Finally, we maintain a continuously updated paper list and an open-source project summary for foundation model SAM at \href{https://github.com/liliu-avril/Awesome-Segment-Anything}{\color{magenta}{here}}.
AutoCoreset: An Automatic Practical Coreset Construction Framework
May 19, 2023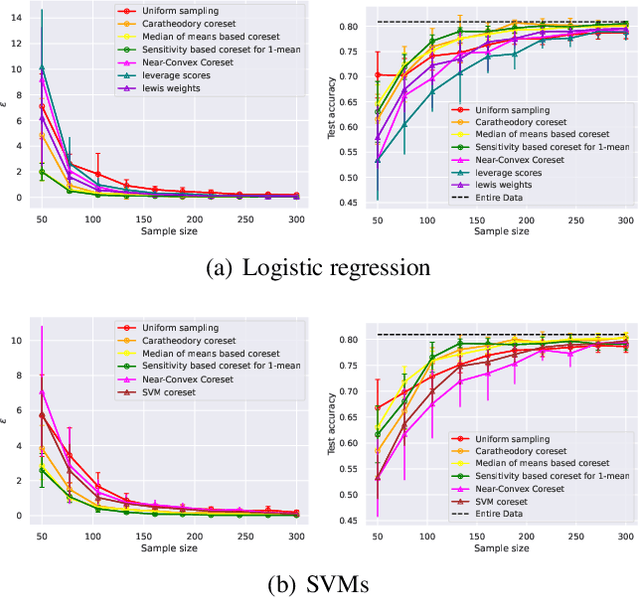
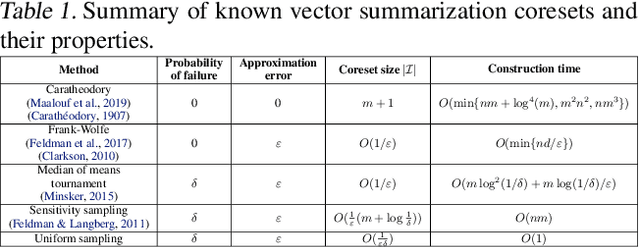
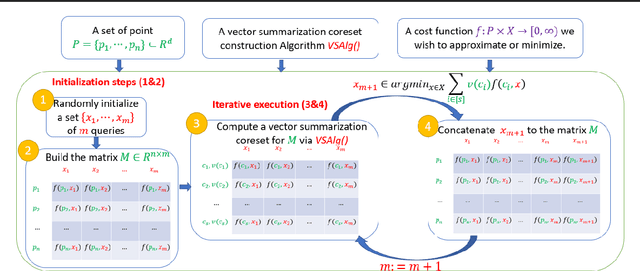

A coreset is a tiny weighted subset of an input set, that closely resembles the loss function, with respect to a certain set of queries. Coresets became prevalent in machine learning as they have shown to be advantageous for many applications. While coreset research is an active research area, unfortunately, coresets are constructed in a problem-dependent manner, where for each problem, a new coreset construction algorithm is usually suggested, a process that may take time or may be hard for new researchers in the field. Even the generic frameworks require additional (problem-dependent) computations or proofs to be done by the user. Besides, many problems do not have (provable) small coresets, limiting their applicability. To this end, we suggest an automatic practical framework for constructing coresets, which requires (only) the input data and the desired cost function from the user, without the need for any other task-related computation to be done by the user. To do so, we reduce the problem of approximating a loss function to an instance of vector summation approximation, where the vectors we aim to sum are loss vectors of a specific subset of the queries, such that we aim to approximate the image of the function on this subset. We show that while this set is limited, the coreset is quite general. An extensive experimental study on various machine learning applications is also conducted. Finally, we provide a ``plug and play" style implementation, proposing a user-friendly system that can be easily used to apply coresets for many problems. Full open source code can be found at \href{https://github.com/alaamaalouf/AutoCoreset}{\text{https://github.com/alaamaalouf/AutoCoreset}}. We believe that these contributions enable future research and easier use and applications of coresets.
Surgical-VQLA: Transformer with Gated Vision-Language Embedding for Visual Question Localized-Answering in Robotic Surgery
May 19, 2023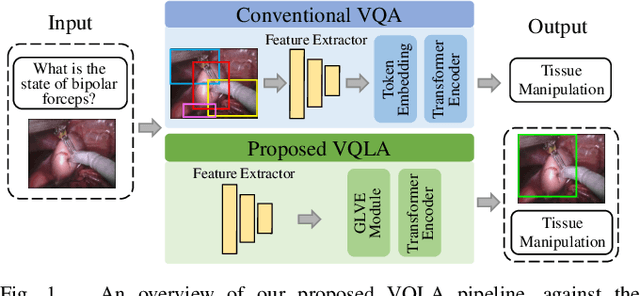
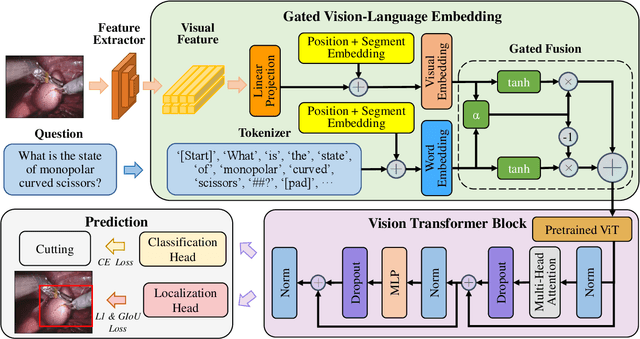
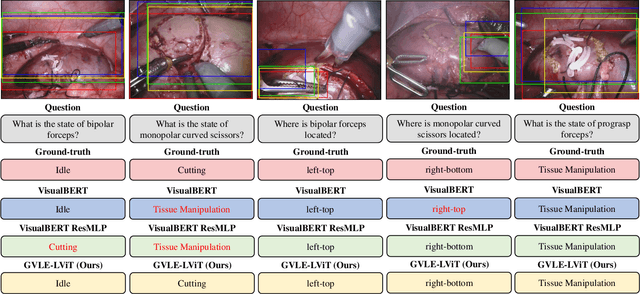
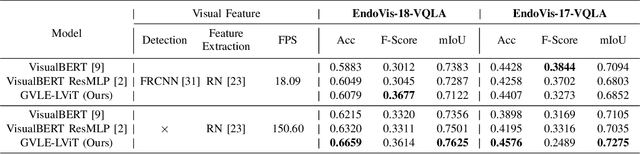
Despite the availability of computer-aided simulators and recorded videos of surgical procedures, junior residents still heavily rely on experts to answer their queries. However, expert surgeons are often overloaded with clinical and academic workloads and limit their time in answering. For this purpose, we develop a surgical question-answering system to facilitate robot-assisted surgical scene and activity understanding from recorded videos. Most of the existing VQA methods require an object detector and regions based feature extractor to extract visual features and fuse them with the embedded text of the question for answer generation. However, (1) surgical object detection model is scarce due to smaller datasets and lack of bounding box annotation; (2) current fusion strategy of heterogeneous modalities like text and image is naive; (3) the localized answering is missing, which is crucial in complex surgical scenarios. In this paper, we propose Visual Question Localized-Answering in Robotic Surgery (Surgical-VQLA) to localize the specific surgical area during the answer prediction. To deal with the fusion of the heterogeneous modalities, we design gated vision-language embedding (GVLE) to build input patches for the Language Vision Transformer (LViT) to predict the answer. To get localization, we add the detection head in parallel with the prediction head of the LViT. We also integrate GIoU loss to boost localization performance by preserving the accuracy of the question-answering model. We annotate two datasets of VQLA by utilizing publicly available surgical videos from MICCAI challenges EndoVis-17 and 18. Our validation results suggest that Surgical-VQLA can better understand the surgical scene and localize the specific area related to the question-answering. GVLE presents an efficient language-vision embedding technique by showing superior performance over the existing benchmarks.
PTQD: Accurate Post-Training Quantization for Diffusion Models
May 18, 2023
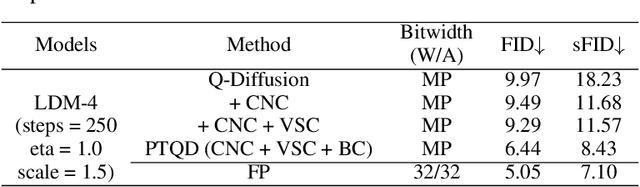
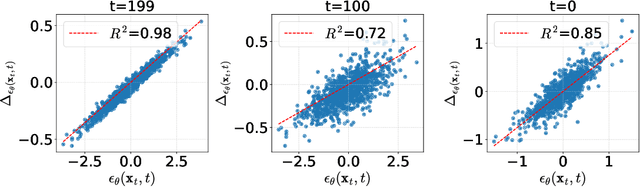
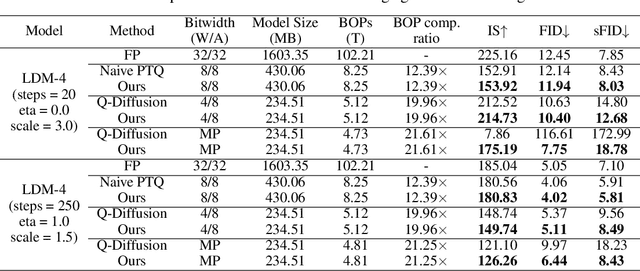
Diffusion models have recently dominated image synthesis and other related generative tasks. However, the iterative denoising process is expensive in computations at inference time, making diffusion models less practical for low-latency and scalable real-world applications. Post-training quantization of diffusion models can significantly reduce the model size and accelerate the sampling process without requiring any re-training. Nonetheless, applying existing post-training quantization methods directly to low-bit diffusion models can significantly impair the quality of generated samples. Specifically, for each denoising step, quantization noise leads to deviations in the estimated mean and mismatches with the predetermined variance schedule. Moreover, as the sampling process proceeds, the quantization noise may accumulate, resulting in a low signal-to-noise ratio (SNR) in late denoising steps. To address these challenges, we propose a unified formulation for the quantization noise and diffusion perturbed noise in the quantized denoising process. We first disentangle the quantization noise into its correlated and residual uncorrelated parts regarding its full-precision counterpart. The correlated part can be easily corrected by estimating the correlation coefficient. For the uncorrelated part, we calibrate the denoising variance schedule to absorb the excess variance resulting from quantization. Moreover, we propose a mixed-precision scheme to choose the optimal bitwidth for each denoising step, which prefers low bits to accelerate the early denoising steps while high bits maintain the high SNR for the late steps. Extensive experiments demonstrate that our method outperforms previous post-training quantized diffusion models in generating high-quality samples, with only a 0.06 increase in FID score compared to full-precision LDM-4 on ImageNet 256x256, while saving 19.9x bit operations.
Counterfactuals for Design: A Model-Agnostic Method For Design Recommendations
May 18, 2023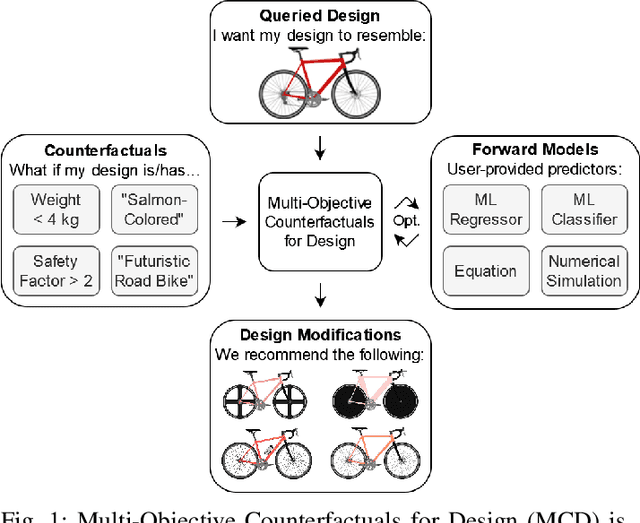
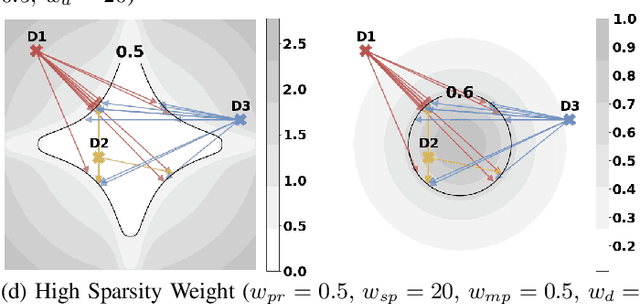
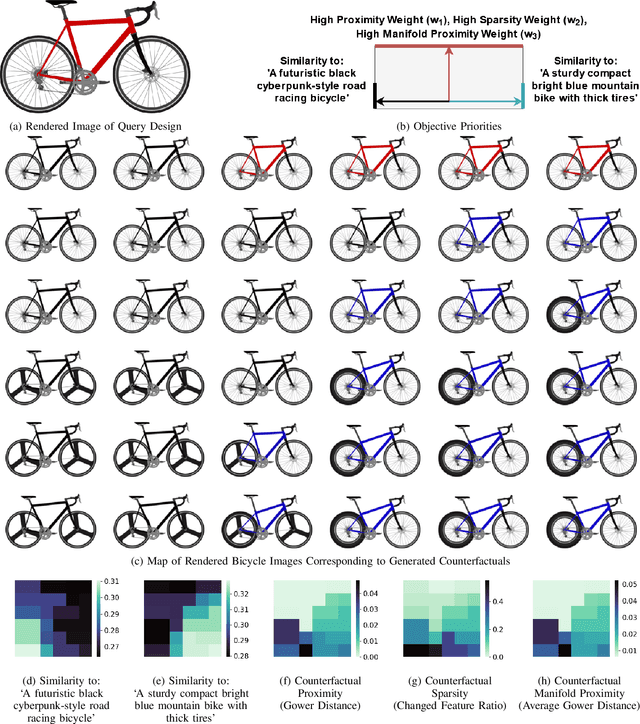
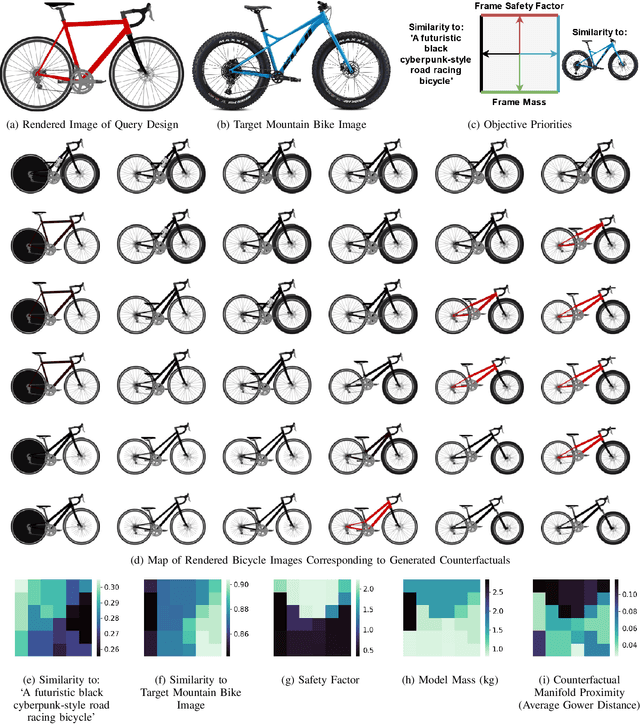
We introduce Multi-Objective Counterfactuals for Design (MCD), a novel method for counterfactual optimization in design problems. Counterfactuals are hypothetical situations that can lead to a different decision or choice. In this paper, the authors frame the counterfactual search problem as a design recommendation tool that can help identify modifications to a design, leading to better functional performance. MCD improves upon existing counterfactual search methods by supporting multi-objective queries, which are crucial in design problems, and by decoupling the counterfactual search and sampling processes, thus enhancing efficiency and facilitating objective tradeoff visualization. The paper demonstrates MCD's core functionality using a two-dimensional test case, followed by three case studies of bicycle design that showcase MCD's effectiveness in real-world design problems. In the first case study, MCD excels at recommending modifications to query designs that can significantly enhance functional performance, such as weight savings and improvements to the structural safety factor. The second case study demonstrates that MCD can work with a pre-trained language model to suggest design changes based on a subjective text prompt effectively. Lastly, the authors task MCD with increasing a query design's similarity to a target image and text prompt while simultaneously reducing weight and improving structural performance, demonstrating MCD's performance on a complex multimodal query. Overall, MCD has the potential to provide valuable recommendations for practitioners and design automation researchers looking for answers to their ``What if'' questions by exploring hypothetical design modifications and their impact on multiple design objectives. The code, test problems, and datasets used in the paper are available to the public at decode.mit.edu/projects/counterfactuals/.
Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
Apr 17, 2023
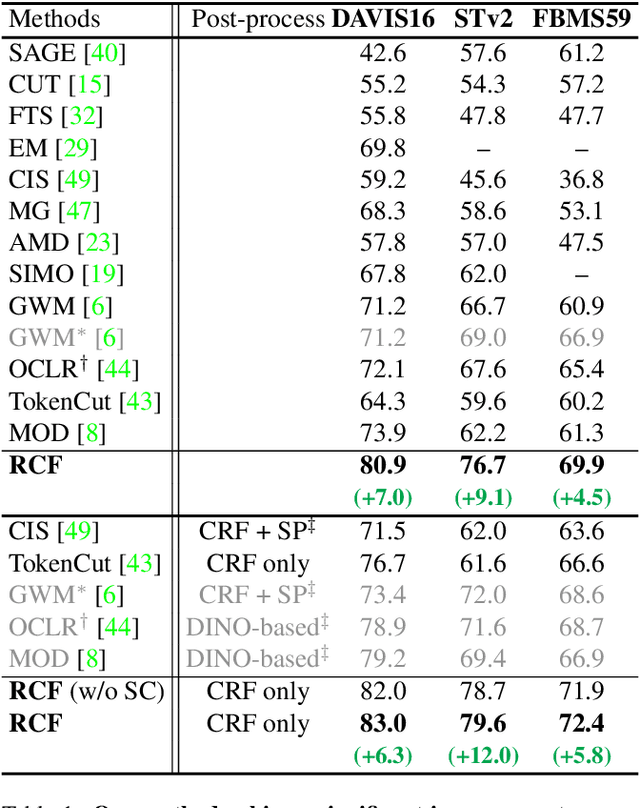

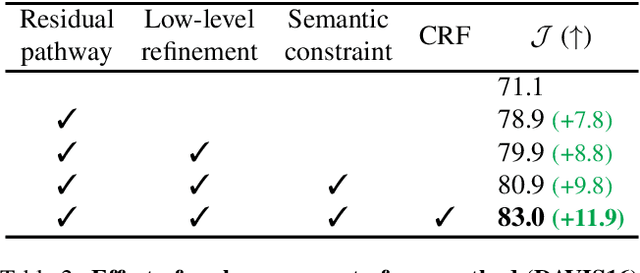
We study learning object segmentation from unlabeled videos. Humans can easily segment moving objects without knowing what they are. The Gestalt law of common fate, i.e., what move at the same speed belong together, has inspired unsupervised object discovery based on motion segmentation. However, common fate is not a reliable indicator of objectness: Parts of an articulated / deformable object may not move at the same speed, whereas shadows / reflections of an object always move with it but are not part of it. Our insight is to bootstrap objectness by first learning image features from relaxed common fate and then refining them based on visual appearance grouping within the image itself and across images statistically. Specifically, we learn an image segmenter first in the loop of approximating optical flow with constant segment flow plus small within-segment residual flow, and then by refining it for more coherent appearance and statistical figure-ground relevance. On unsupervised video object segmentation, using only ResNet and convolutional heads, our model surpasses the state-of-the-art by absolute gains of 7/9/5% on DAVIS16 / STv2 / FBMS59 respectively, demonstrating the effectiveness of our ideas. Our code is publicly available.
Invariant Scattering Transform for Medical Imaging
Apr 20, 2023
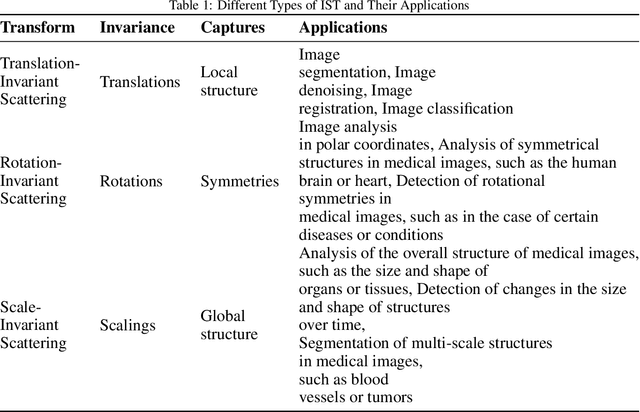
Over the years, the Invariant Scattering Transform (IST) technique has become popular for medical image analysis, including using wavelet transform computation using Convolutional Neural Networks (CNN) to capture patterns' scale and orientation in the input signal. IST aims to be invariant to transformations that are common in medical images, such as translation, rotation, scaling, and deformation, used to improve the performance in medical imaging applications such as segmentation, classification, and registration, which can be integrated into machine learning algorithms for disease detection, diagnosis, and treatment planning. Additionally, combining IST with deep learning approaches has the potential to leverage their strengths and enhance medical image analysis outcomes. This study provides an overview of IST in medical imaging by considering the types of IST, their application, limitations, and potential scopes for future researchers and practitioners.
Forged Image Detection using SOTA Image Classification Deep Learning Methods for Image Forensics with Error Level Analysis
Nov 28, 2022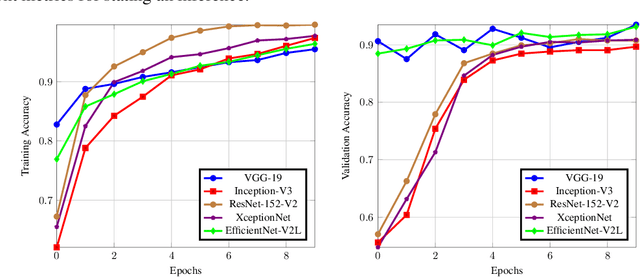
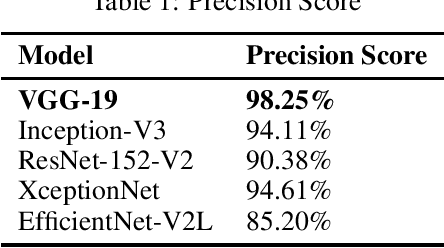
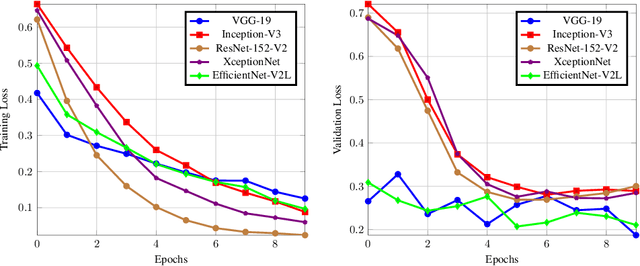
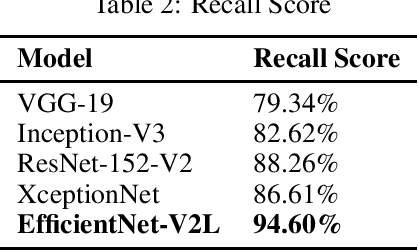
The advancement in the area of computer vision has been brought using deep learning mechanisms. Image Forensics is one of the major areas of computer vision application. Forgery of images is sub-category of image forensics and can be detected using Error Level Analysis. Using such images as an input, this can turn out to be a binary classification problem which can be leveraged using variations of convolutional neural networks. In this paper we perform transfer learning with state-of-the-art image classification models over error level analysis induced CASIA ITDE v.2 dataset. The algorithms used are VGG-19, Inception-V3, ResNet-152-V2, XceptionNet and EfficientNet-V2L with their respective methodologies and results.