 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Generalized Framework for Critical Heat Flux Detection Using Unsupervised Image-to-Image Translation
Dec 18, 2022
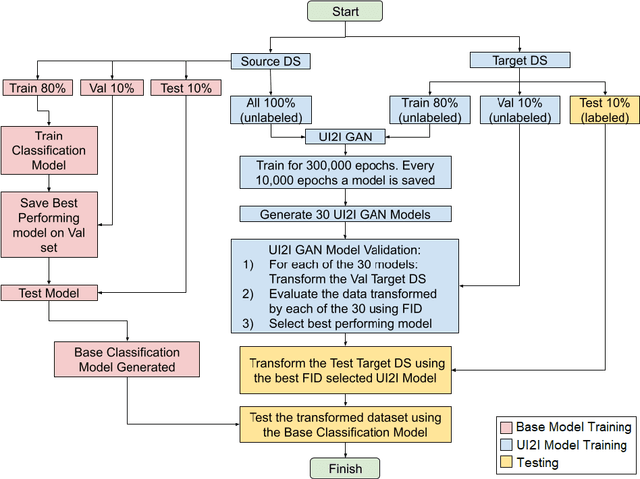
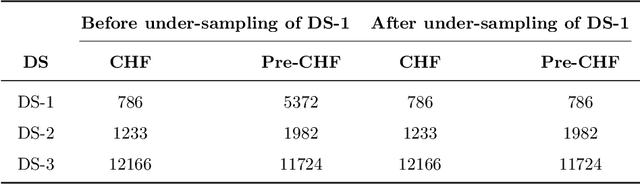
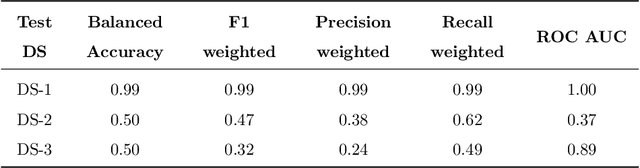

This work proposes a framework developed to generalize Critical Heat Flux (CHF) detection classification models using an Unsupervised Image-to-Image (UI2I) translation model. The framework enables a typical classification model that was trained and tested on boiling images from domain A to predict boiling images coming from domain B that was never seen by the classification model. This is done by using the UI2I model to transform the domain B images to look like domain A images that the classification model is familiar with. Although CNN was used as the classification model and Fixed-Point GAN (FP-GAN) was used as the UI2I model, the framework is model agnostic. Meaning, that the framework can generalize any image classification model type, making it applicable to a variety of similar applications and not limited to the boiling crisis detection problem. It also means that the more the UI2I models advance, the better the performance of the framework.
A Chain Rule for the Expected Suprema of Bernoulli Processes
Apr 27, 2023We obtain an upper bound on the expected supremum of a Bernoulli process indexed by the image of an index set under a uniformly Lipschitz function class in terms of properties of the index set and the function class, extending an earlier result of Maurer for Gaussian processes. The proof makes essential use of recent results of Bednorz and Latala on the boundedness of Bernoulli processes.
STEPS: Joint Self-supervised Nighttime Image Enhancement and Depth Estimation
Feb 02, 2023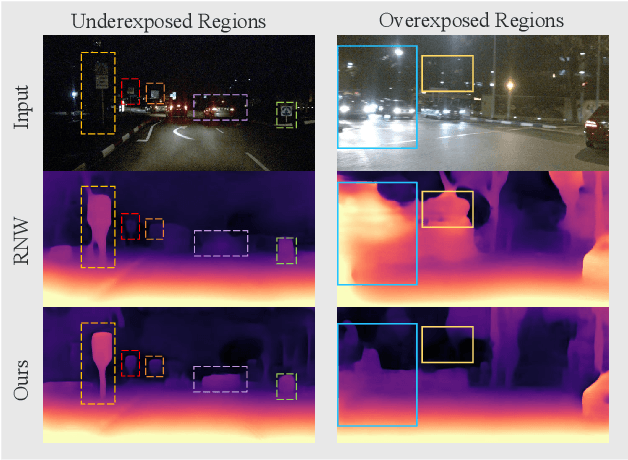
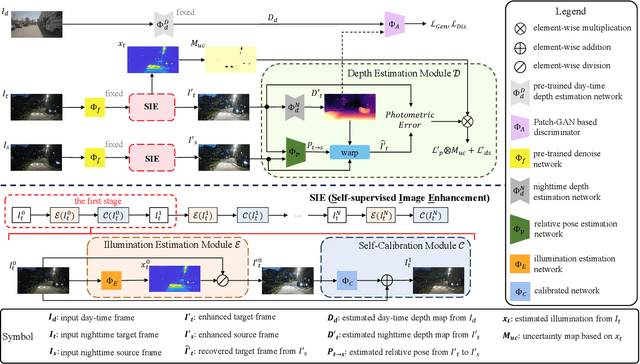

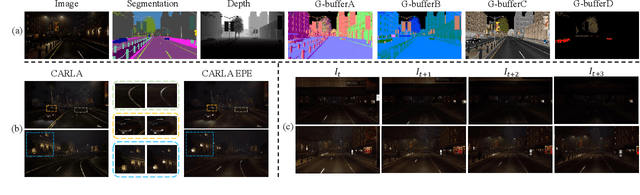
Self-supervised depth estimation draws a lot of attention recently as it can promote the 3D sensing capabilities of self-driving vehicles. However, it intrinsically relies upon the photometric consistency assumption, which hardly holds during nighttime. Although various supervised nighttime image enhancement methods have been proposed, their generalization performance in challenging driving scenarios is not satisfactory. To this end, we propose the first method that jointly learns a nighttime image enhancer and a depth estimator, without using ground truth for either task. Our method tightly entangles two self-supervised tasks using a newly proposed uncertain pixel masking strategy. This strategy originates from the observation that nighttime images not only suffer from underexposed regions but also from overexposed regions. By fitting a bridge-shaped curve to the illumination map distribution, both regions are suppressed and two tasks are bridged naturally. We benchmark the method on two established datasets: nuScenes and RobotCar and demonstrate state-of-the-art performance on both of them. Detailed ablations also reveal the mechanism of our proposal. Last but not least, to mitigate the problem of sparse ground truth of existing datasets, we provide a new photo-realistically enhanced nighttime dataset based upon CARLA. It brings meaningful new challenges to the community. Codes, data, and models are available at https://github.com/ucaszyp/STEPS.
Target-Free Text-guided Image Manipulation
Dec 01, 2022
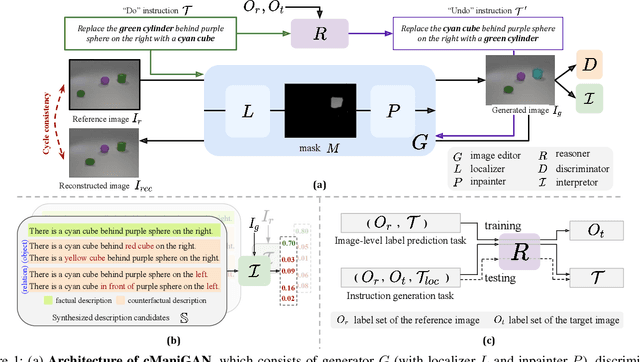

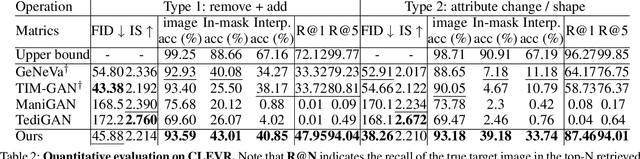
We tackle the problem of target-free text-guided image manipulation, which requires one to modify the input reference image based on the given text instruction, while no ground truth target image is observed during training. To address this challenging task, we propose a Cyclic-Manipulation GAN (cManiGAN) in this paper, which is able to realize where and how to edit the image regions of interest. Specifically, the image editor in cManiGAN learns to identify and complete the input image, while cross-modal interpreter and reasoner are deployed to verify the semantic correctness of the output image based on the input instruction. While the former utilizes factual/counterfactual description learning for authenticating the image semantics, the latter predicts the "undo" instruction and provides pixel-level supervision for the training of cManiGAN. With such operational cycle-consistency, our cManiGAN can be trained in the above weakly supervised setting. We conduct extensive experiments on the datasets of CLEVR and COCO, and the effectiveness and generalizability of our proposed method can be successfully verified. Project page: https://sites.google.com/view/wancyuanfan/projects/cmanigan.
Improving Performance of Private Federated Models in Medical Image Analysis
Apr 11, 2023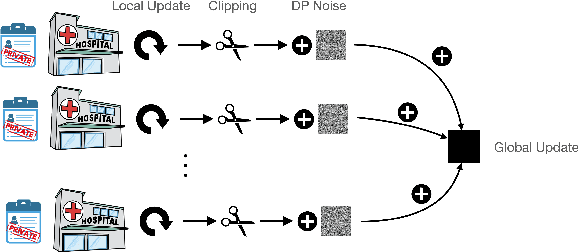

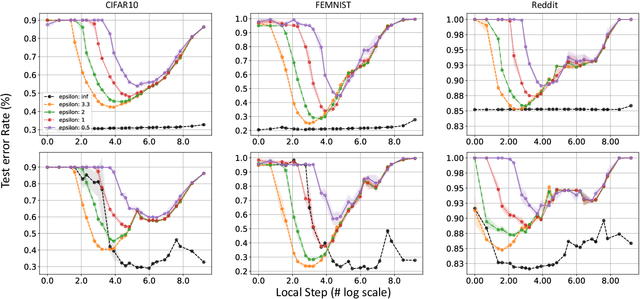
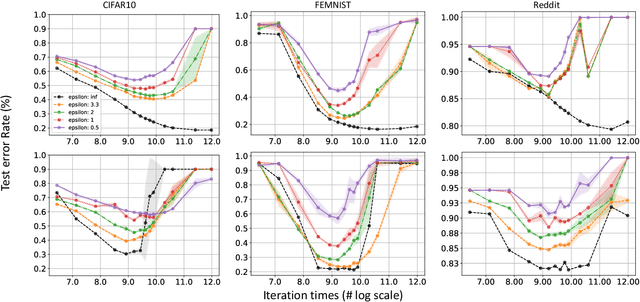
Federated learning (FL) is a distributed machine learning (ML) approach that allows data to be trained without being centralized. This approach is particularly beneficial for medical applications because it addresses some key challenges associated with medical data, such as privacy, security, and data ownership. On top of that, FL can improve the quality of ML models used in medical applications. Medical data is often diverse and can vary significantly depending on the patient population, making it challenging to develop ML models that are accurate and generalizable. FL allows medical data to be used from multiple sources, which can help to improve the quality and generalizability of ML models. Differential privacy (DP) is a go-to algorithmic tool to make this process secure and private. In this work, we show that the model performance can be further improved by employing local steps, a popular approach to improving the communication efficiency of FL, and tuning the number of communication rounds. Concretely, given the privacy budget, we show an optimal number of local steps and communications rounds. We provide theoretical motivations further corroborated with experimental evaluations on real-world medical imaging tasks.
Flickr-PAD: New Face High-Resolution Presentation Attack Detection Database
Apr 25, 2023
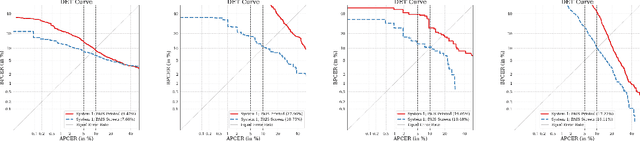
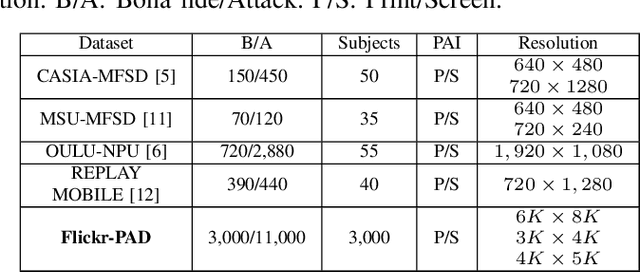
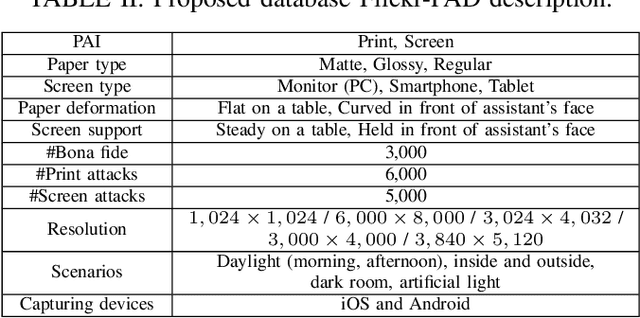
Nowadays, Presentation Attack Detection is a very active research area. Several databases are constituted in the state-of-the-art using images extracted from videos. One of the main problems identified is that many databases present a low-quality, small image size and do not represent an operational scenario in a real remote biometric system. Currently, these images are captured from smartphones with high-quality and bigger resolutions. In order to increase the diversity of image quality, this work presents a new PAD database based on open-access Flickr images called: "Flickr-PAD". Our new hand-made database shows high-quality printed and screen scenarios. This will help researchers to compare new approaches to existing algorithms on a wider database. This database will be available for other researchers. A leave-one-out protocol was used to train and evaluate three PAD models based on MobileNet-V3 (small and large) and EfficientNet-B0. The best result was reached with MobileNet-V3 large with BPCER10 of 7.08% and BPCER20 of 11.15%.
Unified Noise-aware Network for Low-count PET Denoising
Apr 28, 2023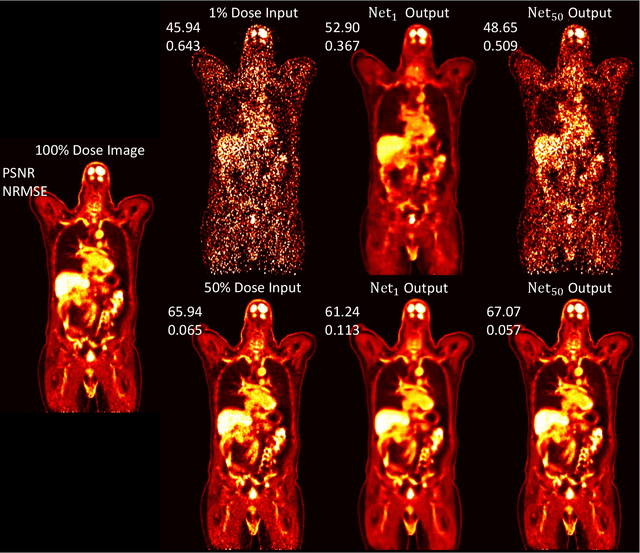
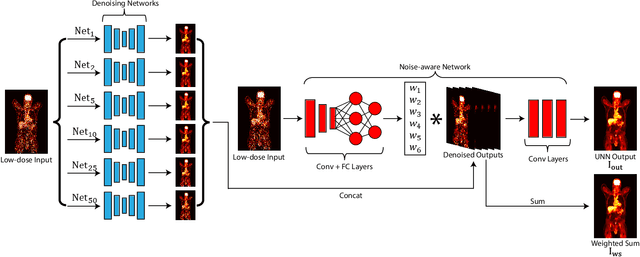
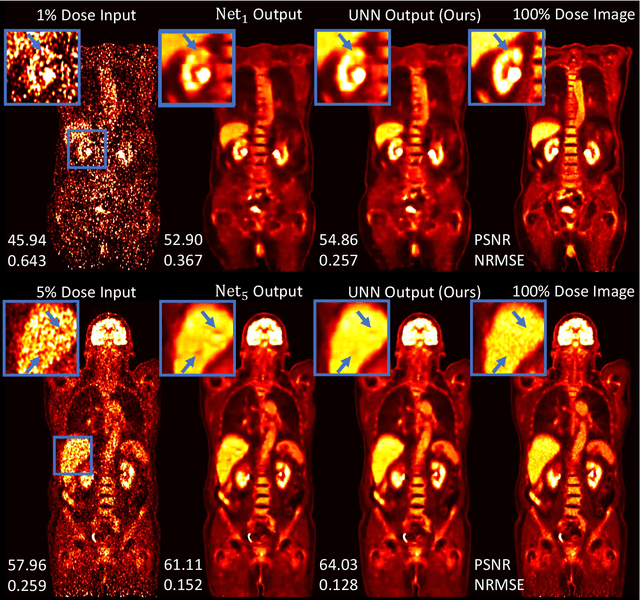
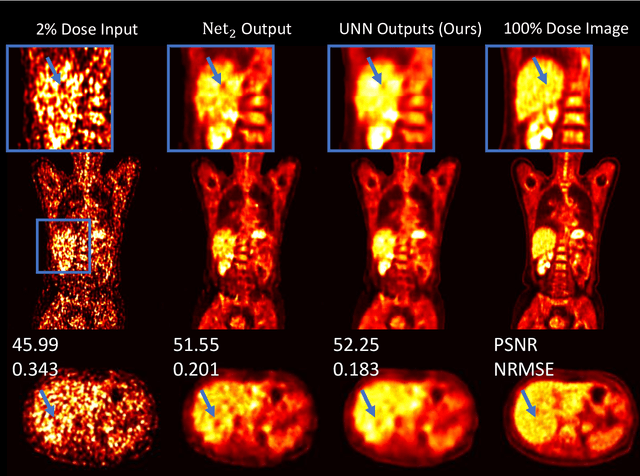
As PET imaging is accompanied by substantial radiation exposure and cancer risk, reducing radiation dose in PET scans is an important topic. However, low-count PET scans often suffer from high image noise, which can negatively impact image quality and diagnostic performance. Recent advances in deep learning have shown great potential for recovering underlying signal from noisy counterparts. However, neural networks trained on a specific noise level cannot be easily generalized to other noise levels due to different noise amplitude and variances. To obtain optimal denoised results, we may need to train multiple networks using data with different noise levels. But this approach may be infeasible in reality due to limited data availability. Denoising dynamic PET images presents additional challenge due to tracer decay and continuously changing noise levels across dynamic frames. To address these issues, we propose a Unified Noise-aware Network (UNN) that combines multiple sub-networks with varying denoising power to generate optimal denoised results regardless of the input noise levels. Evaluated using large-scale data from two medical centers with different vendors, presented results showed that the UNN can consistently produce promising denoised results regardless of input noise levels, and demonstrate superior performance over networks trained on single noise level data, especially for extremely low-count data.
Gradient Domain Weighted Guided Image Filtering
Nov 30, 2022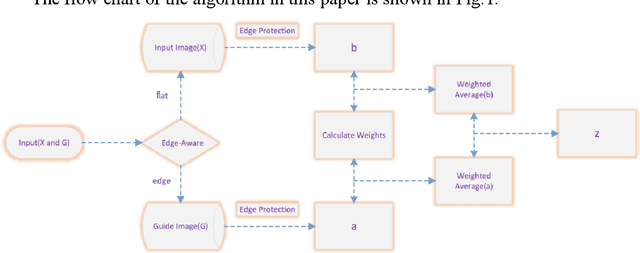
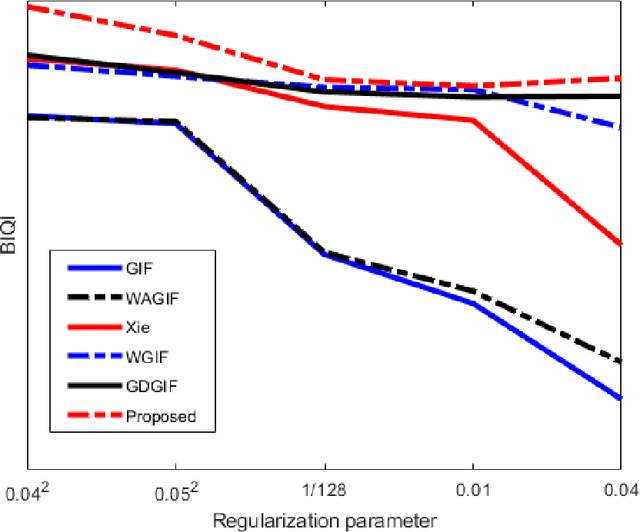


As an excellent local filter, guided image filters are subject to halo artifacts. In this paper, the algorithm uses gradient information to accurately determine the edge of the image, and uses the weighted information to further accurately distinguish the flat area and edge area of the image. As a result, the edges of the image are sharper and the level of blur in flat areas is reduced, avoiding halo artifacts caused by excessive blurring near edges. Experiments show that the proposed algorithm can better suppress halo artifacts at the edges. The proposed algorithm has good performance in both image denoising and image detail enhancement.
Image To Tree with Recursive Prompting
Jan 01, 2023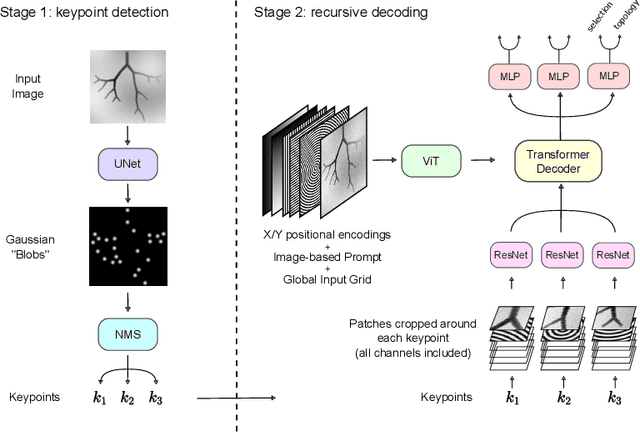
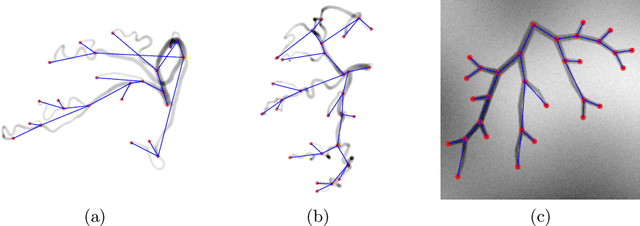

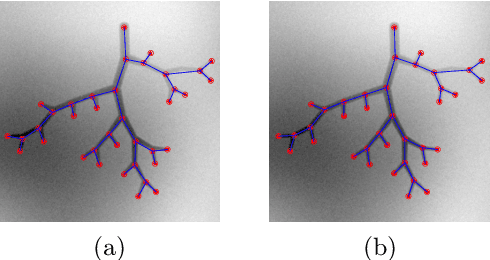
Extracting complex structures from grid-based data is a common key step in automated medical image analysis. The conventional solution to recovering tree-structured geometries typically involves computing the minimal cost path through intermediate representations derived from segmentation masks. However, this methodology has significant limitations in the context of projective imaging of tree-structured 3D anatomical data such as coronary arteries, since there are often overlapping branches in the 2D projection. In this work, we propose a novel approach to predicting tree connectivity structure which reformulates the task as an optimization problem over individual steps of a recursive process. We design and train a two-stage model which leverages the UNet and Transformer architectures and introduces an image-based prompting technique. Our proposed method achieves compelling results on a pair of synthetic datasets, and outperforms a shortest-path baseline.
Guiding Text-to-Image Diffusion Model Towards Grounded Generation
Jan 12, 2023The goal of this paper is to augment a pre-trained text-to-image diffusion model with the ability of open-vocabulary objects grounding, i.e., simultaneously generating images and segmentation masks for the corresponding visual entities described in the text prompt. We make the following contributions: (i) we insert a grounding module into the existing diffusion model, that can be trained to align the visual and textual embedding space of the diffusion model with only a small number of object categories; (ii) we propose an automatic pipeline for constructing a dataset, that consists of {image, segmentation mask, text prompt} triplets, to train the proposed grounding module; (iii) we evaluate the performance of open-vocabulary grounding on images generated from the text-to-image diffusion model and show that the module can well segment the objects of categories beyond seen ones at training time; (iv) we adopt the guided diffusion model to build a synthetic semantic segmentation dataset, and show that training a standard segmentation model on such dataset demonstrates competitive performance on zero-shot segmentation(ZS3) benchmark, which opens up new opportunities for adopting the powerful diffusion model for discriminative tasks.