 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SENDD: Sparse Efficient Neural Depth and Deformation for Tissue Tracking
May 10, 2023
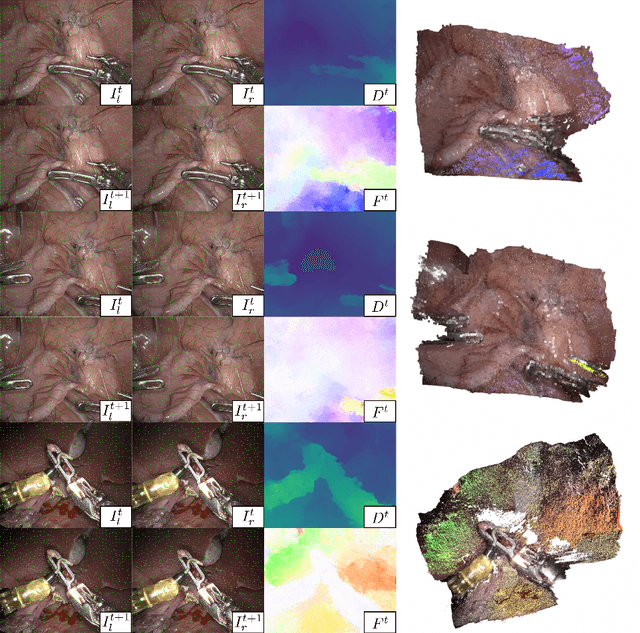
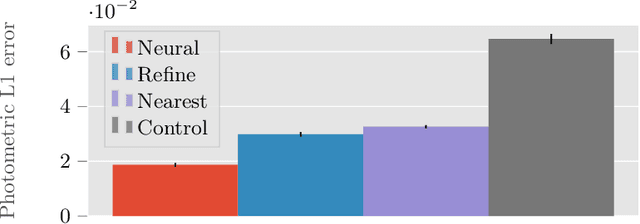
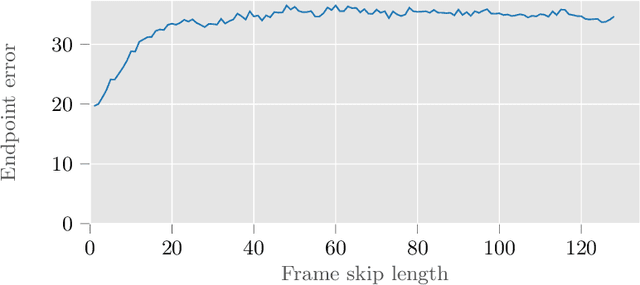
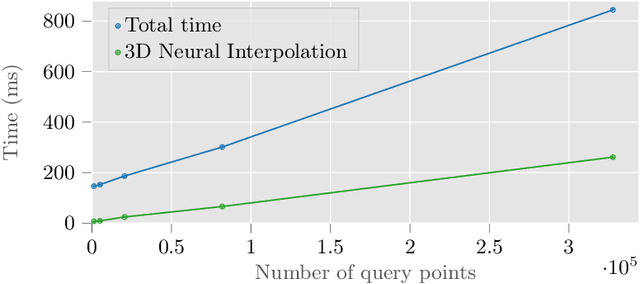
Deformable tracking and real-time estimation of 3D tissue motion is essential to enable automation and image guidance applications in robotically assisted surgery. Our model, Sparse Efficient Neural Depth and Deformation (SENDD), extends prior 2D tracking work to estimate flow in 3D space. SENDD introduces novel contributions of learned detection, and sparse per-point depth and 3D flow estimation, all with less than half a million parameters. SENDD does this by using graph neural networks of sparse keypoint matches to estimate both depth and 3D flow. We quantify and benchmark SENDD on a comprehensively labelled tissue dataset, and compare it to an equivalent 2D flow model. SENDD performs comparably while enabling applications that 2D flow cannot. SENDD can track points and estimate depth at 10fps on an NVIDIA RTX 4000 for 1280 tracked (query) points and its cost scales linearly with an increasing/decreasing number of points. SENDD enables multiple downstream applications that require 3D motion estimation.
Level-line Guided Edge Drawing for Robust Line Segment Detection
May 10, 2023
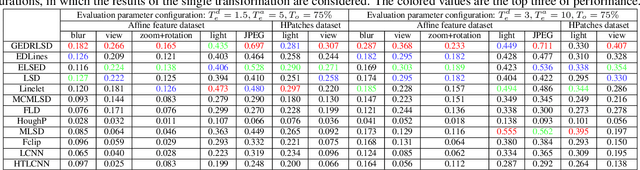
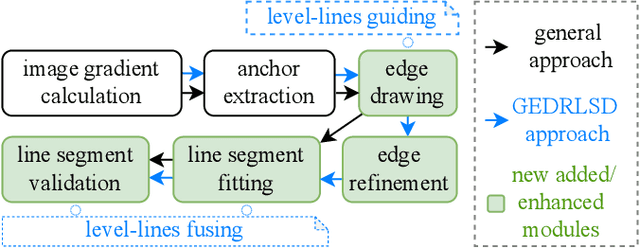

Line segment detection plays a cornerstone role in computer vision tasks. Among numerous detection methods that have been recently proposed, the ones based on edge drawing attract increasing attention owing to their excellent detection efficiency. However, the existing methods are not robust enough due to the inadequate usage of image gradients for edge drawing and line segment fitting. Based on the observation that the line segments should locate on the edge points with both consistent coordinates and level-line information, i.e., the unit vector perpendicular to the gradient orientation, this paper proposes a level-line guided edge drawing for robust line segment detection (GEDRLSD). The level-line information provides potential directions for edge tracking, which could be served as a guideline for accurate edge drawing. Additionally, the level-line information is fused in line segment fitting to improve the robustness. Numerical experiments show the superiority of the proposed GEDRLSD algorithm compared with state-of-the-art methods.
* Accepted by ICASSP 2023
Deep sound-field denoiser: optically-measured sound-field denoising using deep neural network
Apr 27, 2023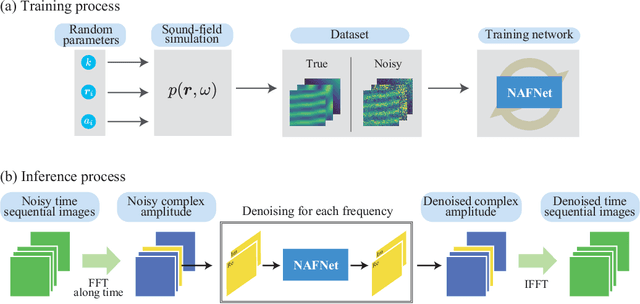
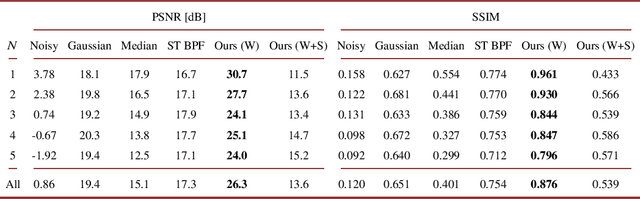

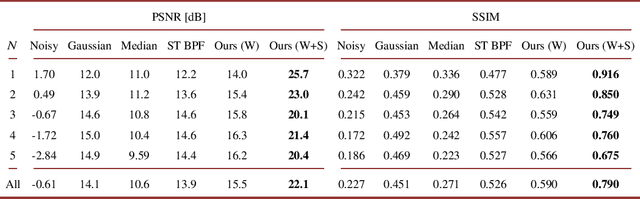
This paper proposes a deep sound-field denoiser, a deep neural network (DNN) based denoising of optically measured sound-field images. Sound-field imaging using optical methods has gained considerable attention due to its ability to achieve high-spatial-resolution imaging of acoustic phenomena that conventional acoustic sensors cannot accomplish. However, the optically measured sound-field images are often heavily contaminated by noise because of the low sensitivity of optical interferometric measurements to airborne sound. Here, we propose a DNN-based sound-field denoising method. Time-varying sound-field image sequences are decomposed into harmonic complex-amplitude images by using a time-directional Fourier transform. The complex images are converted into two-channel images consisting of real and imaginary parts and denoised by a nonlinear-activation-free network. The network is trained on a sound-field dataset obtained from numerical acoustic simulations with randomized parameters. We compared the method with conventional ones, such as image filters and a spatiotemporal filter, on numerical and experimental data. The experimental data were measured by parallel phase-shifting interferometry and holographic speckle interferometry. The proposed deep sound-field denoiser significantly outperformed the conventional methods on both the numerical and experimental data.
Dual flow fusion model for concrete surface crack segmentation
May 16, 2023
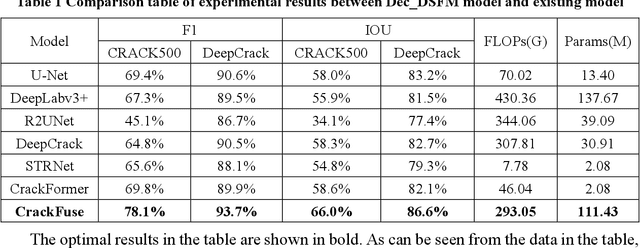
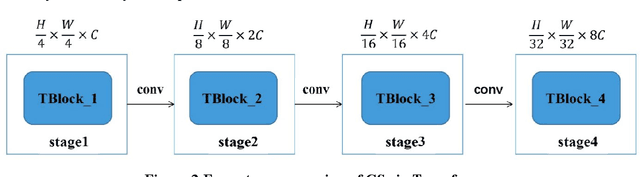
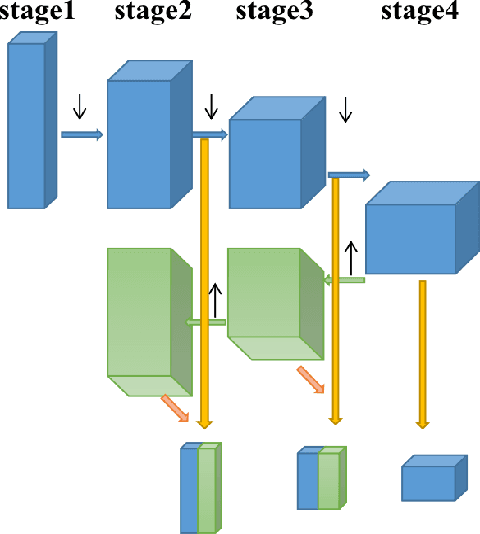
The existence of cracks and other damages pose a significant threat to the safe operation of transportation infrastructure. Traditional manual detection and ultrasound equipment testing consume a lot of time and resources. With the development of deep learning technology, many deep learning models have been widely applied to practical visual segmentation tasks. The detection method based on deep learning models has the advantages of high detection accuracy, fast detection speed, and simple operation. However, deep learning-based crack segmentation models are sensitive to background noise, have rough edges, and lack robustness. Therefore, this paper proposes a crack segmentation model based on the fusion of dual streams. The image is inputted simultaneously into two designed processing streams to independently extract long-distance dependence and local detail features. The adaptive prediction is achieved through the dual-headed mechanism. Meanwhile, a novel interaction fusion mechanism is proposed to guide the complementary of different feature layers to achieve crack location and recognition in complex backgrounds. Finally, an edge optimization method is proposed to improve the accuracy of segmentation. Experiments show that the F1 value of segmentation results on the DeepCrack[1] public dataset is 93.7% and the IOU value is 86.6%. The F1 value of segmentation results on the CRACK500[2] dataset is 78.1%, and the IOU value is 66.0%.
Osteosarcoma Tumor Detection using Transfer Learning Models
May 16, 2023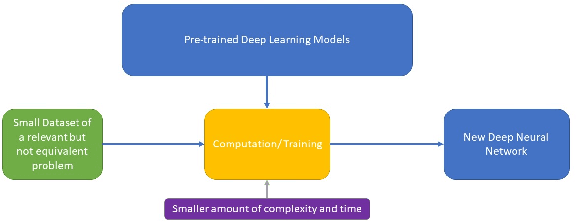

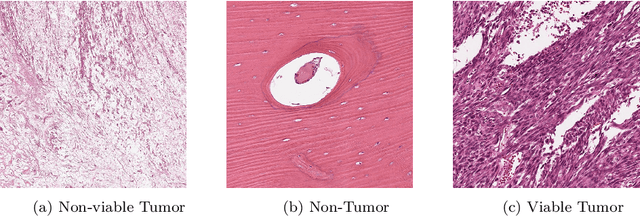
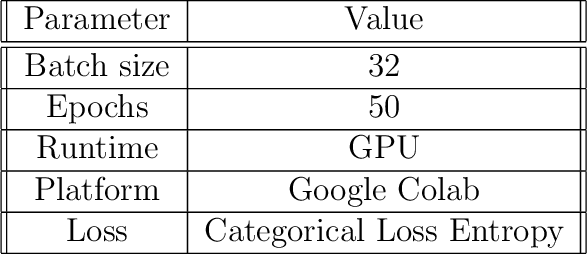
The field of clinical image analysis has been applying transfer learning models increasingly due to their less computational complexity, better accuracy etc. These are pre-trained models that don't require to be trained from scratch which eliminates the necessity of large datasets. Transfer learning models are mostly used for the analysis of brain, breast, or lung images but other sectors such as bone marrow cell detection or bone cancer detection can also benefit from using transfer learning models, especially considering the lack of available large datasets for these tasks. This paper studies the performance of several transfer learning models for osteosarcoma tumour detection. Osteosarcoma is a type of bone cancer mostly found in the cells of the long bones of the body. The dataset consists of H&E stained images divided into 4 categories- Viable Tumor, Non-viable Tumor, Non-Tumor and Viable Non-viable. Both datasets were randomly divided into train and test sets following an 80-20 ratio. 80% was used for training and 20\% for test. 4 models are considered for comparison- EfficientNetB7, InceptionResNetV2, NasNetLarge and ResNet50. All these models are pre-trained on ImageNet. According to the result, InceptionResNetV2 achieved the highest accuracy (93.29%), followed by NasNetLarge (90.91%), ResNet50 (89.83%) and EfficientNetB7 (62.77%). It also had the highest precision (0.8658) and recall (0.8658) values among the 4 models.
Aesthetically Relevant Image Captioning
Nov 25, 2022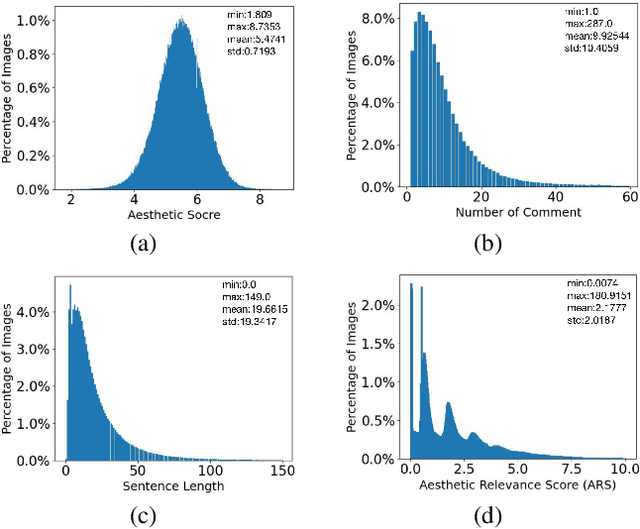

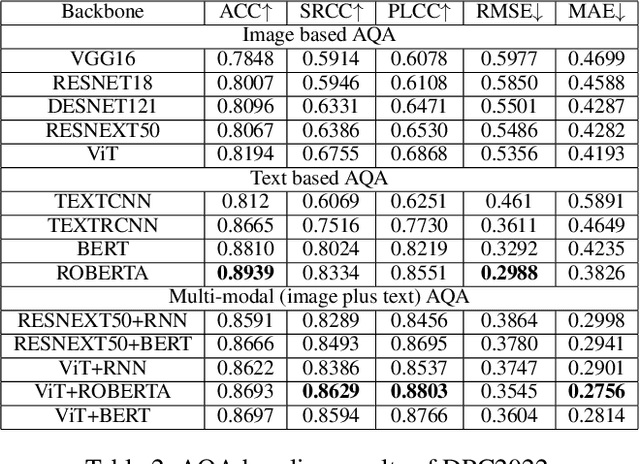
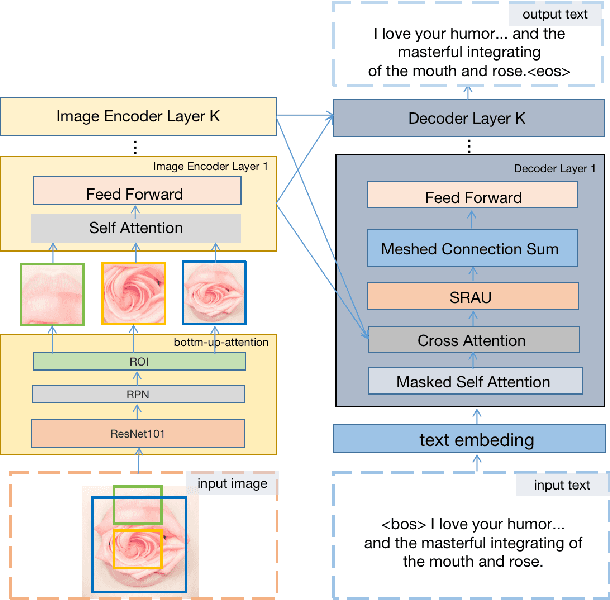
Image aesthetic quality assessment (AQA) aims to assign numerical aesthetic ratings to images whilst image aesthetic captioning (IAC) aims to generate textual descriptions of the aesthetic aspects of images. In this paper, we study image AQA and IAC together and present a new IAC method termed Aesthetically Relevant Image Captioning (ARIC). Based on the observation that most textual comments of an image are about objects and their interactions rather than aspects of aesthetics, we first introduce the concept of Aesthetic Relevance Score (ARS) of a sentence and have developed a model to automatically label a sentence with its ARS. We then use the ARS to design the ARIC model which includes an ARS weighted IAC loss function and an ARS based diverse aesthetic caption selector (DACS). We present extensive experimental results to show the soundness of the ARS concept and the effectiveness of the ARIC model by demonstrating that texts with higher ARS's can predict the aesthetic ratings more accurately and that the new ARIC model can generate more accurate, aesthetically more relevant and more diverse image captions. Furthermore, a large new research database containing 510K images with over 5 million comments and 350K aesthetic scores, and code for implementing ARIC are available at https://github.com/PengZai/ARIC.
Self-supervised Learning for Gastrointestinal Pathologies Endoscopy Image Classification with Triplet Loss
Mar 03, 2023



Recently, the amount of GI tract datasets is introduced more and more by gathering from contests and challenges. The most common task needs to solve that is to classify images from the GI tract into various classes. However, the contributions of the existing approaches exhibit lots of limitations. In this paper, we aim to develop a computer-aided diagnosis system to classify the pathological findings in endoscopy images, the system can classify some common pathologies including polyps, esophagitis, and ulcerative -- colitis. To evaluate the proposed work, we use the public dataset which is Hyper--Kvasir instead of gathering the data. The key idea of our system is to develop self-supervised learning based on the Barlow Twins framework with a downstream task which is an endoscopy image classification integrated with triplet loss and focal loss functions. The self-supervision framework and focal loss function are used to overcome class-imbalanced data, while the triplet loss function is to tackle the domain-specific properties in endoscopy images which are inter/intra class problems. An extensive experimental study on the pathological finding images in the Hyper--Kvasir dataset has shown that our proposed system is in general better than the compared methods, whereas using a simple neural network model. This means the proposed system can be used efficiently and capable of accurately for the classification of pathology images in the GI tract.
A Chain Rule for the Expected Suprema of Bernoulli Processes
Apr 27, 2023We obtain an upper bound on the expected supremum of a Bernoulli process indexed by the image of an index set under a uniformly Lipschitz function class in terms of properties of the index set and the function class, extending an earlier result of Maurer for Gaussian processes. The proof makes essential use of recent results of Bednorz and Latala on the boundedness of Bernoulli processes.
Fully 3D Implementation of the End-to-end Deep Image Prior-based PET Image Reconstruction Using Block Iterative Algorithm
Dec 22, 2022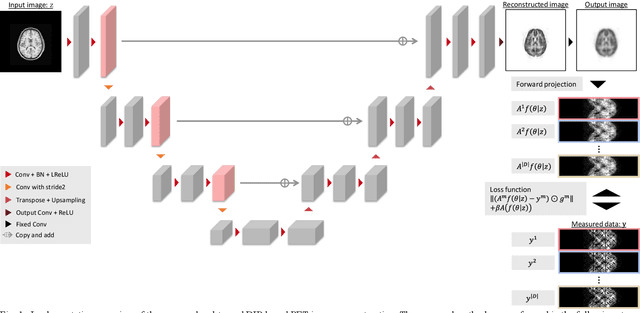
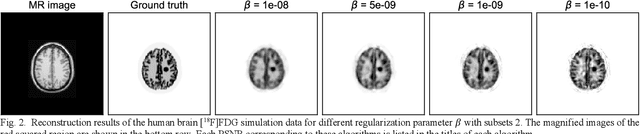
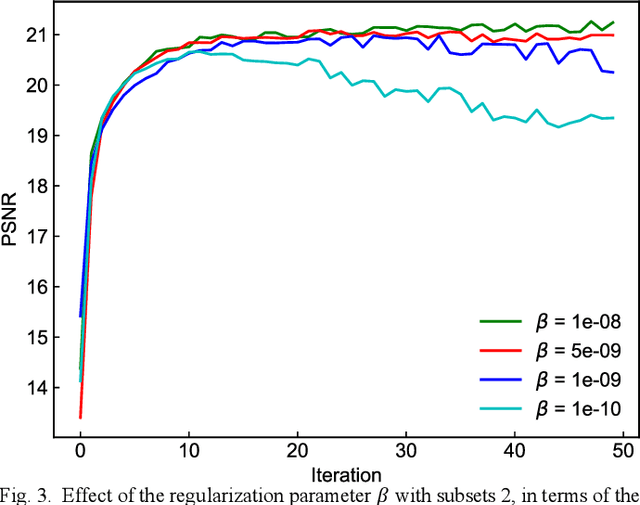
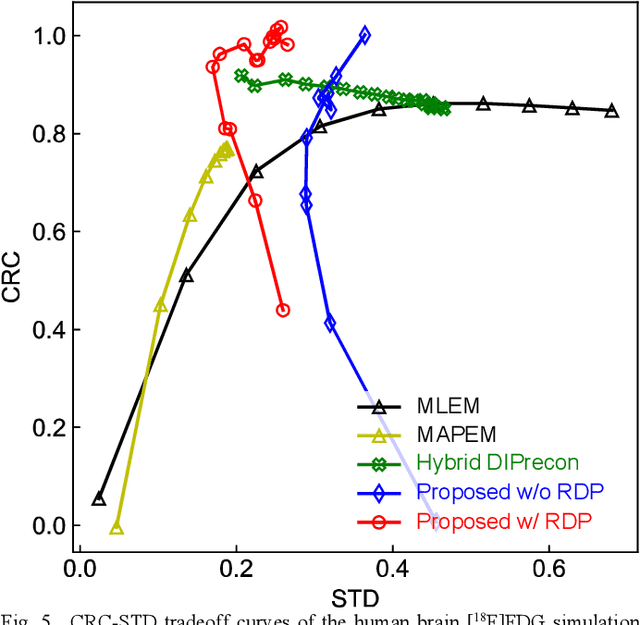
Deep image prior (DIP) has recently attracted attention owing to its unsupervised positron emission tomography (PET) image reconstruction, which does not require any prior training dataset. In this paper, we present the first attempt to implement an end-to-end DIP-based fully 3D PET image reconstruction method that incorporates a forward-projection model into a loss function. To implement a practical fully 3D PET image reconstruction, which could not be performed due to a graphics processing unit memory limitation, we modify the DIP optimization to block-iteration and sequentially learn an ordered sequence of block sinograms. Furthermore, the relative difference penalty (RDP) term was added to the loss function to enhance the quantitative PET image accuracy. We evaluated our proposed method using Monte Carlo simulation with [$^{18}$F]FDG PET data of a human brain and a preclinical study on monkey brain [$^{18}$F]FDG PET data. The proposed method was compared with the maximum-likelihood expectation maximization (EM), maximum-a-posterior EM with RDP, and hybrid DIP-based PET reconstruction methods. The simulation results showed that the proposed method improved the PET image quality by reducing statistical noise and preserved a contrast of brain structures and inserted tumor compared with other algorithms. In the preclinical experiment, finer structures and better contrast recovery were obtained by the proposed method. This indicated that the proposed method can produce high-quality images without a prior training dataset. Thus, the proposed method is a key enabling technology for the straightforward and practical implementation of end-to-end DIP-based fully 3D PET image reconstruction.
A2S-NAS: Asymmetric Spectral-Spatial Neural Architecture Search For Hyperspectral Image Classification
Feb 23, 2023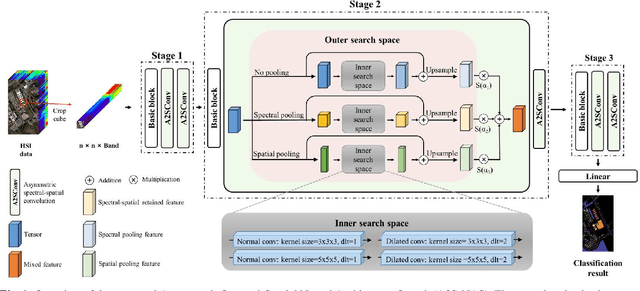
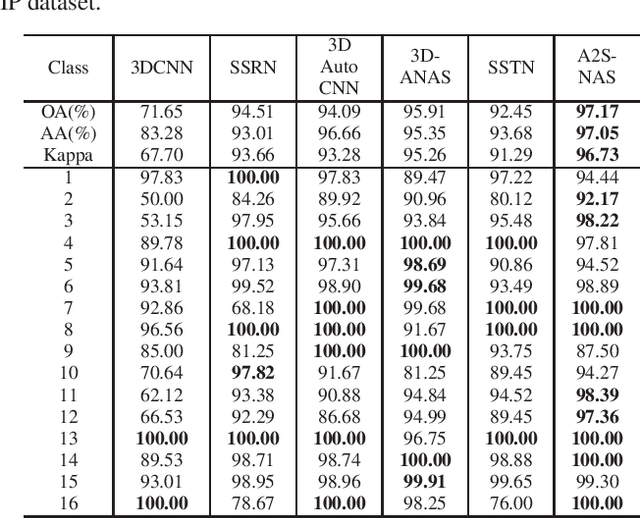
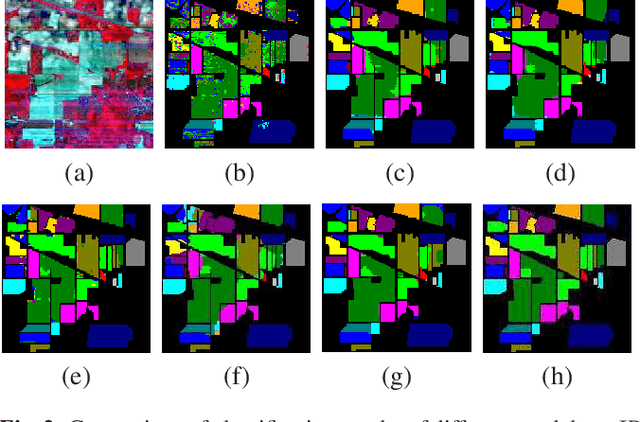
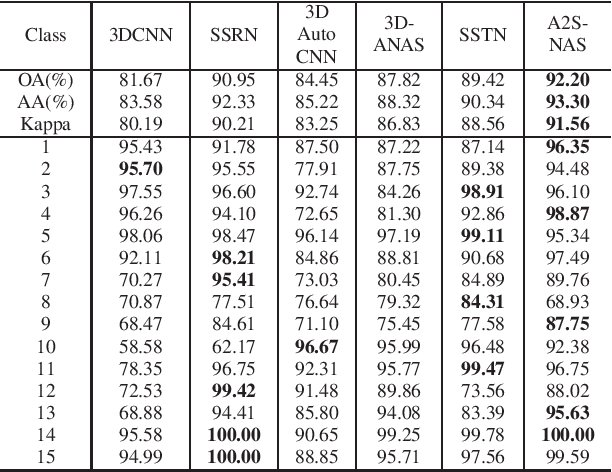
Existing deep learning-based hyperspectral image (HSI) classification works still suffer from the limitation of the fixed-sized receptive field, leading to difficulties in distinctive spectral-spatial features for ground objects with various sizes and arbitrary shapes. Meanwhile, plenty of previous works ignore asymmetric spectral-spatial dimensions in HSI. To address the above issues, we propose a multi-stage search architecture in order to overcome asymmetric spectral-spatial dimensions and capture significant features. First, the asymmetric pooling on the spectral-spatial dimension maximally retains the essential features of HSI. Then, the 3D convolution with a selectable range of receptive fields overcomes the constraints of fixed-sized convolution kernels. Finally, we extend these two searchable operations to different layers of each stage to build the final architecture. Extensive experiments are conducted on two challenging HSI benchmarks including Indian Pines and Houston University, and results demonstrate the effectiveness of the proposed method with superior performance compared with the related works.