 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Active Semantic Localization with Graph Neural Embedding
May 12, 2023
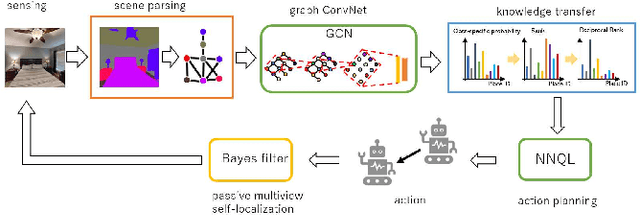
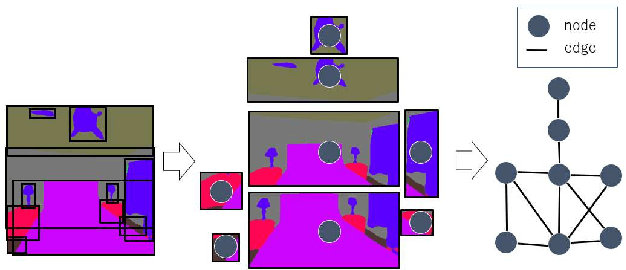


Semantic localization, i.e., robot self-localization with semantic image modality, is critical in recently emerging embodied AI applications such as point-goal navigation, object-goal navigation and vision language navigation. However, most existing works on semantic localization focus on passive vision tasks without viewpoint planning, or rely on additional rich modalities (e.g., depth measurements). Thus, the problem is largely unsolved. In this work, we explore a lightweight, entirely CPU-based, domain-adaptive semantic localization framework, called graph neural localizer.Our approach is inspired by two recently emerging technologies: (1) Scene graph, which combines the viewpoint- and appearance- invariance of local and global features; (2) Graph neural network, which enables direct learning/recognition of graph data (i.e., non-vector data). Specifically, a graph convolutional neural network is first trained as a scene graph classifier for passive vision, and then its knowledge is transferred to a reinforcement-learning planner for active vision. Experiments on two scenarios, self-supervised learning and unsupervised domain adaptation, using a photo-realistic Habitat simulator validate the effectiveness of the proposed method.
Joint MR sequence optimization beats pure neural network approaches for spin-echo MRI super-resolution
May 12, 2023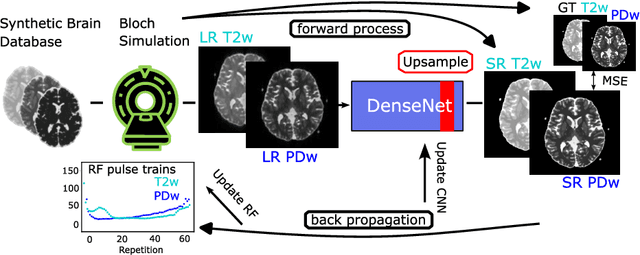
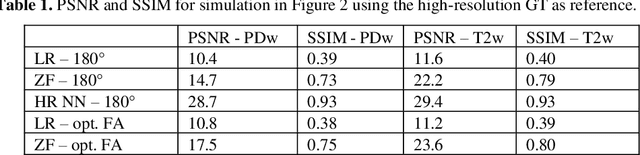
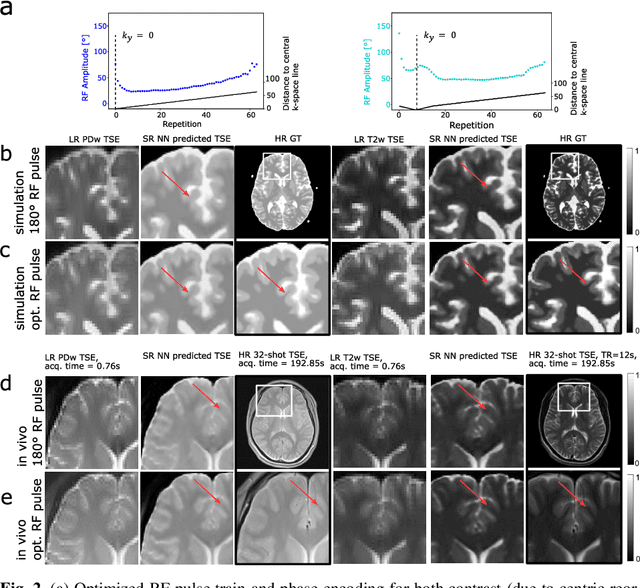
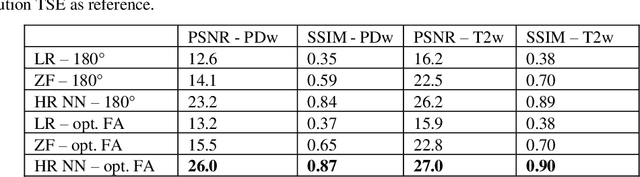
Current MRI super-resolution (SR) methods only use existing contrasts acquired from typical clinical sequences as input for the neural network (NN). In turbo spin echo sequences (TSE) the sequence parameters can have a strong influence on the actual resolution of the acquired image and have consequently a considera-ble impact on the performance of the NN. We propose a known-operator learning approach to perform an end-to-end optimization of MR sequence and neural net-work parameters for SR-TSE. This MR-physics-informed training procedure jointly optimizes the radiofrequency pulse train of a proton density- (PD-) and T2-weighted TSE and a subsequently applied convolutional neural network to predict the corresponding PDw and T2w super-resolution TSE images. The found radiofrequency pulse train designs generate an optimal signal for the NN to perform the SR task. Our method generalizes from the simulation-based optimi-zation to in vivo measurements and the acquired physics-informed SR images show higher correlation with a time-consuming segmented high-resolution TSE sequence compared to a pure network training approach.
PixCUE: Joint Uncertainty Estimation and Image Reconstruction in MRI using Deep Pixel Classification
Mar 08, 2023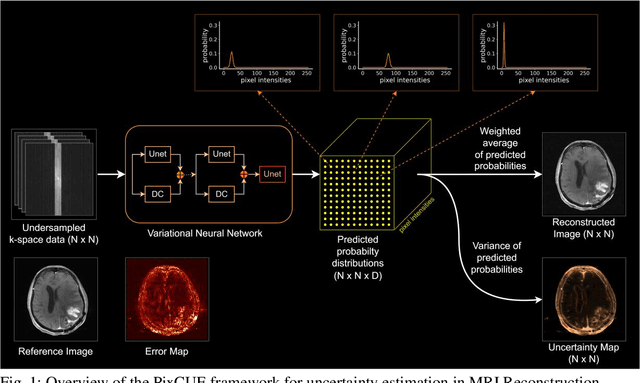
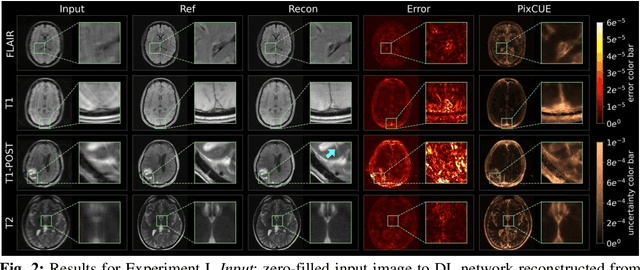
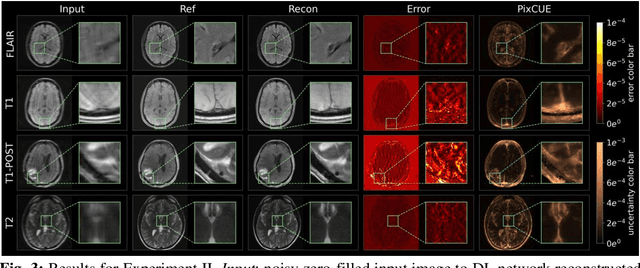
Deep learning (DL) models are capable of successfully exploiting latent representations in MR data and have become state-of-the-art for accelerated MRI reconstruction. However, undersampling the measurements in k-space as well as the over- or under-parameterized and non-transparent nature of DL make these models exposed to uncertainty. Consequently, uncertainty estimation has become a major issue in DL MRI reconstruction. To estimate uncertainty, Monte Carlo (MC) inference techniques have become a common practice where multiple reconstructions are utilized to compute the variance in reconstruction as a measurement of uncertainty. However, these methods demand high computational costs as they require multiple inferences through the DL model. To this end, we introduce a method to estimate uncertainty during MRI reconstruction using a pixel classification framework. The proposed method, PixCUE (stands for Pixel Classification Uncertainty Estimation) produces the reconstructed image along with an uncertainty map during a single forward pass through the DL model. We demonstrate that this approach generates uncertainty maps that highly correlate with the reconstruction errors with respect to various MR imaging sequences and under numerous adversarial conditions. We also show that the estimated uncertainties are correlated to that of the conventional MC method. We further provide an empirical relationship between the uncertainty estimations using PixCUE and well-established reconstruction metrics such as NMSE, PSNR, and SSIM. We conclude that PixCUE is capable of reliably estimating the uncertainty in MRI reconstruction with a minimum additional computational cost.
Segment anything, from space?
May 15, 2023
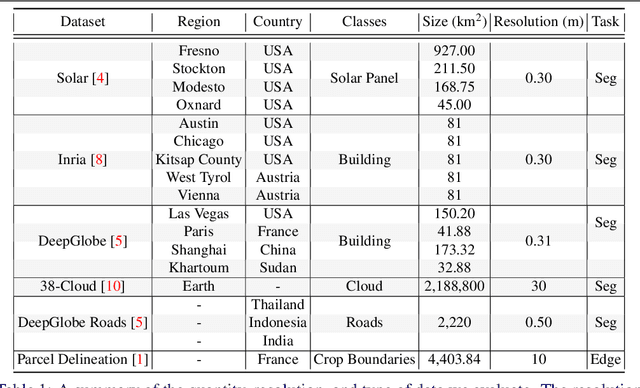
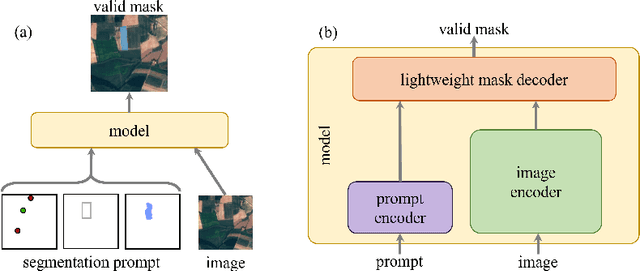
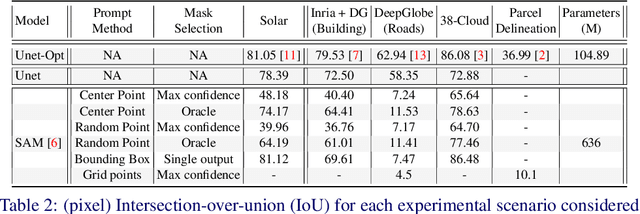
Recently, the first foundation model developed specifically for vision tasks was developed, termed the "Segment Anything Model" (SAM). SAM can segment objects in input imagery based upon cheap input prompts, such as one (or more) points, a bounding box, or a mask. The authors examined the zero-shot image segmentation accuracy of SAM on a large number of vision benchmark tasks and found that SAM usually achieved recognition accuracy similar to, or sometimes exceeding, vision models that had been trained on the target tasks. The impressive generalization of SAM for segmentation has major implications for vision researchers working on natural imagery. In this work, we examine whether SAM's impressive performance extends to overhead imagery problems, and help guide the community's response to its development. We examine SAM's performance on a set of diverse and widely-studied benchmark tasks. We find that SAM does often generalize well to overhead imagery, although it fails in some cases due to the unique characteristics of overhead imagery and the target objects. We report on these unique systematic failure cases for remote sensing imagery that may comprise useful future research for the community. Note that this is a working paper, and it will be updated as additional analysis and results are completed.
CLIP-VG: Self-paced Curriculum Adapting of CLIP via Exploiting Pseudo-Language Labels for Visual Grounding
May 15, 2023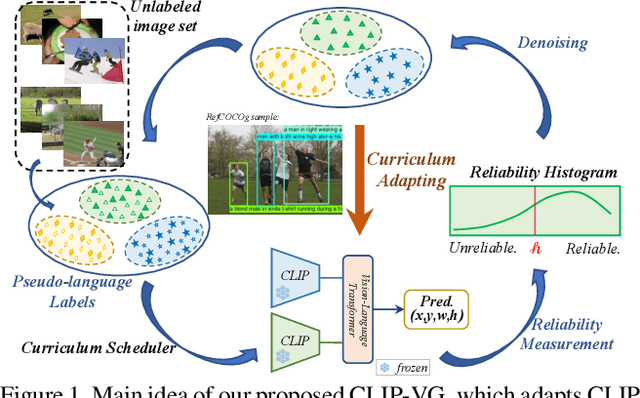
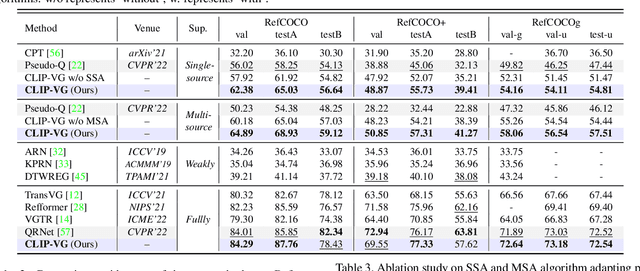

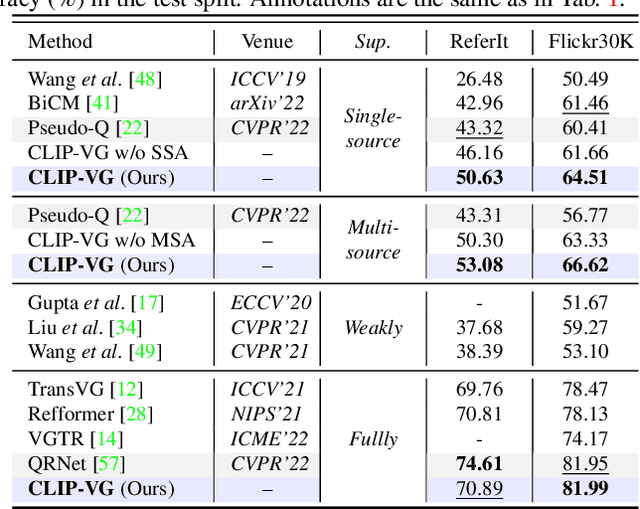
Visual Grounding (VG) refers to locating a region described by expressions in a specific image, which is a critical topic in vision-language fields. To alleviate the dependence on labeled data, existing unsupervised methods try to locate regions using task-unrelated pseudo-labels. However, a large proportion of pseudo-labels are noisy and diversity scarcity in language taxonomy. Inspired by the advances in V-L pretraining, we consider utilizing the VLP models to realize unsupervised transfer learning in downstream grounding task. Thus, we propose CLIP-VG, a novel method that can conduct self-paced curriculum adapting of CLIP via exploiting pseudo-language labels to solve VG problem. By elaborating an efficient model structure, we first propose a single-source and multi-source curriculum adapting method for unsupervised VG to progressively sample more reliable cross-modal pseudo-labels to obtain the optimal model, thus achieving implicit knowledge exploiting and denoising. Our method outperforms the existing state-of-the-art unsupervised VG method Pseudo-Q in both single-source and multi-source scenarios with a large margin, i.e., 6.78%~10.67% and 11.39%~24.87% on RefCOCO/+/g datasets, even outperforms existing weakly supervised methods. The code and models will be released at \url{https://github.com/linhuixiao/CLIP-VG}.
M$^{6}$Doc: A Large-Scale Multi-Format, Multi-Type, Multi-Layout, Multi-Language, Multi-Annotation Category Dataset for Modern Document Layout Analysis
May 15, 2023
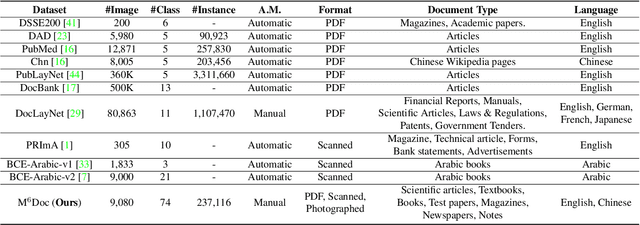
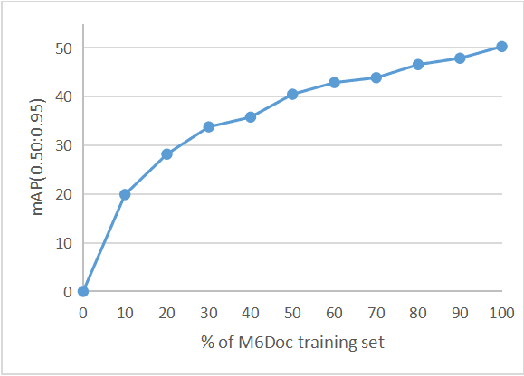
Document layout analysis is a crucial prerequisite for document understanding, including document retrieval and conversion. Most public datasets currently contain only PDF documents and lack realistic documents. Models trained on these datasets may not generalize well to real-world scenarios. Therefore, this paper introduces a large and diverse document layout analysis dataset called $M^{6}Doc$. The $M^6$ designation represents six properties: (1) Multi-Format (including scanned, photographed, and PDF documents); (2) Multi-Type (such as scientific articles, textbooks, books, test papers, magazines, newspapers, and notes); (3) Multi-Layout (rectangular, Manhattan, non-Manhattan, and multi-column Manhattan); (4) Multi-Language (Chinese and English); (5) Multi-Annotation Category (74 types of annotation labels with 237,116 annotation instances in 9,080 manually annotated pages); and (6) Modern documents. Additionally, we propose a transformer-based document layout analysis method called TransDLANet, which leverages an adaptive element matching mechanism that enables query embedding to better match ground truth to improve recall, and constructs a segmentation branch for more precise document image instance segmentation. We conduct a comprehensive evaluation of $M^{6}Doc$ with various layout analysis methods and demonstrate its effectiveness. TransDLANet achieves state-of-the-art performance on $M^{6}Doc$ with 64.5\% mAP. The $M^{6}Doc$ dataset will be available at https://github.com/HCIILAB/M6Doc.
Enhancing Performance of Vision Transformers on Small Datasets through Local Inductive Bias Incorporation
May 15, 2023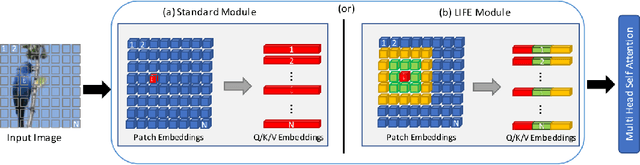
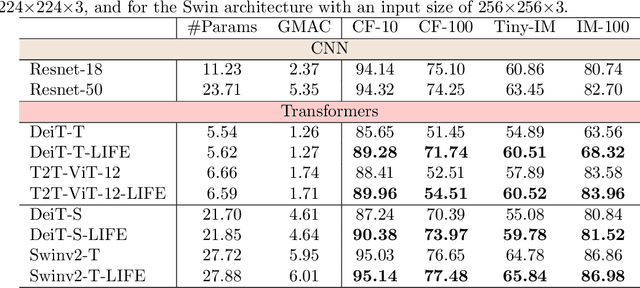
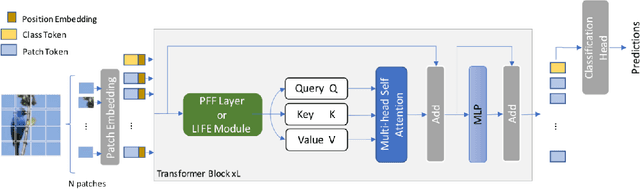

Vision transformers (ViTs) achieve remarkable performance on large datasets, but tend to perform worse than convolutional neural networks (CNNs) when trained from scratch on smaller datasets, possibly due to a lack of local inductive bias in the architecture. Recent studies have therefore added locality to the architecture and demonstrated that it can help ViTs achieve performance comparable to CNNs in the small-size dataset regime. Existing methods, however, are architecture-specific or have higher computational and memory costs. Thus, we propose a module called Local InFormation Enhancer (LIFE) that extracts patch-level local information and incorporates it into the embeddings used in the self-attention block of ViTs. Our proposed module is memory and computation efficient, as well as flexible enough to process auxiliary tokens such as the classification and distillation tokens. Empirical results show that the addition of the LIFE module improves the performance of ViTs on small image classification datasets. We further demonstrate how the effect can be extended to downstream tasks, such as object detection and semantic segmentation. In addition, we introduce a new visualization method, Dense Attention Roll-Out, specifically designed for dense prediction tasks, allowing the generation of class-specific attention maps utilizing the attention maps of all tokens.
Not All Pixels Are Equal: Learning Pixel Hardness for Semantic Segmentation
May 15, 2023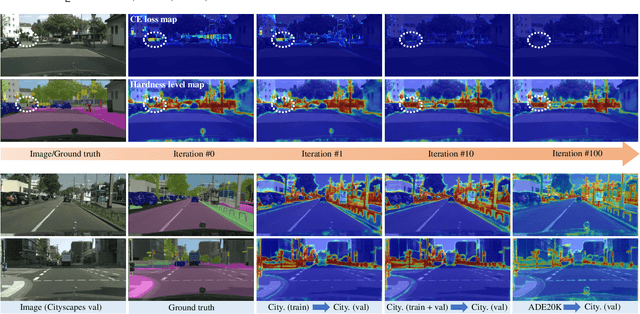
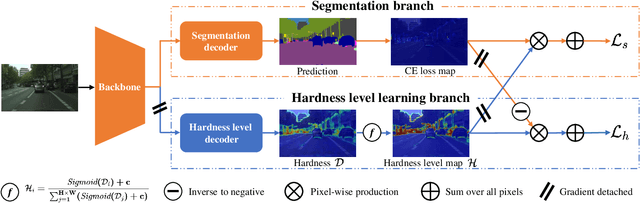
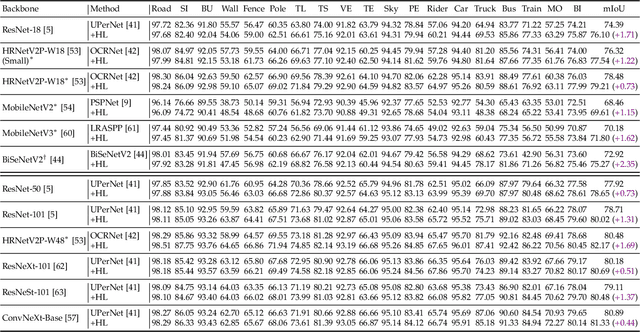
Semantic segmentation has recently witnessed great progress. Despite the impressive overall results, the segmentation performance in some hard areas (e.g., small objects or thin parts) is still not promising. A straightforward solution is hard sample mining, which is widely used in object detection. Yet, most existing hard pixel mining strategies for semantic segmentation often rely on pixel's loss value, which tends to decrease during training. Intuitively, the pixel hardness for segmentation mainly depends on image structure and is expected to be stable. In this paper, we propose to learn pixel hardness for semantic segmentation, leveraging hardness information contained in global and historical loss values. More precisely, we add a gradient-independent branch for learning a hardness level (HL) map by maximizing hardness-weighted segmentation loss, which is minimized for the segmentation head. This encourages large hardness values in difficult areas, leading to appropriate and stable HL map. Despite its simplicity, the proposed method can be applied to most segmentation methods with no and marginal extra cost during inference and training, respectively. Without bells and whistles, the proposed method achieves consistent/significant improvement (1.37% mIoU on average) over most popular semantic segmentation methods on Cityscapes dataset, and demonstrates good generalization ability across domains. The source codes are available at https://github.com/Menoly-xin/Hardness-Level-Learning .
Online Sequence Clustering Algorithm for Video Trajectory Analysis
May 15, 2023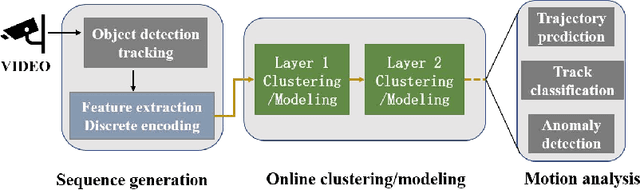
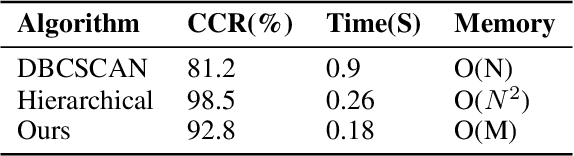
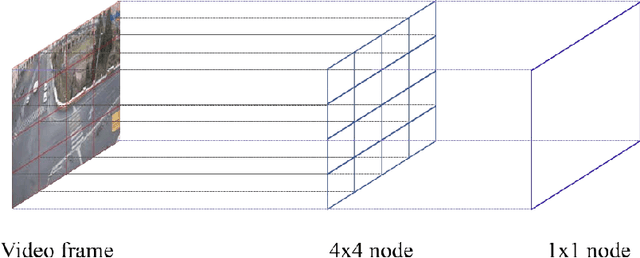
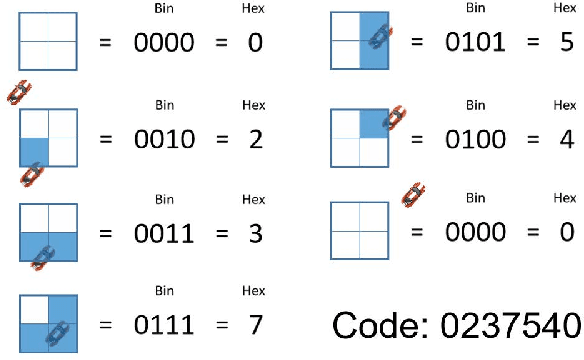
Target tracking and trajectory modeling have important applications in surveillance video analysis and have received great attention in the fields of road safety and community security. In this work, we propose a lightweight real-time video analysis scheme that uses a model learned from motion patterns to monitor the behavior of objects, which can be used for applications such as real-time representation and prediction. The proposed sequence clustering algorithm based on discrete sequences makes the system have continuous online learning ability. The intrinsic repeatability of the target object trajectory is used to automatically construct the behavioral model in the three processes of feature extraction, cluster learning, and model application. In addition to the discretization of trajectory features and simple model applications, this paper focuses on online clustering algorithms and their incremental learning processes. Finally, through the learning of the trajectory model of the actual surveillance video image, the feasibility of the algorithm is verified. And the characteristics and performance of the clustering algorithm are discussed in the analysis. This scheme has real-time online learning and processing of motion models while avoiding a large number of arithmetic operations, which is more in line with the application scenarios of front-end intelligent perception.
Venn Diagram Multi-label Class Interpretation of Diabetic Foot Ulcer with Color and Sharpness Enhancement
May 05, 2023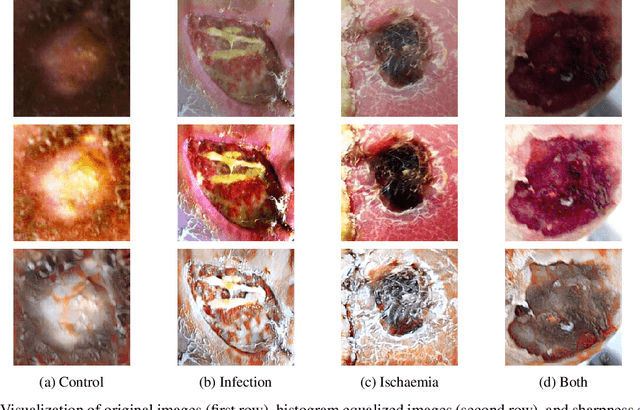
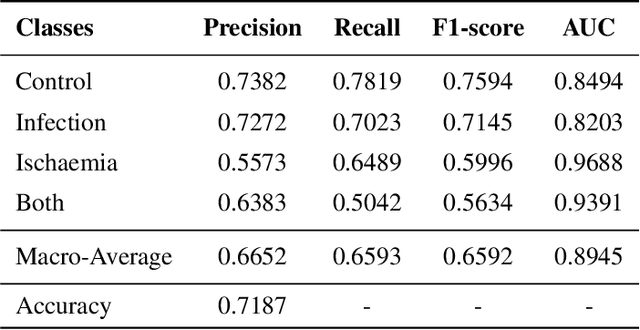
DFU is a severe complication of diabetes that can lead to amputation of the lower limb if not treated properly. Inspired by the 2021 Diabetic Foot Ulcer Grand Challenge, researchers designed automated multi-class classification of DFU, including infection, ischaemia, both of these conditions, and none of these conditions. However, it remains a challenge as classification accuracy is still not satisfactory. This paper proposes a Venn Diagram interpretation of multi-label CNN-based method, utilizing different image enhancement strategies, to improve the multi-class DFU classification. We propose to reduce the four classes into two since both class wounds can be interpreted as the simultaneous occurrence of infection and ischaemia and none class wounds as the absence of infection and ischaemia. We introduce a novel Venn Diagram representation block in the classifier to interpret all four classes from these two classes. To make our model more resilient, we propose enhancing the perceptual quality of DFU images, particularly blurry or inconsistently lit DFU images, by performing color and sharpness enhancements on them. We also employ a fine-tuned optimization technique, adaptive sharpness aware minimization, to improve the CNN model generalization performance. The proposed method is evaluated on the test dataset of DFUC2021, containing 5,734 images and the results are compared with the top-3 winning entries of DFUC2021. Our proposed approach outperforms these existing approaches and achieves Macro-Average F1, Recall and Precision scores of 0.6592, 0.6593, and 0.6652, respectively.Additionally, We perform ablation studies and image quality measurements to further interpret our proposed method. This proposed method will benefit patients with DFUs since it tackles the inconsistencies in captured images and can be employed for a more robust remote DFU wound classification.