 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Chain of Compression: A Systematic Approach to Combinationally Compress Convolutional Neural Networks
Mar 26, 2024
Convolutional neural networks (CNNs) have achieved significant popularity, but their computational and memory intensity poses challenges for resource-constrained computing systems, particularly with the prerequisite of real-time performance. To release this burden, model compression has become an important research focus. Many approaches like quantization, pruning, early exit, and knowledge distillation have demonstrated the effect of reducing redundancy in neural networks. Upon closer examination, it becomes apparent that each approach capitalizes on its unique features to compress the neural network, and they can also exhibit complementary behavior when combined. To explore the interactions and reap the benefits from the complementary features, we propose the Chain of Compression, which works on the combinational sequence to apply these common techniques to compress the neural network. Validated on the image-based regression and classification networks across different data sets, our proposed Chain of Compression can significantly compress the computation cost by 100-1000 times with ignorable accuracy loss compared with the baseline model.
DeepGleason: a System for Automated Gleason Grading of Prostate Cancer using Deep Neural Networks
Mar 25, 2024Advances in digital pathology and artificial intelligence (AI) offer promising opportunities for clinical decision support and enhancing diagnostic workflows. Previous studies already demonstrated AI's potential for automated Gleason grading, but lack state-of-the-art methodology and model reusability. To address this issue, we propose DeepGleason: an open-source deep neural network based image classification system for automated Gleason grading using whole-slide histopathology images from prostate tissue sections. Implemented with the standardized AUCMEDI framework, our tool employs a tile-wise classification approach utilizing fine-tuned image preprocessing techniques in combination with a ConvNeXt architecture which was compared to various state-of-the-art architectures. The neural network model was trained and validated on an in-house dataset of 34,264 annotated tiles from 369 prostate carcinoma slides. We demonstrated that DeepGleason is capable of highly accurate and reliable Gleason grading with a macro-averaged F1-score of 0.806, AUC of 0.991, and Accuracy of 0.974. The internal architecture comparison revealed that the ConvNeXt model was superior performance-wise on our dataset to established and other modern architectures like transformers. Furthermore, we were able to outperform the current state-of-the-art in tile-wise fine-classification with a sensitivity and specificity of 0.94 and 0.98 for benign vs malignant detection as well as of 0.91 and 0.75 for Gleason 3 vs Gleason 4 & 5 classification, respectively. Our tool contributes to the wider adoption of AI-based Gleason grading within the research community and paves the way for broader clinical application of deep learning models in digital pathology. DeepGleason is open-source and publicly available for research application in the following Git repository: https://github.com/frankkramer-lab/DeepGleason.
Comparison of No-Reference Image Quality Models via MAP Estimation in Diffusion Latents
Mar 11, 2024
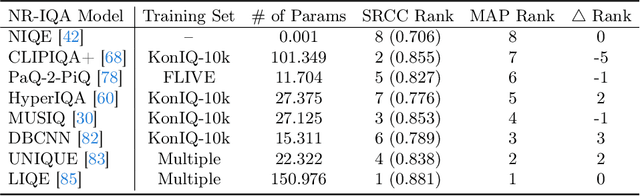


Contemporary no-reference image quality assessment (NR-IQA) models can effectively quantify the perceived image quality, with high correlations between model predictions and human perceptual scores on fixed test sets. However, little progress has been made in comparing NR-IQA models from a perceptual optimization perspective. Here, for the first time, we demonstrate that NR-IQA models can be plugged into the maximum a posteriori (MAP) estimation framework for image enhancement. This is achieved by taking the gradients in differentiable and bijective diffusion latents rather than in the raw pixel domain. Different NR-IQA models are likely to induce different enhanced images, which are ultimately subject to psychophysical testing. This leads to a new computational method for comparing NR-IQA models within the analysis-by-synthesis framework. Compared to conventional correlation-based metrics, our method provides complementary insights into the relative strengths and weaknesses of the competing NR-IQA models in the context of perceptual optimization.
Generalizable Two-Branch Framework for Image Class-Incremental Learning
Mar 13, 2024Deep neural networks often severely forget previously learned knowledge when learning new knowledge. Various continual learning (CL) methods have been proposed to handle such a catastrophic forgetting issue from different perspectives and achieved substantial improvements. In this paper, a novel two-branch continual learning framework is proposed to further enhance most existing CL methods. Specifically, the main branch can be any existing CL model and the newly introduced side branch is a lightweight convolutional network. The output of each main branch block is modulated by the output of the corresponding side branch block. Such a simple two-branch model can then be easily implemented and learned with the vanilla optimization setting without whistles and bells. Extensive experiments with various settings on multiple image datasets show that the proposed framework yields consistent improvements over state-of-the-art methods.
A Bayesian Approach to OOD Robustness in Image Classification
Mar 12, 2024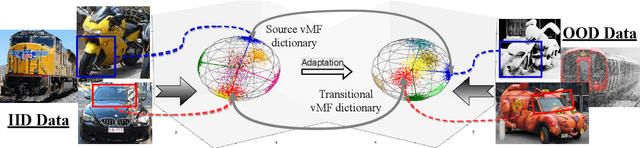
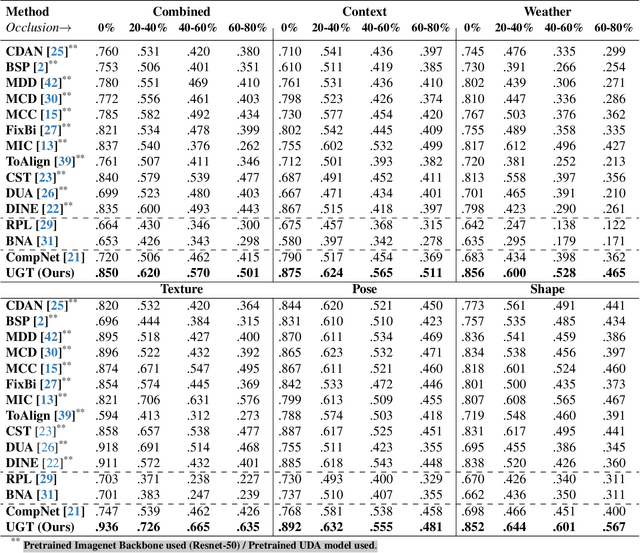
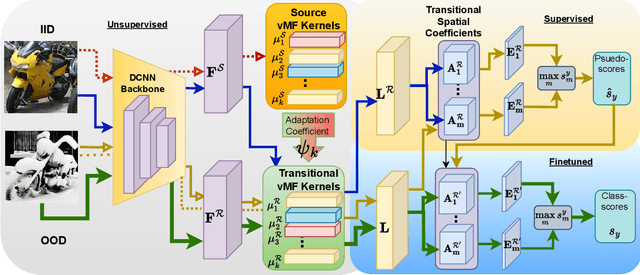
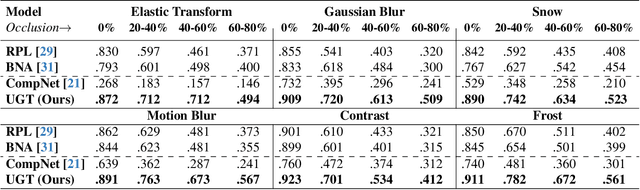
An important and unsolved problem in computer vision is to ensure that the algorithms are robust to changes in image domains. We address this problem in the scenario where we have access to images from the target domains but no annotations. Motivated by the challenges of the OOD-CV benchmark where we encounter real world Out-of-Domain (OOD) nuisances and occlusion, we introduce a novel Bayesian approach to OOD robustness for object classification. Our work extends Compositional Neural Networks (CompNets), which have been shown to be robust to occlusion but degrade badly when tested on OOD data. We exploit the fact that CompNets contain a generative head defined over feature vectors represented by von Mises-Fisher (vMF) kernels, which correspond roughly to object parts, and can be learned without supervision. We obverse that some vMF kernels are similar between different domains, while others are not. This enables us to learn a transitional dictionary of vMF kernels that are intermediate between the source and target domains and train the generative model on this dictionary using the annotations on the source domain, followed by iterative refinement. This approach, termed Unsupervised Generative Transition (UGT), performs very well in OOD scenarios even when occlusion is present. UGT is evaluated on different OOD benchmarks including the OOD-CV dataset, several popular datasets (e.g., ImageNet-C [9]), artificial image corruptions (including adding occluders), and synthetic-to-real domain transfer, and does well in all scenarios outperforming SOTA alternatives (e.g. up to 10% top-1 accuracy on Occluded OOD-CV dataset).
DivCon: Divide and Conquer for Progressive Text-to-Image Generation
Mar 11, 2024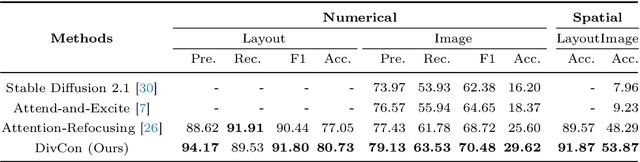

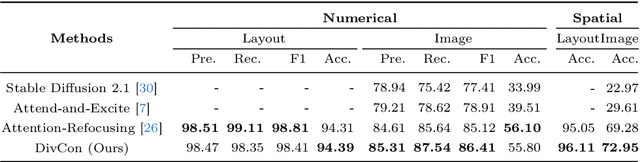
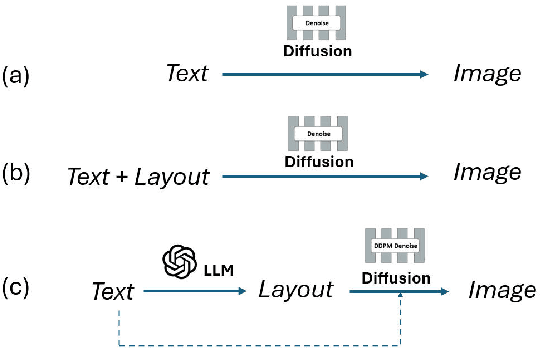
Diffusion-driven text-to-image (T2I) generation has achieved remarkable advancements. To further improve T2I models' capability in numerical and spatial reasoning, the layout is employed as an intermedium to bridge large language models and layout-based diffusion models. However, these methods still struggle with generating images from textural prompts with multiple objects and complicated spatial relationships. To tackle this challenge, we introduce a divide-and-conquer approach which decouples the T2I generation task into simple subtasks. Our approach divides the layout prediction stage into numerical \& spatial reasoning and bounding box prediction. Then, the layout-to-image generation stage is conducted in an iterative manner to reconstruct objects from easy ones to difficult ones. We conduct experiments on the HRS and NSR-1K benchmarks and our approach outperforms previous state-of-the-art models with notable margins. In addition, visual results demonstrate that our approach significantly improves the controllability and consistency in generating multiple objects from complex textural prompts.
Skull-to-Face: Anatomy-Guided 3D Facial Reconstruction and Editing
Mar 24, 2024Deducing the 3D face from a skull is an essential but challenging task in forensic science and archaeology. Existing methods for automated facial reconstruction yield inaccurate results, suffering from the non-determinative nature of the problem that a skull with a sparse set of tissue depth cannot fully determine the skinned face. Additionally, their texture-less results require further post-processing stages to achieve a photo-realistic appearance. This paper proposes an end-to-end 3D face reconstruction and exploration tool, providing textured 3D faces for reference. With the help of state-of-the-art text-to-image diffusion models and image-based facial reconstruction techniques, we generate an initial reference 3D face, whose biological profile aligns with the given skull. We then adapt these initial faces to meet the statistical expectations of extruded anatomical landmarks on the skull through an optimization process. The joint statistical distribution of tissue depths is learned on a small set of anatomical landmarks on the skull. To support further adjustment, we propose an efficient face adaptation tool to assist users in tuning tissue depths, either globally or at local regions, while observing plausible visual feedback. Experiments conducted on a real skull-face dataset demonstrated the effectiveness of our proposed pipeline in terms of reconstruction accuracy, diversity, and stability.
Red Teaming Models for Hyperspectral Image Analysis Using Explainable AI
Mar 14, 2024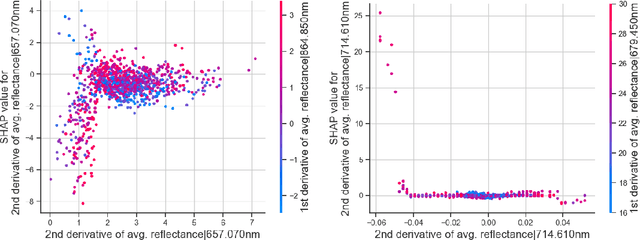
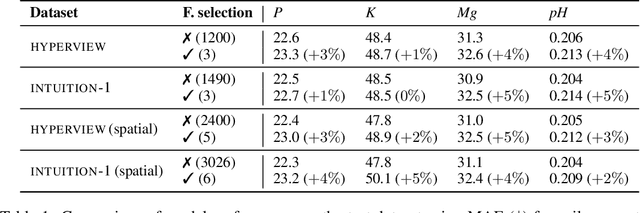
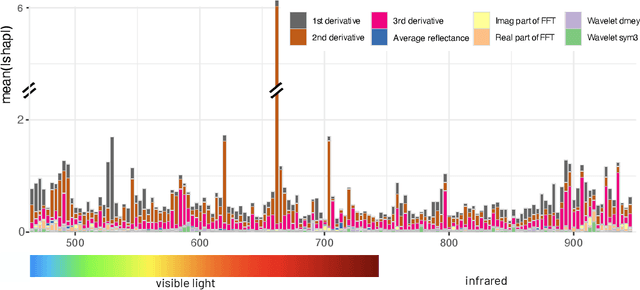
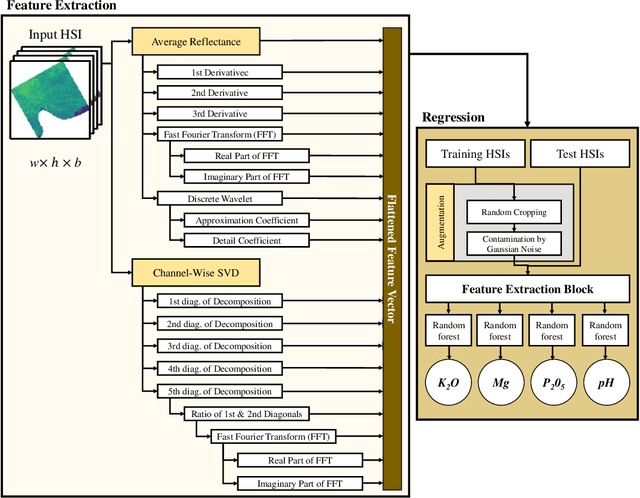
Remote sensing (RS) applications in the space domain demand machine learning (ML) models that are reliable, robust, and quality-assured, making red teaming a vital approach for identifying and exposing potential flaws and biases. Since both fields advance independently, there is a notable gap in integrating red teaming strategies into RS. This paper introduces a methodology for examining ML models operating on hyperspectral images within the HYPERVIEW challenge, focusing on soil parameters' estimation. We use post-hoc explanation methods from the Explainable AI (XAI) domain to critically assess the best performing model that won the HYPERVIEW challenge and served as an inspiration for the model deployed on board the INTUITION-1 hyperspectral mission. Our approach effectively red teams the model by pinpointing and validating key shortcomings, constructing a model that achieves comparable performance using just 1% of the input features and a mere up to 5% performance loss. Additionally, we propose a novel way of visualizing explanations that integrate domain-specific information about hyperspectral bands (wavelengths) and data transformations to better suit interpreting models for hyperspectral image analysis.
MeaCap: Memory-Augmented Zero-shot Image Captioning
Mar 06, 2024
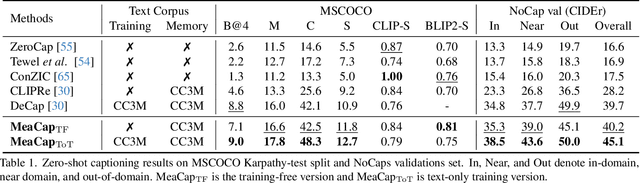
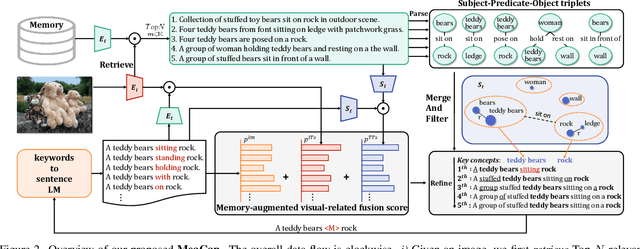
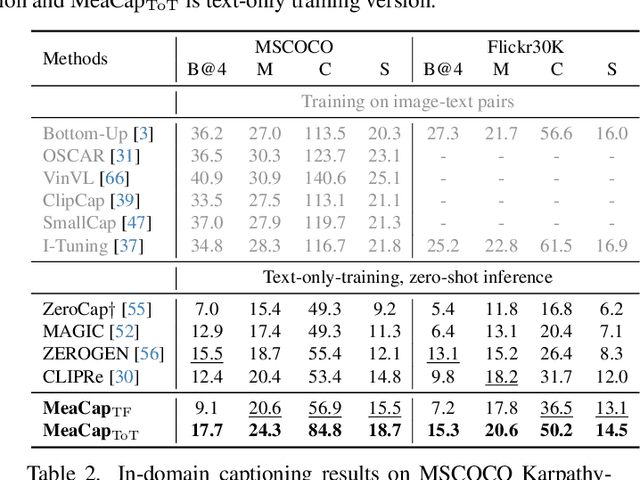
Zero-shot image captioning (IC) without well-paired image-text data can be divided into two categories, training-free and text-only-training. Generally, these two types of methods realize zero-shot IC by integrating pretrained vision-language models like CLIP for image-text similarity evaluation and a pre-trained language model (LM) for caption generation. The main difference between them is whether using a textual corpus to train the LM. Though achieving attractive performance w.r.t. some metrics, existing methods often exhibit some common drawbacks. Training-free methods tend to produce hallucinations, while text-only-training often lose generalization capability. To move forward, in this paper, we propose a novel Memory-Augmented zero-shot image Captioning framework (MeaCap). Specifically, equipped with a textual memory, we introduce a retrieve-then-filter module to get key concepts that are highly related to the image. By deploying our proposed memory-augmented visual-related fusion score in a keywords-to-sentence LM, MeaCap can generate concept-centered captions that keep high consistency with the image with fewer hallucinations and more world-knowledge. The framework of MeaCap achieves the state-of-the-art performance on a series of zero-shot IC settings. Our code is available at https://github.com/joeyz0z/MeaCap.
Leveraging Near-Field Lighting for Monocular Depth Estimation from Endoscopy Videos
Mar 26, 2024Monocular depth estimation in endoscopy videos can enable assistive and robotic surgery to obtain better coverage of the organ and detection of various health issues. Despite promising progress on mainstream, natural image depth estimation, techniques perform poorly on endoscopy images due to a lack of strong geometric features and challenging illumination effects. In this paper, we utilize the photometric cues, i.e., the light emitted from an endoscope and reflected by the surface, to improve monocular depth estimation. We first create two novel loss functions with supervised and self-supervised variants that utilize a per-pixel shading representation. We then propose a novel depth refinement network (PPSNet) that leverages the same per-pixel shading representation. Finally, we introduce teacher-student transfer learning to produce better depth maps from both synthetic data with supervision and clinical data with self-supervision. We achieve state-of-the-art results on the C3VD dataset while estimating high-quality depth maps from clinical data. Our code, pre-trained models, and supplementary materials can be found on our project page: https://ppsnet.github.io/