 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Investigating GANsformer: A Replication Study of a State-of-the-Art Image Generation Model
Mar 15, 2023

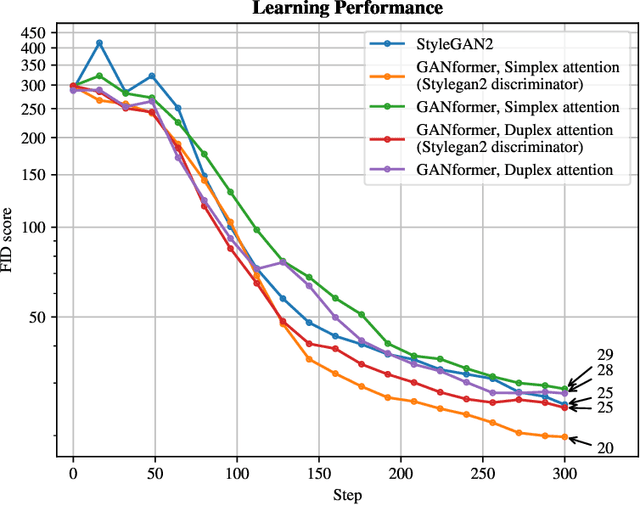


The field of image generation through generative modelling is abundantly discussed nowadays. It can be used for various applications, such as up-scaling existing images, creating non-existing objects, such as interior design scenes, products or even human faces, and achieving transfer-learning processes. In this context, Generative Adversarial Networks (GANs) are a class of widely studied machine learning frameworks first appearing in the paper "Generative adversarial nets" by Goodfellow et al. that achieve the goal above. In our work, we reproduce and evaluate a novel variation of the original GAN network, the GANformer, proposed in "Generative Adversarial Transformers" by Hudson and Zitnick. This project aimed to recreate the methods presented in this paper to reproduce the original results and comment on the authors' claims. Due to resources and time limitations, we had to constrain the network's training times, dataset types, and sizes. Our research successfully recreated both variations of the proposed GANformer model and found differences between the authors' and our results. Moreover, discrepancies between the publication methodology and the one implemented, made available in the code, allowed us to study two undisclosed variations of the presented procedures.
Transfer Learning for Fine-grained Classification Using Semi-supervised Learning and Visual Transformers
May 17, 2023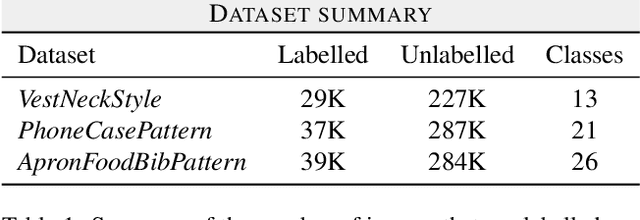

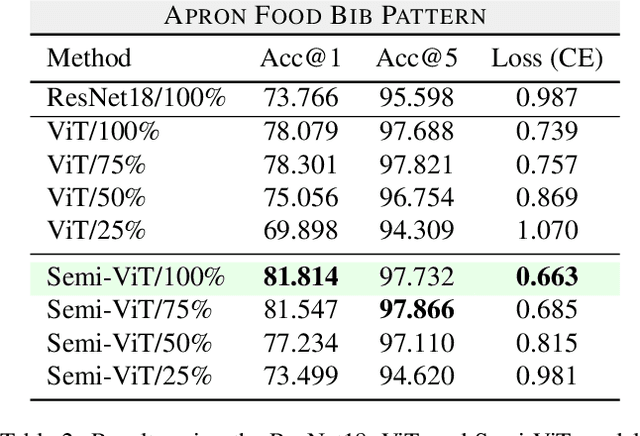
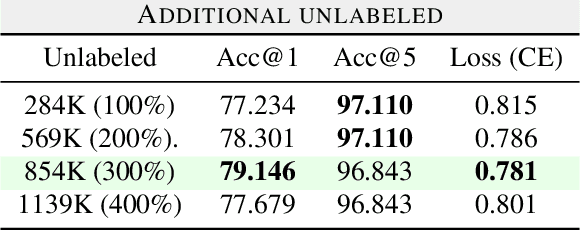
Fine-grained classification is a challenging task that involves identifying subtle differences between objects within the same category. This task is particularly challenging in scenarios where data is scarce. Visual transformers (ViT) have recently emerged as a powerful tool for image classification, due to their ability to learn highly expressive representations of visual data using self-attention mechanisms. In this work, we explore Semi-ViT, a ViT model fine tuned using semi-supervised learning techniques, suitable for situations where we have lack of annotated data. This is particularly common in e-commerce, where images are readily available but labels are noisy, nonexistent, or expensive to obtain. Our results demonstrate that Semi-ViT outperforms traditional convolutional neural networks (CNN) and ViTs, even when fine-tuned with limited annotated data. These findings indicate that Semi-ViTs hold significant promise for applications that require precise and fine-grained classification of visual data.
Fast MRI Reconstruction via Edge Attention
Apr 22, 2023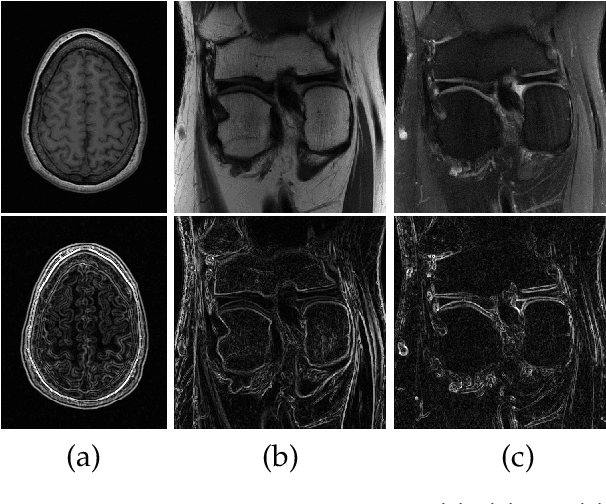
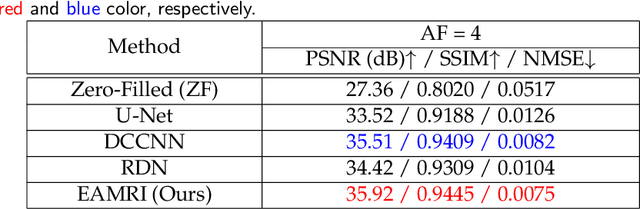
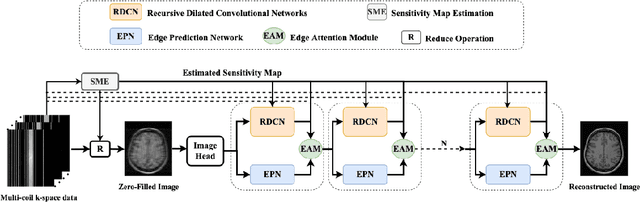
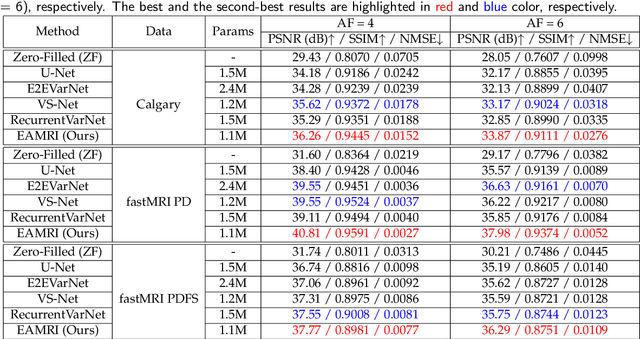
Fast and accurate MRI reconstruction is a key concern in modern clinical practice. Recently, numerous Deep-Learning methods have been proposed for MRI reconstruction, however, they usually fail to reconstruct sharp details from the subsampled k-space data. To solve this problem, we propose a lightweight and accurate Edge Attention MRI Reconstruction Network (EAMRI) to reconstruct images with edge guidance. Specifically, we design an efficient Edge Prediction Network to directly predict accurate edges from the blurred image. Meanwhile, we propose a novel Edge Attention Module (EAM) to guide the image reconstruction utilizing the extracted edge priors, as inspired by the popular self-attention mechanism. EAM first projects the input image and edges into Q_image, K_edge, and V_image, respectively. Then EAM pairs the Q_image with K_edge along the channel dimension, such that 1) it can search globally for the high-frequency image features that are activated by the edge priors; 2) the overall computation burdens are largely reduced compared with the traditional spatial-wise attention. With the help of EAM, the predicted edge priors can effectively guide the model to reconstruct high-quality MR images with accurate edges. Extensive experiments show that our proposed EAMRI outperforms other methods with fewer parameters and can recover more accurate edges.
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
May 25, 2023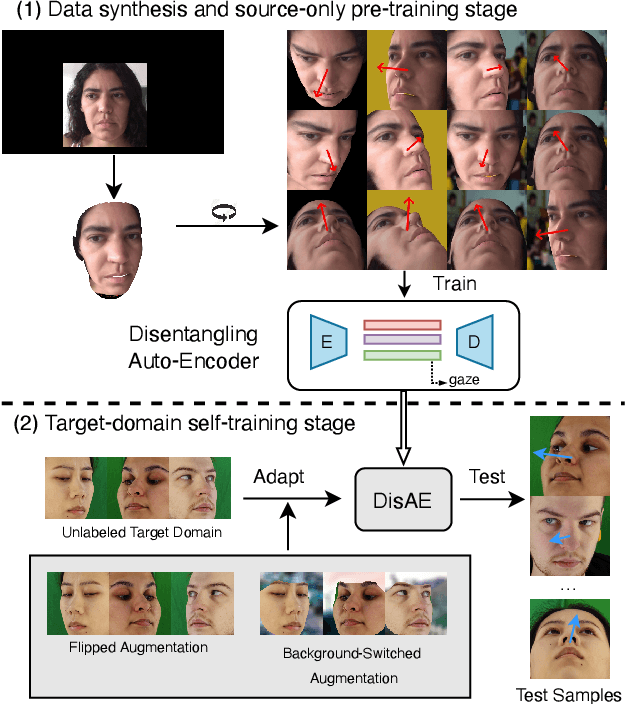
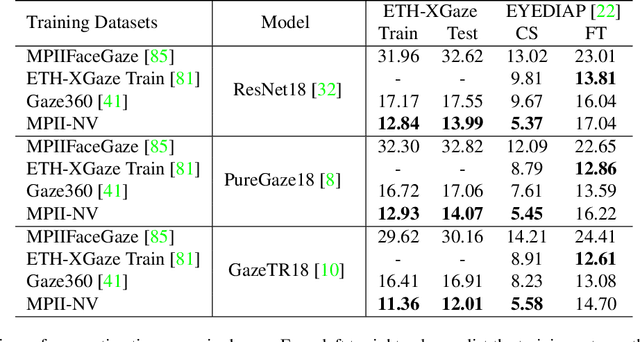
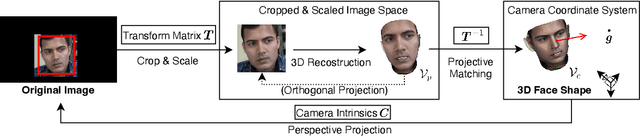
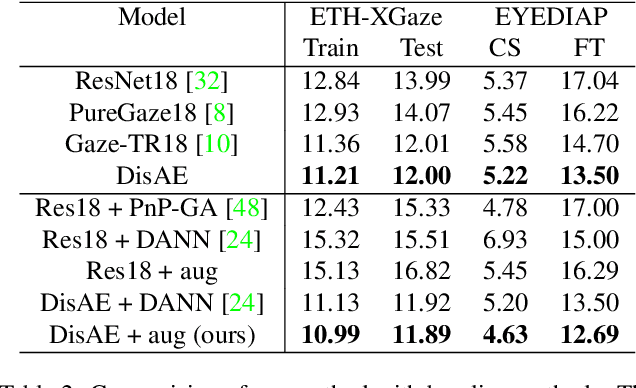
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play a significant role in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, we show that the model only using monocular-reconstructed synthetic training data can perform comparably to real data with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at \url{https://github.com/ut-vision/AdaptiveGaze}.
On the Robustness of Segment Anything
May 25, 2023
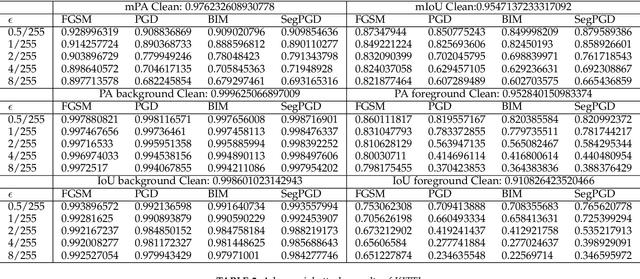

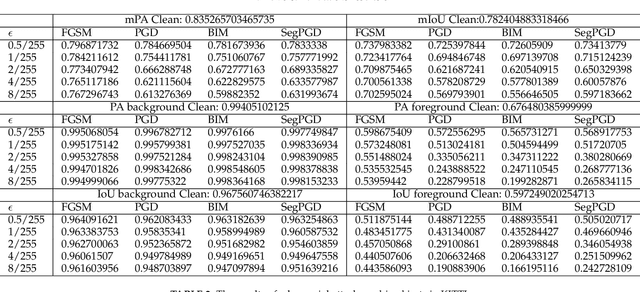
Segment anything model (SAM) has presented impressive objectness identification capability with the idea of prompt learning and a new collected large-scale dataset. Given a prompt (e.g., points, bounding boxes, or masks) and an input image, SAM is able to generate valid segment masks for all objects indicated by the prompts, presenting high generalization across diverse scenarios and being a general method for zero-shot transfer to downstream vision tasks. Nevertheless, it remains unclear whether SAM may introduce errors in certain threatening scenarios. Clarifying this is of significant importance for applications that require robustness, such as autonomous vehicles. In this paper, we aim to study the testing-time robustness of SAM under adversarial scenarios and common corruptions. To this end, we first build a testing-time robustness evaluation benchmark for SAM by integrating existing public datasets. Second, we extend representative adversarial attacks against SAM and study the influence of different prompts on robustness. Third, we study the robustness of SAM under diverse corruption types by evaluating SAM on corrupted datasets with different prompts. With experiments conducted on SA-1B and KITTI datasets, we find that SAM exhibits remarkable robustness against various corruptions, except for blur-related corruption. Furthermore, SAM remains susceptible to adversarial attacks, particularly when subjected to PGD and BIM attacks. We think such a comprehensive study could highlight the importance of the robustness issues of SAM and trigger a series of new tasks for SAM as well as downstream vision tasks.
When SAM Meets Medical Images: An Investigation of Segment Anything Model (SAM) on Multi-phase Liver Tumor Segmentation
Apr 17, 2023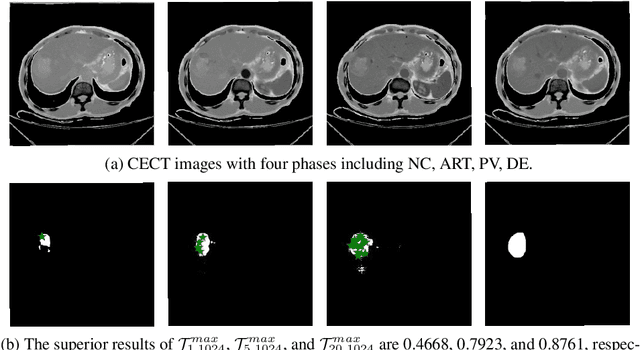
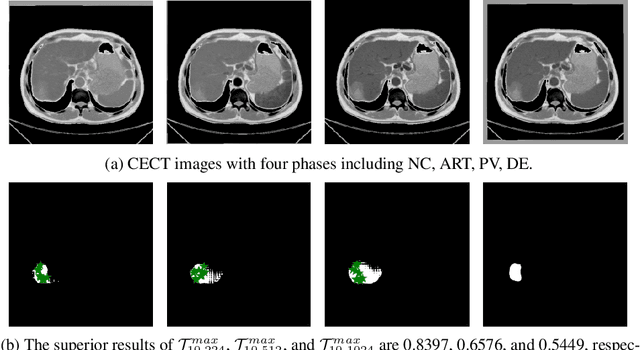
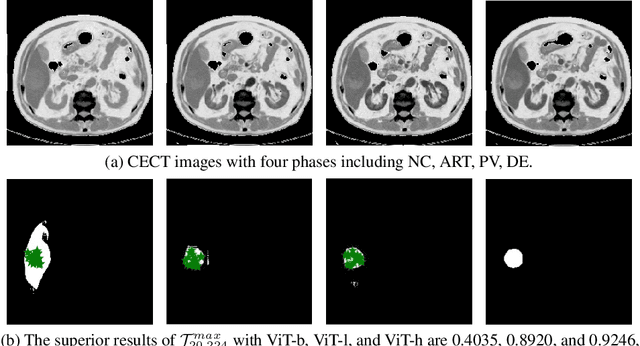
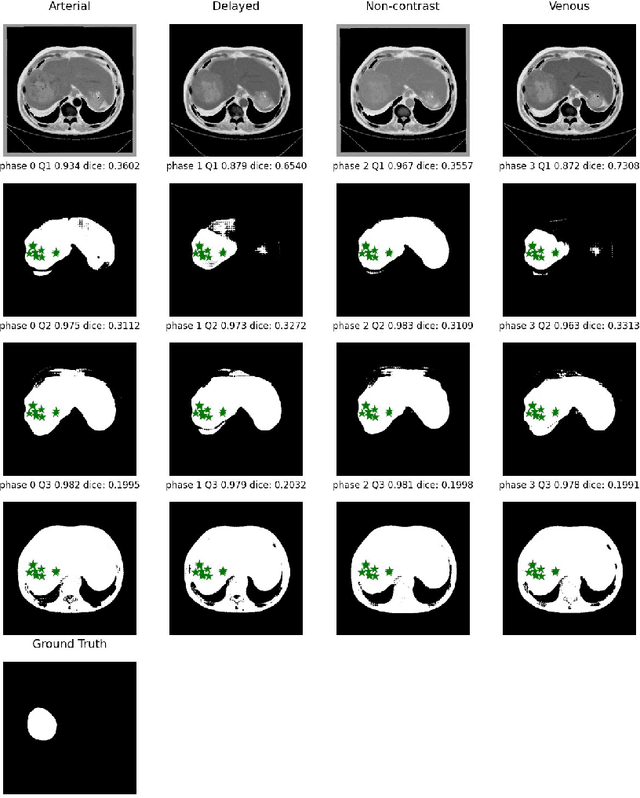
Learning to segmentation without large-scale samples is an inherent capability of human. Recently, Segment Anything Model (SAM) performs the significant zero-shot image segmentation, attracting considerable attention from the computer vision community. Here, we investigate the capability of SAM for medical image analysis, especially for multi-phase liver tumor segmentation (MPLiTS), in terms of prompts, data resolution, phases. Experimental results demonstrate that there might be a large gap between SAM and expected performance. Fortunately, the qualitative results show that SAM is a powerful annotation tool for the community of interactive medical image segmentation.
A Plug-and-Play Defensive Perturbation for Copyright Protection of DNN-based Applications
Apr 20, 2023

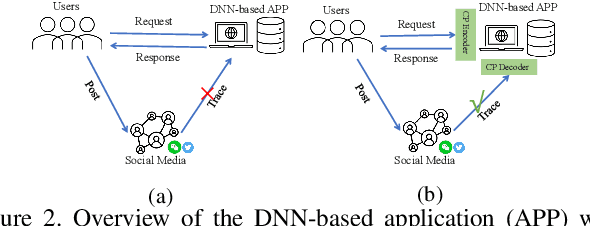

Wide deployment of deep neural networks (DNNs) based applications (e.g., style transfer, cartoonish), stimulating the requirement of copyright protection of such application's production. Although some traditional visible copyright techniques are available, they would introduce undesired traces and result in a poor user experience. In this paper, we propose a novel plug-and-play invisible copyright protection method based on defensive perturbation for DNN-based applications (i.e., style transfer). Rather than apply the perturbation to attack the DNNs model, we explore the potential utilization of perturbation in copyright protection. Specifically, we project the copyright information to the defensive perturbation with the designed copyright encoder, which is added to the image to be protected. Then, we extract the copyright information from the encoded copyrighted image with the devised copyright decoder. Furthermore, we use a robustness module to strengthen the decoding capability of the decoder toward images with various distortions (e.g., JPEG compression), which may be occurred when the user posts the image on social media. To ensure the image quality of encoded images and decoded copyright images, a loss function was elaborately devised. Objective and subjective experiment results demonstrate the effectiveness of the proposed method. We have also conducted physical world tests on social media (i.e., Wechat and Twitter) by posting encoded copyright images. The results show that the copyright information in the encoded image saved from social media can still be correctly extracted.
Zero-shot Visual Relation Detection via Composite Visual Cues from Large Language Models
May 21, 2023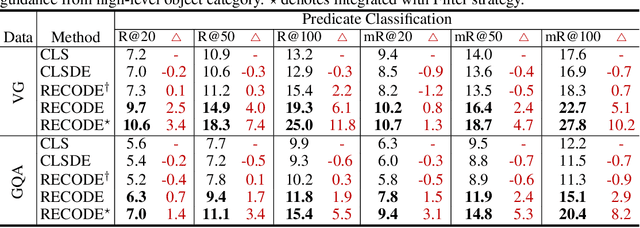
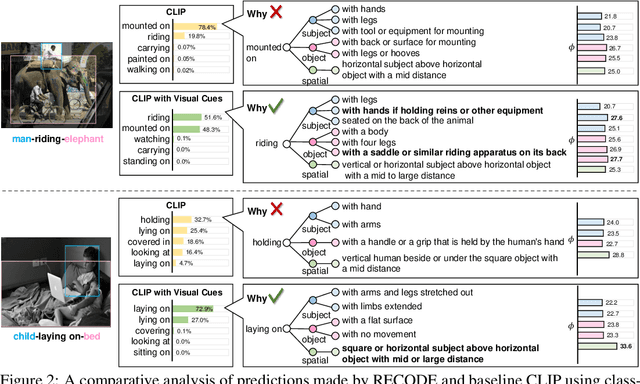
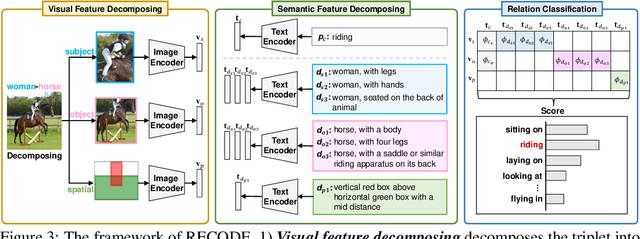
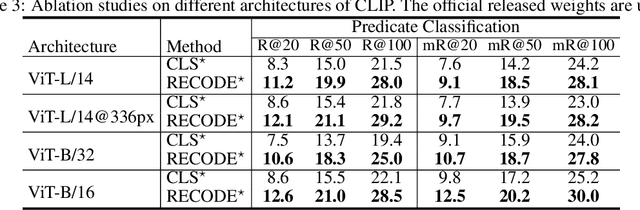
Pretrained vision-language models, such as CLIP, have demonstrated strong generalization capabilities, making them promising tools in the realm of zero-shot visual recognition. Visual relation detection (VRD) is a typical task that identifies relationship (or interaction) types between object pairs within an image. However, naively utilizing CLIP with prevalent class-based prompts for zero-shot VRD has several weaknesses, e.g., it struggles to distinguish between different fine-grained relation types and it neglects essential spatial information of two objects. To this end, we propose a novel method for zero-shot VRD: RECODE, which solves RElation detection via COmposite DEscription prompts. Specifically, RECODE first decomposes each predicate category into subject, object, and spatial components. Then, it leverages large language models (LLMs) to generate description-based prompts (or visual cues) for each component. Different visual cues enhance the discriminability of similar relation categories from different perspectives, which significantly boosts performance in VRD. To dynamically fuse different cues, we further introduce a chain-of-thought method that prompts LLMs to generate reasonable weights for different visual cues. Extensive experiments on four VRD benchmarks have demonstrated the effectiveness and interpretability of RECODE.
Multispectral Image Compression Based on HEVC Using Pel-Recursive Inter-Band Prediction
Mar 09, 2023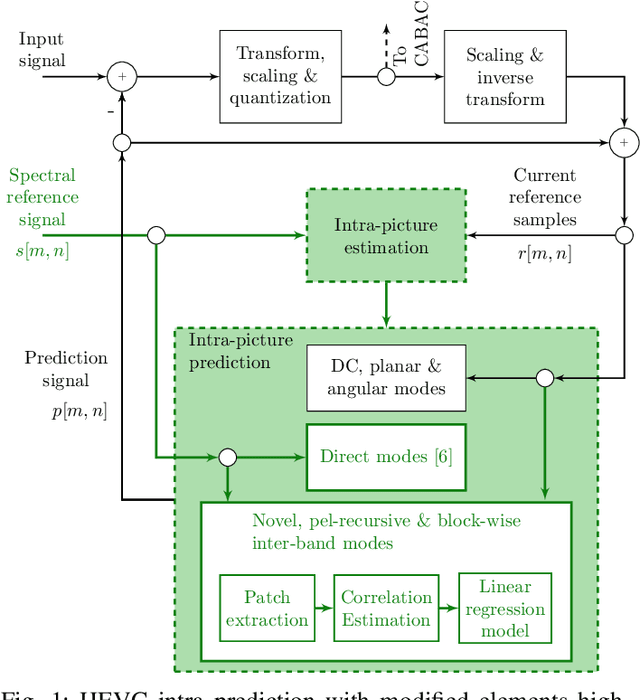
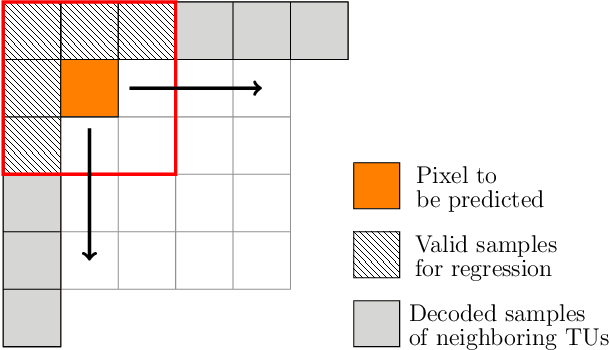
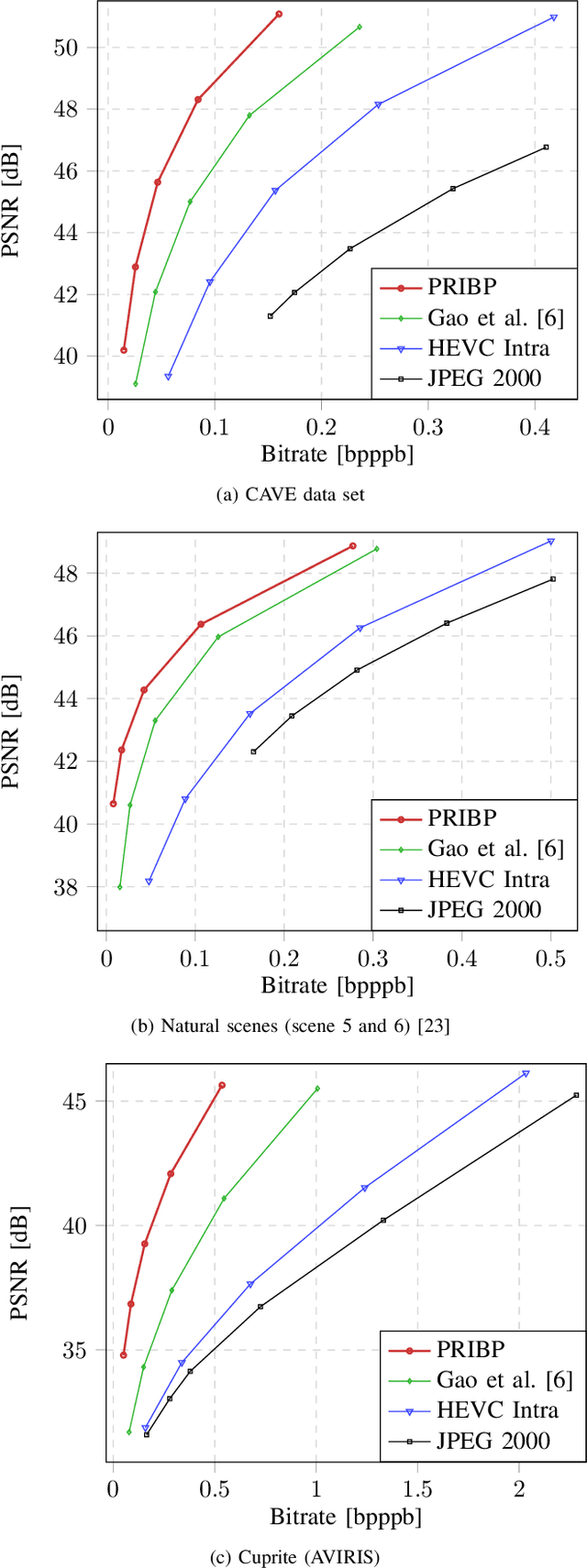

Recent developments in optical sensors enable a wide range of applications for multispectral imaging, e.g., in surveillance, optical sorting, and life-science instrumentation. Increasing spatial and spectral resolution allows creating higher quality products, however, it poses challenges in handling such large amounts of data. Consequently, specialized compression techniques for multispectral images are required. High Efficiency Video Coding (HEVC) is known to be the state of the art in efficiency for both video coding and still image coding. In this paper, we propose a cross-spectral compression scheme for efficiently coding multispectral data based on HEVC. Extending intra picture prediction by a novel inter-band predictor, spectral as well as spatial redundancies can be effectively exploited. Dependencies among the current band and further spectral references are considered jointly by adaptive linear regression modeling. The proposed backward prediction scheme does not require additional side information for decoding. We show that our novel approach is able to outperform state-of-the-art lossy compression techniques in terms of rate-distortion performance. On different data sets, average Bj{\o}ntegaard delta rate savings of 82 % and 55 % compared to HEVC and a reference method from literature are achieved, respectively.
* 6 pages, 4 figures, 1 table; Originally published as conference paper at IEEE MMSP 2020
Generative AI: Implications and Applications for Education
May 15, 2023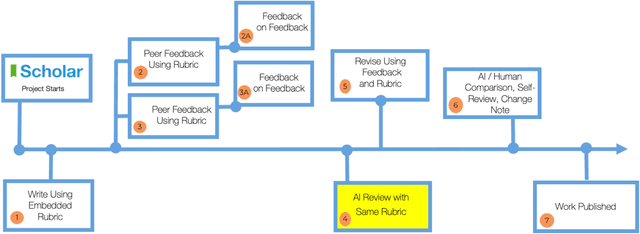
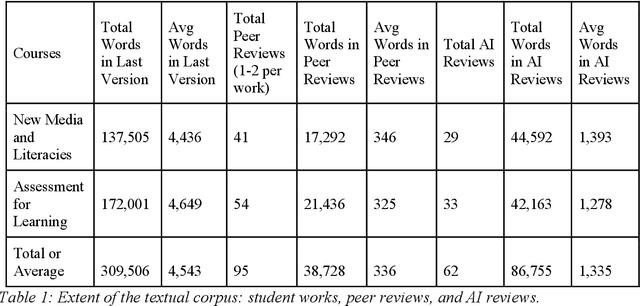
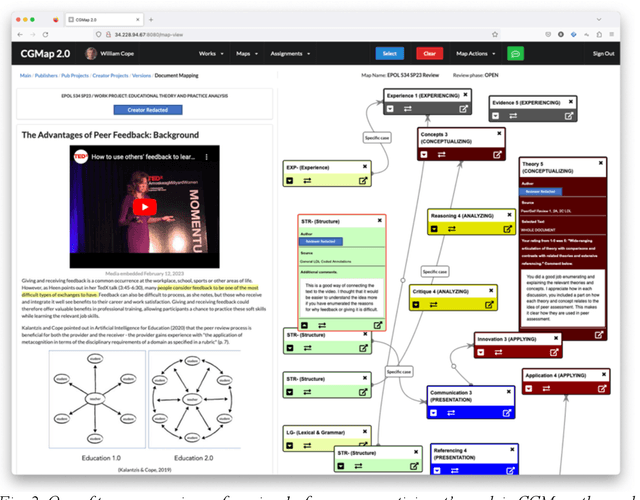
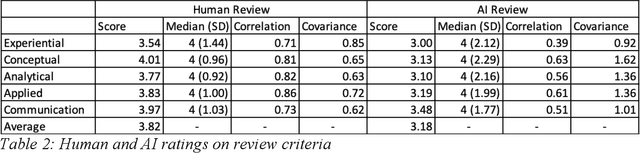
The launch of ChatGPT in November 2022 precipitated a panic among some educators while prompting qualified enthusiasm from others. Under the umbrella term Generative AI, ChatGPT is an example of a range of technologies for the delivery of computer-generated text, image, and other digitized media. This paper examines the implications for education of one generative AI technology, chatbots responding from large language models, or C-LLM. It reports on an application of a C-LLM to AI review and assessment of complex student work. In a concluding discussion, the paper explores the intrinsic limits of generative AI, bound as it is to language corpora and their textual representation through binary notation. Within these limits, we suggest the range of emerging and potential applications of Generative AI in education.