 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Edge Enhanced Image Style Transfer via Transformers
Jan 02, 2023


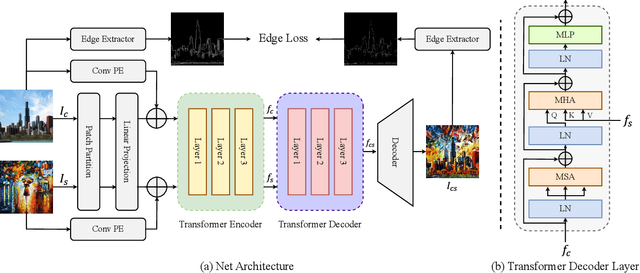
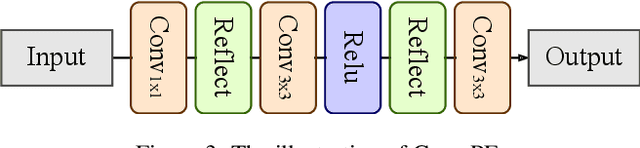
In recent years, arbitrary image style transfer has attracted more and more attention. Given a pair of content and style images, a stylized one is hoped that retains the content from the former while catching style patterns from the latter. However, it is difficult to simultaneously keep well the trade-off between the content details and the style features. To stylize the image with sufficient style patterns, the content details may be damaged and sometimes the objects of images can not be distinguished clearly. For this reason, we present a new transformer-based method named STT for image style transfer and an edge loss which can enhance the content details apparently to avoid generating blurred results for excessive rendering on style features. Qualitative and quantitative experiments demonstrate that STT achieves comparable performance to state-of-the-art image style transfer methods while alleviating the content leak problem.
Exploring Transformer Backbones for Image Diffusion Models
Dec 27, 2022
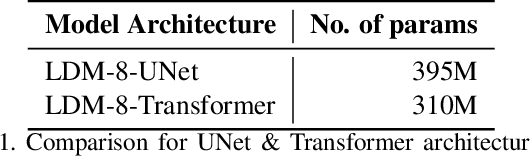
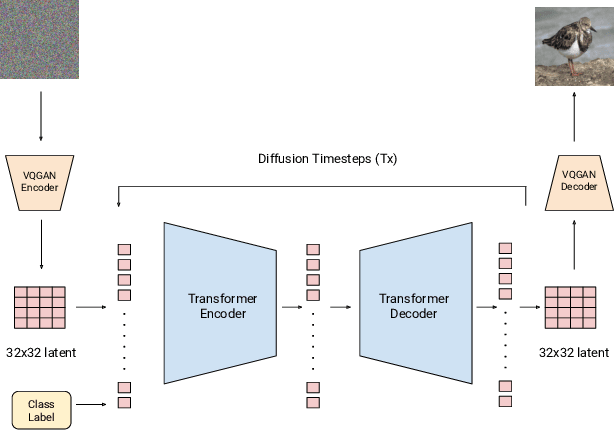
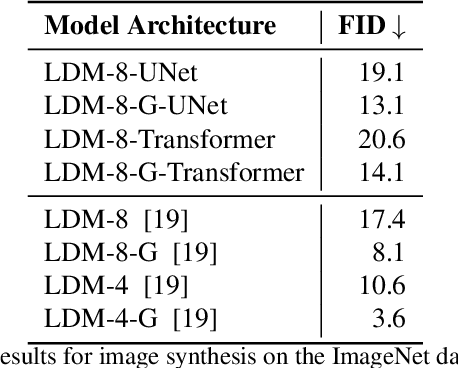
We present an end-to-end Transformer based Latent Diffusion model for image synthesis. On the ImageNet class conditioned generation task we show that a Transformer based Latent Diffusion model achieves a 14.1FID which is comparable to the 13.1FID score of a UNet based architecture. In addition to showing the application of Transformer models for Diffusion based image synthesis this simplification in architecture allows easy fusion and modeling of text and image data. The multi-head attention mechanism of Transformers enables simplified interaction between the image and text features which removes the requirement for crossattention mechanism in UNet based Diffusion models.
Graph Neural Network for Accurate and Low-complexity SAR ATR
May 11, 2023
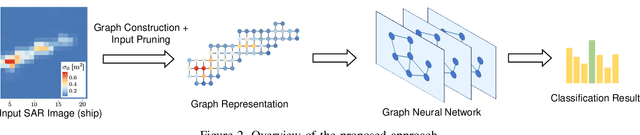
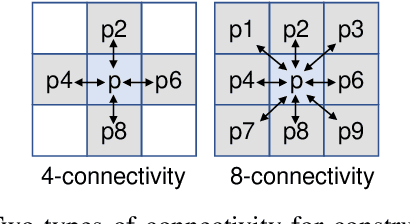
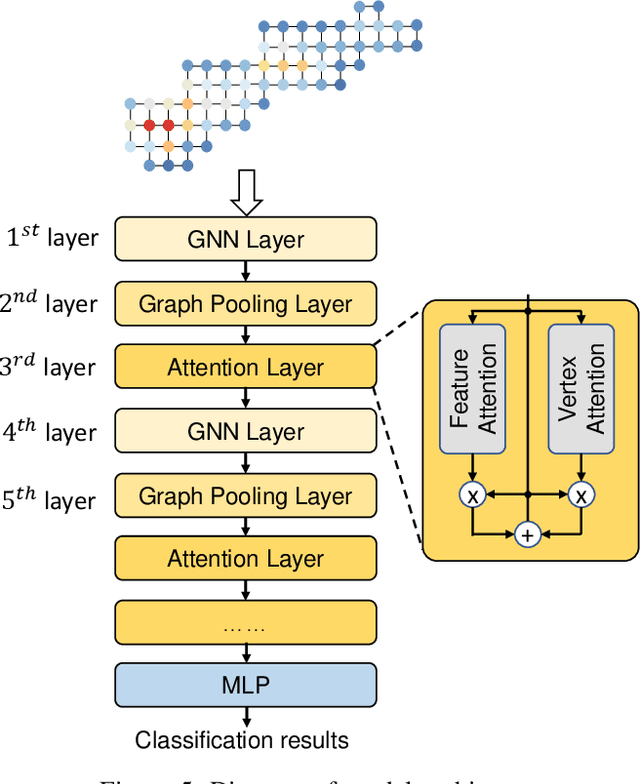
Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) is the key technique for remote sensing image recognition. The state-of-the-art works exploit the deep convolutional neural networks (CNNs) for SAR ATR, leading to high computation costs. These deep CNN models are unsuitable to be deployed on resource-limited platforms. In this work, we propose a graph neural network (GNN) model to achieve accurate and low-latency SAR ATR. We transform the input SAR image into the graph representation. The proposed GNN model consists of a stack of GNN layers that operates on the input graph to perform target classification. Unlike the state-of-the-art CNNs, which need heavy convolution operations, the proposed GNN model has low computation complexity and achieves comparable high accuracy. The GNN-based approach enables our proposed \emph{input pruning} strategy. By filtering out the irrelevant vertices in the input graph, we can reduce the computation complexity. Moreover, we propose the \emph{model pruning} strategy to sparsify the model weight matrices which further reduces the computation complexity. We evaluate the proposed GNN model on the MSTAR dataset and ship discrimination dataset. The evaluation results show that the proposed GNN model achieves 99.38\% and 99.7\% classification accuracy on the above two datasets, respectively. The proposed pruning strategies can prune 98.6\% input vertices and 97\% weight entries with negligible accuracy loss. Compared with the state-of-the-art CNNs, the proposed GNN model has only 1/3000 computation cost and 1/80 model size.
Critical heat flux diagnosis using conditional generative adversarial networks
May 04, 2023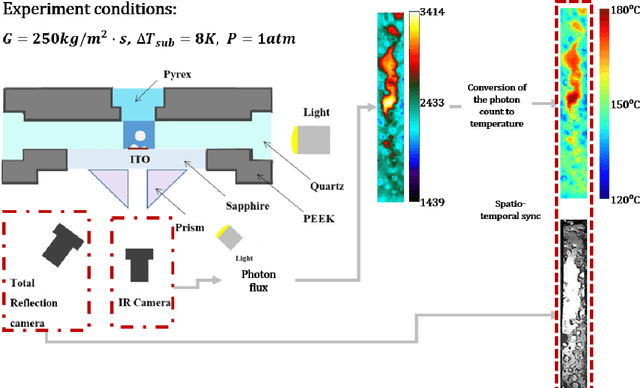
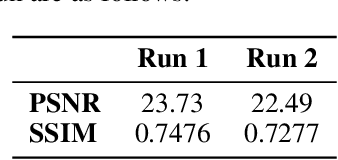
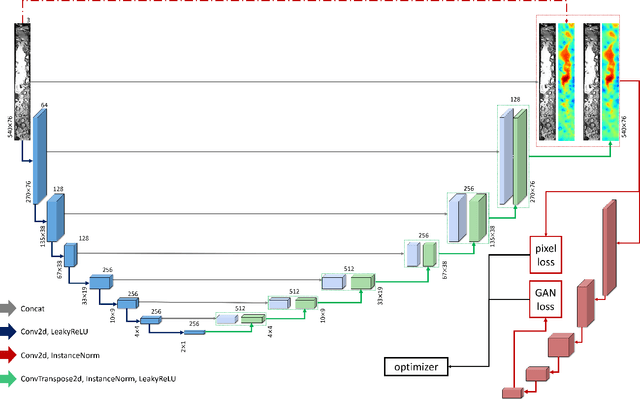

The critical heat flux (CHF) is an essential safety boundary in boiling heat transfer processes employed in high heat flux thermal-hydraulic systems. Identifying CHF is vital for preventing equipment damage and ensuring overall system safety, yet it is challenging due to the complexity of the phenomena. For an in-depth understanding of the complicated phenomena, various methodologies have been devised, but the acquisition of high-resolution data is limited by the substantial resource consumption required. This study presents a data-driven, image-to-image translation method for reconstructing thermal data of a boiling system at CHF using conditional generative adversarial networks (cGANs). The supervised learning process relies on paired images, which include total reflection visualizations and infrared thermometry measurements obtained from flow boiling experiments. Our proposed approach has the potential to not only provide evidence connecting phase interface dynamics with thermal distribution but also to simplify the laborious and time-consuming experimental setup and data-reduction procedures associated with infrared thermal imaging, thereby providing an effective solution for CHF diagnosis.
HARD: Hard Augmentations for Robust Distillation
May 24, 2023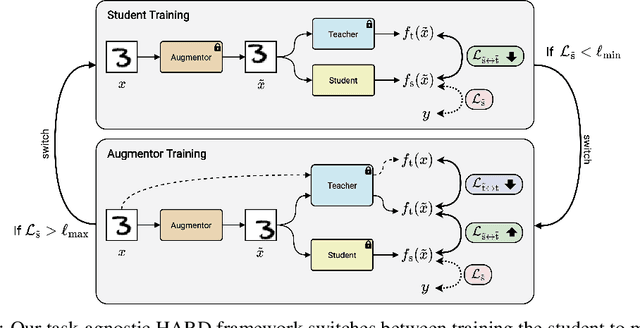
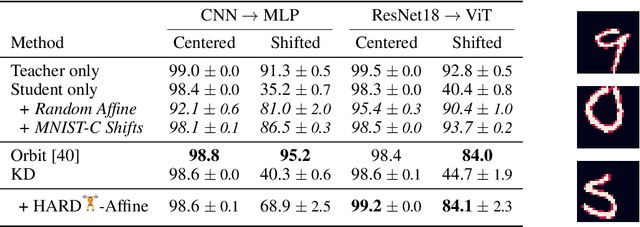
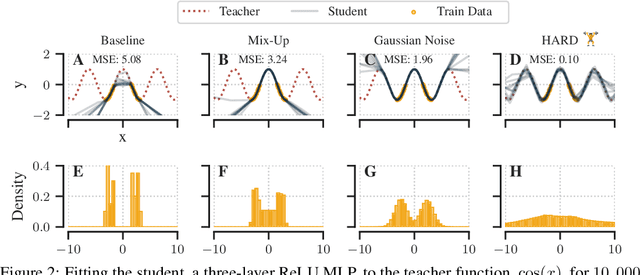
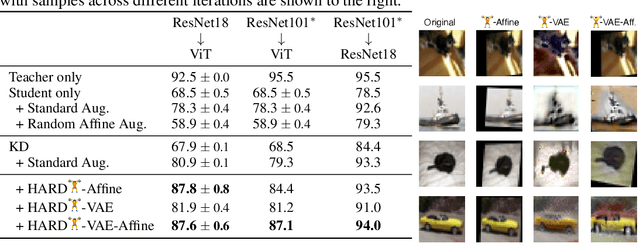
Knowledge distillation (KD) is a simple and successful method to transfer knowledge from a teacher to a student model solely based on functional activity. However, current KD has a few shortcomings: it has recently been shown that this method is unsuitable to transfer simple inductive biases like shift equivariance, struggles to transfer out of domain generalization, and optimization time is magnitudes longer compared to default non-KD model training. To improve these aspects of KD, we propose Hard Augmentations for Robust Distillation (HARD), a generally applicable data augmentation framework, that generates synthetic data points for which the teacher and the student disagree. We show in a simple toy example that our augmentation framework solves the problem of transferring simple equivariances with KD. We then apply our framework in real-world tasks for a variety of augmentation models, ranging from simple spatial transformations to unconstrained image manipulations with a pretrained variational autoencoder. We find that our learned augmentations significantly improve KD performance on in-domain and out-of-domain evaluation. Moreover, our method outperforms even state-of-the-art data augmentations and since the augmented training inputs can be visualized, they offer a qualitative insight into the properties that are transferred from the teacher to the student. Thus HARD represents a generally applicable, dynamically optimized data augmentation technique tailored to improve the generalization and convergence speed of models trained with KD.
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
Apr 18, 2023
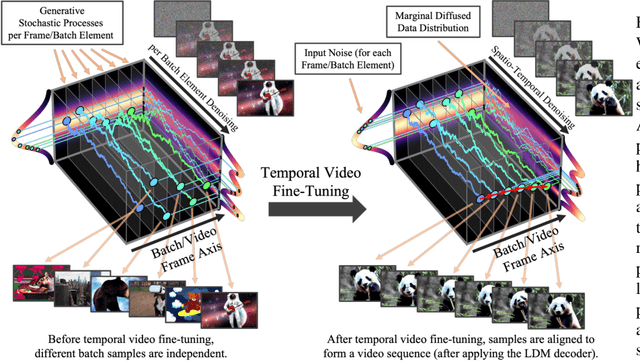

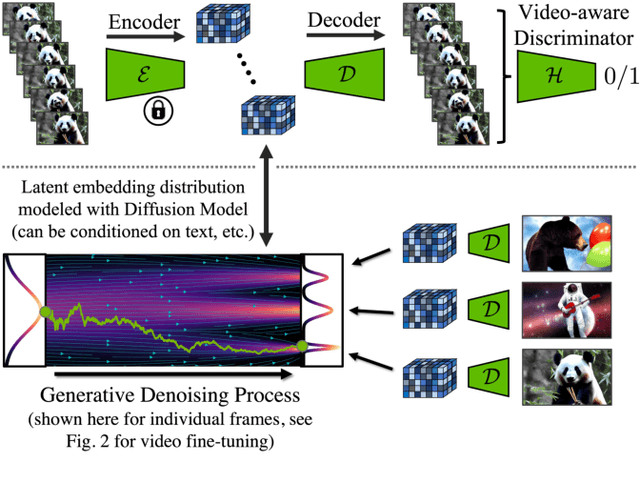
Latent Diffusion Models (LDMs) enable high-quality image synthesis while avoiding excessive compute demands by training a diffusion model in a compressed lower-dimensional latent space. Here, we apply the LDM paradigm to high-resolution video generation, a particularly resource-intensive task. We first pre-train an LDM on images only; then, we turn the image generator into a video generator by introducing a temporal dimension to the latent space diffusion model and fine-tuning on encoded image sequences, i.e., videos. Similarly, we temporally align diffusion model upsamplers, turning them into temporally consistent video super resolution models. We focus on two relevant real-world applications: Simulation of in-the-wild driving data and creative content creation with text-to-video modeling. In particular, we validate our Video LDM on real driving videos of resolution 512 x 1024, achieving state-of-the-art performance. Furthermore, our approach can easily leverage off-the-shelf pre-trained image LDMs, as we only need to train a temporal alignment model in that case. Doing so, we turn the publicly available, state-of-the-art text-to-image LDM Stable Diffusion into an efficient and expressive text-to-video model with resolution up to 1280 x 2048. We show that the temporal layers trained in this way generalize to different fine-tuned text-to-image LDMs. Utilizing this property, we show the first results for personalized text-to-video generation, opening exciting directions for future content creation. Project page: https://research.nvidia.com/labs/toronto-ai/VideoLDM/
Unsupervised Synthetic Image Refinement via Contrastive Learning and Consistent Semantic-Structural Constraints
Apr 26, 2023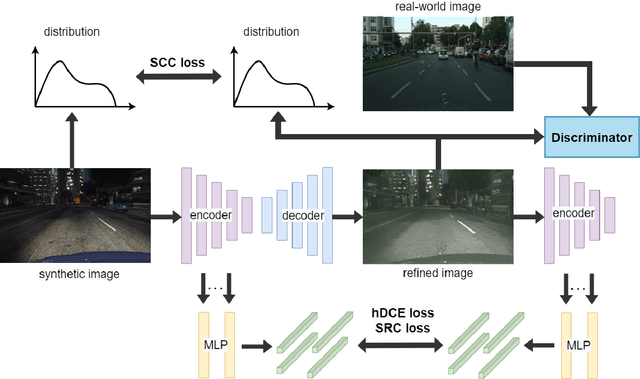
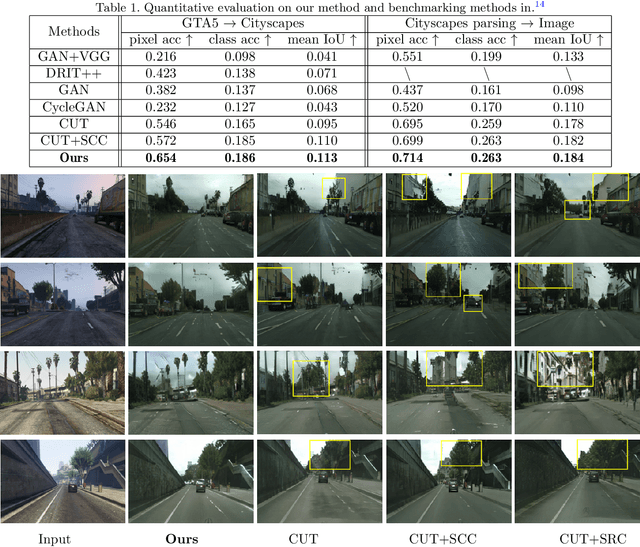
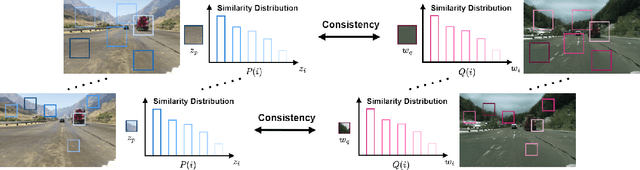

Ensuring the realism of computer-generated synthetic images is crucial to deep neural network (DNN) training. Due to different semantic distributions between synthetic and real-world captured datasets, there exists semantic mismatch between synthetic and refined images, which in turn results in the semantic distortion. Recently, contrastive learning (CL) has been successfully used to pull correlated patches together and push uncorrelated ones apart. In this work, we exploit semantic and structural consistency between synthetic and refined images and adopt CL to reduce the semantic distortion. Besides, we incorporate hard negative mining to improve the performance furthermore. We compare the performance of our method with several other benchmarking methods using qualitative and quantitative measures and show that our method offers the state-of-the-art performance.
Controllable Mind Visual Diffusion Model
May 18, 2023

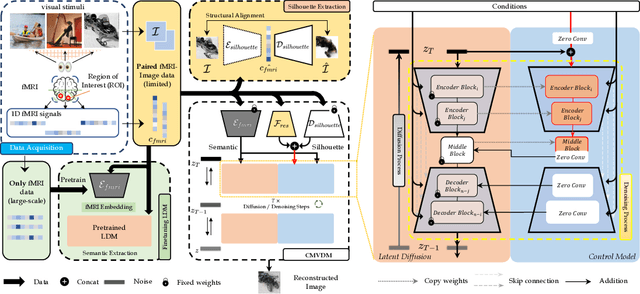

Brain signal visualization has emerged as an active research area, serving as a critical interface between the human visual system and computer vision models. Although diffusion models have shown promise in analyzing functional magnetic resonance imaging (fMRI) data, including reconstructing high-quality images consistent with original visual stimuli, their accuracy in extracting semantic and silhouette information from brain signals remains limited. In this regard, we propose a novel approach, referred to as Controllable Mind Visual Diffusion Model (CMVDM). CMVDM extracts semantic and silhouette information from fMRI data using attribute alignment and assistant networks. Additionally, a residual block is incorporated to capture information beyond semantic and silhouette features. We then leverage a control model to fully exploit the extracted information for image synthesis, resulting in generated images that closely resemble the visual stimuli in terms of semantics and silhouette. Through extensive experimentation, we demonstrate that CMVDM outperforms existing state-of-the-art methods both qualitatively and quantitatively.
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture
May 18, 2023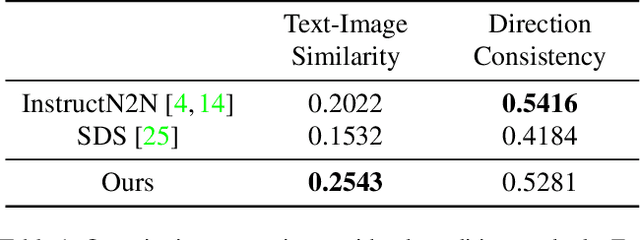
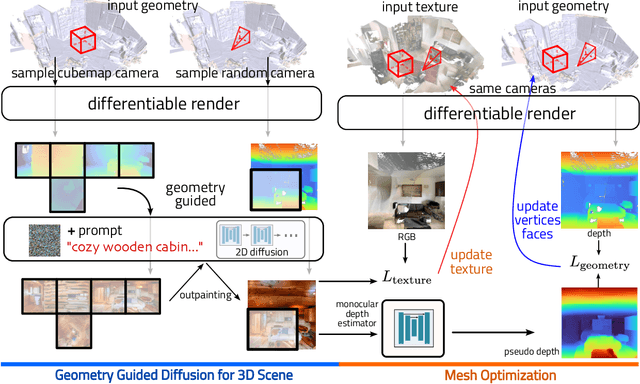
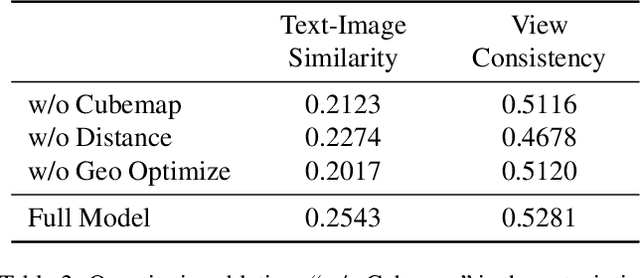
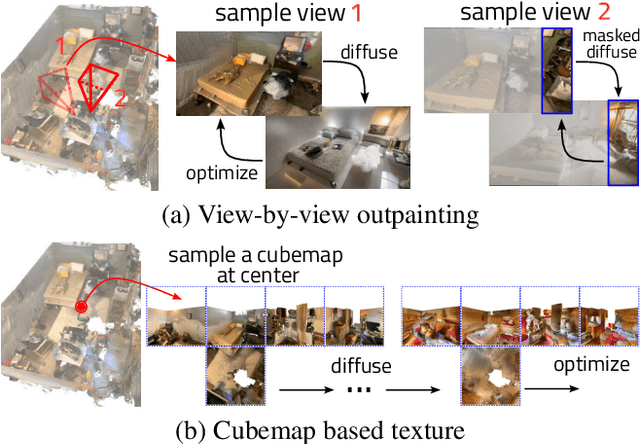
The techniques for 3D indoor scene capturing are widely used, but the meshes produced leave much to be desired. In this paper, we propose "RoomDreamer", which leverages powerful natural language to synthesize a new room with a different style. Unlike existing image synthesis methods, our work addresses the challenge of synthesizing both geometry and texture aligned to the input scene structure and prompt simultaneously. The key insight is that a scene should be treated as a whole, taking into account both scene texture and geometry. The proposed framework consists of two significant components: Geometry Guided Diffusion and Mesh Optimization. Geometry Guided Diffusion for 3D Scene guarantees the consistency of the scene style by applying the 2D prior to the entire scene simultaneously. Mesh Optimization improves the geometry and texture jointly and eliminates the artifacts in the scanned scene. To validate the proposed method, real indoor scenes scanned with smartphones are used for extensive experiments, through which the effectiveness of our method is demonstrated.
Improving Transformer-based Image Matching by Cascaded Capturing Spatially Informative Keypoints
Mar 06, 2023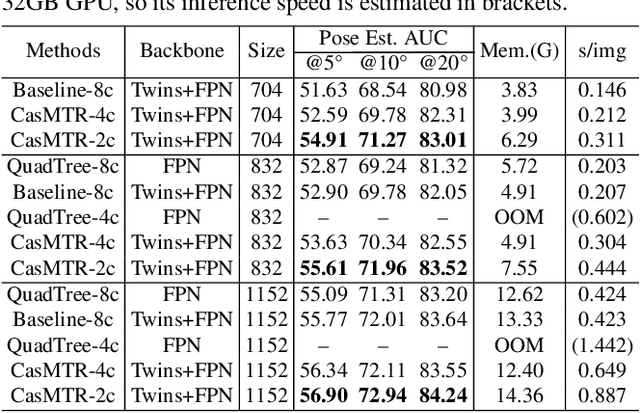

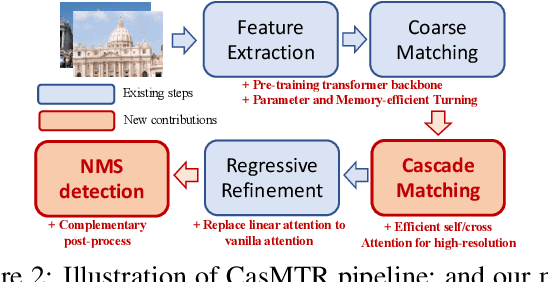
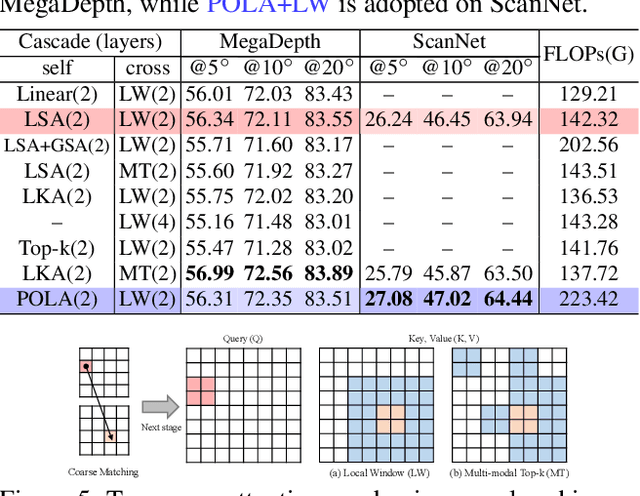
Learning robust local image feature matching is a fundamental low-level vision task, which has been widely explored in the past few years. Recently, detector-free local feature matchers based on transformers have shown promising results, which largely outperform pure Convolutional Neural Network (CNN) based ones. But correlations produced by transformer-based methods are spatially limited to the center of source views' coarse patches, because of the costly attention learning. In this work, we rethink this issue and find that such matching formulation degrades pose estimation, especially for low-resolution images. So we propose a transformer-based cascade matching model -- Cascade feature Matching TRansformer (CasMTR), to efficiently learn dense feature correlations, which allows us to choose more reliable matching pairs for the relative pose estimation. Instead of re-training a new detector, we use a simple yet effective Non-Maximum Suppression (NMS) post-process to filter keypoints through the confidence map, and largely improve the matching precision. CasMTR achieves state-of-the-art performance in indoor and outdoor pose estimation as well as visual localization. Moreover, thorough ablations show the efficacy of the proposed components and techniques.