 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning for Retrospective Motion Correction in MRI: A Comprehensive Review
May 11, 2023
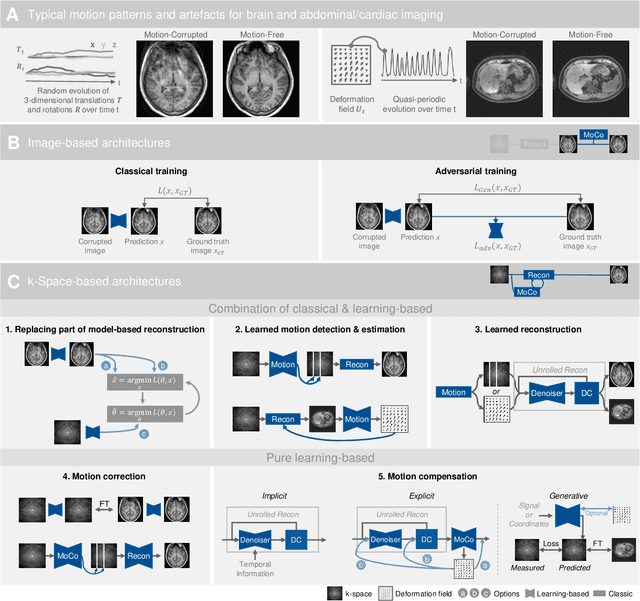
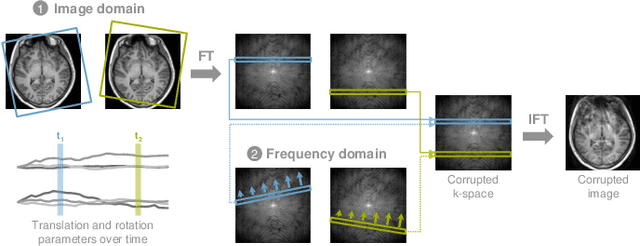

Motion represents one of the major challenges in magnetic resonance imaging (MRI). Since the MR signal is acquired in frequency space, any motion of the imaged object leads to complex artefacts in the reconstructed image in addition to other MR imaging artefacts. Deep learning has been frequently proposed for motion correction at several stages of the reconstruction process. The wide range of MR acquisition sequences, anatomies and pathologies of interest, and motion patterns (rigid vs. deformable and random vs. regular) makes a comprehensive solution unlikely. To facilitate the transfer of ideas between different applications, this review provides a detailed overview of proposed methods for learning-based motion correction in MRI together with their common challenges and potentials. This review identifies differences and synergies in underlying data usage, architectures and evaluation strategies. We critically discuss general trends and outline future directions, with the aim to enhance interaction between different application areas and research fields.
DarkVision: A Benchmark for Low-light Image/Video Perception
Jan 16, 2023
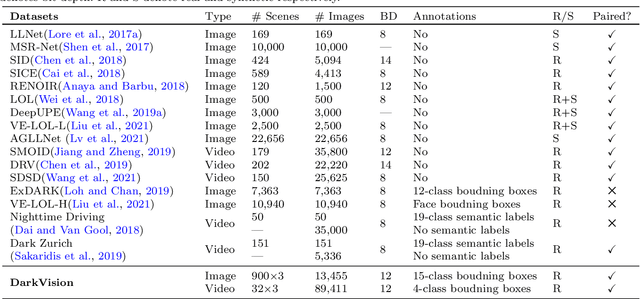


Imaging and perception in photon-limited scenarios is necessary for various applications, e.g., night surveillance or photography, high-speed photography, and autonomous driving. In these cases, cameras suffer from low signal-to-noise ratio, which degrades the image quality severely and poses challenges for downstream high-level vision tasks like object detection and recognition. Data-driven methods have achieved enormous success in both image restoration and high-level vision tasks. However, the lack of high-quality benchmark dataset with task-specific accurate annotations for photon-limited images/videos delays the research progress heavily. In this paper, we contribute the first multi-illuminance, multi-camera, and low-light dataset, named DarkVision, serving for both image enhancement and object detection. We provide bright and dark pairs with pixel-wise registration, in which the bright counterpart provides reliable reference for restoration and annotation. The dataset consists of bright-dark pairs of 900 static scenes with objects from 15 categories, and 32 dynamic scenes with 4-category objects. For each scene, images/videos were captured at 5 illuminance levels using three cameras of different grades, and average photons can be reliably estimated from the calibration data for quantitative studies. The static-scene images and dynamic videos respectively contain around 7,344 and 320,667 instances in total. With DarkVision, we established baselines for image/video enhancement and object detection by representative algorithms. To demonstrate an exemplary application of DarkVision, we propose two simple yet effective approaches for improving performance in video enhancement and object detection respectively. We believe DarkVision would advance the state-of-the-arts in both imaging and related computer vision tasks in low-light environment.
Frequency-Supported Neural Networks for Nonlinear Dynamical System Identification
May 10, 2023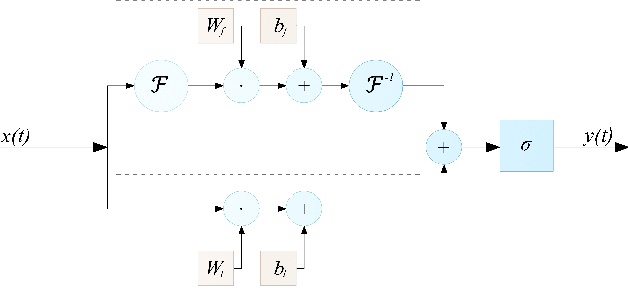
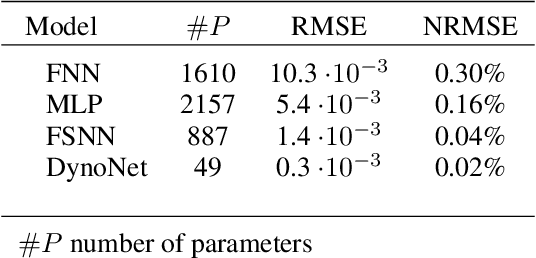
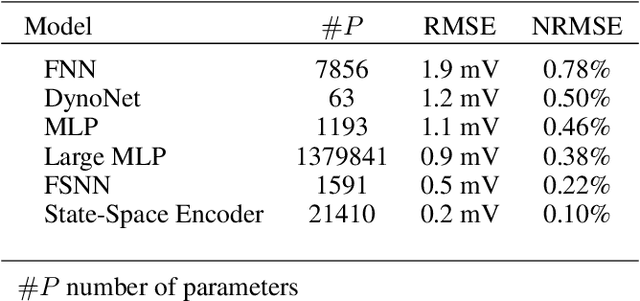
Neural networks are a very general type of model capable of learning various relationships between multiple variables. One example of such relationships, particularly interesting in practice, is the input-output relation of nonlinear systems, which has a multitude of applications. Studying models capable of estimating such relation is a broad discipline with numerous theoretical and practical results. Neural networks are very general, but multiple special cases exist, including convolutional neural networks and recurrent neural networks, which are adjusted for specific applications, which are image and sequence processing respectively. We formulate a hypothesis that adjusting general network structure by incorporating frequency information into it should result in a network specifically well suited to nonlinear system identification. Moreover, we show that it is possible to add this frequency information without the loss of generality from a theoretical perspective. We call this new structure Frequency-Supported Neural Network (FSNN) and empirically investigate its properties.
Inverse Quantum Fourier Transform Inspired Algorithm for Unsupervised Image Segmentation
Jan 11, 2023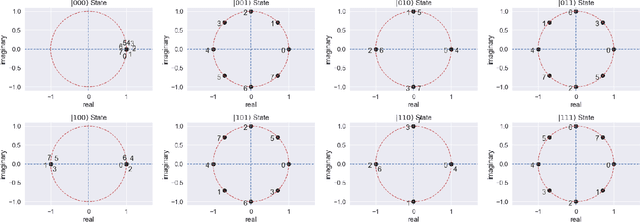

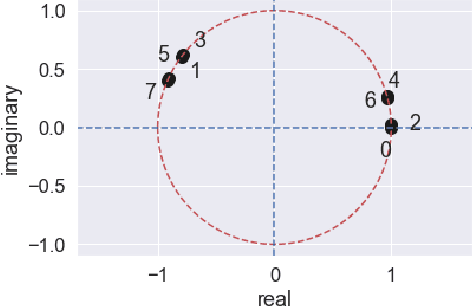
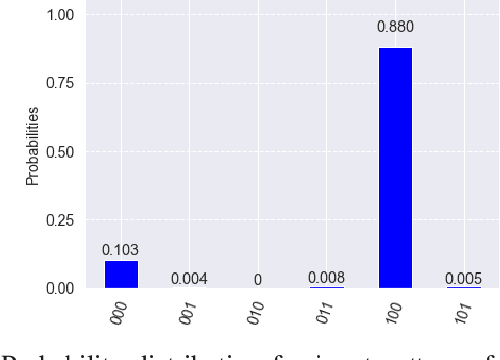
Image segmentation is a very popular and important task in computer vision. In this paper, inverse quantum Fourier transform (IQFT) for image segmentation has been explored and a novel IQFT-inspired algorithm is proposed and implemented by leveraging the underlying mathematical structure of the IQFT. Specifically, the proposed method takes advantage of the phase information of the pixels in the image by encoding the pixels' intensity into qubit relative phases and applying IQFT to classify the pixels into different segments automatically and efficiently. To the best of our knowledge, this is the first attempt of using IQFT for unsupervised image segmentation. The proposed method has low computational cost comparing to the deep learning-based methods and more importantly it does not require training, thus make it suitable for real-time applications. The performance of the proposed method is compared with K-means and Otsu-thresholding. The proposed method outperforms both of them on the PASCAL VOC 2012 segmentation benchmark and the xVIEW2 challenge dataset by as much as 50% in terms of mean Intersection-Over-Union (mIOU).
Vision Langauge Pre-training by Contrastive Learning with Cross-Modal Similarity Regulation
May 09, 2023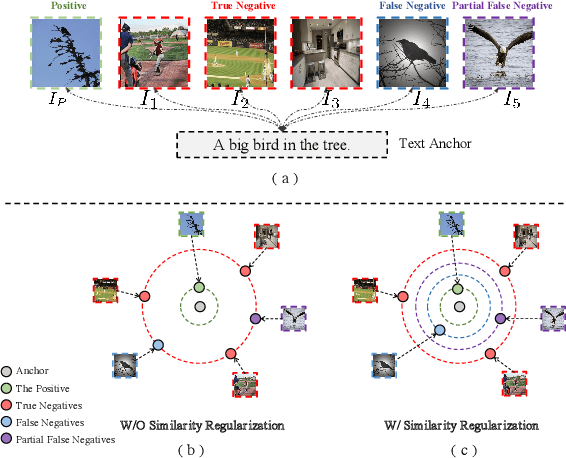
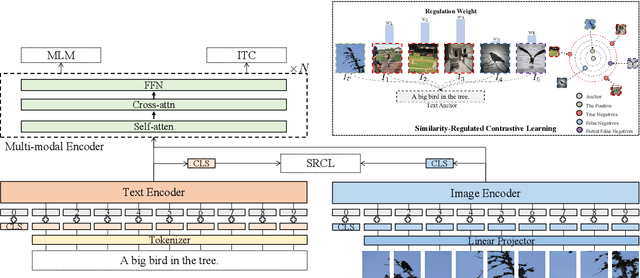
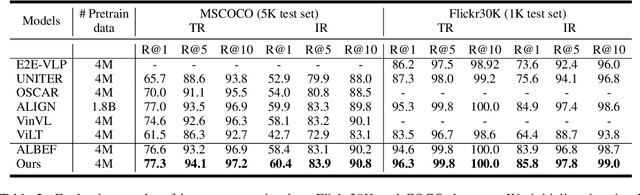
Cross-modal contrastive learning in vision language pretraining (VLP) faces the challenge of (partial) false negatives. In this paper, we study this problem from the perspective of Mutual Information (MI) optimization. It is common sense that InfoNCE loss used in contrastive learning will maximize the lower bound of MI between anchors and their positives, while we theoretically prove that MI involving negatives also matters when noises commonly exist. Guided by a more general lower bound form for optimization, we propose a contrastive learning strategy regulated by progressively refined cross-modal similarity, to more accurately optimize MI between an image/text anchor and its negative texts/images instead of improperly minimizing it. Our method performs competitively on four downstream cross-modal tasks and systematically balances the beneficial and harmful effects of (partial) false negative samples under theoretical guidance.
PhysBench: A Benchmark Framework for Remote Physiological Sensing with New Dataset and Baseline
May 07, 2023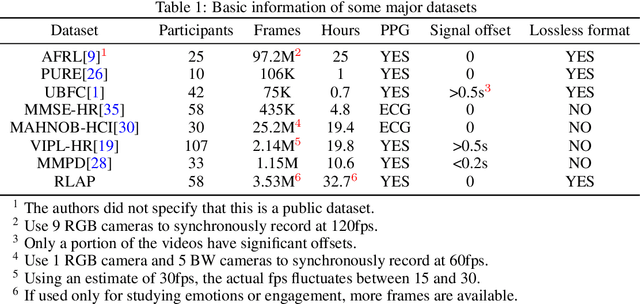
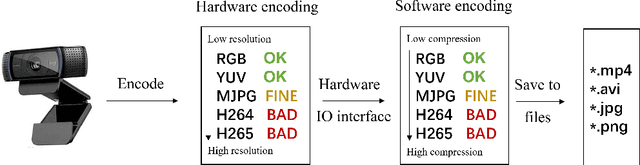
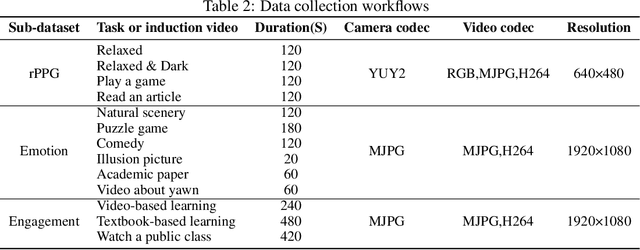

In recent years, due to the widespread use of internet videos, physiological remote sensing has gained more and more attention in the fields of affective computing and telemedicine. Recovering physiological signals from facial videos is a challenging task that involves a series of preprocessing, image algorithms, and post-processing to finally restore waveforms. We propose a complete and efficient end-to-end training and testing framework that provides fair comparisons for different algorithms through unified preprocessing and post-processing. In addition, we introduce a highly synchronized lossless format dataset along with a lightweight algorithm. The dataset contains over 32 hours (3.53M frames) of video from 58 subjects; by training on our collected dataset both our proposed algorithm as well as existing ones can achieve improvements.
Multi-spectral Class Center Network for Face Manipulation Detection and Localization
May 18, 2023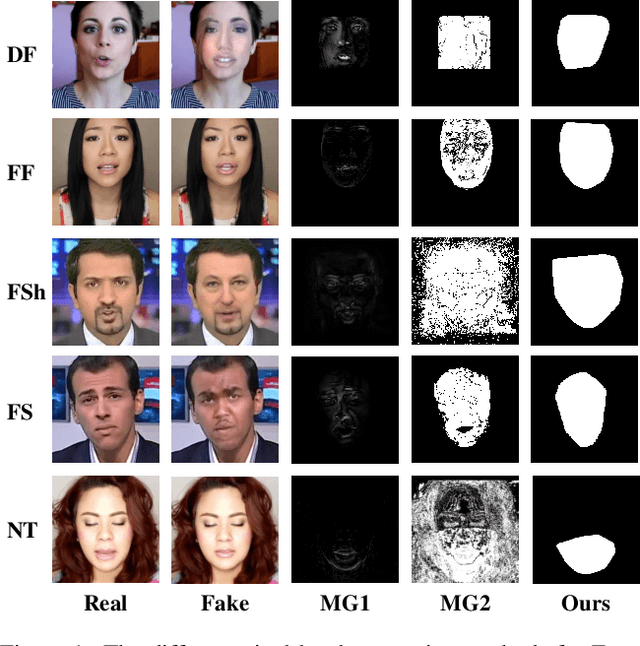
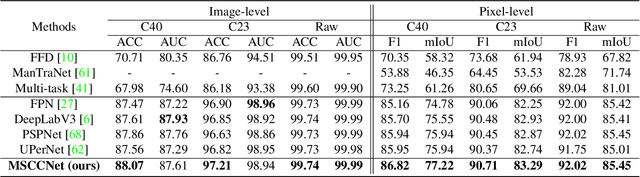
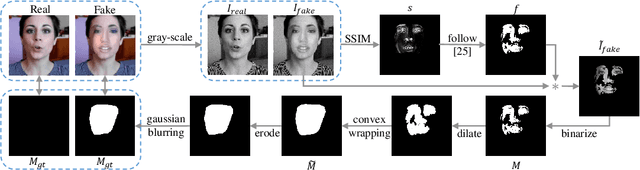

As Deepfake contents continue to proliferate on the internet, advancing face manipulation forensics has become a pressing issue. To combat this emerging threat, previous methods mainly focus on studying how to distinguish authentic and manipulated face images. Despite impressive, image-level classification lacks explainability and is limited to some specific application scenarios. Existing forgery localization methods suffer from imprecise and inconsistent pixel-level annotations. To alleviate these problems, this paper first re-constructs the FaceForensics++ dataset by introducing pixel-level annotations, then builds an extensive benchmark for localizing tampered regions. Next, a novel Multi-Spectral Class Center Network (MSCCNet) is proposed for face manipulation detection and localization. Specifically, inspired by the power of frequency-related forgery traces, we design Multi-Spectral Class Center (MSCC) module to learn more generalizable and semantic-agnostic features. Based on the features of different frequency bands, the MSCC module collects multispectral class centers and computes pixel-to-class relations. Applying multi-spectral class-level representations suppresses the semantic information of the visual concepts, which is insensitive to manipulations. Furthermore, we propose a Multi-level Features Aggregation (MFA) module to employ more low-level forgery artifacts and structure textures. Experimental results quantitatively and qualitatively indicate the effectiveness and superiority of the proposed MSCCNet on comprehensive localization benchmarks. We expect this work to inspire more studies on pixel-level face manipulation localization. The annotations and code will be available.
Parallel development of social preferences in fish and machines
May 18, 2023
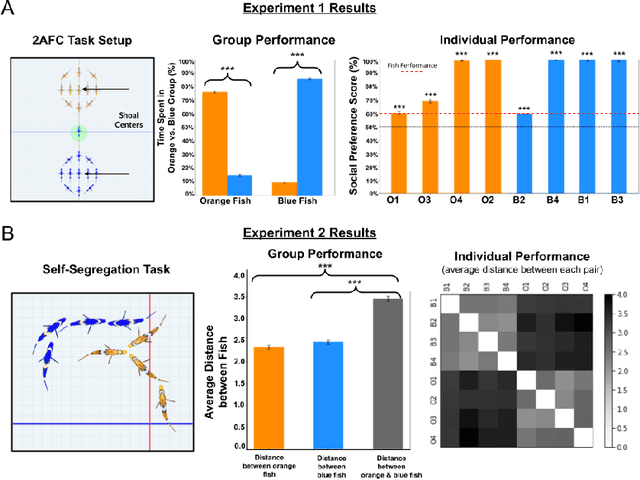
What are the computational foundations of social grouping? Traditional approaches to this question have focused on verbal reasoning or simple (low-dimensional) quantitative models. In the real world, however, social preferences emerge when high-dimensional learning systems (brains and bodies) interact with high-dimensional sensory inputs during an animal's embodied interactions with the world. A deep understanding of social grouping will therefore require embodied models that learn directly from sensory inputs using high-dimensional learning mechanisms. To this end, we built artificial neural networks (ANNs), embodied those ANNs in virtual fish bodies, and raised the artificial fish in virtual fish tanks that mimicked the rearing conditions of real fish. We then compared the social preferences that emerged in real fish versus artificial fish. We found that when artificial fish had two core learning mechanisms (reinforcement learning and curiosity-driven learning), artificial fish developed fish-like social preferences. Like real fish, the artificial fish spontaneously learned to prefer members of their own group over members of other groups. The artificial fish also spontaneously learned to self-segregate with their in-group, akin to self-segregation behavior seen in nature. Our results suggest that social grouping can emerge from three ingredients: (1) reinforcement learning, (2) intrinsic motivation, and (3) early social experiences with in-group members. This approach lays a foundation for reverse engineering animal-like social behavior with image-computable models, bridging the divide between high-dimensional sensory inputs and social preferences.
Improving 2D face recognition via fine-level facial depth generation and RGB-D complementary feature learning
May 08, 2023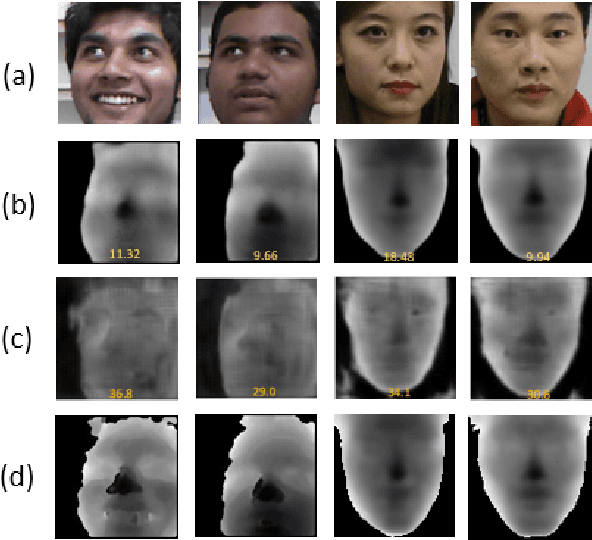

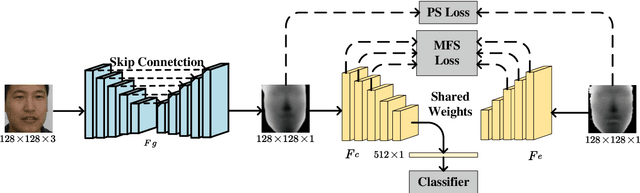

Face recognition in complex scenes suffers severe challenges coming from perturbations such as pose deformation, ill illumination, partial occlusion. Some methods utilize depth estimation to obtain depth corresponding to RGB to improve the accuracy of face recognition. However, the depth generated by them suffer from image blur, which introduces noise in subsequent RGB-D face recognition tasks. In addition, existing RGB-D face recognition methods are unable to fully extract complementary features. In this paper, we propose a fine-grained facial depth generation network and an improved multimodal complementary feature learning network. Extensive experiments on the Lock3DFace dataset and the IIIT-D dataset show that the proposed FFDGNet and I MCFLNet can improve the accuracy of RGB-D face recognition while achieving the state-of-the-art performance.
3DFill:Reference-guided Image Inpainting by Self-supervised 3D Image Alignment
Nov 09, 2022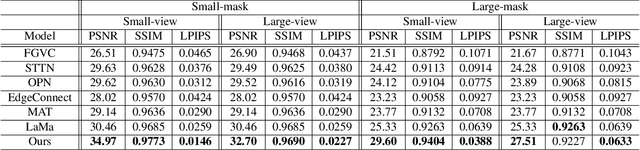
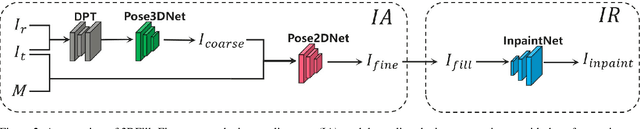
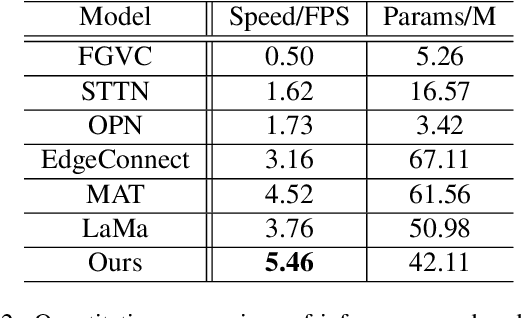
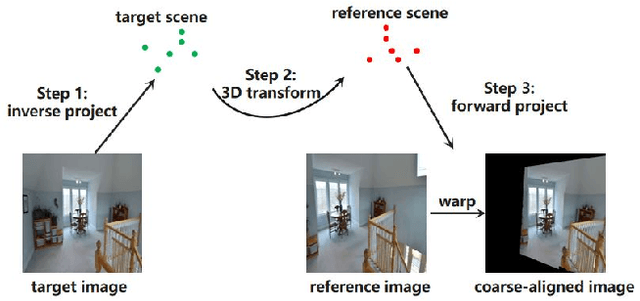
Most existing image inpainting algorithms are based on a single view, struggling with large holes or the holes containing complicated scenes. Some reference-guided algorithms fill the hole by referring to another viewpoint image and use 2D image alignment. Due to the camera imaging process, simple 2D transformation is difficult to achieve a satisfactory result. In this paper, we propose 3DFill, a simple and efficient method for reference-guided image inpainting. Given a target image with arbitrary hole regions and a reference image from another viewpoint, the 3DFill first aligns the two images by a two-stage method: 3D projection + 2D transformation, which has better results than 2D image alignment. The 3D projection is an overall alignment between images and the 2D transformation is a local alignment focused on the hole region. The entire process of image alignment is self-supervised. We then fill the hole in the target image with the contents of the aligned image. Finally, we use a conditional generation network to refine the filled image to obtain the inpainting result. 3DFill achieves state-of-the-art performance on image inpainting across a variety of wide view shifts and has a faster inference speed than other inpainting models.