 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not
Mar 24, 2023
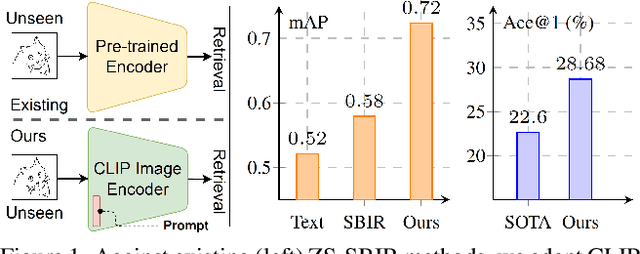
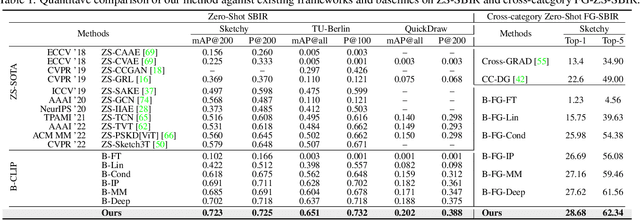

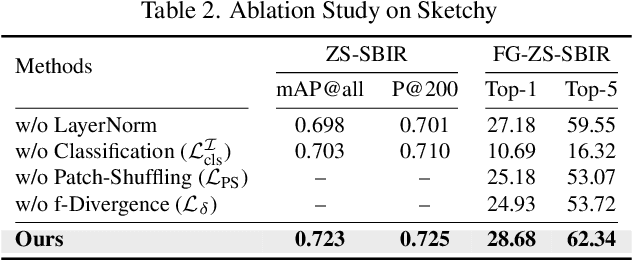
In this paper, we leverage CLIP for zero-shot sketch based image retrieval (ZS-SBIR). We are largely inspired by recent advances on foundation models and the unparalleled generalisation ability they seem to offer, but for the first time tailor it to benefit the sketch community. We put forward novel designs on how best to achieve this synergy, for both the category setting and the fine-grained setting ("all"). At the very core of our solution is a prompt learning setup. First we show just via factoring in sketch-specific prompts, we already have a category-level ZS-SBIR system that overshoots all prior arts, by a large margin (24.8%) - a great testimony on studying the CLIP and ZS-SBIR synergy. Moving onto the fine-grained setup is however trickier, and requires a deeper dive into this synergy. For that, we come up with two specific designs to tackle the fine-grained matching nature of the problem: (i) an additional regularisation loss to ensure the relative separation between sketches and photos is uniform across categories, which is not the case for the gold standard standalone triplet loss, and (ii) a clever patch shuffling technique to help establishing instance-level structural correspondences between sketch-photo pairs. With these designs, we again observe significant performance gains in the region of 26.9% over previous state-of-the-art. The take-home message, if any, is the proposed CLIP and prompt learning paradigm carries great promise in tackling other sketch-related tasks (not limited to ZS-SBIR) where data scarcity remains a great challenge. Project page: https://aneeshan95.github.io/Sketch_LVM/
ColMix -- A Simple Data Augmentation Framework to Improve Object Detector Performance and Robustness in Aerial Images
May 22, 2023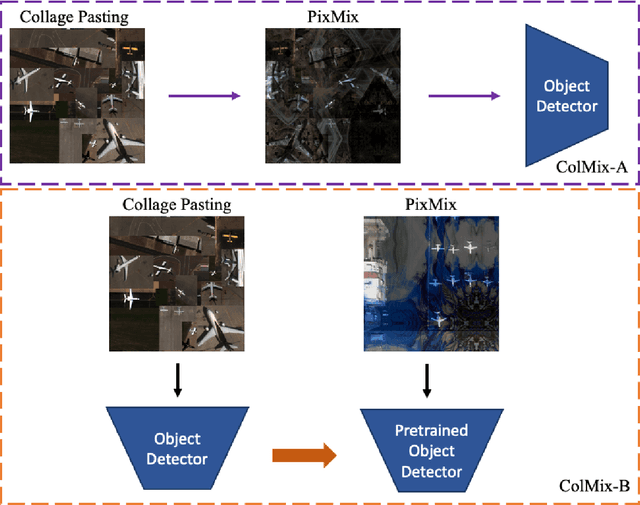
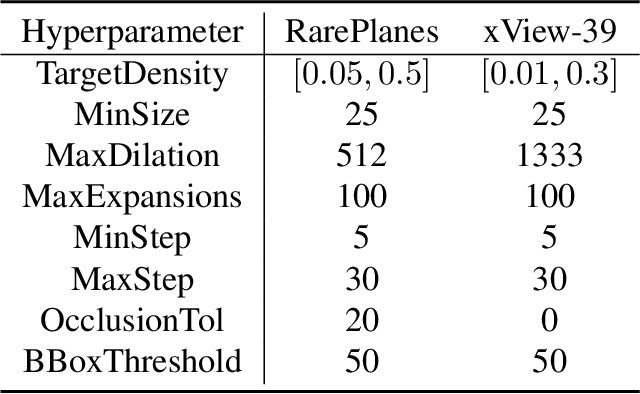

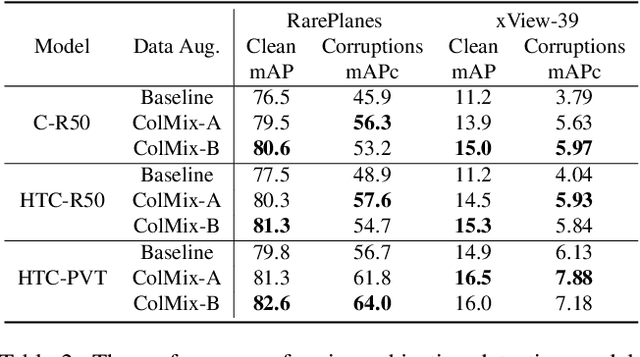
In the last decade, Convolutional Neural Network (CNN) and transformer based object detectors have achieved high performance on a large variety of datasets. Though the majority of detection literature has developed this capability on datasets such as MS COCO, these detectors have still proven effective for remote sensing applications. Challenges in this particular domain, such as small numbers of annotated objects and low object density, hinder overall performance. In this work, we present a novel augmentation method, called collage pasting, for increasing the object density without a need for segmentation masks, thereby improving the detector performance. We demonstrate that collage pasting improves precision and recall beyond related methods, such as mosaic augmentation, and enables greater control of object density. However, we find that collage pasting is vulnerable to certain out-of-distribution shifts, such as image corruptions. To address this, we introduce two simple approaches for combining collage pasting with PixMix augmentation method, and refer to our combined techniques as ColMix. Through extensive experiments, we show that employing ColMix results in detectors with superior performance on aerial imagery datasets and robust to various corruptions.
ControlVideo: Training-free Controllable Text-to-Video Generation
May 22, 2023
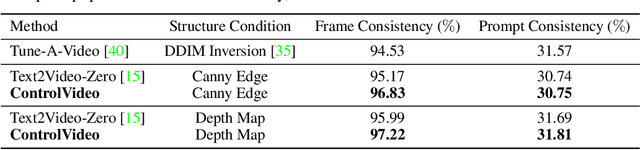
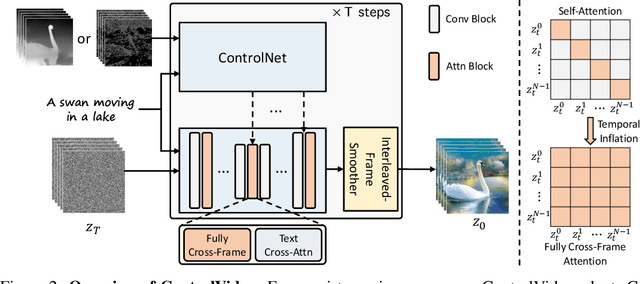
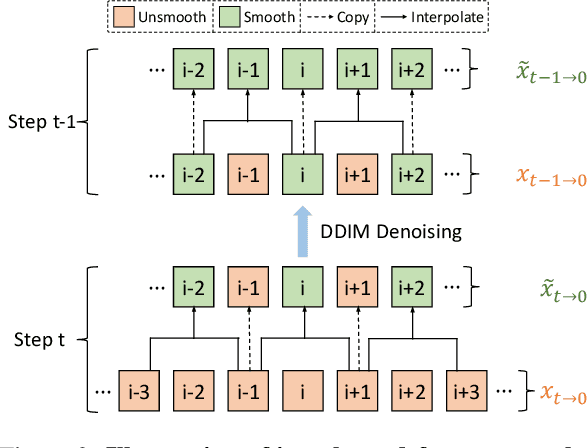
Text-driven diffusion models have unlocked unprecedented abilities in image generation, whereas their video counterpart still lags behind due to the excessive training cost of temporal modeling. Besides the training burden, the generated videos also suffer from appearance inconsistency and structural flickers, especially in long video synthesis. To address these challenges, we design a \emph{training-free} framework called \textbf{ControlVideo} to enable natural and efficient text-to-video generation. ControlVideo, adapted from ControlNet, leverages coarsely structural consistency from input motion sequences, and introduces three modules to improve video generation. Firstly, to ensure appearance coherence between frames, ControlVideo adds fully cross-frame interaction in self-attention modules. Secondly, to mitigate the flicker effect, it introduces an interleaved-frame smoother that employs frame interpolation on alternated frames. Finally, to produce long videos efficiently, it utilizes a hierarchical sampler that separately synthesizes each short clip with holistic coherency. Empowered with these modules, ControlVideo outperforms the state-of-the-arts on extensive motion-prompt pairs quantitatively and qualitatively. Notably, thanks to the efficient designs, it generates both short and long videos within several minutes using one NVIDIA 2080Ti. Code is available at https://github.com/YBYBZhang/ControlVideo.
Open-world Semi-supervised Novel Class Discovery
May 22, 2023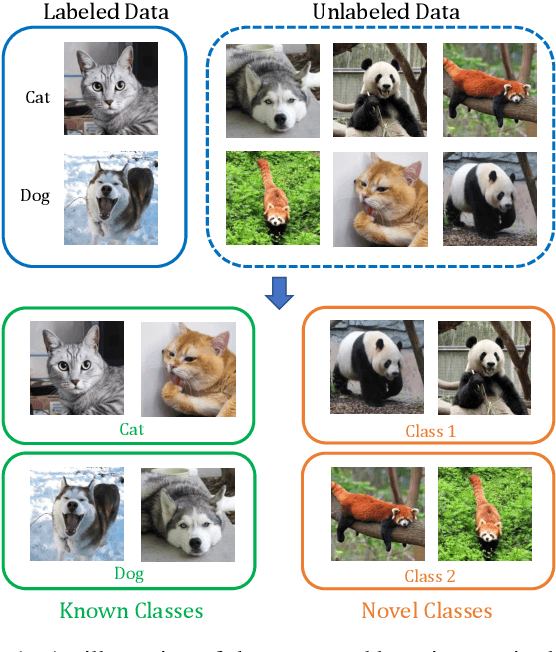
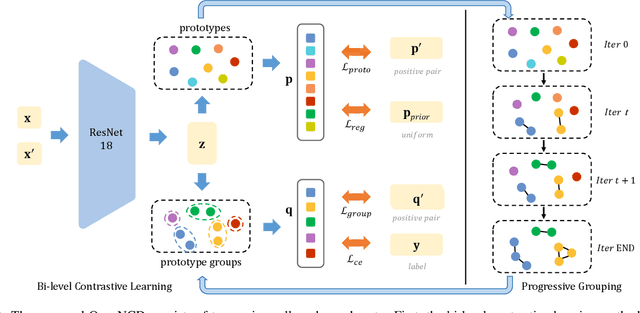
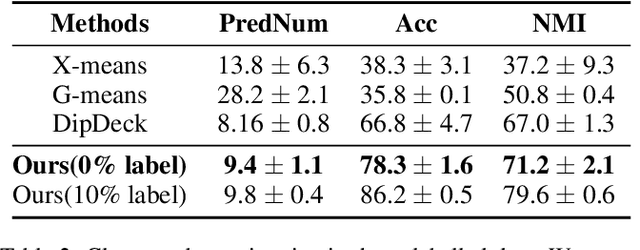
Traditional semi-supervised learning tasks assume that both labeled and unlabeled data follow the same class distribution, but the realistic open-world scenarios are of more complexity with unknown novel classes mixed in the unlabeled set. Therefore, it is of great challenge to not only recognize samples from known classes but also discover the unknown number of novel classes within the unlabeled data. In this paper, we introduce a new open-world semi-supervised novel class discovery approach named OpenNCD, a progressive bi-level contrastive learning method over multiple prototypes. The proposed method is composed of two reciprocally enhanced parts. First, a bi-level contrastive learning method is introduced, which maintains the pair-wise similarity of the prototypes and the prototype group levels for better representation learning. Then, a reliable prototype similarity metric is proposed based on the common representing instances. Prototypes with high similarities will be grouped progressively for known class recognition and novel class discovery. Extensive experiments on three image datasets are conducted and the results show the effectiveness of the proposed method in open-world scenarios, especially with scarce known classes and labels.
LPMM: Intuitive Pose Control for Neural Talking-Head Model via Landmark-Parameter Morphable Model
May 17, 2023
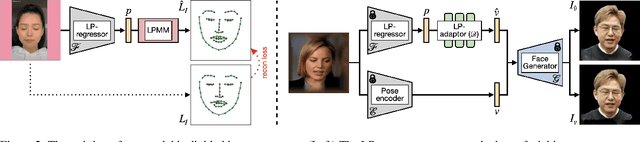
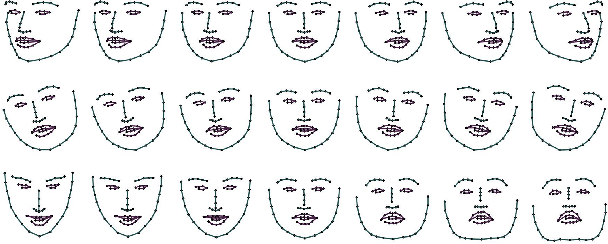
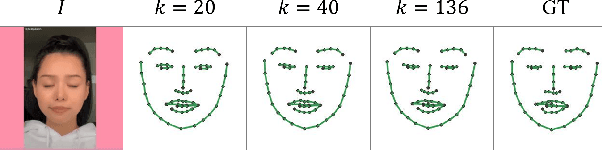
While current talking head models are capable of generating photorealistic talking head videos, they provide limited pose controllability. Most methods require specific video sequences that should exactly contain the head pose desired, being far from user-friendly pose control. Three-dimensional morphable models (3DMM) offer semantic pose control, but they fail to capture certain expressions. We present a novel method that utilizes parametric control of head orientation and facial expression over a pre-trained neural-talking head model. To enable this, we introduce a landmark-parameter morphable model (LPMM), which offers control over the facial landmark domain through a set of semantic parameters. Using LPMM, it is possible to adjust specific head pose factors, without distorting other facial attributes. The results show our approach provides intuitive rig-like control over neural talking head models, allowing both parameter and image-based inputs.
DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Apr 23, 2023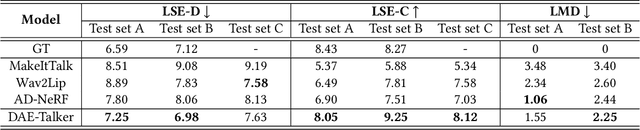
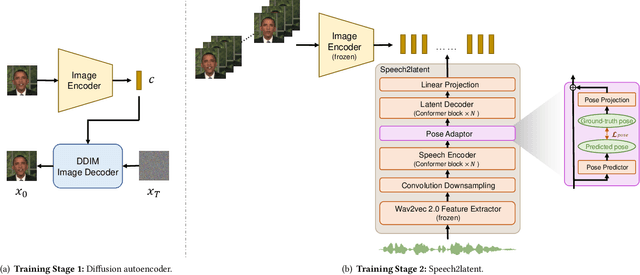

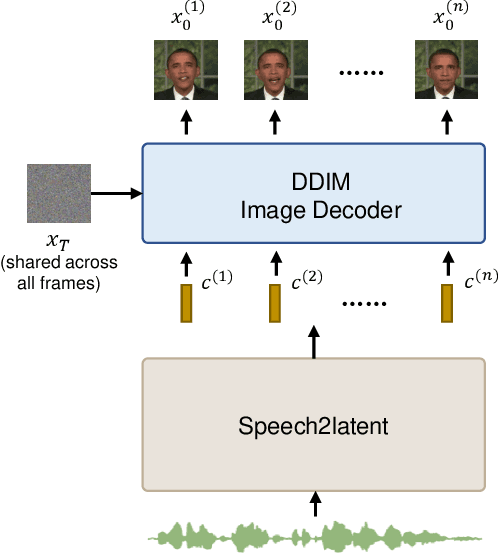
While recent research has made significant progress in speech-driven talking face generation, the quality of the generated video still lags behind that of real recordings. One reason for this is the use of handcrafted intermediate representations like facial landmarks and 3DMM coefficients, which are designed based on human knowledge and are insufficient to precisely describe facial movements. Additionally, these methods require an external pretrained model for extracting these representations, whose performance sets an upper bound on talking face generation. To address these limitations, we propose a novel method called DAE-Talker that leverages data-driven latent representations obtained from a diffusion autoencoder (DAE). DAE contains an image encoder that encodes an image into a latent vector and a DDIM image decoder that reconstructs the image from it. We train our DAE on talking face video frames and then extract their latent representations as the training target for a Conformer-based speech2latent model. This allows DAE-Talker to synthesize full video frames and produce natural head movements that align with the content of speech, rather than relying on a predetermined head pose from a template video. We also introduce pose modelling in speech2latent for pose controllability. Additionally, we propose a novel method for generating continuous video frames with the DDIM image decoder trained on individual frames, eliminating the need for modelling the joint distribution of consecutive frames directly. Our experiments show that DAE-Talker outperforms existing popular methods in lip-sync, video fidelity, and pose naturalness. We also conduct ablation studies to analyze the effectiveness of the proposed techniques and demonstrate the pose controllability of DAE-Talker.
CoReFace: Sample-Guided Contrastive Regularization for Deep Face Recognition
Apr 23, 2023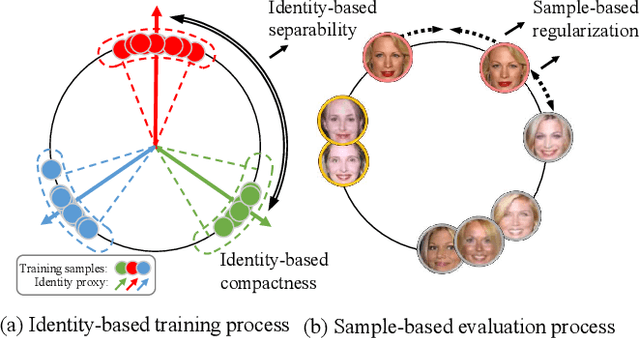
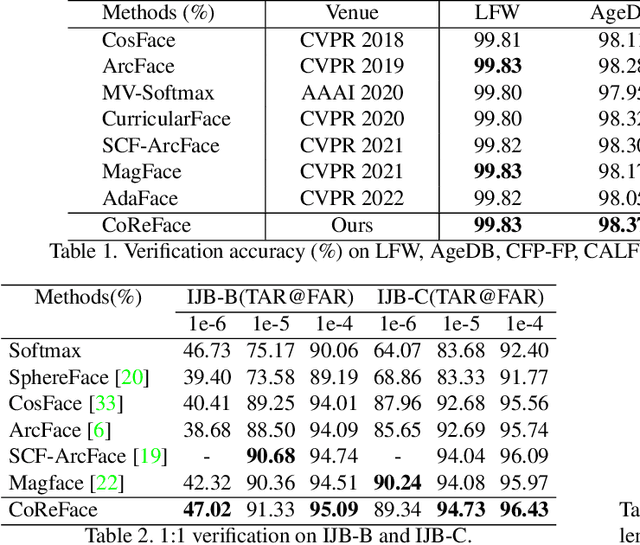
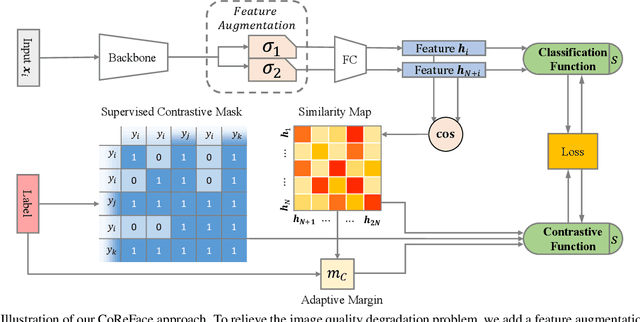
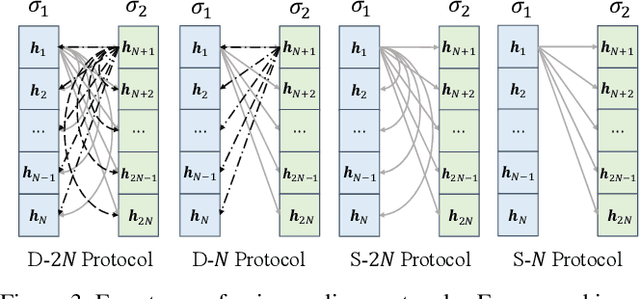
The discriminability of feature representation is the key to open-set face recognition. Previous methods rely on the learnable weights of the classification layer that represent the identities. However, the evaluation process learns no identity representation and drops the classifier from training. This inconsistency could confuse the feature encoder in understanding the evaluation goal and hinder the effect of identity-based methods. To alleviate the above problem, we propose a novel approach namely Contrastive Regularization for Face recognition (CoReFace) to apply image-level regularization in feature representation learning. Specifically, we employ sample-guided contrastive learning to regularize the training with the image-image relationship directly, which is consistent with the evaluation process. To integrate contrastive learning into face recognition, we augment embeddings instead of images to avoid the image quality degradation. Then, we propose a novel contrastive loss for the representation distribution by incorporating an adaptive margin and a supervised contrastive mask to generate steady loss values and avoid the collision with the classification supervision signal. Finally, we discover and solve the semantically repetitive signal problem in contrastive learning by exploring new pair coupling protocols. Extensive experiments demonstrate the efficacy and efficiency of our CoReFace which is highly competitive with the state-of-the-art approaches.
Do SSL Models Have Déjà Vu? A Case of Unintended Memorization in Self-supervised Learning
Apr 26, 2023
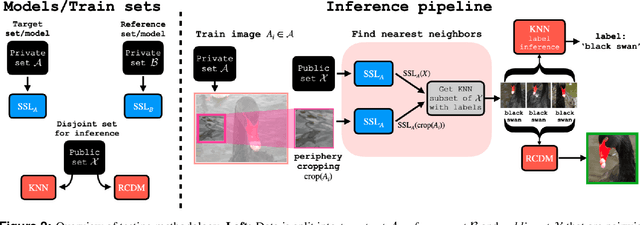
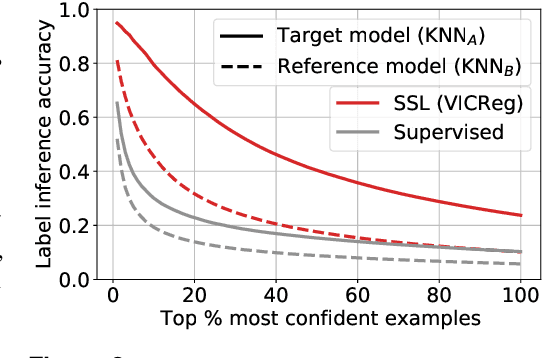
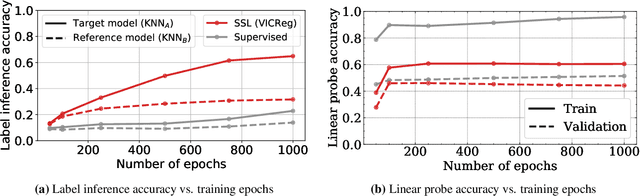
Self-supervised learning (SSL) algorithms can produce useful image representations by learning to associate different parts of natural images with one another. However, when taken to the extreme, SSL models can unintendedly memorize specific parts in individual training samples rather than learning semantically meaningful associations. In this work, we perform a systematic study of the unintended memorization of image-specific information in SSL models -- which we refer to as d\'ej\`a vu memorization. Concretely, we show that given the trained model and a crop of a training image containing only the background (e.g., water, sky, grass), it is possible to infer the foreground object with high accuracy or even visually reconstruct it. Furthermore, we show that d\'ej\`a vu memorization is common to different SSL algorithms, is exacerbated by certain design choices, and cannot be detected by conventional techniques for evaluating representation quality. Our study of d\'ej\`a vu memorization reveals previously unknown privacy risks in SSL models, as well as suggests potential practical mitigation strategies. Code is available at https://github.com/facebookresearch/DejaVu.
Single-View Height Estimation with Conditional Diffusion Probabilistic Models
Apr 26, 2023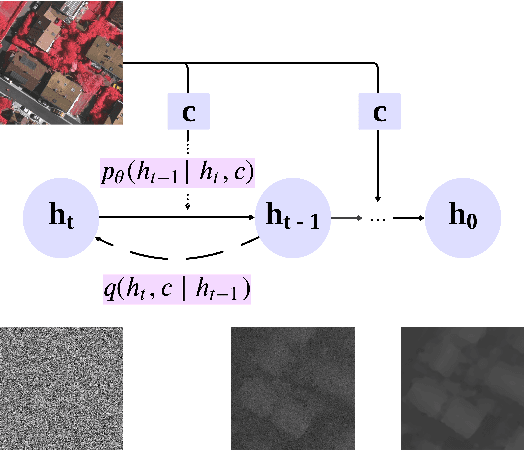
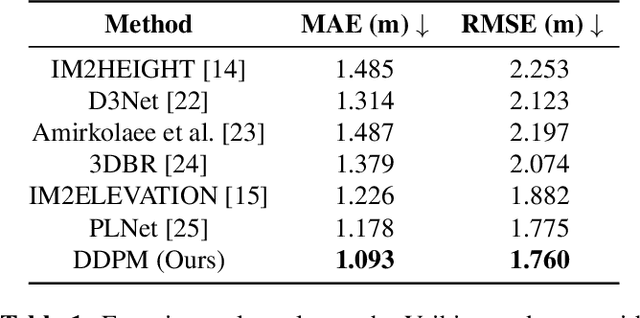
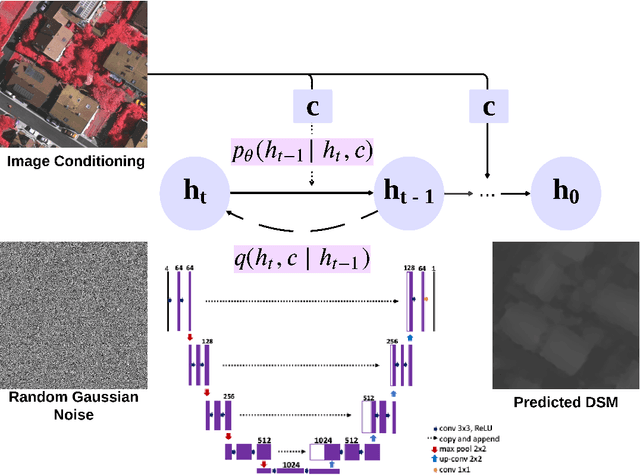

Digital Surface Models (DSM) offer a wealth of height information for understanding the Earth's surface as well as monitoring the existence or change in natural and man-made structures. Classical height estimation requires multi-view geospatial imagery or LiDAR point clouds which can be expensive to acquire. Single-view height estimation using neural network based models shows promise however it can struggle with reconstructing high resolution features. The latest advancements in diffusion models for high resolution image synthesis and editing have yet to be utilized for remote sensing imagery, particularly height estimation. Our approach involves training a generative diffusion model to learn the joint distribution of optical and DSM images across both domains as a Markov chain. This is accomplished by minimizing a denoising score matching objective while being conditioned on the source image to generate realistic high resolution 3D surfaces. In this paper we experiment with conditional denoising diffusion probabilistic models (DDPM) for height estimation from a single remotely sensed image and show promising results on the Vaihingen benchmark dataset.
Z-GMOT: Zero-shot Generic Multiple Object Tracking
May 28, 2023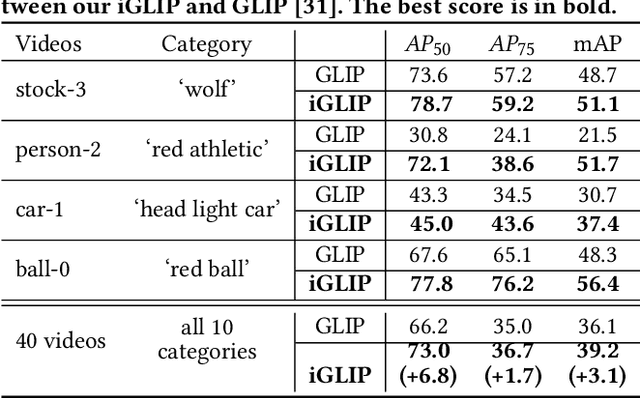
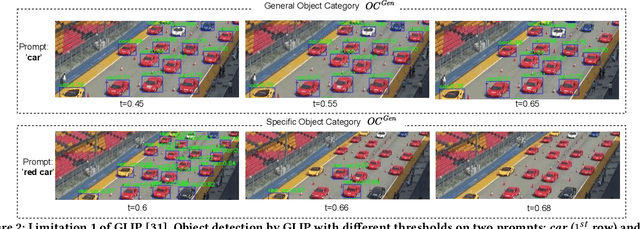


Despite the significant progress made in recent years, Multi-Object Tracking (MOT) approaches still suffer from several limitations, including their reliance on prior knowledge of tracking targets, which necessitates the costly annotation of large labeled datasets. As a result, existing MOT methods are limited to a small set of predefined categories, and they struggle with unseen objects in the real world. To address these issues, Generic Multiple Object Tracking (GMOT) has been proposed, which requires less prior information about the targets. However, all existing GMOT approaches follow a one-shot paradigm, relying mainly on the initial bounding box and thus struggling to handle variants e.g., viewpoint, lighting, occlusion, scale, and etc. In this paper, we introduce a novel approach to address the limitations of existing MOT and GMOT methods. Specifically, we propose a zero-shot GMOT (Z-GMOT) algorithm that can track never-seen object categories with zero training examples, without the need for predefined categories or an initial bounding box. To achieve this, we propose iGLIP, an improved version of Grounded language-image pretraining (GLIP), which can detect unseen objects while minimizing false positives. We evaluate our Z-GMOT thoroughly on the GMOT-40 dataset, AnimalTrack testset, DanceTrack testset. The results of these evaluations demonstrate a significant improvement over existing methods. For instance, on the GMOT-40 dataset, the Z-GMOT outperforms one-shot GMOT with OC-SORT by 27.79 points HOTA and 44.37 points MOTA. On the AnimalTrack dataset, it surpasses fully-supervised methods with DeepSORT by 12.55 points HOTA and 8.97 points MOTA. To facilitate further research, we will make our code and models publicly available upon acceptance of this paper.