 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training
Feb 28, 2023
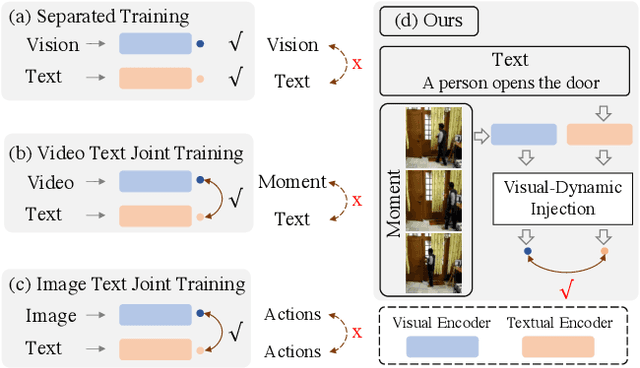
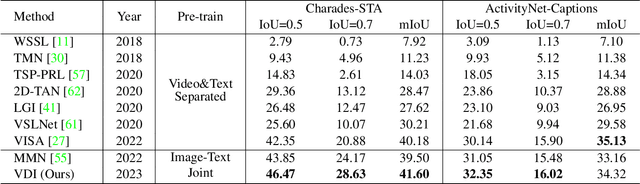
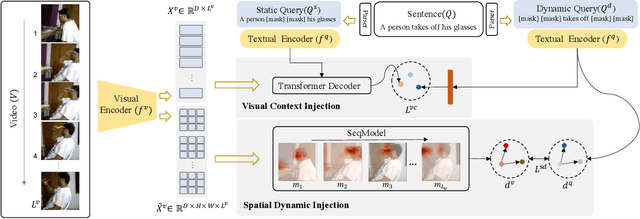
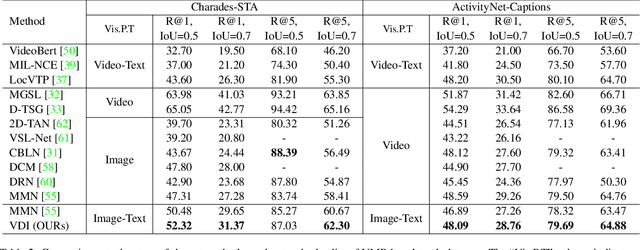
The correlation between the vision and text is essential for video moment retrieval (VMR), however, existing methods heavily rely on separate pre-training feature extractors for visual and textual understanding. Without sufficient temporal boundary annotations, it is non-trivial to learn universal video-text alignments. In this work, we explore multi-modal correlations derived from large-scale image-text data to facilitate generalisable VMR. To address the limitations of image-text pre-training models on capturing the video changes, we propose a generic method, referred to as Visual-Dynamic Injection (VDI), to empower the model's understanding of video moments. Whilst existing VMR methods are focusing on building temporal-aware video features, being aware of the text descriptions about the temporal changes is also critical but originally overlooked in pre-training by matching static images with sentences. Therefore, we extract visual context and spatial dynamic information from video frames and explicitly enforce their alignments with the phrases describing video changes (e.g. verb). By doing so, the potentially relevant visual and motion patterns in videos are encoded in the corresponding text embeddings (injected) so to enable more accurate video-text alignments. We conduct extensive experiments on two VMR benchmark datasets (Charades-STA and ActivityNet-Captions) and achieve state-of-the-art performances. Especially, VDI yields notable advantages when being tested on the out-of-distribution splits where the testing samples involve novel scenes and vocabulary.
Meta-Album: Multi-domain Meta-Dataset for Few-Shot Image Classification
Feb 16, 2023
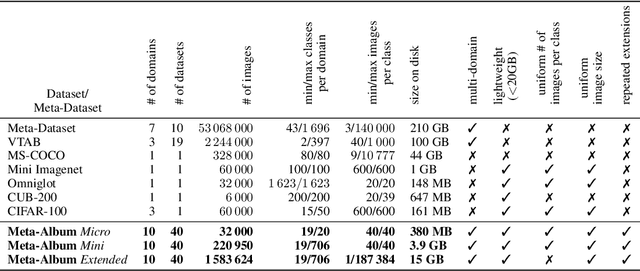
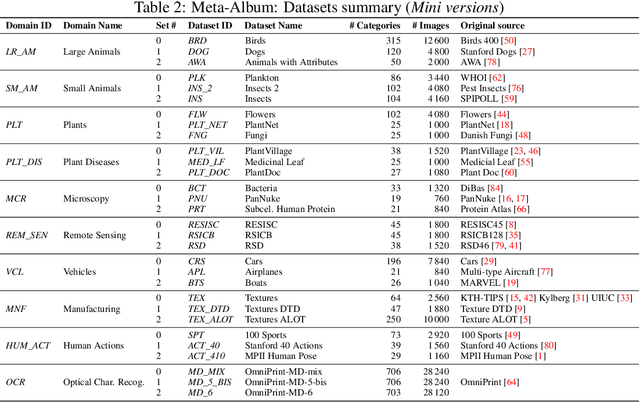
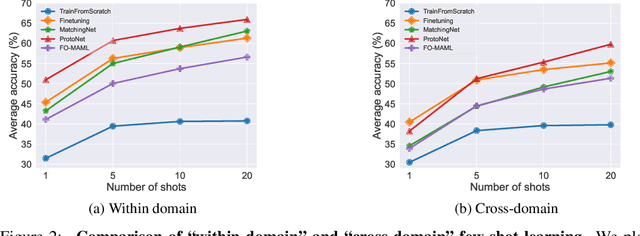
We introduce Meta-Album, an image classification meta-dataset designed to facilitate few-shot learning, transfer learning, meta-learning, among other tasks. It includes 40 open datasets, each having at least 20 classes with 40 examples per class, with verified licences. They stem from diverse domains, such as ecology (fauna and flora), manufacturing (textures, vehicles), human actions, and optical character recognition, featuring various image scales (microscopic, human scales, remote sensing). All datasets are preprocessed, annotated, and formatted uniformly, and come in 3 versions (Micro $\subset$ Mini $\subset$ Extended) to match users' computational resources. We showcase the utility of the first 30 datasets on few-shot learning problems. The other 10 will be released shortly after. Meta-Album is already more diverse and larger (in number of datasets) than similar efforts, and we are committed to keep enlarging it via a series of competitions. As competitions terminate, their test data are released, thus creating a rolling benchmark, available through OpenML.org. Our website https://meta-album.github.io/ contains the source code of challenge winning methods, baseline methods, data loaders, and instructions for contributing either new datasets or algorithms to our expandable meta-dataset.
CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model
May 23, 2023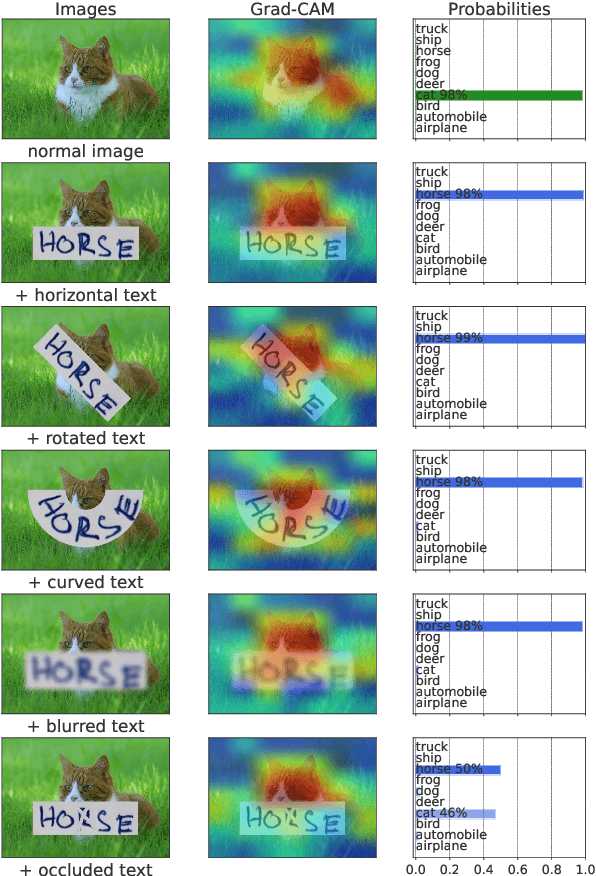
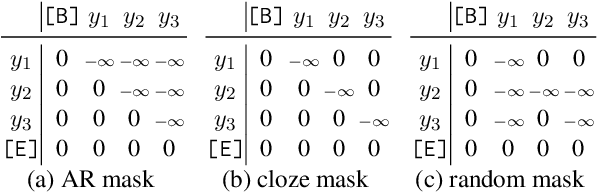
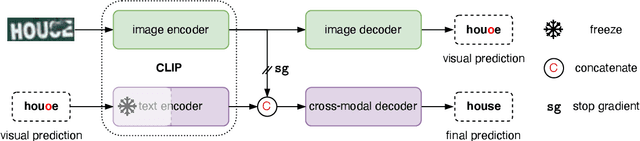
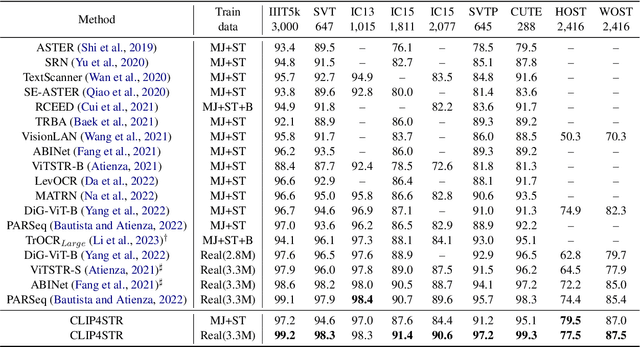
Pre-trained vision-language models are the de-facto foundation models for various downstream tasks. However, this trend has not extended to the field of scene text recognition (STR), despite the potential of CLIP to serve as a powerful scene text reader. CLIP can robustly identify regular (horizontal) and irregular (rotated, curved, blurred, or occluded) text in natural images. With such merits, we introduce CLIP4STR, a simple yet effective STR method built upon image and text encoders of CLIP. It has two encoder-decoder branches: a visual branch and a cross-modal branch. The visual branch provides an initial prediction based on the visual feature, and the cross-modal branch refines this prediction by addressing the discrepancy between the visual feature and text semantics. To fully leverage the capabilities of both branches, we design a dual predict-and-refine decoding scheme for inference. CLIP4STR achieves new state-of-the-art performance on 11 STR benchmarks. Additionally, a comprehensive empirical study is provided to enhance the understanding of the adaptation of CLIP to STR. We believe our method establishes a simple but strong baseline for future STR research with VL models.
ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings
May 23, 2023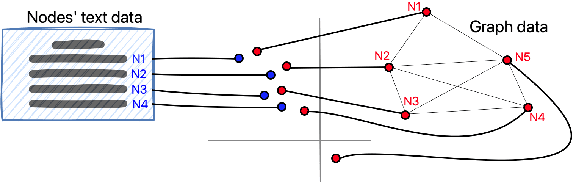
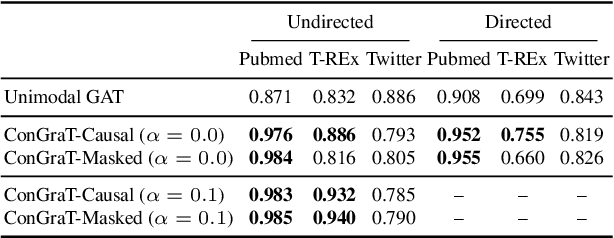
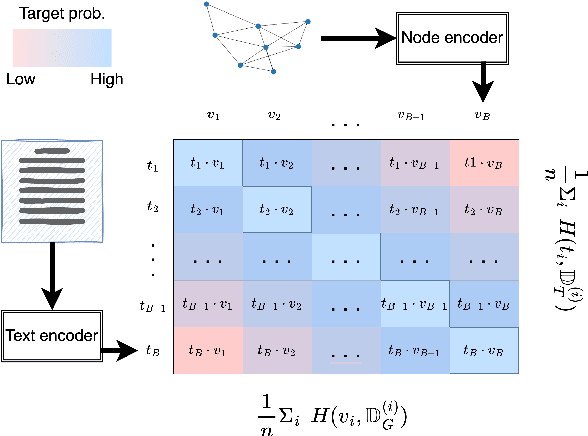
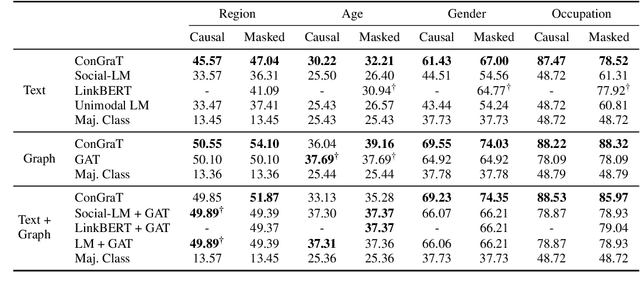
We propose ConGraT(Contrastive Graph-Text pretraining), a general, self-supervised method for jointly learning separate representations of texts and nodes in a parent (or ``supervening'') graph, where each text is associated with one of the nodes. Datasets fitting this paradigm are common, from social media (users and posts), to citation networks over articles, to link graphs over web pages. We expand on prior work by providing a general, self-supervised, joint pretraining method, one which does not depend on particular dataset structure or a specific task. Our method uses two separate encoders for graph nodes and texts, which are trained to align their representations within a common latent space. Training uses a batch-wise contrastive learning objective inspired by prior work on joint text and image encoding. As graphs are more structured objects than images, we also extend the training objective to incorporate information about node similarity and plausible next guesses in matching nodes and texts. Experiments on various datasets reveal that ConGraT outperforms strong baselines on various downstream tasks, including node and text category classification and link prediction. Code and certain datasets are available at https://github.com/wwbrannon/congrat.
REC-MV: REconstructing 3D Dynamic Cloth from Monocular Videos
May 23, 2023

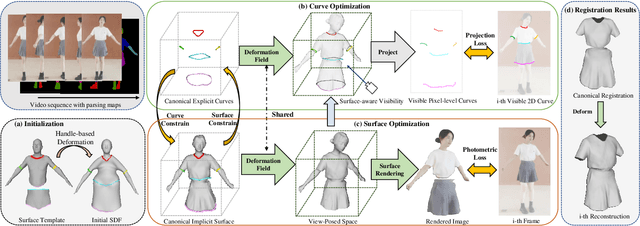
Reconstructing dynamic 3D garment surfaces with open boundaries from monocular videos is an important problem as it provides a practical and low-cost solution for clothes digitization. Recent neural rendering methods achieve high-quality dynamic clothed human reconstruction results from monocular video, but these methods cannot separate the garment surface from the body. Moreover, despite existing garment reconstruction methods based on feature curve representation demonstrating impressive results for garment reconstruction from a single image, they struggle to generate temporally consistent surfaces for the video input. To address the above limitations, in this paper, we formulate this task as an optimization problem of 3D garment feature curves and surface reconstruction from monocular video. We introduce a novel approach, called REC-MV, to jointly optimize the explicit feature curves and the implicit signed distance field (SDF) of the garments. Then the open garment meshes can be extracted via garment template registration in the canonical space. Experiments on multiple casually captured datasets show that our approach outperforms existing methods and can produce high-quality dynamic garment surfaces. The source code is available at https://github.com/GAP-LAB-CUHK-SZ/REC-MV.
Design and Operation of Autonomous Wheelchair Towing Robot
May 23, 2023
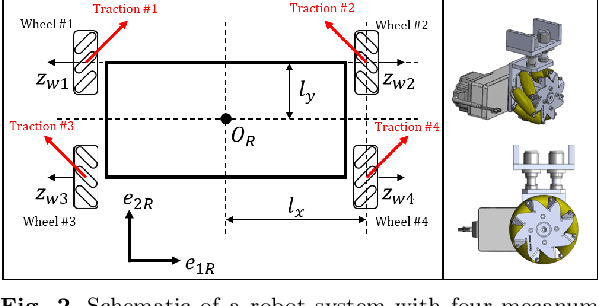
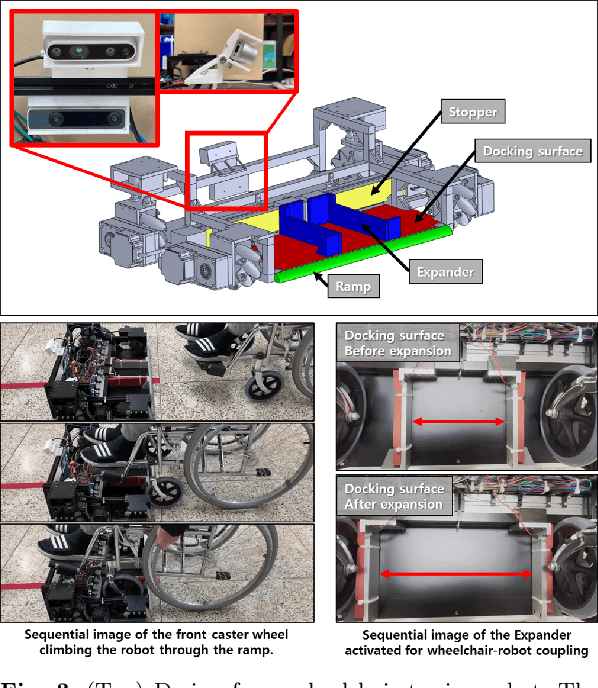
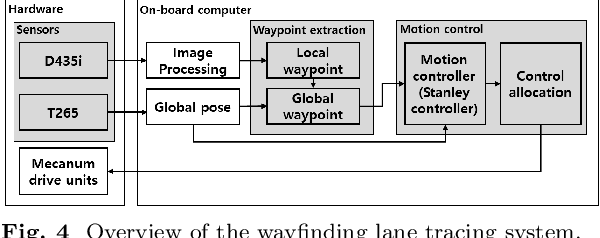
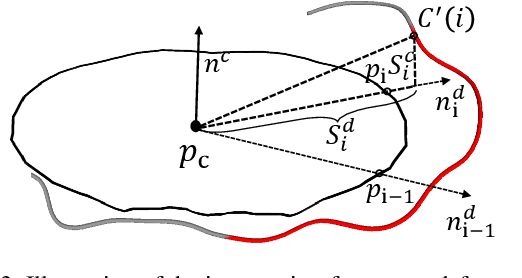
In this study, a new concept of a wheelchair-towing robot for the facile electrification of manual wheelchairs is introduced. The development of this concept includes the design of towing robot hardware and an autonomous driving algorithm to ensure the safe transportation of patients to their intended destinations inside the hospital. We developed a novel docking mechanism to facilitate easy docking and separation between the towing robot and the manual wheelchair, which is connected to the front caster wheel of the manual wheelchair. The towing robot has a mecanum wheel drive, enabling the robot to move with a high degree of freedom in the standalone driving mode while adhering to kinematic constraints in the docking mode. Our novel towing robot features a camera sensor that can observe the ground ahead which allows the robot to autonomously follow color-coded wayfinding lanes installed in hospital corridors. This study introduces dedicated image processing techniques for capturing the lanes and control algorithms for effectively tracing a path to achieve autonomous path following. The autonomous towing performance of our proposed platform was validated by a real-world experiment in which a hospital environment with colored lanes was created.
Learning Remote Sensing Object Detection with Single Point Supervision
May 23, 2023


Pointly Supervised Object Detection (PSOD) has attracted considerable interests due to its lower labeling cost as compared to box-level supervised object detection. However, the complex scenes, densely packed and dynamic-scale objects in Remote Sensing (RS) images hinder the development of PSOD methods in RS field. In this paper, we make the first attempt to achieve RS object detection with single point supervision, and propose a PSOD framework tailored with RS images. Specifically, we design a point label upgrader (PLUG) to generate pseudo box labels from single point labels, and then use the pseudo boxes to supervise the optimization of existing detectors. Moreover, to handle the challenge of the densely packed objects in RS images, we propose a sparse feature guided semantic prediction module which can generate high-quality semantic maps by fully exploiting informative cues from sparse objects. Extensive ablation studies on the DOTA dataset have validated the effectiveness of our method. Our method can achieve significantly better performance as compared to state-of-the-art image-level and point-level supervised detection methods, and reduce the performance gap between PSOD and box-level supervised object detection. Code will be available at https://github.com/heshitian/PLUG.
Spatio-Temporal Structure Consistency for Semi-supervised Medical Image Classification
Mar 03, 2023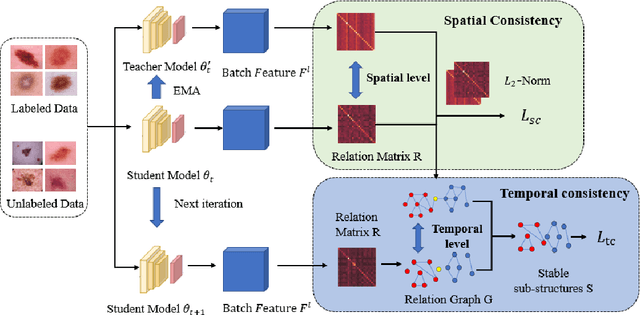
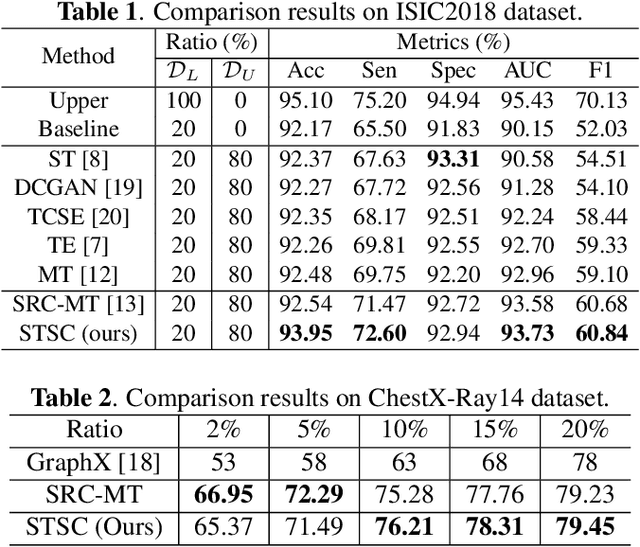
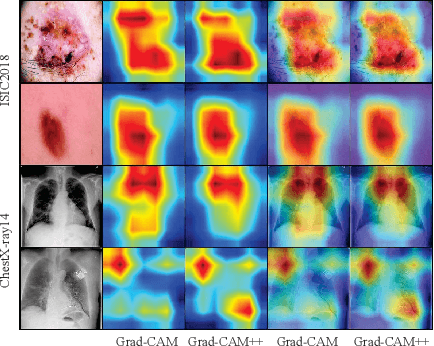
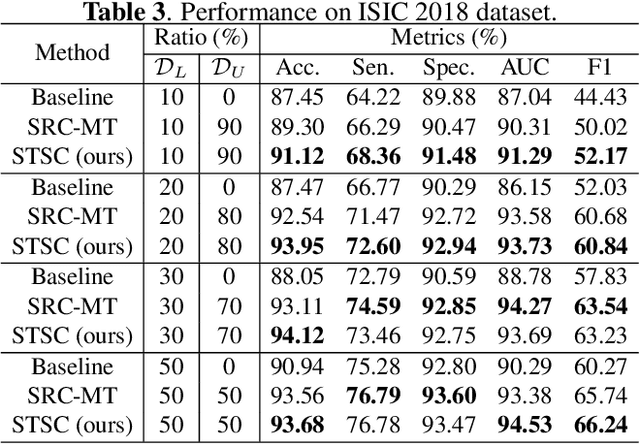
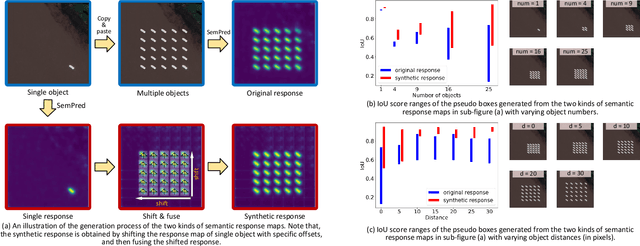
Intelligent medical diagnosis has shown remarkable progress based on the large-scale datasets with precise annotations. However, fewer labeled images are available due to significantly expensive cost for annotating data by experts. To fully exploit the easily available unlabeled data, we propose a novel Spatio-Temporal Structure Consistent (STSC) learning framework. Specifically, a gram matrix is derived to combine the spatial structure consistency and temporal structure consistency together. This gram matrix captures the structural similarity among the representations of different training samples. At the spatial level, our framework explicitly enforces the consistency of structural similarity among different samples under perturbations. At the temporal level, we consider the consistency of the structural similarity in different training iterations by digging out the stable sub-structures in a relation graph. Experiments on two medical image datasets (i.e., ISIC 2018 challenge and ChestX-ray14) show that our method outperforms state-of-the-art SSL methods. Furthermore, extensive qualitative analysis on the Gram matrices and heatmaps by Grad-CAM are presented to validate the effectiveness of our method.
Data Redaction from Conditional Generative Models
May 18, 2023

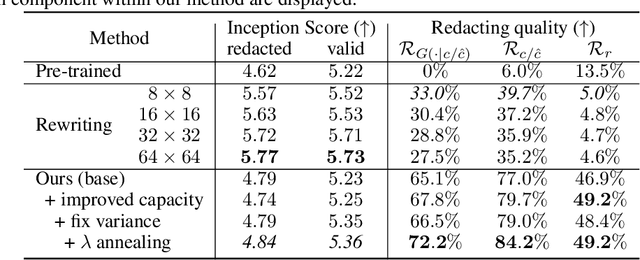

Deep generative models are known to produce undesirable samples such as harmful content. Traditional mitigation methods include re-training from scratch, filtering, or editing; however, these are either computationally expensive or can be circumvented by third parties. In this paper, we take a different approach and study how to post-edit an already-trained conditional generative model so that it redacts certain conditionals that will, with high probability, lead to undesirable content. This is done by distilling the conditioning network in the models, giving a solution that is effective, efficient, controllable, and universal for a class of deep generative models. We conduct experiments on redacting prompts in text-to-image models and redacting voices in text-to-speech models. Our method is computationally light, leads to better redaction quality and robustness than baseline methods while still retaining high generation quality.
An Image Processing Pipeline for Autonomous Deep-Space Optical Navigation
Feb 14, 2023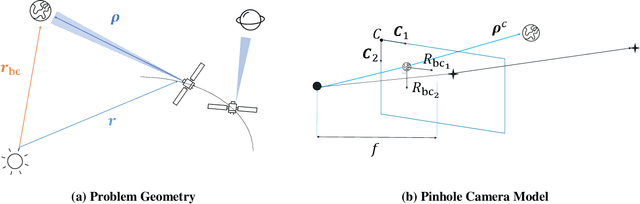

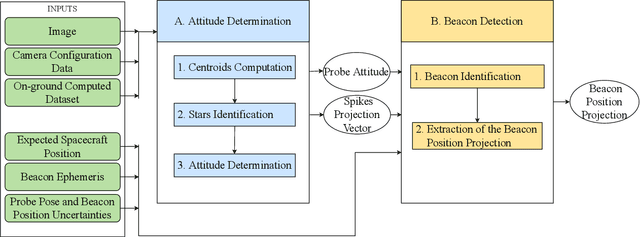
A new era of space exploration and exploitation is fast approaching. A multitude of spacecraft will flow in the future decades under the propulsive momentum of the new space economy. Yet, the flourishing proliferation of deep-space assets will make it unsustainable to pilot them from ground with standard radiometric tracking. The adoption of autonomous navigation alternatives is crucial to overcoming these limitations. Among these, optical navigation is an affordable and fully ground-independent approach. Probes can triangulate their position by observing visible beacons, e.g., planets or asteroids, by acquiring their line-of-sight in deep space. To do so, developing efficient and robust image processing algorithms providing information to navigation filters is a necessary action. This paper proposes an innovative pipeline for unresolved beacon recognition and line-of-sight extraction from images for autonomous interplanetary navigation. The developed algorithm exploits the k-vector method for the non-stellar object identification and statistical likelihood to detect whether any beacon projection is visible in the image. Statistical results show that the accuracy in detecting the planet position projection is independent of the spacecraft position uncertainty. Whereas, the planet detection success rate is higher than 95% when the spacecraft position is known with a 3sigma accuracy up to 10^5 km.