 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Putting People in Their Place: Affordance-Aware Human Insertion into Scenes
Apr 27, 2023

We study the problem of inferring scene affordances by presenting a method for realistically inserting people into scenes. Given a scene image with a marked region and an image of a person, we insert the person into the scene while respecting the scene affordances. Our model can infer the set of realistic poses given the scene context, re-pose the reference person, and harmonize the composition. We set up the task in a self-supervised fashion by learning to re-pose humans in video clips. We train a large-scale diffusion model on a dataset of 2.4M video clips that produces diverse plausible poses while respecting the scene context. Given the learned human-scene composition, our model can also hallucinate realistic people and scenes when prompted without conditioning and also enables interactive editing. A quantitative evaluation shows that our method synthesizes more realistic human appearance and more natural human-scene interactions than prior work.
SRCNet: Seminal Representation Collaborative Network for Marine Oil Spill Segmentation
Apr 17, 2023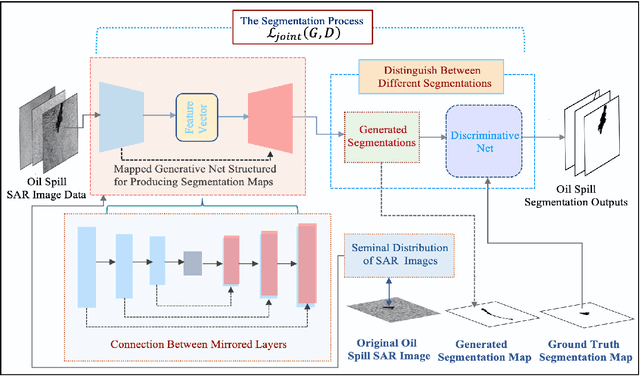
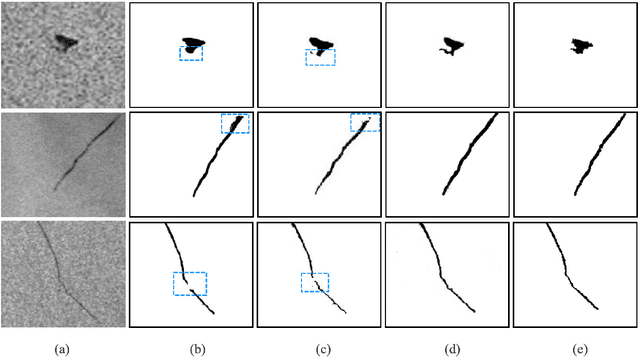

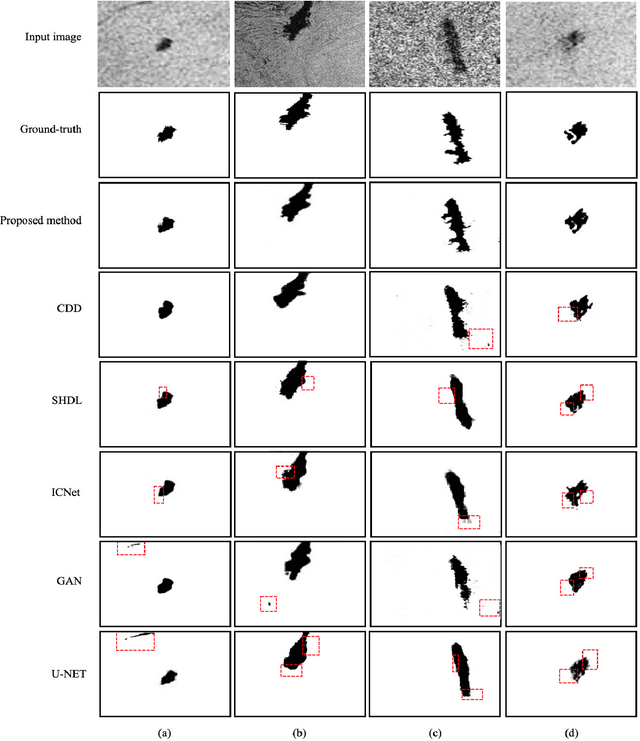
Effective oil spill segmentation in Synthetic Aperture Radar (SAR) images is critical for marine oil pollution cleanup, and proper image representation is helpful for accurate image segmentation. In this paper, we propose an effective oil spill image segmentation network named SRCNet by leveraging SAR image representation and the training for oil spill segmentation simultaneously. Specifically, our proposed segmentation network is constructed with a pair of deep neural nets with the collaboration of the seminal representation that describes SAR images, where one deep neural net is the generative net which strives to produce oil spill segmentation maps, and the other is the discriminative net which trys its best to distinguish between the produced and the true segmentations, and they thus built a two-player game. Particularly, the seminal representation exploited in our proposed SRCNet originates from SAR imagery, modelling with the internal characteristics of SAR images. Thus, in the training process, the collaborated seminal representation empowers the mapped generative net to produce accurate oil spill segmentation maps efficiently with small amount of training data, promoting the discriminative net reaching its optimal solution at a fast speed. Therefore, our proposed SRCNet operates effective oil spill segmentation in an economical and efficient manner. Additionally, to increase the segmentation capability of the proposed segmentation network in terms of accurately delineating oil spill details in SAR images, a regularisation term that penalises the segmentation loss is devised. This encourages our proposed SRCNet for accurately segmenting oil spill areas from SAR images. Empirical experimental evaluations from different metrics validate the effectiveness of our proposed SRCNet for oil spill image segmentation.
Few-Shot Image-to-Semantics Translation for Policy Transfer in Reinforcement Learning
Jan 31, 2023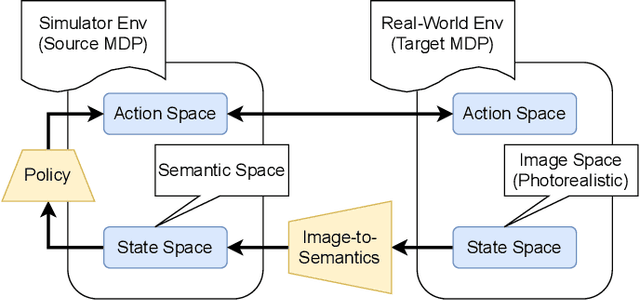
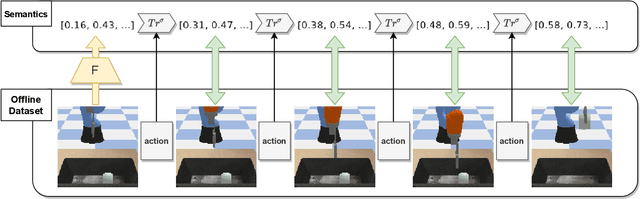

We investigate policy transfer using image-to-semantics translation to mitigate learning difficulties in vision-based robotics control agents. This problem assumes two environments: a simulator environment with semantics, that is, low-dimensional and essential information, as the state space, and a real-world environment with images as the state space. By learning mapping from images to semantics, we can transfer a policy, pre-trained in the simulator, to the real world, thereby eliminating real-world on-policy agent interactions to learn, which are costly and risky. In addition, using image-to-semantics mapping is advantageous in terms of the computational efficiency to train the policy and the interpretability of the obtained policy over other types of sim-to-real transfer strategies. To tackle the main difficulty in learning image-to-semantics mapping, namely the human annotation cost for producing a training dataset, we propose two techniques: pair augmentation with the transition function in the simulator environment and active learning. We observed a reduction in the annotation cost without a decline in the performance of the transfer, and the proposed approach outperformed the existing approach without annotation.
Image-based Pose Estimation and Shape Reconstruction for Robot Manipulators and Soft, Continuum Robots via Differentiable Rendering
Feb 27, 2023
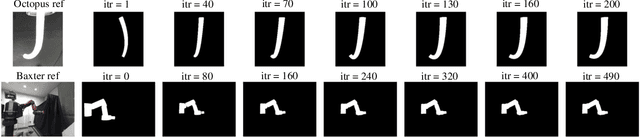
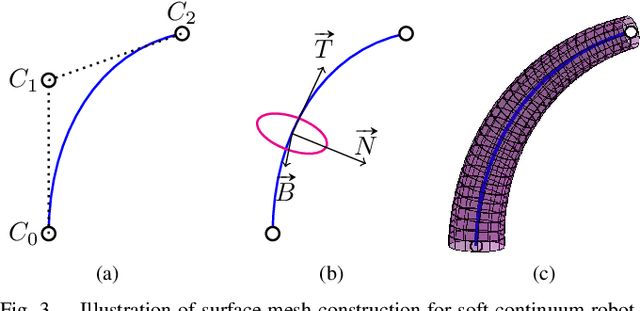
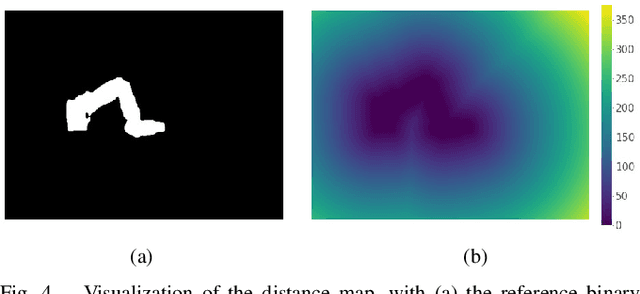
State estimation from measured data is crucial for robotic applications as autonomous systems rely on sensors to capture the motion and localize in the 3D world. Among sensors that are designed for measuring a robot's pose, or for soft robots, their shape, vision sensors are favorable because they are information-rich, easy to set up, and cost-effective. With recent advancements in computer vision, deep learning-based methods no longer require markers for identifying feature points on the robot. However, learning-based methods are data-hungry and hence not suitable for soft and prototyping robots, as building such bench-marking datasets is usually infeasible. In this work, we achieve image-based robot pose estimation and shape reconstruction from camera images. Our method requires no precise robot meshes, but rather utilizes a differentiable renderer and primitive shapes. It hence can be applied to robots for which CAD models might not be available or are crude. Our parameter estimation pipeline is fully differentiable. The robot shape and pose are estimated iteratively by back-propagating the image loss to update the parameters. We demonstrate that our method of using geometrical shape primitives can achieve high accuracy in shape reconstruction for a soft continuum robot and pose estimation for a robot manipulator.
Frequency-aware Learned Image Compression for Quality Scalability
Jan 03, 2023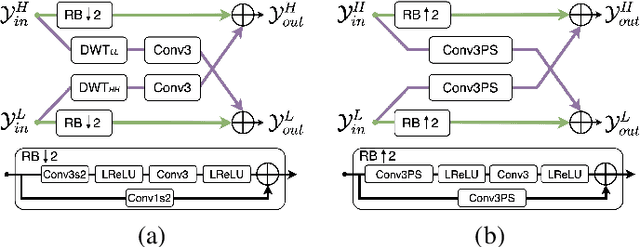
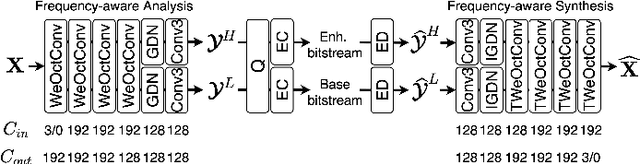

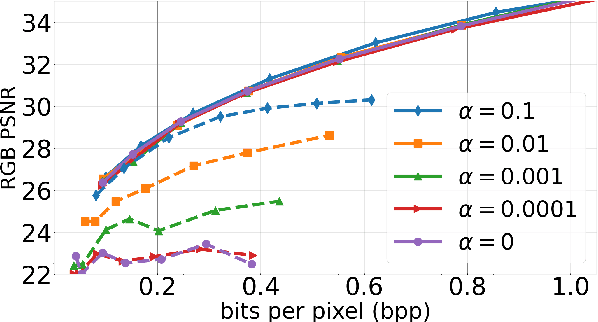
Spatial frequency analysis and transforms serve a central role in most engineered image and video lossy codecs, but are rarely employed in neural network (NN)-based approaches. We propose a novel NN-based image coding framework that utilizes forward wavelet transforms to decompose the input signal by spatial frequency. Our encoder generates separate bitstreams for each latent representation of low and high frequencies. This enables our decoder to selectively decode bitstreams in a quality-scalable manner. Hence, the decoder can produce an enhanced image by using an enhancement bitstream in addition to the base bitstream. Furthermore, our method is able to enhance only a specific region of interest (ROI) by using a corresponding part of the enhancement latent representation. Our experiments demonstrate that the proposed method shows competitive rate-distortion performance compared to several non-scalable image codecs. We also showcase the effectiveness of our two-level quality scalability, as well as its practicality in ROI quality enhancement.
An Aligned Multi-Temporal Multi-Resolution Satellite Image Dataset for Change Detection Research
Feb 23, 2023
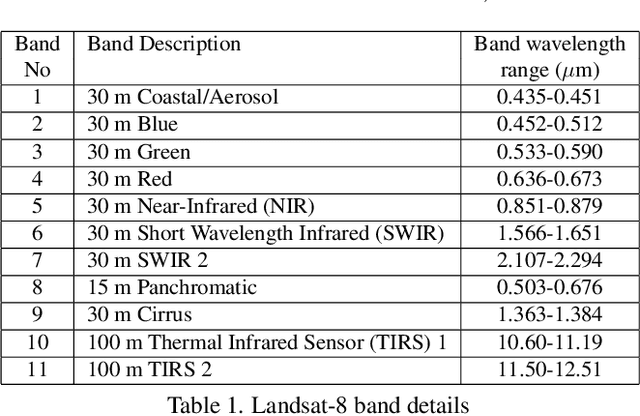
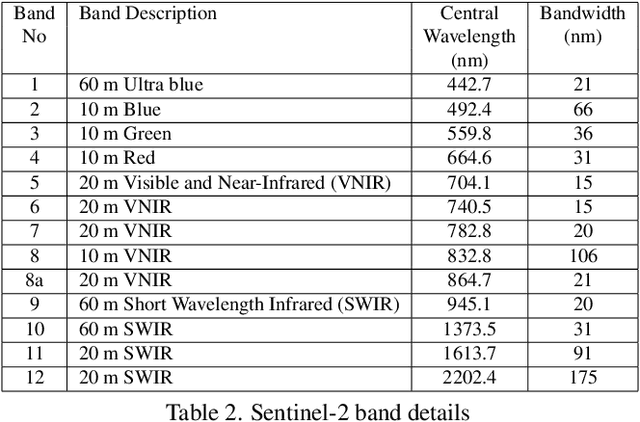
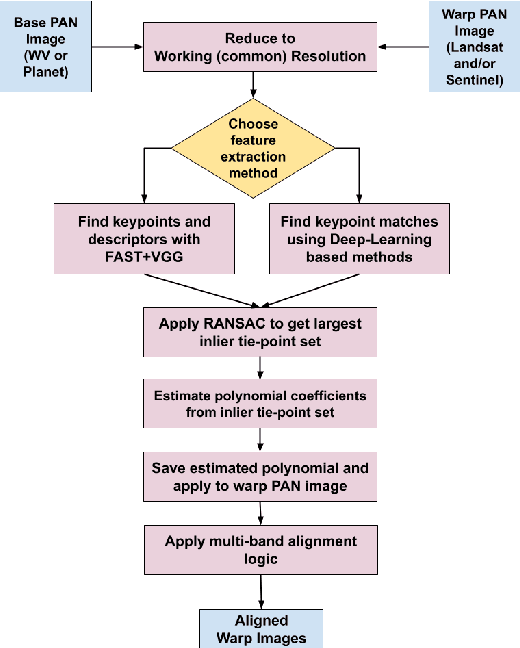
This paper presents an aligned multi-temporal and multi-resolution satellite image dataset for research in change detection. We expect our dataset to be useful to researchers who want to fuse information from multiple satellites for detecting changes on the surface of the earth that may not be fully visible in any single satellite. The dataset we present was created by augmenting the SpaceNet-7 dataset with temporally parallel stacks of Landsat and Sentinel images. The SpaceNet-7 dataset consists of time-sequenced Planet images recorded over 101 AOIs (Areas-of-Interest). In our dataset, for each of the 60 AOIs that are meant for training, we augment the Planet datacube with temporally parallel datacubes of Landsat and Sentinel images. The temporal alignments between the high-res Planet images, on the one hand, and the Landsat and Sentinel images, on the other, are approximate since the temporal resolution for the Planet images is one month -- each image being a mosaic of the best data collected over a month. Whenever we have a choice regarding which Landsat and Sentinel images to pair up with the Planet images, we have chosen those that had the least cloud cover. A particularly important feature of our dataset is that the high-res and the low-res images are spatially aligned together with our MuRA framework presented in this paper. Foundational to the alignment calculation is the modeling of inter-satellite misalignment errors with polynomials as in NASA's AROP algorithm. We have named our dataset MuRA-T for the MuRA framework that is used for aligning the cross-satellite images and "T" for the temporal dimension in the dataset.
An Edit Friendly DDPM Noise Space: Inversion and Manipulations
Apr 14, 2023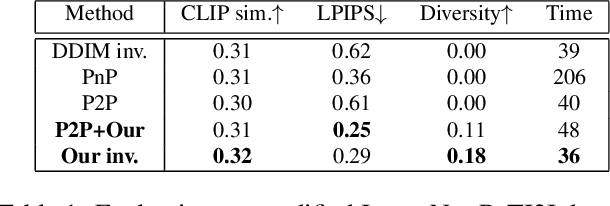


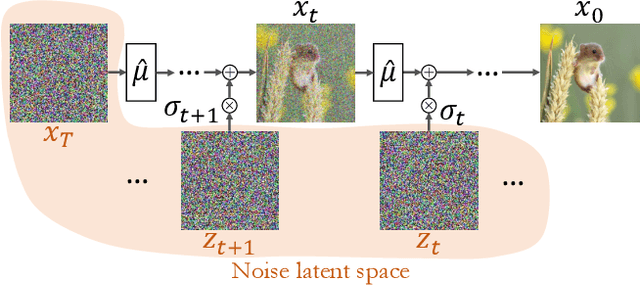
Denoising diffusion probabilistic models (DDPMs) employ a sequence of white Gaussian noise samples to generate an image. In analogy with GANs, those noise maps could be considered as the latent code associated with the generated image. However, this native noise space does not possess a convenient structure, and is thus challenging to work with in editing tasks. Here, we propose an alternative latent noise space for DDPM that enables a wide range of editing operations via simple means, and present an inversion method for extracting these edit-friendly noise maps for any given image (real or synthetically generated). As opposed to the native DDPM noise space, the edit-friendly noise maps do not have a standard normal distribution and are not statistically independent across timesteps. However, they allow perfect reconstruction of any desired image, and simple transformations on them translate into meaningful manipulations of the output image (e.g., shifting, color edits). Moreover, in text-conditional models, fixing those noise maps while changing the text prompt, modifies semantics while retaining structure. We illustrate how this property enables text-based editing of real images via the diverse DDPM sampling scheme (in contrast to the popular non-diverse DDIM inversion). We also show how it can be used within existing diffusion-based editing methods to improve their quality and diversity.
Exposing and Mitigating Spurious Correlations for Cross-Modal Retrieval
Apr 06, 2023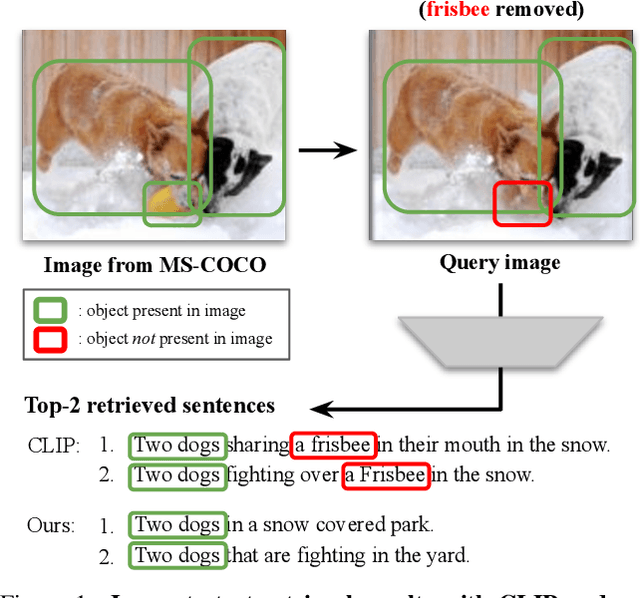
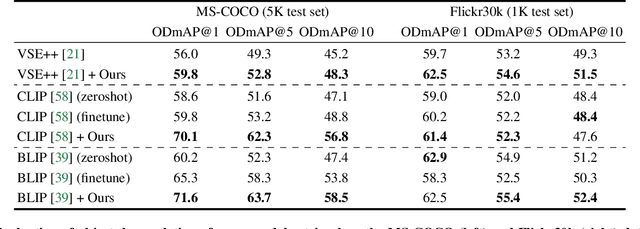
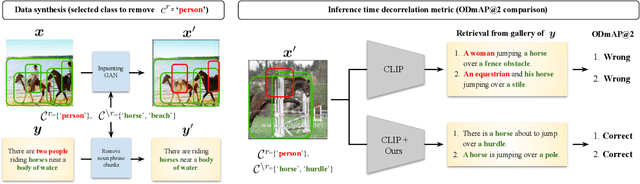
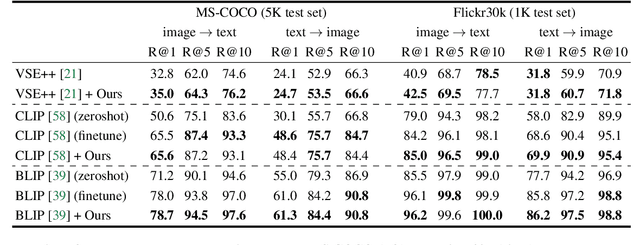
Cross-modal retrieval methods are the preferred tool to search databases for the text that best matches a query image and vice versa. However, image-text retrieval models commonly learn to memorize spurious correlations in the training data, such as frequent object co-occurrence, instead of looking at the actual underlying reasons for the prediction in the image. For image-text retrieval, this manifests in retrieved sentences that mention objects that are not present in the query image. In this work, we introduce ODmAP@k, an object decorrelation metric that measures a model's robustness to spurious correlations in the training data. We use automatic image and text manipulations to control the presence of such object correlations in designated test data. Additionally, our data synthesis technique is used to tackle model biases due to spurious correlations of semantically unrelated objects in the training data. We apply our proposed pipeline, which involves the finetuning of image-text retrieval frameworks on carefully designed synthetic data, to three state-of-the-art models for image-text retrieval. This results in significant improvements for all three models, both in terms of the standard retrieval performance and in terms of our object decorrelation metric. The code is available at https://github.com/ExplainableML/Spurious_CM_Retrieval.
LDMIC: Learning-based Distributed Multi-view Image Coding
Jan 24, 2023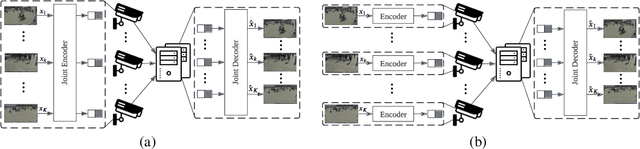
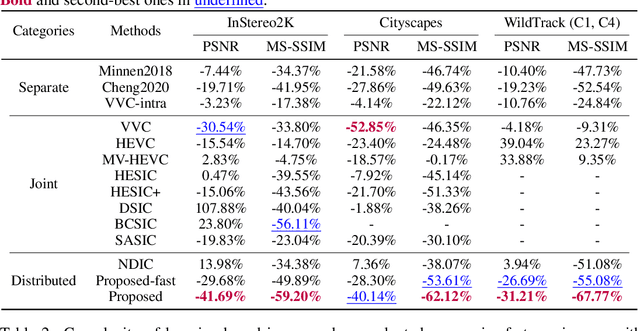
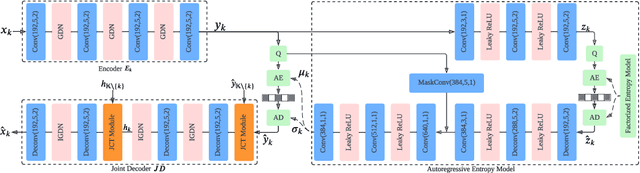
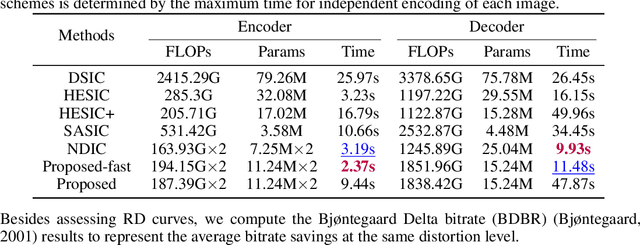
Multi-view image compression plays a critical role in 3D-related applications. Existing methods adopt a predictive coding architecture, which requires joint encoding to compress the corresponding disparity as well as residual information. This demands collaboration among cameras and enforces the epipolar geometric constraint between different views, which makes it challenging to deploy these methods in distributed camera systems with randomly overlapping fields of view. Meanwhile, distributed source coding theory indicates that efficient data compression of correlated sources can be achieved by independent encoding and joint decoding, which motivates us to design a learning-based distributed multi-view image coding (LDMIC) framework. With independent encoders, LDMIC introduces a simple yet effective joint context transfer module based on the cross-attention mechanism at the decoder to effectively capture the global inter-view correlations, which is insensitive to the geometric relationships between images. Experimental results show that LDMIC significantly outperforms both traditional and learning-based MIC methods while enjoying fast encoding speed. Code will be released at https://github.com/Xinjie-Q/LDMIC.
A Generalized Framework for Critical Heat Flux Detection Using Unsupervised Image-to-Image Translation
Dec 25, 2022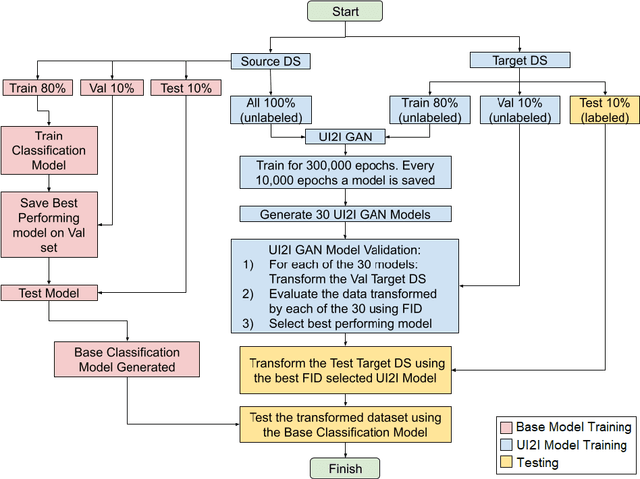
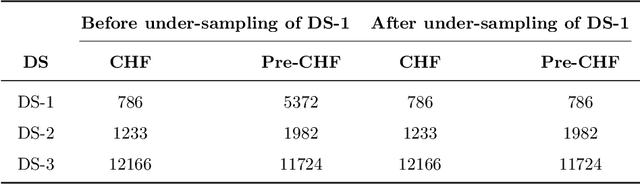
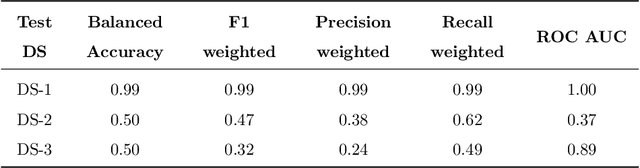

This work proposes a framework developed to generalize Critical Heat Flux (CHF) detection classification models using an Unsupervised Image-to-Image (UI2I) translation model. The framework enables a typical classification model that was trained and tested on boiling images from domain A to predict boiling images coming from domain B that was never seen by the classification model. This is done by using the UI2I model to transform the domain B images to look like domain A images that the classification model is familiar with. Although CNN was used as the classification model and Fixed-Point GAN (FP-GAN) was used as the UI2I model, the framework is model agnostic. Meaning, that the framework can generalize any image classification model type, making it applicable to a variety of similar applications and not limited to the boiling crisis detection problem. It also means that the more the UI2I models advance, the better the performance of the framework.