 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adapting Pre-trained Vision Transformers from 2D to 3D through Weight Inflation Improves Medical Image Segmentation
Feb 08, 2023
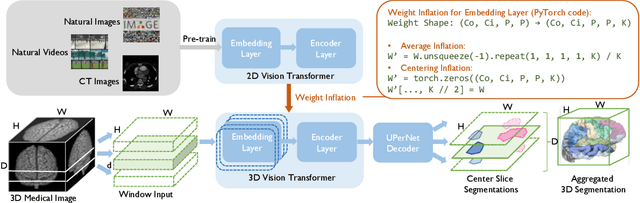
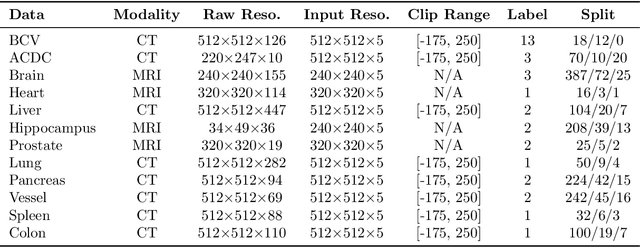
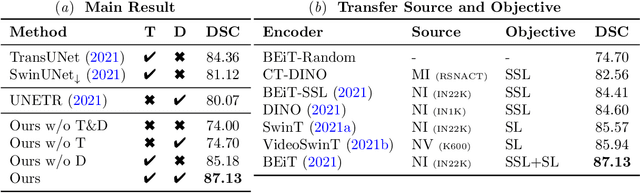
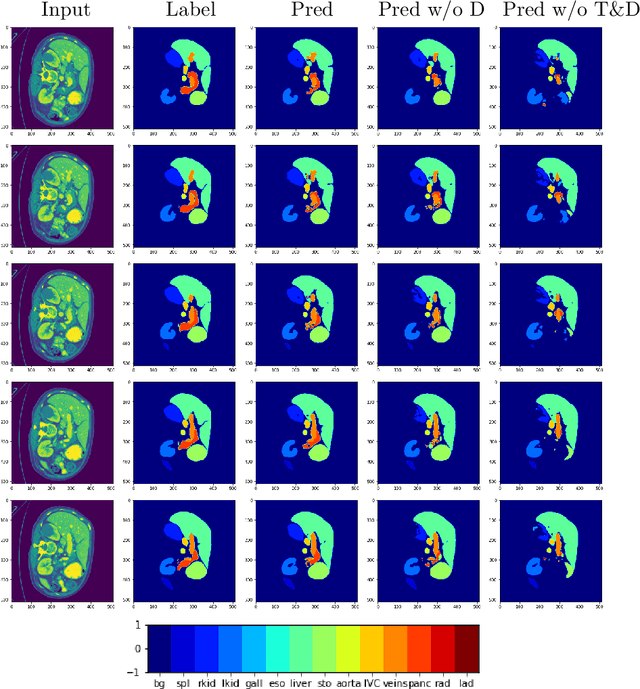
Given the prevalence of 3D medical imaging technologies such as MRI and CT that are widely used in diagnosing and treating diverse diseases, 3D segmentation is one of the fundamental tasks of medical image analysis. Recently, Transformer-based models have started to achieve state-of-the-art performances across many vision tasks, through pre-training on large-scale natural image benchmark datasets. While works on medical image analysis have also begun to explore Transformer-based models, there is currently no optimal strategy to effectively leverage pre-trained Transformers, primarily due to the difference in dimensionality between 2D natural images and 3D medical images. Existing solutions either split 3D images into 2D slices and predict each slice independently, thereby losing crucial depth-wise information, or modify the Transformer architecture to support 3D inputs without leveraging pre-trained weights. In this work, we use a simple yet effective weight inflation strategy to adapt pre-trained Transformers from 2D to 3D, retaining the benefit of both transfer learning and depth information. We further investigate the effectiveness of transfer from different pre-training sources and objectives. Our approach achieves state-of-the-art performances across a broad range of 3D medical image datasets, and can become a standard strategy easily utilized by all work on Transformer-based models for 3D medical images, to maximize performance.
Content-Adaptive Downsampling in Convolutional Neural Networks
May 16, 2023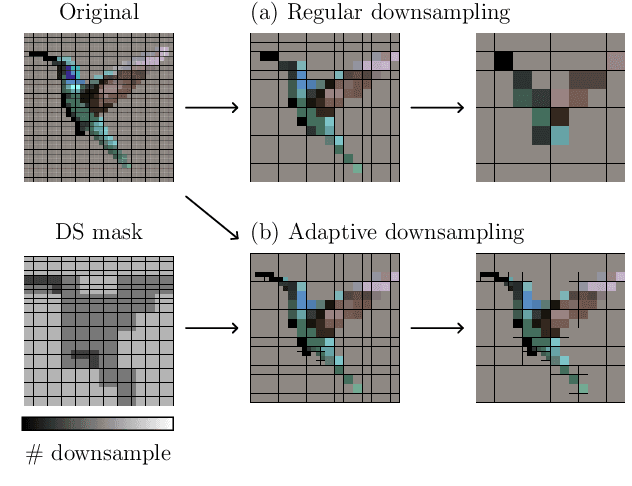
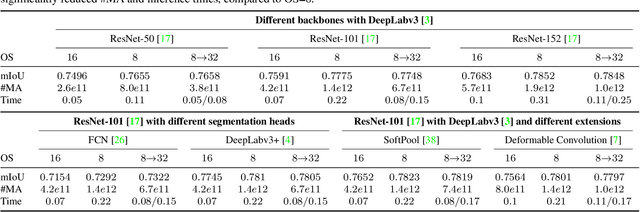
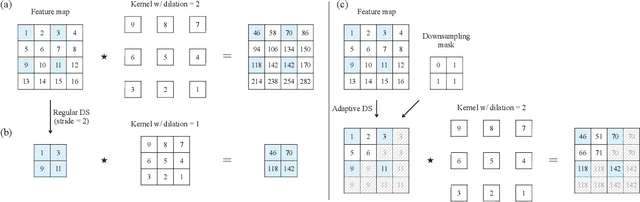
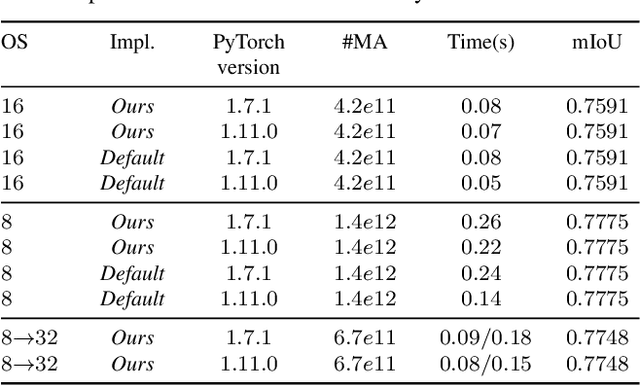
Many convolutional neural networks (CNNs) rely on progressive downsampling of their feature maps to increase the network's receptive field and decrease computational cost. However, this comes at the price of losing granularity in the feature maps, limiting the ability to correctly understand images or recover fine detail in dense prediction tasks. To address this, common practice is to replace the last few downsampling operations in a CNN with dilated convolutions, allowing to retain the feature map resolution without reducing the receptive field, albeit increasing the computational cost. This allows to trade off predictive performance against cost, depending on the output feature resolution. By either regularly downsampling or not downsampling the entire feature map, existing work implicitly treats all regions of the input image and subsequent feature maps as equally important, which generally does not hold. We propose an adaptive downsampling scheme that generalizes the above idea by allowing to process informative regions at a higher resolution than less informative ones. In a variety of experiments, we demonstrate the versatility of our adaptive downsampling strategy and empirically show that it improves the cost-accuracy trade-off of various established CNNs.
Consensus and Subjectivity of Skin Tone Annotation for ML Fairness
May 16, 2023

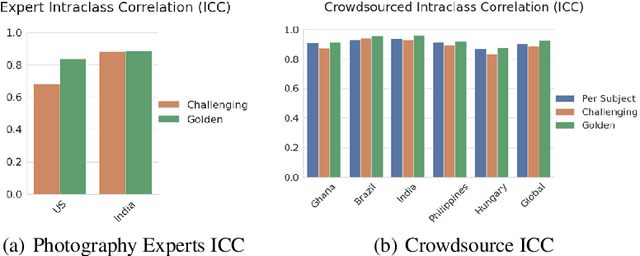
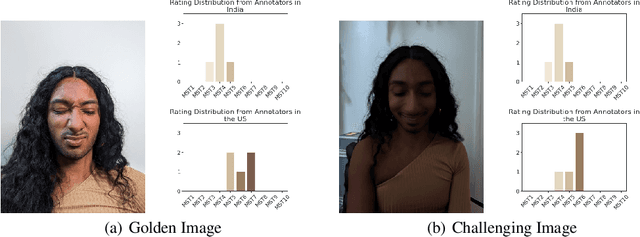
Recent advances in computer vision fairness have relied on datasets augmented with perceived attribute signals (e.g. gender presentation, skin tone, and age) and benchmarks enabled by these datasets. Typically labels for these tasks come from human annotators. However, annotating attribute signals, especially skin tone, is a difficult and subjective task. Perceived skin tone is affected by technical factors, like lighting conditions, and social factors that shape an annotator's lived experience. This paper examines the subjectivity of skin tone annotation through a series of annotation experiments using the Monk Skin Tone (MST) scale, a small pool of professional photographers, and a much larger pool of trained crowdsourced annotators. Our study shows that annotators can reliably annotate skin tone in a way that aligns with an expert in the MST scale, even under challenging environmental conditions. We also find evidence that annotators from different geographic regions rely on different mental models of MST categories resulting in annotations that systematically vary across regions. Given this, we advise practitioners to use a diverse set of annotators and a higher replication count for each image when annotating skin tone for fairness research.
Universal Domain Adaptation for Remote Sensing Image Scene Classification
Jan 26, 2023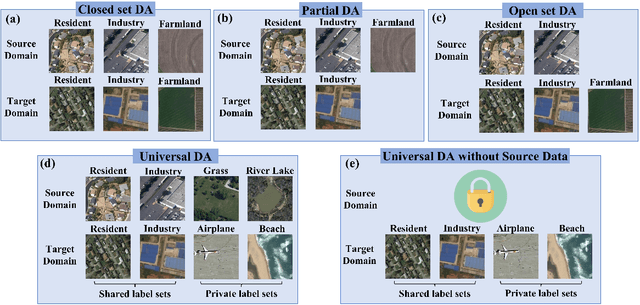
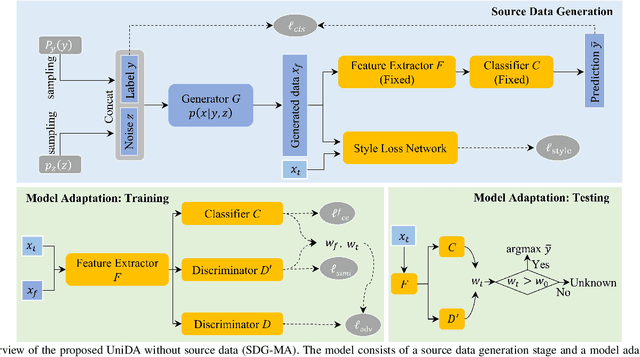

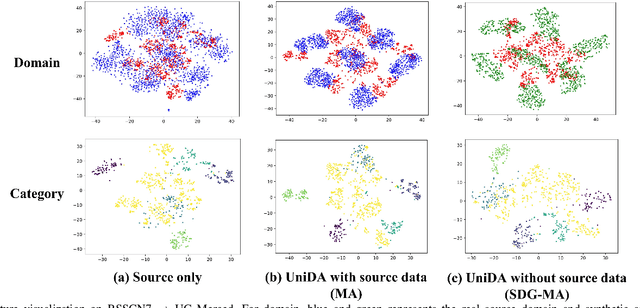
The domain adaptation (DA) approaches available to date are usually not well suited for practical DA scenarios of remote sensing image classification, since these methods (such as unsupervised DA) rely on rich prior knowledge about the relationship between label sets of source and target domains, and source data are often not accessible due to privacy or confidentiality issues. To this end, we propose a practical universal domain adaptation setting for remote sensing image scene classification that requires no prior knowledge on the label sets. Furthermore, a novel universal domain adaptation method without source data is proposed for cases when the source data is unavailable. The architecture of the model is divided into two parts: the source data generation stage and the model adaptation stage. The first stage estimates the conditional distribution of source data from the pre-trained model using the knowledge of class-separability in the source domain and then synthesizes the source data. With this synthetic source data in hand, it becomes a universal DA task to classify a target sample correctly if it belongs to any category in the source label set, or mark it as ``unknown" otherwise. In the second stage, a novel transferable weight that distinguishes the shared and private label sets in each domain promotes the adaptation in the automatically discovered shared label set and recognizes the ``unknown'' samples successfully. Empirical results show that the proposed model is effective and practical for remote sensing image scene classification, regardless of whether the source data is available or not. The code is available at https://github.com/zhu-xlab/UniDA.
ReMark: Receptive Field based Spatial WaterMark Embedding Optimization using Deep Network
May 11, 2023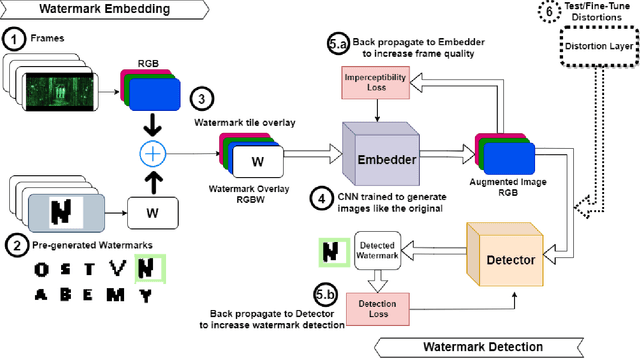
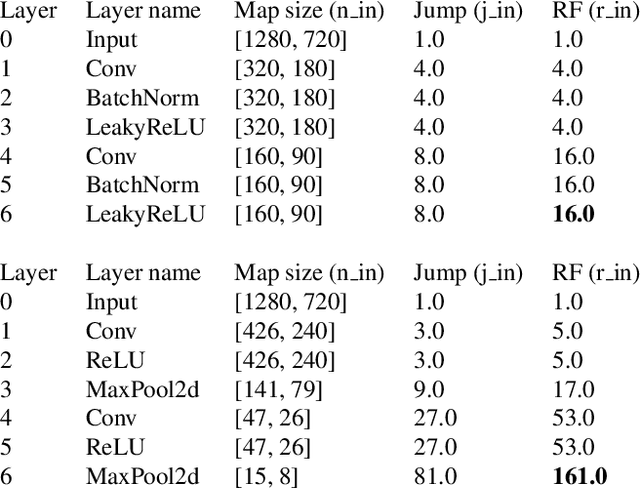
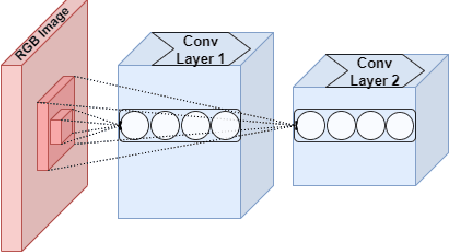
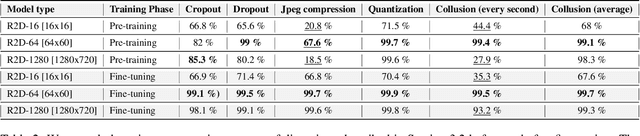
Watermarking is one of the most important copyright protection tools for digital media. The most challenging type of watermarking is the imperceptible one, which embeds identifying information in the data while retaining the latter's original quality. To fulfill its purpose, watermarks need to withstand various distortions whose goal is to damage their integrity. In this study, we investigate a novel deep learning-based architecture for embedding imperceptible watermarks. The key insight guiding our architecture design is the need to correlate the dimensions of our watermarks with the sizes of receptive fields (RF) of modules of our architecture. This adaptation makes our watermarks more robust, while also enabling us to generate them in a way that better maintains image quality. Extensive evaluations on a wide variety of distortions show that the proposed method is robust against most common distortions on watermarks including collusive distortion.
Radious: Unveiling the Enigma of Dental Radiology with BEIT Adaptor and Mask2Former in Semantic Segmentation
May 10, 2023
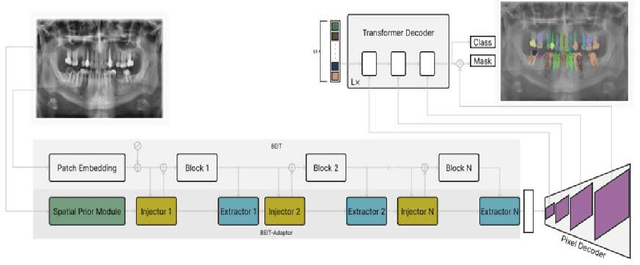
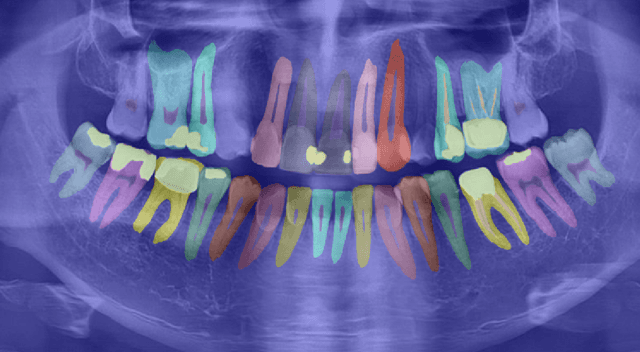
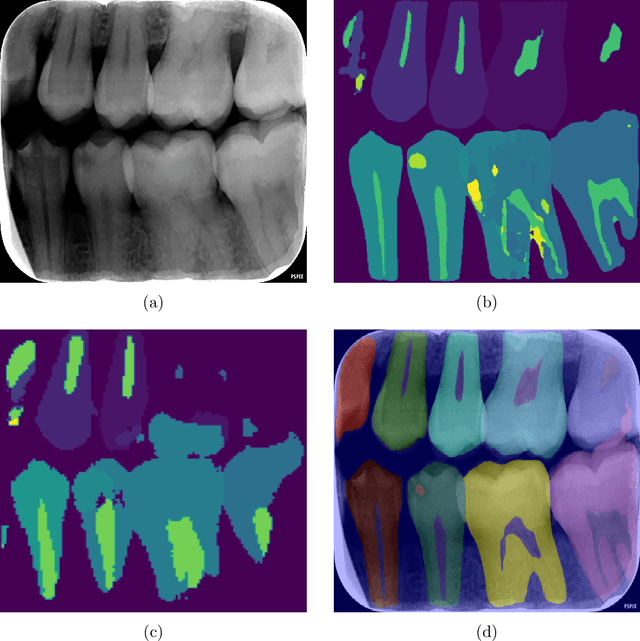
X-ray images are the first steps for diagnosing and further treating dental problems. So, early diagnosis prevents the development and increase of oral and dental diseases. In this paper, we developed a semantic segmentation algorithm based on BEIT adaptor and Mask2Former to detect and identify teeth, roots, and multiple dental diseases and abnormalities such as pulp chamber, restoration, endodontics, crown, decay, pin, composite, bridge, pulpitis, orthodontics, radicular cyst, periapical cyst, cyst, implant, and bone graft material in panoramic, periapical, and bitewing X-ray images. We compared the result of our algorithm to two state-of-the-art algorithms in image segmentation named: Deeplabv3 and Segformer on our own data set. We discovered that Radious outperformed those algorithms by increasing the mIoU scores by 9% and 33% in Deeplabv3+ and Segformer, respectively.
Supervised Multi-Regional Segmentation Machine Learning Architecture for Digital Twin Applications in Coastal Regions
May 23, 2023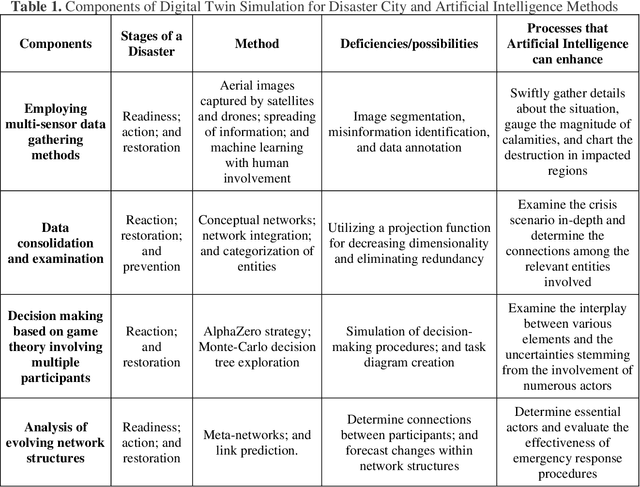
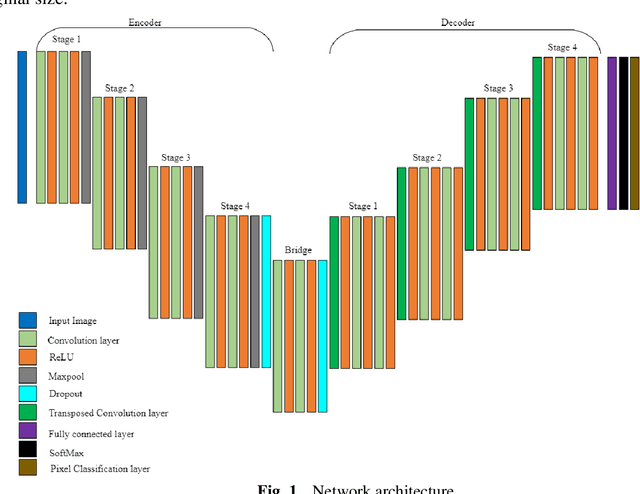
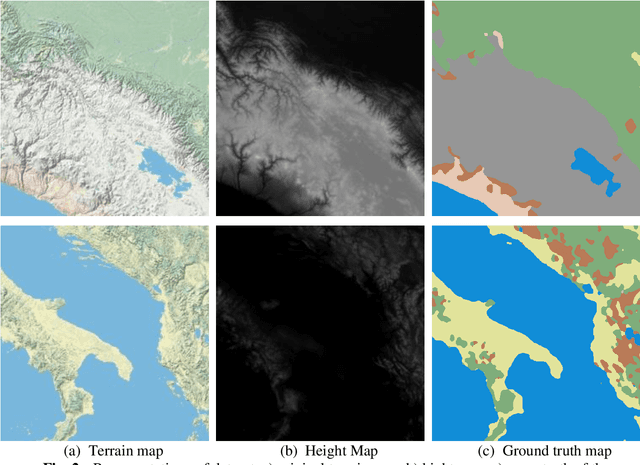
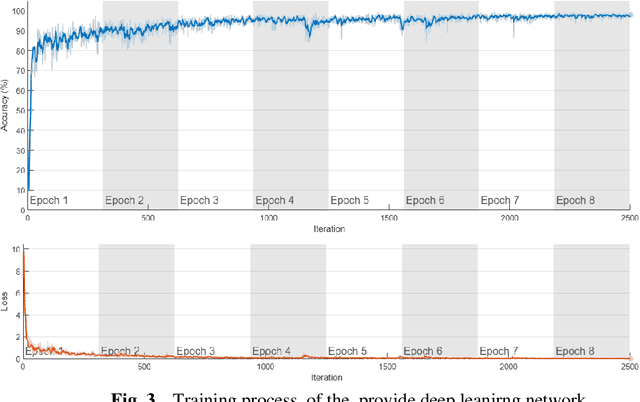
This study explores the use of a digital twin model and deep learning method to build a global terrain and altitude map based on USGS information. The goal is to artistically represent various landforms while incorporating precise elevation modifications in the terrain map and encoding land height in the altitude map. A random selection of 5000 segments from the worldwide map guarantees the inclusion of significant characteristics in the subsets, with rescaling according to latitude accounting for distortions caused by map projection. The process of generating segmentation maps involves using unsupervised clustering and classification methods, segmenting the terrain into seven groups: Water, Grassland, Forest, Hills, Desert, Mountain, and Tundra. Each group is assigned a unique color, and median filtering is used to improve map characteristics. Random parameters are added to provide diversity and avoid duplication in overlapping image sets. The U-Net network is deployed for the segmentation task, with training conducted on the seven terrain classes. Cross-validation is carried out every 10 epochs to gauge the model's performance. The segmentation maps produced accurately categorize the terrain, as evidenced by the ROC curve and AUC values. The main goal of this research is to create a digital twin model of Florida's coastal area. This is achieved through the application of deep learning methods and satellite imagery from Google Earth, resulting in a detailed depiction of the coast of Florida. The digital twin acts as both a physical and a simulation model of the area, emphasizing its capability to capture and replicate real-world locations. The model effectively creates a global terrain and altitude map with precise segmentation and capture of important land features. The results confirm the effectiveness of the digital twin, especially in depicting Florida's coastline.
SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections
Feb 02, 2023
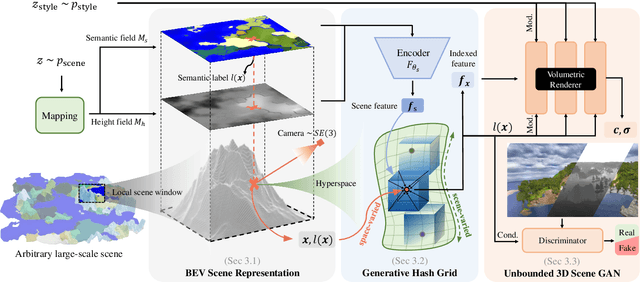
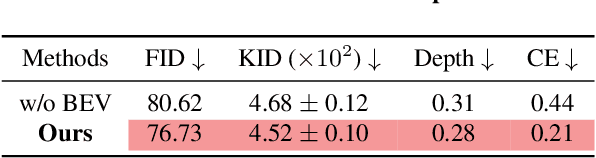
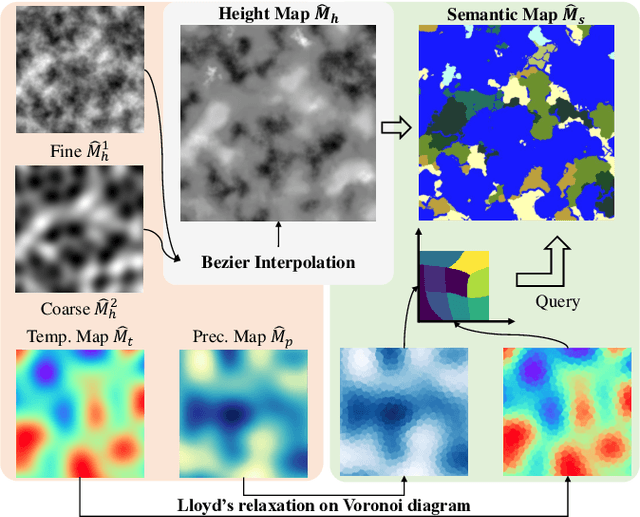
In this work, we present SceneDreamer, an unconditional generative model for unbounded 3D scenes, which synthesizes large-scale 3D landscapes from random noises. Our framework is learned from in-the-wild 2D image collections only, without any 3D annotations. At the core of SceneDreamer is a principled learning paradigm comprising 1) an efficient yet expressive 3D scene representation, 2) a generative scene parameterization, and 3) an effective renderer that can leverage the knowledge from 2D images. Our framework starts from an efficient bird's-eye-view (BEV) representation generated from simplex noise, which consists of a height field and a semantic field. The height field represents the surface elevation of 3D scenes, while the semantic field provides detailed scene semantics. This BEV scene representation enables 1) representing a 3D scene with quadratic complexity, 2) disentangled geometry and semantics, and 3) efficient training. Furthermore, we propose a novel generative neural hash grid to parameterize the latent space given 3D positions and the scene semantics, which aims to encode generalizable features across scenes. Lastly, a neural volumetric renderer, learned from 2D image collections through adversarial training, is employed to produce photorealistic images. Extensive experiments demonstrate the effectiveness of SceneDreamer and superiority over state-of-the-art methods in generating vivid yet diverse unbounded 3D worlds.
Deep Learning-Based UAV Aerial Triangulation without Image Control Points
Jan 07, 2023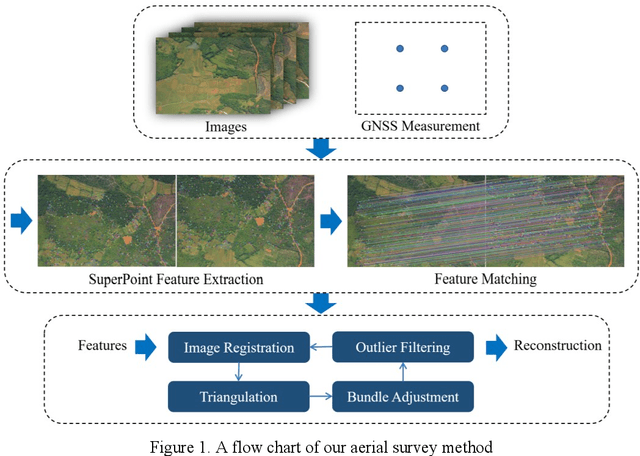
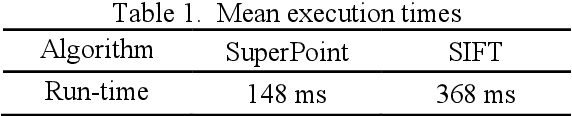
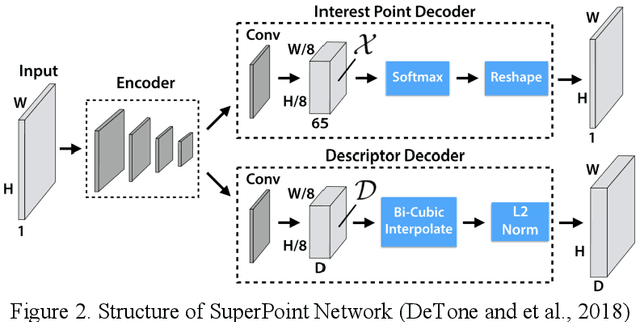
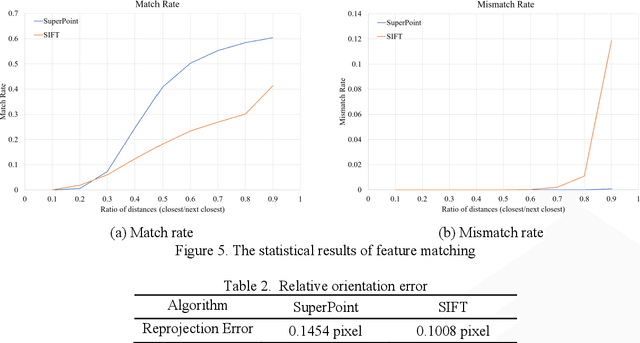
The emerging drone aerial survey has the advantages of low cost, high efficiency, and flexible use. However, UAVs are often equipped with cheap POS systems and non-measurement cameras, and their flight attitudes are easily affected. How to realize the large-scale mapping of UAV image-free control supported by POS faces many technical problems. The most basic and important core technology is how to accurately realize the absolute orientation of images through advanced aerial triangulation technology. In traditional aerial triangulation, image matching algorithms are constrained to varying degrees by preset prior knowledge. In recent years, deep learning has developed rapidly in the field of photogrammetric computer vision. It has surpassed the performance of traditional handcrafted features in many aspects. It has shown stronger stability in image-based navigation and positioning tasks, especially it has better resistance to unfavorable factors such as blur, illumination changes, and geometric distortion. Based on the introduction of the key technologies of aerial triangulation without image control points, this paper proposes a new drone image registration method based on deep learning image features to solve the problem of high mismatch rate in traditional methods. It adopts SuperPoint as the feature detector, uses the superior generalization performance of CNN to extract precise feature points from the UAV image, thereby achieving high-precision aerial triangulation. Experimental results show that under the same pre-processing and post-processing conditions, compared with the traditional method based on the SIFT algorithm, this method achieves suitable precision more efficiently, which can meet the requirements of UAV aerial triangulation without image control points in large-scale surveys.
Anatomical Invariance Modeling and Semantic Alignment for Self-supervised Learning in 3D Medical Image Segmentation
Feb 11, 2023
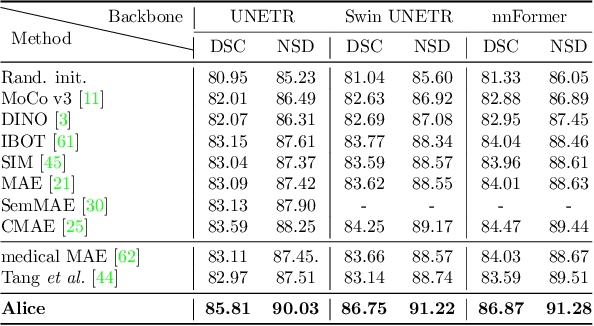
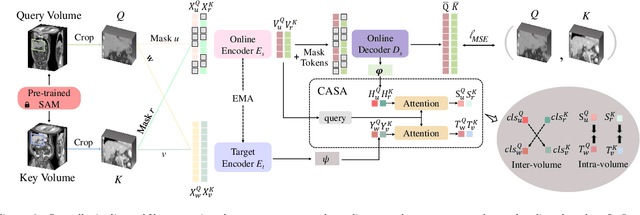
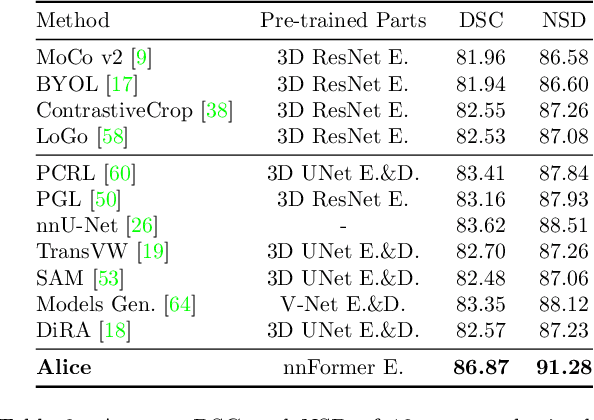
Self-supervised learning (SSL) has recently achieved promising performance for 3D medical image segmentation tasks. Most current methods follow existing SSL paradigm originally designed for photographic or natural images, which cannot explicitly and thoroughly exploit the intrinsic similar anatomical structures across varying medical images. This may in fact degrade the quality of learned deep representations by maximizing the similarity among features containing spatial misalignment information and different anatomical semantics. In this work, we propose a new self-supervised learning framework, namely Alice, that explicitly fulfills Anatomical invariance modeling and semantic alignment via elaborately combining discriminative and generative objectives. Alice introduces a new contrastive learning strategy which encourages the similarity between views that are diversely mined but with consistent high-level semantics, in order to learn invariant anatomical features. Moreover, we design a conditional anatomical feature alignment module to complement corrupted embeddings with globally matched semantics and inter-patch topology information, conditioned by the distribution of local image content, which permits to create better contrastive pairs. Our extensive quantitative experiments on two public 3D medical image segmentation benchmarks of FLARE 2022 and BTCV demonstrate and validate the performance superiority of Alice, surpassing the previous best SSL counterpart methods by 2.11% and 1.77% in Dice coefficients, respectively.