 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Representation Learning via Manifold Flattening and Reconstruction
May 12, 2023
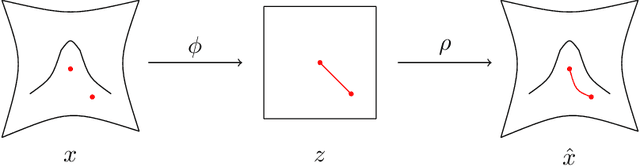
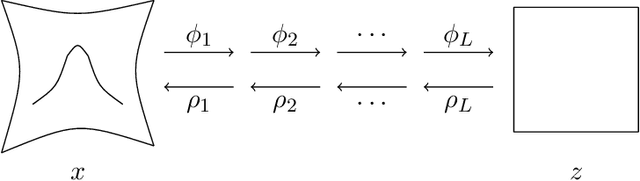
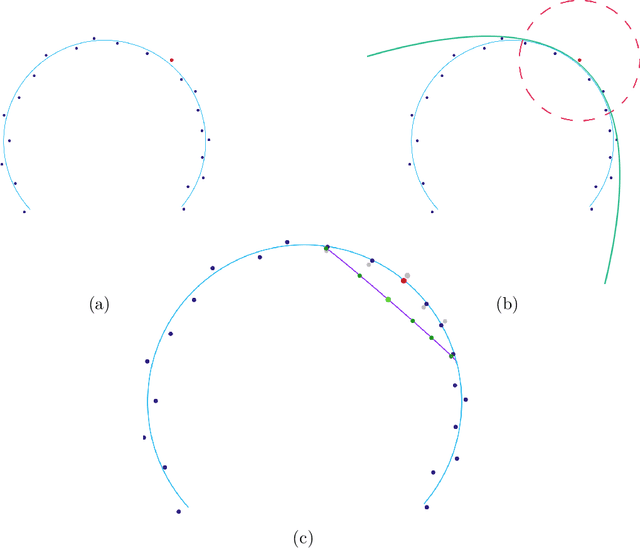
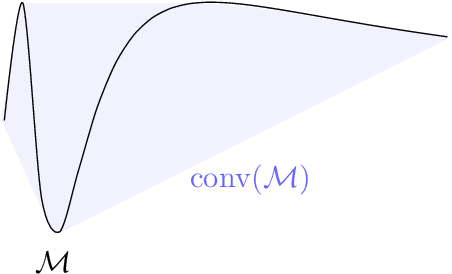
This work proposes an algorithm for explicitly constructing a pair of neural networks that linearize and reconstruct an embedded submanifold, from finite samples of this manifold. Our such-generated neural networks, called Flattening Networks (FlatNet), are theoretically interpretable, computationally feasible at scale, and generalize well to test data, a balance not typically found in manifold-based learning methods. We present empirical results and comparisons to other models on synthetic high-dimensional manifold data and 2D image data. Our code is publicly available.
ReConPatch : Contrastive Patch Representation Learning for Industrial Anomaly Detection
May 26, 2023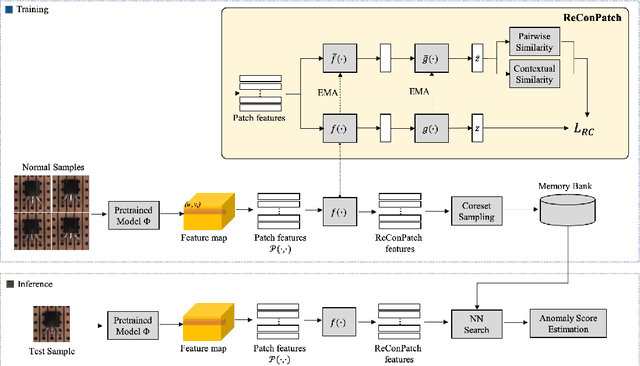
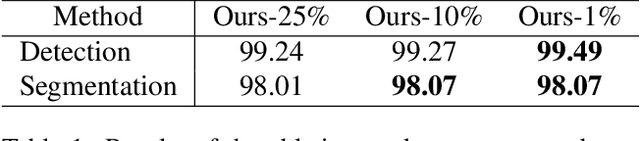
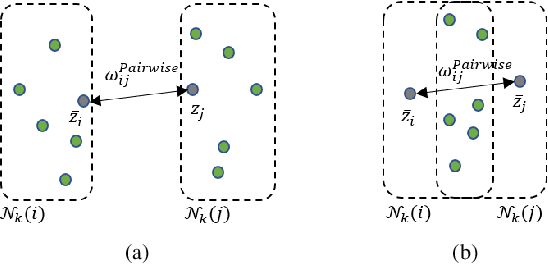
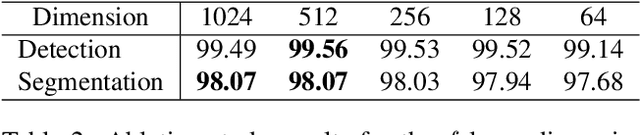
Anomaly detection is crucial to the advanced identification of product defects such as incorrect parts, misaligned components, and damages in industrial manufacturing. Due to the rare observations and unknown types of defects, anomaly detection is considered to be challenging in machine learning. To overcome this difficulty, recent approaches utilize the common visual representations from natural image datasets and distill the relevant features. However, existing approaches still have the discrepancy between the pre-trained feature and the target data, or require the input augmentation which should be carefully designed particularly for the industrial dataset. In this paper, we introduce ReConPatch, which constructs discriminative features for anomaly detection by training a linear modulation attached to a pre-trained model. ReConPatch employs contrastive representation learning to collect and distribute features in a way that produces a target-oriented and easily separable representation. To address the absence of labeled pairs for the contrastive learning, we utilize two similarity measures, pairwise and contextual similarities, between data representations as a pseudo-label. Unlike previous work, ReConPatch achieves robust anomaly detection performance without extensive input augmentation. Our method achieves the state-of-the-art anomaly detection performance (99.72%) for the widely used and challenging MVTec AD dataset.
Unsupervised Domain Adaptation for Semantic Segmentation via Feature-space Density Matching
May 09, 2023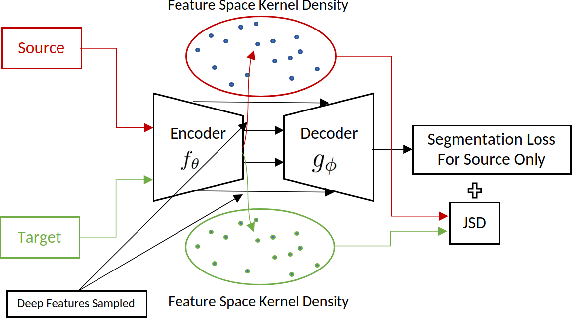
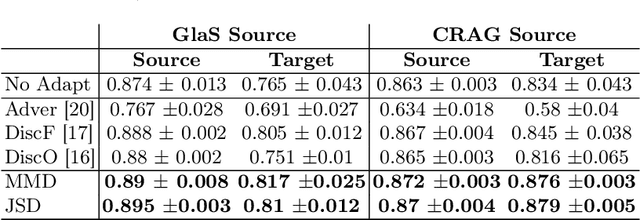

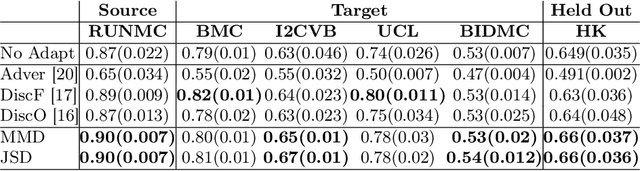
Semantic segmentation is a critical step in automated image interpretation and analysis where pixels are classified into one or more predefined semantically meaningful classes. Deep learning approaches for semantic segmentation rely on harnessing the power of annotated images to learn features indicative of these semantic classes. Nonetheless, they often fail to generalize when there is a significant domain (i.e., distributional) shift between the training (i.e., source) data and the dataset(s) encountered when deployed (i.e., target), necessitating manual annotations for the target data to achieve acceptable performance. This is especially important in medical imaging because different image modalities have significant intra- and inter-site variations due to protocol and vendor variability. Current techniques are sensitive to hyperparameter tuning and target dataset size. This paper presents an unsupervised domain adaptation approach for semantic segmentation that alleviates the need for annotating target data. Using kernel density estimation, we match the target data distribution to the source data in the feature space. We demonstrate that our results are comparable or superior on multiple-site prostate MRI and histopathology images, which mitigates the need for annotating target data.
Building Multimodal AI Chatbots
Apr 21, 2023
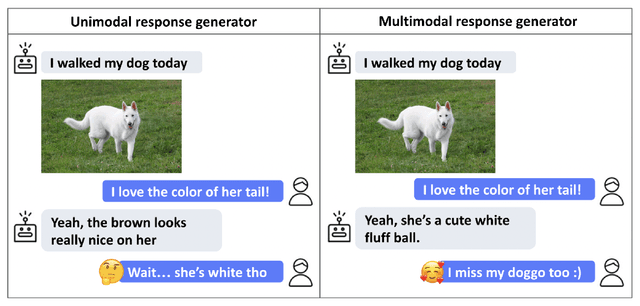
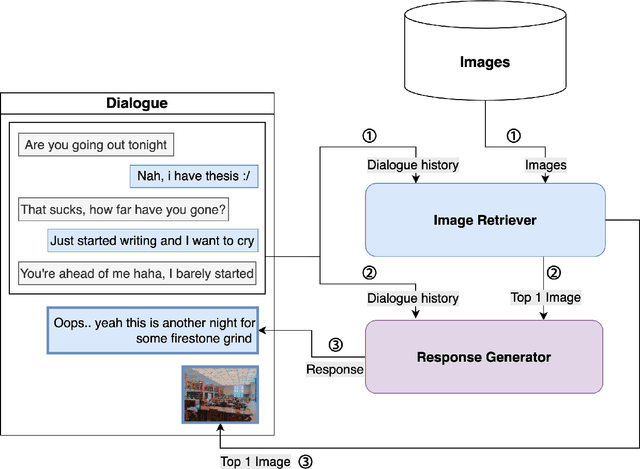
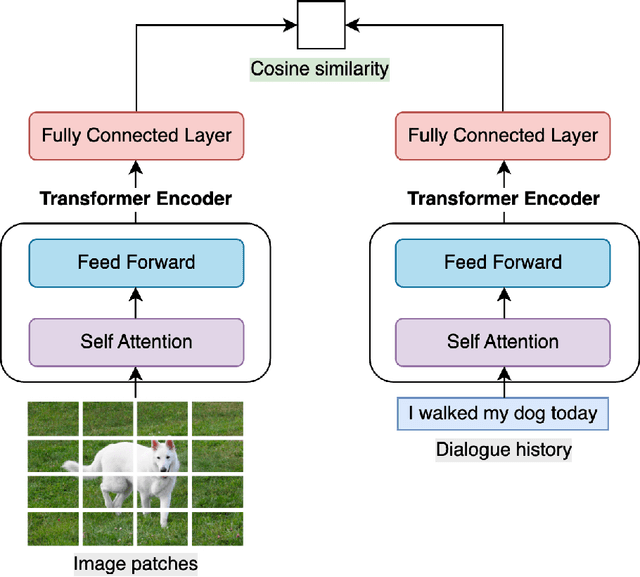
This work aims to create a multimodal AI system that chats with humans and shares relevant photos. While earlier works were limited to dialogues about specific objects or scenes within images, recent works have incorporated images into open-domain dialogues. However, their response generators are unimodal, accepting text input but no image input, thus prone to generating responses contradictory to the images shared in the dialogue. Therefore, this work proposes a complete chatbot system using two multimodal deep learning models: an image retriever that understands texts and a response generator that understands images. The image retriever, implemented by ViT and BERT, selects the most relevant image given the dialogue history and a database of images. The response generator, implemented by ViT and GPT-2/DialoGPT, generates an appropriate response given the dialogue history and the most recently retrieved image. The two models are trained and evaluated on PhotoChat, an open-domain dialogue dataset in which a photo is shared in each session. In automatic evaluation, the proposed image retriever outperforms existing baselines VSE++ and SCAN with Recall@1/5/10 of 0.1/0.3/0.4 and MRR of 0.2 when ranking 1,000 images. The proposed response generator also surpasses the baseline Divter with PPL of 16.9, BLEU-1/2 of 0.13/0.03, and Distinct-1/2 of 0.97/0.86, showing a significant improvement in PPL by -42.8 and BLEU-1/2 by +0.07/0.02. In human evaluation with a Likert scale of 1-5, the complete multimodal chatbot system receives higher image-groundedness of 4.3 and engagingness of 4.3, along with competitive fluency of 4.1, coherence of 3.9, and humanness of 3.1, when compared to other chatbot variants. The source code is available at: https://github.com/minniie/multimodal_chat.git.
DNN-Compressed Domain Visual Recognition with Feature Adaptation
May 13, 2023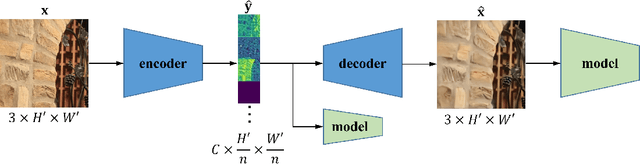
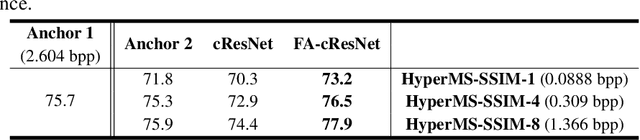
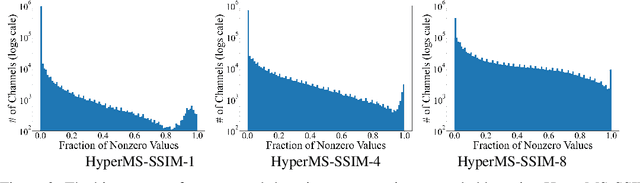

Learning-based image compression was shown to achieve a competitive performance with state-of-the-art transform-based codecs. This motivated the development of new learning-based visual compression standards such as JPEG-AI. Of particular interest to these emerging standards is the development of learning-based image compression systems targeting both humans and machines. This paper is concerned with learning-based compression schemes whose compressed-domain representations can be utilized to perform visual processing and computer vision tasks directly in the compressed domain. In our work, we adopt a learning-based compressed-domain classification framework for performing visual recognition using the compressed-domain latent representation at varying bit-rates. We propose a novel feature adaptation module integrating a lightweight attention model to adaptively emphasize and enhance the key features within the extracted channel-wise information. Also, we design an adaptation training strategy to utilize the pretrained pixel-domain weights. For comparison, in addition to the performance results that are obtained using our proposed latent-based compressed-domain method, we also present performance results using compressed but fully decoded images in the pixel domain as well as original uncompressed images. The obtained performance results show that our proposed compressed-domain classification model can distinctly outperform the existing compressed-domain classification models, and that it can also yield similar accuracy results with a much higher computational efficiency as compared to the pixel-domain models that are trained using fully decoded images.
Global Structure Knowledge-Guided Relation Extraction Method for Visually-Rich Document
May 23, 2023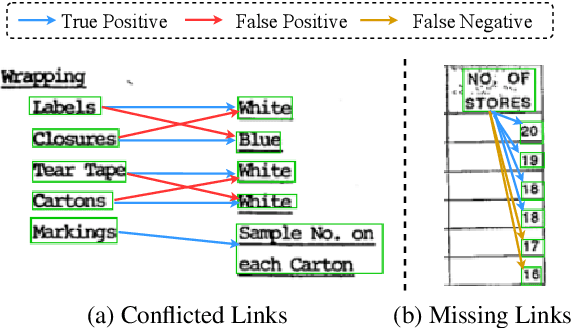
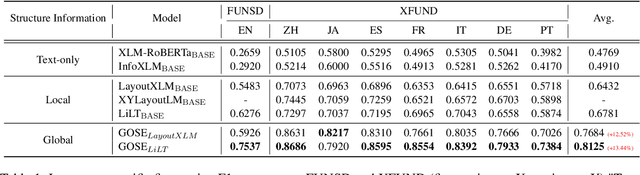
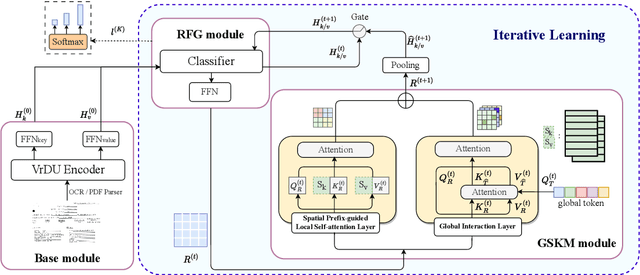
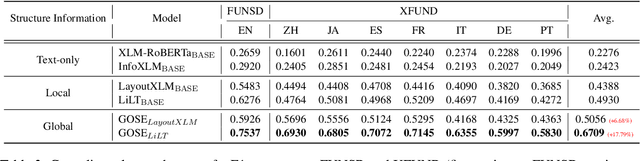
Visual relation extraction (VRE) aims to extract relations between entities from visuallyrich documents. Existing methods usually predict relations for each entity pair independently based on entity features but ignore the global structure information, i.e., dependencies between entity pairs. The absence of global structure information may make the model struggle to learn long-range relations and easily predict conflicted results. To alleviate such limitations, we propose a GlObal Structure knowledgeguided relation Extraction (GOSE) framework, which captures dependencies between entity pairs in an iterative manner. Given a scanned image of the document, GOSE firstly generates preliminary relation predictions on entity pairs. Secondly, it mines global structure knowledge based on prediction results of the previous iteration and further incorporates global structure knowledge into entity representations. This "generate-capture-incorporate" schema is performed multiple times so that entity representations and global structure knowledge can mutually reinforce each other. Extensive experiments show that GOSE not only outperforms previous methods on the standard fine-tuning setting but also shows promising superiority in cross-lingual learning; even yields stronger data-efficient performance in the low-resource setting.
Continual Learning with Strong Experience Replay
May 23, 2023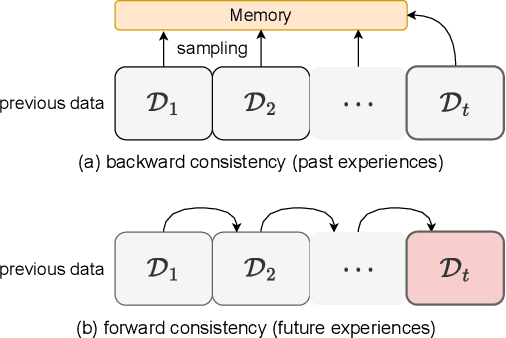
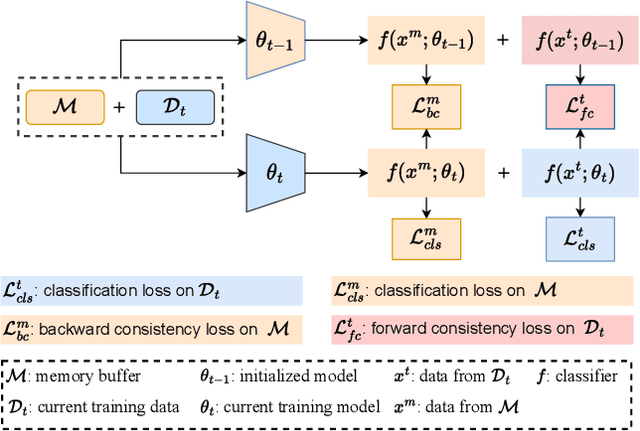
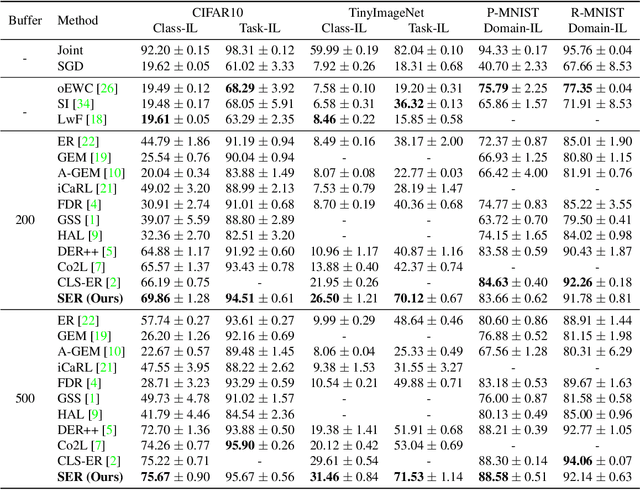
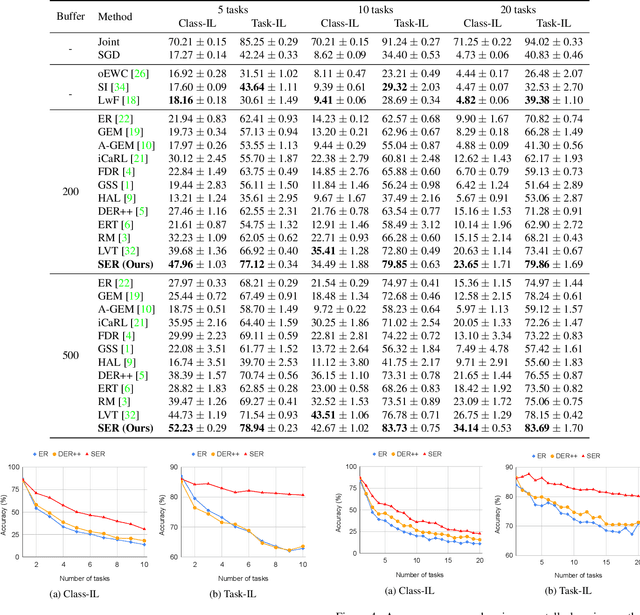
Continual Learning (CL) aims at incrementally learning new tasks without forgetting the knowledge acquired from old ones. Experience Replay (ER) is a simple and effective rehearsal-based strategy, which optimizes the model with current training data and a subset of old samples stored in a memory buffer. To further reduce forgetting, recent approaches extend ER with various techniques, such as model regularization and memory sampling. However, the prediction consistency between the new model and the old one on current training data has been seldom explored, resulting in less knowledge preserved when few previous samples are available. To address this issue, we propose a CL method with Strong Experience Replay (SER), which additionally utilizes future experiences mimicked on the current training data, besides distilling past experience from the memory buffer. In our method, the updated model will produce approximate outputs as its original ones, which can effectively preserve the acquired knowledge. Experimental results on multiple image classification datasets show that our SER method surpasses the state-of-the-art methods by a noticeable margin.
When SAM Meets Medical Images: An Investigation of Segment Anything Model (SAM) on Multi-phase Liver Tumor Segmentation
Apr 21, 2023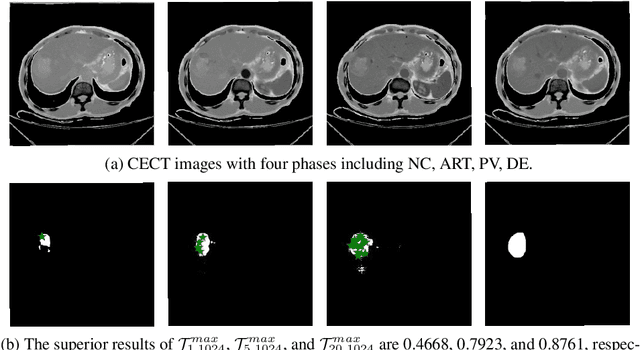
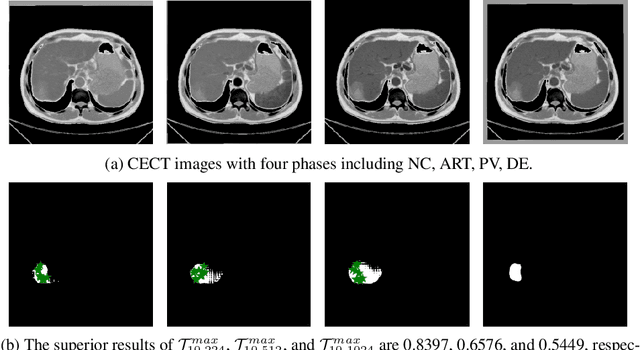
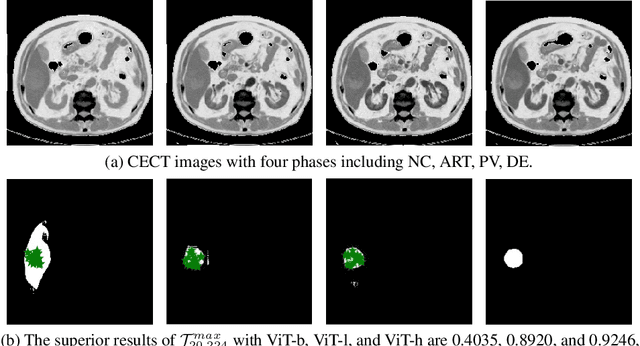
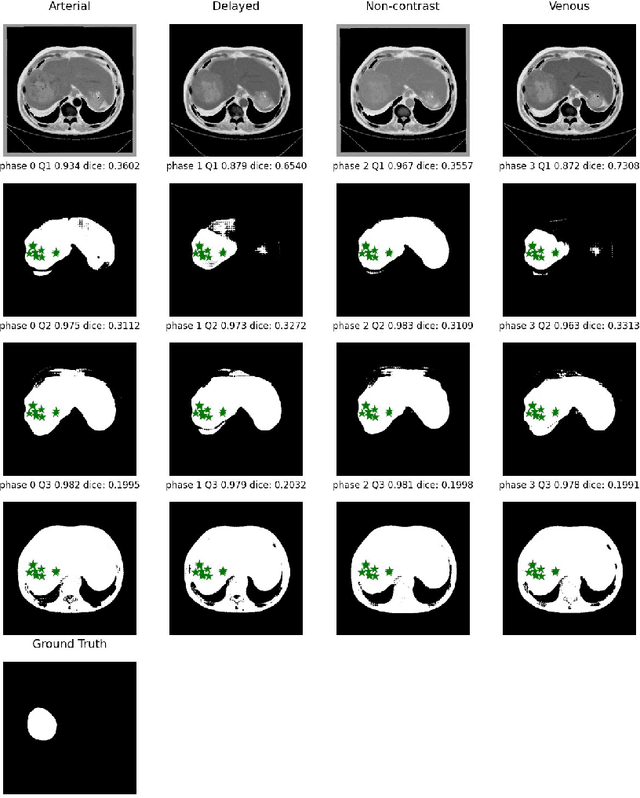
Learning to segmentation without large-scale samples is an inherent capability of human. Recently, Segment Anything Model (SAM) performs the significant zero-shot image segmentation, attracting considerable attention from the computer vision community. Here, we investigate the capability of SAM for medical image analysis, especially for multi-phase liver tumor segmentation (MPLiTS), in terms of prompts, data resolution, phases. Experimental results demonstrate that there might be a large gap between SAM and expected performance. Fortunately, the qualitative results show that SAM is a powerful annotation tool for the community of interactive medical image segmentation.
SAM on Medical Images: A Comprehensive Study on Three Prompt Modes
Apr 28, 2023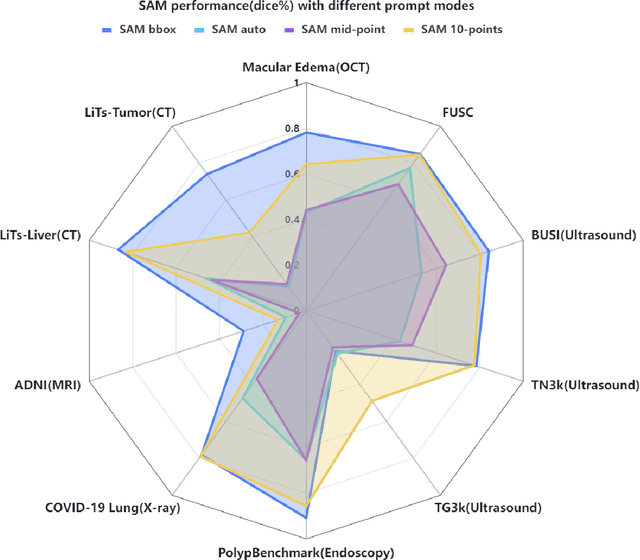
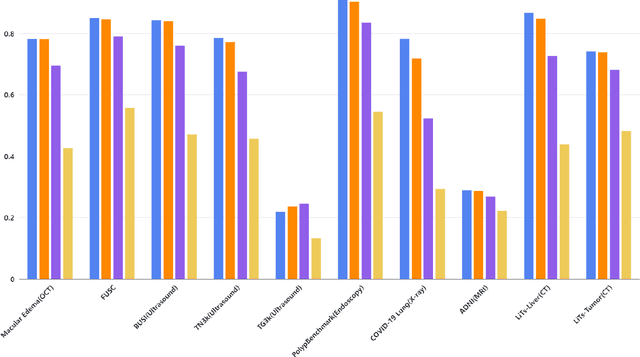
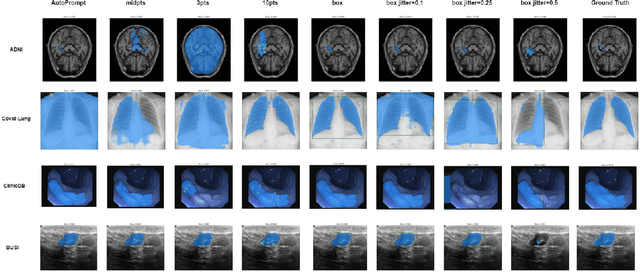

The Segment Anything Model (SAM) made an eye-catching debut recently and inspired many researchers to explore its potential and limitation in terms of zero-shot generalization capability. As the first promptable foundation model for segmentation tasks, it was trained on a large dataset with an unprecedented number of images and annotations. This large-scale dataset and its promptable nature endow the model with strong zero-shot generalization. Although the SAM has shown competitive performance on several datasets, we still want to investigate its zero-shot generalization on medical images. As we know, the acquisition of medical image annotation usually requires a lot of effort from professional practitioners. Therefore, if there exists a foundation model that can give high-quality mask prediction simply based on a few point prompts, this model will undoubtedly become the game changer for medical image analysis. To evaluate whether SAM has the potential to become the foundation model for medical image segmentation tasks, we collected more than 12 public medical image datasets that cover various organs and modalities. We also explore what kind of prompt can lead to the best zero-shot performance with different modalities. Furthermore, we find that a pattern shows that the perturbation of the box size will significantly change the prediction accuracy. Finally, Extensive experiments show that the predicted mask quality varied a lot among different datasets. And providing proper prompts, such as bounding boxes, to the SAM will significantly increase its performance.
HeteroEdge: Addressing Asymmetry in Heterogeneous Collaborative Autonomous Systems
May 05, 2023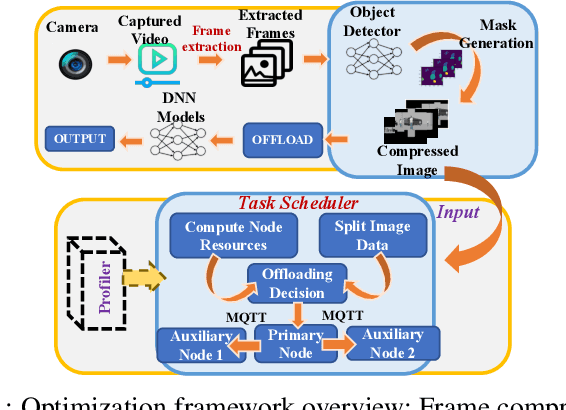

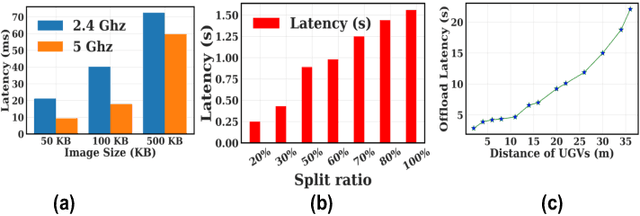

Gathering knowledge about surroundings and generating situational awareness for IoT devices is of utmost importance for systems developed for smart urban and uncontested environments. For example, a large-area surveillance system is typically equipped with multi-modal sensors such as cameras and LIDARs and is required to execute deep learning algorithms for action, face, behavior, and object recognition. However, these systems face power and memory constraints due to their ubiquitous nature, making it crucial to optimize data processing, deep learning algorithm input, and model inference communication. In this paper, we propose a self-adaptive optimization framework for a testbed comprising two Unmanned Ground Vehicles (UGVs) and two NVIDIA Jetson devices. This framework efficiently manages multiple tasks (storage, processing, computation, transmission, inference) on heterogeneous nodes concurrently. It involves compressing and masking input image frames, identifying similar frames, and profiling devices to obtain boundary conditions for optimization.. Finally, we propose and optimize a novel parameter split-ratio, which indicates the proportion of the data required to be offloaded to another device while considering the networking bandwidth, busy factor, memory (CPU, GPU, RAM), and power constraints of the devices in the testbed. Our evaluations captured while executing multiple tasks (e.g., PoseNet, SegNet, ImageNet, DetectNet, DepthNet) simultaneously, reveal that executing 70% (split-ratio=70%) of the data on the auxiliary node minimizes the offloading latency by approx. 33% (18.7 ms/image to 12.5 ms/image) and the total operation time by approx. 47% (69.32s to 36.43s) compared to the baseline configuration (executing on the primary node).