 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Better 3D Knowledge Transfer via Masked Image Modeling for Multi-view 3D Understanding
Mar 20, 2023
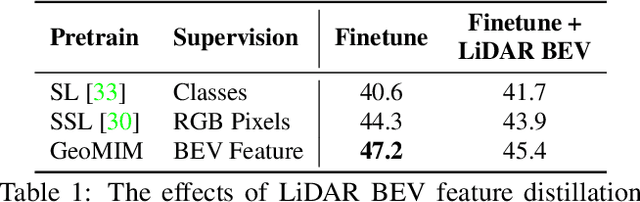
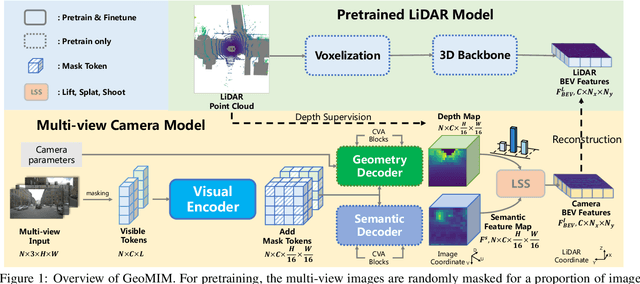
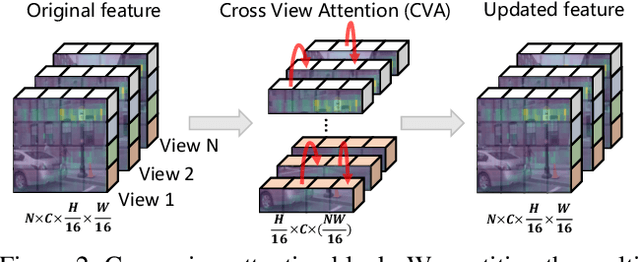
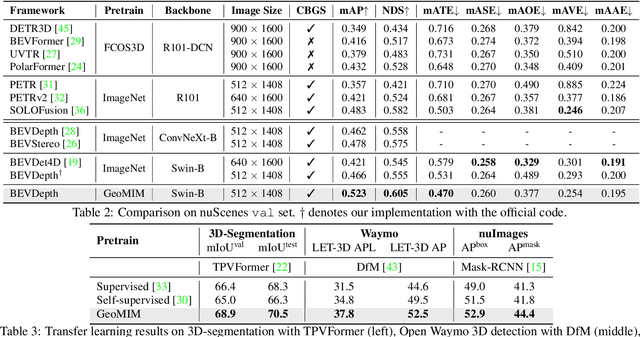
Multi-view camera-based 3D detection is a challenging problem in computer vision. Recent works leverage a pretrained LiDAR detection model to transfer knowledge to a camera-based student network. However, we argue that there is a major domain gap between the LiDAR BEV features and the camera-based BEV features, as they have different characteristics and are derived from different sources. In this paper, we propose Geometry Enhanced Masked Image Modeling (GeoMIM) to transfer the knowledge of the LiDAR model in a pretrain-finetune paradigm for improving the multi-view camera-based 3D detection. GeoMIM is a multi-camera vision transformer with Cross-View Attention (CVA) blocks that uses LiDAR BEV features encoded by the pretrained BEV model as learning targets. During pretraining, GeoMIM's decoder has a semantic branch completing dense perspective-view features and the other geometry branch reconstructing dense perspective-view depth maps. The depth branch is designed to be camera-aware by inputting the camera's parameters for better transfer capability. Extensive results demonstrate that GeoMIM outperforms existing methods on nuScenes benchmark, achieving state-of-the-art performance for camera-based 3D object detection and 3D segmentation.
S-JEA: Stacked Joint Embedding Architectures for Self-Supervised Visual Representation Learning
May 19, 2023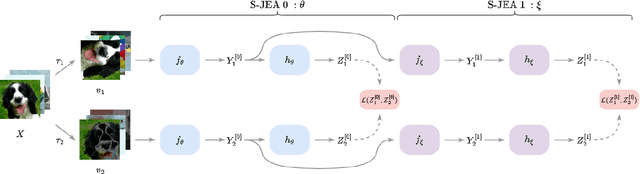
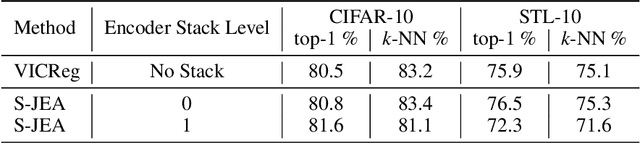

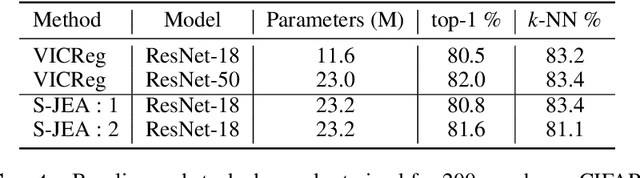
The recent emergence of Self-Supervised Learning (SSL) as a fundamental paradigm for learning image representations has, and continues to, demonstrate high empirical success in a variety of tasks. However, most SSL approaches fail to learn embeddings that capture hierarchical semantic concepts that are separable and interpretable. In this work, we aim to learn highly separable semantic hierarchical representations by stacking Joint Embedding Architectures (JEA) where higher-level JEAs are input with representations of lower-level JEA. This results in a representation space that exhibits distinct sub-categories of semantic concepts (e.g., model and colour of vehicles) in higher-level JEAs. We empirically show that representations from stacked JEA perform on a similar level as traditional JEA with comparative parameter counts and visualise the representation spaces to validate the semantic hierarchies.
Structure-guided Image Outpainting
Dec 21, 2022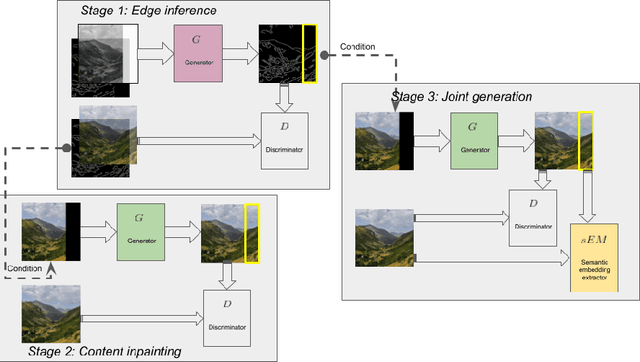
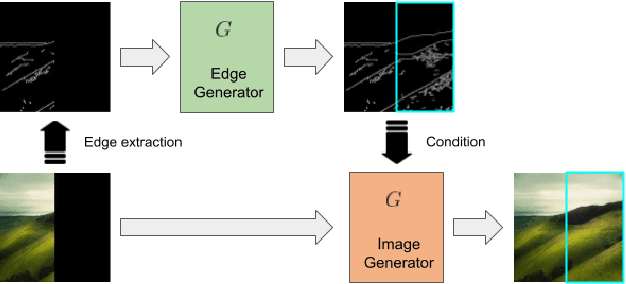


Deep learning techniques have made considerable progress in image inpainting, restoration, and reconstruction in the last few years. Image outpainting, also known as image extrapolation, lacks attention and practical approaches to be fulfilled, owing to difficulties caused by large-scale area loss and less legitimate neighboring information. These difficulties have made outpainted images handled by most of the existing models unrealistic to human eyes and spatially inconsistent. When upsampling through deconvolution to generate fake content, the naive generation methods may lead to results lacking high-frequency details and structural authenticity. Therefore, as our novelties to handle image outpainting problems, we introduce structural prior as a condition to optimize the generation quality and a new semantic embedding term to enhance perceptual sanity. we propose a deep learning method based on Generative Adversarial Network (GAN) and condition edges as structural prior in order to assist the generation. We use a multi-phase adversarial training scheme that comprises edge inference training, contents inpainting training, and joint training. The newly added semantic embedding loss is proved effective in practice.
Edit Everything: A Text-Guided Generative System for Images Editing
Apr 27, 2023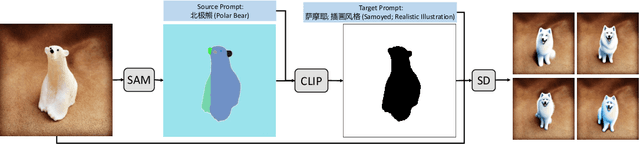

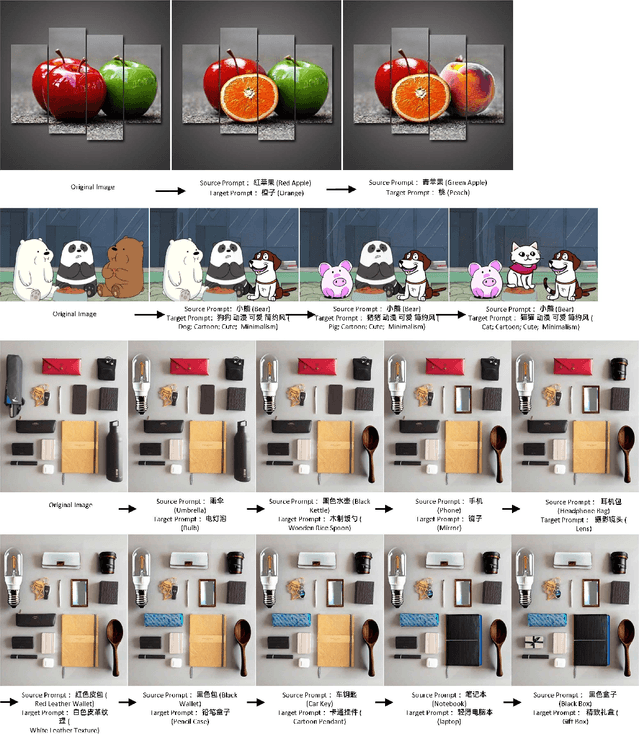

We introduce a new generative system called Edit Everything, which can take image and text inputs and produce image outputs. Edit Everything allows users to edit images using simple text instructions. Our system designs prompts to guide the visual module in generating requested images. Experiments demonstrate that Edit Everything facilitates the implementation of the visual aspects of Stable Diffusion with the use of Segment Anything model and CLIP. Our system is publicly available at https://github.com/DefengXie/Edit_Everything.
Investigating image-based fallow weed detection performance on Raphanus sativus and Avena sativa at speeds up to 30 km h$^{-1}$
May 17, 2023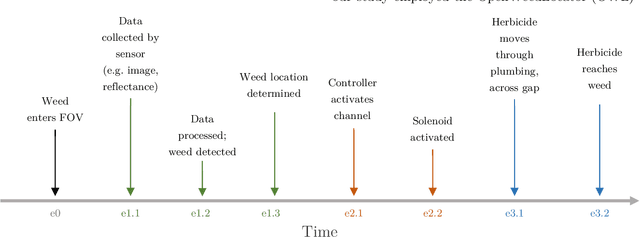
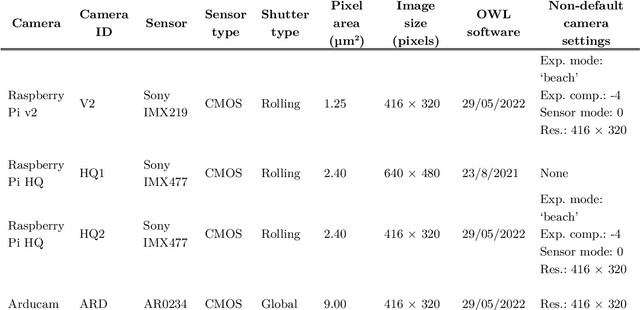

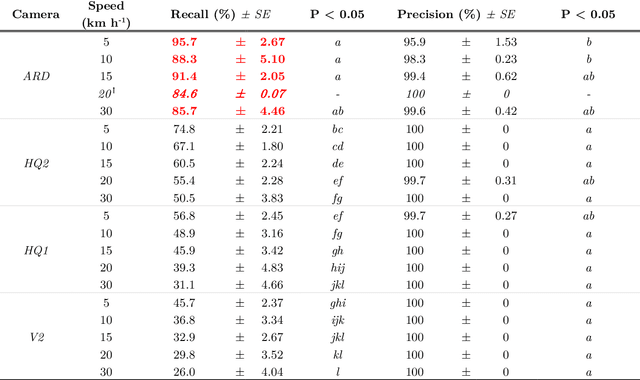
Site-specific weed control (SSWC) can provide considerable reductions in weed control costs and herbicide usage. Despite the promise of machine vision for SSWC systems and the importance of ground speed in weed control efficacy, there has been little investigation of the role of ground speed and camera characteristics on weed detection performance. Here, we compare the performance of four camera-software combinations using the open-source OpenWeedLocator platform - (1) default settings on a Raspberry Pi HQ camera, (2) optimised software settings on a HQ camera, (3) optimised software settings on the Raspberry Pi v2 camera, and (4) a global shutter Arducam AR0234 camera - at speeds ranging from 5 km h$^{-1}$ to 30 km h$^{-1}$. A combined excess green (ExG) and hue, saturation, value (HSV) thresholding algorithm was used for testing under fallow conditions using tillage radish (Raphanus sativus) and forage oats (Avena sativa) as representative broadleaf and grass weeds, respectively. ARD demonstrated the highest recall among camera systems, with up to 95.7% of weeds detected at 5 km h$^{-1}$ and 85.7% at 30 km h$^{-1}$. HQ1 and V2 cameras had the lowest recall of 31.1% and 26.0% at 30 km h$^{-1}$, respectively. All cameras experienced a decrease in recall as speed increased. The highest rate of decrease was observed for HQ1 with 1.12% and 0.90% reductions in recall for every km h$^{-1}$ increase in speed for tillage radish and forage oats, respectively. Detection of the grassy forage oats was worse (P<0.05) than the broadleaved tillage radish for all cameras. Despite the variations in recall, HQ1, HQ2, and V2 maintained near-perfect precision at all tested speeds. The variable effect of ground speed and camera system on detection performance of grass and broadleaf weeds, indicates that careful hardware and software considerations must be made when developing SSWC systems.
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 14, 2023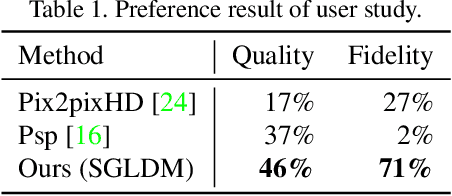

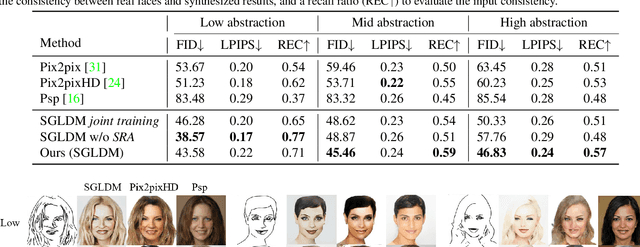
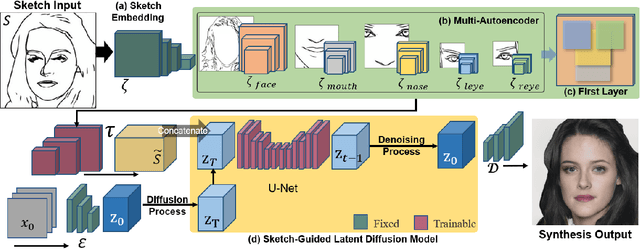
Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
Fair Diffusion: Instructing Text-to-Image Generation Models on Fairness
Feb 07, 2023
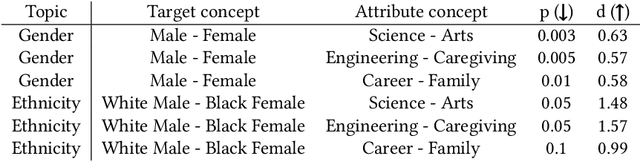
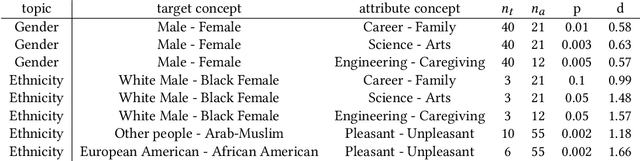
Generative AI models have recently achieved astonishing results in quality and are consequently employed in a fast-growing number of applications. However, since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer from degenerated and biased human behavior, as we demonstrate. In fact, they may even reinforce such biases. To not only uncover but also combat these undesired effects, we present a novel strategy, called Fair Diffusion, to attenuate biases after the deployment of generative text-to-image models. Specifically, we demonstrate shifting a bias, based on human instructions, in any direction yielding arbitrarily new proportions for, e.g., identity groups. As our empirical evaluation demonstrates, this introduced control enables instructing generative image models on fairness, with no data filtering and additional training required.
Multi-object Video Generation from Single Frame Layouts
May 06, 2023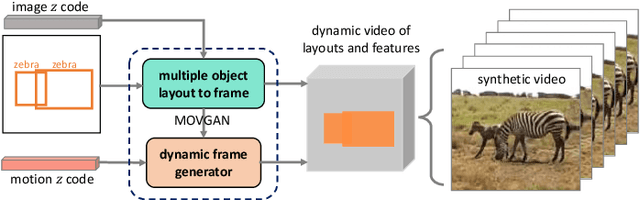
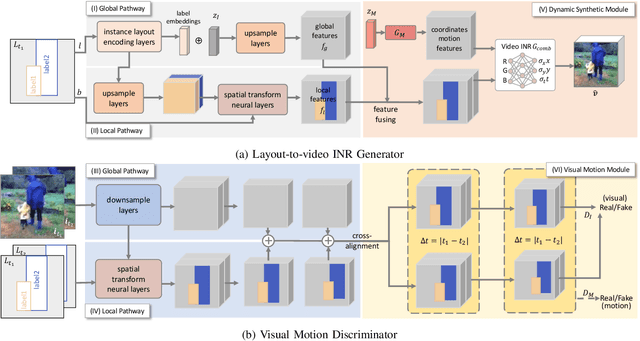

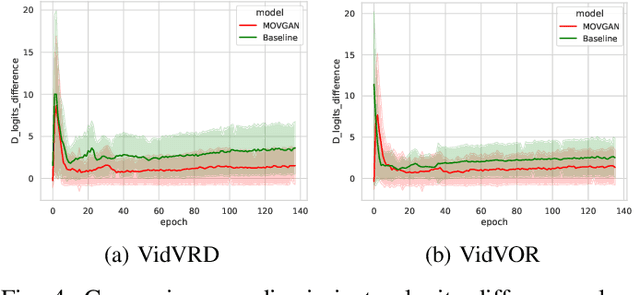
In this paper, we study video synthesis with emphasis on simplifying the generation conditions. Most existing video synthesis models or datasets are designed to address complex motions of a single object, lacking the ability of comprehensively understanding the spatio-temporal relationships among multiple objects. Besides, current methods are usually conditioned on intricate annotations (e.g. video segmentations) to generate new videos, being fundamentally less practical. These motivate us to generate multi-object videos conditioning exclusively on object layouts from a single frame. To solve above challenges and inspired by recent research on image generation from layouts, we have proposed a novel video generative framework capable of synthesizing global scenes with local objects, via implicit neural representations and layout motion self-inference. Our framework is a non-trivial adaptation from image generation methods, and is new to this field. In addition, our model has been evaluated on two widely-used video recognition benchmarks, demonstrating effectiveness compared to the baseline model.
Near-Field MIMO-ISAR Millimeter-Wave Imaging
May 03, 2023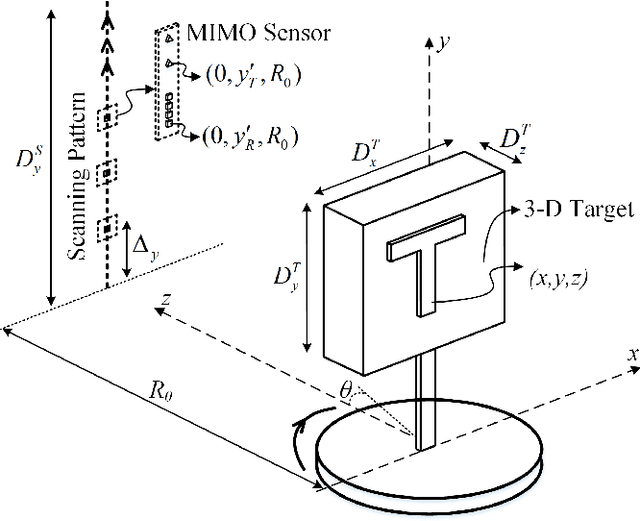
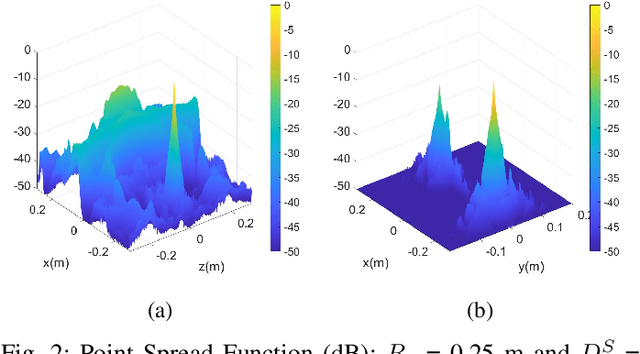
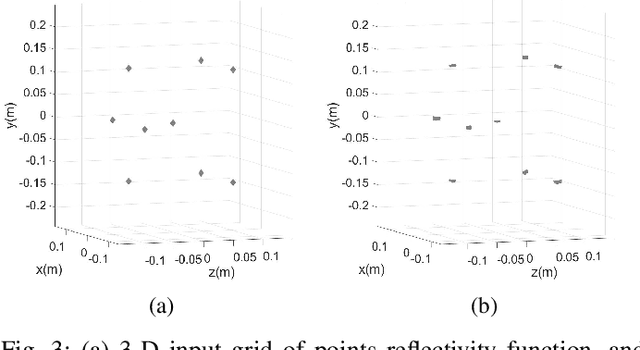
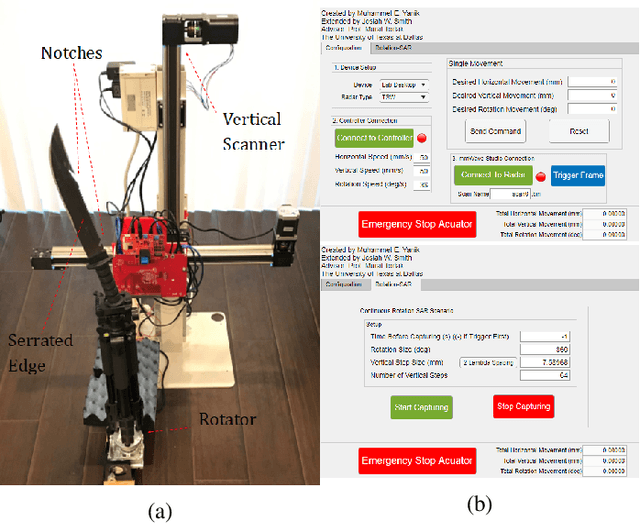
Multiple-input-multiple-output (MIMO) millimeter-wave (mmWave) sensors for synthetic aperture radar (SAR) and inverse SAR (ISAR) address the fundamental challenges of cost-effectiveness and scalability inherent to near-field imaging. In this paper, near-field MIMO-ISAR mmWave imaging systems are discussed and developed. The rotational ISAR (R-ISAR) regime investigated in this paper requires rotating the target at a constant radial distance from the transceiver and scanning the transceiver along a vertical track. Using a 77GHz mmWave radar, a high resolution three-dimensional (3-D) image can be reconstructed from this two-dimensional scanning taking into account the spherical near-field wavefront. While prior work in literature consists of single-input-single-output circular synthetic aperture radar (SISO-CSAR) algorithms or computationally sluggish MIMO-CSAR image reconstruction algorithms, this paper proposes a novel algorithm for efficient MIMO 3-D holographic imaging and details the design of a MIMO R-ISAR imaging system. The proposed algorithm applies a multistatic-to-monostatic phase compensation to the R-ISAR regime allowing for use of highly efficient monostatic algorithms. We demonstrate the algorithm's performance in real-world imaging scenarios on a prototyped MIMO R-ISAR platform. Our fully integrated system, consisting of a mechanical scanner and efficient imaging algorithm, is capable of pairing the scanning efficiency of the MIMO regime with the computational efficiency of single pixel image reconstruction algorithms.
Representation Learning via Manifold Flattening and Reconstruction
May 12, 2023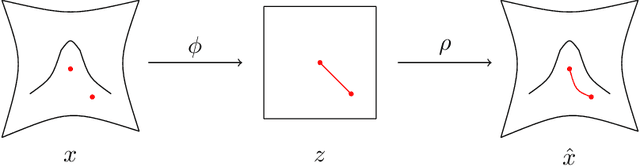
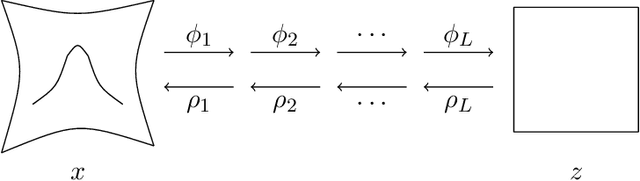
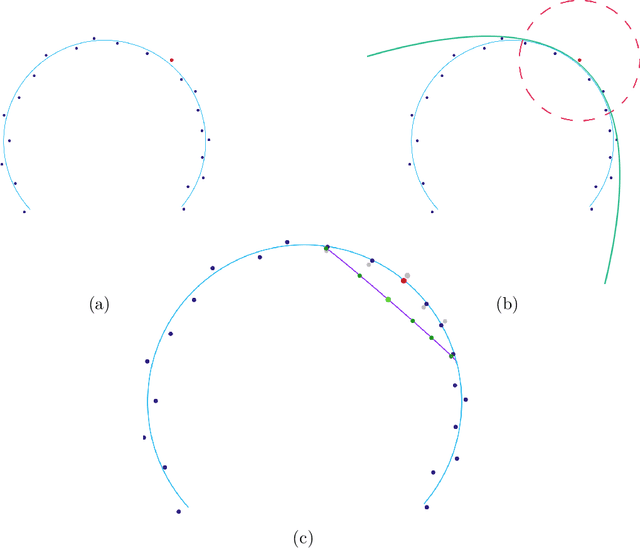
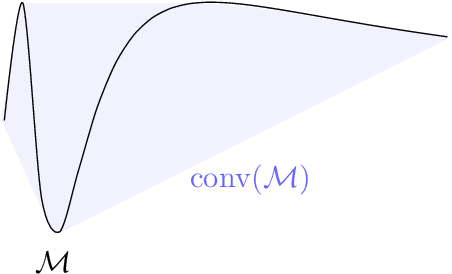
This work proposes an algorithm for explicitly constructing a pair of neural networks that linearize and reconstruct an embedded submanifold, from finite samples of this manifold. Our such-generated neural networks, called Flattening Networks (FlatNet), are theoretically interpretable, computationally feasible at scale, and generalize well to test data, a balance not typically found in manifold-based learning methods. We present empirical results and comparisons to other models on synthetic high-dimensional manifold data and 2D image data. Our code is publicly available.