 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Physics-based network fine-tuning for robust quantitative susceptibility mapping from high-pass filtered phase
May 05, 2023
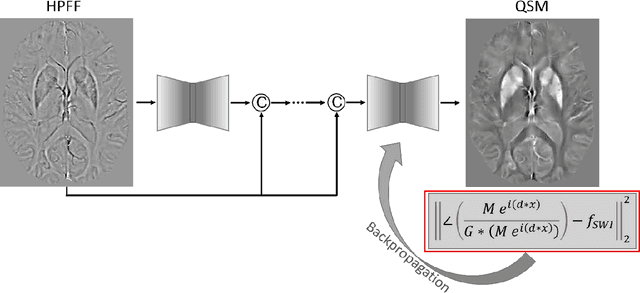
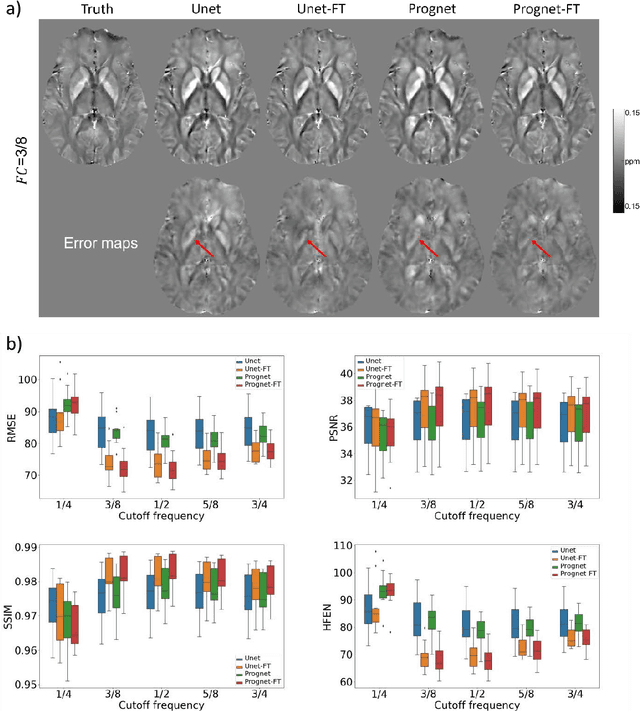
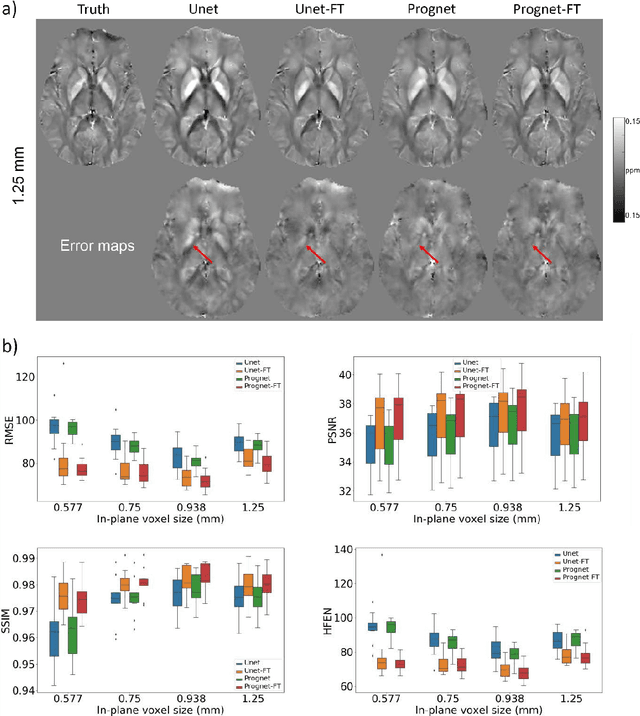
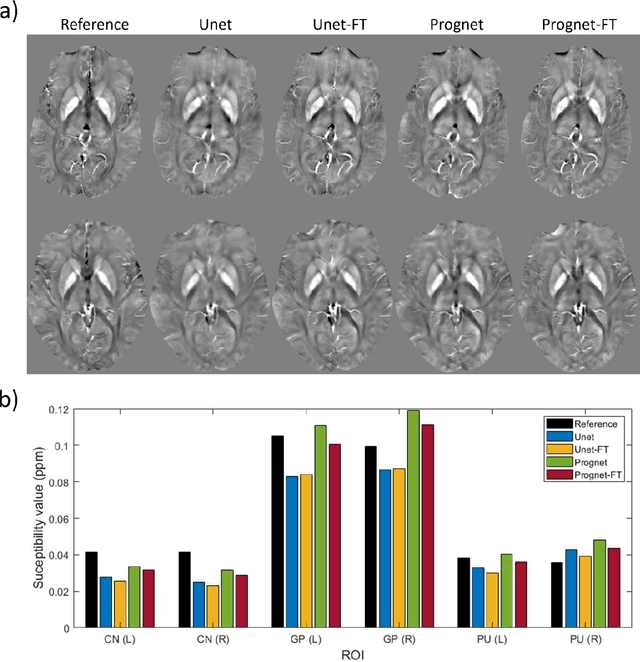
Purpose: To improve the generalization ability of convolutional neural network (CNN) based prediction of quantitative susceptibility mapping (QSM) from high-pass filtered phase (HPFP) image. Methods: The proposed network addresses two common generalization issues that arise when using a pre-trained network to predict QSM from HPFP: a) data with unseen voxel sizes, and b) data with unknown high-pass filter parameters. A network fine-tuning step based on a high-pass filtering dipole convolution forward model is proposed to reduce the generalization error of the pre-trained network. A progressive Unet architecture is proposed to improve prediction accuracy without increasing fine-tuning computational cost. Results: In retrospective studies using RMSE, PSNR, SSIM and HFEN as quality metrics, the performance of both Unet and progressive Unet was improved after physics-based fine-tuning at all voxel sizes and most high-pass filtering cutoff frequencies tested in the experiment. Progressive Unet slightly outperformed Unet both before and after fine-tuning. In a prospective study, image sharpness was improved after physics-based fine-tuning for both Unet and progressive Unet. Compared to Unet, progressive Unet had better agreement of regional susceptibility values with reference QSM. Conclusion: The proposed method shows improved robustness compared to the pre-trained network without fine-tuning when the test dataset deviates from training. Our code is available at https://github.com/Jinwei1209/SWI_to_QSM/
Post-Train Adaptive U-Net for Image Segmentation
Jan 16, 2023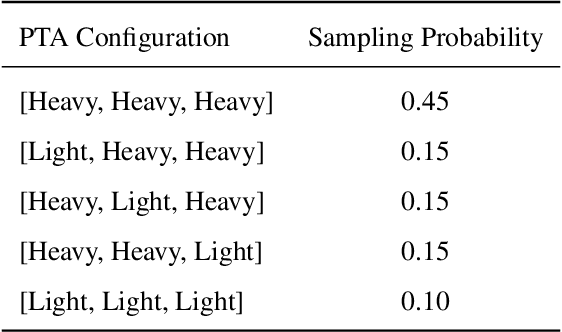
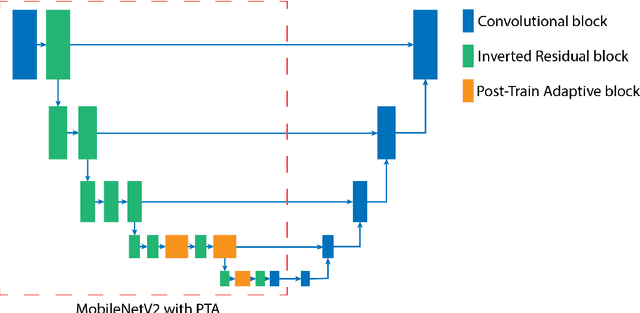
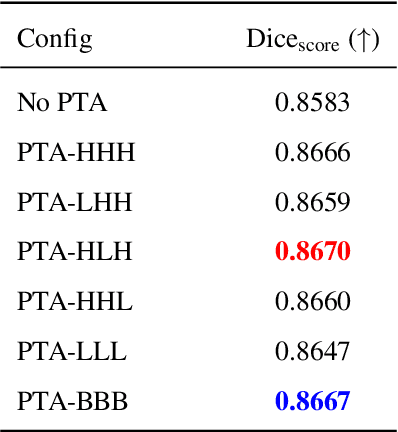
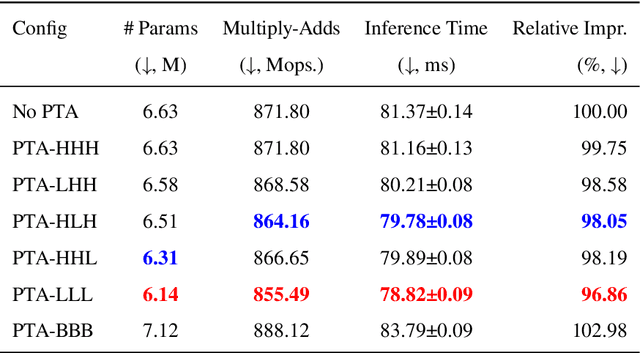
Typical neural network architectures used for image segmentation cannot be changed without further training. This is quite limiting as the network might not only be executed on a powerful server, but also on a mobile or edge device. Adaptive neural networks offer a solution to the problem by allowing certain adaptivity after the training process is complete. In this work for the first time, we apply Post-Train Adaptive (PTA) approach to the task of image segmentation. We introduce U-Net+PTA neural network, which can be trained once, and then adapted to different device performance categories. The two key components of the approach are PTA blocks and PTA-sampling training strategy. The post-train configuration can be done at runtime on any inference device including mobile. Also, the PTA approach has allowed to improve image segmentation Dice score on the CamVid dataset. The final trained model can be switched at runtime between 6 PTA configurations, which differ by inference time and quality. Importantly, all of the configurations have better quality than the original U-Net (No PTA) model.
Video4MRI: An Empirical Study on Brain Magnetic Resonance Image Analytics with CNN-based Video Classification Frameworks
Feb 24, 2023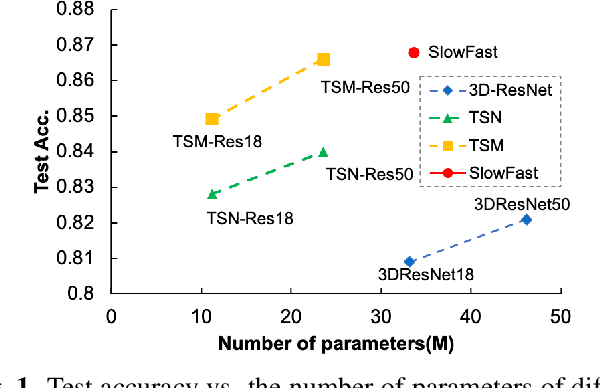

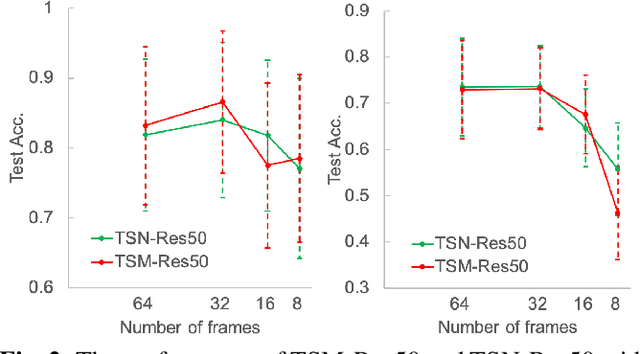

To address the problem of medical image recognition, computer vision techniques like convolutional neural networks (CNN) are frequently used. Recently, 3D CNN-based models dominate the field of magnetic resonance image (MRI) analytics. Due to the high similarity between MRI data and videos, we conduct extensive empirical studies on video recognition techniques for MRI classification to answer the questions: (1) can we directly use video recognition models for MRI classification, (2) which model is more appropriate for MRI, (3) are the common tricks like data augmentation in video recognition still useful for MRI classification? Our work suggests that advanced video techniques benefit MRI classification. In this paper, four datasets of Alzheimer's and Parkinson's disease recognition are utilized in experiments, together with three alternative video recognition models and data augmentation techniques that are frequently applied to video tasks. In terms of efficiency, the results reveal that the video framework performs better than 3D-CNN models by 5% - 11% with 50% - 66% less trainable parameters. This report pushes forward the potential fusion of 3D medical imaging and video understanding research.
Image2SSM: Reimagining Statistical Shape Models from Images with Radial Basis Functions
May 19, 2023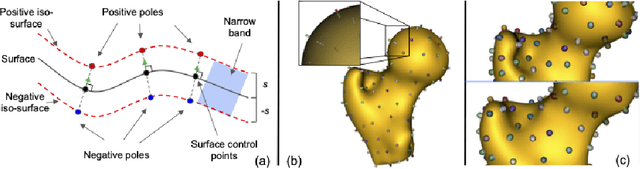
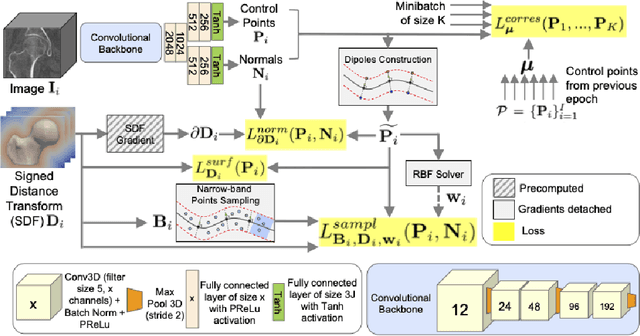
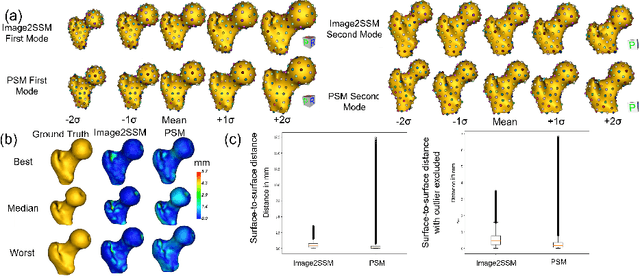
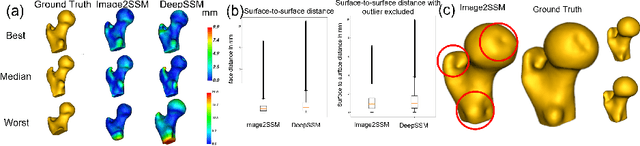
Statistical shape modeling (SSM) is an essential tool for analyzing variations in anatomical morphology. In a typical SSM pipeline, 3D anatomical images, gone through segmentation and rigid registration, are represented using lower-dimensional shape features, on which statistical analysis can be performed. Various methods for constructing compact shape representations have been proposed, but they involve laborious and costly steps. We propose Image2SSM, a novel deep-learning-based approach for SSM that leverages image-segmentation pairs to learn a radial-basis-function (RBF)-based representation of shapes directly from images. This RBF-based shape representation offers a rich self-supervised signal for the network to estimate a continuous, yet compact representation of the underlying surface that can adapt to complex geometries in a data-driven manner. Image2SSM can characterize populations of biological structures of interest by constructing statistical landmark-based shape models of ensembles of anatomical shapes while requiring minimal parameter tuning and no user assistance. Once trained, Image2SSM can be used to infer low-dimensional shape representations from new unsegmented images, paving the way toward scalable approaches for SSM, especially when dealing with large cohorts. Experiments on synthetic and real datasets show the efficacy of the proposed method compared to the state-of-art correspondence-based method for SSM.
AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation
May 19, 2023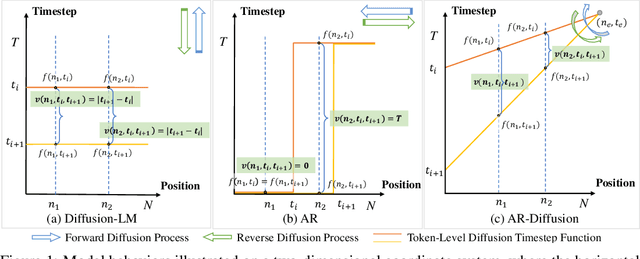
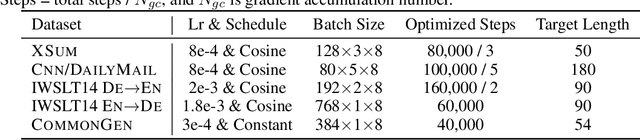
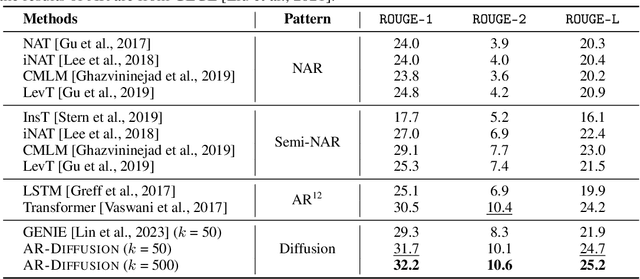
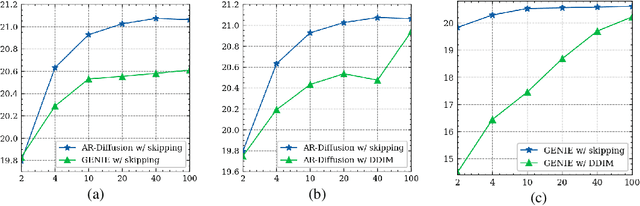
Diffusion models have gained significant attention in the realm of image generation due to their exceptional performance. Their success has been recently expanded to text generation via generating all tokens within a sequence concurrently. However, natural language exhibits a far more pronounced sequential dependency in comparison to images, and the majority of existing language models are trained with a left-to-right auto-regressive approach. To account for the inherent sequential characteristic of natural language, we introduce Auto-Regressive Diffusion (AR-Diffusion). AR-Diffusion ensures that the generation of tokens on the right depends on the generated ones on the left, a mechanism achieved through employing a dynamic number of denoising steps that vary based on token position. This results in tokens on the left undergoing fewer denoising steps than those on the right, thereby enabling them to generate earlier and subsequently influence the generation of tokens on the right. In a series of experiments on various text generation tasks, including text summarization, machine translation, and common sense generation, AR-Diffusion clearly demonstrated its superiority over existing diffusion language models and that it can be $100\times\sim600\times$ faster when achieving comparable results. Our code is available at https://github.com/microsoft/ProphetNet/tree/master/AR-diffusion.
SurgMAE: Masked Autoencoders for Long Surgical Video Analysis
May 19, 2023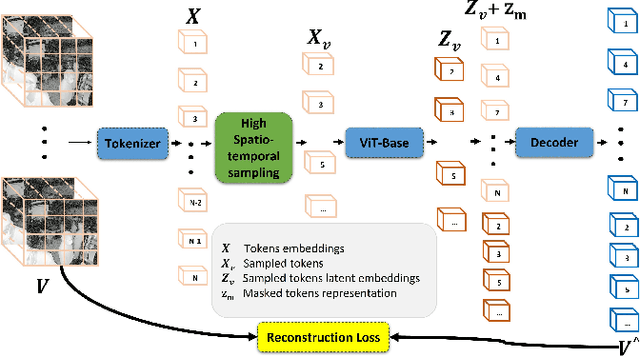

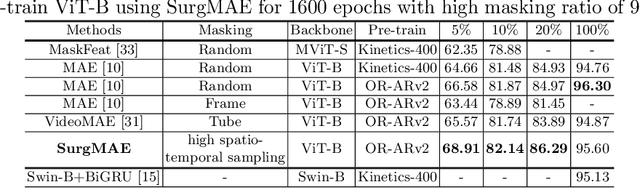

There has been a growing interest in using deep learning models for processing long surgical videos, in order to automatically detect clinical/operational activities and extract metrics that can enable workflow efficiency tools and applications. However, training such models require vast amounts of labeled data which is costly and not scalable. Recently, self-supervised learning has been explored in computer vision community to reduce the burden of the annotation cost. Masked autoencoders (MAE) got the attention in self-supervised paradigm for Vision Transformers (ViTs) by predicting the randomly masked regions given the visible patches of an image or a video clip, and have shown superior performance on benchmark datasets. However, the application of MAE in surgical data remains unexplored. In this paper, we first investigate whether MAE can learn transferrable representations in surgical video domain. We propose SurgMAE, which is a novel architecture with a masking strategy based on sampling high spatio-temporal tokens for MAE. We provide an empirical study of SurgMAE on two large scale long surgical video datasets, and find that our method outperforms several baselines in low data regime. We conduct extensive ablation studies to show the efficacy of our approach and also demonstrate it's superior performance on UCF-101 to prove it's generalizability in non-surgical datasets as well.
Q-malizing flow and infinitesimal density ratio estimation
May 19, 2023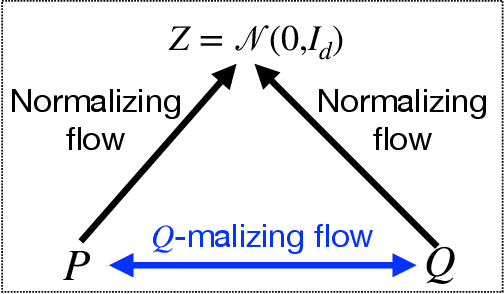

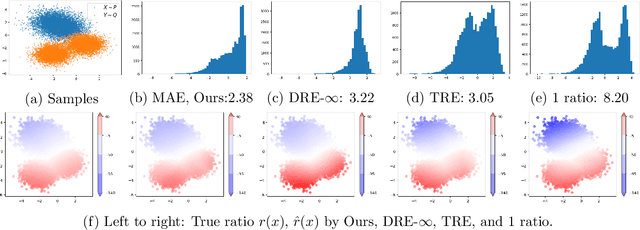
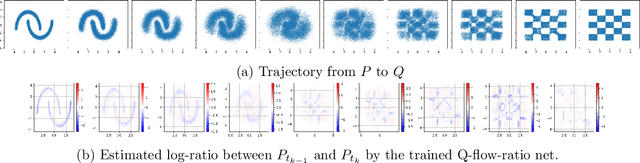
Continuous normalizing flows are widely used in generative tasks, where a flow network transports from a data distribution $P$ to a normal distribution. A flow model that can transport from $P$ to an arbitrary $Q$, where both $P$ and $Q$ are accessible via finite samples, would be of various application interests, particularly in the recently developed telescoping density ratio estimation (DRE) which calls for the construction of intermediate densities to bridge between $P$ and $Q$. In this work, we propose such a ``Q-malizing flow'' by a neural-ODE model which is trained to transport invertibly from $P$ to $Q$ (and vice versa) from empirical samples and is regularized by minimizing the transport cost. The trained flow model allows us to perform infinitesimal DRE along the time-parametrized $\log$-density by training an additional continuous-time flow network using classification loss, which estimates the time-partial derivative of the $\log$-density. Integrating the time-score network along time provides a telescopic DRE between $P$ and $Q$ that is more stable than a one-step DRE. The effectiveness of the proposed model is empirically demonstrated on mutual information estimation from high-dimensional data and energy-based generative models of image data.
ADS_UNet: A Nested UNet for Histopathology Image Segmentation
Apr 10, 2023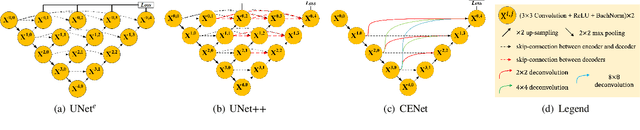
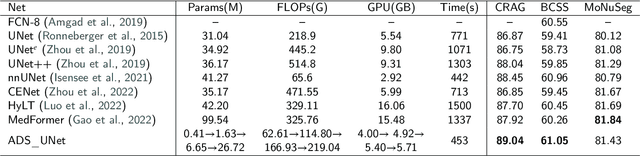
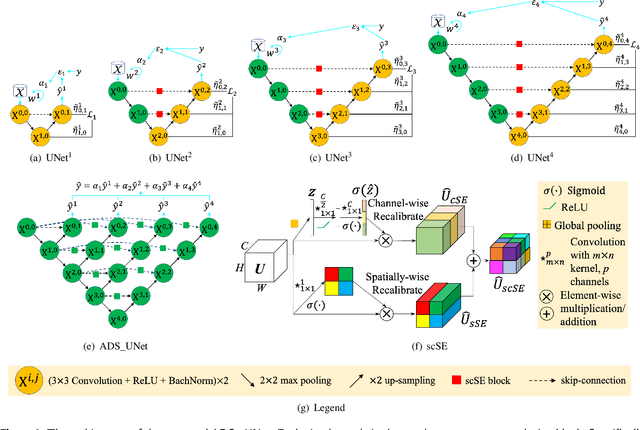

The UNet model consists of fully convolutional network (FCN) layers arranged as contracting encoder and upsampling decoder maps. Nested arrangements of these encoder and decoder maps give rise to extensions of the UNet model, such as UNete and UNet++. Other refinements include constraining the outputs of the convolutional layers to discriminate between segment labels when trained end to end, a property called deep supervision. This reduces feature diversity in these nested UNet models despite their large parameter space. Furthermore, for texture segmentation, pixel correlations at multiple scales contribute to the classification task; hence, explicit deep supervision of shallower layers is likely to enhance performance. In this paper, we propose ADS UNet, a stage-wise additive training algorithm that incorporates resource-efficient deep supervision in shallower layers and takes performance-weighted combinations of the sub-UNets to create the segmentation model. We provide empirical evidence on three histopathology datasets to support the claim that the proposed ADS UNet reduces correlations between constituent features and improves performance while being more resource efficient. We demonstrate that ADS_UNet outperforms state-of-the-art Transformer-based models by 1.08 and 0.6 points on CRAG and BCSS datasets, and yet requires only 37% of GPU consumption and 34% of training time as that required by Transformers.
K-space interpretation of image-scanning-microscopy
Jan 11, 2023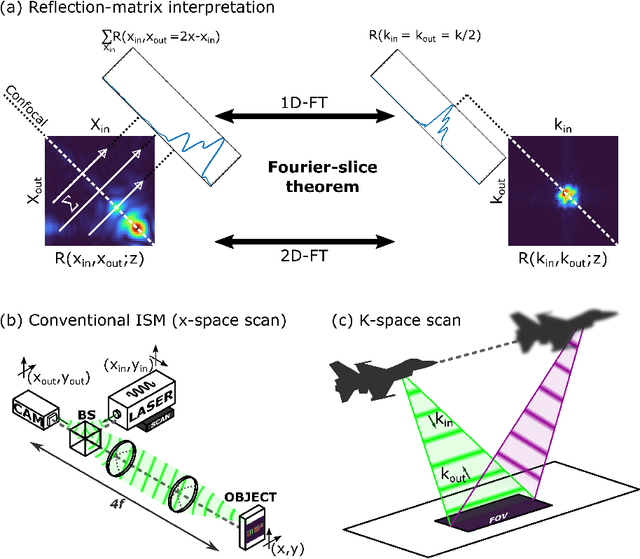
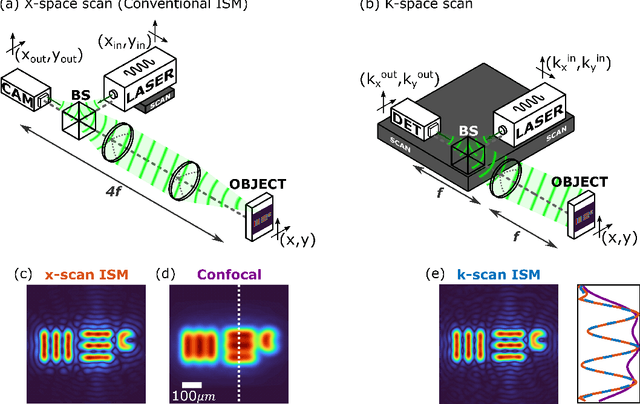
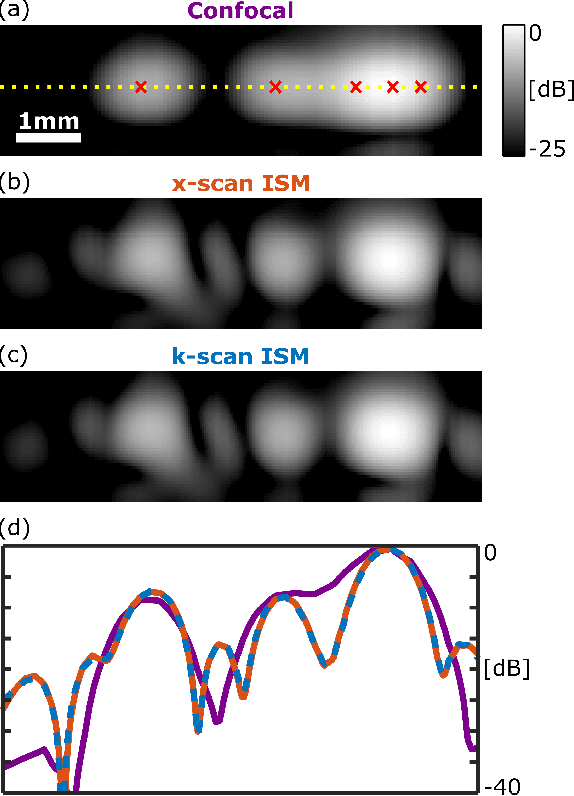
In recent years, image-scanning microscopy (ISM, also termed pixel-reassignment microscopy) has emerged as a technique that improves the resolution and signal-to-noise compared to confocal and widefield microscopy by employing a detector array at the image plane of a confocal laser scanning microscope. Here, we present a k-space analysis of coherent ISM, showing that ISM is equivalent to spotlight synthetic-aperture radar (SAR) and analogous to oblique-illumination microscopy. This insight indicates that ISM can be performed with a single detector placed in the k-space of the sample, which we numerically demonstrate.
SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection
May 02, 2023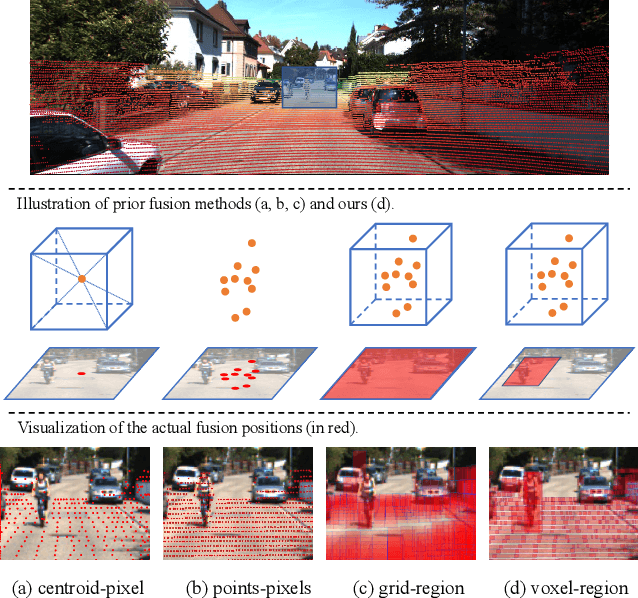
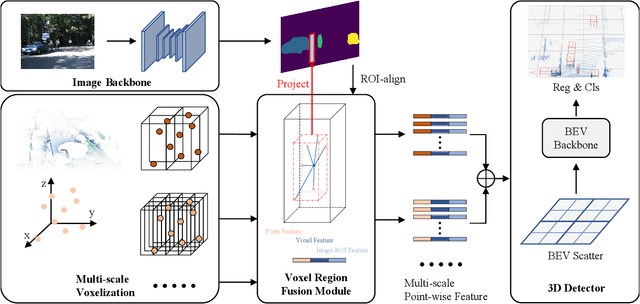
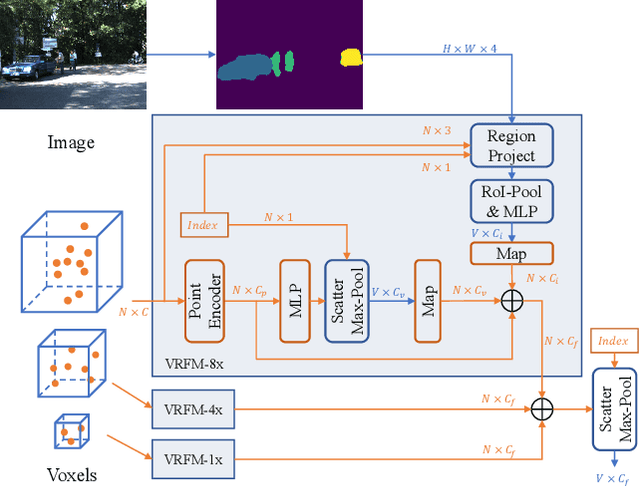

In the perception task of autonomous driving, multi-modal methods have become a trend due to the complementary characteristics of LiDAR point clouds and image data. However, the performance of previous methods is usually limited by the sparsity of the point cloud or the noise problem caused by the misalignment between LiDAR and the camera. To solve these two problems, we present a new concept, Voxel Region (VR), which is obtained by projecting the sparse local point clouds in each voxel dynamically. And we propose a novel fusion method, named Sparse-to-Dense Voxel Region Fusion (SDVRF). Specifically, more pixels of the image feature map inside the VR are gathered to supplement the voxel feature extracted from sparse points and achieve denser fusion. Meanwhile, different from prior methods, which project the size-fixed grids, our strategy of generating dynamic regions achieves better alignment and avoids introducing too much background noise. Furthermore, we propose a multi-scale fusion framework to extract more contextual information and capture the features of objects of different sizes. Experiments on the KITTI dataset show that our method improves the performance of different baselines, especially on classes of small size, including Pedestrian and Cyclist.