 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Constructing Dreams using Generative AI
May 19, 2023


Generative AI tools introduce new and accessible forms of media creation for youth. They also raise ethical concerns about the generation of fake media, data protection, privacy and ownership of AI-generated art. Since generative AI is already being used in products used by youth, it is critical that they understand how these tools work and how they can be used or misused. In this work, we facilitated students' generative AI learning through expression of their imagined future identities. We designed a learning workshop - Dreaming with AI - where students learned about the inner workings of generative AI tools, used text-to-image generation algorithms to create their imaged future dreams, reflected on the potential benefits and harms of generative AI tools and voiced their opinions about policies for the use of these tools in classrooms. In this paper, we present the learning activities and experiences of 34 high school students who engaged in our workshops. Students reached creative learning objectives by using prompt engineering to create their future dreams, gained technical knowledge by learning the abilities, limitations, text-visual mappings and applications of generative AI, and identified most potential societal benefits and harms of generative AI.
Generative Sliced MMD Flows with Riesz Kernels
May 19, 2023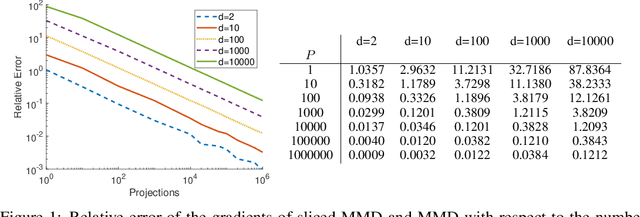
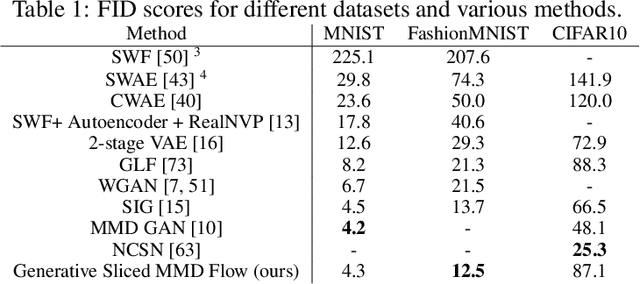


Maximum mean discrepancy (MMD) flows suffer from high computational costs in large scale computations. In this paper, we show that MMD flows with Riesz kernels $K(x,y) = - \|x-y\|^r$, $r \in (0,2)$ have exceptional properties which allow for their efficient computation. First, the MMD of Riesz kernels coincides with the MMD of their sliced version. As a consequence, the computation of gradients of MMDs can be performed in the one-dimensional setting. Here, for $r=1$, a simple sorting algorithm can be applied to reduce the complexity from $O(MN+N^2)$ to $O((M+N)\log(M+N))$ for two empirical measures with $M$ and $N$ support points. For the implementations we approximate the gradient of the sliced MMD by using only a finite number $P$ of slices. We show that the resulting error has complexity $O(\sqrt{d/P})$, where $d$ is the data dimension. These results enable us to train generative models by approximating MMD gradient flows by neural networks even for large scale applications. We demonstrate the efficiency of our model by image generation on MNIST, FashionMNIST and CIFAR10.
Beware of diffusion models for synthesizing medical images -- A comparison with GANs in terms of memorizing brain tumor images
May 12, 2023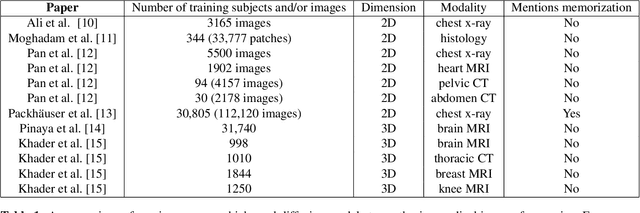
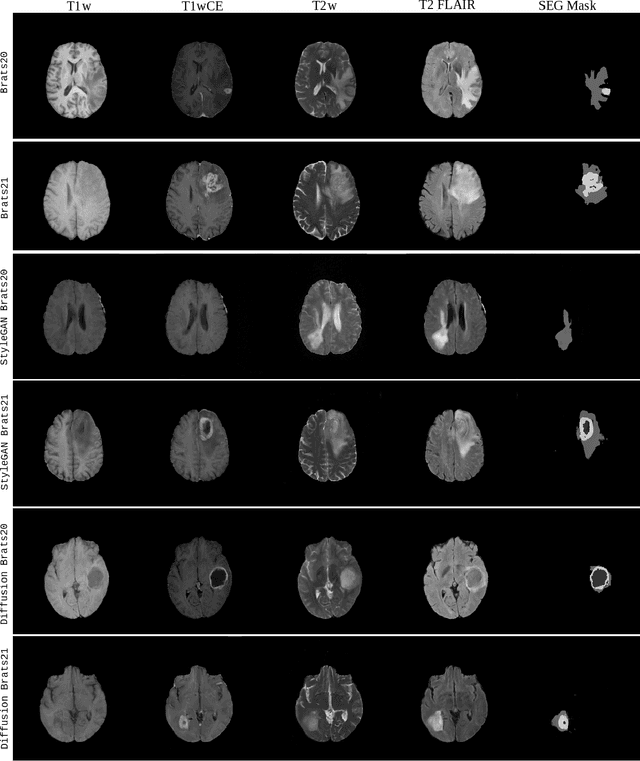

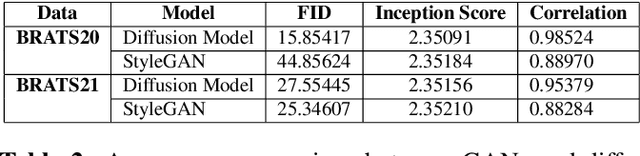
Diffusion models were initially developed for text-to-image generation and are now being utilized to generate high quality synthetic images. Preceded by GANs, diffusion models have shown impressive results using various evaluation metrics. However, commonly used metrics such as FID and IS are not suitable for determining whether diffusion models are simply reproducing the training images. Here we train StyleGAN and diffusion models, using BRATS20 and BRATS21 datasets, to synthesize brain tumor images, and measure the correlation between the synthetic images and all training images. Our results show that diffusion models are much more likely to memorize the training images, especially for small datasets. Researchers should be careful when using diffusion models for medical imaging, if the final goal is to share the synthetic images.
DetGPT: Detect What You Need via Reasoning
May 24, 2023

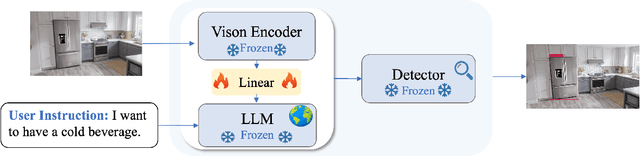

In recent years, the field of computer vision has seen significant advancements thanks to the development of large language models (LLMs). These models have enabled more effective and sophisticated interactions between humans and machines, paving the way for novel techniques that blur the lines between human and machine intelligence. In this paper, we introduce a new paradigm for object detection that we call reasoning-based object detection. Unlike conventional object detection methods that rely on specific object names, our approach enables users to interact with the system using natural language instructions, allowing for a higher level of interactivity. Our proposed method, called DetGPT, leverages state-of-the-art multi-modal models and open-vocabulary object detectors to perform reasoning within the context of the user's instructions and the visual scene. This enables DetGPT to automatically locate the object of interest based on the user's expressed desires, even if the object is not explicitly mentioned. For instance, if a user expresses a desire for a cold beverage, DetGPT can analyze the image, identify a fridge, and use its knowledge of typical fridge contents to locate the beverage. This flexibility makes our system applicable across a wide range of fields, from robotics and automation to autonomous driving. Overall, our proposed paradigm and DetGPT demonstrate the potential for more sophisticated and intuitive interactions between humans and machines. We hope that our proposed paradigm and approach will provide inspiration to the community and open the door to more interative and versatile object detection systems. Our project page is launched at detgpt.github.io.
A Systematic Study on Object Recognition Using Millimeter-wave Radar
May 03, 2023
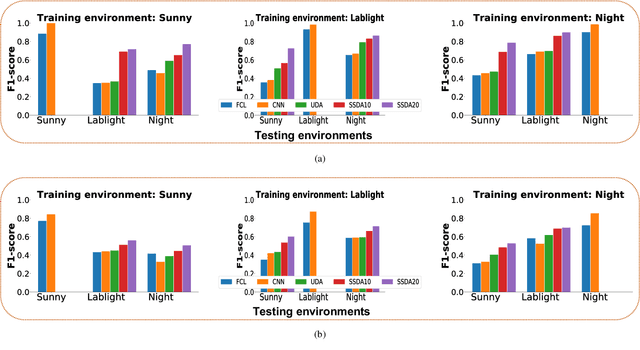


Due to its light and weather-independent sensing, millimeter-wave (MMW) radar is essential in smart environments. Intelligent vehicle systems and industry-grade MMW radars have integrated such capabilities. Industry-grade MMW radars are expensive and hard to get for community-purpose smart environment applications. However, commercially available MMW radars have hidden underpinning challenges that need to be investigated for tasks like recognizing objects and activities, real-time person tracking, object localization, etc. Image and video data are straightforward to gather, understand, and annotate for such jobs. Image and video data are light and weather-dependent, susceptible to the occlusion effect, and present privacy problems. To eliminate dependence and ensure privacy, commercial MMW radars should be tested. MMW radar's practicality and performance in varied operating settings must be addressed before promoting it. To address the problems, we collected a dataset using Texas Instruments' Automotive mmWave Radar (AWR2944) and reported the best experimental settings for object recognition performance using different deep learning algorithms. Our extensive data gathering technique allows us to systematically explore and identify object identification task problems under cross-ambience conditions. We investigated several solutions and published detailed experimental data.
Towards Large-scale Single-shot Millimeter-wave Imaging for Low-cost Security Inspection
May 25, 2023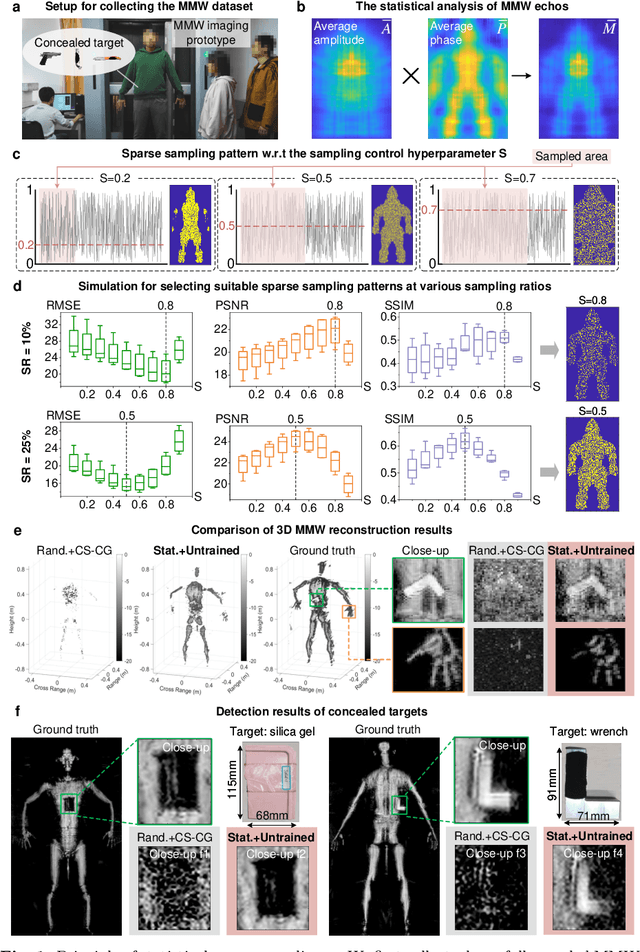
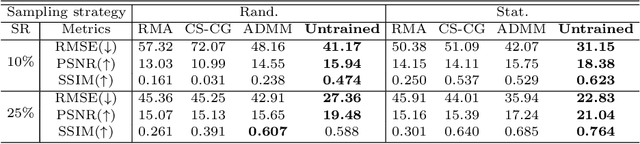
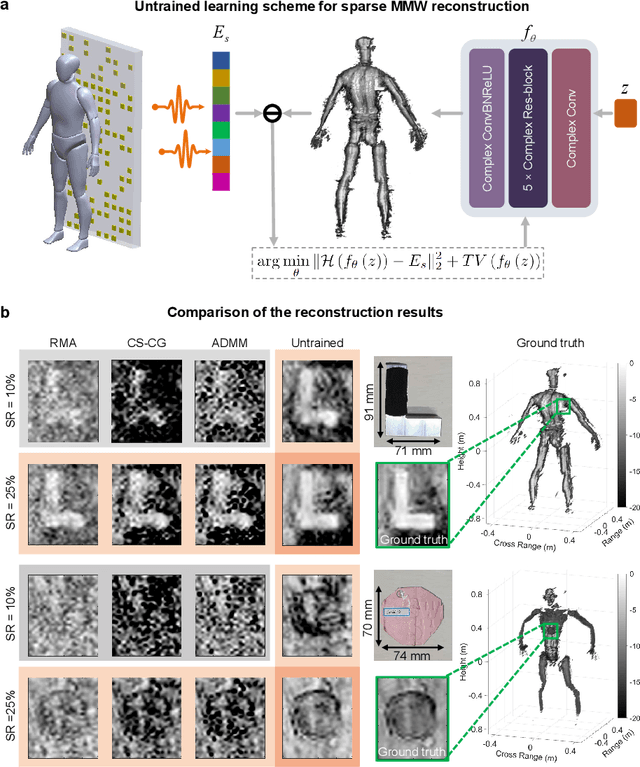
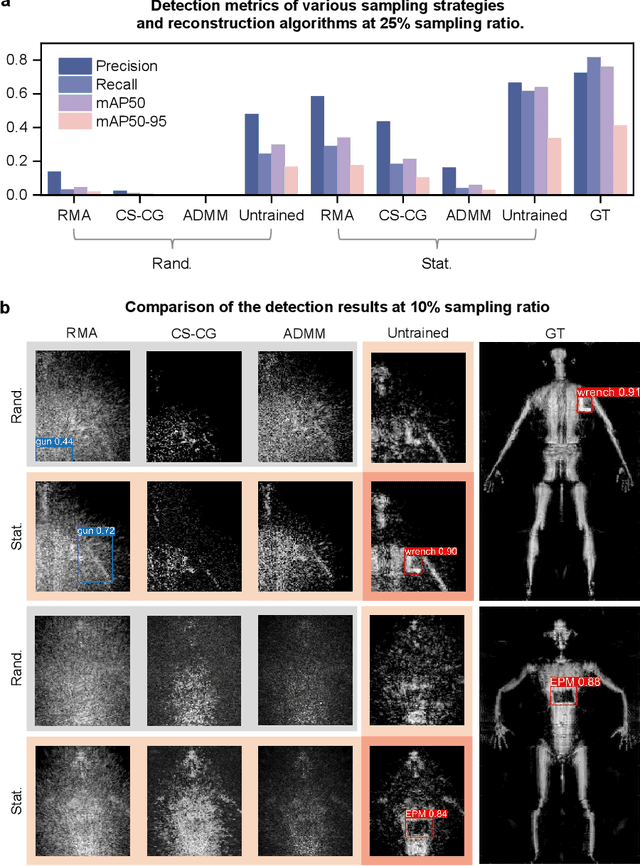
Millimeter-wave (MMW) imaging is emerging as a promising technique for safe security inspection. It achieves a delicate balance between imaging resolution, penetrability and human safety, resulting in higher resolution compared to low-frequency microwave, stronger penetrability compared to visible light, and stronger safety compared to X ray. Despite of recent advance in the last decades, the high cost of requisite large-scale antenna array hinders widespread adoption of MMW imaging in practice. To tackle this challenge, we report a large-scale single-shot MMW imaging framework using sparse antenna array, achieving low-cost but high-fidelity security inspection under an interpretable learning scheme. We first collected extensive full-sampled MMW echoes to study the statistical ranking of each element in the large-scale array. These elements are then sampled based on the ranking, building the experimentally optimal sparse sampling strategy that reduces the cost of antenna array by up to one order of magnitude. Additionally, we derived an untrained interpretable learning scheme, which realizes robust and accurate image reconstruction from sparsely sampled echoes. Last, we developed a neural network for automatic object detection, and experimentally demonstrated successful detection of concealed centimeter-sized targets using 10% sparse array, whereas all the other contemporary approaches failed at the same sample sampling ratio. The performance of the reported technique presents higher than 50% superiority over the existing MMW imaging schemes on various metrics including precision, recall, and mAP50. With such strong detection ability and order-of-magnitude cost reduction, we anticipate that this technique provides a practical way for large-scale single-shot MMW imaging, and could advocate its further practical applications.
Domain Adaptive and Generalizable Network Architectures and Training Strategies for Semantic Image Segmentation
Apr 26, 2023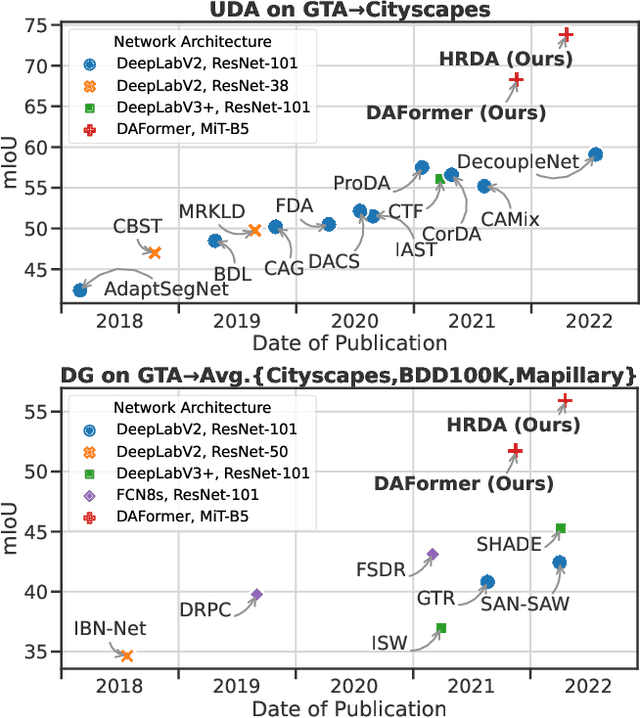
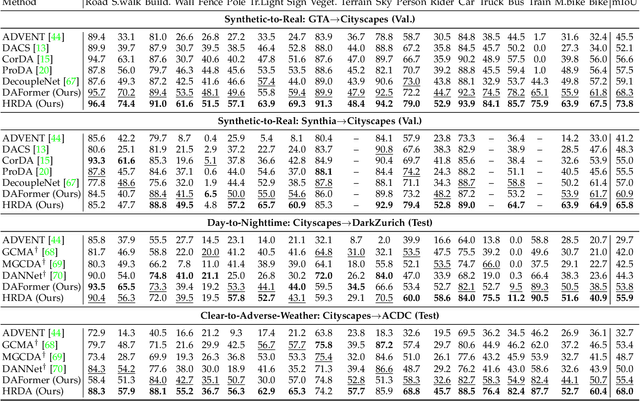

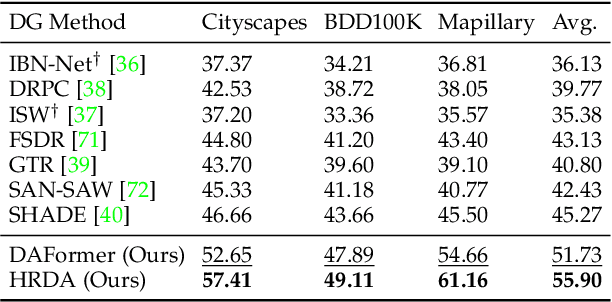
Unsupervised domain adaptation (UDA) and domain generalization (DG) enable machine learning models trained on a source domain to perform well on unlabeled or even unseen target domains. As previous UDA&DG semantic segmentation methods are mostly based on outdated networks, we benchmark more recent architectures, reveal the potential of Transformers, and design the DAFormer network tailored for UDA&DG. It is enabled by three training strategies to avoid overfitting to the source domain: While (1) Rare Class Sampling mitigates the bias toward common source domain classes, (2) a Thing-Class ImageNet Feature Distance and (3) a learning rate warmup promote feature transfer from ImageNet pretraining. As UDA&DG are usually GPU memory intensive, most previous methods downscale or crop images. However, low-resolution predictions often fail to preserve fine details while models trained with cropped images fall short in capturing long-range, domain-robust context information. Therefore, we propose HRDA, a multi-resolution framework for UDA&DG, that combines the strengths of small high-resolution crops to preserve fine segmentation details and large low-resolution crops to capture long-range context dependencies with a learned scale attention. DAFormer and HRDA significantly improve the state-of-the-art UDA&DG by more than 10 mIoU on 5 different benchmarks. The implementation is available at https://github.com/lhoyer/HRDA.
Rotation and Translation Invariant Representation Learning with Implicit Neural Representations
Apr 27, 2023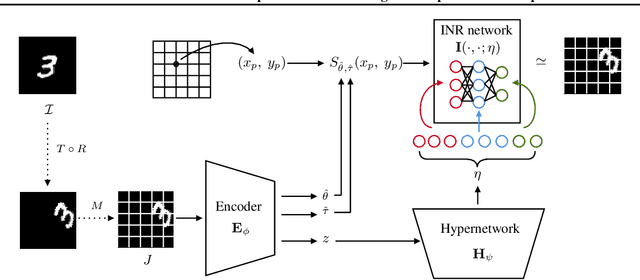

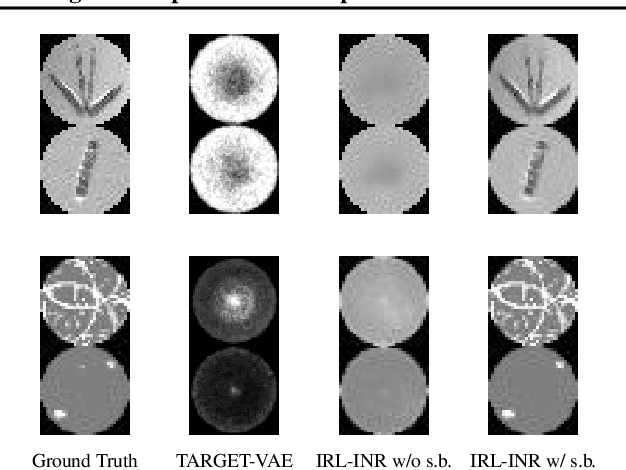
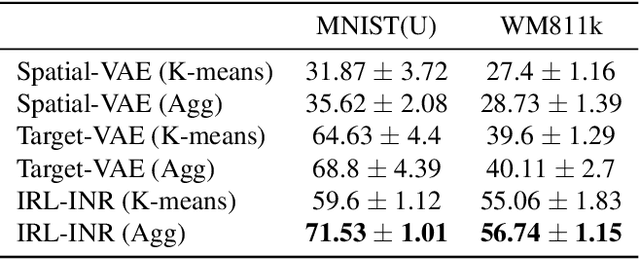
In many computer vision applications, images are acquired with arbitrary or random rotations and translations, and in such setups, it is desirable to obtain semantic representations disentangled from the image orientation. Examples of such applications include semiconductor wafer defect inspection, plankton microscope images, and inference on single-particle cryo-electron microscopy (cryo-EM) micro-graphs. In this work, we propose Invariant Representation Learning with Implicit Neural Representation (IRL-INR), which uses an implicit neural representation (INR) with a hypernetwork to obtain semantic representations disentangled from the orientation of the image. We show that IRL-INR can effectively learn disentangled semantic representations on more complex images compared to those considered in prior works and show that these semantic representations synergize well with SCAN to produce state-of-the-art unsupervised clustering results.
Learning to Render Novel Views from Wide-Baseline Stereo Pairs
Apr 17, 2023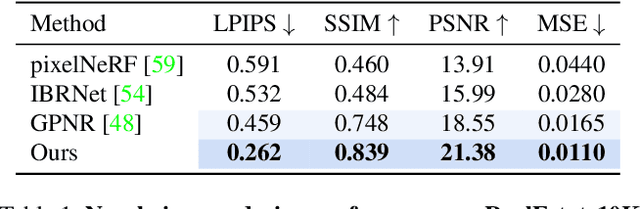
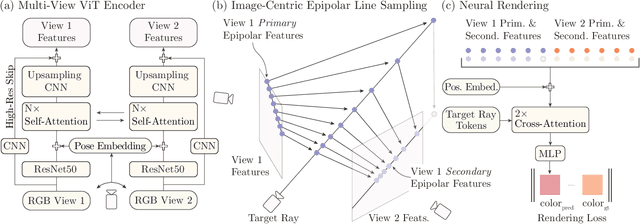
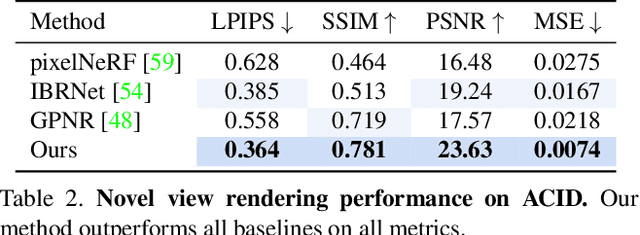

We introduce a method for novel view synthesis given only a single wide-baseline stereo image pair. In this challenging regime, 3D scene points are regularly observed only once, requiring prior-based reconstruction of scene geometry and appearance. We find that existing approaches to novel view synthesis from sparse observations fail due to recovering incorrect 3D geometry and due to the high cost of differentiable rendering that precludes their scaling to large-scale training. We take a step towards resolving these shortcomings by formulating a multi-view transformer encoder, proposing an efficient, image-space epipolar line sampling scheme to assemble image features for a target ray, and a lightweight cross-attention-based renderer. Our contributions enable training of our method on a large-scale real-world dataset of indoor and outdoor scenes. We demonstrate that our method learns powerful multi-view geometry priors while reducing the rendering time. We conduct extensive comparisons on held-out test scenes across two real-world datasets, significantly outperforming prior work on novel view synthesis from sparse image observations and achieving multi-view-consistent novel view synthesis.
UW-CVGAN: UnderWater Image Enhancement with Capsules Vectors Quantization
Feb 02, 2023
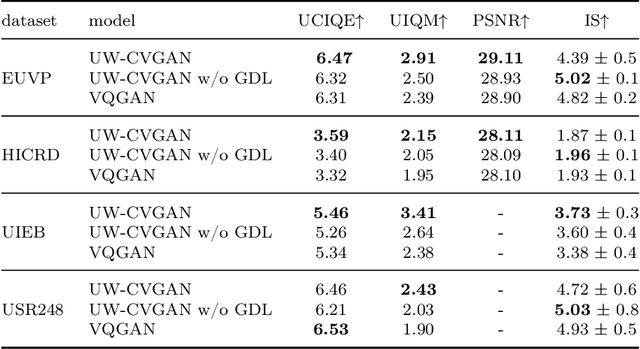

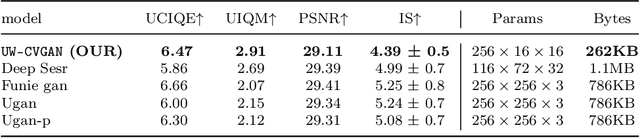
The degradation in the underwater images is due to wavelength-dependent light attenuation, scattering, and to the diversity of the water types in which they are captured. Deep neural networks take a step in this field, providing autonomous models able to achieve the enhancement of underwater images. We introduce Underwater Capsules Vectors GAN UWCVGAN based on the discrete features quantization paradigm from VQGAN for this task. The proposed UWCVGAN combines an encoding network, which compresses the image into its latent representation, with a decoding network, able to reconstruct the enhancement of the image from the only latent representation. In contrast with VQGAN, UWCVGAN achieves feature quantization by exploiting the clusterization ability of capsule layer, making the model completely trainable and easier to manage. The model obtains enhanced underwater images with high quality and fine details. Moreover, the trained encoder is independent of the decoder giving the possibility to be embedded onto the collector as compressing algorithm to reduce the memory space required for the images, of factor $3\times$. \myUWCVGAN{ }is validated with quantitative and qualitative analysis on benchmark datasets, and we present metrics results compared with the state of the art.