 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ChatCAD: Interactive Computer-Aided Diagnosis on Medical Image using Large Language Models
Feb 14, 2023



Large language models (LLMs) have recently demonstrated their potential in clinical applications, providing valuable medical knowledge and advice. For example, a large dialog LLM like ChatGPT has successfully passed part of the US medical licensing exam. However, LLMs currently have difficulty processing images, making it challenging to interpret information from medical images, which are rich in information that supports clinical decisions. On the other hand, computer-aided diagnosis (CAD) networks for medical images have seen significant success in the medical field by using advanced deep-learning algorithms to support clinical decision-making. This paper presents a method for integrating LLMs into medical-image CAD networks. The proposed framework uses LLMs to enhance the output of multiple CAD networks, such as diagnosis networks, lesion segmentation networks, and report generation networks, by summarizing and reorganizing the information presented in natural language text format. The goal is to merge the strengths of LLMs' medical domain knowledge and logical reasoning with the vision understanding capability of existing medical-image CAD models to create a more user-friendly and understandable system for patients compared to conventional CAD systems. In the future, LLM's medical knowledge can be also used to improve the performance of vision-based medical-image CAD models.
Does Conceptual Representation Require Embodiment? Insights From Large Language Models
May 30, 2023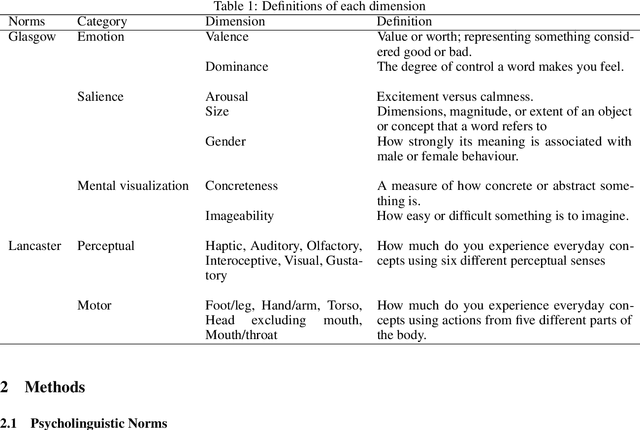
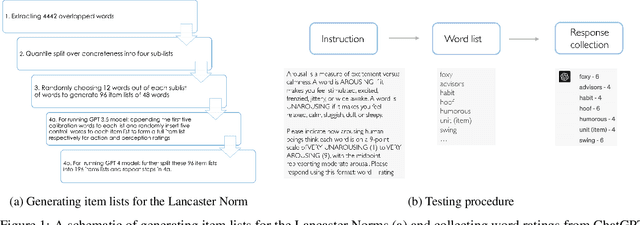
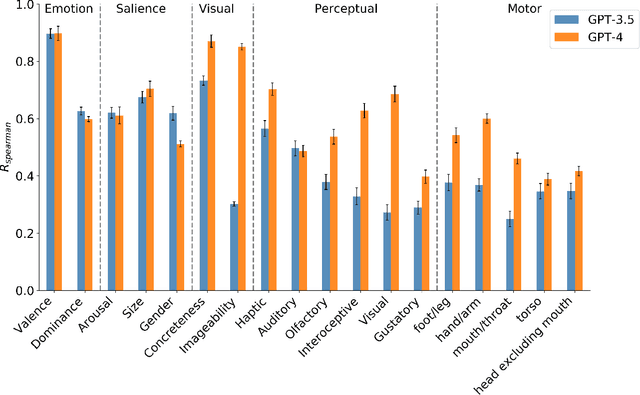

Recent advances in large language models (LLM) have the potential to shed light on the debate regarding the extent to which knowledge representation requires the grounding of embodied experience. Despite learning from limited modalities (e.g., text for GPT-3.5, and text+image for GPT-4), LLMs have nevertheless demonstrated human-like behaviors in various psychology tasks, which may provide an alternative interpretation of the acquisition of conceptual knowledge. We compared lexical conceptual representations between humans and ChatGPT (GPT-3.5 and GPT-4) on subjective ratings of various lexical conceptual features or dimensions (e.g., emotional arousal, concreteness, haptic, etc.). The results show that both GPT-3.5 and GPT-4 were strongly correlated with humans in some abstract dimensions, such as emotion and salience. In dimensions related to sensory and motor domains, GPT-3.5 shows weaker correlations while GPT-4 has made significant progress compared to GPT-3.5. Still, GPT-4 struggles to fully capture motor aspects of conceptual knowledge such as actions with foot/leg, mouth/throat, and torso. Moreover, we found that GPT-4's progress can largely be associated with its training in the visual domain. Certain aspects of conceptual representation appear to exhibit a degree of independence from sensory capacities, but others seem to necessitate them. Our findings provide insights into the complexities of knowledge representation from diverse perspectives and highlights the potential influence of embodied experience in shaping language and cognition.
Reduced Precision Floating-Point Optimization for Deep Neural Network On-Device Learning on MicroControllers
May 30, 2023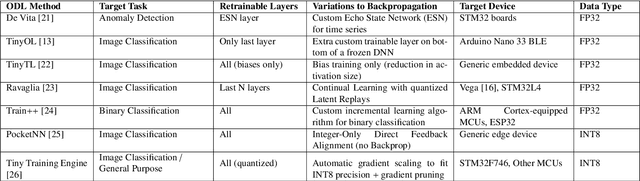
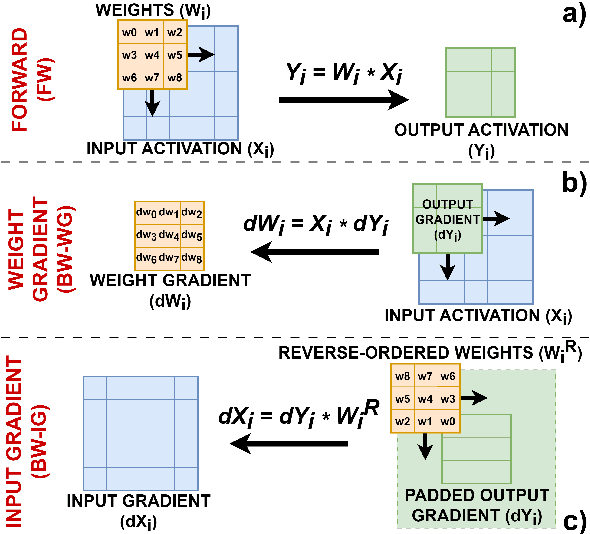
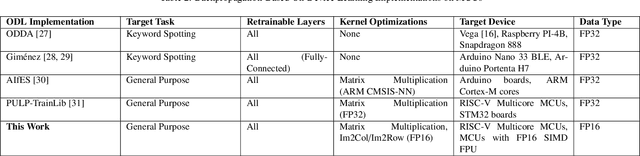
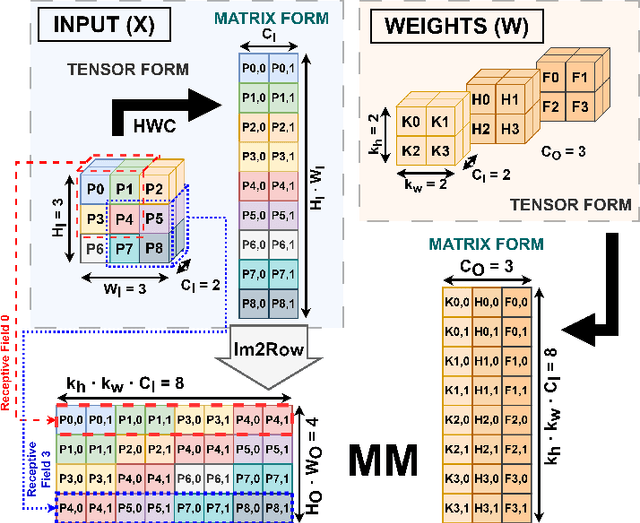
Enabling On-Device Learning (ODL) for Ultra-Low-Power Micro-Controller Units (MCUs) is a key step for post-deployment adaptation and fine-tuning of Deep Neural Network (DNN) models in future TinyML applications. This paper tackles this challenge by introducing a novel reduced precision optimization technique for ODL primitives on MCU-class devices, leveraging the State-of-Art advancements in RISC-V RV32 architectures with support for vectorized 16-bit floating-point (FP16) Single-Instruction Multiple-Data (SIMD) operations. Our approach for the Forward and Backward steps of the Back-Propagation training algorithm is composed of specialized shape transform operators and Matrix Multiplication (MM) kernels, accelerated with parallelization and loop unrolling. When evaluated on a single training step of a 2D Convolution layer, the SIMD-optimized FP16 primitives result up to 1.72$\times$ faster than the FP32 baseline on a RISC-V-based 8+1-core MCU. An average computing efficiency of 3.11 Multiply and Accumulate operations per clock cycle (MAC/clk) and 0.81 MAC/clk is measured for the end-to-end training tasks of a ResNet8 and a DS-CNN for Image Classification and Keyword Spotting, respectively -- requiring 17.1 ms and 6.4 ms on the target platform to compute a training step on a single sample. Overall, our approach results more than two orders of magnitude faster than existing ODL software frameworks for single-core MCUs and outperforms by 1.6 $\times$ previous FP32 parallel implementations on a Continual Learning setup.
DENTEX: An Abnormal Tooth Detection with Dental Enumeration and Diagnosis Benchmark for Panoramic X-rays
May 30, 2023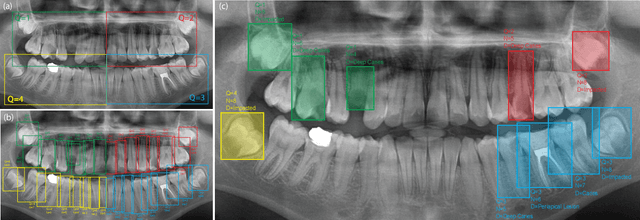
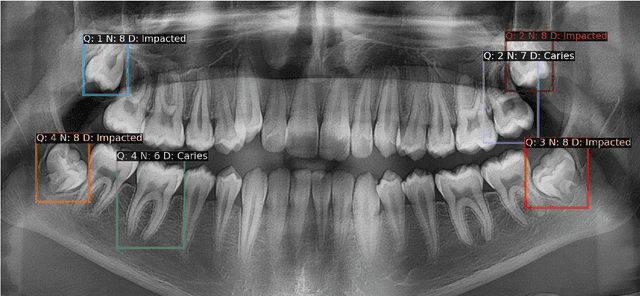
Panoramic X-rays are frequently used in dentistry for treatment planning, but their interpretation can be both time-consuming and prone to error. Artificial intelligence (AI) has the potential to aid in the analysis of these X-rays, thereby improving the accuracy of dental diagnoses and treatment plans. Nevertheless, designing automated algorithms for this purpose poses significant challenges, mainly due to the scarcity of annotated data and variations in anatomical structure. To address these issues, the Dental Enumeration and Diagnosis on Panoramic X-rays Challenge (DENTEX) has been organized in association with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2023. This challenge aims to promote the development of algorithms for multi-label detection of abnormal teeth, using three types of hierarchically annotated data: partially annotated quadrant data, partially annotated quadrant-enumeration data, and fully annotated quadrant-enumeration-diagnosis data, inclusive of four different diagnoses. In this paper, we present the results of evaluating participant algorithms on the fully annotated data, additionally investigating performance variation for quadrant, enumeration, and diagnosis labels in the detection of abnormal teeth. The provision of this annotated dataset, alongside the results of this challenge, may lay the groundwork for the creation of AI-powered tools that can offer more precise and efficient diagnosis and treatment planning in the field of dentistry. The evaluation code and datasets can be accessed at https://github.com/ibrahimethemhamamci/DENTEX
Large Language Models are Frame-level Directors for Zero-shot Text-to-Video Generation
May 23, 2023
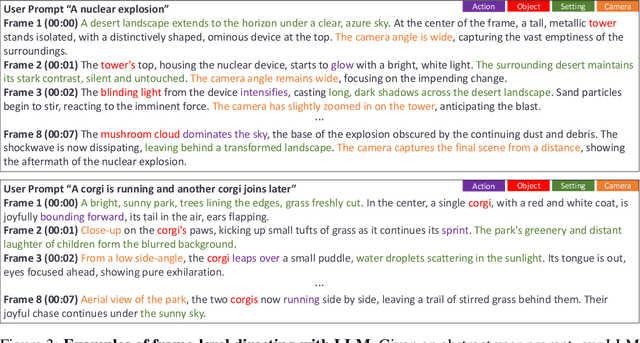
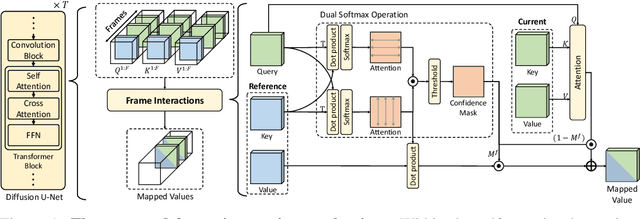
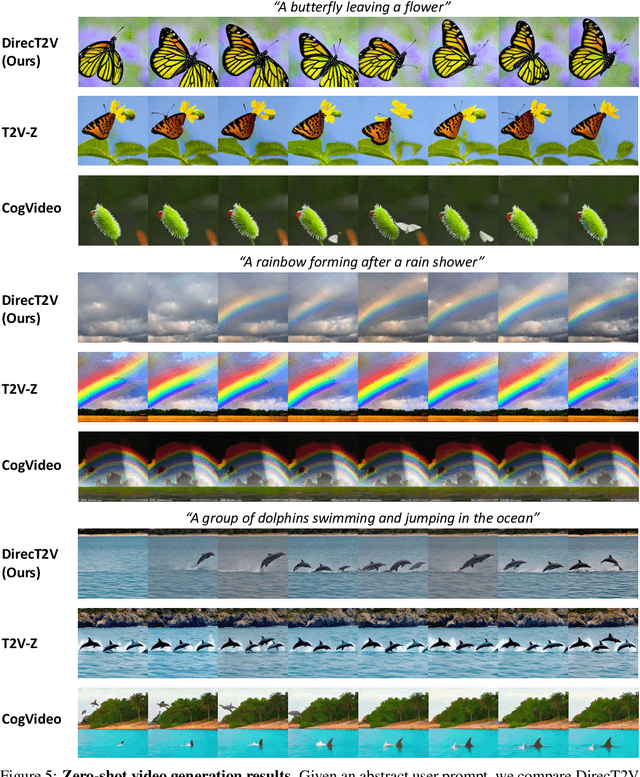
In the paradigm of AI-generated content (AIGC), there has been increasing attention in extending pre-trained text-to-image (T2I) models to text-to-video (T2V) generation. Despite their effectiveness, these frameworks face challenges in maintaining consistent narratives and handling rapid shifts in scene composition or object placement from a single user prompt. This paper introduces a new framework, dubbed DirecT2V, which leverages instruction-tuned large language models (LLMs) to generate frame-by-frame descriptions from a single abstract user prompt. DirecT2V utilizes LLM directors to divide user inputs into separate prompts for each frame, enabling the inclusion of time-varying content and facilitating consistent video generation. To maintain temporal consistency and prevent object collapse, we propose a novel value mapping method and dual-softmax filtering. Extensive experimental results validate the effectiveness of the DirecT2V framework in producing visually coherent and consistent videos from abstract user prompts, addressing the challenges of zero-shot video generation.
Constant Memory Attentive Neural Processes
May 23, 2023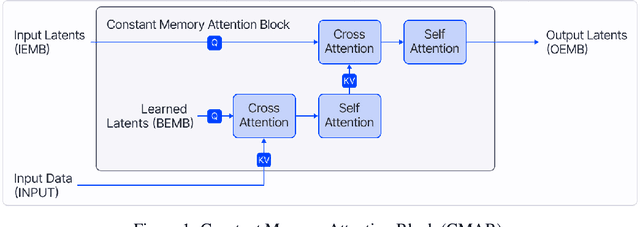

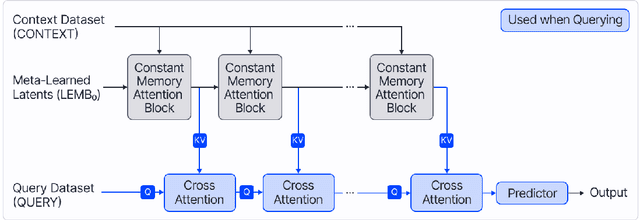
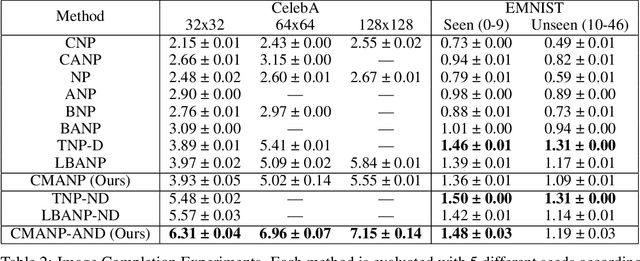
Neural Processes (NPs) are efficient methods for estimating predictive uncertainties. NPs comprise of a conditioning phase where a context dataset is encoded, a querying phase where the model makes predictions using the context dataset encoding, and an updating phase where the model updates its encoding with newly received datapoints. However, state-of-the-art methods require additional memory which scales linearly or quadratically with the size of the dataset, limiting their applications, particularly in low-resource settings. In this work, we propose Constant Memory Attentive Neural Processes (CMANPs), an NP variant which only requires constant memory for the conditioning, querying, and updating phases. In building CMANPs, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that can compute its output in constant memory and perform updates in constant computation. Empirically, we show CMANPs achieve state-of-the-art results on meta-regression and image completion tasks while being (1) significantly more memory efficient than prior methods and (2) more scalable to harder settings.
DiffProtect: Generate Adversarial Examples with Diffusion Models for Facial Privacy Protection
May 23, 2023
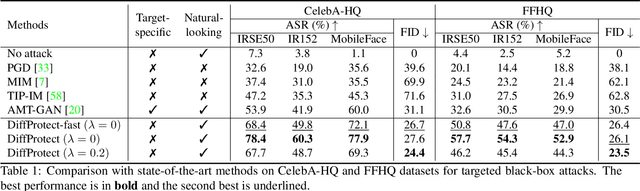
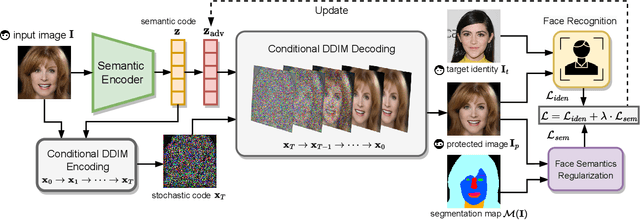

The increasingly pervasive facial recognition (FR) systems raise serious concerns about personal privacy, especially for billions of users who have publicly shared their photos on social media. Several attempts have been made to protect individuals from being identified by unauthorized FR systems utilizing adversarial attacks to generate encrypted face images. However, existing methods suffer from poor visual quality or low attack success rates, which limit their utility. Recently, diffusion models have achieved tremendous success in image generation. In this work, we ask: can diffusion models be used to generate adversarial examples to improve both visual quality and attack performance? We propose DiffProtect, which utilizes a diffusion autoencoder to generate semantically meaningful perturbations on FR systems. Extensive experiments demonstrate that DiffProtect produces more natural-looking encrypted images than state-of-the-art methods while achieving significantly higher attack success rates, e.g., 24.5% and 25.1% absolute improvements on the CelebA-HQ and FFHQ datasets.
Efficient Multi-Scale Attention Module with Cross-Spatial Learning
May 23, 2023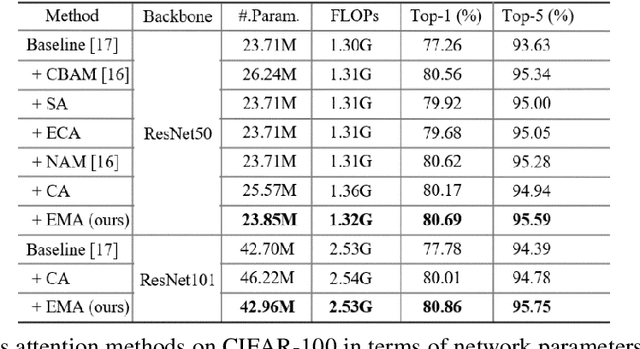
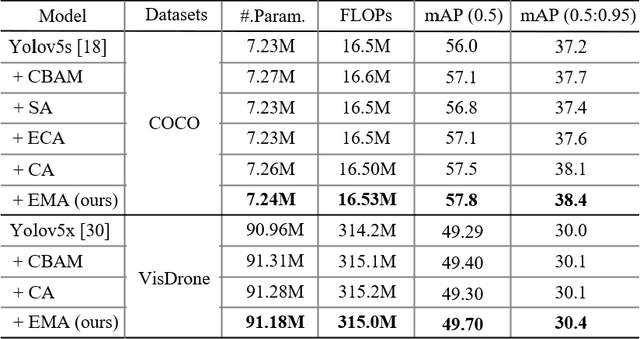
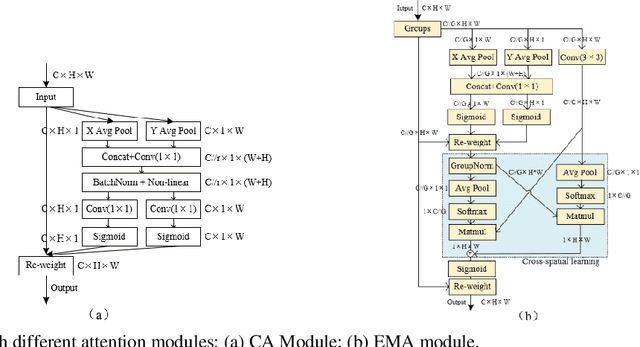
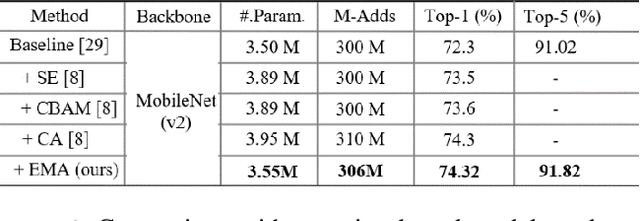
Remarkable effectiveness of the channel or spatial attention mechanisms for producing more discernible feature representation are illustrated in various computer vision tasks. However, modeling the cross-channel relationships with channel dimensionality reduction may bring side effect in extracting deep visual representations. In this paper, a novel efficient multi-scale attention (EMA) module is proposed. Focusing on retaining the information on per channel and decreasing the computational overhead, we reshape the partly channels into the batch dimensions and group the channel dimensions into multiple sub-features which make the spatial semantic features well-distributed inside each feature group. Specifically, apart from encoding the global information to re-calibrate the channel-wise weight in each parallel branch, the output features of the two parallel branches are further aggregated by a cross-dimension interaction for capturing pixel-level pairwise relationship. We conduct extensive ablation studies and experiments on image classification and object detection tasks with popular benchmarks (e.g., CIFAR-100, ImageNet-1k, MS COCO and VisDrone2019) for evaluating its performance.
Images in Language Space: Exploring the Suitability of Large Language Models for Vision & Language Tasks
May 23, 2023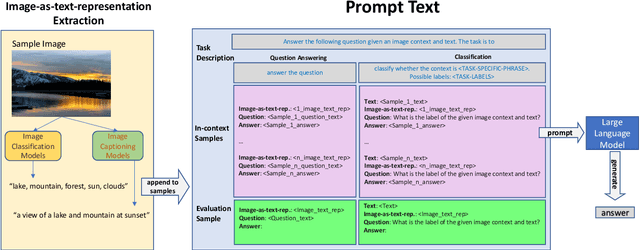
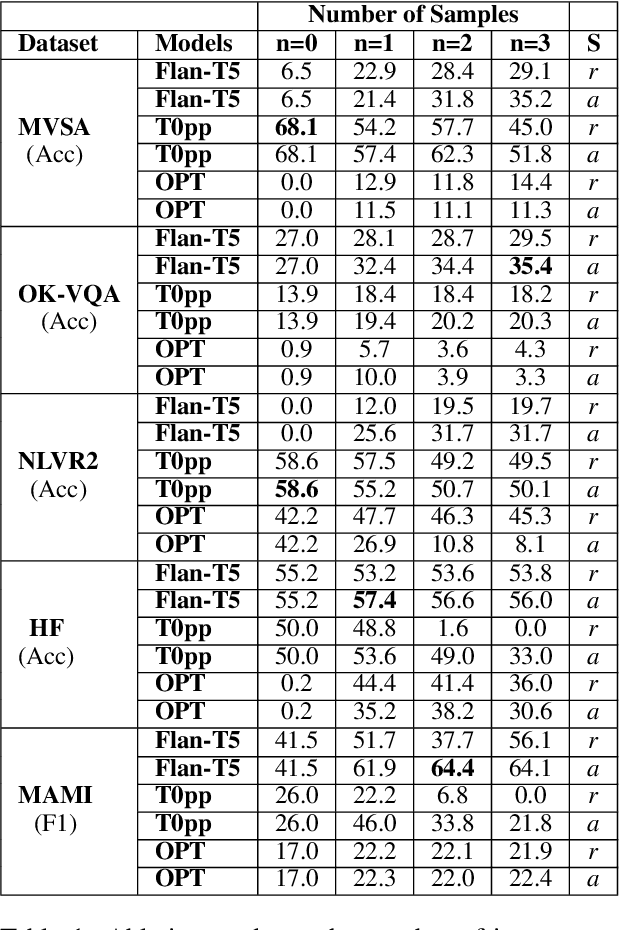
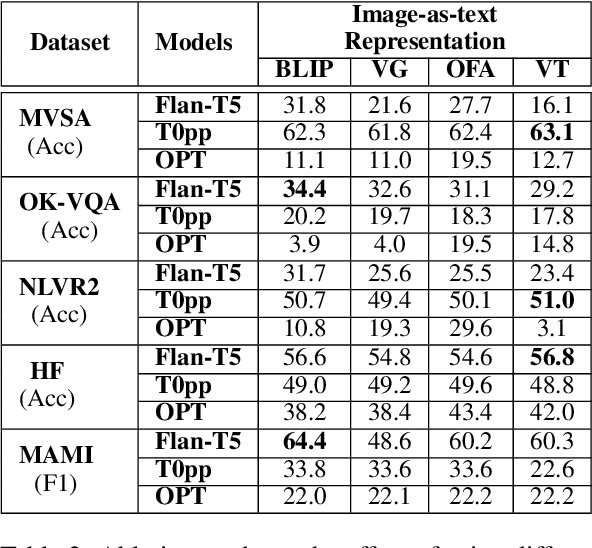
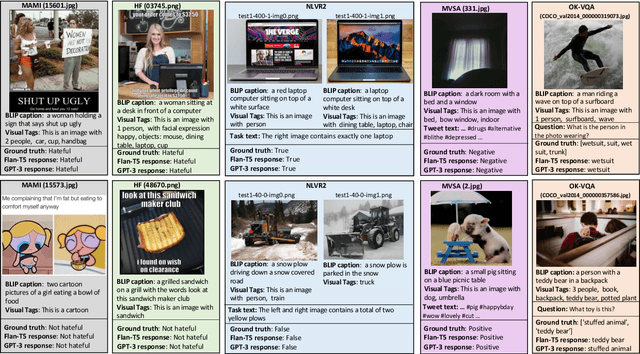
Large language models have demonstrated robust performance on various language tasks using zero-shot or few-shot learning paradigms. While being actively researched, multimodal models that can additionally handle images as input have yet to catch up in size and generality with language-only models. In this work, we ask whether language-only models can be utilised for tasks that require visual input -- but also, as we argue, often require a strong reasoning component. Similar to some recent related work, we make visual information accessible to the language model using separate verbalisation models. Specifically, we investigate the performance of open-source, open-access language models against GPT-3 on five vision-language tasks when given textually-encoded visual information. Our results suggest that language models are effective for solving vision-language tasks even with limited samples. This approach also enhances the interpretability of a model's output by providing a means of tracing the output back through the verbalised image content.
Gallery Sampling for Robust and Fast Face Identification
May 12, 2023
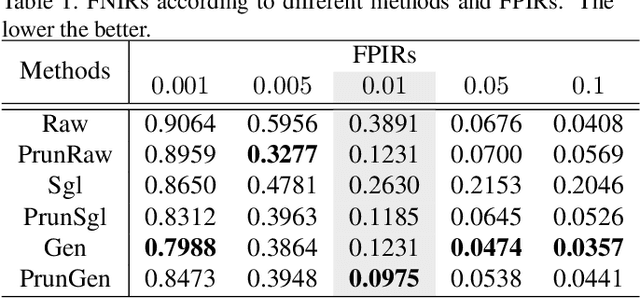
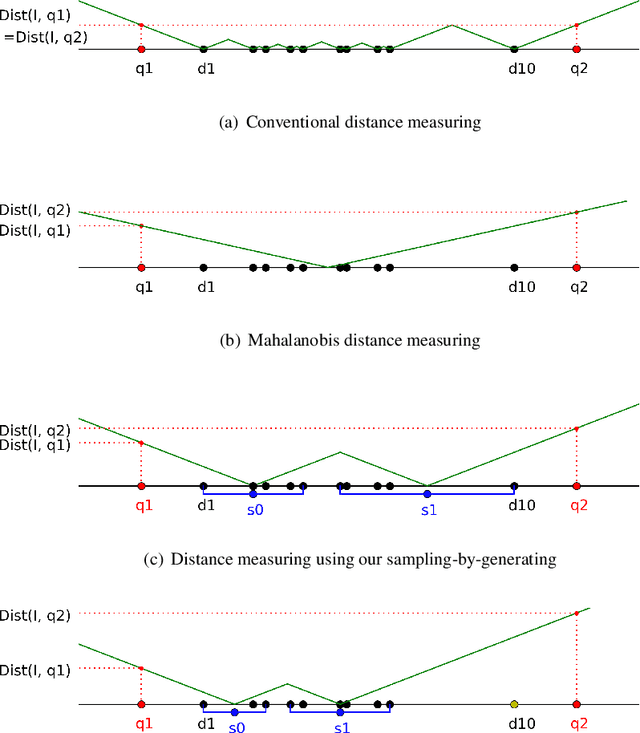
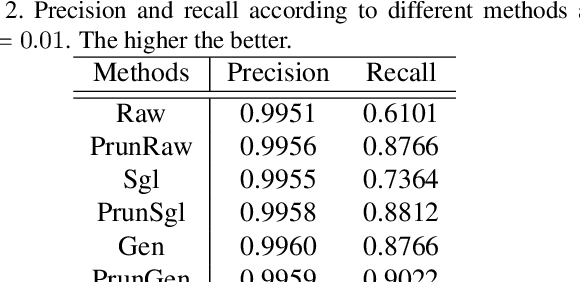
Deep learning methods have been achieved brilliant results in face recognition. One of the important tasks to improve the performance is to collect and label images as many as possible. However, labeling identities and checking qualities of large image data are difficult task and mistakes cannot be avoided in processing large data. Previous works have been trying to deal with the problem only in training domain, however it can cause much serious problem if the mistakes are in gallery data of face identification. We proposed gallery data sampling methods which are robust to outliers including wrong labeled, low quality, and less-informative images and reduce searching time. The proposed sampling-by-pruning and sampling-by-generating methods significantly improved face identification performance on our 5.4M web image dataset of celebrities. The proposed method achieved 0.0975 in terms of FNIR at FPIR=0.01, while conventional method showed 0.3891. The average number of feature vectors for each individual gallery was reduced to 17.1 from 115.9 and it can provide much faster search. We also made experiments on public datasets and our method achieved 0.1314 and 0.0668 FNIRs at FPIR=0.01 on the CASIA-WebFace and MS1MV2, while the convectional method did 0.5446, and 0.1327, respectively.