 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explainable Knowledge Distillation for On-device Chest X-Ray Classification
May 10, 2023
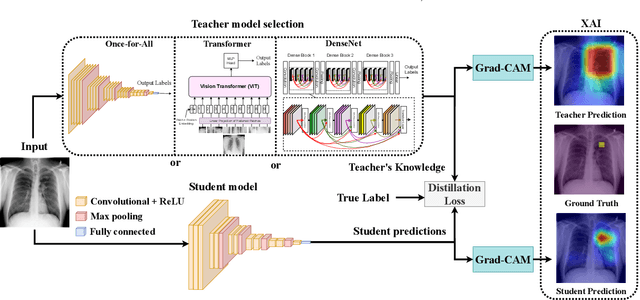

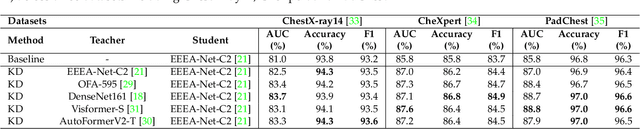
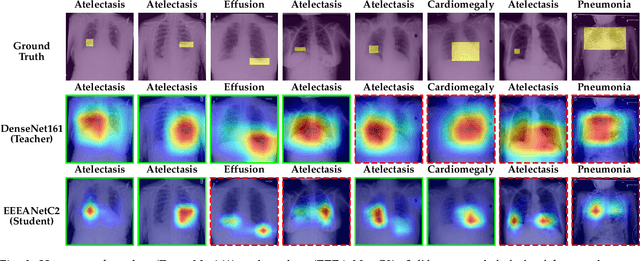
Automated multi-label chest X-rays (CXR) image classification has achieved substantial progress in clinical diagnosis via utilizing sophisticated deep learning approaches. However, most deep models have high computational demands, which makes them less feasible for compact devices with low computational requirements. To overcome this problem, we propose a knowledge distillation (KD) strategy to create the compact deep learning model for the real-time multi-label CXR image classification. We study different alternatives of CNNs and Transforms as the teacher to distill the knowledge to a smaller student. Then, we employed explainable artificial intelligence (XAI) to provide the visual explanation for the model decision improved by the KD. Our results on three benchmark CXR datasets show that our KD strategy provides the improved performance on the compact student model, thus being the feasible choice for many limited hardware platforms. For instance, when using DenseNet161 as the teacher network, EEEA-Net-C2 achieved an AUC of 83.7%, 87.1%, and 88.7% on the ChestX-ray14, CheXpert, and PadChest datasets, respectively, with fewer parameters of 4.7 million and computational cost of 0.3 billion FLOPS.
Text-guided High-definition Consistency Texture Model
May 10, 2023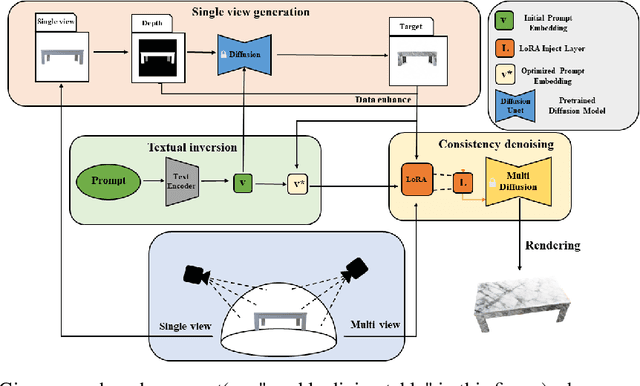
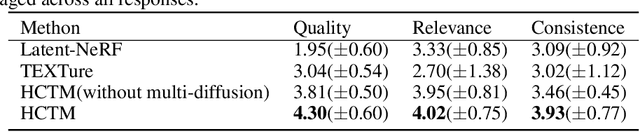


With the advent of depth-to-image diffusion models, text-guided generation, editing, and transfer of realistic textures are no longer difficult. However, due to the limitations of pre-trained diffusion models, they can only create low-resolution, inconsistent textures. To address this issue, we present the High-definition Consistency Texture Model (HCTM), a novel method that can generate high-definition and consistent textures for 3D meshes according to the text prompts. We achieve this by leveraging a pre-trained depth-to-image diffusion model to generate single viewpoint results based on the text prompt and a depth map. We fine-tune the diffusion model with Parameter-Efficient Fine-Tuning to quickly learn the style of the generated result, and apply the multi-diffusion strategy to produce high-resolution and consistent results from different viewpoints. Furthermore, we propose a strategy that prevents the appearance of noise on the textures caused by backpropagation. Our proposed approach has demonstrated promising results in generating high-definition and consistent textures for 3D meshes, as demonstrated through a series of experiments.
DAFD: Domain Adaptation via Feature Disentanglement for Image Classification
Jan 30, 2023
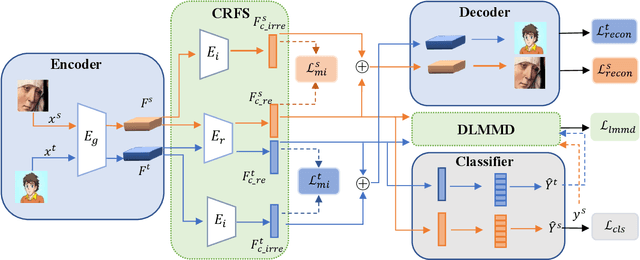
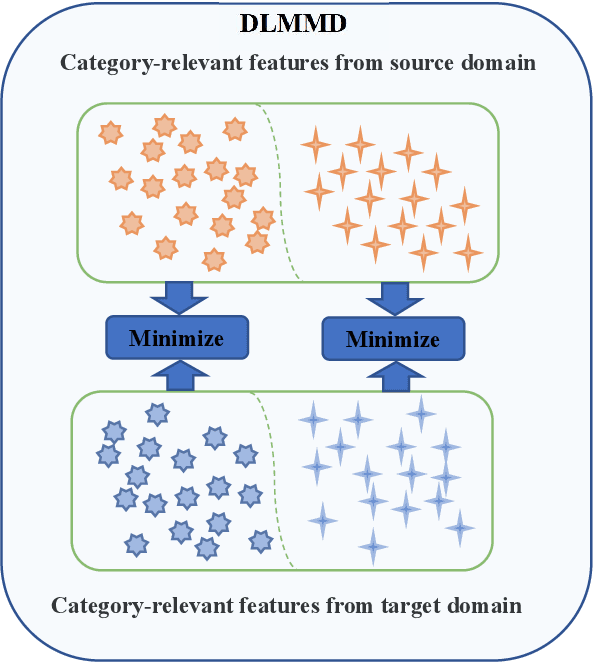

A good feature representation is the key to image classification. In practice, image classifiers may be applied in scenarios different from what they have been trained on. This so-called domain shift leads to a significant performance drop in image classification. Unsupervised domain adaptation (UDA) reduces the domain shift by transferring the knowledge learned from a labeled source domain to an unlabeled target domain. We perform feature disentanglement for UDA by distilling category-relevant features and excluding category-irrelevant features from the global feature maps. This disentanglement prevents the network from overfitting to category-irrelevant information and makes it focus on information useful for classification. This reduces the difficulty of domain alignment and improves the classification accuracy on the target domain. We propose a coarse-to-fine domain adaptation method called Domain Adaptation via Feature Disentanglement~(DAFD), which has two components: (1)the Category-Relevant Feature Selection (CRFS) module, which disentangles the category-relevant features from the category-irrelevant features, and (2)the Dynamic Local Maximum Mean Discrepancy (DLMMD) module, which achieves fine-grained alignment by reducing the discrepancy within the category-relevant features from different domains. Combined with the CRFS, the DLMMD module can align the category-relevant features properly. We conduct comprehensive experiment on four standard datasets. Our results clearly demonstrate the robustness and effectiveness of our approach in domain adaptive image classification tasks and its competitiveness to the state of the art.
Transforming Geospatial Ontologies by Homomorphisms
May 22, 2023In this paper, we study the (geospatial) ontologies we are interested in together as an ontology (a geospatial ontology) system, consisting of a set of the (geospatial) ontologies and a set of ontology operations. A homomorphism between two ontology systems is a function between two sets of ontologies, which preserves these ontology operations. We view clustering a set of the ontologies we are interested in as partitioning the set or defining an equivalence relation on the set or forming a quotient set of the set or obtaining the surjective image of the set. Each ontology system homomorphism can be factored as a surjective clustering to a quotient space, followed by an embedding. Ontology (merging) systems, natural partial orders on the systems, and ontology merging closures in the systems are then transformed under ontology system homomorphisms, given by quotients and embeddings.
CFFT-GAN: Cross-domain Feature Fusion Transformer for Exemplar-based Image Translation
Feb 03, 2023

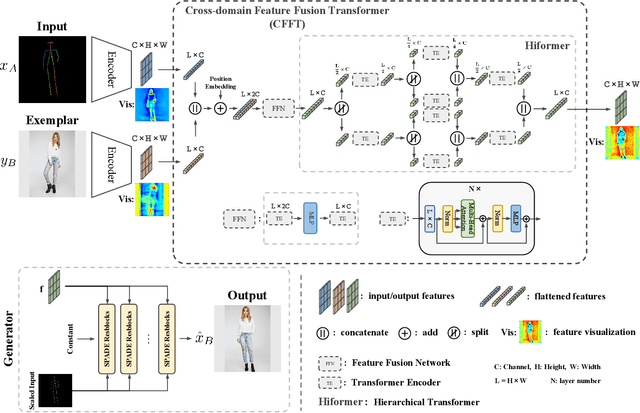
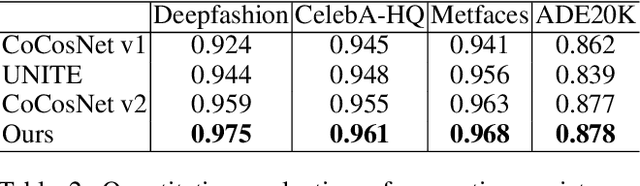
Exemplar-based image translation refers to the task of generating images with the desired style, while conditioning on certain input image. Most of the current methods learn the correspondence between two input domains and lack the mining of information within the domains. In this paper, we propose a more general learning approach by considering two domain features as a whole and learning both inter-domain correspondence and intra-domain potential information interactions. Specifically, we propose a Cross-domain Feature Fusion Transformer (CFFT) to learn inter- and intra-domain feature fusion. Based on CFFT, the proposed CFFT-GAN works well on exemplar-based image translation. Moreover, CFFT-GAN is able to decouple and fuse features from multiple domains by cascading CFFT modules. We conduct rich quantitative and qualitative experiments on several image translation tasks, and the results demonstrate the superiority of our approach compared to state-of-the-art methods. Ablation studies show the importance of our proposed CFFT. Application experimental results reflect the potential of our method.
Spatial and Modal Optimal Transport for Fast Cross-Modal MRI Reconstruction
May 04, 2023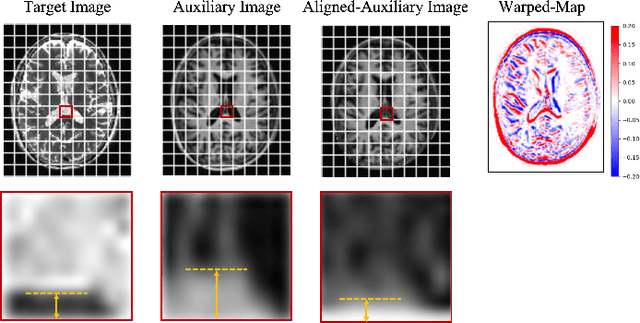
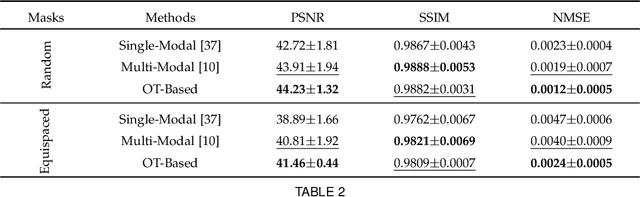
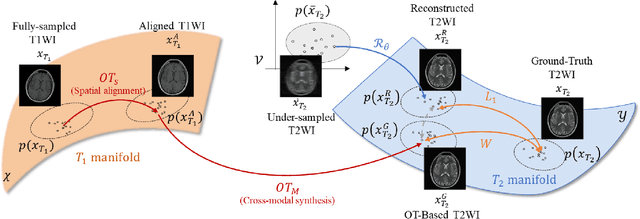
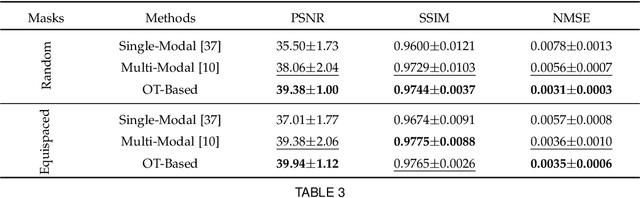
Multi-modal Magnetic Resonance Imaging (MRI) plays an important role in clinical medicine. However, the acquisitions of some modalities, such as the T2-weighted modality, need a long time and they are always accompanied by motion artifacts. On the other hand, the T1-weighted image (T1WI) shares the same underlying information with T2-weighted image (T2WI), which needs a shorter scanning time. Therefore, in this paper we accelerate the acquisition of the T2WI by introducing the auxiliary modality (T1WI). Concretely, we first reconstruct high-quality T2WIs with under-sampled T2WIs. Here, we realize fast T2WI reconstruction by reducing the sampling rate in the k-space. Second, we establish a cross-modal synthesis task to generate the synthetic T2WIs for guiding better T2WI reconstruction. Here, we obtain the synthetic T2WIs by decomposing the whole cross-modal generation mapping into two OT processes, the spatial alignment mapping on the T1 image manifold and the cross-modal synthesis mapping from aligned T1WIs to T2WIs. It overcomes the negative transfer caused by the spatial misalignment. Then, we prove the reconstruction and the synthesis tasks are well complementary. Finally, we compare it with state-of-the-art approaches on an open dataset FastMRI and an in-house dataset to testify the validity of the proposed method.
Use the Detection Transformer as a Data Augmenter
Apr 26, 2023
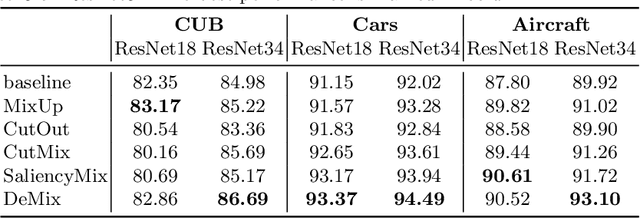
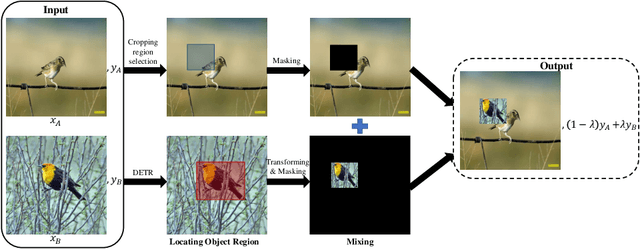
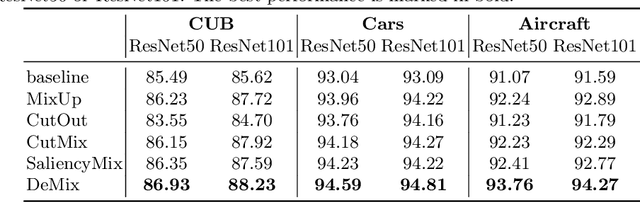
Detection Transformer (DETR) is a Transformer architecture based object detection model. In this paper, we demonstrate that it can also be used as a data augmenter. We term our approach as DETR assisted CutMix, or DeMix for short. DeMix builds on CutMix, a simple yet highly effective data augmentation technique that has gained popularity in recent years. CutMix improves model performance by cutting and pasting a patch from one image onto another, yielding a new image. The corresponding label for this new example is specified as the weighted average of the original labels, where the weight is proportional to the area of the patch. CutMix selects a random patch to be cut. In contrast, DeMix elaborately selects a semantically rich patch, located by a pre-trained DETR. The label of the new image is specified in the same way as in CutMix. Experimental results on benchmark datasets for image classification demonstrate that DeMix significantly outperforms prior art data augmentation methods including CutMix. Oue code is available at https://github.com/ZJLAB-AMMI/DeMix.
On enhancing the robustness of Vision Transformers: Defensive Diffusion
May 14, 2023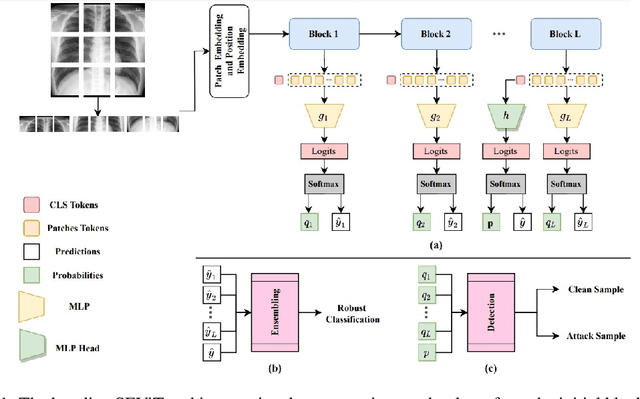
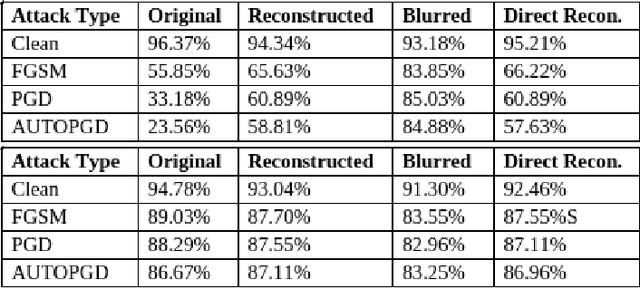
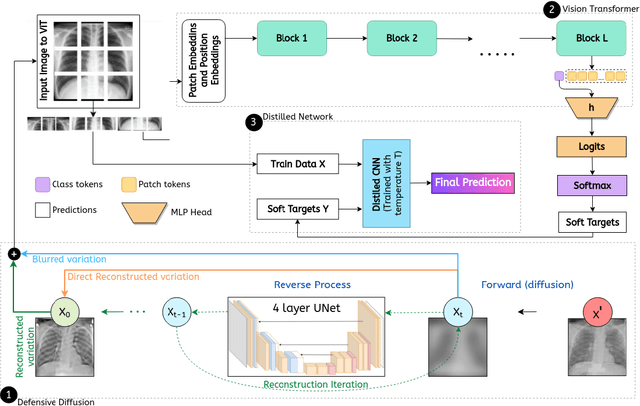
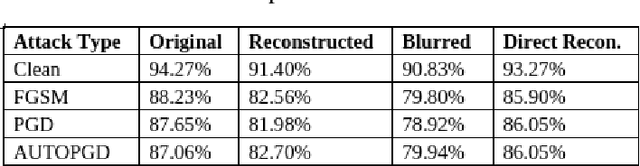
Privacy and confidentiality of medical data are of utmost importance in healthcare settings. ViTs, the SOTA vision model, rely on large amounts of patient data for training, which raises concerns about data security and the potential for unauthorized access. Adversaries may exploit vulnerabilities in ViTs to extract sensitive patient information and compromising patient privacy. This work address these vulnerabilities to ensure the trustworthiness and reliability of ViTs in medical applications. In this work, we introduced a defensive diffusion technique as an adversarial purifier to eliminate adversarial noise introduced by attackers in the original image. By utilizing the denoising capabilities of the diffusion model, we employ a reverse diffusion process to effectively eliminate the adversarial noise from the attack sample, resulting in a cleaner image that is then fed into the ViT blocks. Our findings demonstrate the effectiveness of the diffusion model in eliminating attack-agnostic adversarial noise from images. Additionally, we propose combining knowledge distillation with our framework to obtain a lightweight student model that is both computationally efficient and robust against gray box attacks. Comparison of our method with a SOTA baseline method, SEViT, shows that our work is able to outperform the baseline. Extensive experiments conducted on a publicly available Tuberculosis X-ray dataset validate the computational efficiency and improved robustness achieved by our proposed architecture.
Attribute-Centric Compositional Text-to-Image Generation
Jan 04, 2023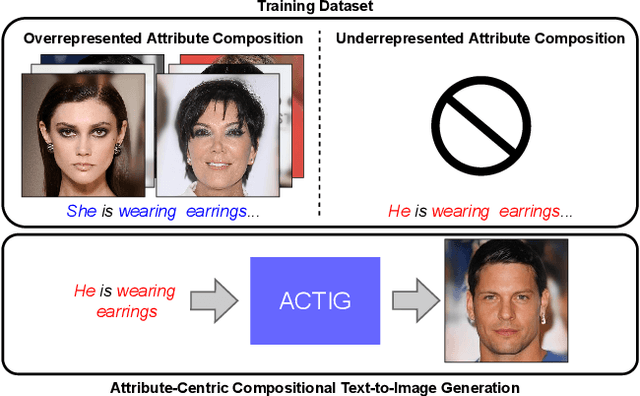
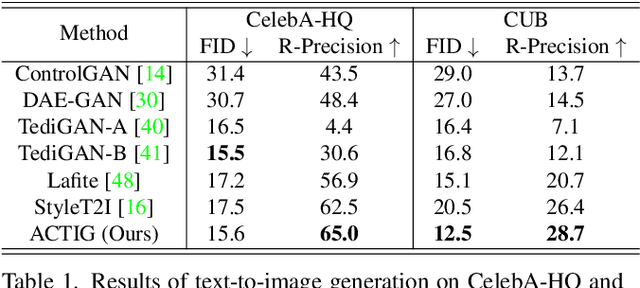
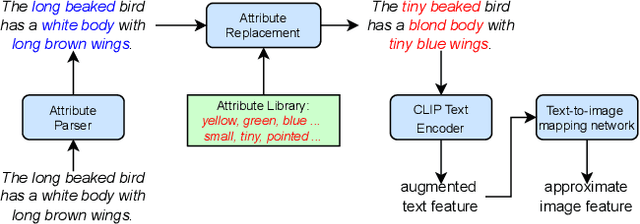
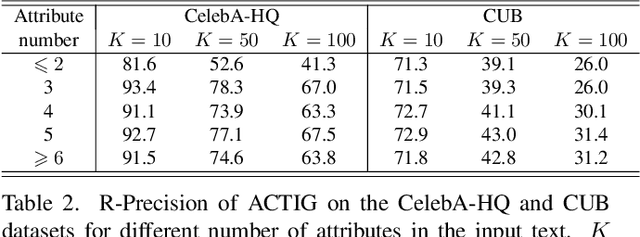
Despite the recent impressive breakthroughs in text-to-image generation, generative models have difficulty in capturing the data distribution of underrepresented attribute compositions while over-memorizing overrepresented attribute compositions, which raises public concerns about their robustness and fairness. To tackle this challenge, we propose ACTIG, an attribute-centric compositional text-to-image generation framework. We present an attribute-centric feature augmentation and a novel image-free training scheme, which greatly improves model's ability to generate images with underrepresented attributes. We further propose an attribute-centric contrastive loss to avoid overfitting to overrepresented attribute compositions. We validate our framework on the CelebA-HQ and CUB datasets. Extensive experiments show that the compositional generalization of ACTIG is outstanding, and our framework outperforms previous works in terms of image quality and text-image consistency.
Iteratively Coupled Multiple Instance Learning from Instance to Bag Classifier for Whole Slide Image Classification
Mar 28, 2023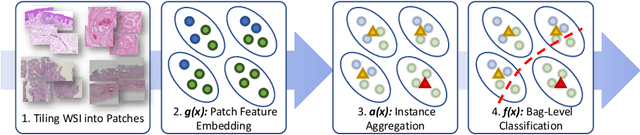

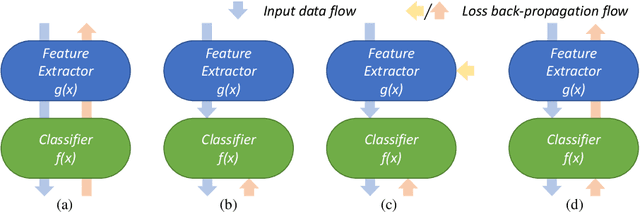
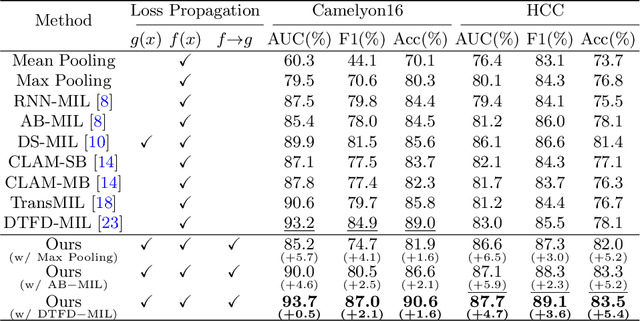
Whole Slide Image (WSI) classification remains a challenge due to their extremely high resolution and the absence of fine-grained labels. Presently, WSIs are usually classified as a Multiple Instance Learning (MIL) problem when only slide-level labels are available. MIL methods involve a patch embedding process and a bag-level classification process, but they are prohibitively expensive to be trained end-to-end. Therefore, existing methods usually train them separately, or directly skip the training of the embedder. Such schemes hinder the patch embedder's access to slide-level labels, resulting in inconsistencies within the entire MIL pipeline. To overcome this issue, we propose a novel framework called Iteratively Coupled MIL (ICMIL), which bridges the loss back-propagation process from the bag-level classifier to the patch embedder. In ICMIL, we use category information in the bag-level classifier to guide the patch-level fine-tuning of the patch feature extractor. The refined embedder then generates better instance representations for achieving a more accurate bag-level classifier. By coupling the patch embedder and bag classifier at a low cost, our proposed framework enables information exchange between the two processes, benefiting the entire MIL classification model. We tested our framework on two datasets using three different backbones, and our experimental results demonstrate consistent performance improvements over state-of-the-art MIL methods. Code will be made available upon acceptance.