 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-BVOC Super-Resolution Exploiting Compounds Inter-Connection
May 23, 2023
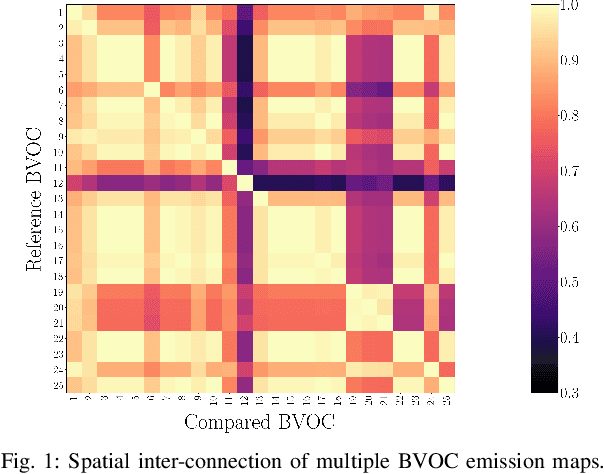
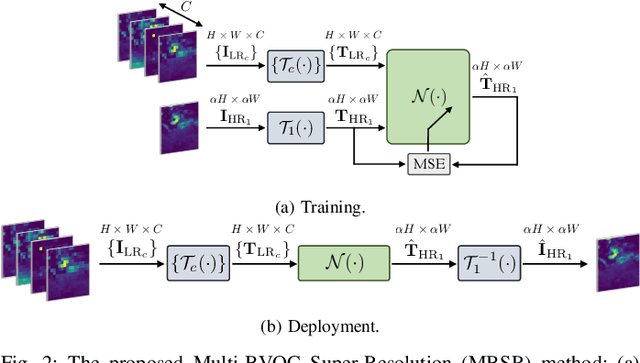
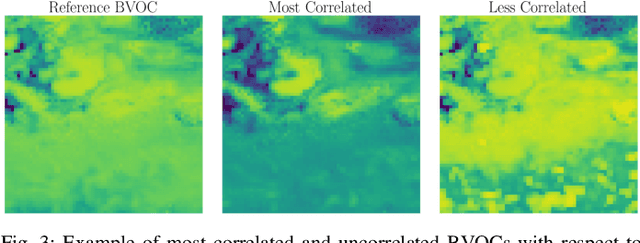
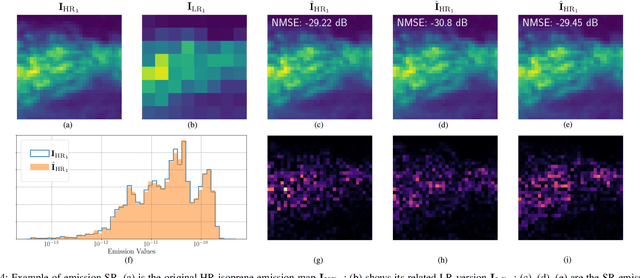
Biogenic Volatile Organic Compounds (BVOCs) emitted from the terrestrial ecosystem into the Earth's atmosphere are an important component of atmospheric chemistry. Due to the scarcity of measurement, a reliable enhancement of BVOCs emission maps can aid in providing denser data for atmospheric chemical, climate, and air quality models. In this work, we propose a strategy to super-resolve coarse BVOC emission maps by simultaneously exploiting the contributions of different compounds. To this purpose, we first accurately investigate the spatial inter-connections between several BVOC species. Then, we exploit the found similarities to build a Multi-Image Super-Resolution (MISR) system, in which a number of emission maps associated with diverse compounds are aggregated to boost Super-Resolution (SR) performance. We compare different configurations regarding the species and the number of joined BVOCs. Our experimental results show that incorporating BVOCs' relationship into the process can substantially improve the accuracy of the super-resolved maps. Interestingly, the best results are achieved when we aggregate the emission maps of strongly uncorrelated compounds. This peculiarity seems to confirm what was already guessed for other data-domains, i.e., joined uncorrelated information are more helpful than correlated ones to boost MISR performance. Nonetheless, the proposed work represents the first attempt in SR of BVOC emissions through the fusion of multiple different compounds.
Cold PAWS: Unsupervised class discovery and the cold-start problem
May 17, 2023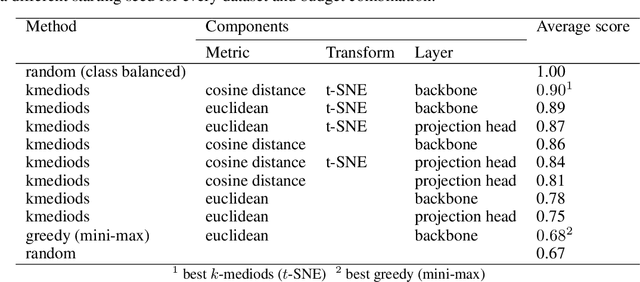
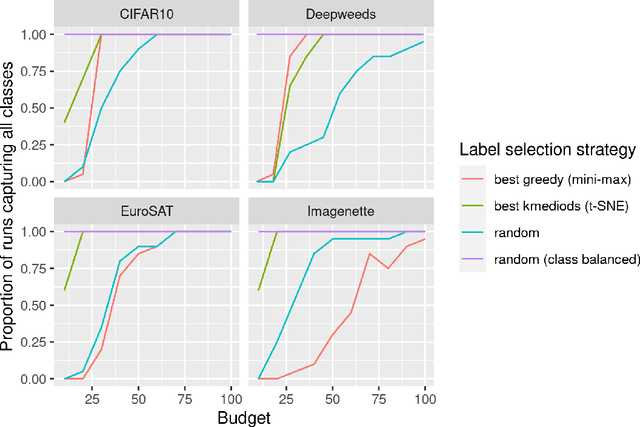
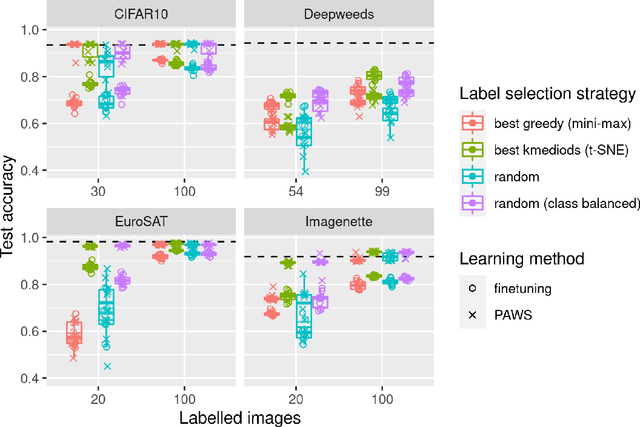

In many machine learning applications, labeling datasets can be an arduous and time-consuming task. Although research has shown that semi-supervised learning techniques can achieve high accuracy with very few labels within the field of computer vision, little attention has been given to how images within a dataset should be selected for labeling. In this paper, we propose a novel approach based on well-established self-supervised learning, clustering, and manifold learning techniques that address this challenge of selecting an informative image subset to label in the first instance, which is known as the cold-start or unsupervised selective labelling problem. We test our approach using several publicly available datasets, namely CIFAR10, Imagenette, DeepWeeds, and EuroSAT, and observe improved performance with both supervised and semi-supervised learning strategies when our label selection strategy is used, in comparison to random sampling. We also obtain superior performance for the datasets considered with a much simpler approach compared to other methods in the literature.
Logit-Based Ensemble Distribution Distillation for Robust Autoregressive Sequence Uncertainties
May 17, 2023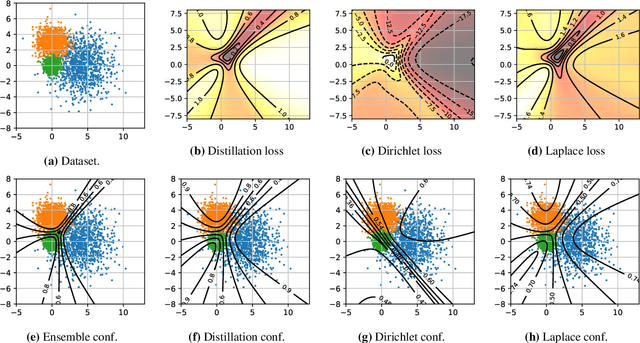
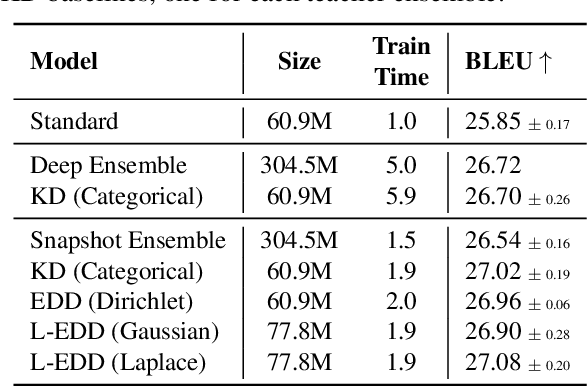
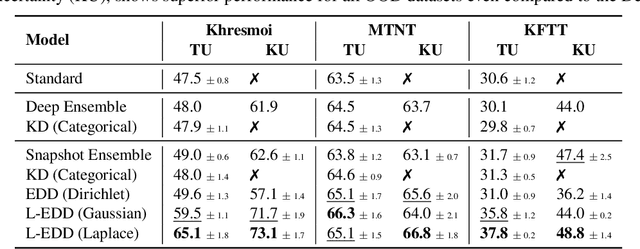
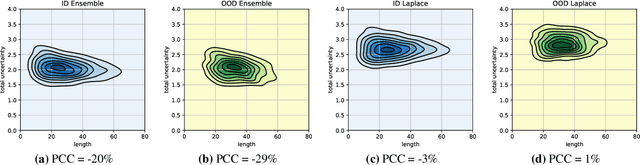
Efficiently and reliably estimating uncertainty is an important objective in deep learning. It is especially pertinent to autoregressive sequence tasks, where training and inference costs are typically very high. However, existing research has predominantly focused on tasks with static data such as image classification. In this work, we investigate Ensemble Distribution Distillation (EDD) applied to large-scale natural language sequence-to-sequence data. EDD aims to compress the superior uncertainty performance of an expensive (teacher) ensemble into a cheaper (student) single model. Importantly, the ability to separate knowledge (epistemic) and data (aleatoric) uncertainty is retained. Existing probability-space approaches to EDD, however, are difficult to scale to large vocabularies. We show, for modern transformer architectures on large-scale translation tasks, that modelling the ensemble logits, instead of softmax probabilities, leads to significantly better students. Moreover, the students surprisingly even outperform Deep Ensembles by up to ~10% AUROC on out-of-distribution detection, whilst matching them at in-distribution translation.
HICO-DET-SG and V-COCO-SG: New Data Splits to Evaluate Systematic Generalization in Human-Object Interaction Detection
May 17, 2023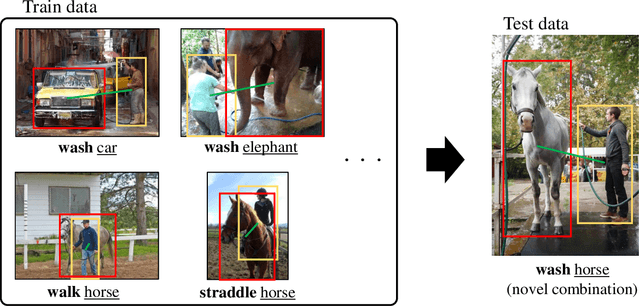
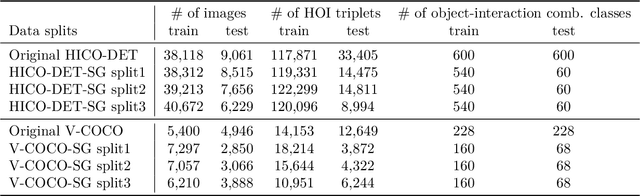
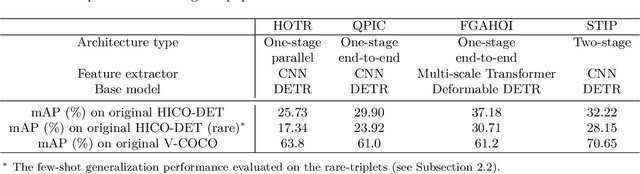
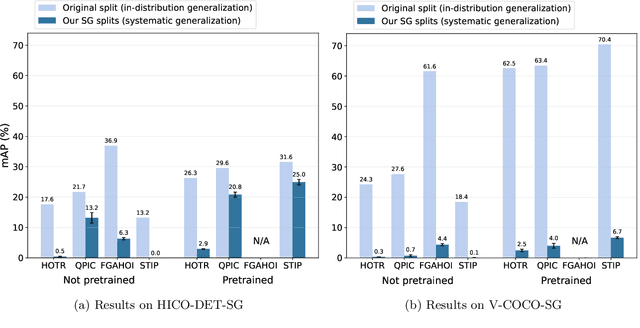
Human-Object Interaction (HOI) detection is a task to predict interactions between humans and objects in an image. In real-world scenarios, HOI detection models are required systematic generalization, i.e., generalization to novel combinations of objects and interactions, because it is highly probable that the train data only cover a limited portion of all possible combinations. However, to our knowledge, no open benchmark or existing work evaluates the systematic generalization in HOI detection. To address this issue, we created two new sets of HOI detection data splits named HICO-DET-SG and V-COCO-SG based on HICO-DET and V-COCO datasets. We evaluated representative HOI detection models on the new data splits and observed large degradation in the test performances compared to those on the original datasets. This result shows that systematic generalization is a challenging goal in HOI detection. We hope our new data splits encourage more research toward this goal.
TextSLAM: Visual SLAM with Semantic Planar Text Features
May 17, 2023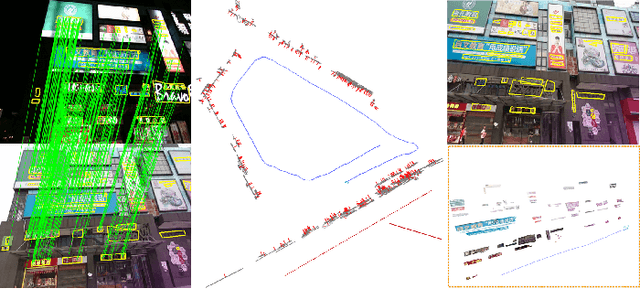

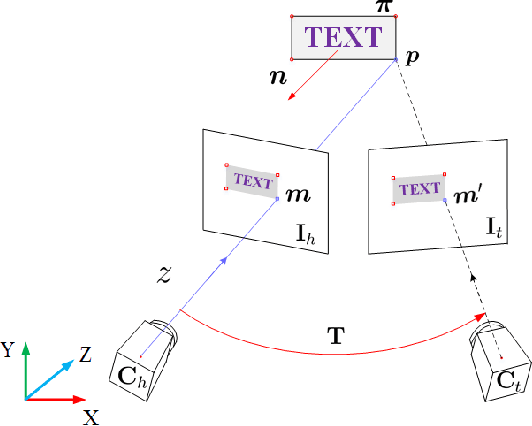
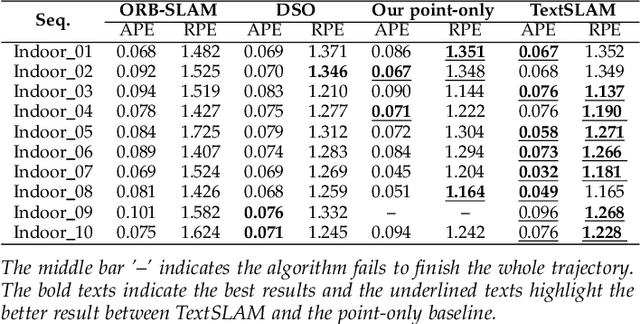
We propose a novel visual SLAM method that integrates text objects tightly by treating them as semantic features via fully exploring their geometric and semantic prior. The text object is modeled as a texture-rich planar patch whose semantic meaning is extracted and updated on the fly for better data association. With the full exploration of locally planar characteristics and semantic meaning of text objects, the SLAM system becomes more accurate and robust even under challenging conditions such as image blurring, large viewpoint changes, and significant illumination variations (day and night). We tested our method in various scenes with the ground truth data. The results show that integrating texture features leads to a more superior SLAM system that can match images across day and night. The reconstructed semantic 3D text map could be useful for navigation and scene understanding in robotic and mixed reality applications. Our project page: https://github.com/SJTU-ViSYS/TextSLAM .
MoE-Fusion: Instance Embedded Mixture-of-Experts for Infrared and Visible Image Fusion
Feb 02, 2023
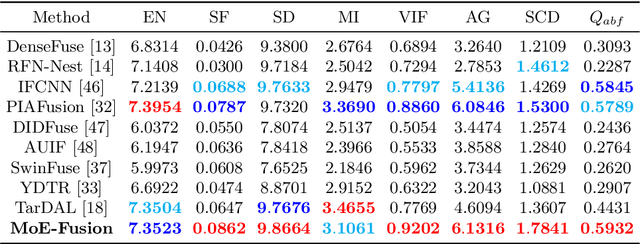
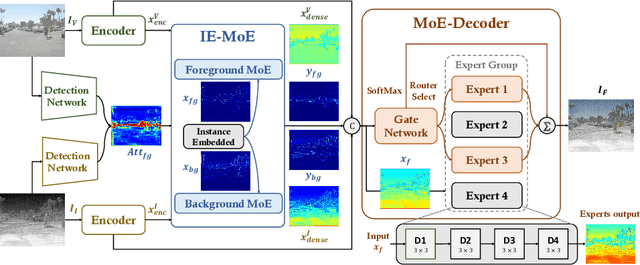
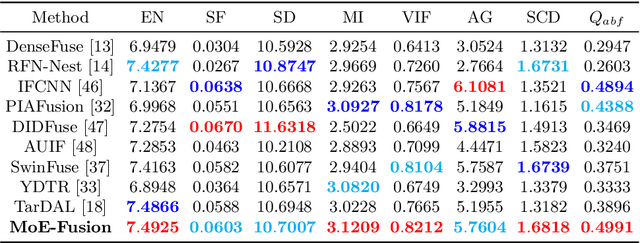
Infrared and visible image fusion can compensate for the incompleteness of single-modality imaging and provide a more comprehensive scene description based on cross-modal complementarity. Most works focus on learning the overall cross-modal features by high- and low-frequency constraints at the image level alone, ignoring the fact that cross-modal instance-level features often contain more valuable information. To fill this gap, we model cross-modal instance-level features by embedding instance information into a set of Mixture-of-Experts (MoEs) for the first time, prompting image fusion networks to specifically learn instance-level information. We propose a novel framework with instance embedded Mixture-of-Experts for infrared and visible image fusion, termed MoE-Fusion, which contains an instance embedded MoE group (IE-MoE), an MoE-Decoder, two encoders, and two auxiliary detection networks. By embedding the instance-level information learned in the auxiliary network, IE-MoE achieves specialized learning of cross-modal foreground and background features. MoE-Decoder can adaptively select suitable experts for cross-modal feature decoding and obtain fusion results dynamically. Extensive experiments show that our MoE-Fusion outperforms state-of-the-art methods in preserving contrast and texture details by learning instance-level information in cross-modal images.
Collaborative Discrepancy Optimization for Reliable Image Anomaly Localization
Feb 17, 2023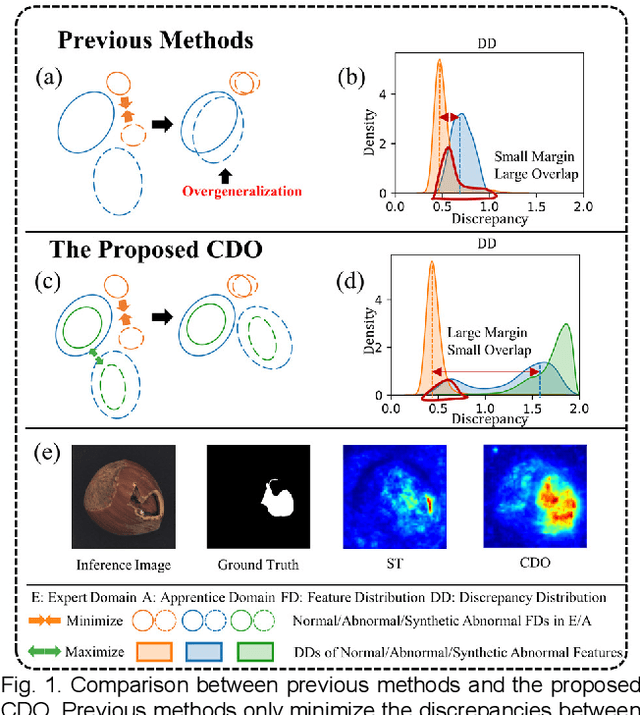
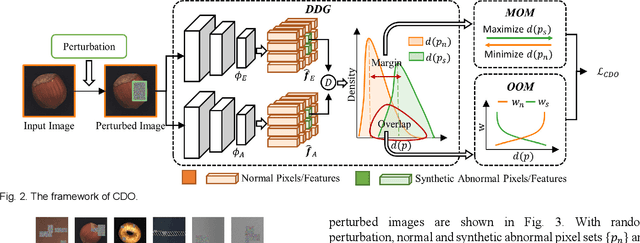
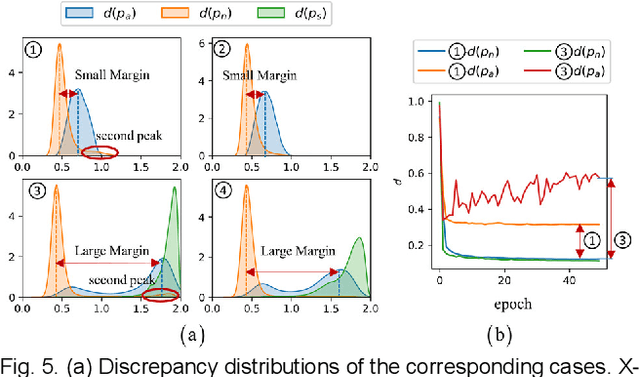
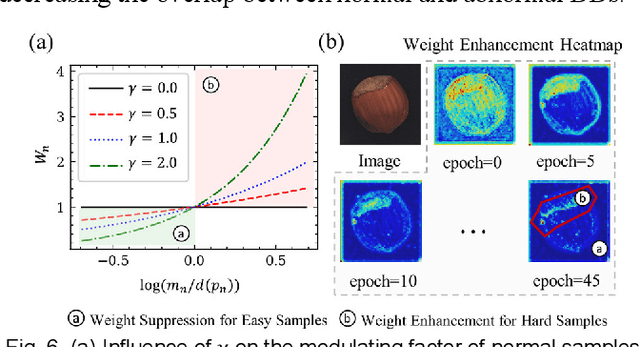
Most unsupervised image anomaly localization methods suffer from overgeneralization because of the high generalization abilities of convolutional neural networks, leading to unreliable predictions. To mitigate the overgeneralization, this study proposes to collaboratively optimize normal and abnormal feature distributions with the assistance of synthetic anomalies, namely collaborative discrepancy optimization (CDO). CDO introduces a margin optimization module and an overlap optimization module to optimize the two key factors determining the localization performance, i.e., the margin and the overlap between the discrepancy distributions (DDs) of normal and abnormal samples. With CDO, a large margin and a small overlap between normal and abnormal DDs are obtained, and the prediction reliability is boosted. Experiments on MVTec2D and MVTec3D show that CDO effectively mitigates the overgeneralization and achieves great anomaly localization performance with real-time computation efficiency. A real-world automotive plastic parts inspection application further demonstrates the capability of the proposed CDO. Code is available on https://github.com/caoyunkang/CDO.
* Accepted by IEEE Transactions on Industrial Informatics
What can generic neural networks learn from a child's visual experience?
May 24, 2023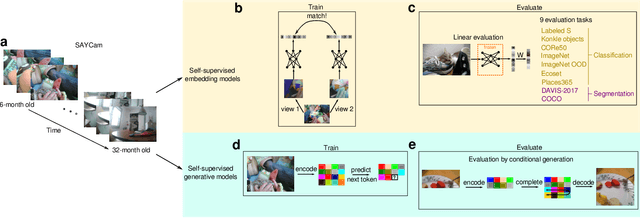
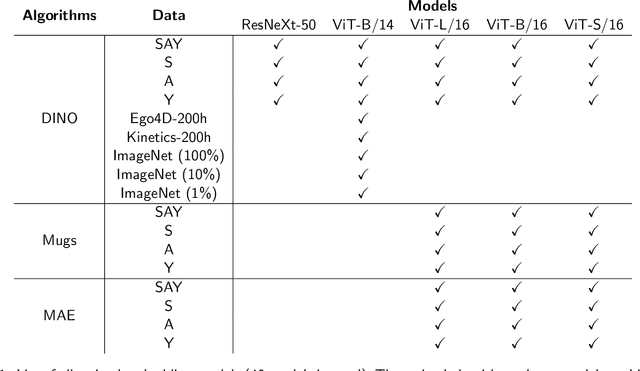
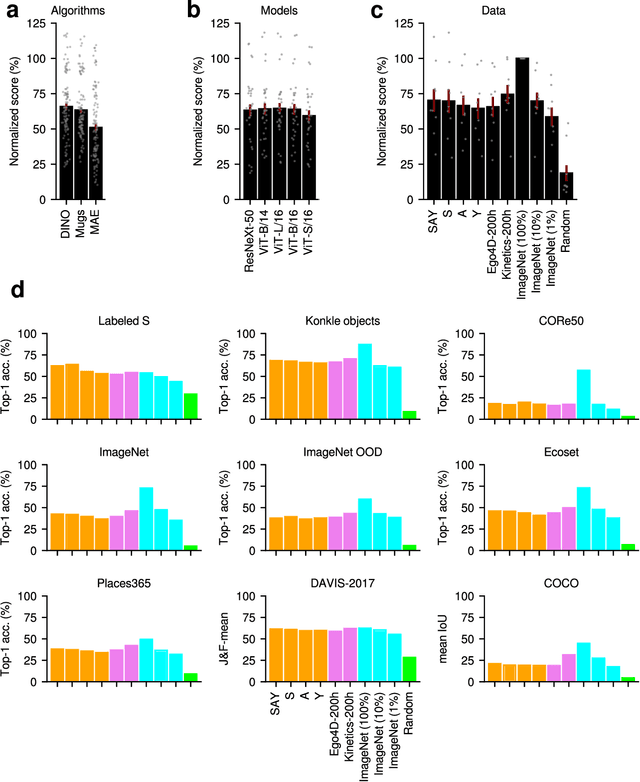
Young children develop sophisticated internal models of the world based on their egocentric visual experience. How much of this is driven by innate constraints and how much is driven by their experience? To investigate these questions, we train state-of-the-art neural networks on a realistic proxy of a child's visual experience without any explicit supervision or domain-specific inductive biases. Specifically, we train both embedding models and generative models on 200 hours of headcam video from a single child collected over two years. We train a total of 72 different models, exploring a range of model architectures and self-supervised learning algorithms, and comprehensively evaluate their performance in downstream tasks. The best embedding models perform at 70% of a highly performant ImageNet-trained model on average. They also learn broad semantic categories without any labeled examples and learn to localize semantic categories in an image without any location supervision. However, these models are less object-centric and more background-sensitive than comparable ImageNet-trained models. Generative models trained with the same data successfully extrapolate simple properties of partially masked objects, such as their texture, color, orientation, and rough outline, but struggle with finer object details. We replicate our experiments with two other children and find very similar results. Broadly useful high-level visual representations are thus robustly learnable from a representative sample of a child's visual experience without strong inductive biases.
Album Storytelling with Iterative Story-aware Captioning and Large Language Models
May 24, 2023
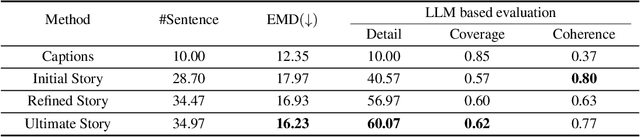
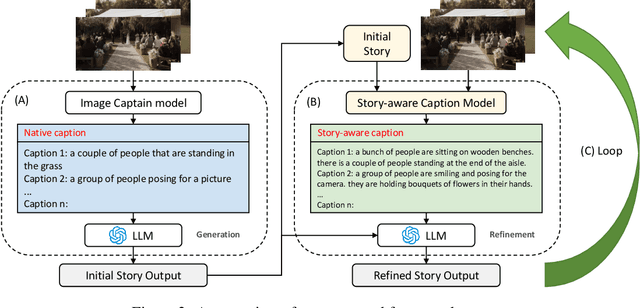

This work studies how to transform an album to vivid and coherent stories, a task we refer to as "album storytelling". While this task can help preserve memories and facilitate experience sharing, it remains an underexplored area in current literature. With recent advances in Large Language Models (LLMs), it is now possible to generate lengthy, coherent text, opening up the opportunity to develop an AI assistant for album storytelling. One natural approach is to use caption models to describe each photo in the album, and then use LLMs to summarize and rewrite the generated captions into an engaging story. However, we find this often results in stories containing hallucinated information that contradicts the images, as each generated caption ("story-agnostic") is not always about the description related to the whole story or miss some necessary information. To address these limitations, we propose a new iterative album storytelling pipeline. Specifically, we start with an initial story and build a story-aware caption model to refine the captions using the whole story as guidance. The polished captions are then fed into the LLMs to generate a new refined story. This process is repeated iteratively until the story contains minimal factual errors while maintaining coherence. To evaluate our proposed pipeline, we introduce a new dataset of image collections from vlogs and a set of systematic evaluation metrics. Our results demonstrate that our method effectively generates more accurate and engaging stories for albums, with enhanced coherence and vividness.
Vision and Control for Grasping Clear Plastic Bags
May 12, 2023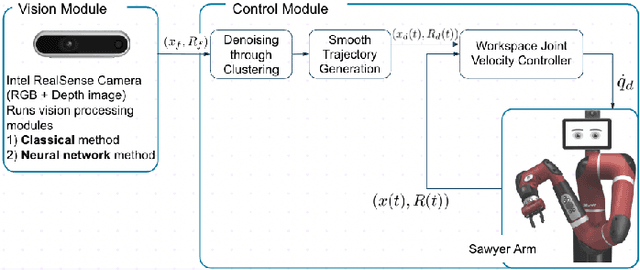

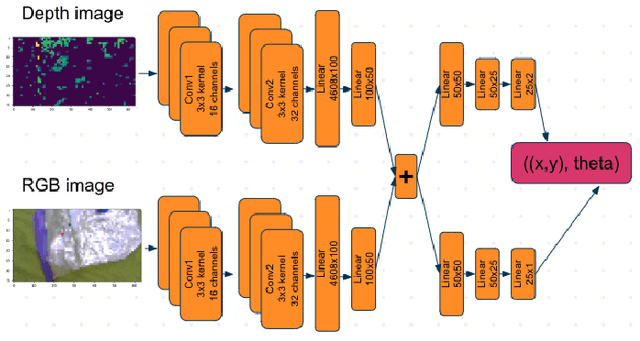
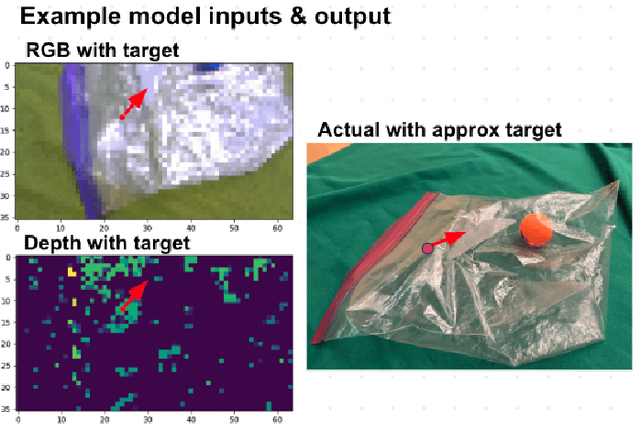
We develop two novel vision methods for planning effective grasps for clear plastic bags, as well as a control method to enable a Sawyer arm with a parallel gripper to execute the grasps. The first vision method is based on classical image processing and heuristics (e.g., Canny edge detection) to select a grasp target and angle. The second uses a deep-learning model trained on a human-labeled data set to mimic human grasp decisions. A clustering algorithm is used to de-noise the outputs of each vision method. Subsequently, a workspace PD control method is used to execute each grasp. Of the two vision methods, we find the deep-learning based method to be more effective.