 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PrimeComposer: Faster Progressively Combined Diffusion for Image Composition with Attention Steering
Mar 08, 2024

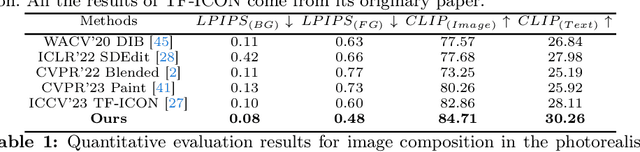

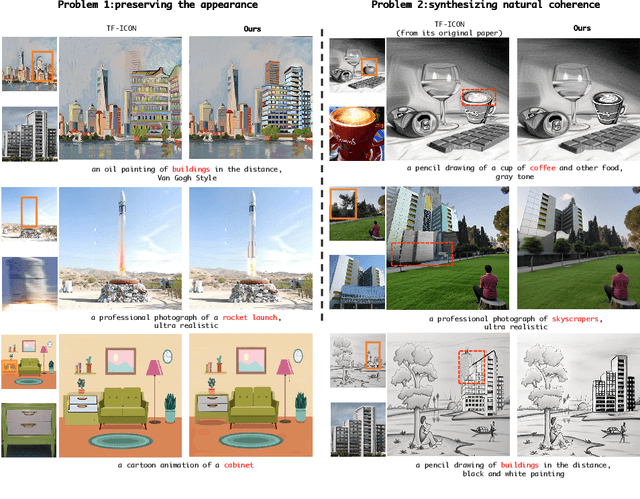
Image composition involves seamlessly integrating given objects into a specific visual context. The current training-free methods rely on composing attention weights from several samplers to guide the generator. However, since these weights are derived from disparate contexts, their combination leads to coherence confusion in synthesis and loss of appearance information. These issues worsen with their excessive focus on background generation, even when unnecessary in this task. This not only slows down inference but also compromises foreground generation quality. Moreover, these methods introduce unwanted artifacts in the transition area. In this paper, we formulate image composition as a subject-based local editing task, solely focusing on foreground generation. At each step, the edited foreground is combined with the noisy background to maintain scene consistency. To address the remaining issues, we propose PrimeComposer, a faster training-free diffuser that composites the images by well-designed attention steering across different noise levels. This steering is predominantly achieved by our Correlation Diffuser, utilizing its self-attention layers at each step. Within these layers, the synthesized subject interacts with both the referenced object and background, capturing intricate details and coherent relationships. This prior information is encoded into the attention weights, which are then integrated into the self-attention layers of the generator to guide the synthesis process. Besides, we introduce a Region-constrained Cross-Attention to confine the impact of specific subject-related words to desired regions, addressing the unwanted artifacts shown in the prior method thereby further improving the coherence in the transition area. Our method exhibits the fastest inference efficiency and extensive experiments demonstrate our superiority both qualitatively and quantitatively.
A Simple Framework Uniting Visual In-context Learning with Masked Image Modeling to Improve Ultrasound Segmentation
Mar 08, 2024Conventional deep learning models deal with images one-by-one, requiring costly and time-consuming expert labeling in the field of medical imaging, and domain-specific restriction limits model generalizability. Visual in-context learning (ICL) is a new and exciting area of research in computer vision. Unlike conventional deep learning, ICL emphasizes the model's ability to adapt to new tasks based on given examples quickly. Inspired by MAE-VQGAN, we proposed a new simple visual ICL method called SimICL, combining visual ICL pairing images with masked image modeling (MIM) designed for self-supervised learning. We validated our method on bony structures segmentation in a wrist ultrasound (US) dataset with limited annotations, where the clinical objective was to segment bony structures to help with further fracture detection. We used a test set containing 3822 images from 18 patients for bony region segmentation. SimICL achieved an remarkably high Dice coeffient (DC) of 0.96 and Jaccard Index (IoU) of 0.92, surpassing state-of-the-art segmentation and visual ICL models (a maximum DC 0.86 and IoU 0.76), with SimICL DC and IoU increasing up to 0.10 and 0.16. This remarkably high agreement with limited manual annotations indicates SimICL could be used for training AI models even on small US datasets. This could dramatically decrease the human expert time required for image labeling compared to conventional approaches, and enhance the real-world use of AI assistance in US image analysis.
Raw Instinct: Trust Your Classifiers and Skip the Conversion
Mar 21, 2024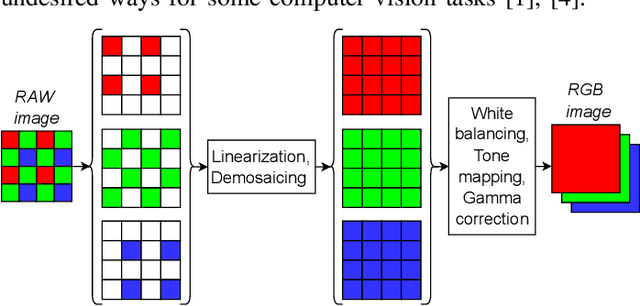
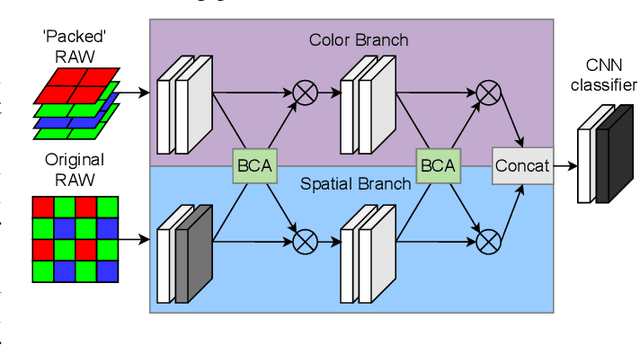

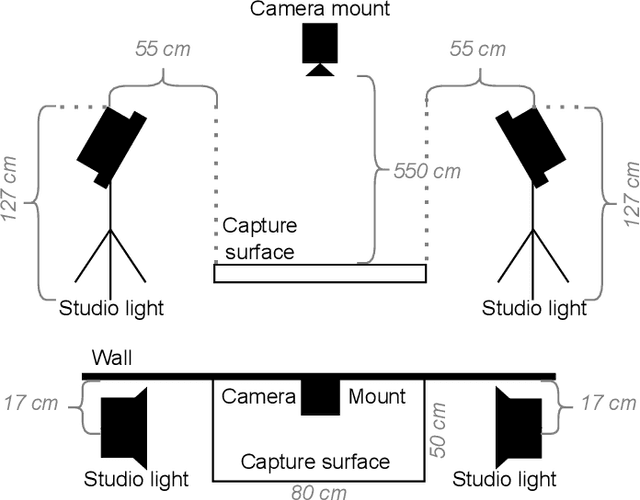
Using RAW-images in computer vision problems is surprisingly underexplored considering that converting from RAW to RGB does not introduce any new capture information. In this paper, we show that a sufficiently advanced classifier can yield equivalent results on RAW input compared to RGB and present a new public dataset consisting of RAW images and the corresponding converted RGB images. Classifying images directly from RAW is attractive, as it allows for skipping the conversion to RGB, lowering computation time significantly. Two CNN classifiers are used to classify the images in both formats, confirming that classification performance can indeed be preserved. We furthermore show that the total computation time from RAW image data to classification results for RAW images can be up to 8.46 times faster than RGB. These results contribute to the evidence found in related works, that using RAW images as direct input to computer vision algorithms looks very promising.
* https://www.kaggle.com/datasets/mathiasviborg/raw-instinct
Towards Controllable Face Generation with Semantic Latent Diffusion Models
Mar 19, 2024
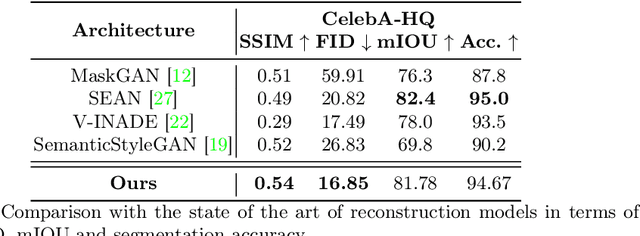
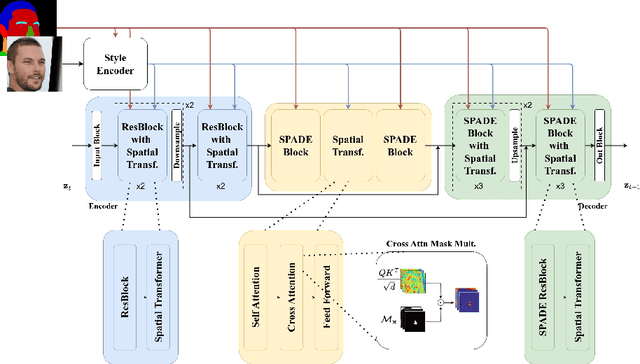

Semantic Image Synthesis (SIS) is among the most popular and effective techniques in the field of face generation and editing, thanks to its good generation quality and the versatility is brings along. Recent works attempted to go beyond the standard GAN-based framework, and started to explore Diffusion Models (DMs) for this task as these stand out with respect to GANs in terms of both quality and diversity. On the other hand, DMs lack in fine-grained controllability and reproducibility. To address that, in this paper we propose a SIS framework based on a novel Latent Diffusion Model architecture for human face generation and editing that is both able to reproduce and manipulate a real reference image and generate diversity-driven results. The proposed system utilizes both SPADE normalization and cross-attention layers to merge shape and style information and, by doing so, allows for a precise control over each of the semantic parts of the human face. This was not possible with previous methods in the state of the art. Finally, we performed an extensive set of experiments to prove that our model surpasses current state of the art, both qualitatively and quantitatively.
Urban Scene Diffusion through Semantic Occupancy Map
Mar 19, 2024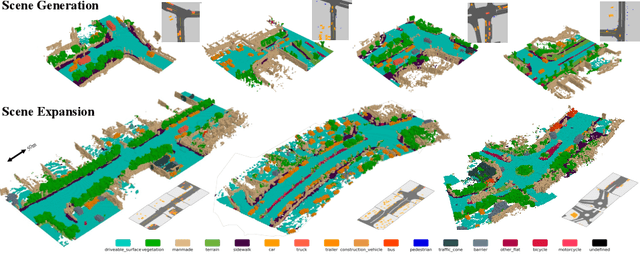

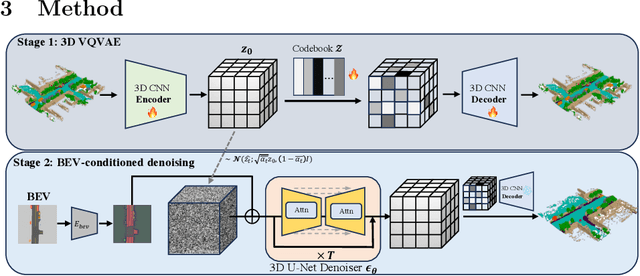
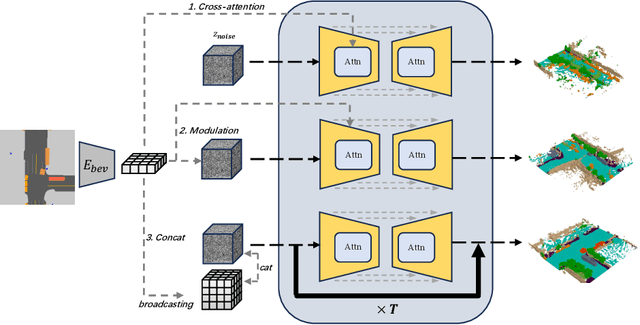
Generating unbounded 3D scenes is crucial for large-scale scene understanding and simulation. Urban scenes, unlike natural landscapes, consist of various complex man-made objects and structures such as roads, traffic signs, vehicles, and buildings. To create a realistic and detailed urban scene, it is crucial to accurately represent the geometry and semantics of the underlying objects, going beyond their visual appearance. In this work, we propose UrbanDiffusion, a 3D diffusion model that is conditioned on a Bird's-Eye View (BEV) map and generates an urban scene with geometry and semantics in the form of semantic occupancy map. Our model introduces a novel paradigm that learns the data distribution of scene-level structures within a latent space and further enables the expansion of the synthesized scene into an arbitrary scale. After training on real-world driving datasets, our model can generate a wide range of diverse urban scenes given the BEV maps from the held-out set and also generalize to the synthesized maps from a driving simulator. We further demonstrate its application to scene image synthesis with a pretrained image generator as a prior.
Zippo: Zipping Color and Transparency Distributions into a Single Diffusion Model
Mar 19, 2024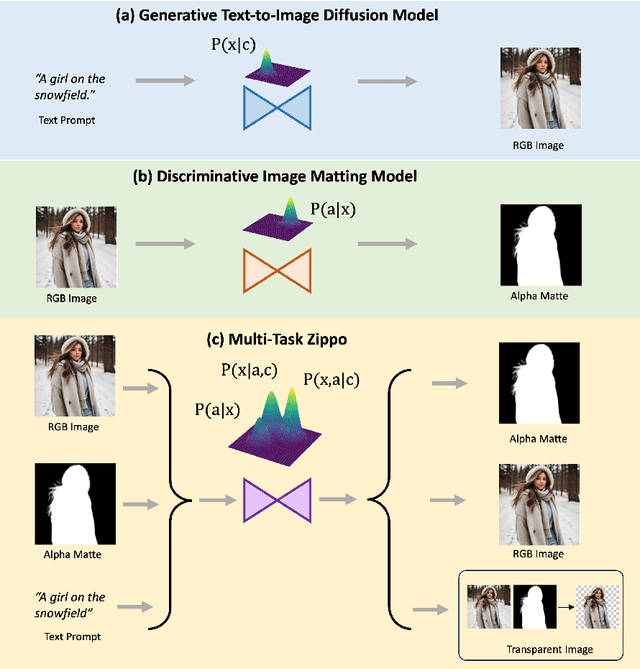

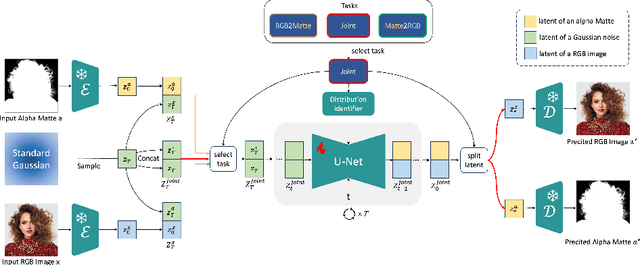
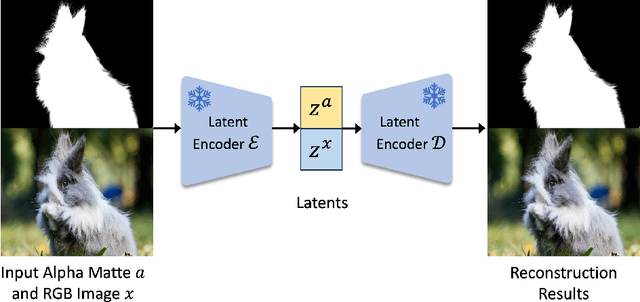
Beyond the superiority of the text-to-image diffusion model in generating high-quality images, recent studies have attempted to uncover its potential for adapting the learned semantic knowledge to visual perception tasks. In this work, instead of translating a generative diffusion model into a visual perception model, we explore to retain the generative ability with the perceptive adaptation. To accomplish this, we present Zippo, a unified framework for zipping the color and transparency distributions into a single diffusion model by expanding the diffusion latent into a joint representation of RGB images and alpha mattes. By alternatively selecting one modality as the condition and then applying the diffusion process to the counterpart modality, Zippo is capable of generating RGB images from alpha mattes and predicting transparency from input images. In addition to single-modality prediction, we propose a modality-aware noise reassignment strategy to further empower Zippo with jointly generating RGB images and its corresponding alpha mattes under the text guidance. Our experiments showcase Zippo's ability of efficient text-conditioned transparent image generation and present plausible results of Matte-to-RGB and RGB-to-Matte translation.
Perceptive self-supervised learning network for noisy image watermark removal
Mar 04, 2024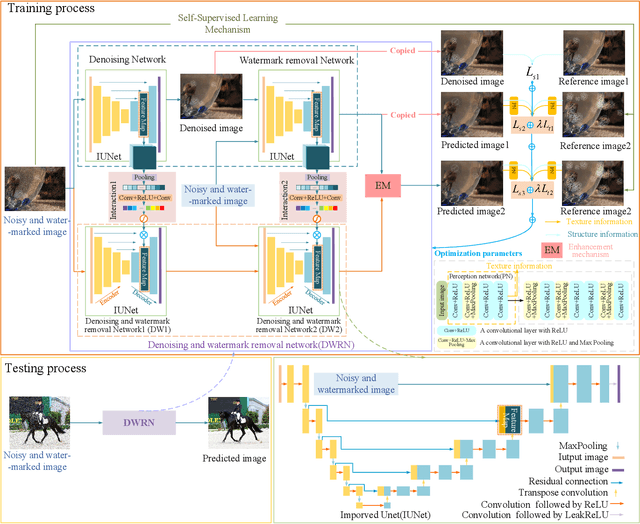



Popular methods usually use a degradation model in a supervised way to learn a watermark removal model. However, it is true that reference images are difficult to obtain in the real world, as well as collected images by cameras suffer from noise. To overcome these drawbacks, we propose a perceptive self-supervised learning network for noisy image watermark removal (PSLNet) in this paper. PSLNet depends on a parallel network to remove noise and watermarks. The upper network uses task decomposition ideas to remove noise and watermarks in sequence. The lower network utilizes the degradation model idea to simultaneously remove noise and watermarks. Specifically, mentioned paired watermark images are obtained in a self supervised way, and paired noisy images (i.e., noisy and reference images) are obtained in a supervised way. To enhance the clarity of obtained images, interacting two sub-networks and fusing obtained clean images are used to improve the effects of image watermark removal in terms of structural information and pixel enhancement. Taking into texture information account, a mixed loss uses obtained images and features to achieve a robust model of noisy image watermark removal. Comprehensive experiments show that our proposed method is very effective in comparison with popular convolutional neural networks (CNNs) for noisy image watermark removal. Codes can be obtained at https://github.com/hellloxiaotian/PSLNet.
Matching Non-Identical Objects
Mar 18, 2024
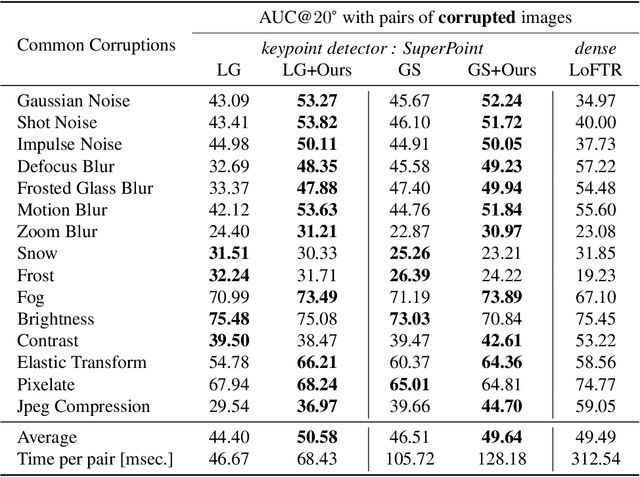

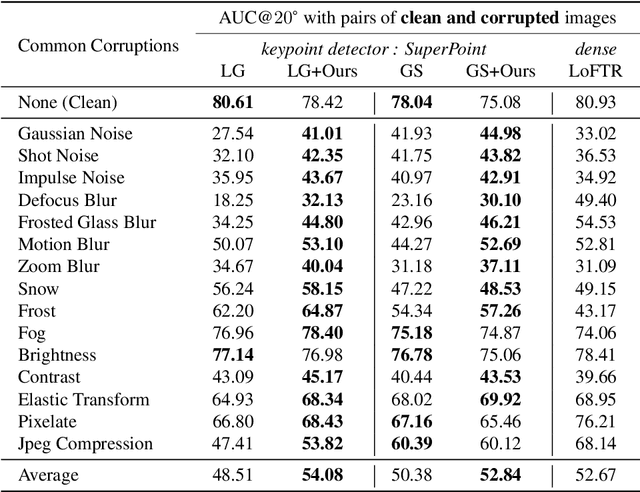
Not identical but similar objects are everywhere in the world. Examples include four-legged animals such as dogs and cats, cars of different models, akin flowers in various colors, and countless others. In this study, we address a novel task of matching such non-identical objects. We propose a simple weighting scheme of descriptors that enhances various sparse image matching methods, which were originally designed for matching identical objects captured from different perspectives, and achieve semantically robust matching. The experiments show successful matching between non-identical objects in various cases including domain shift. Further, we present a first evaluation of the robustness of the image matching methods under common corruptions, which is a sort of domain shift, and the proposed method improves the matching in this case as well.
HOIDiffusion: Generating Realistic 3D Hand-Object Interaction Data
Mar 18, 2024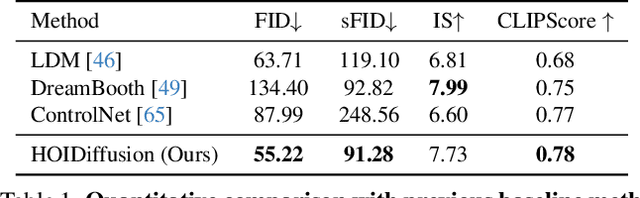
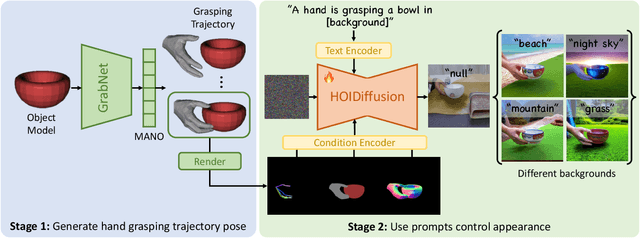
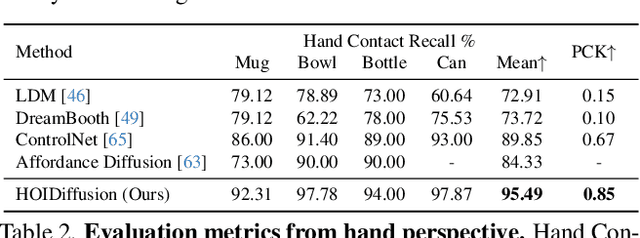
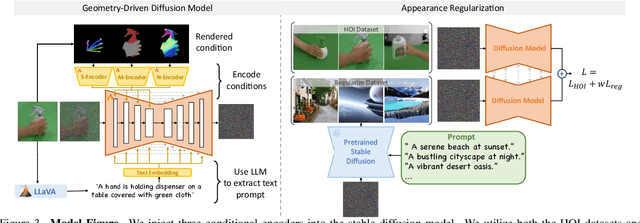
3D hand-object interaction data is scarce due to the hardware constraints in scaling up the data collection process. In this paper, we propose HOIDiffusion for generating realistic and diverse 3D hand-object interaction data. Our model is a conditional diffusion model that takes both the 3D hand-object geometric structure and text description as inputs for image synthesis. This offers a more controllable and realistic synthesis as we can specify the structure and style inputs in a disentangled manner. HOIDiffusion is trained by leveraging a diffusion model pre-trained on large-scale natural images and a few 3D human demonstrations. Beyond controllable image synthesis, we adopt the generated 3D data for learning 6D object pose estimation and show its effectiveness in improving perception systems. Project page: https://mq-zhang1.github.io/HOIDiffusion
Multi-Spectral Remote Sensing Image Retrieval Using Geospatial Foundation Models
Mar 04, 2024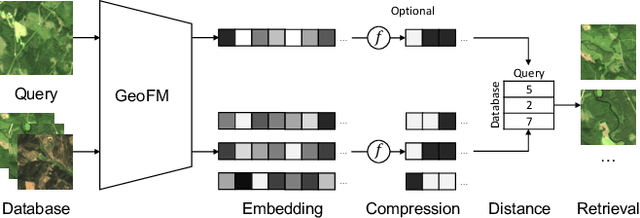
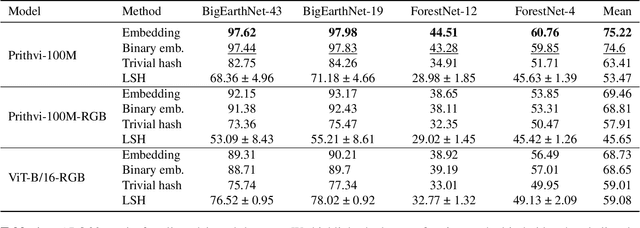
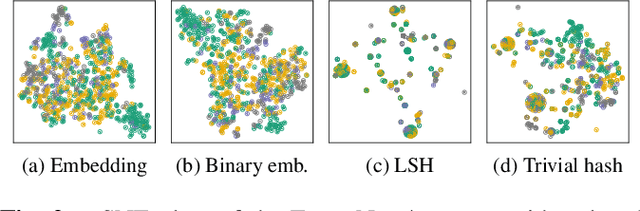

Image retrieval enables an efficient search through vast amounts of satellite imagery and returns similar images to a query. Deep learning models can identify images across various semantic concepts without the need for annotations. This work proposes to use Geospatial Foundation Models, like Prithvi, for remote sensing image retrieval with multiple benefits: i) the models encode multi-spectral satellite data and ii) generalize without further fine-tuning. We introduce two datasets to the retrieval task and observe a strong performance: Prithvi processes six bands and achieves a mean Average Precision of 97.62\% on BigEarthNet-43 and 44.51\% on ForestNet-12, outperforming other RGB-based models. Further, we evaluate three compression methods with binarized embeddings balancing retrieval speed and accuracy. They match the retrieval speed of much shorter hash codes while maintaining the same accuracy as floating-point embeddings but with a 32-fold compression. The code is available at https://github.com/IBM/remote-sensing-image-retrieval.