 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Synthetic Image Refinement via Contrastive Learning and Consistent Semantic-Structural Constraints
Apr 26, 2023
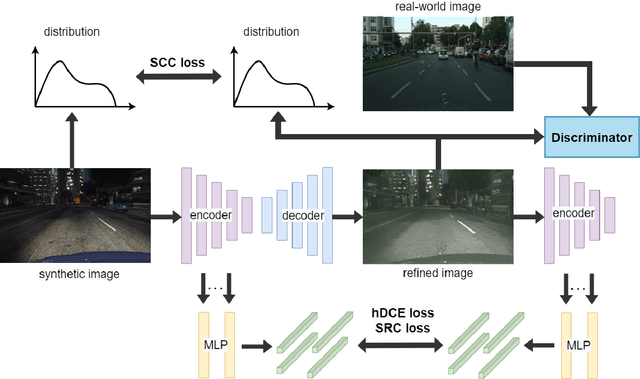
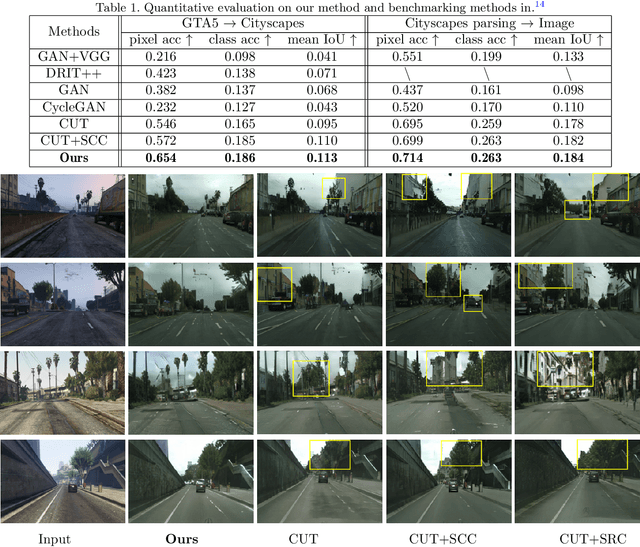
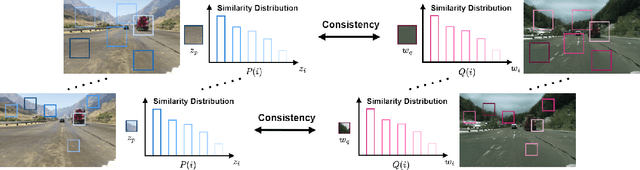

Ensuring the realism of computer-generated synthetic images is crucial to deep neural network (DNN) training. Due to different semantic distributions between synthetic and real-world captured datasets, there exists semantic mismatch between synthetic and refined images, which in turn results in the semantic distortion. Recently, contrastive learning (CL) has been successfully used to pull correlated patches together and push uncorrelated ones apart. In this work, we exploit semantic and structural consistency between synthetic and refined images and adopt CL to reduce the semantic distortion. Besides, we incorporate hard negative mining to improve the performance furthermore. We compare the performance of our method with several other benchmarking methods using qualitative and quantitative measures and show that our method offers the state-of-the-art performance.
Generative AI: Implications and Applications for Education
May 15, 2023
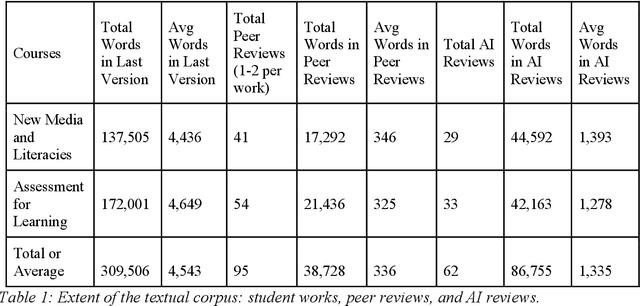
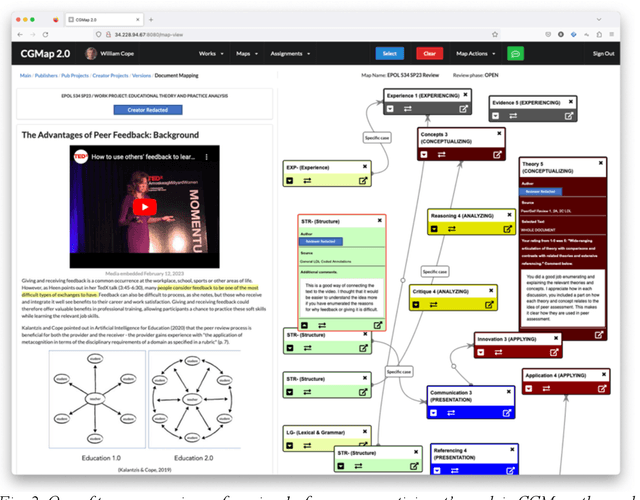
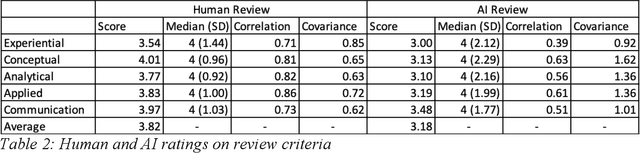
The launch of ChatGPT in November 2022 precipitated a panic among some educators while prompting qualified enthusiasm from others. Under the umbrella term Generative AI, ChatGPT is an example of a range of technologies for the delivery of computer-generated text, image, and other digitized media. This paper examines the implications for education of one generative AI technology, chatbots responding from large language models, or C-LLM. It reports on an application of a C-LLM to AI review and assessment of complex student work. In a concluding discussion, the paper explores the intrinsic limits of generative AI, bound as it is to language corpora and their textual representation through binary notation. Within these limits, we suggest the range of emerging and potential applications of Generative AI in education.
Group Sparse Coding for Image Denoising
Dec 22, 2022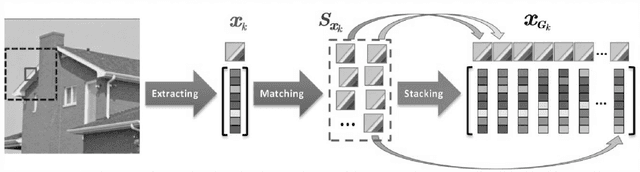
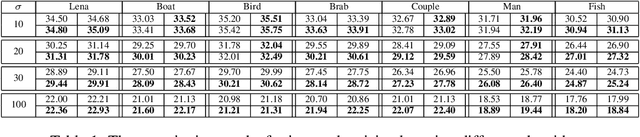


Group sparse representation has shown promising results in image debulrring and image inpainting in GSR [3] , the main reason that lead to the success is by exploiting Sparsity and Nonlocal self-similarity (NSS) between patches on natural images, and solve a regularized optimization problem. However, directly adapting GSR[3] in image denoising yield very unstable and non-satisfactory results, to overcome these issues, this paper proposes a progressive image denoising algorithm that successfully adapt GSR [3] model and experiments shows the superior performance than some of the state-of-the-art methods.
FIT: Far-reaching Interleaved Transformers
May 22, 2023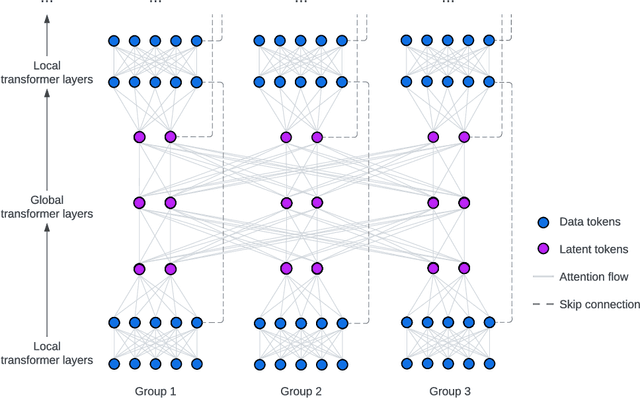
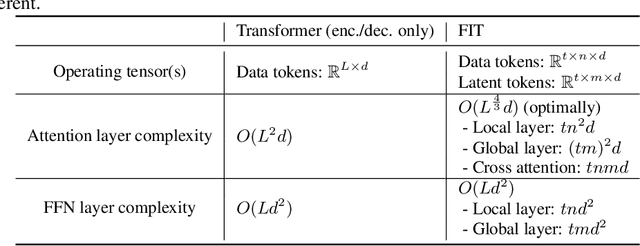
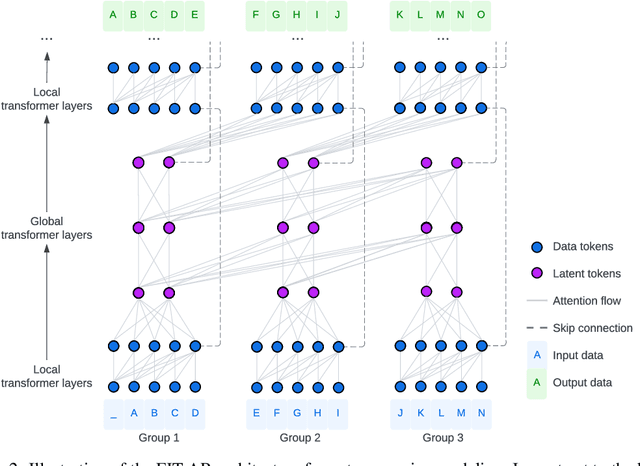
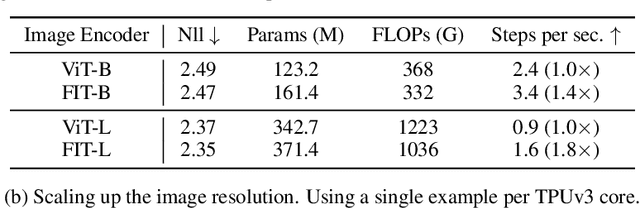
We present FIT: a transformer-based architecture with efficient self-attention and adaptive computation. Unlike original transformers, which operate on a single sequence of data tokens, we divide the data tokens into groups, with each group being a shorter sequence of tokens. We employ two types of transformer layers: local layers operate on data tokens within each group, while global layers operate on a smaller set of introduced latent tokens. These layers, comprising the same set of self-attention and feed-forward layers as standard transformers, are interleaved, and cross-attention is used to facilitate information exchange between data and latent tokens within the same group. The attention complexity is $O(n^2)$ locally within each group of size $n$, but can reach $O(L^{{4}/{3}})$ globally for sequence length of $L$. The efficiency can be further enhanced by relying more on global layers that perform adaptive computation using a smaller set of latent tokens. FIT is a versatile architecture and can function as an encoder, diffusion decoder, or autoregressive decoder. We provide initial evidence demonstrating its effectiveness in high-resolution image understanding and generation tasks. Notably, FIT exhibits potential in performing end-to-end training on gigabit-scale data, such as 6400$\times$6400 images, even without specific optimizations or model parallelism.
Joint Device-Edge Digital Semantic Communication with Adaptive Network Split and Learned Non-Linear Quantization
May 22, 2023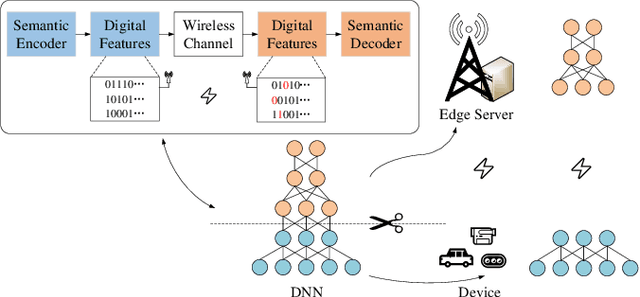
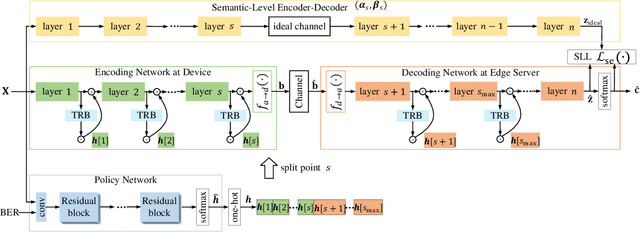
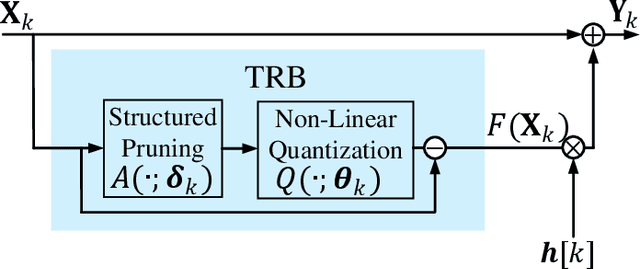
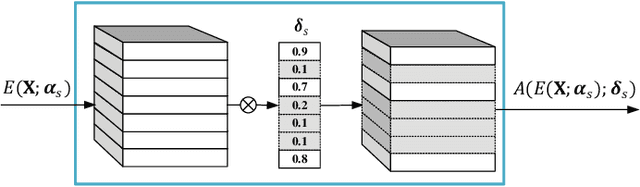
Semantic communication, an intelligent communication paradigm that aims to transmit useful information in the semantic domain, is facilitated by deep learning techniques. Although robust semantic features can be learned and transmitted in an analog fashion, it poses new challenges to hardware, protocol, and encryption. In this paper, we propose a digital semantic communication system, which consists of an encoding network deployed on a resource-limited device and a decoding network deployed at the edge. To acquire better semantic representation for digital transmission, a novel non-linear quantization module is proposed with the trainable quantization levels that efficiently quantifies semantic features. Additionally, structured pruning by a sparse scaling vector is incorporated to reduce the dimension of the transmitted features. We also introduce a semantic learning loss (SLL) function to reduce semantic error. To adapt to various channel conditions and inputs under constraints of communication and computing resources, a policy network is designed to adaptively choose the split point and the dimension of the transmitted semantic features. Experiments using the CIFAR-10 dataset for image classification are employed to evaluate the proposed digital semantic communication network, and ablation studies are conducted to assess the proposed modules including the quantization module, structured pruning and SLL.
Learning Generalized Hybrid Proximity Representation for Image Recognition
Jan 31, 2023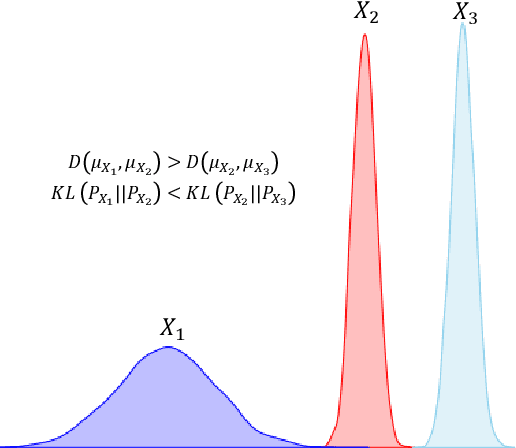
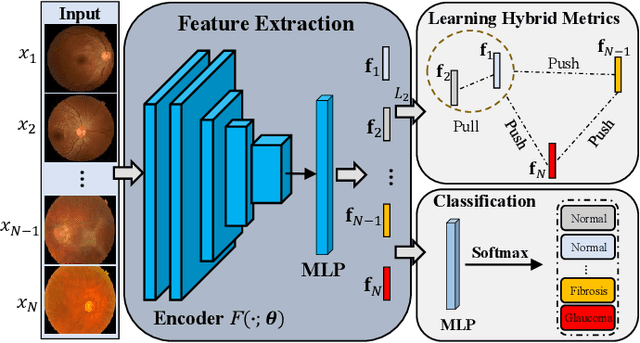
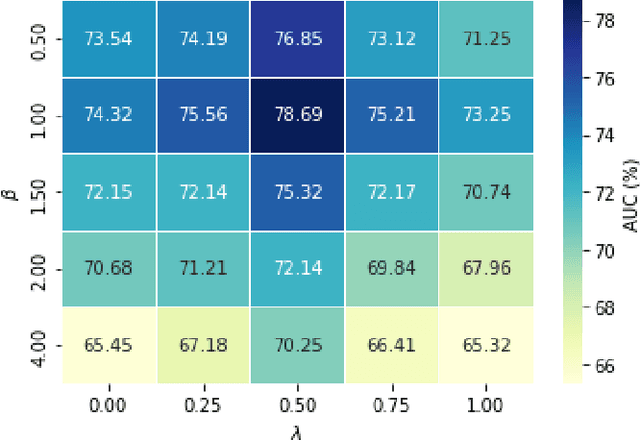
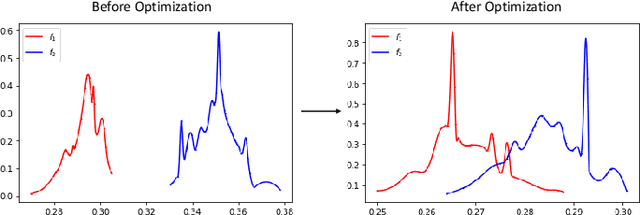
Recently, deep metric learning techniques received attention, as the learned distance representations are useful to capture the similarity relationship among samples and further improve the performance of various of supervised or unsupervised learning tasks. We propose a novel supervised metric learning method that can learn the distance metrics in both geometric and probabilistic space for image recognition. In contrast to the previous metric learning methods which usually focus on learning the distance metrics in Euclidean space, our proposed method is able to learn better distance representation in a hybrid approach. To achieve this, we proposed a Generalized Hybrid Metric Loss (GHM-Loss) to learn the general hybrid proximity features from the image data by controlling the trade-off between geometric proximity and probabilistic proximity. To evaluate the effectiveness of our method, we first provide theoretical derivations and proofs of the proposed loss function, then we perform extensive experiments on two public datasets to show the advantage of our method compared to other state-of-the-art metric learning methods.
Chupa: Carving 3D Clothed Humans from Skinned Shape Priors using 2D Diffusion Probabilistic Models
May 19, 2023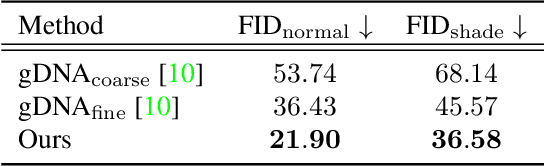
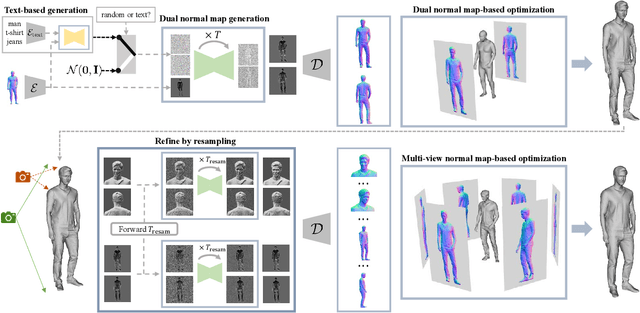


We propose a 3D generation pipeline that uses diffusion models to generate realistic human digital avatars. Due to the wide variety of human identities, poses, and stochastic details, the generation of 3D human meshes has been a challenging problem. To address this, we decompose the problem into 2D normal map generation and normal map-based 3D reconstruction. Specifically, we first simultaneously generate realistic normal maps for the front and backside of a clothed human, dubbed dual normal maps, using a pose-conditional diffusion model. For 3D reconstruction, we ``carve'' the prior SMPL-X mesh to a detailed 3D mesh according to the normal maps through mesh optimization. To further enhance the high-frequency details, we present a diffusion resampling scheme on both body and facial regions, thus encouraging the generation of realistic digital avatars. We also seamlessly incorporate a recent text-to-image diffusion model to support text-based human identity control. Our method, namely, Chupa, is capable of generating realistic 3D clothed humans with better perceptual quality and identity variety.
Generative Steganography Diffusion
May 05, 2023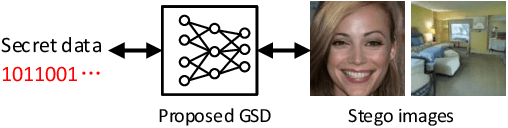
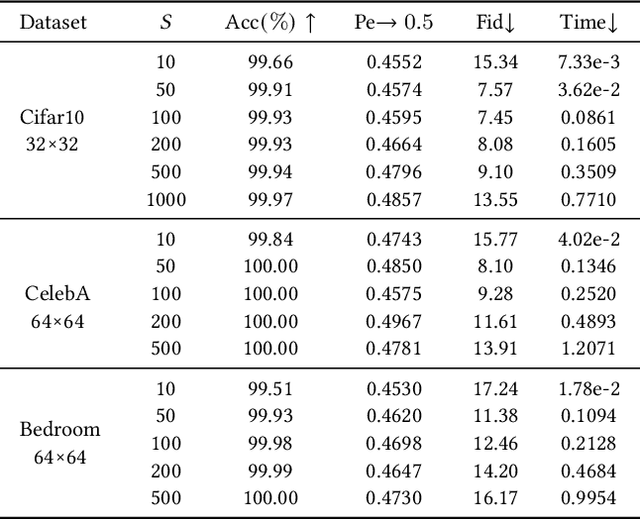
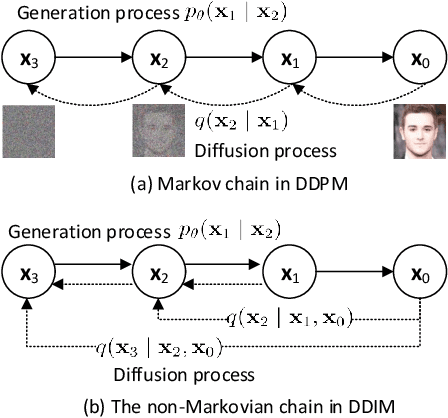
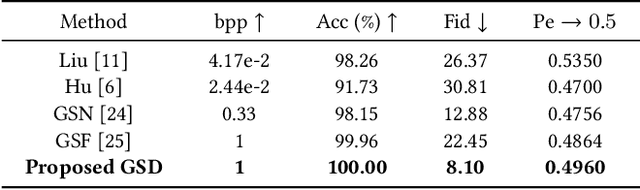
Generative steganography (GS) is an emerging technique that generates stego images directly from secret data. Various GS methods based on GANs or Flow have been developed recently. However, existing GAN-based GS methods cannot completely recover the hidden secret data due to the lack of network invertibility, while Flow-based methods produce poor image quality due to the stringent reversibility restriction in each module. To address this issue, we propose a novel GS scheme called "Generative Steganography Diffusion" (GSD) by devising an invertible diffusion model named "StegoDiffusion". It not only generates realistic stego images but also allows for 100\% recovery of the hidden secret data. The proposed StegoDiffusion model leverages a non-Markov chain with a fast sampling technique to achieve efficient stego image generation. By constructing an ordinary differential equation (ODE) based on the transition probability of the generation process in StegoDiffusion, secret data and stego images can be converted to each other through the approximate solver of ODE -- Euler iteration formula, enabling the use of irreversible but more expressive network structures to achieve model invertibility. Our proposed GSD has the advantages of both reversibility and high performance, significantly outperforming existing GS methods in all metrics.
Change Detection Methods for Remote Sensing in the Last Decade: A Comprehensive Review
May 09, 2023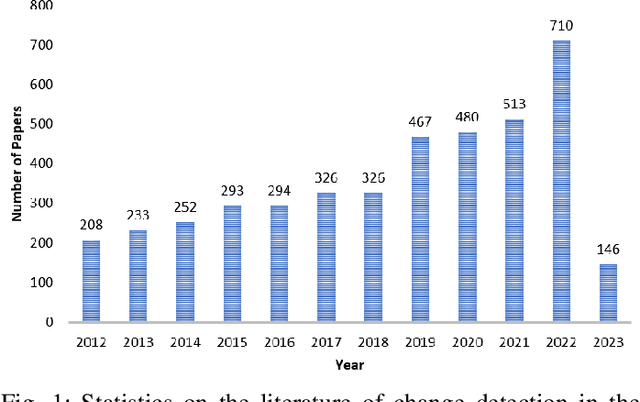
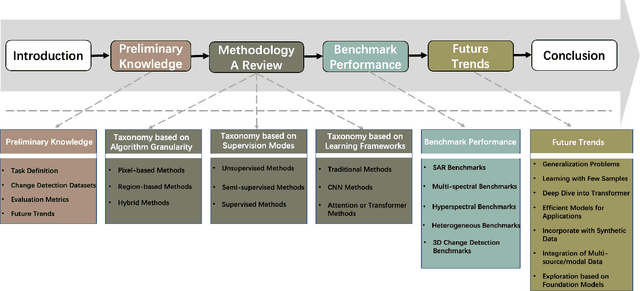
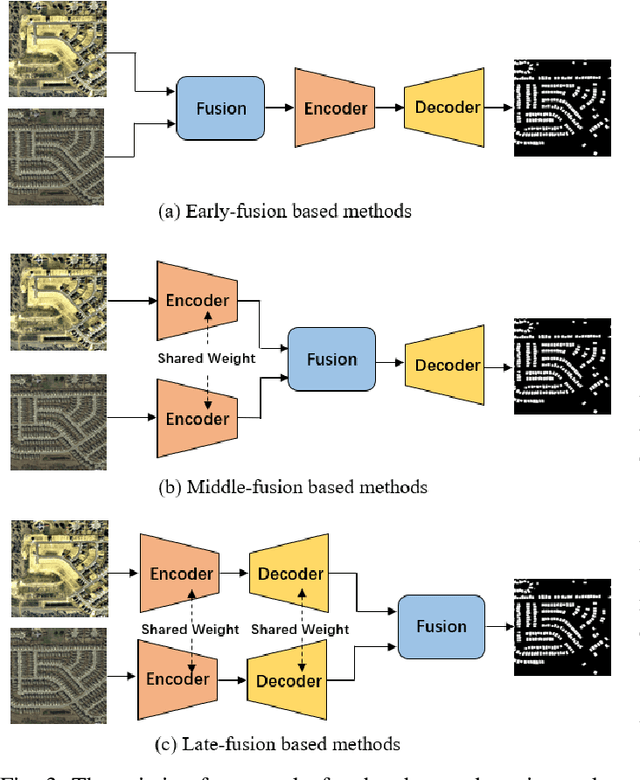
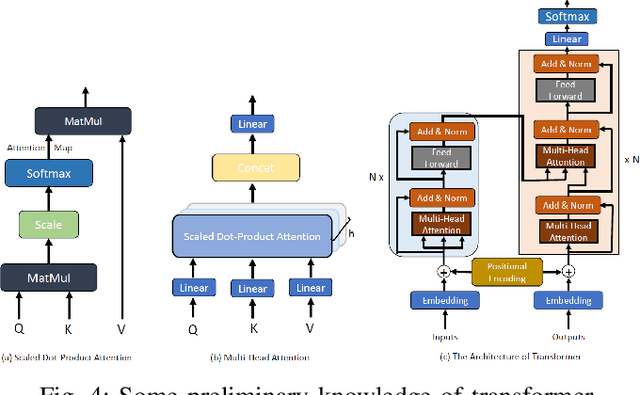
Change detection is an essential and widely utilized task in remote sensing that aims to detect and analyze changes occurring in the same geographical area over time, which has broad applications in urban development, agricultural surveys, and land cover monitoring. Detecting changes in remote sensing images is a complex challenge due to various factors, including variations in image quality, noise, registration errors, illumination changes, complex landscapes, and spatial heterogeneity. In recent years, deep learning has emerged as a powerful tool for feature extraction and addressing these challenges. Its versatility has resulted in its widespread adoption for numerous image-processing tasks. This paper presents a comprehensive survey of significant advancements in change detection for remote sensing images over the past decade. We first introduce some preliminary knowledge for the change detection task, such as problem definition, datasets, evaluation metrics, and transformer basics, as well as provide a detailed taxonomy of existing algorithms from three different perspectives: algorithm granularity, supervision modes, and learning frameworks in the methodology section. This survey enables readers to gain systematic knowledge of change detection tasks from various angles. We then summarize the state-of-the-art performance on several dominant change detection datasets, providing insights into the strengths and limitations of existing algorithms. Based on our survey, some future research directions for change detection in remote sensing are well identified. This survey paper will shed some light on the community and inspire further research efforts in the change detection task.
Boosting Visual-Language Models by Exploiting Hard Samples
May 09, 2023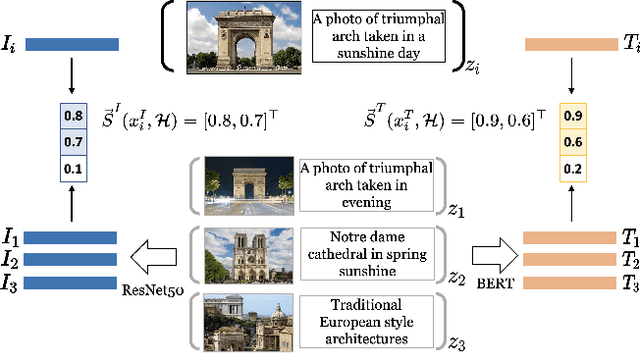
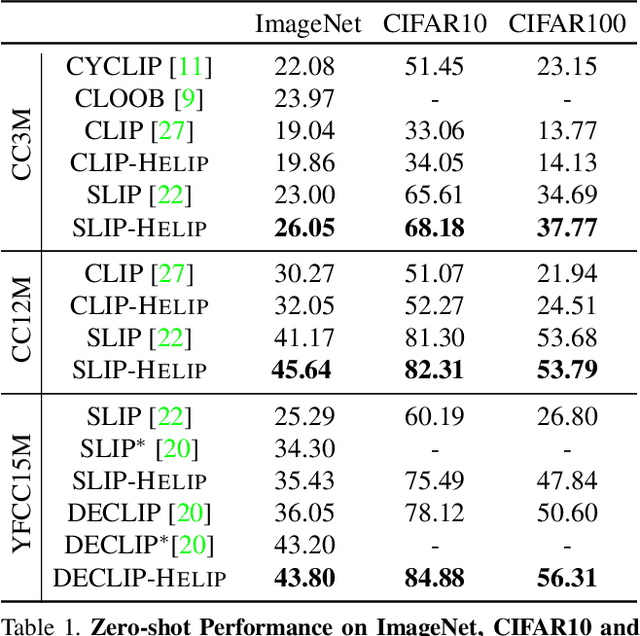
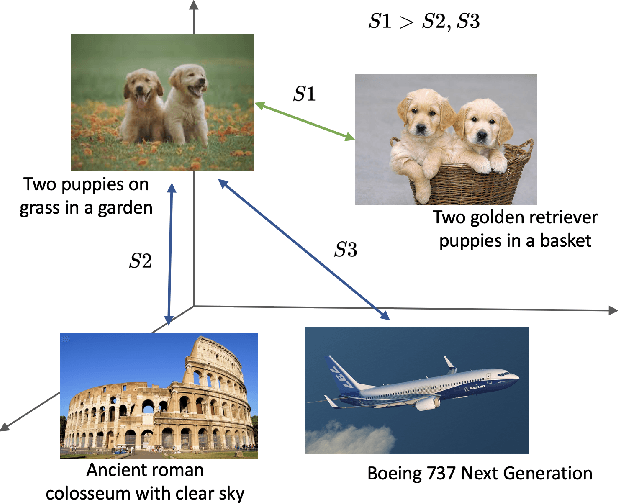
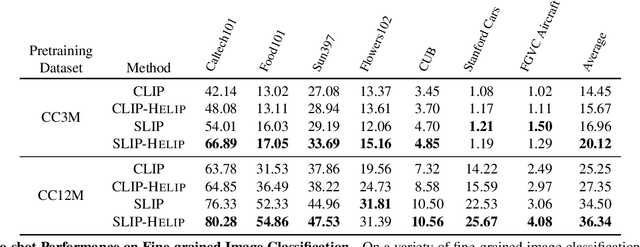
Large vision and language models, such as Contrastive Language-Image Pre-training (CLIP), are rapidly becoming the industry norm for matching images and texts. In order to improve its zero-shot recognition performance, current research either adds additional web-crawled image-text pairs or designs new training losses. However, the additional costs associated with training from scratch and data collection substantially hinder their deployment. In this paper, we present HELIP, a low-cost strategy for boosting the performance of well-trained CLIP models by finetuning them with hard samples over original training data. Mixing hard examples into each batch, the well-trained CLIP model is then fine-tuned using the conventional contrastive alignment objective and a margin loss to distinguish between normal and hard negative data. HELIP is deployed in a plug-and-play fashion to existing models. On a comprehensive zero-shot and retrieval benchmark, without training the model from scratch or utilizing additional data, HELIP consistently boosts existing models to achieve leading performance. In particular, HELIP boosts ImageNet zero-shot accuracy of SLIP by 3.05 and 4.47 when pretrained on CC3M and CC12M respectively. In addition, a systematic evaluation of zero-shot and linear probing experiments across fine-grained classification datasets demonstrates a consistent performance improvement and validates the efficacy of HELIP . When pretraining on CC3M, HELIP boosts zero-shot performance of CLIP and SLIP by 8.4\% and 18.6\% on average respectively, and linear probe performance by 9.5\% and 3.0\% on average respectively.