 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Controllable Mind Visual Diffusion Model
May 18, 2023


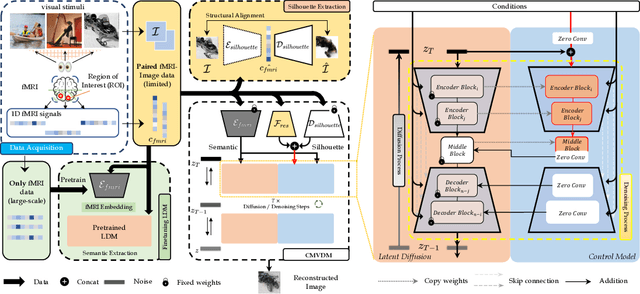

Brain signal visualization has emerged as an active research area, serving as a critical interface between the human visual system and computer vision models. Although diffusion models have shown promise in analyzing functional magnetic resonance imaging (fMRI) data, including reconstructing high-quality images consistent with original visual stimuli, their accuracy in extracting semantic and silhouette information from brain signals remains limited. In this regard, we propose a novel approach, referred to as Controllable Mind Visual Diffusion Model (CMVDM). CMVDM extracts semantic and silhouette information from fMRI data using attribute alignment and assistant networks. Additionally, a residual block is incorporated to capture information beyond semantic and silhouette features. We then leverage a control model to fully exploit the extracted information for image synthesis, resulting in generated images that closely resemble the visual stimuli in terms of semantics and silhouette. Through extensive experimentation, we demonstrate that CMVDM outperforms existing state-of-the-art methods both qualitatively and quantitatively.
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture
May 18, 2023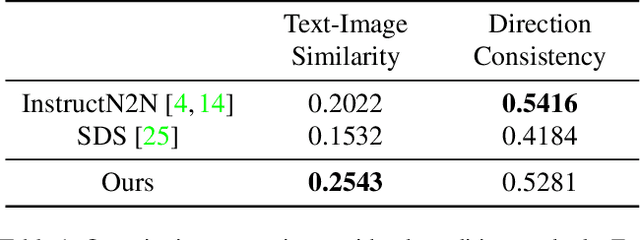
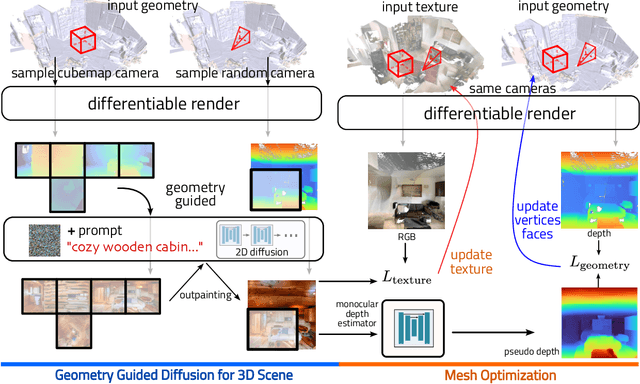
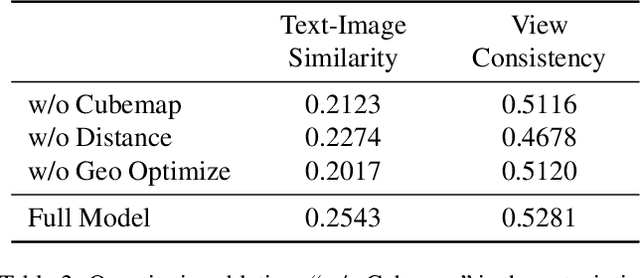
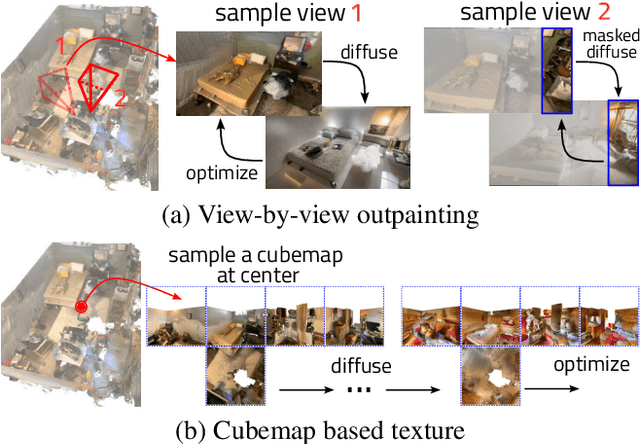
The techniques for 3D indoor scene capturing are widely used, but the meshes produced leave much to be desired. In this paper, we propose "RoomDreamer", which leverages powerful natural language to synthesize a new room with a different style. Unlike existing image synthesis methods, our work addresses the challenge of synthesizing both geometry and texture aligned to the input scene structure and prompt simultaneously. The key insight is that a scene should be treated as a whole, taking into account both scene texture and geometry. The proposed framework consists of two significant components: Geometry Guided Diffusion and Mesh Optimization. Geometry Guided Diffusion for 3D Scene guarantees the consistency of the scene style by applying the 2D prior to the entire scene simultaneously. Mesh Optimization improves the geometry and texture jointly and eliminates the artifacts in the scanned scene. To validate the proposed method, real indoor scenes scanned with smartphones are used for extensive experiments, through which the effectiveness of our method is demonstrated.
Noise-aware Learning from Web-crawled Image-Text Data for Image Captioning
Dec 27, 2022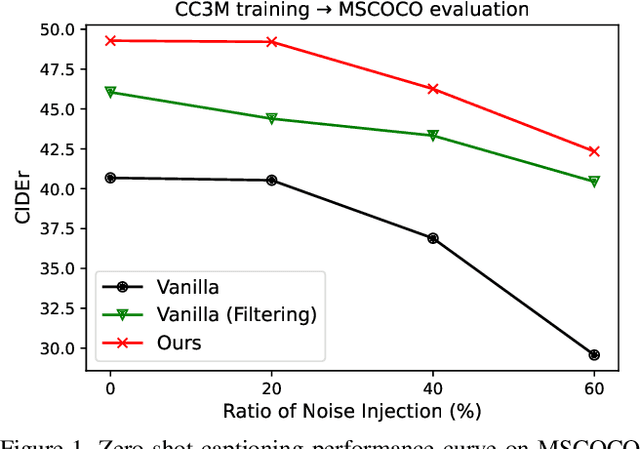
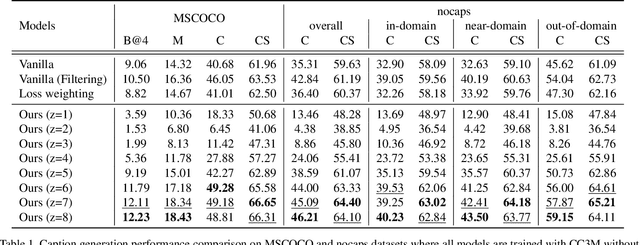

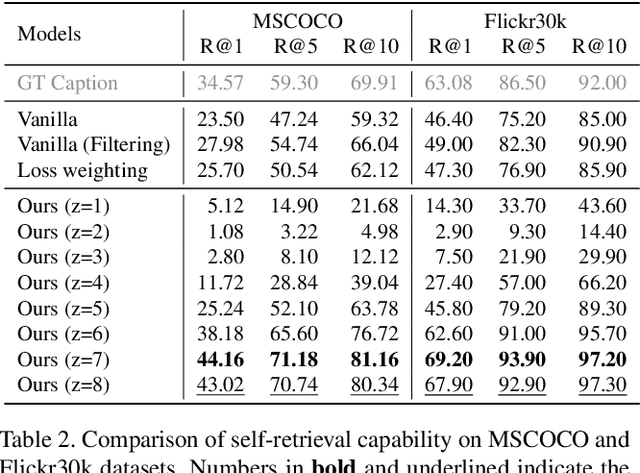
Image captioning is one of the straightforward tasks that can take advantage of large-scale web-crawled data which provides rich knowledge about the visual world for a captioning model. However, since web-crawled data contains image-text pairs that are aligned at different levels, the inherent noises (e.g., misaligned pairs) make it difficult to learn a precise captioning model. While the filtering strategy can effectively remove noisy data, however, it leads to a decrease in learnable knowledge and sometimes brings about a new problem of data deficiency. To take the best of both worlds, we propose a noise-aware learning framework, which learns rich knowledge from the whole web-crawled data while being less affected by the noises. This is achieved by the proposed quality controllable model, which is learned using alignment levels of the image-text pairs as an additional control signal during training. The alignment-conditioned training allows the model to generate high-quality captions of well-aligned by simply setting the control signal to desired alignment level at inference time. Through in-depth analysis, we show that our controllable captioning model is effective in handling noise. In addition, with two tasks of zero-shot captioning and text-to-image retrieval using generated captions (i.e., self-retrieval), we also demonstrate our model can produce high-quality captions in terms of descriptiveness and distinctiveness. Code is available at \url{https://github.com/kakaobrain/noc}.
ganX -- generate artificially new XRF a python library to generate MA-XRF raw data out of RGB images
Apr 27, 2023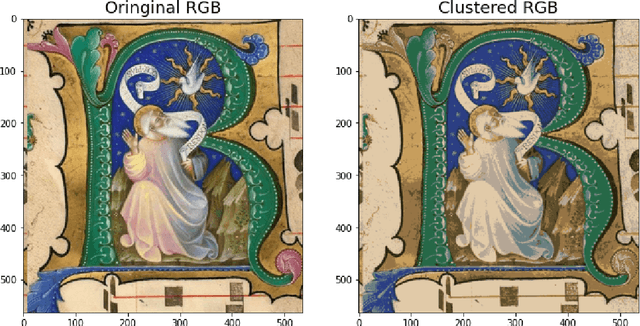
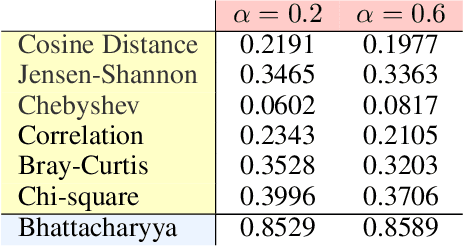
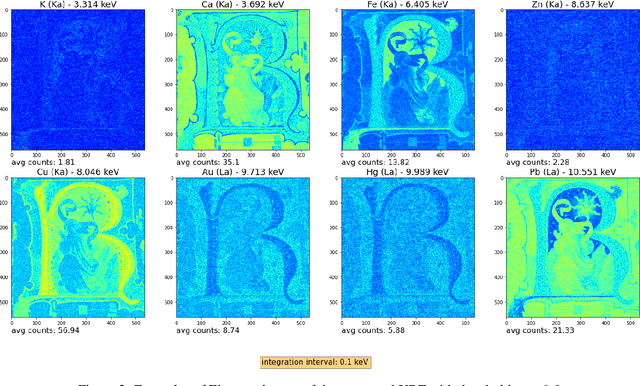

In this paper we present the first version of ganX -- generate artificially new XRF, a Python library to generate X-ray fluorescence Macro maps (MA-XRF) from a coloured RGB image. To do that, a Monte Carlo method is used, where each MA-XRF pixel signal is sampled out of an XRF signal probability function. Such probability function is computed using a database of couples (pigment characteristic XRF signal, RGB), by a weighted sum of such pigment XRF signal by proximity of the image RGB to the pigment characteristic RGB. The library is released to PyPi and the code is available open source on GitHub.
Critical heat flux diagnosis using conditional generative adversarial networks
May 04, 2023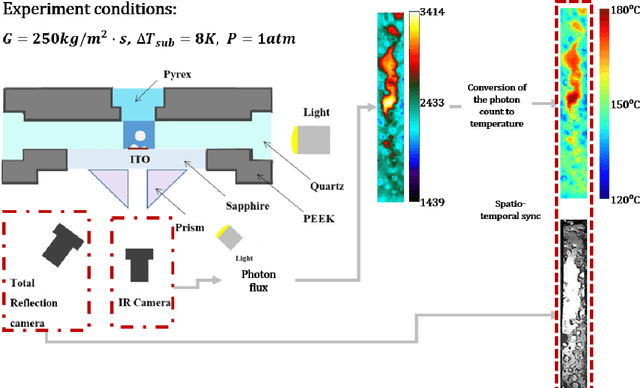
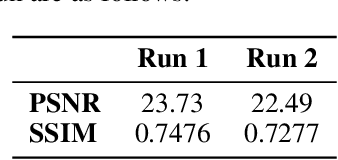

The critical heat flux (CHF) is an essential safety boundary in boiling heat transfer processes employed in high heat flux thermal-hydraulic systems. Identifying CHF is vital for preventing equipment damage and ensuring overall system safety, yet it is challenging due to the complexity of the phenomena. For an in-depth understanding of the complicated phenomena, various methodologies have been devised, but the acquisition of high-resolution data is limited by the substantial resource consumption required. This study presents a data-driven, image-to-image translation method for reconstructing thermal data of a boiling system at CHF using conditional generative adversarial networks (cGANs). The supervised learning process relies on paired images, which include total reflection visualizations and infrared thermometry measurements obtained from flow boiling experiments. Our proposed approach has the potential to not only provide evidence connecting phase interface dynamics with thermal distribution but also to simplify the laborious and time-consuming experimental setup and data-reduction procedures associated with infrared thermal imaging, thereby providing an effective solution for CHF diagnosis.
DDMM-Synth: A Denoising Diffusion Model for Cross-modal Medical Image Synthesis with Sparse-view Measurement Embedding
Mar 28, 2023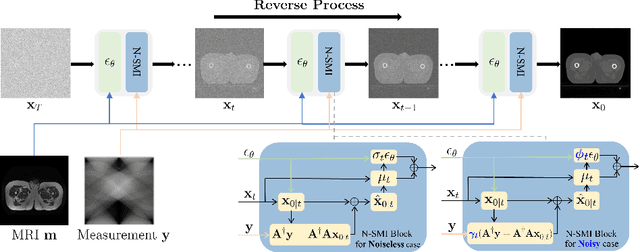
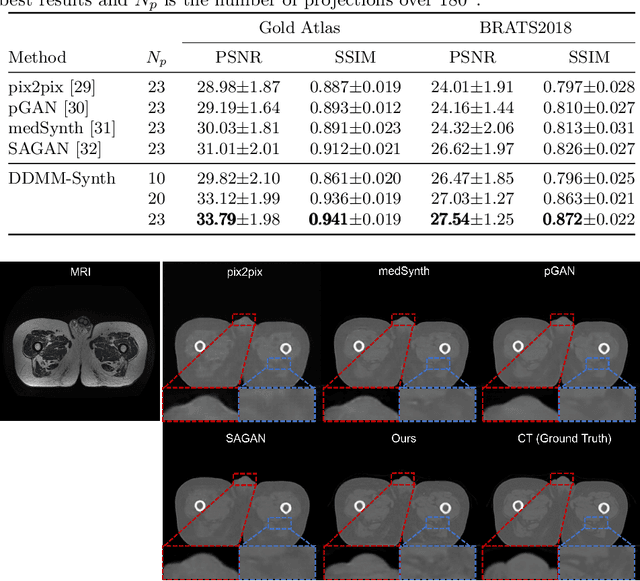
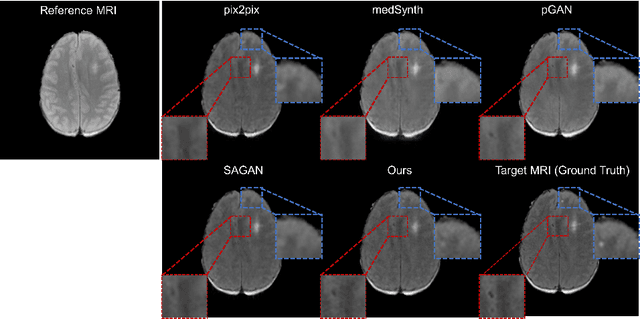
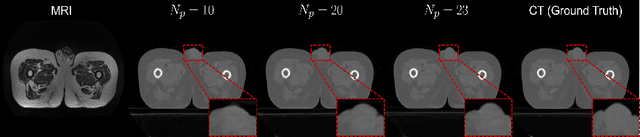
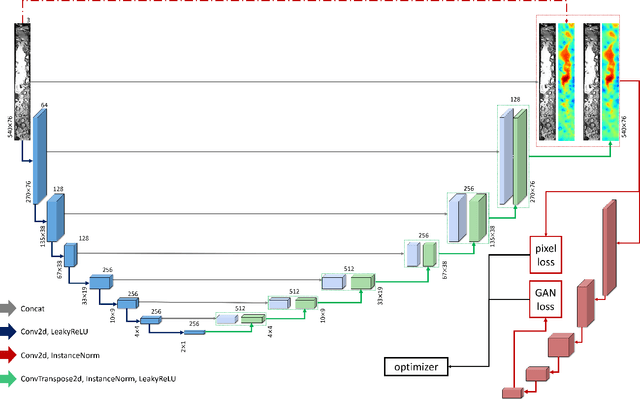
Reducing the radiation dose in computed tomography (CT) is important to mitigate radiation-induced risks. One option is to employ a well-trained model to compensate for incomplete information and map sparse-view measurements to the CT reconstruction. However, reconstruction from sparsely sampled measurements is insufficient to uniquely characterize an object in CT, and a learned prior model may be inadequate for unencountered cases. Medical modal translation from magnetic resonance imaging (MRI) to CT is an alternative but may introduce incorrect information into the synthesized CT images in addition to the fact that there exists no explicit transformation describing their relationship. To address these issues, we propose a novel framework called the denoising diffusion model for medical image synthesis (DDMM-Synth) to close the performance gaps described above. This framework combines an MRI-guided diffusion model with a new CT measurement embedding reverse sampling scheme. Specifically, the null-space content of the one-step denoising result is refined by the MRI-guided data distribution prior, and its range-space component derived from an explicit operator matrix and the sparse-view CT measurements is directly integrated into the inference stage. DDMM-Synth can adjust the projection number of CT a posteriori for a particular clinical application and its modified version can even improve the results significantly for noisy cases. Our results show that DDMM-Synth outperforms other state-of-the-art supervised-learning-based baselines under fair experimental conditions.
Remote Sensing Scene Classification with Masked Image Modeling (MIM)
Feb 28, 2023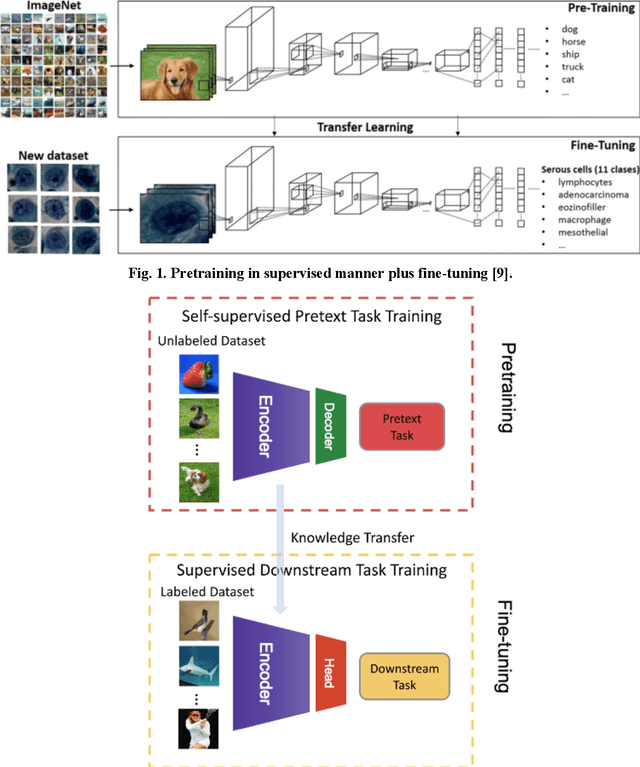


Remote sensing scene classification has been extensively studied for its critical roles in geological survey, oil exploration, traffic management, earthquake prediction, wildfire monitoring, and intelligence monitoring. In the past, the Machine Learning (ML) methods for performing the task mainly used the backbones pretrained in the manner of supervised learning (SL). As Masked Image Modeling (MIM), a self-supervised learning (SSL) technique, has been shown as a better way for learning visual feature representation, it presents a new opportunity for improving ML performance on the scene classification task. This research aims to explore the potential of MIM pretrained backbones on four well-known classification datasets: Merced, AID, NWPU-RESISC45, and Optimal-31. Compared to the published benchmarks, we show that the MIM pretrained Vision Transformer (ViTs) backbones outperform other alternatives (up to 18% on top 1 accuracy) and that the MIM technique can learn better feature representation than the supervised learning counterparts (up to 5% on top 1 accuracy). Moreover, we show that the general-purpose MIM-pretrained ViTs can achieve competitive performance as the specially designed yet complicated Transformer for Remote Sensing (TRS) framework. Our experiment results also provide a performance baseline for future studies.
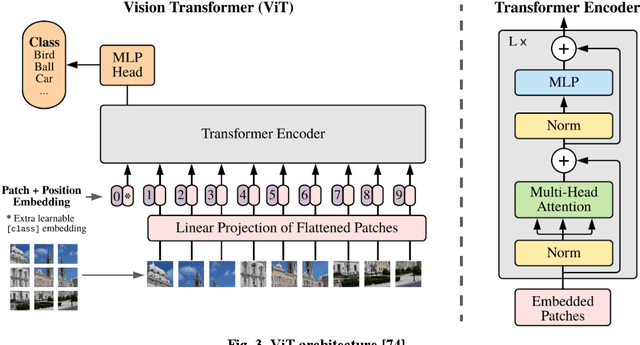
Transfer Learning for Fine-grained Classification Using Semi-supervised Learning and Visual Transformers
May 17, 2023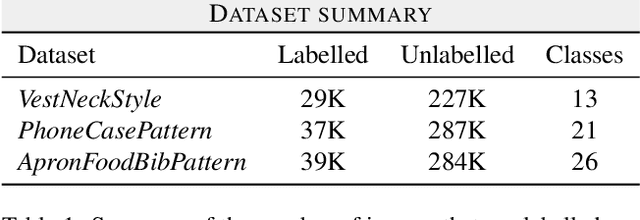

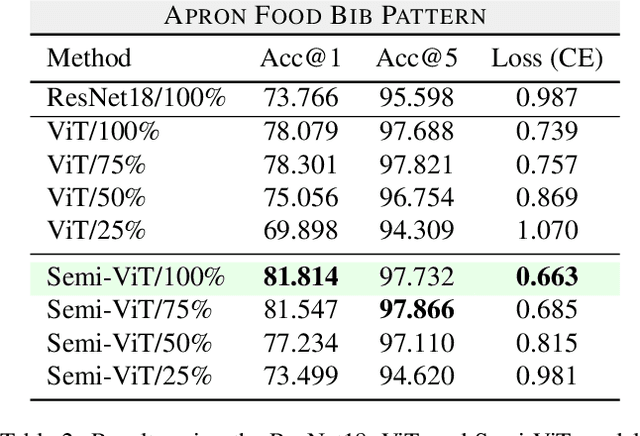
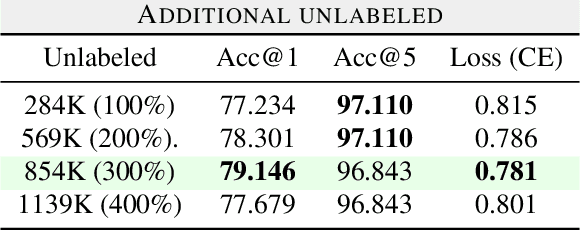
Fine-grained classification is a challenging task that involves identifying subtle differences between objects within the same category. This task is particularly challenging in scenarios where data is scarce. Visual transformers (ViT) have recently emerged as a powerful tool for image classification, due to their ability to learn highly expressive representations of visual data using self-attention mechanisms. In this work, we explore Semi-ViT, a ViT model fine tuned using semi-supervised learning techniques, suitable for situations where we have lack of annotated data. This is particularly common in e-commerce, where images are readily available but labels are noisy, nonexistent, or expensive to obtain. Our results demonstrate that Semi-ViT outperforms traditional convolutional neural networks (CNN) and ViTs, even when fine-tuned with limited annotated data. These findings indicate that Semi-ViTs hold significant promise for applications that require precise and fine-grained classification of visual data.
Zero-shot Visual Relation Detection via Composite Visual Cues from Large Language Models
May 21, 2023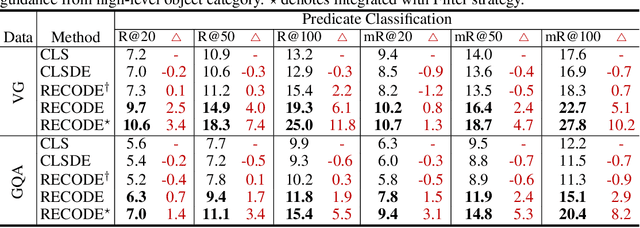
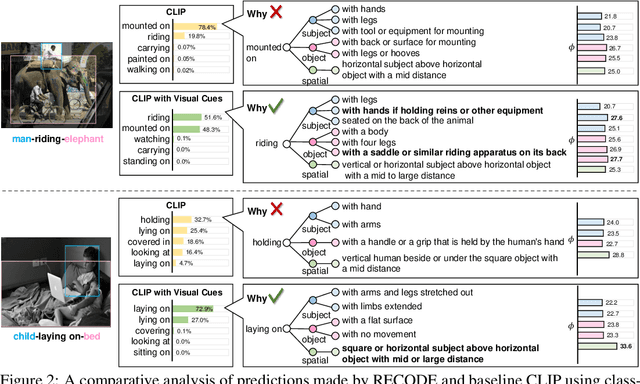
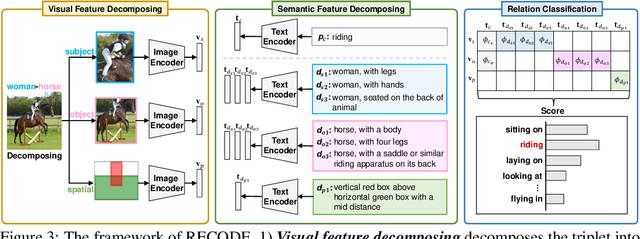
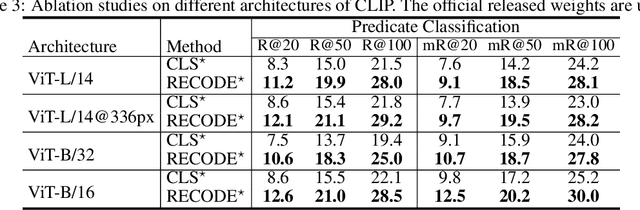
Pretrained vision-language models, such as CLIP, have demonstrated strong generalization capabilities, making them promising tools in the realm of zero-shot visual recognition. Visual relation detection (VRD) is a typical task that identifies relationship (or interaction) types between object pairs within an image. However, naively utilizing CLIP with prevalent class-based prompts for zero-shot VRD has several weaknesses, e.g., it struggles to distinguish between different fine-grained relation types and it neglects essential spatial information of two objects. To this end, we propose a novel method for zero-shot VRD: RECODE, which solves RElation detection via COmposite DEscription prompts. Specifically, RECODE first decomposes each predicate category into subject, object, and spatial components. Then, it leverages large language models (LLMs) to generate description-based prompts (or visual cues) for each component. Different visual cues enhance the discriminability of similar relation categories from different perspectives, which significantly boosts performance in VRD. To dynamically fuse different cues, we further introduce a chain-of-thought method that prompts LLMs to generate reasonable weights for different visual cues. Extensive experiments on four VRD benchmarks have demonstrated the effectiveness and interpretability of RECODE.
Group Sparse Coding for Image Denoising
Dec 22, 2022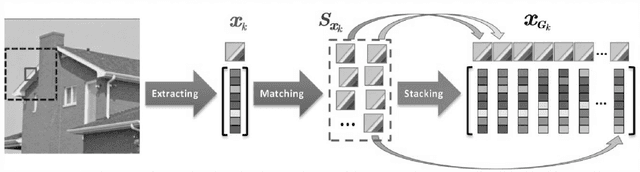
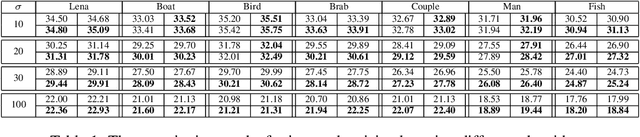


Group sparse representation has shown promising results in image debulrring and image inpainting in GSR [3] , the main reason that lead to the success is by exploiting Sparsity and Nonlocal self-similarity (NSS) between patches on natural images, and solve a regularized optimization problem. However, directly adapting GSR[3] in image denoising yield very unstable and non-satisfactory results, to overcome these issues, this paper proposes a progressive image denoising algorithm that successfully adapt GSR [3] model and experiments shows the superior performance than some of the state-of-the-art methods.