 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LOWA: Localize Objects in the Wild with Attributes
May 31, 2023


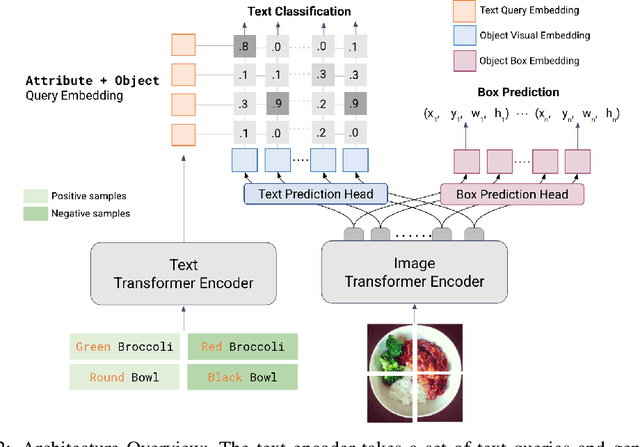
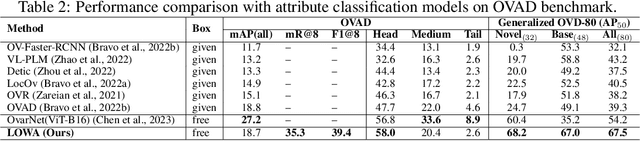
We present LOWA, a novel method for localizing objects with attributes effectively in the wild. It aims to address the insufficiency of current open-vocabulary object detectors, which are limited by the lack of instance-level attribute classification and rare class names. To train LOWA, we propose a hybrid vision-language training strategy to learn object detection and recognition with class names as well as attribute information. With LOWA, users can not only detect objects with class names, but also able to localize objects by attributes. LOWA is built on top of a two-tower vision-language architecture and consists of a standard vision transformer as the image encoder and a similar transformer as the text encoder. To learn the alignment between visual and text inputs at the instance level, we train LOWA with three training steps: object-level training, attribute-aware learning, and free-text joint training of objects and attributes. This hybrid training strategy first ensures correct object detection, then incorporates instance-level attribute information, and finally balances the object class and attribute sensitivity. We evaluate our model performance of attribute classification and attribute localization on the Open-Vocabulary Attribute Detection (OVAD) benchmark and the Visual Attributes in the Wild (VAW) dataset, and experiments indicate strong zero-shot performance. Ablation studies additionally demonstrate the effectiveness of each training step of our approach.
A Universal Latent Fingerprint Enhancer Using Transformers
May 31, 2023
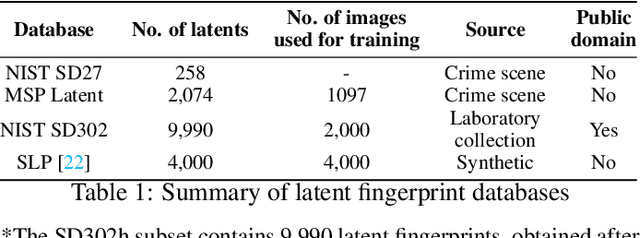

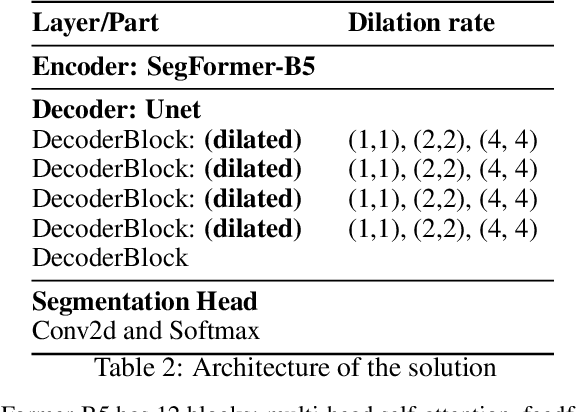
Forensic science heavily relies on analyzing latent fingerprints, which are crucial for criminal investigations. However, various challenges, such as background noise, overlapping prints, and contamination, make the identification process difficult. Moreover, limited access to real crime scene and laboratory-generated databases hinders the development of efficient recognition algorithms. This study aims to develop a fast method, which we call ULPrint, to enhance various latent fingerprint types, including those obtained from real crime scenes and laboratory-created samples, to boost fingerprint recognition system performance. In closed-set identification accuracy experiments, the enhanced image was able to improve the performance of the MSU-AFIS from 61.56\% to 75.19\% in the NIST SD27 database, from 67.63\% to 77.02\% in the MSP Latent database, and from 46.90\% to 52.12\% in the NIST SD302 database. Our contributions include (1) the development of a two-step latent fingerprint enhancement method that combines Ridge Segmentation with UNet and Mix Visual Transformer (MiT) SegFormer-B5 encoder architecture, (2) the implementation of multiple dilated convolutions in the UNet architecture to capture intricate, non-local patterns better and enhance ridge segmentation, and (3) the guided blending of the predicted ridge mask with the latent fingerprint. This novel approach, ULPrint, streamlines the enhancement process, addressing challenges across diverse latent fingerprint types to improve forensic investigations and criminal justice outcomes.
Towards a Robust Framework for NeRF Evaluation
May 31, 2023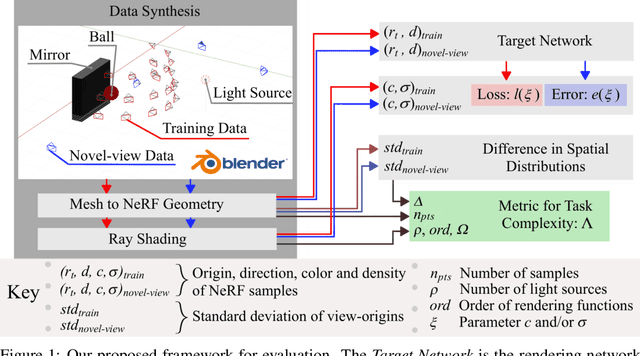

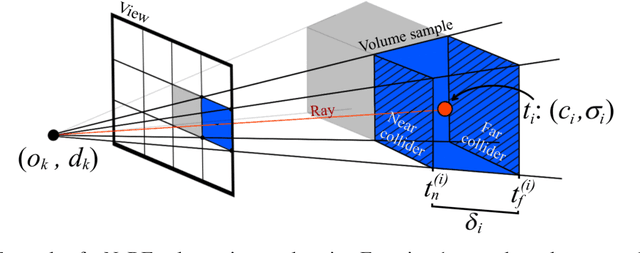
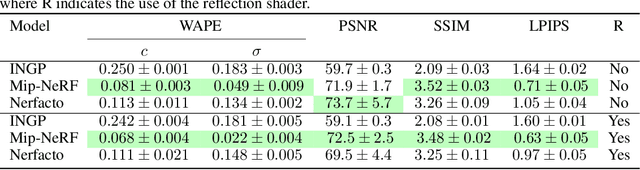
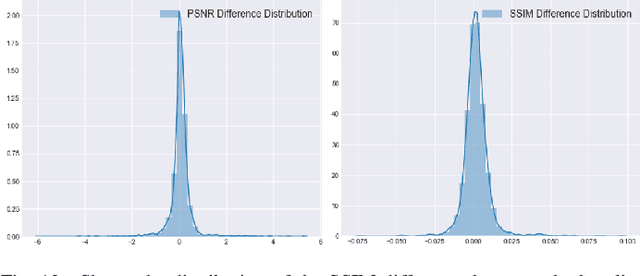
Neural Radiance Field (NeRF) research has attracted significant attention recently, with 3D modelling, virtual/augmented reality, and visual effects driving its application. While current NeRF implementations can produce high quality visual results, there is a conspicuous lack of reliable methods for evaluating them. Conventional image quality assessment methods and analytical metrics (e.g. PSNR, SSIM, LPIPS etc.) only provide approximate indicators of performance since they generalise the ability of the entire NeRF pipeline. Hence, in this paper, we propose a new test framework which isolates the neural rendering network from the NeRF pipeline and then performs a parametric evaluation by training and evaluating the NeRF on an explicit radiance field representation. We also introduce a configurable approach for generating representations specifically for evaluation purposes. This employs ray-casting to transform mesh models into explicit NeRF samples, as well as to "shade" these representations. Combining these two approaches, we demonstrate how different "tasks" (scenes with different visual effects or learning strategies) and types of networks (NeRFs and depth-wise implicit neural representations (INRs)) can be evaluated within this framework. Additionally, we propose a novel metric to measure task complexity of the framework which accounts for the visual parameters and the distribution of the spatial data. Our approach offers the potential to create a comparative objective evaluation framework for NeRF methods.
FishRecGAN: An End to End GAN Based Network for Fisheye Rectification and Calibration
May 09, 2023
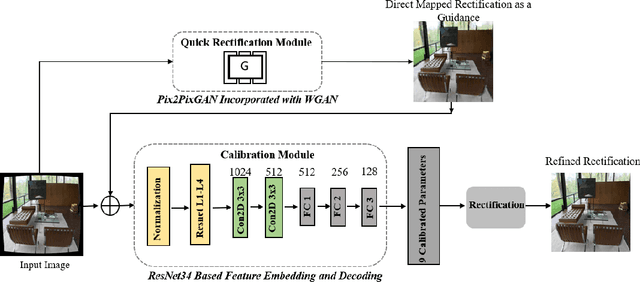

We propose an end-to-end deep learning approach to rectify fisheye images and simultaneously calibrate camera intrinsic and distortion parameters. Our method consists of two parts: a Quick Image Rectification Module developed with a Pix2Pix GAN and Wasserstein GAN (W-Pix2PixGAN), and a Calibration Module with a CNN architecture. Our Quick Rectification Network performs robust rectification with good resolution, making it suitable for constant calibration in camera-based surveillance equipment. To achieve high-quality calibration, we use the straightened output from the Quick Rectification Module as a guidance-like semantic feature map for the Calibration Module to learn the geometric relationship between the straightened feature and the distorted feature. We train and validate our method with a large synthesized dataset labeled with well-simulated parameters applied to a perspective image dataset. Our solution has achieved robust performance in high-resolution with a significant PSNR value of 22.343.
DiffusionCT: Latent Diffusion Model for CT Image Standardization
Jan 20, 2023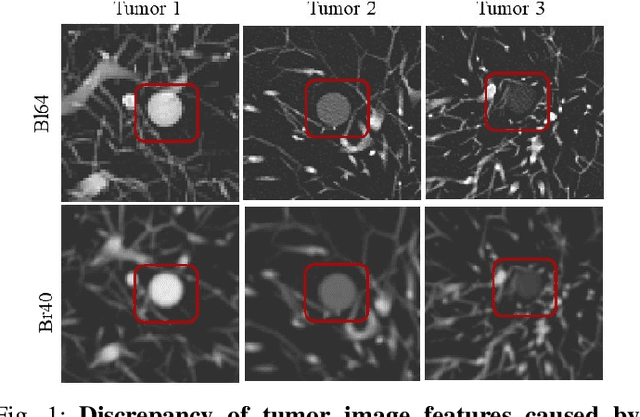
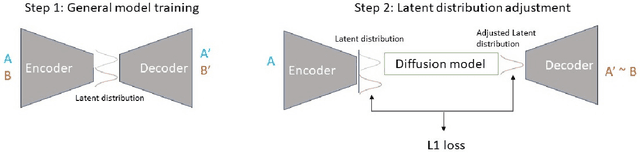
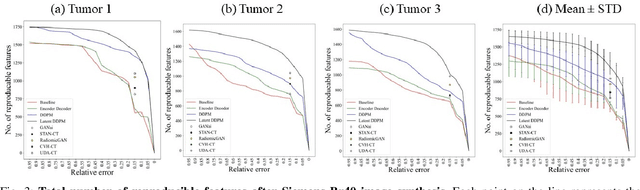
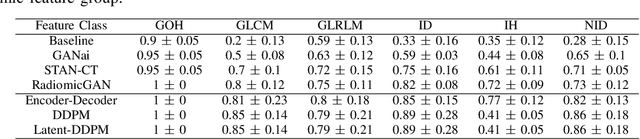
Computed tomography (CT) imaging is a widely used modality for early lung cancer diagnosis, treatment, and prognosis. Features extracted from CT images are now accepted to quantify spatial and temporal variations in tumor architecture and function. However, CT images are often acquired using scanners from different vendors with customized acquisition standards, resulting in significantly different texture features even for the same patient, posing a fundamental challenge to downstream studies. Existing CT image harmonization models rely on supervised or semi-supervised techniques, with limited performance. In this paper, we have proposed a diffusion-based CT image standardization model called DiffusionCT which works on latent space by mapping latent distribution into a standard distribution. DiffusionCT incorporates an Unet-based encoder-decoder and a diffusion model embedded in its bottleneck part. The Unet first trained without the diffusion model to learn the latent representation of the input data. The diffusion model is trained in the next training phase. All the trained models work together on image standardization. The encoded representation outputted from the Unet encoder passes through the diffusion model, and the diffusion model maps the distribution in to target standard image domain. Finally, the decode takes that transformed latent representation to synthesize a standardized image. The experimental results show that DiffusionCT significantly improves the performance of the standardization task.
Vision Transformer Off-the-Shelf: A Surprising Baseline for Few-Shot Class-Agnostic Counting
May 08, 2023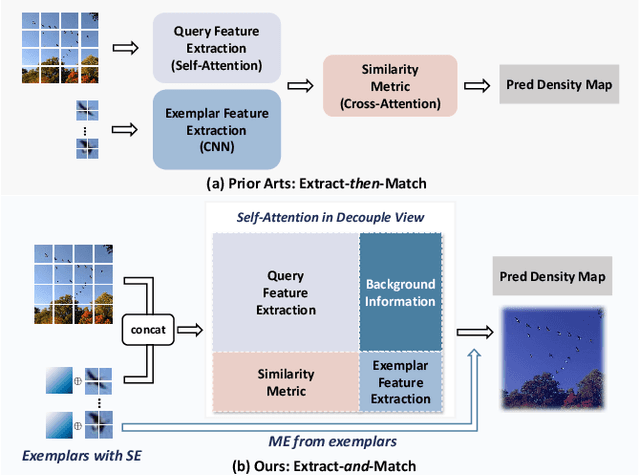
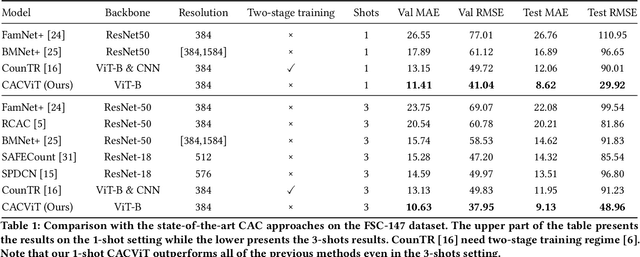
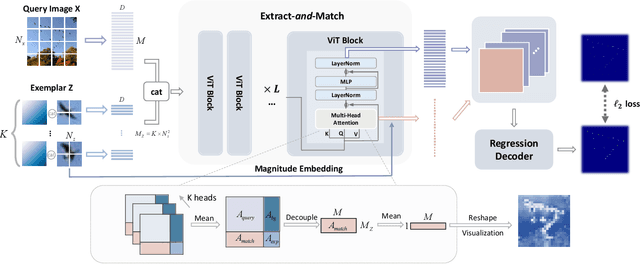
Class-agnostic counting (CAC) aims to count objects of interest from a query image given few exemplars. This task is typically addressed by extracting the features of query image and exemplars respectively with (un)shared feature extractors and by matching their feature similarity, leading to an extract-\textit{then}-match paradigm. In this work, we show that CAC can be simplified in an extract-\textit{and}-match manner, particularly using a pretrained and plain vision transformer (ViT) where feature extraction and similarity matching are executed simultaneously within the self-attention. We reveal the rationale of such simplification from a decoupled view of the self-attention and point out that the simplification is only made possible if the query and exemplar tokens are concatenated as input. The resulting model, termed CACViT, simplifies the CAC pipeline and unifies the feature spaces between the query image and exemplars. In addition, we find CACViT naturally encodes background information within self-attention, which helps reduce background disturbance. Further, to compensate the loss of the scale and the order-of-magnitude information due to resizing and normalization in ViT, we present two effective strategies for scale and magnitude embedding. Extensive experiments on the FSC147 and the CARPK datasets show that CACViT significantly outperforms state-of-the-art CAC approaches in both effectiveness (23.60% error reduction) and generalization, which suggests CACViT provides a concise and strong baseline for CAC. Code will be available.
Automatic Photo Orientation Detection with Convolutional Neural Networks
May 17, 2023


We apply convolutional neural networks (CNN) to the problem of image orientation detection in the context of determining the correct orientation (from 0, 90, 180, and 270 degrees) of a consumer photo. The problem is especially important for digitazing analog photographs. We substantially improve on the published state of the art in terms of the performance on one of the standard datasets, and test our system on a more difficult large dataset of consumer photos. We use Guided Backpropagation to obtain insights into how our CNN detects photo orientation, and to explain its mistakes.
Hyperspectral Image Super Resolution with Real Unaligned RGB Guidance
Feb 13, 2023

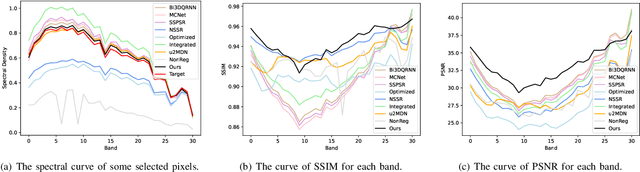
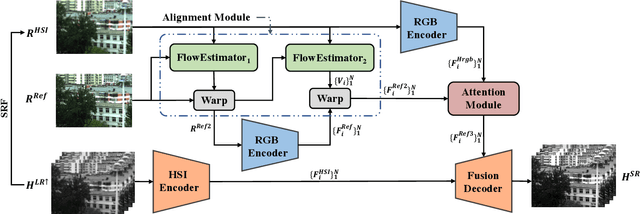
Fusion-based hyperspectral image (HSI) super-resolution has become increasingly prevalent for its capability to integrate high-frequency spatial information from the paired high-resolution (HR) RGB reference image. However, most of the existing methods either heavily rely on the accurate alignment between low-resolution (LR) HSIs and RGB images, or can only deal with simulated unaligned RGB images generated by rigid geometric transformations, which weakens their effectiveness for real scenes. In this paper, we explore the fusion-based HSI super-resolution with real RGB reference images that have both rigid and non-rigid misalignments. To properly address the limitations of existing methods for unaligned reference images, we propose an HSI fusion network with heterogenous feature extractions, multi-stage feature alignments, and attentive feature fusion. Specifically, our network first transforms the input HSI and RGB images into two sets of multi-scale features with an HSI encoder and an RGB encoder, respectively. The features of RGB reference images are then processed by a multi-stage alignment module to explicitly align the features of RGB reference with the LR HSI. Finally, the aligned features of RGB reference are further adjusted by an adaptive attention module to focus more on discriminative regions before sending them to the fusion decoder to generate the reconstructed HR HSI. Additionally, we collect a real-world HSI fusion dataset, consisting of paired HSI and unaligned RGB reference, to support the evaluation of the proposed model for real scenes. Extensive experiments are conducted on both simulated and our real-world datasets, and it shows that our method obtains a clear improvement over existing single-image and fusion-based super-resolution methods on quantitative assessment as well as visual comparison.
FCA: Taming Long-tailed Federated Medical Image Classification by Classifier Anchoring
May 01, 2023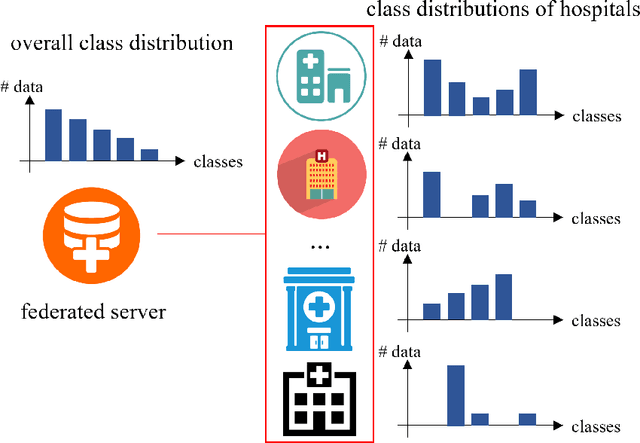
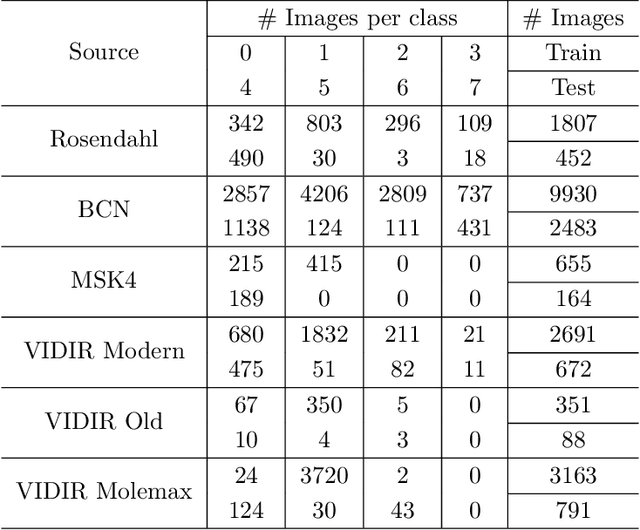
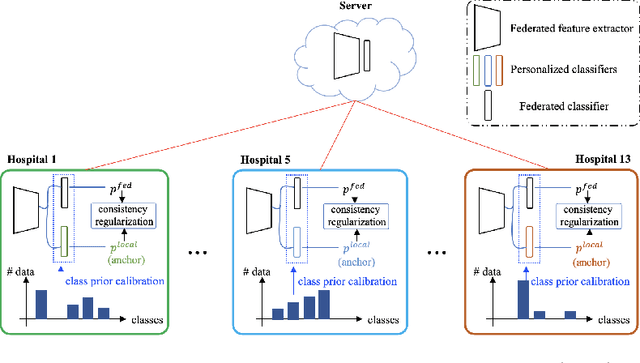
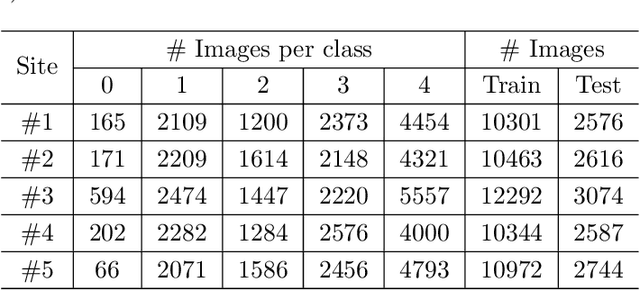
Limited training data and severe class imbalance impose significant challenges to developing clinically robust deep learning models. Federated learning (FL) addresses the former by enabling different medical clients to collaboratively train a deep model without sharing data. However, the class imbalance problem persists due to inter-client class distribution variations. To overcome this, we propose federated classifier anchoring (FCA) by adding a personalized classifier at each client to guide and debias the federated model through consistency learning. Additionally, FCA debiases the federated classifier and each client's personalized classifier based on their respective class distributions, thus mitigating divergence. With FCA, the federated feature extractor effectively learns discriminative features suitably globally for federation as well as locally for all participants. In clinical practice, the federated model is expected to be both generalized, performing well across clients, and specialized, benefiting each individual client from collaboration. According to this, we propose a novel evaluation metric to assess models' generalization and specialization performance globally on an aggregated public test set and locally at each client. Through comprehensive comparison and evaluation, FCA outperforms the state-of-the-art methods with large margins for federated long-tailed skin lesion classification and intracranial hemorrhage classification, making it a more feasible solution in clinical settings.
Unposed: Unsupervised Pose Estimation based Product Image Recommendations
Jan 19, 2023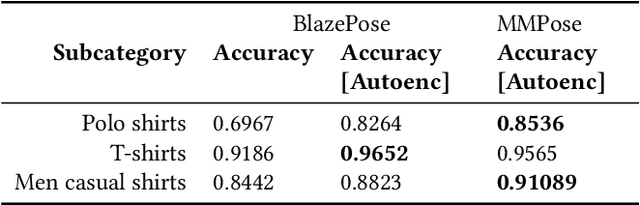
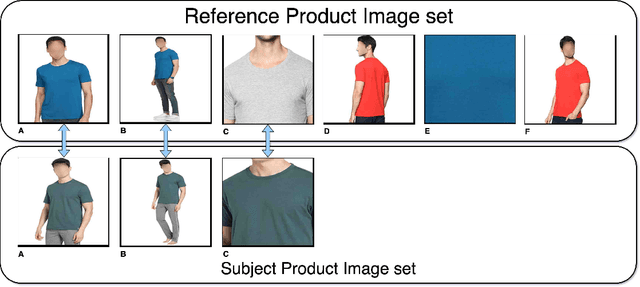
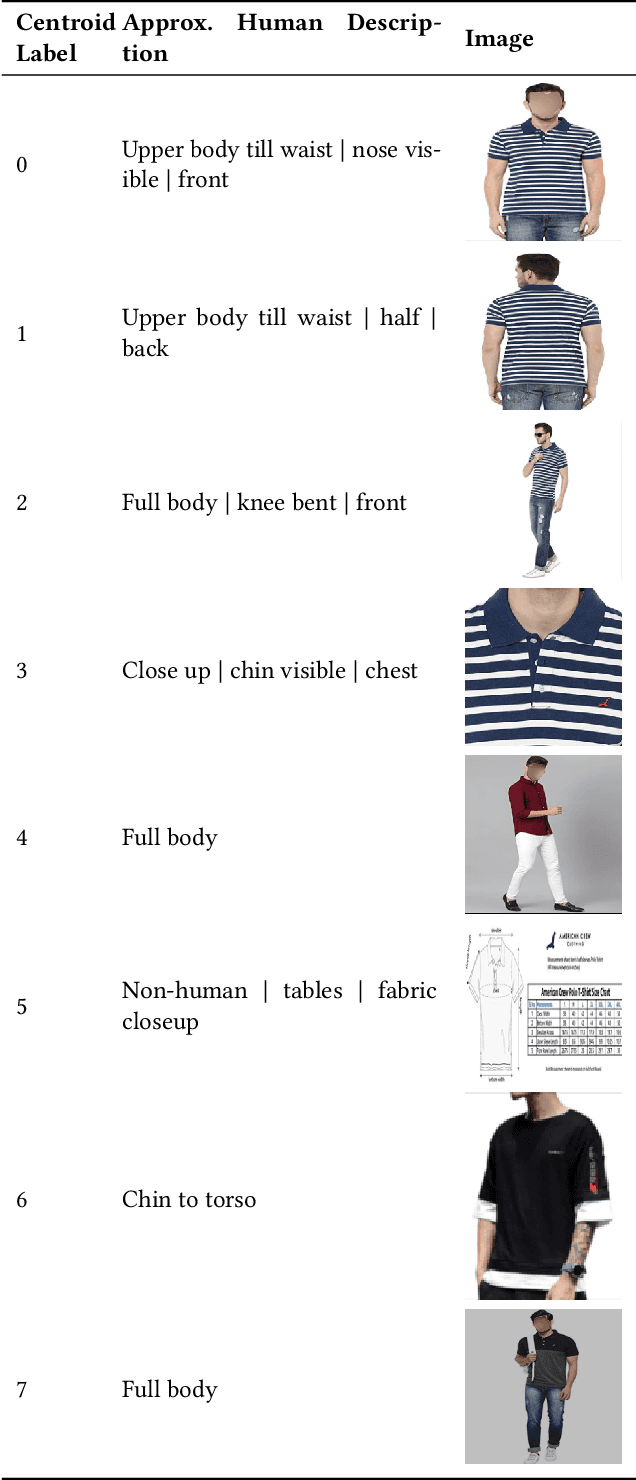
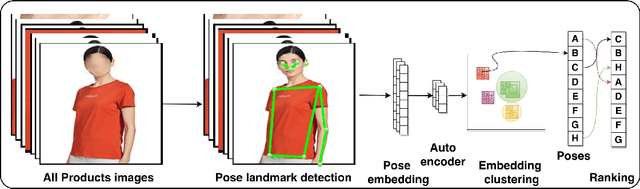
Product images are the most impressing medium of customer interaction on the product detail pages of e-commerce websites. Millions of products are onboarded on to webstore catalogues daily and maintaining a high quality bar for a product's set of images is a problem at scale. Grouping products by categories, clothing is a very high volume and high velocity category and thus deserves its own attention. Given the scale it is challenging to monitor the completeness of image set, which adequately details the product for the consumers, which in turn often leads to a poor customer experience and thus customer drop off. To supervise the quality and completeness of the images in the product pages for these product types and suggest improvements, we propose a Human Pose Detection based unsupervised method to scan the image set of a product for the missing ones. The unsupervised approach suggests a fair approach to sellers based on product and category irrespective of any biases. We first create a reference image set of popular products with wholesome imageset. Then we create clusters of images to label most desirable poses to form the classes for the reference set from these ideal products set. Further, for all test products we scan the images for all desired pose classes w.r.t. reference set poses, determine the missing ones and sort them in the order of potential impact. These missing poses can further be used by the sellers to add enriched product listing image. We gathered data from popular online webstore and surveyed ~200 products manually, a large fraction of which had at least 1 repeated image or missing variant, and sampled 3K products(~20K images) of which a significant proportion had scope for adding many image variants as compared to high rated products which had more than double image variants, indicating that our model can potentially be used on a large scale.