 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Increasing Melanoma Diagnostic Confidence: Forcing the Convolutional Network to Learn from the Lesion
May 16, 2023
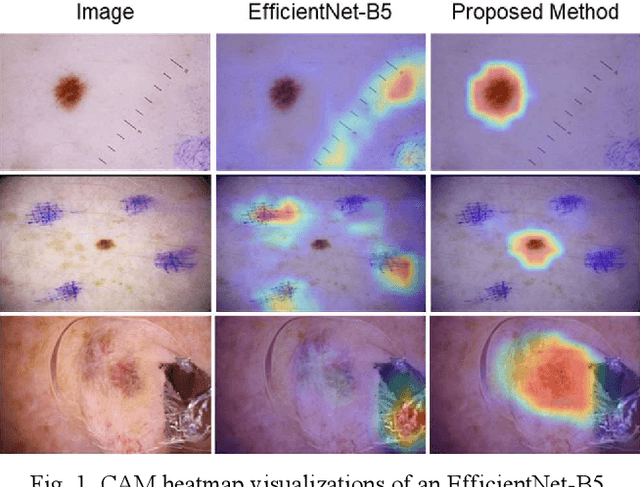
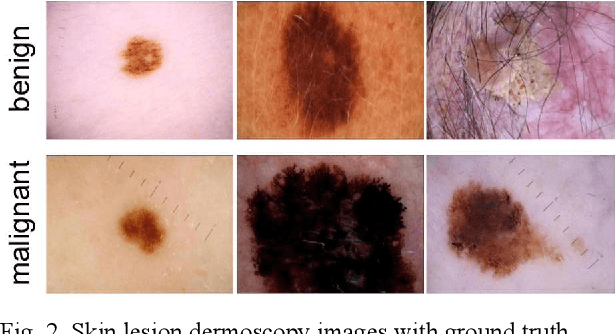
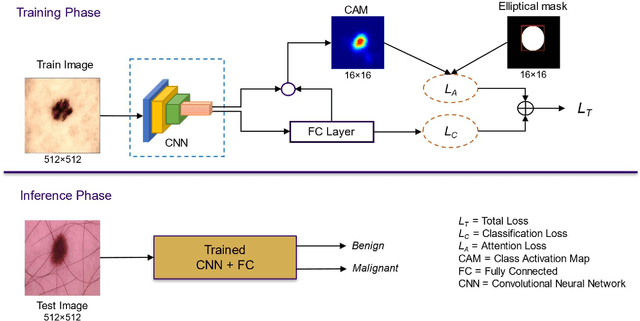

Deep learning implemented with convolutional network architectures can exceed specialists' diagnostic accuracy. However, whole-image deep learning trained on a given dataset may not generalize to other datasets. The problem arises because extra-lesional features - ruler marks, ink marks, and other melanoma correlates - may serve as information leaks. These extra-lesional features, discoverable by heat maps, degrade melanoma diagnostic performance and cause techniques learned on one data set to fail to generalize. We propose a novel technique to improve melanoma recognition by an EfficientNet model. The model trains the network to detect the lesion and learn features from the detected lesion. A generalizable elliptical segmentation model for lesions was developed, with an ellipse enclosing a lesion and the ellipse enclosed by an extended rectangle (bounding box). The minimal bounding box was extended by 20% to allow some background around the lesion. The publicly available International Skin Imaging Collaboration (ISIC) 2020 skin lesion image dataset was used to evaluate the effectiveness of the proposed method. Our test results show that the proposed method improved diagnostic accuracy by increasing the mean area under receiver operating characteristic curve (mean AUC) score from 0.9 to 0.922. Additionally, correctly diagnosed scores are also improved, providing better separation of scores, thereby increasing melanoma diagnostic confidence. The proposed lesion-focused convolutional technique warrants further study.
Selectively Hard Negative Mining for Alleviating Gradient Vanishing in Image-Text Matching
Mar 01, 2023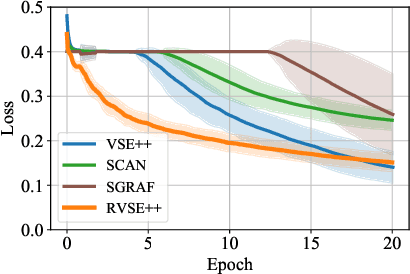
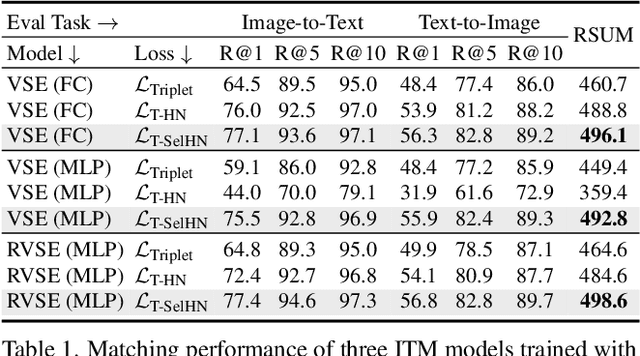
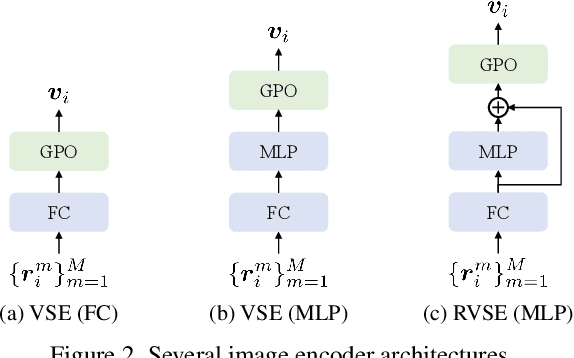
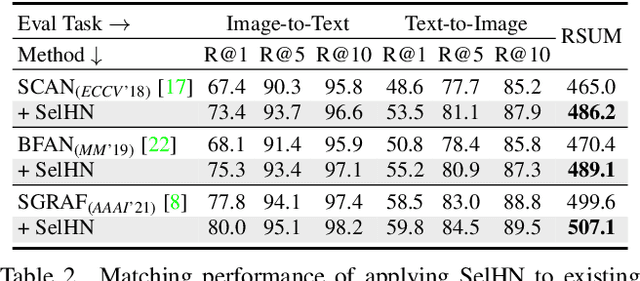
Recently, a series of Image-Text Matching (ITM) methods achieve impressive performance. However, we observe that most existing ITM models suffer from gradients vanishing at the beginning of training, which makes these models prone to falling into local minima. Most ITM models adopt triplet loss with Hard Negative mining (HN) as the optimization objective. We find that optimizing an ITM model using only the hard negative samples can easily lead to gradient vanishing. In this paper, we derive the condition under which the gradient vanishes during training. When the difference between the positive pair similarity and the negative pair similarity is close to 0, the gradients on both the image and text encoders will approach 0. To alleviate the gradient vanishing problem, we propose a Selectively Hard Negative Mining (SelHN) strategy, which chooses whether to mine hard negative samples according to the gradient vanishing condition. SelHN can be plug-and-play applied to existing ITM models to give them better training behavior. To further ensure the back-propagation of gradients, we construct a Residual Visual Semantic Embedding model with SelHN, denoted as RVSE++. Extensive experiments on two ITM benchmarks demonstrate the strength of RVSE++, achieving state-of-the-art performance.
Towards Universal Fake Image Detectors that Generalize Across Generative Models
Feb 20, 2023
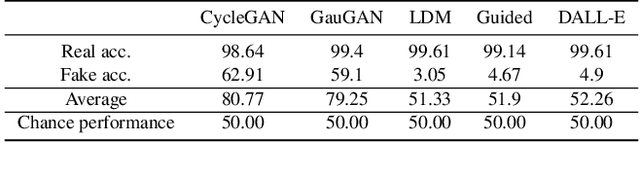
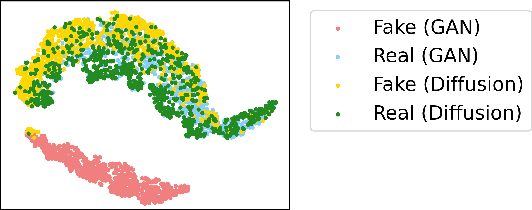
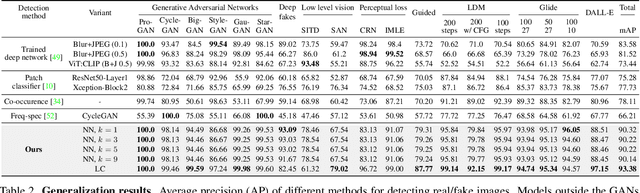
With generative models proliferating at a rapid rate, there is a growing need for general purpose fake image detectors. In this work, we first show that the existing paradigm, which consists of training a deep network for real-vs-fake classification, fails to detect fake images from newer breeds of generative models when trained to detect GAN fake images. Upon analysis, we find that the resulting classifier is asymmetrically tuned to detect patterns that make an image fake. The real class becomes a sink class holding anything that is not fake, including generated images from models not accessible during training. Building upon this discovery, we propose to perform real-vs-fake classification without learning; i.e., using a feature space not explicitly trained to distinguish real from fake images. We use nearest neighbor and linear probing as instantiations of this idea. When given access to the feature space of a large pretrained vision-language model, the very simple baseline of nearest neighbor classification has surprisingly good generalization ability in detecting fake images from a wide variety of generative models; e.g., it improves upon the SoTA by +15.07 mAP and +25.90% acc when tested on unseen diffusion and autoregressive models.
Super-Resolution of License Plate Images Using Attention Modules and Sub-Pixel Convolution Layers
May 27, 2023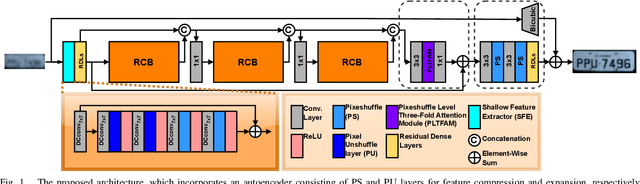
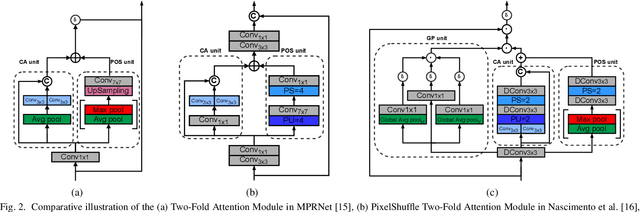


Recent years have seen significant developments in the field of License Plate Recognition (LPR) through the integration of deep learning techniques and the increasing availability of training data. Nevertheless, reconstructing license plates (LPs) from low-resolution (LR) surveillance footage remains challenging. To address this issue, we introduce a Single-Image Super-Resolution (SISR) approach that integrates attention and transformer modules to enhance the detection of structural and textural features in LR images. Our approach incorporates sub-pixel convolution layers (also known as PixelShuffle) and a loss function that uses an Optical Character Recognition (OCR) model for feature extraction. We trained the proposed architecture on synthetic images created by applying heavy Gaussian noise to high-resolution LP images from two public datasets, followed by bicubic downsampling. As a result, the generated images have a Structural Similarity Index Measure (SSIM) of less than 0.10. Our results show that our approach for reconstructing these low-resolution synthesized images outperforms existing ones in both quantitative and qualitative measures. Our code is publicly available at https://github.com/valfride/lpr-rsr-ext/
A Novel Low-Rank Tensor Method for Undersampling Artifact Removal in Respiratory Motion-Resolved Multi-Echo 3D Cones MRI
May 01, 2023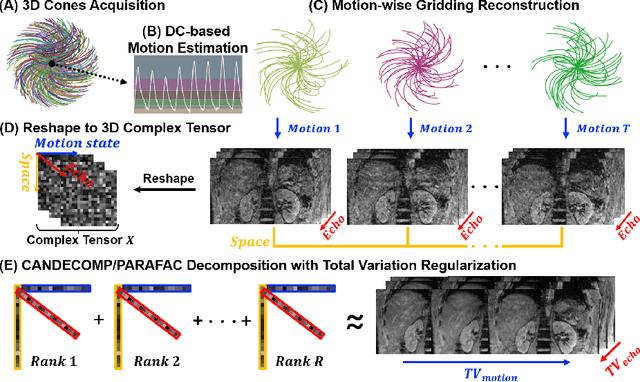
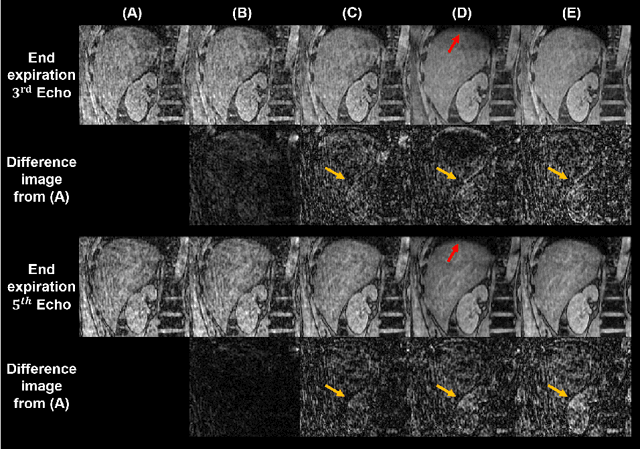
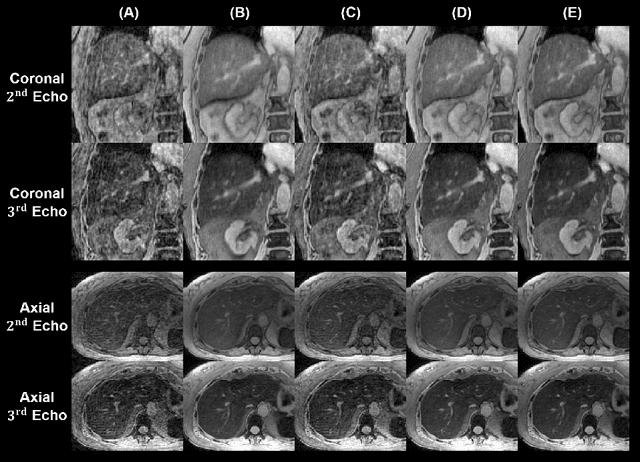
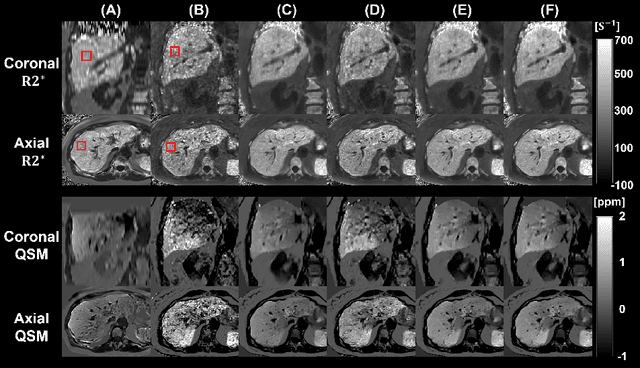
We propose a novel low-rank tensor method for respiratory motion-resolved multi-echo image reconstruction. The key idea is to construct a 3-way image tensor (space $\times$ echo $\times$ motion state) from the conventional gridding reconstruction of highly undersampled multi-echo k-space raw data, and exploit low-rank tensor structure to separate it from undersampling artifacts. Healthy volunteers and patients with iron overload were recruited and imaged on a 3T clinical MRI system for this study. Results show that our proposed method Successfully reduced severe undersampling artifacts in respiratory motion-state resolved complex source images, as well as subsequent R2* and quantitative susceptibility mapping (QSM). Compared to conventional respiratory motion-resolved compressed sensing (CS) image reconstruction, the proposed method had a reconstruction time at least three times faster, accounting for signal evolution along the echo dimension in the multi-echo data.
Concept Decomposition for Visual Exploration and Inspiration
May 31, 2023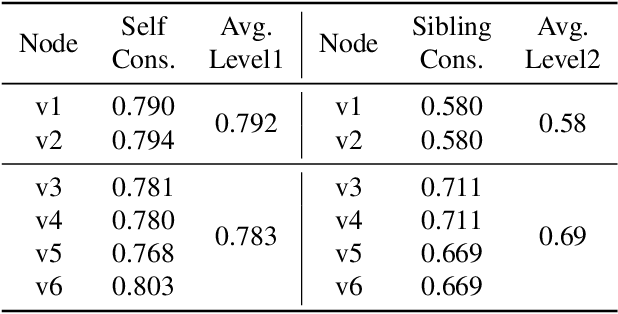
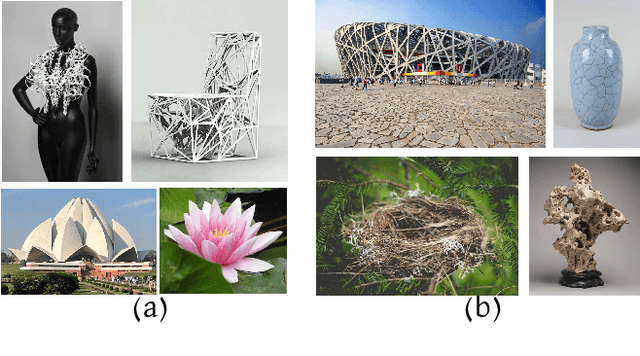

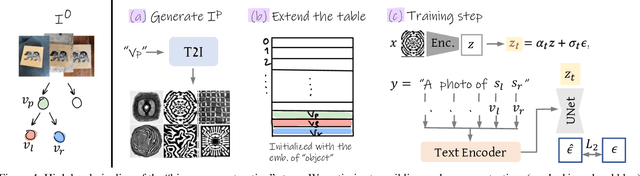
A creative idea is often born from transforming, combining, and modifying ideas from existing visual examples capturing various concepts. However, one cannot simply copy the concept as a whole, and inspiration is achieved by examining certain aspects of the concept. Hence, it is often necessary to separate a concept into different aspects to provide new perspectives. In this paper, we propose a method to decompose a visual concept, represented as a set of images, into different visual aspects encoded in a hierarchical tree structure. We utilize large vision-language models and their rich latent space for concept decomposition and generation. Each node in the tree represents a sub-concept using a learned vector embedding injected into the latent space of a pretrained text-to-image model. We use a set of regularizations to guide the optimization of the embedding vectors encoded in the nodes to follow the hierarchical structure of the tree. Our method allows to explore and discover new concepts derived from the original one. The tree provides the possibility of endless visual sampling at each node, allowing the user to explore the hidden sub-concepts of the object of interest. The learned aspects in each node can be combined within and across trees to create new visual ideas, and can be used in natural language sentences to apply such aspects to new designs.
Learning Explicit Contact for Implicit Reconstruction of Hand-held Objects from Monocular Images
May 31, 2023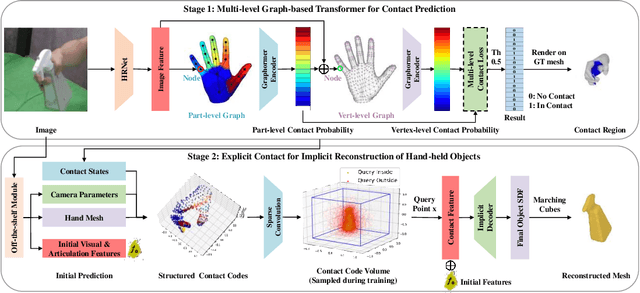

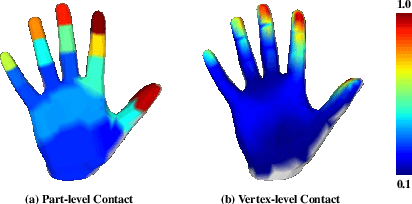
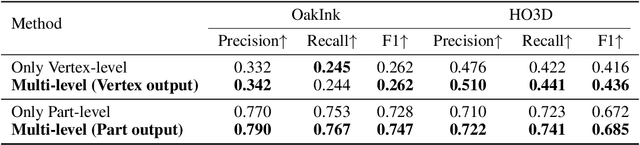
Reconstructing hand-held objects from monocular RGB images is an appealing yet challenging task. In this task, contacts between hands and objects provide important cues for recovering the 3D geometry of the hand-held objects. Though recent works have employed implicit functions to achieve impressive progress, they ignore formulating contacts in their frameworks, which results in producing less realistic object meshes. In this work, we explore how to model contacts in an explicit way to benefit the implicit reconstruction of hand-held objects. Our method consists of two components: explicit contact prediction and implicit shape reconstruction. In the first part, we propose a new subtask of directly estimating 3D hand-object contacts from a single image. The part-level and vertex-level graph-based transformers are cascaded and jointly learned in a coarse-to-fine manner for more accurate contact probabilities. In the second part, we introduce a novel method to diffuse estimated contact states from the hand mesh surface to nearby 3D space and leverage diffused contact probabilities to construct the implicit neural representation for the manipulated object. Benefiting from estimating the interaction patterns between the hand and the object, our method can reconstruct more realistic object meshes, especially for object parts that are in contact with hands. Extensive experiments on challenging benchmarks show that the proposed method outperforms the current state of the arts by a great margin.
LOWA: Localize Objects in the Wild with Attributes
May 31, 2023

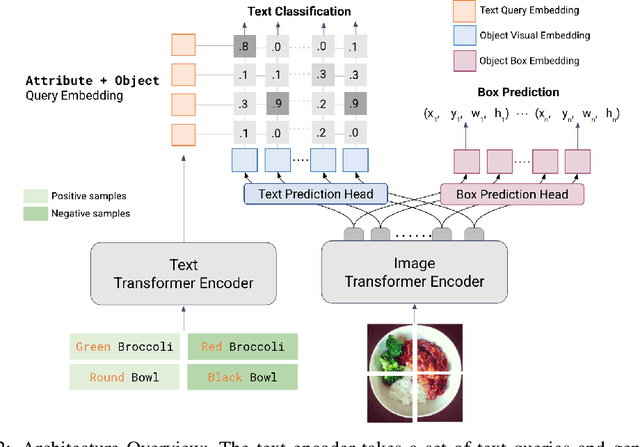
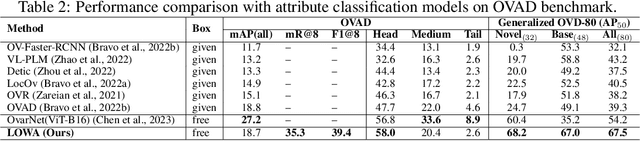
We present LOWA, a novel method for localizing objects with attributes effectively in the wild. It aims to address the insufficiency of current open-vocabulary object detectors, which are limited by the lack of instance-level attribute classification and rare class names. To train LOWA, we propose a hybrid vision-language training strategy to learn object detection and recognition with class names as well as attribute information. With LOWA, users can not only detect objects with class names, but also able to localize objects by attributes. LOWA is built on top of a two-tower vision-language architecture and consists of a standard vision transformer as the image encoder and a similar transformer as the text encoder. To learn the alignment between visual and text inputs at the instance level, we train LOWA with three training steps: object-level training, attribute-aware learning, and free-text joint training of objects and attributes. This hybrid training strategy first ensures correct object detection, then incorporates instance-level attribute information, and finally balances the object class and attribute sensitivity. We evaluate our model performance of attribute classification and attribute localization on the Open-Vocabulary Attribute Detection (OVAD) benchmark and the Visual Attributes in the Wild (VAW) dataset, and experiments indicate strong zero-shot performance. Ablation studies additionally demonstrate the effectiveness of each training step of our approach.
A Universal Latent Fingerprint Enhancer Using Transformers
May 31, 2023
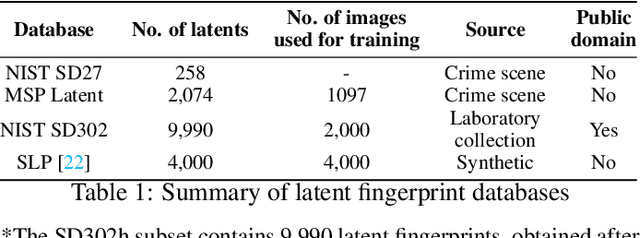

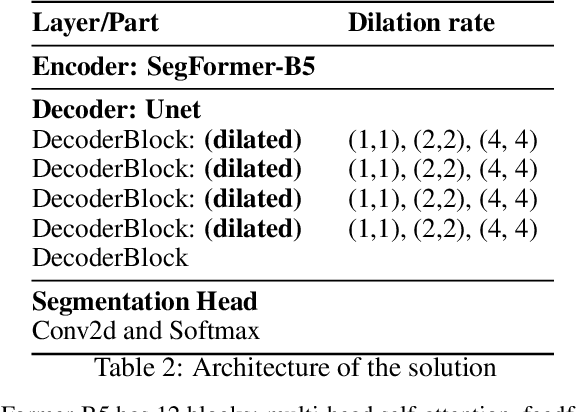
Forensic science heavily relies on analyzing latent fingerprints, which are crucial for criminal investigations. However, various challenges, such as background noise, overlapping prints, and contamination, make the identification process difficult. Moreover, limited access to real crime scene and laboratory-generated databases hinders the development of efficient recognition algorithms. This study aims to develop a fast method, which we call ULPrint, to enhance various latent fingerprint types, including those obtained from real crime scenes and laboratory-created samples, to boost fingerprint recognition system performance. In closed-set identification accuracy experiments, the enhanced image was able to improve the performance of the MSU-AFIS from 61.56\% to 75.19\% in the NIST SD27 database, from 67.63\% to 77.02\% in the MSP Latent database, and from 46.90\% to 52.12\% in the NIST SD302 database. Our contributions include (1) the development of a two-step latent fingerprint enhancement method that combines Ridge Segmentation with UNet and Mix Visual Transformer (MiT) SegFormer-B5 encoder architecture, (2) the implementation of multiple dilated convolutions in the UNet architecture to capture intricate, non-local patterns better and enhance ridge segmentation, and (3) the guided blending of the predicted ridge mask with the latent fingerprint. This novel approach, ULPrint, streamlines the enhancement process, addressing challenges across diverse latent fingerprint types to improve forensic investigations and criminal justice outcomes.
Towards a Robust Framework for NeRF Evaluation
May 31, 2023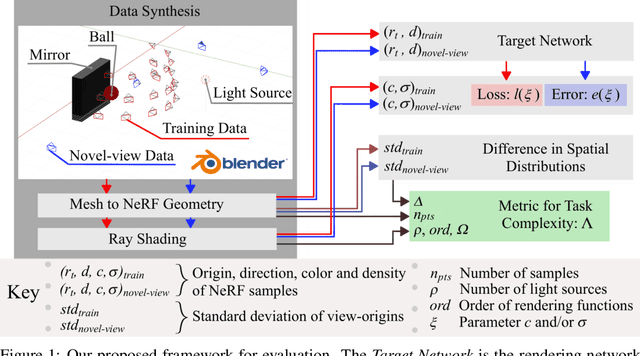

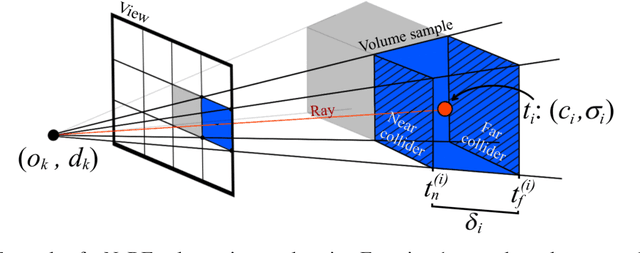
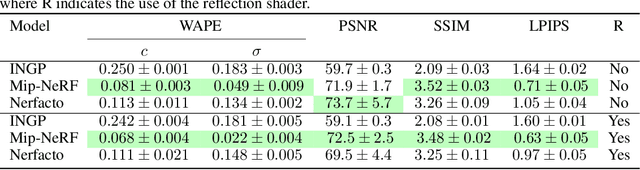
Neural Radiance Field (NeRF) research has attracted significant attention recently, with 3D modelling, virtual/augmented reality, and visual effects driving its application. While current NeRF implementations can produce high quality visual results, there is a conspicuous lack of reliable methods for evaluating them. Conventional image quality assessment methods and analytical metrics (e.g. PSNR, SSIM, LPIPS etc.) only provide approximate indicators of performance since they generalise the ability of the entire NeRF pipeline. Hence, in this paper, we propose a new test framework which isolates the neural rendering network from the NeRF pipeline and then performs a parametric evaluation by training and evaluating the NeRF on an explicit radiance field representation. We also introduce a configurable approach for generating representations specifically for evaluation purposes. This employs ray-casting to transform mesh models into explicit NeRF samples, as well as to "shade" these representations. Combining these two approaches, we demonstrate how different "tasks" (scenes with different visual effects or learning strategies) and types of networks (NeRFs and depth-wise implicit neural representations (INRs)) can be evaluated within this framework. Additionally, we propose a novel metric to measure task complexity of the framework which accounts for the visual parameters and the distribution of the spatial data. Our approach offers the potential to create a comparative objective evaluation framework for NeRF methods.