 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evaluating LeNet Algorithms in Classification Lung Cancer from Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases
May 19, 2023
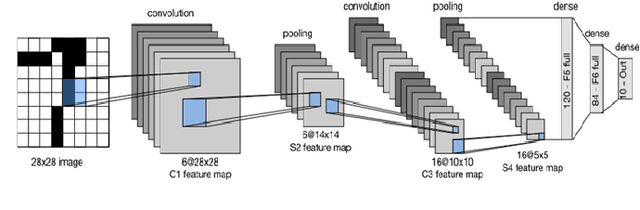
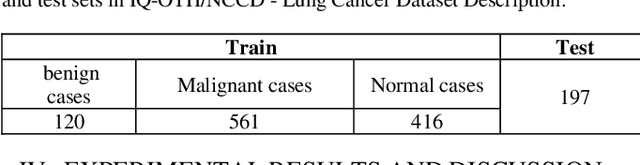
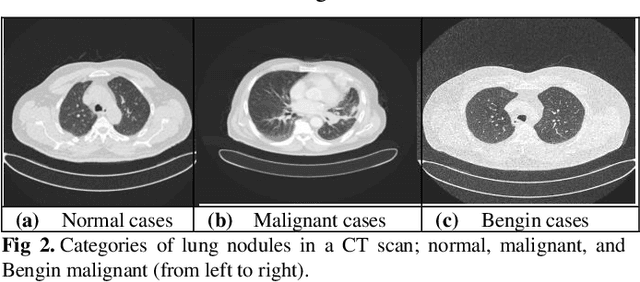
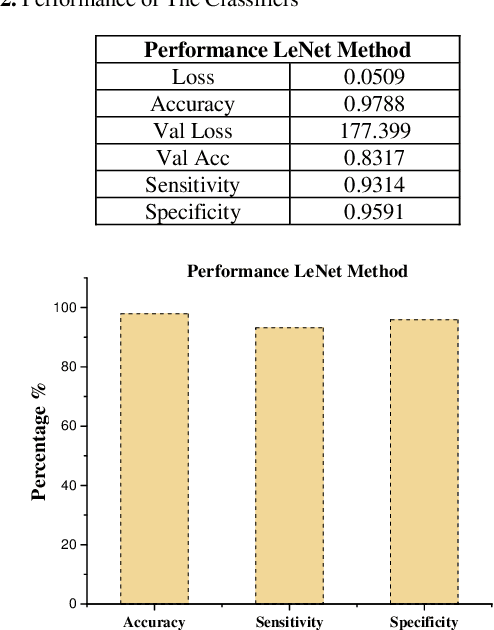
The advancement of computer-aided detection systems had a significant impact on clinical analysis and decision-making on human disease. Lung cancer requires more attention among the numerous diseases being examined because it affects both men and women, increasing the mortality rate. LeNet, a deep learning model, is used in this study to detect lung tumors. The studies were run on a publicly available dataset made up of CT image data (IQ-OTH/NCCD). Convolutional neural networks (CNNs) were employed in the experiment for feature extraction and classification. The proposed system was evaluated on Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases datasets the success percentage was calculated as 99.51%, sensitivity (93%) and specificity (95%), and better results were obtained compared to the existing methods. Development and validation of algorithms such as ours are important initial steps in the development of software suites that could be adopted in routine pathological practices and potentially help reduce the burden on pathologists.
PyTorch Hyperparameter Tuning -- A Tutorial for spotPython
May 19, 2023

The goal of hyperparameter tuning (or hyperparameter optimization) is to optimize the hyperparameters to improve the performance of the machine or deep learning model. spotPython (``Sequential Parameter Optimization Toolbox in Python'') is the Python version of the well-known hyperparameter tuner SPOT, which has been developed in the R programming environment for statistical analysis for over a decade. PyTorch is an optimized tensor library for deep learning using GPUs and CPUs. This document shows how to integrate the spotPython hyperparameter tuner into the PyTorch training workflow. As an example, the results of the CIFAR10 image classifier are used. In addition to an introduction to spotPython, this tutorial also includes a brief comparison with Ray Tune, a Python library for running experiments and tuning hyperparameters. This comparison is based on the PyTorch hyperparameter tuning tutorial. The advantages and disadvantages of both approaches are discussed. We show that spotPython achieves similar or even better results while being more flexible and transparent than Ray Tune.
ESPT: A Self-Supervised Episodic Spatial Pretext Task for Improving Few-Shot Learning
Apr 26, 2023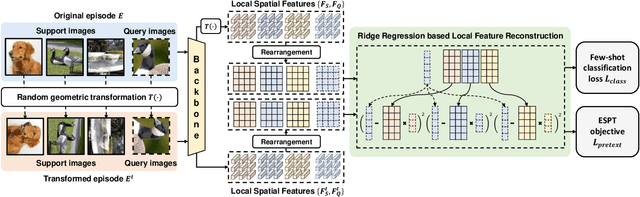
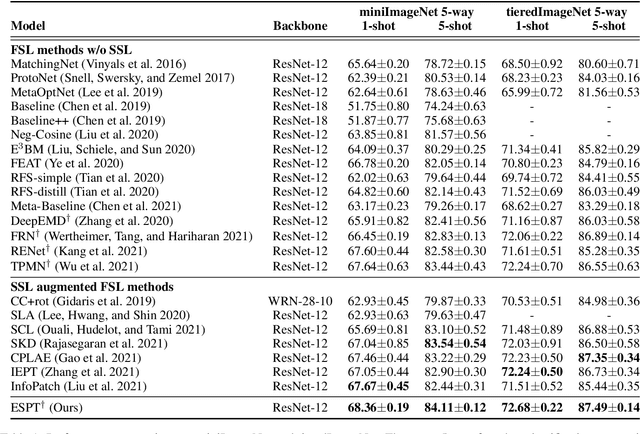
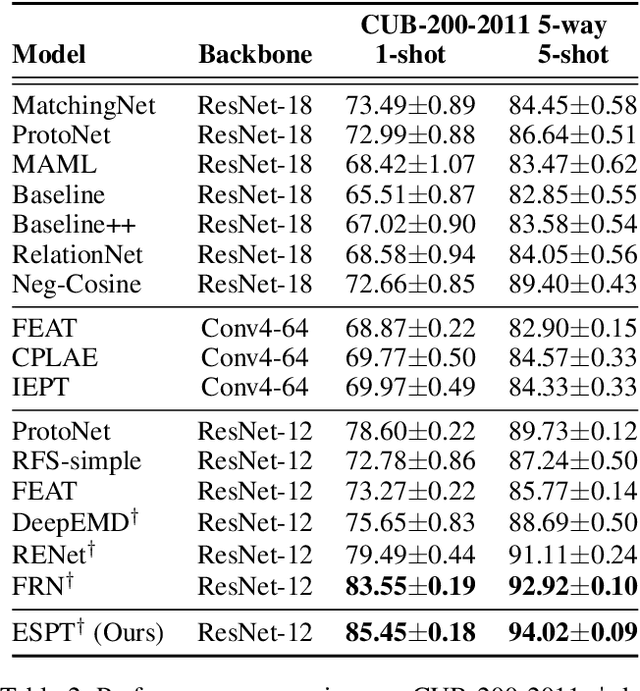
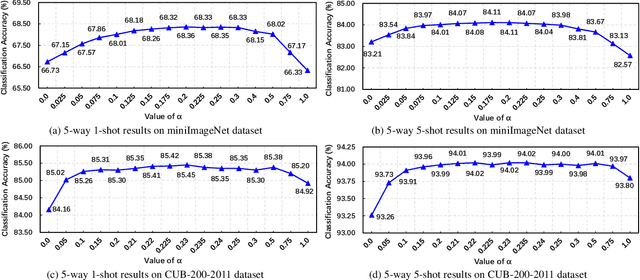
Self-supervised learning (SSL) techniques have recently been integrated into the few-shot learning (FSL) framework and have shown promising results in improving the few-shot image classification performance. However, existing SSL approaches used in FSL typically seek the supervision signals from the global embedding of every single image. Therefore, during the episodic training of FSL, these methods cannot capture and fully utilize the local visual information in image samples and the data structure information of the whole episode, which are beneficial to FSL. To this end, we propose to augment the few-shot learning objective with a novel self-supervised Episodic Spatial Pretext Task (ESPT). Specifically, for each few-shot episode, we generate its corresponding transformed episode by applying a random geometric transformation to all the images in it. Based on these, our ESPT objective is defined as maximizing the local spatial relationship consistency between the original episode and the transformed one. With this definition, the ESPT-augmented FSL objective promotes learning more transferable feature representations that capture the local spatial features of different images and their inter-relational structural information in each input episode, thus enabling the model to generalize better to new categories with only a few samples. Extensive experiments indicate that our ESPT method achieves new state-of-the-art performance for few-shot image classification on three mainstay benchmark datasets. The source code will be available at: https://github.com/Whut-YiRong/ESPT.
SuSana Distancia is all you need: Enforcing class separability in metric learning via two novel distance-based loss functions for few-shot image classification
May 18, 2023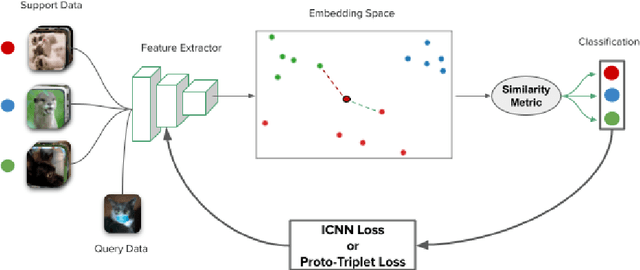
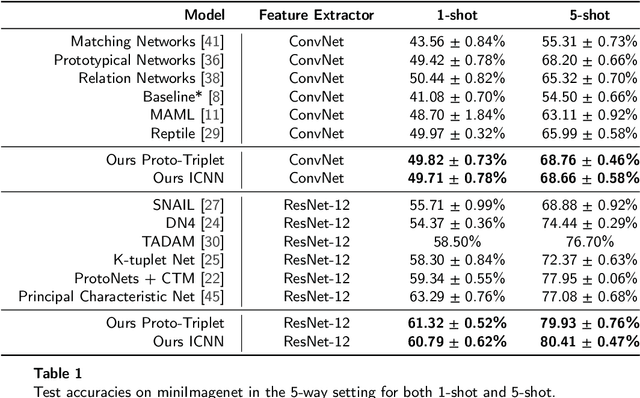
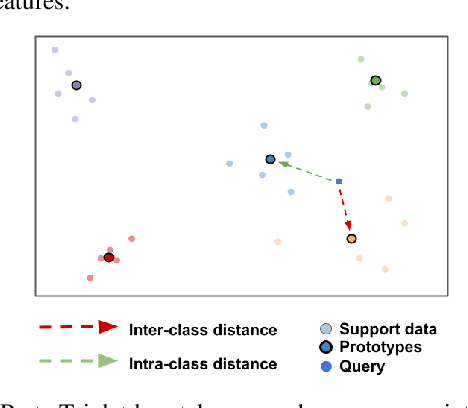
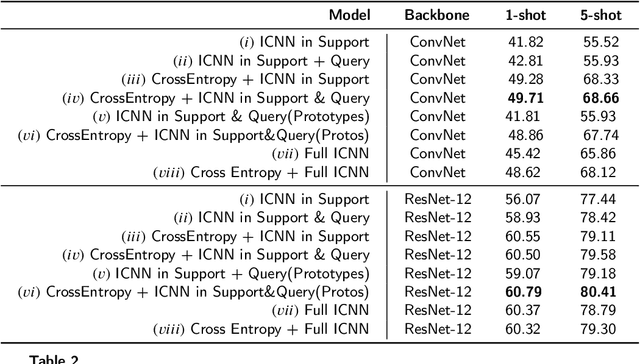
Few-shot learning is a challenging area of research that aims to learn new concepts with only a few labeled samples of data. Recent works based on metric-learning approaches leverage the meta-learning approach, which is encompassed by episodic tasks that make use a support (training) and query set (test) with the objective of learning a similarity comparison metric between those sets. Due to the lack of data, the learning process of the embedding network becomes an important part of the few-shot task. Previous works have addressed this problem using metric learning approaches, but the properties of the underlying latent space and the separability of the difference classes on it was not entirely enforced. In this work, we propose two different loss functions which consider the importance of the embedding vectors by looking at the intra-class and inter-class distance between the few data. The first loss function is the Proto-Triplet Loss, which is based on the original triplet loss with the modifications needed to better work on few-shot scenarios. The second loss function, which we dub ICNN loss is based on an inter and intra class nearest neighbors score, which help us to assess the quality of embeddings obtained from the trained network. Our results, obtained from a extensive experimental setup show a significant improvement in accuracy in the miniImagenNet benchmark compared to other metric-based few-shot learning methods by a margin of 2%, demonstrating the capability of these loss functions to allow the network to generalize better to previously unseen classes. In our experiments, we demonstrate competitive generalization capabilities to other domains, such as the Caltech CUB, Dogs and Cars datasets compared with the state of the art.
Z-GMOT: Zero-shot Generic Multiple Object Tracking
May 28, 2023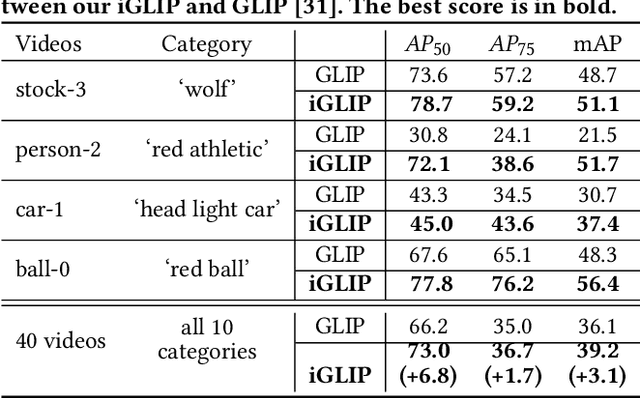
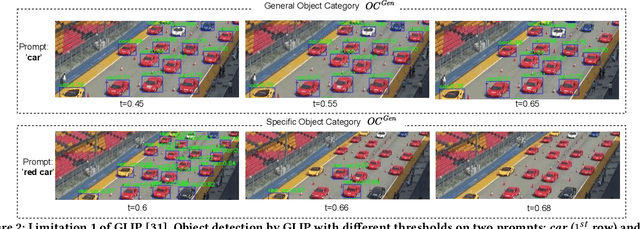


Despite the significant progress made in recent years, Multi-Object Tracking (MOT) approaches still suffer from several limitations, including their reliance on prior knowledge of tracking targets, which necessitates the costly annotation of large labeled datasets. As a result, existing MOT methods are limited to a small set of predefined categories, and they struggle with unseen objects in the real world. To address these issues, Generic Multiple Object Tracking (GMOT) has been proposed, which requires less prior information about the targets. However, all existing GMOT approaches follow a one-shot paradigm, relying mainly on the initial bounding box and thus struggling to handle variants e.g., viewpoint, lighting, occlusion, scale, and etc. In this paper, we introduce a novel approach to address the limitations of existing MOT and GMOT methods. Specifically, we propose a zero-shot GMOT (Z-GMOT) algorithm that can track never-seen object categories with zero training examples, without the need for predefined categories or an initial bounding box. To achieve this, we propose iGLIP, an improved version of Grounded language-image pretraining (GLIP), which can detect unseen objects while minimizing false positives. We evaluate our Z-GMOT thoroughly on the GMOT-40 dataset, AnimalTrack testset, DanceTrack testset. The results of these evaluations demonstrate a significant improvement over existing methods. For instance, on the GMOT-40 dataset, the Z-GMOT outperforms one-shot GMOT with OC-SORT by 27.79 points HOTA and 44.37 points MOTA. On the AnimalTrack dataset, it surpasses fully-supervised methods with DeepSORT by 12.55 points HOTA and 8.97 points MOTA. To facilitate further research, we will make our code and models publicly available upon acceptance of this paper.
Reconstructing Sea Surface Temperature Images: A Masked Autoencoder Approach for Cloud Masking and Reconstruction
May 28, 2023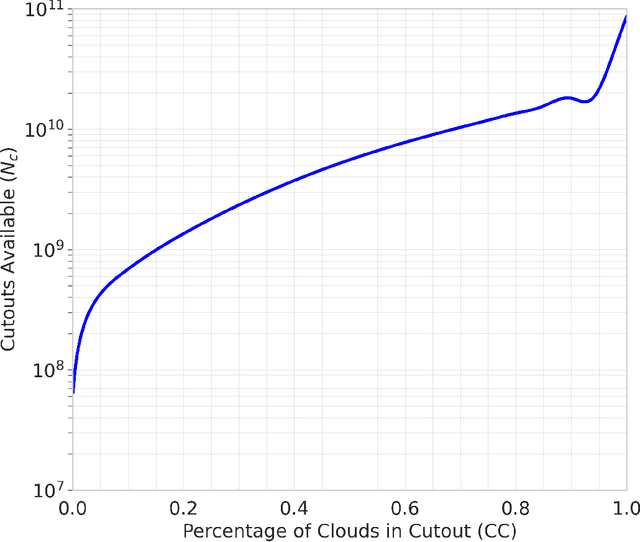
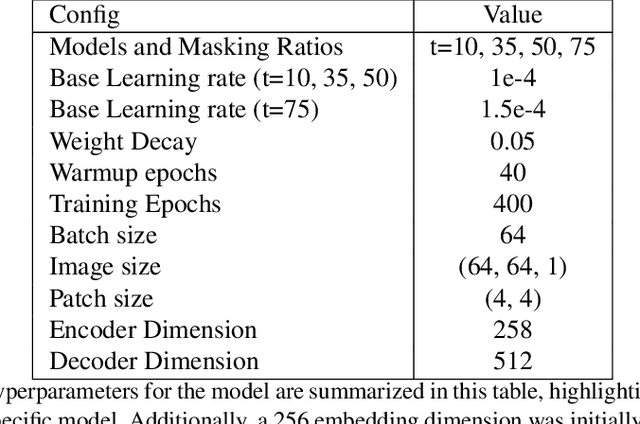
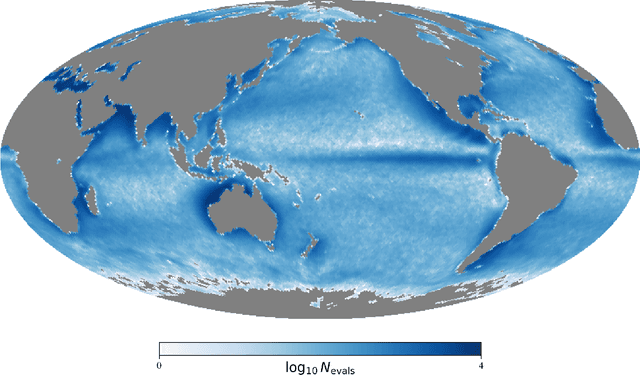
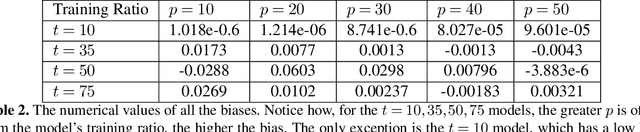
This thesis presents a new algorithm to mitigate cloud masking in the analysis of sea surface temperature (SST) data generated by remote sensing technologies, e.g., Clouds interfere with the analysis of all remote sensing data using wavelengths shorter than 12 microns, significantly limiting the quantity of usable data and creating a biased geographical distribution (towards equatorial and coastal regions). To address this issue, we propose an unsupervised machine learning algorithm called Enki which uses a Vision Transformer with Masked Autoencoding to reconstruct masked pixels. We train four different models of Enki with varying mask ratios (t) of 10%, 35%, 50%, and 75% on the generated Ocean General Circulation Model (OGCM) dataset referred to as LLC4320. To evaluate performance, we reconstruct a validation set of LLC4320 SST images with random ``clouds'' corrupting p=10%, 20%, 30%, 40%, 50% of the images with individual patches of 4x4 pixel^2. We consistently find that at all levels of p there is one or multiple models that reconstruct the images with a mean RMSE of less than 0.03K, i.e. lower than the estimated sensor error of VIIRS data. Similarly, at the individual patch level, the reconstructions have RMSE 8x smaller than the fluctuations in the patch. And, as anticipated, reconstruction errors are larger for images with a higher degree of complexity. Our analysis also reveals that patches along the image border have systematically higher reconstruction error; we recommend ignoring these in production. We conclude that Enki shows great promise to surpass in-painting as a means of reconstructing cloud masking. Future research will develop Enki to reconstruct real-world data.
Few Shot Learning for Medical Imaging: A Comparative Analysis of Methodologies and Formal Mathematical Framework
May 08, 2023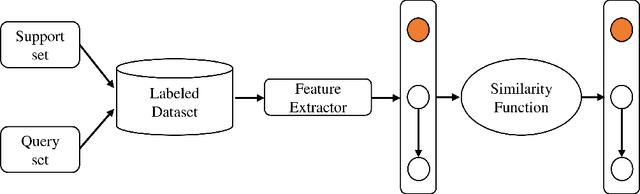
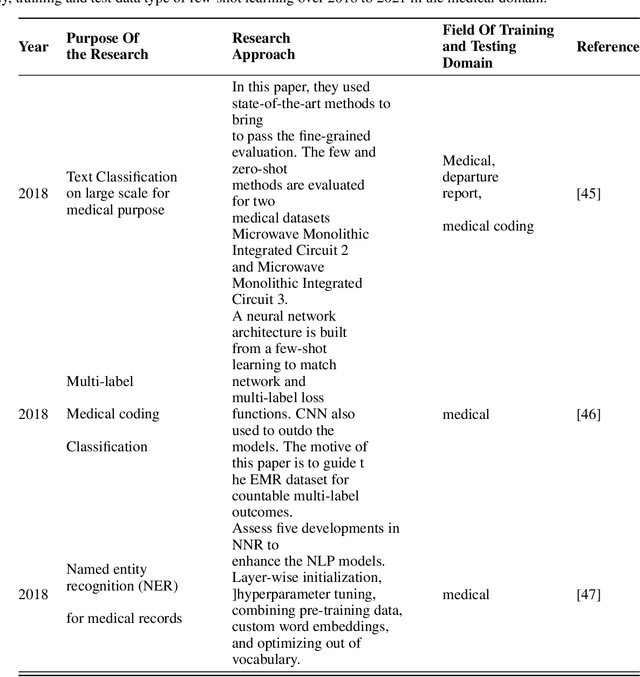
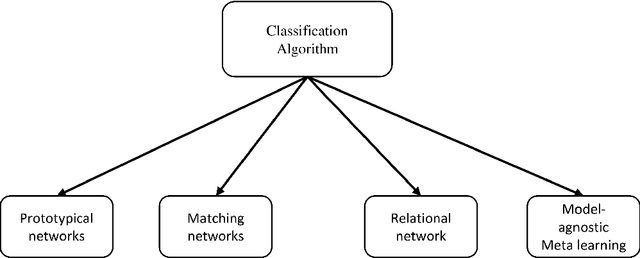
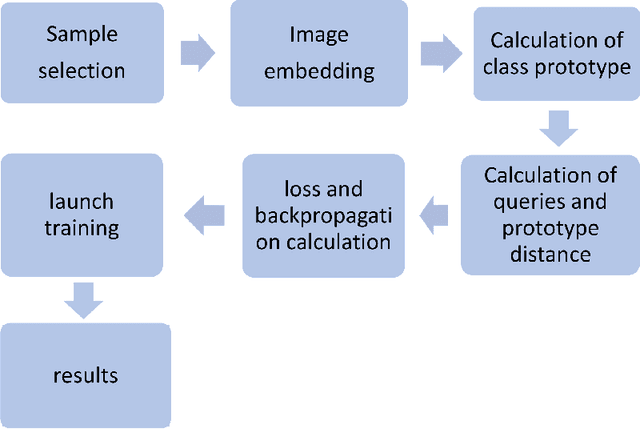
Deep learning becomes an elevated context regarding disposing of many machine learning tasks and has shown a breakthrough upliftment to extract features from unstructured data. Though this flourishing context is developing in the medical image processing sector, scarcity of problem-dependent training data has become a larger issue in the way of easy application of deep learning in the medical sector. To unravel the confined data source, researchers have developed a model that can solve machine learning problems with fewer data called ``Few shot learning". Few hot learning algorithms determine to solve the data limitation problems by extracting the characteristics from a small dataset through classification and segmentation methods. In the medical sector, there is frequently a shortage of available datasets in respect of some confidential diseases. Therefore, Few shot learning gets the limelight in this data scarcity sector. In this chapter, the background and basic overview of a few shots of learning is represented. Henceforth, the classification of few-shot learning is described also. Even the paper shows a comparison of methodological approaches that are applied in medical image analysis over time. The current advancement in the implementation of few-shot learning concerning medical imaging is illustrated. The future scope of this domain in the medical imaging sector is further described.
A Multi-Modal Context Reasoning Approach for Conditional Inference on Joint Textual and Visual Clues
May 08, 2023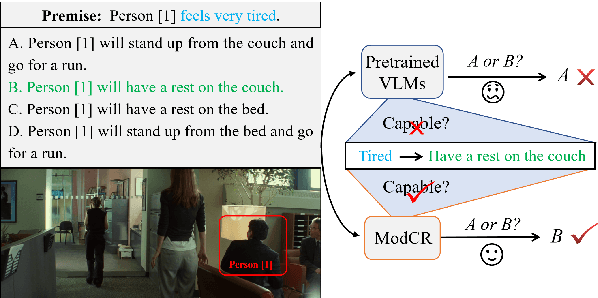
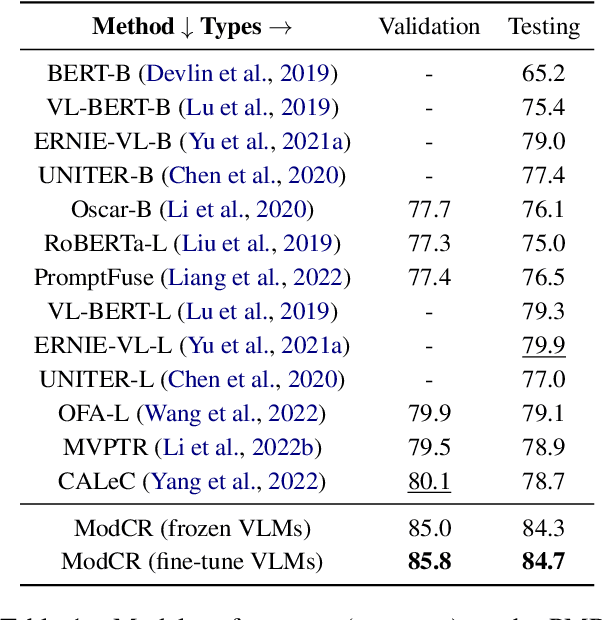
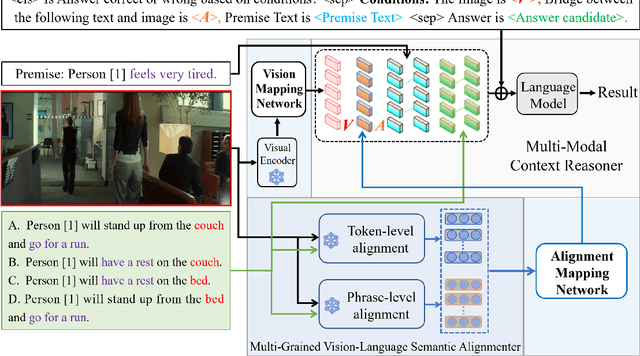
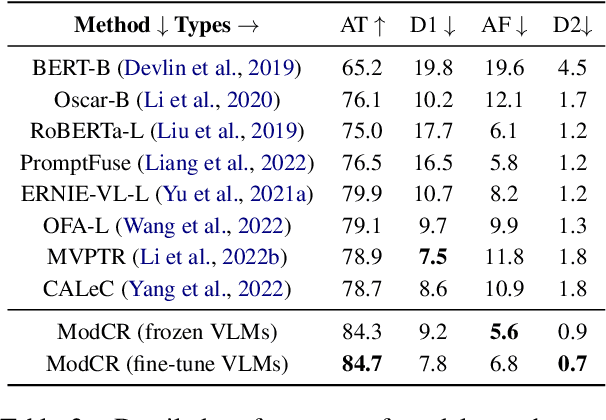
Conditional inference on joint textual and visual clues is a multi-modal reasoning task that textual clues provide prior permutation or external knowledge, which are complementary with visual content and pivotal to deducing the correct option. Previous methods utilizing pretrained vision-language models (VLMs) have achieved impressive performances, yet they show a lack of multimodal context reasoning capability, especially for text-modal information. To address this issue, we propose a Multi-modal Context Reasoning approach, named ModCR. Compared to VLMs performing reasoning via cross modal semantic alignment, it regards the given textual abstract semantic and objective image information as the pre-context information and embeds them into the language model to perform context reasoning. Different from recent vision-aided language models used in natural language processing, ModCR incorporates the multi-view semantic alignment information between language and vision by introducing the learnable alignment prefix between image and text in the pretrained language model. This makes the language model well-suitable for such multi-modal reasoning scenario on joint textual and visual clues. We conduct extensive experiments on two corresponding data sets and experimental results show significantly improved performance (exact gain by 4.8% on PMR test set) compared to previous strong baselines. Code Link: \url{https://github.com/YunxinLi/Multimodal-Context-Reasoning}.
ColMix -- A Simple Data Augmentation Framework to Improve Object Detector Performance and Robustness in Aerial Images
May 22, 2023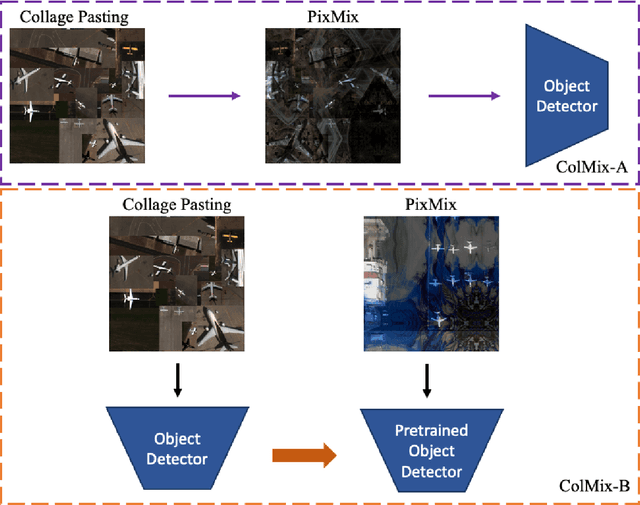

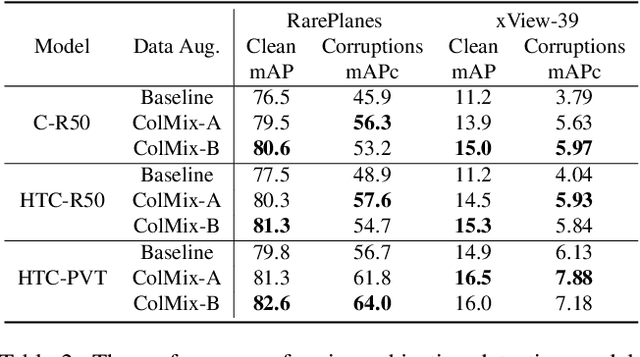
In the last decade, Convolutional Neural Network (CNN) and transformer based object detectors have achieved high performance on a large variety of datasets. Though the majority of detection literature has developed this capability on datasets such as MS COCO, these detectors have still proven effective for remote sensing applications. Challenges in this particular domain, such as small numbers of annotated objects and low object density, hinder overall performance. In this work, we present a novel augmentation method, called collage pasting, for increasing the object density without a need for segmentation masks, thereby improving the detector performance. We demonstrate that collage pasting improves precision and recall beyond related methods, such as mosaic augmentation, and enables greater control of object density. However, we find that collage pasting is vulnerable to certain out-of-distribution shifts, such as image corruptions. To address this, we introduce two simple approaches for combining collage pasting with PixMix augmentation method, and refer to our combined techniques as ColMix. Through extensive experiments, we show that employing ColMix results in detectors with superior performance on aerial imagery datasets and robust to various corruptions.
ControlVideo: Training-free Controllable Text-to-Video Generation
May 22, 2023
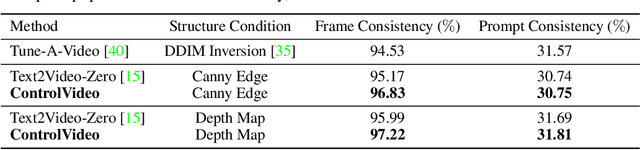
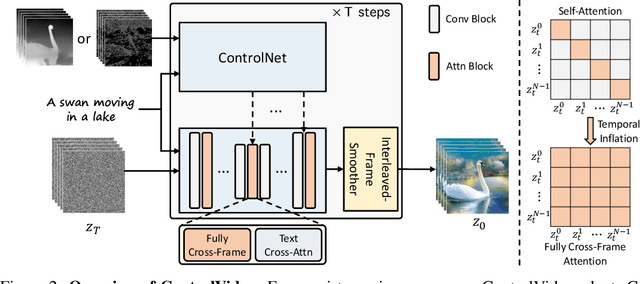
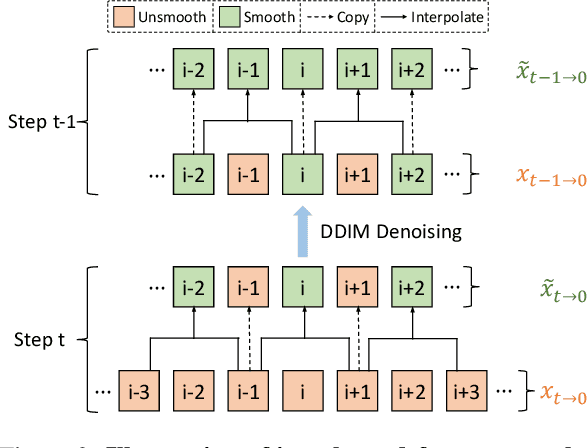
Text-driven diffusion models have unlocked unprecedented abilities in image generation, whereas their video counterpart still lags behind due to the excessive training cost of temporal modeling. Besides the training burden, the generated videos also suffer from appearance inconsistency and structural flickers, especially in long video synthesis. To address these challenges, we design a \emph{training-free} framework called \textbf{ControlVideo} to enable natural and efficient text-to-video generation. ControlVideo, adapted from ControlNet, leverages coarsely structural consistency from input motion sequences, and introduces three modules to improve video generation. Firstly, to ensure appearance coherence between frames, ControlVideo adds fully cross-frame interaction in self-attention modules. Secondly, to mitigate the flicker effect, it introduces an interleaved-frame smoother that employs frame interpolation on alternated frames. Finally, to produce long videos efficiently, it utilizes a hierarchical sampler that separately synthesizes each short clip with holistic coherency. Empowered with these modules, ControlVideo outperforms the state-of-the-arts on extensive motion-prompt pairs quantitatively and qualitatively. Notably, thanks to the efficient designs, it generates both short and long videos within several minutes using one NVIDIA 2080Ti. Code is available at https://github.com/YBYBZhang/ControlVideo.