 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Seam Prediction for Image Stitching Based on Selection Consistency Loss
Feb 10, 2023
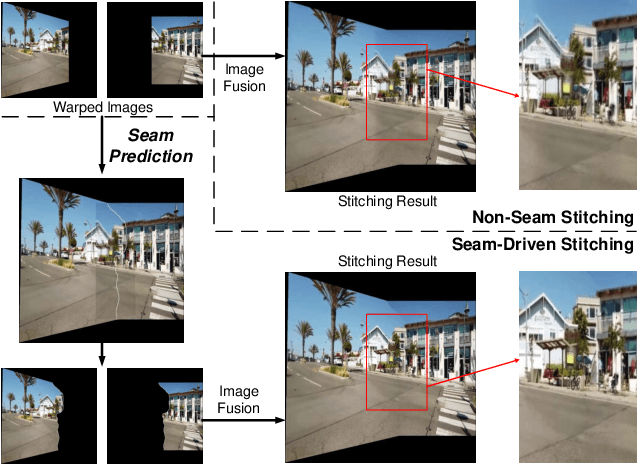
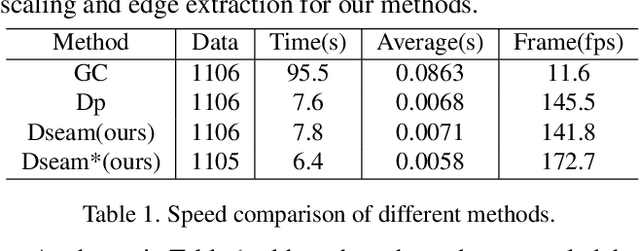
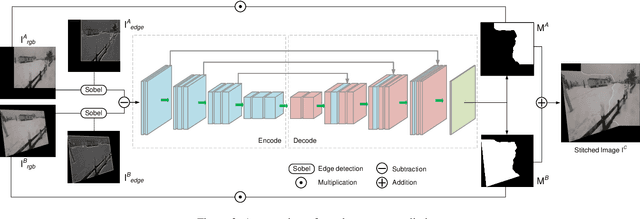
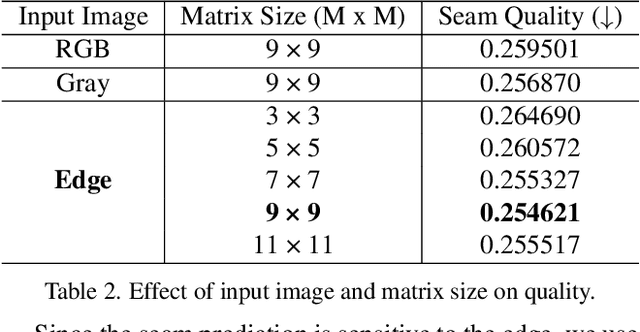
Image stitching is to construct panoramic images with wider field of vision (FOV) from some images captured from different viewing positions. To solve the problem of fusion ghosting in the stitched image, seam-driven methods avoid the misalignment area to fuse images by predicting the best seam. Currently, as standard tools of the OpenCV library, dynamic programming (DP) and GraphCut (GC) are still the only commonly used seam prediction methods despite the fact that they were both proposed two decades ago. However, GC can get excellent seam quality but poor real-time performance while DP method has good efficiency but poor seam quality. In this paper, we propose a deep learning based seam prediction method (DSeam) for the sake of high seam quality with high efficiency. To overcome the difficulty of the seam description in network and no GroundTruth for training we design a selective consistency loss combining the seam shape constraint and seam quality constraint to supervise the network learning. By the constraint of the selection of consistency loss, we implicitly defined the mask boundaries as seams and transform seam prediction into mask prediction. To our knowledge, the proposed DSeam is the first deep learning based seam prediction method for image stitching. Extensive experimental results well demonstrate the superior performance of our proposed Dseam method which is 15 times faster than the classic GC seam prediction method in OpenCV 2.4.9 with similar seam quality.
Inverse Consistency by Construction for Multistep Deep Registration
Apr 28, 2023
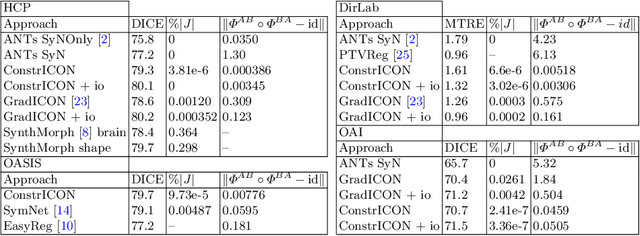
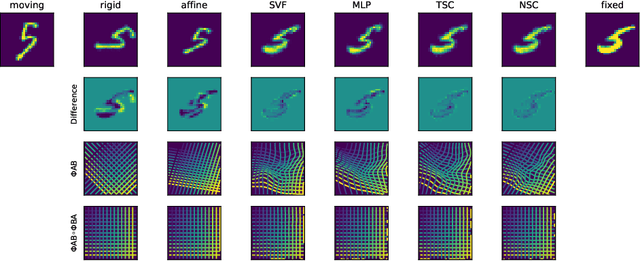
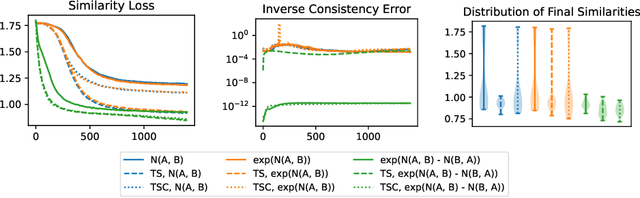
Inverse consistency is a desirable property for image registration. We propose a simple technique to make a neural registration network inverse consistent by construction, as a consequence of its structure, as long as it parameterizes its output transform by a Lie group. We extend this technique to multi-step neural registration by composing many such networks in a way that preserves inverse consistency. This multi-step approach also allows for inverse-consistent coarse to fine registration. We evaluate our technique on synthetic 2-D data and four 3-D medical image registration tasks and obtain excellent registration accuracy while assuring inverse consistency.
Towards a Simple Framework of Skill Transfer Learning for Robotic Ultrasound-guidance Procedures
May 06, 2023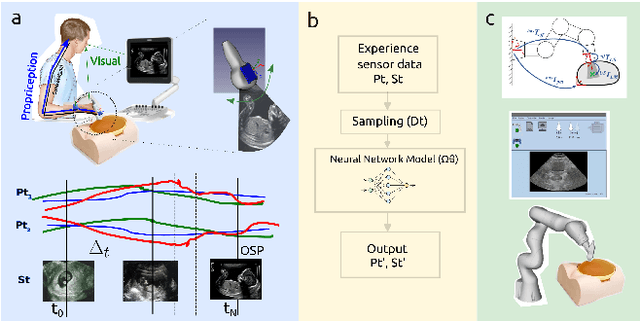
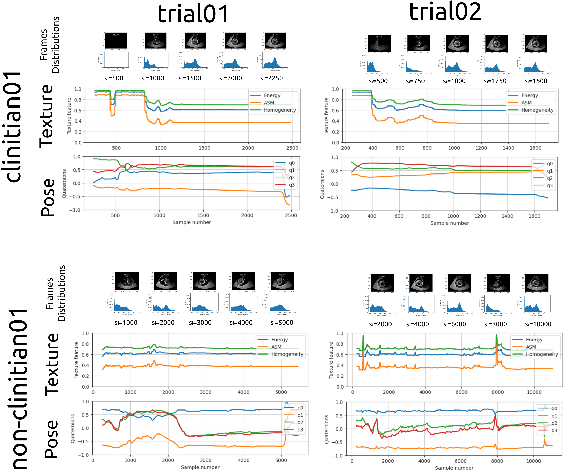
In this paper, we present a simple framework of skill transfer learning for robotic ultrasound-guidance procedures. We briefly review challenges in skill transfer learning for robotic ultrasound-guidance procedures. We then identify the need of appropriate sampling techniques, computationally efficient neural networks models that lead to the proposal of a simple framework of skill transfer learning for real-time applications in robotic ultrasound-guidance procedures. We present pilot experiments from two participants (one experienced clinician and one non-clinician) looking for an optimal scanning plane of the four-chamber cardiac view from a fetal phantom. We analysed ultrasound image frames, time series of texture image features and quaternions and found that the experienced clinician performed the procedure in a quicker and smoother way compared to lengthy and non-constant movements from non-clinicians. For future work, we pointed out the need of pruned and quantised neural network models for real-time applications in robotic ultrasound-guidance procedure. The resources to reproduce this work are available at \url{https://github.com/mxochicale/rami-icra2023}.
Condition-Invariant Semantic Segmentation
May 27, 2023
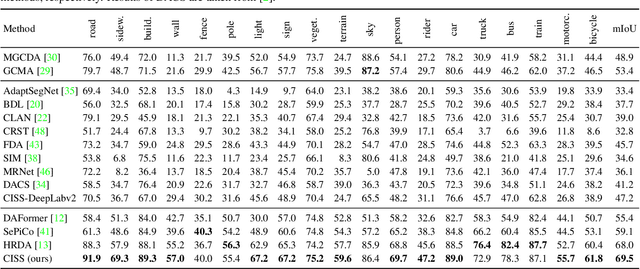
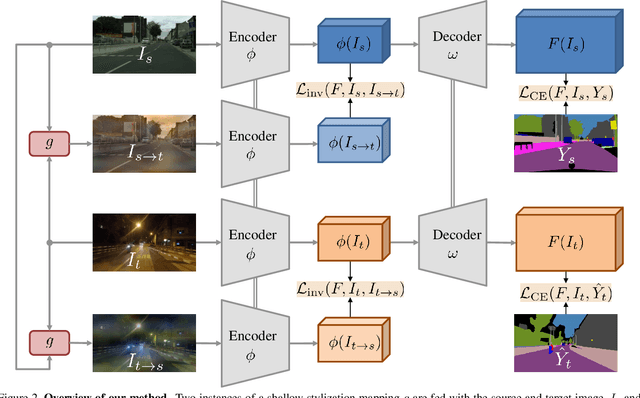
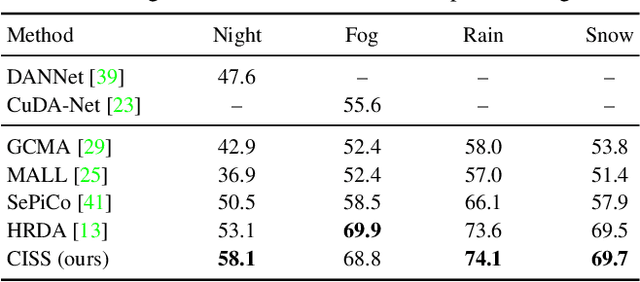
Adaptation of semantic segmentation networks to different visual conditions from those for which ground-truth annotations are available at training is vital for robust perception in autonomous cars and robots. However, previous work has shown that most feature-level adaptation methods, which employ adversarial training and are validated on synthetic-to-real adaptation, provide marginal gains in normal-to-adverse condition-level adaptation, being outperformed by simple pixel-level adaptation via stylization. Motivated by these findings, we propose to leverage stylization in performing feature-level adaptation by aligning the deep features extracted by the encoder of the network from the original and the stylized view of each input image with a novel feature invariance loss. In this way, we encourage the encoder to extract features that are invariant to the style of the input, allowing the decoder to focus on parsing these features and not on further abstracting from the specific style of the input. We implement our method, named Condition-Invariant Semantic Segmentation (CISS), on the top-performing domain adaptation architecture and demonstrate a significant improvement over previous state-of-the-art methods both on Cityscapes$\to$ACDC and Cityscapes$\to$Dark Zurich adaptation. In particular, CISS is ranked first among all published unsupervised domain adaptation methods on the public ACDC leaderboard. Our method is also shown to generalize well to domains unseen during training, outperforming competing domain adaptation approaches on BDD100K-night and Nighttime Driving. Code is publicly available at https://github.com/SysCV/CISS .
Decom--CAM: Tell Me What You See, In Details! Feature-Level Interpretation via Decomposition Class Activation Map
May 27, 2023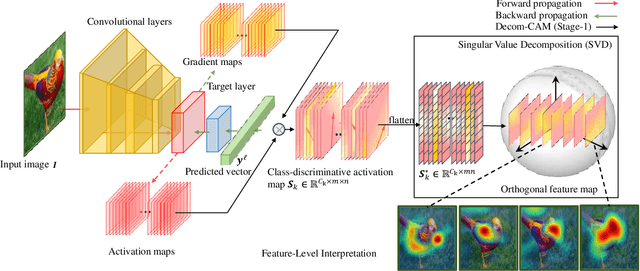

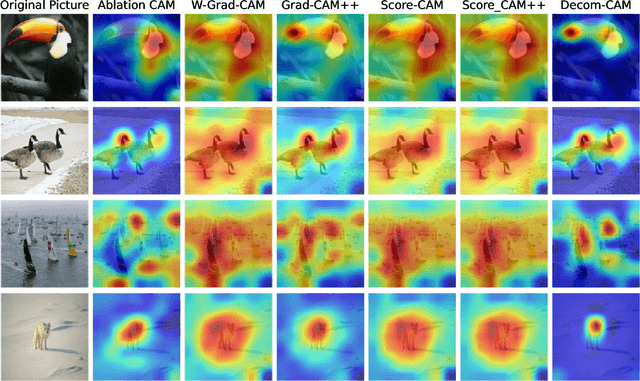
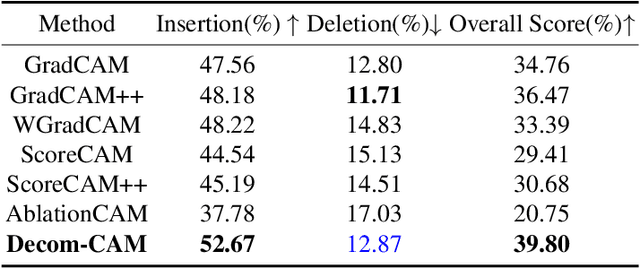
Interpretation of deep learning remains a very challenging problem. Although the Class Activation Map (CAM) is widely used to interpret deep model predictions by highlighting object location, it fails to provide insight into the salient features used by the model to make decisions. Furthermore, existing evaluation protocols often overlook the correlation between interpretability performance and the model's decision quality, which presents a more fundamental issue. This paper proposes a new two-stage interpretability method called the Decomposition Class Activation Map (Decom-CAM), which offers a feature-level interpretation of the model's prediction. Decom-CAM decomposes intermediate activation maps into orthogonal features using singular value decomposition and generates saliency maps by integrating them. The orthogonality of features enables CAM to capture local features and can be used to pinpoint semantic components such as eyes, noses, and faces in the input image, making it more beneficial for deep model interpretation. To ensure a comprehensive comparison, we introduce a new evaluation protocol by dividing the dataset into subsets based on classification accuracy results and evaluating the interpretability performance on each subset separately. Our experiments demonstrate that the proposed Decom-CAM outperforms current state-of-the-art methods significantly by generating more precise saliency maps across all levels of classification accuracy. Combined with our feature-level interpretability approach, this paper could pave the way for a new direction for understanding the decision-making process of deep neural networks.
Knowledge Transfer via Multi-Head Feature Adaptation for Whole Slide Image Classification
Mar 10, 2023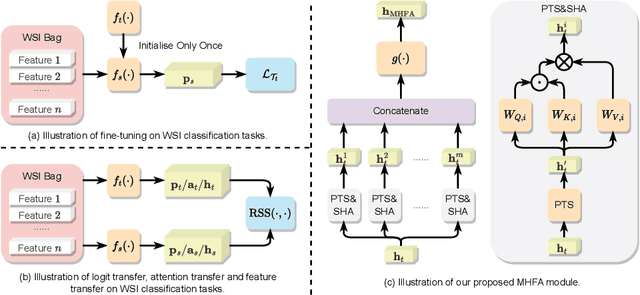
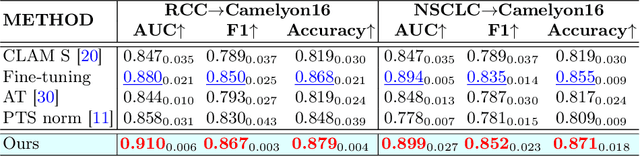
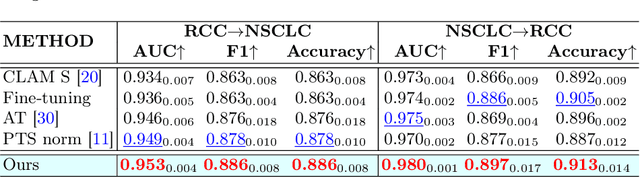
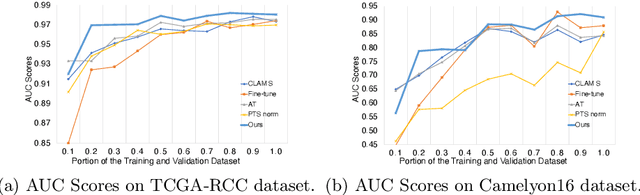
Transferring prior knowledge from a source domain to the same or similar target domain can greatly enhance the performance of models on the target domain. However, it is challenging to directly leverage the knowledge from the source domain due to task discrepancy and domain shift. To bridge the gaps between different tasks and domains, we propose a Multi-Head Feature Adaptation module, which projects features in the source feature space to a new space that is more similar to the target space. Knowledge transfer is particularly important in Whole Slide Image (WSI) classification since the number of WSIs in one dataset might be too small to achieve satisfactory performance. Therefore, WSI classification is an ideal testbed for our method, and we adapt multiple knowledge transfer methods for WSI classification. The experimental results show that models with knowledge transfer outperform models that are trained from scratch by a large margin regardless of the number of WSIs in the datasets, and our method achieves state-of-the-art performances among other knowledge transfer methods on multiple datasets, including TCGA-RCC, TCGA-NSCLC, and Camelyon16 datasets.
CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model
May 23, 2023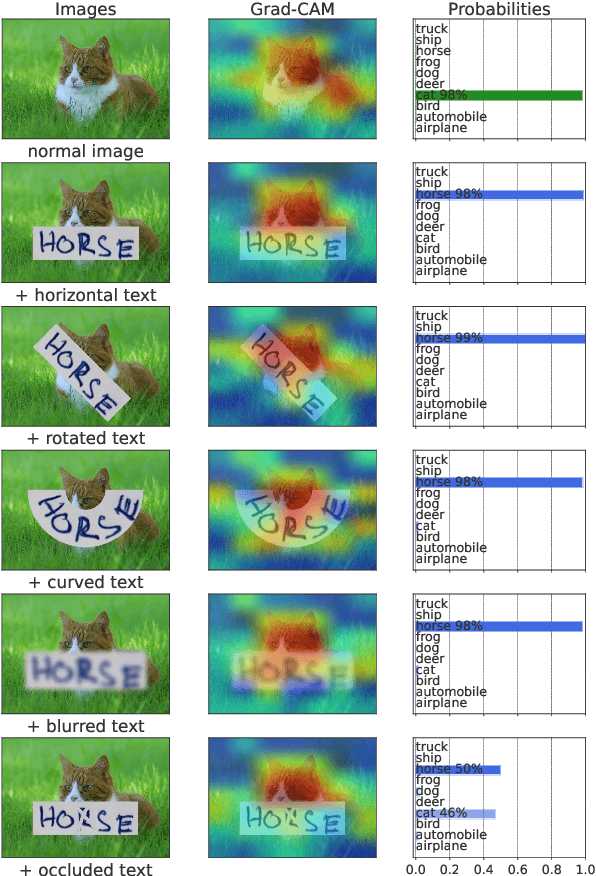
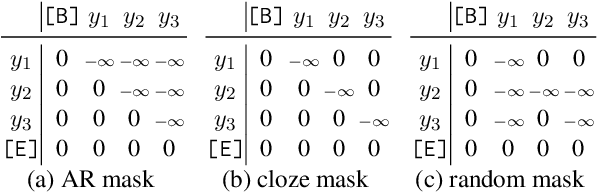
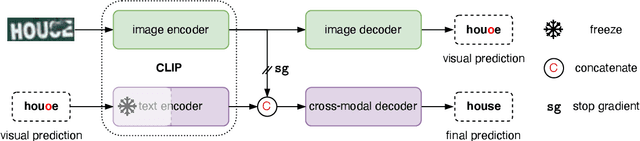
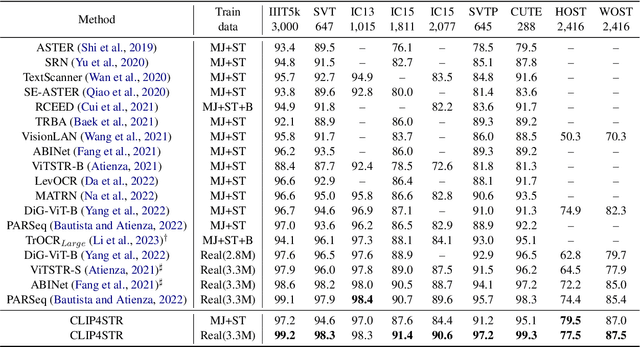
Pre-trained vision-language models are the de-facto foundation models for various downstream tasks. However, this trend has not extended to the field of scene text recognition (STR), despite the potential of CLIP to serve as a powerful scene text reader. CLIP can robustly identify regular (horizontal) and irregular (rotated, curved, blurred, or occluded) text in natural images. With such merits, we introduce CLIP4STR, a simple yet effective STR method built upon image and text encoders of CLIP. It has two encoder-decoder branches: a visual branch and a cross-modal branch. The visual branch provides an initial prediction based on the visual feature, and the cross-modal branch refines this prediction by addressing the discrepancy between the visual feature and text semantics. To fully leverage the capabilities of both branches, we design a dual predict-and-refine decoding scheme for inference. CLIP4STR achieves new state-of-the-art performance on 11 STR benchmarks. Additionally, a comprehensive empirical study is provided to enhance the understanding of the adaptation of CLIP to STR. We believe our method establishes a simple but strong baseline for future STR research with VL models.
ConGraT: Self-Supervised Contrastive Pretraining for Joint Graph and Text Embeddings
May 23, 2023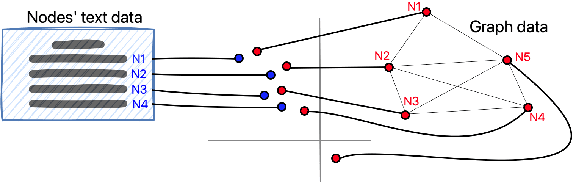
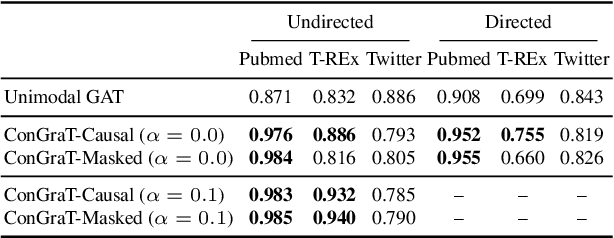
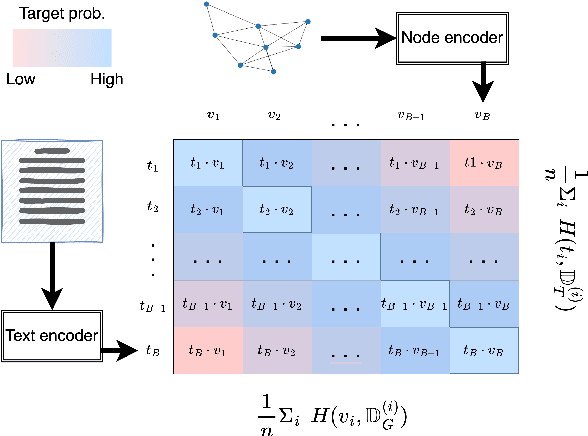
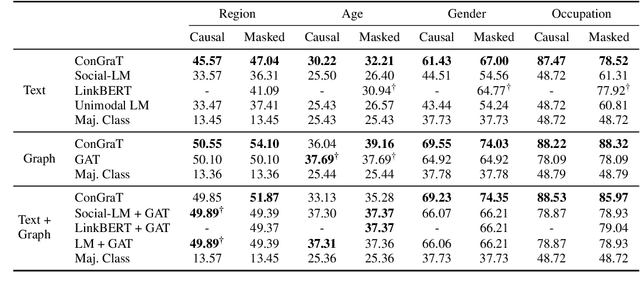
We propose ConGraT(Contrastive Graph-Text pretraining), a general, self-supervised method for jointly learning separate representations of texts and nodes in a parent (or ``supervening'') graph, where each text is associated with one of the nodes. Datasets fitting this paradigm are common, from social media (users and posts), to citation networks over articles, to link graphs over web pages. We expand on prior work by providing a general, self-supervised, joint pretraining method, one which does not depend on particular dataset structure or a specific task. Our method uses two separate encoders for graph nodes and texts, which are trained to align their representations within a common latent space. Training uses a batch-wise contrastive learning objective inspired by prior work on joint text and image encoding. As graphs are more structured objects than images, we also extend the training objective to incorporate information about node similarity and plausible next guesses in matching nodes and texts. Experiments on various datasets reveal that ConGraT outperforms strong baselines on various downstream tasks, including node and text category classification and link prediction. Code and certain datasets are available at https://github.com/wwbrannon/congrat.
REC-MV: REconstructing 3D Dynamic Cloth from Monocular Videos
May 23, 2023

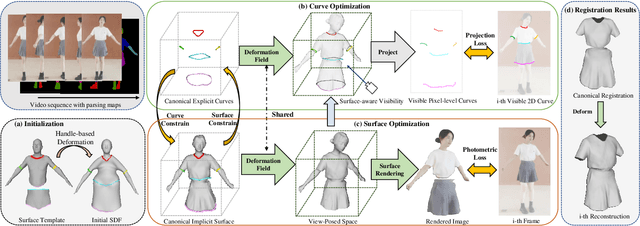
Reconstructing dynamic 3D garment surfaces with open boundaries from monocular videos is an important problem as it provides a practical and low-cost solution for clothes digitization. Recent neural rendering methods achieve high-quality dynamic clothed human reconstruction results from monocular video, but these methods cannot separate the garment surface from the body. Moreover, despite existing garment reconstruction methods based on feature curve representation demonstrating impressive results for garment reconstruction from a single image, they struggle to generate temporally consistent surfaces for the video input. To address the above limitations, in this paper, we formulate this task as an optimization problem of 3D garment feature curves and surface reconstruction from monocular video. We introduce a novel approach, called REC-MV, to jointly optimize the explicit feature curves and the implicit signed distance field (SDF) of the garments. Then the open garment meshes can be extracted via garment template registration in the canonical space. Experiments on multiple casually captured datasets show that our approach outperforms existing methods and can produce high-quality dynamic garment surfaces. The source code is available at https://github.com/GAP-LAB-CUHK-SZ/REC-MV.
Design and Operation of Autonomous Wheelchair Towing Robot
May 23, 2023
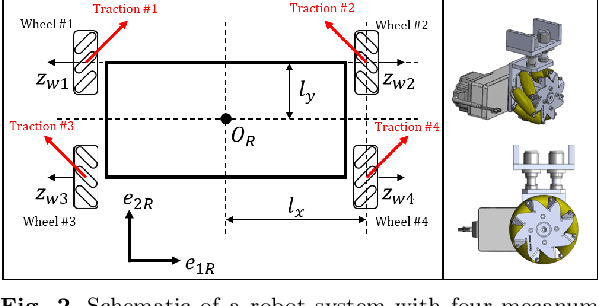
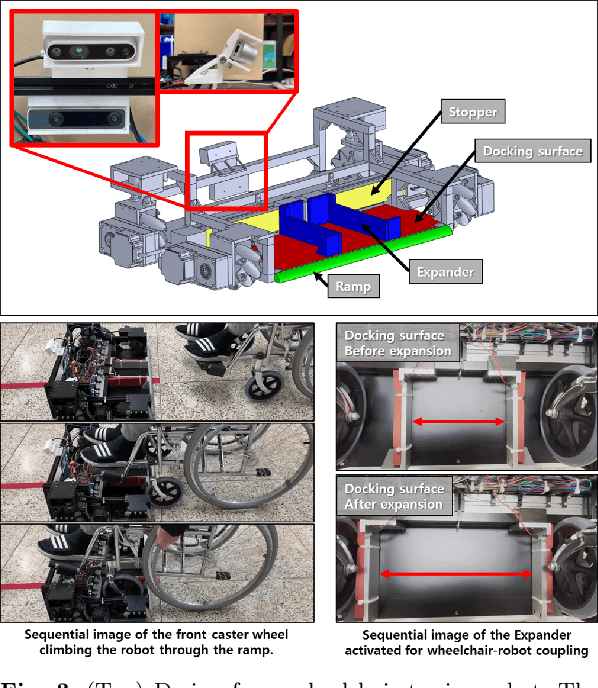
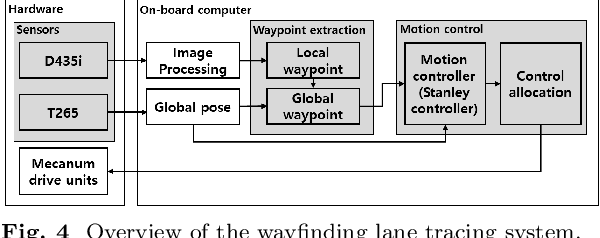
In this study, a new concept of a wheelchair-towing robot for the facile electrification of manual wheelchairs is introduced. The development of this concept includes the design of towing robot hardware and an autonomous driving algorithm to ensure the safe transportation of patients to their intended destinations inside the hospital. We developed a novel docking mechanism to facilitate easy docking and separation between the towing robot and the manual wheelchair, which is connected to the front caster wheel of the manual wheelchair. The towing robot has a mecanum wheel drive, enabling the robot to move with a high degree of freedom in the standalone driving mode while adhering to kinematic constraints in the docking mode. Our novel towing robot features a camera sensor that can observe the ground ahead which allows the robot to autonomously follow color-coded wayfinding lanes installed in hospital corridors. This study introduces dedicated image processing techniques for capturing the lanes and control algorithms for effectively tracing a path to achieve autonomous path following. The autonomous towing performance of our proposed platform was validated by a real-world experiment in which a hospital environment with colored lanes was created.