 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single-Image HDR Reconstruction Assisted Ghost Suppression and Detail Preservation Network for Multi-Exposure HDR Imaging
Mar 07, 2024




The reconstruction of high dynamic range (HDR) images from multi-exposure low dynamic range (LDR) images in dynamic scenes presents significant challenges, especially in preserving and restoring information in oversaturated regions and avoiding ghosting artifacts. While current methods often struggle to address these challenges, our work aims to bridge this gap by developing a multi-exposure HDR image reconstruction network for dynamic scenes, complemented by single-frame HDR image reconstruction. This network, comprising single-frame HDR reconstruction with enhanced stop image (SHDR-ESI) and SHDR-ESI-assisted multi-exposure HDR reconstruction (SHDRA-MHDR), effectively leverages the ghost-free characteristic of single-frame HDR reconstruction and the detail-enhancing capability of ESI in oversaturated areas. Specifically, SHDR-ESI innovatively integrates single-frame HDR reconstruction with the utilization of ESI. This integration not only optimizes the single image HDR reconstruction process but also effectively guides the synthesis of multi-exposure HDR images in SHDR-AMHDR. In this method, the single-frame HDR reconstruction is specifically applied to reduce potential ghosting effects in multiexposure HDR synthesis, while the use of ESI images assists in enhancing the detail information in the HDR synthesis process. Technically, SHDR-ESI incorporates a detail enhancement mechanism, which includes a self-representation module and a mutual-representation module, designed to aggregate crucial information from both reference image and ESI. To fully leverage the complementary information from non-reference images, a feature interaction fusion module is integrated within SHDRA-MHDR. Additionally, a ghost suppression module, guided by the ghost-free results of SHDR-ESI, is employed to suppress the ghosting artifacts.
Raw Instinct: Trust Your Classifiers and Skip the Conversion
Mar 21, 2024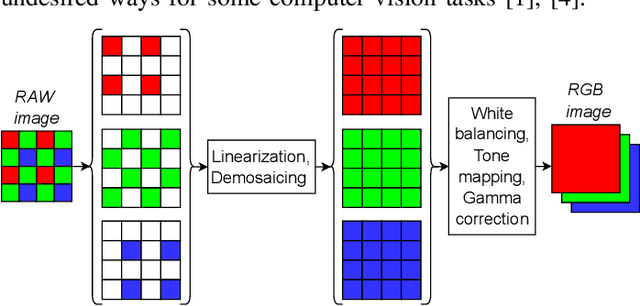
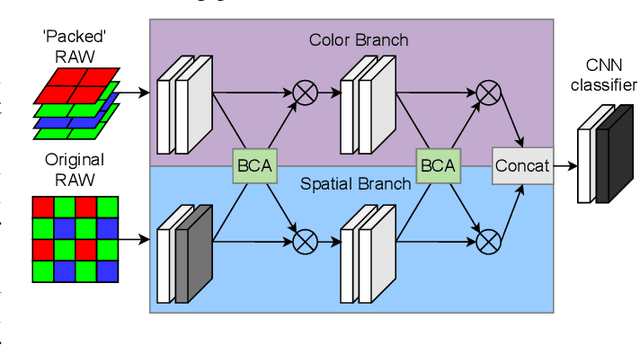

Using RAW-images in computer vision problems is surprisingly underexplored considering that converting from RAW to RGB does not introduce any new capture information. In this paper, we show that a sufficiently advanced classifier can yield equivalent results on RAW input compared to RGB and present a new public dataset consisting of RAW images and the corresponding converted RGB images. Classifying images directly from RAW is attractive, as it allows for skipping the conversion to RGB, lowering computation time significantly. Two CNN classifiers are used to classify the images in both formats, confirming that classification performance can indeed be preserved. We furthermore show that the total computation time from RAW image data to classification results for RAW images can be up to 8.46 times faster than RGB. These results contribute to the evidence found in related works, that using RAW images as direct input to computer vision algorithms looks very promising.
* https://www.kaggle.com/datasets/mathiasviborg/raw-instinct
Visual Preference Inference: An Image Sequence-Based Preference Reasoning in Tabletop Object Manipulation
Mar 18, 2024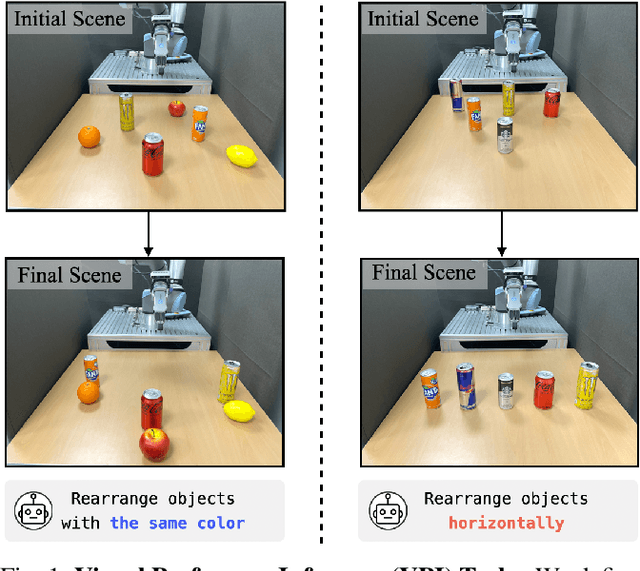
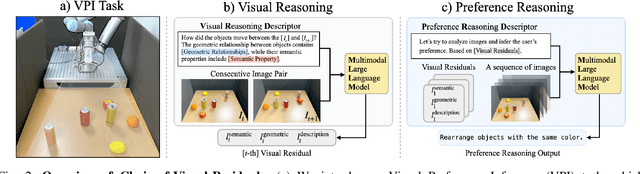
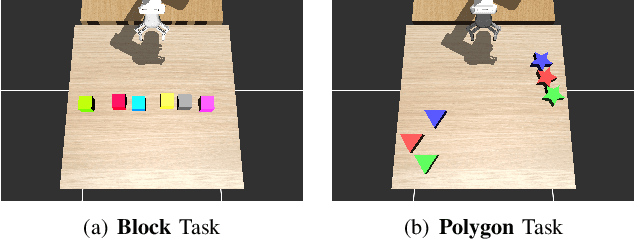

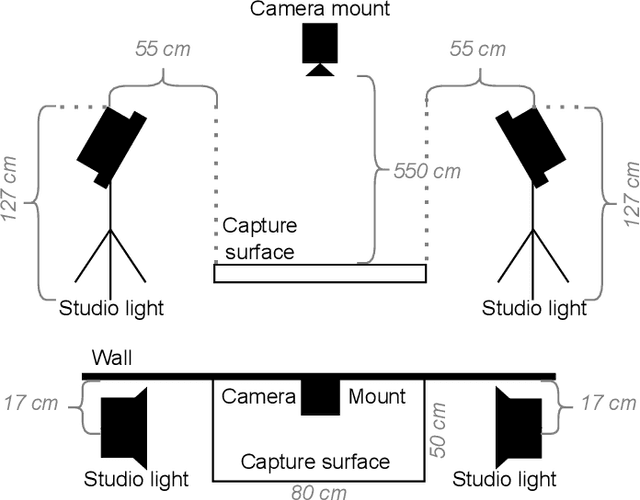
In robotic object manipulation, human preferences can often be influenced by the visual attributes of objects, such as color and shape. These properties play a crucial role in operating a robot to interact with objects and align with human intention. In this paper, we focus on the problem of inferring underlying human preferences from a sequence of raw visual observations in tabletop manipulation environments with a variety of object types, named Visual Preference Inference (VPI). To facilitate visual reasoning in the context of manipulation, we introduce the Chain-of-Visual-Residuals (CoVR) method. CoVR employs a prompting mechanism that describes the difference between the consecutive images (i.e., visual residuals) and incorporates such texts with a sequence of images to infer the user's preference. This approach significantly enhances the ability to understand and adapt to dynamic changes in its visual environment during manipulation tasks. Furthermore, we incorporate such texts along with a sequence of images to infer the user's preferences. Our method outperforms baseline methods in terms of extracting human preferences from visual sequences in both simulation and real-world environments. Code and videos are available at: \href{https://joonhyung-lee.github.io/vpi/}{https://joonhyung-lee.github.io/vpi/}
GeoWizard: Unleashing the Diffusion Priors for 3D Geometry Estimation from a Single Image
Mar 18, 2024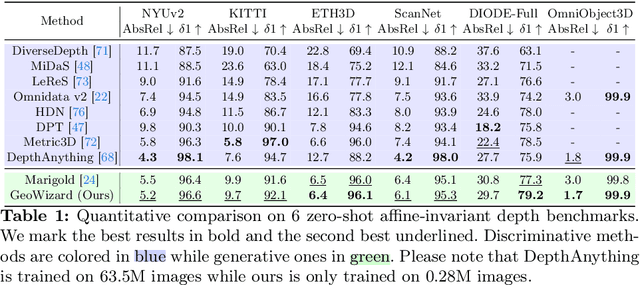
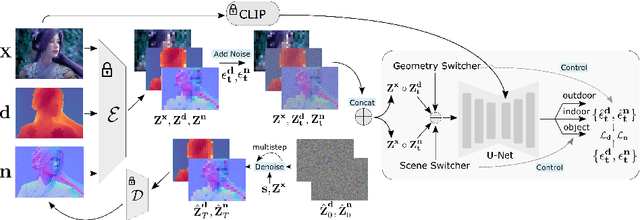

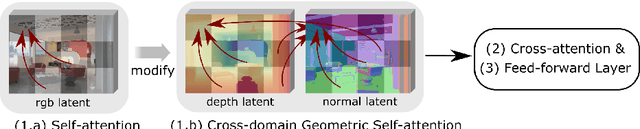
We introduce GeoWizard, a new generative foundation model designed for estimating geometric attributes, e.g., depth and normals, from single images. While significant research has already been conducted in this area, the progress has been substantially limited by the low diversity and poor quality of publicly available datasets. As a result, the prior works either are constrained to limited scenarios or suffer from the inability to capture geometric details. In this paper, we demonstrate that generative models, as opposed to traditional discriminative models (e.g., CNNs and Transformers), can effectively address the inherently ill-posed problem. We further show that leveraging diffusion priors can markedly improve generalization, detail preservation, and efficiency in resource usage. Specifically, we extend the original stable diffusion model to jointly predict depth and normal, allowing mutual information exchange and high consistency between the two representations. More importantly, we propose a simple yet effective strategy to segregate the complex data distribution of various scenes into distinct sub-distributions. This strategy enables our model to recognize different scene layouts, capturing 3D geometry with remarkable fidelity. GeoWizard sets new benchmarks for zero-shot depth and normal prediction, significantly enhancing many downstream applications such as 3D reconstruction, 2D content creation, and novel viewpoint synthesis.
InterFusion: Text-Driven Generation of 3D Human-Object Interaction
Mar 22, 2024In this study, we tackle the complex task of generating 3D human-object interactions (HOI) from textual descriptions in a zero-shot text-to-3D manner. We identify and address two key challenges: the unsatisfactory outcomes of direct text-to-3D methods in HOI, largely due to the lack of paired text-interaction data, and the inherent difficulties in simultaneously generating multiple concepts with complex spatial relationships. To effectively address these issues, we present InterFusion, a two-stage framework specifically designed for HOI generation. InterFusion involves human pose estimations derived from text as geometric priors, which simplifies the text-to-3D conversion process and introduces additional constraints for accurate object generation. At the first stage, InterFusion extracts 3D human poses from a synthesized image dataset depicting a wide range of interactions, subsequently mapping these poses to interaction descriptions. The second stage of InterFusion capitalizes on the latest developments in text-to-3D generation, enabling the production of realistic and high-quality 3D HOI scenes. This is achieved through a local-global optimization process, where the generation of human body and object is optimized separately, and jointly refined with a global optimization of the entire scene, ensuring a seamless and contextually coherent integration. Our experimental results affirm that InterFusion significantly outperforms existing state-of-the-art methods in 3D HOI generation.
WSCLoc: Weakly-Supervised Sparse-View Camera Relocalization
Mar 22, 2024Despite the advancements in deep learning for camera relocalization tasks, obtaining ground truth pose labels required for the training process remains a costly endeavor. While current weakly supervised methods excel in lightweight label generation, their performance notably declines in scenarios with sparse views. In response to this challenge, we introduce WSCLoc, a system capable of being customized to various deep learning-based relocalization models to enhance their performance under weakly-supervised and sparse view conditions. This is realized with two stages. In the initial stage, WSCLoc employs a multilayer perceptron-based structure called WFT-NeRF to co-optimize image reconstruction quality and initial pose information. To ensure a stable learning process, we incorporate temporal information as input. Furthermore, instead of optimizing SE(3), we opt for $\mathfrak{sim}(3)$ optimization to explicitly enforce a scale constraint. In the second stage, we co-optimize the pre-trained WFT-NeRF and WFT-Pose. This optimization is enhanced by Time-Encoding based Random View Synthesis and supervised by inter-frame geometric constraints that consider pose, depth, and RGB information. We validate our approaches on two publicly available datasets, one outdoor and one indoor. Our experimental results demonstrate that our weakly-supervised relocalization solutions achieve superior pose estimation accuracy in sparse-view scenarios, comparable to state-of-the-art camera relocalization methods. We will make our code publicly available.
Brain-grounding of semantic vectors improves neural decoding of visual stimuli
Mar 22, 2024Developing algorithms for accurate and comprehensive neural decoding of mental contents is one of the long-cherished goals in the field of neuroscience and brain-machine interfaces. Previous studies have demonstrated the feasibility of neural decoding by training machine learning models to map brain activity patterns into a semantic vector representation of stimuli. These vectors, hereafter referred as pretrained feature vectors, are usually derived from semantic spaces based solely on image and/or text features and therefore they might have a totally different characteristics than how visual stimuli is represented in the human brain, resulting in limiting the capability of brain decoders to learn this mapping. To address this issue, we propose a representation learning framework, termed brain-grounding of semantic vectors, which fine-tunes pretrained feature vectors to better align with the neural representation of visual stimuli in the human brain. We trained this model this model with functional magnetic resonance imaging (fMRI) of 150 different visual stimuli categories, and then performed zero-shot brain decoding and identification analyses on 1) fMRI and 2) magnetoencephalography (MEG). Interestingly, we observed that by using the brain-grounded vectors, the brain decoding and identification accuracy on brain data from different neuroimaging modalities increases. These findings underscore the potential of incorporating a richer array of brain-derived features to enhance performance of brain decoding algorithms.
S2DM: Sector-Shaped Diffusion Models for Video Generation
Mar 22, 2024
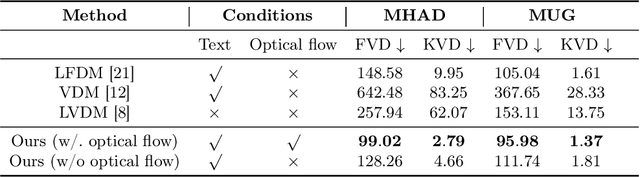
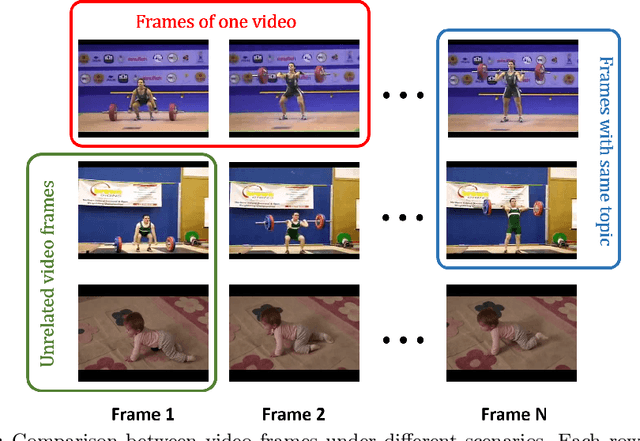

Diffusion models have achieved great success in image generation. However, when leveraging this idea for video generation, we face significant challenges in maintaining the consistency and continuity across video frames. This is mainly caused by the lack of an effective framework to align frames of videos with desired temporal features while preserving consistent semantic and stochastic features. In this work, we propose a novel Sector-Shaped Diffusion Model (S2DM) whose sector-shaped diffusion region is formed by a set of ray-shaped reverse diffusion processes starting at the same noise point. S2DM can generate a group of intrinsically related data sharing the same semantic and stochastic features while varying on temporal features with appropriate guided conditions. We apply S2DM to video generation tasks, and explore the use of optical flow as temporal conditions. Our experimental results show that S2DM outperforms many existing methods in the task of video generation without any temporal-feature modelling modules. For text-to-video generation tasks where temporal conditions are not explicitly given, we propose a two-stage generation strategy which can decouple the generation of temporal features from semantic-content features. We show that, without additional training, our model integrated with another temporal conditions generative model can still achieve comparable performance with existing works. Our results can be viewd at https://s2dm.github.io/S2DM/.
Towards Controllable Face Generation with Semantic Latent Diffusion Models
Mar 19, 2024
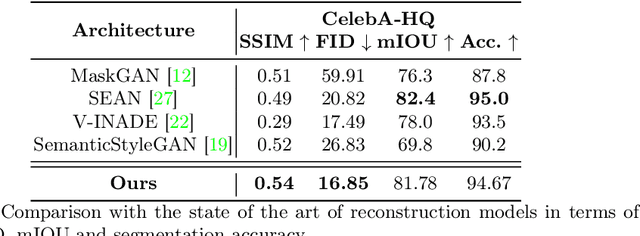
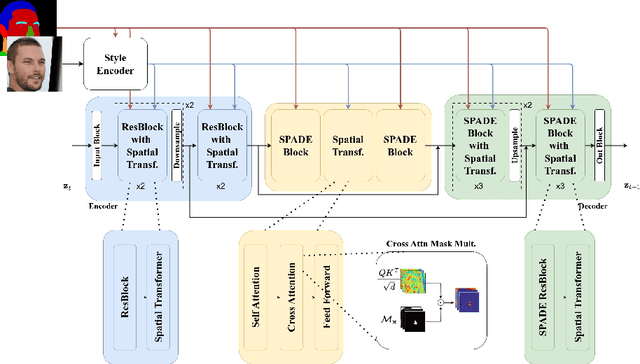

Semantic Image Synthesis (SIS) is among the most popular and effective techniques in the field of face generation and editing, thanks to its good generation quality and the versatility is brings along. Recent works attempted to go beyond the standard GAN-based framework, and started to explore Diffusion Models (DMs) for this task as these stand out with respect to GANs in terms of both quality and diversity. On the other hand, DMs lack in fine-grained controllability and reproducibility. To address that, in this paper we propose a SIS framework based on a novel Latent Diffusion Model architecture for human face generation and editing that is both able to reproduce and manipulate a real reference image and generate diversity-driven results. The proposed system utilizes both SPADE normalization and cross-attention layers to merge shape and style information and, by doing so, allows for a precise control over each of the semantic parts of the human face. This was not possible with previous methods in the state of the art. Finally, we performed an extensive set of experiments to prove that our model surpasses current state of the art, both qualitatively and quantitatively.
Zippo: Zipping Color and Transparency Distributions into a Single Diffusion Model
Mar 19, 2024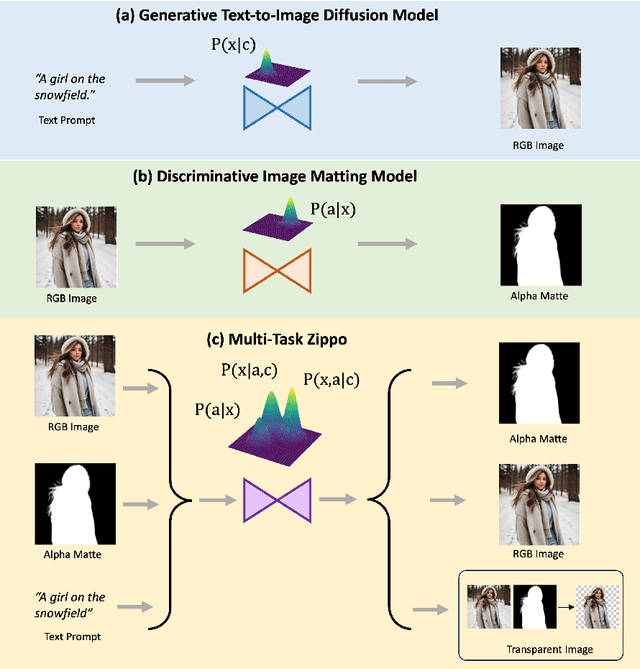

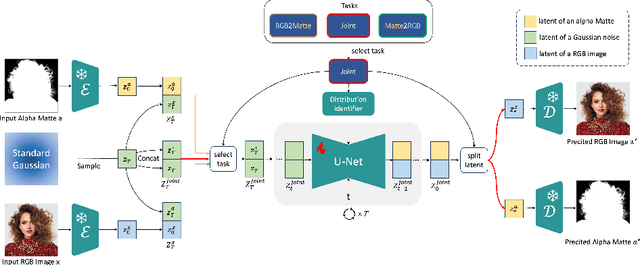
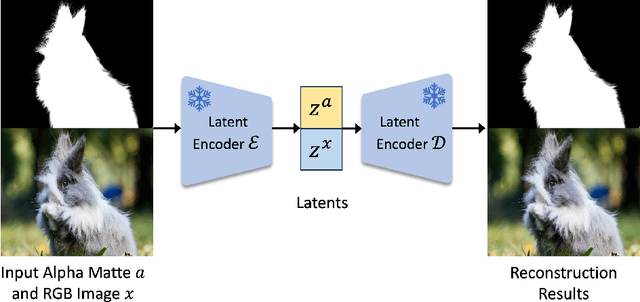
Beyond the superiority of the text-to-image diffusion model in generating high-quality images, recent studies have attempted to uncover its potential for adapting the learned semantic knowledge to visual perception tasks. In this work, instead of translating a generative diffusion model into a visual perception model, we explore to retain the generative ability with the perceptive adaptation. To accomplish this, we present Zippo, a unified framework for zipping the color and transparency distributions into a single diffusion model by expanding the diffusion latent into a joint representation of RGB images and alpha mattes. By alternatively selecting one modality as the condition and then applying the diffusion process to the counterpart modality, Zippo is capable of generating RGB images from alpha mattes and predicting transparency from input images. In addition to single-modality prediction, we propose a modality-aware noise reassignment strategy to further empower Zippo with jointly generating RGB images and its corresponding alpha mattes under the text guidance. Our experiments showcase Zippo's ability of efficient text-conditioned transparent image generation and present plausible results of Matte-to-RGB and RGB-to-Matte translation.