 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CMSG Cross-Media Semantic-Graph Feature Matching Algorithm for Autonomous Vehicle Relocalization
May 15, 2023
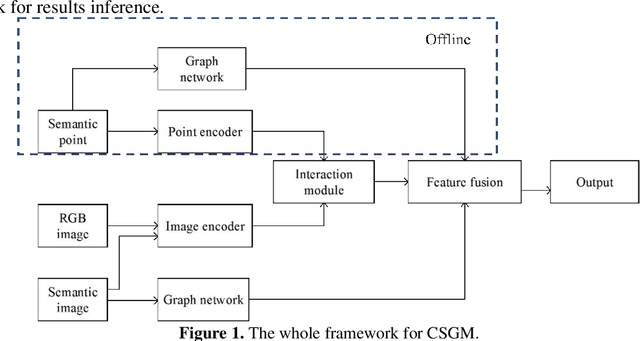
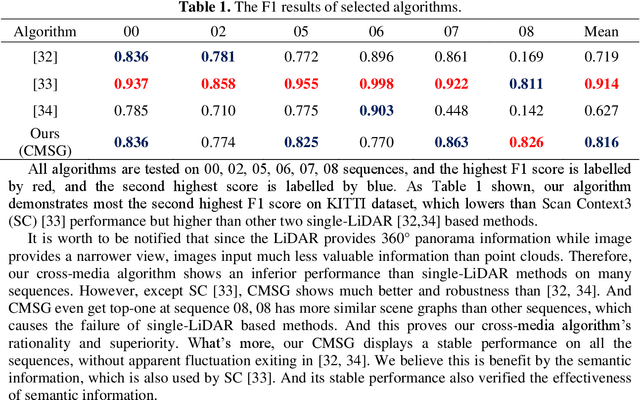
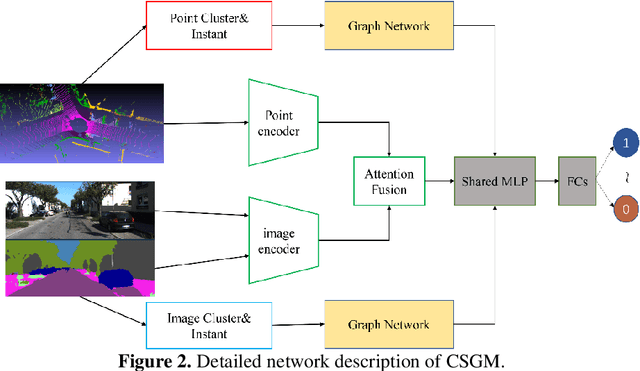

Relocalization is the basis of map-based localization algorithms. Camera and LiDAR map-based methods are pervasive since their robustness under different scenarios. Generally, mapping and localization using the same sensor have better accuracy since matching features between the same type of data is easier. However, due to the camera's lack of 3D information and the high cost of LiDAR, cross-media methods are developing, which combined live image data and Lidar map. Although matching features between different media is challenging, we believe cross-media is the tendency for AV relocalization since its low cost and accuracy can be comparable to the same-sensor-based methods. In this paper, we propose CMSG, a novel cross-media algorithm for AV relocalization tasks. Semantic features are utilized for better interpretation the correlation between point clouds and image features. What's more, abstracted semantic graph nodes are introduced, and a graph network architecture is integrated to better extract the similarity of semantic features. Validation experiments are conducted on the KITTI odometry dataset. Our results show that CMSG can have comparable or even better accuracy compared to current single-sensor-based methods at a speed of 25 FPS on NVIDIA 1080 Ti GPU.
When SAM Meets Shadow Detection
May 19, 2023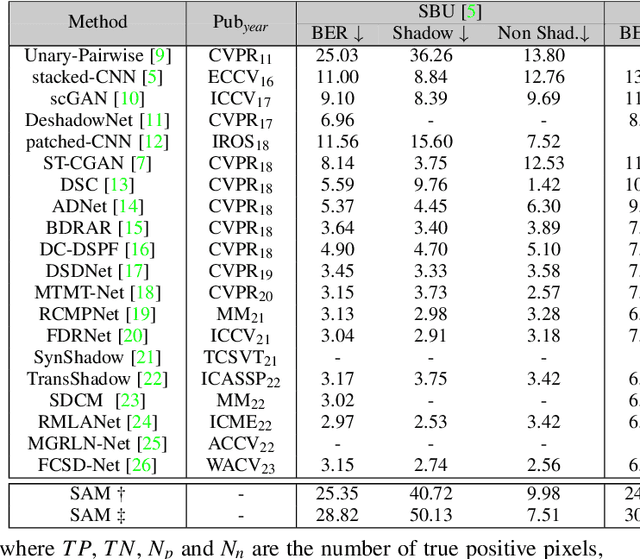

As a promptable generic object segmentation model, segment anything model (SAM) has recently attracted significant attention, and also demonstrates its powerful performance. Nevertheless, it still meets its Waterloo when encountering several tasks, e.g., medical image segmentation, camouflaged object detection, etc. In this report, we try SAM on an unexplored popular task: shadow detection. Specifically, four benchmarks were chosen and evaluated with widely used metrics. The experimental results show that the performance for shadow detection using SAM is not satisfactory, especially when comparing with the elaborate models. Code is available at https://github.com/LeipingJie/SAMSh.
Human Attention-Guided Explainable Artificial Intelligence for Computer Vision Models
May 05, 2023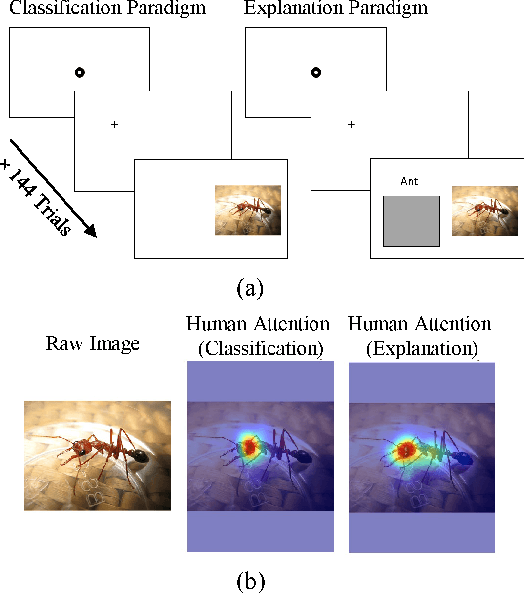
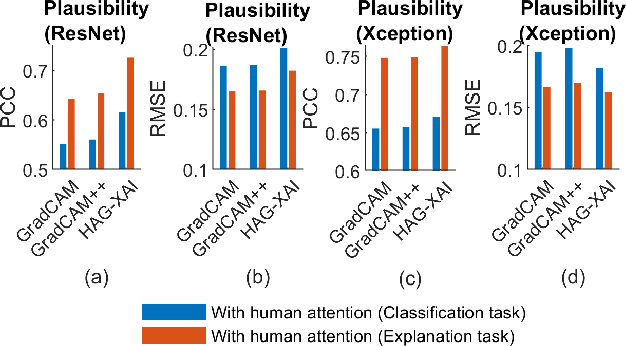
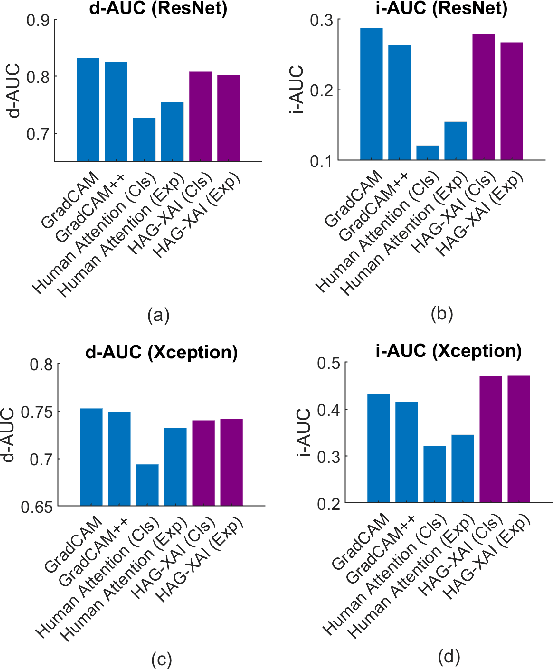
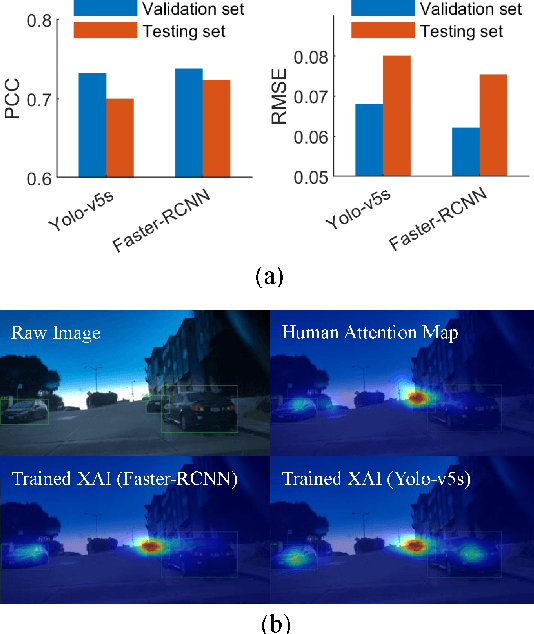
We examined whether embedding human attention knowledge into saliency-based explainable AI (XAI) methods for computer vision models could enhance their plausibility and faithfulness. We first developed new gradient-based XAI methods for object detection models to generate object-specific explanations by extending the current methods for image classification models. Interestingly, while these gradient-based methods worked well for explaining image classification models, when being used for explaining object detection models, the resulting saliency maps generally had lower faithfulness than human attention maps when performing the same task. We then developed Human Attention-Guided XAI (HAG-XAI) to learn from human attention how to best combine explanatory information from the models to enhance explanation plausibility by using trainable activation functions and smoothing kernels to maximize XAI saliency map's similarity to human attention maps. While for image classification models, HAG-XAI enhanced explanation plausibility at the expense of faithfulness, for object detection models it enhanced plausibility and faithfulness simultaneously and outperformed existing methods. The learned functions were model-specific, well generalizable to other databases.
Semantic Segmentation using Vision Transformers: A survey
May 05, 2023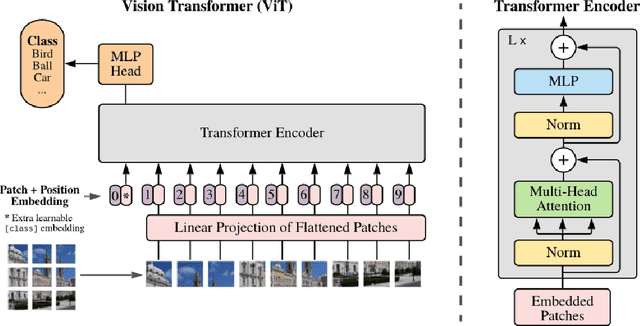
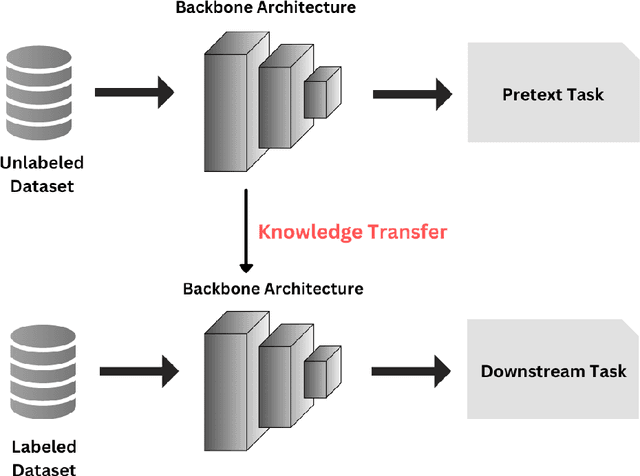
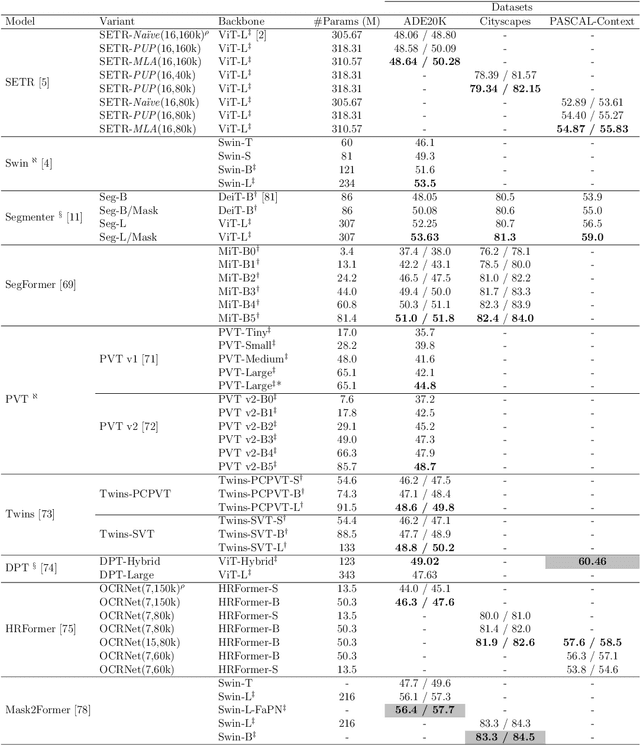
Semantic segmentation has a broad range of applications in a variety of domains including land coverage analysis, autonomous driving, and medical image analysis. Convolutional neural networks (CNN) and Vision Transformers (ViTs) provide the architecture models for semantic segmentation. Even though ViTs have proven success in image classification, they cannot be directly applied to dense prediction tasks such as image segmentation and object detection since ViT is not a general purpose backbone due to its patch partitioning scheme. In this survey, we discuss some of the different ViT architectures that can be used for semantic segmentation and how their evolution managed the above-stated challenge. The rise of ViT and its performance with a high success rate motivated the community to slowly replace the traditional convolutional neural networks in various computer vision tasks. This survey aims to review and compare the performances of ViT architectures designed for semantic segmentation using benchmarking datasets. This will be worthwhile for the community to yield knowledge regarding the implementations carried out in semantic segmentation and to discover more efficient methodologies using ViTs.
Deep Multiple Instance Learning with Distance-Aware Self-Attention
May 20, 2023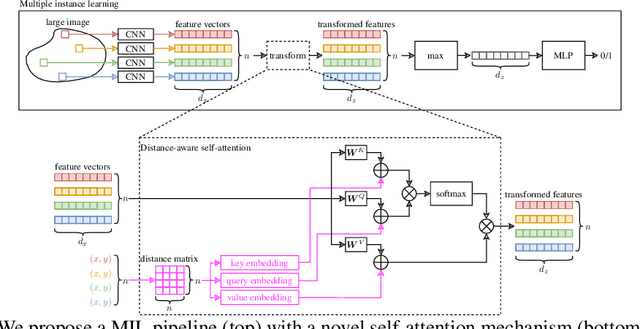
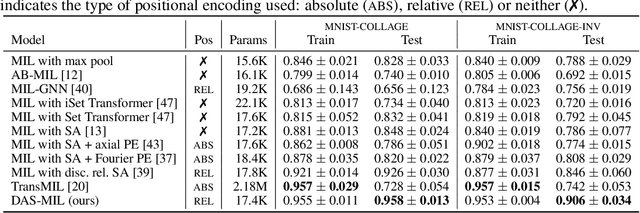

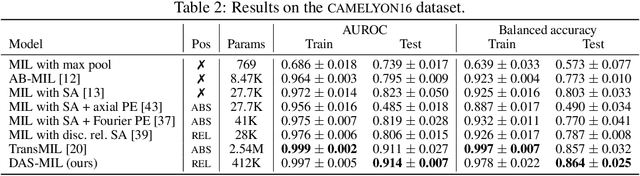
Traditional supervised learning tasks require a label for every instance in the training set, but in many real-world applications, labels are only available for collections (bags) of instances. This problem setting, known as multiple instance learning (MIL), is particularly relevant in the medical domain, where high-resolution images are split into smaller patches, but labels apply to the image as a whole. Recent MIL models are able to capture correspondences between patches by employing self-attention, allowing them to weigh each patch differently based on all other patches in the bag. However, these approaches still do not consider the relative spatial relationships between patches within the larger image, which is especially important in computational pathology. To this end, we introduce a novel MIL model with distance-aware self-attention (DAS-MIL), which explicitly takes into account relative spatial information when modelling the interactions between patches. Unlike existing relative position representations for self-attention which are discrete, our approach introduces continuous distance-dependent terms into the computation of the attention weights, and is the first to apply relative position representations in the context of MIL. We evaluate our model on a custom MNIST-based MIL dataset that requires the consideration of relative spatial information, as well as on CAMELYON16, a publicly available cancer metastasis detection dataset, where we achieve a test AUROC score of 0.91. On both datasets, our model outperforms existing MIL approaches that employ absolute positional encodings, as well as existing relative position representation schemes applied to MIL. Our code is available at https://anonymous.4open.science/r/das-mil.
Coil Sketching for computationally-efficient MR iterative reconstruction
May 10, 2023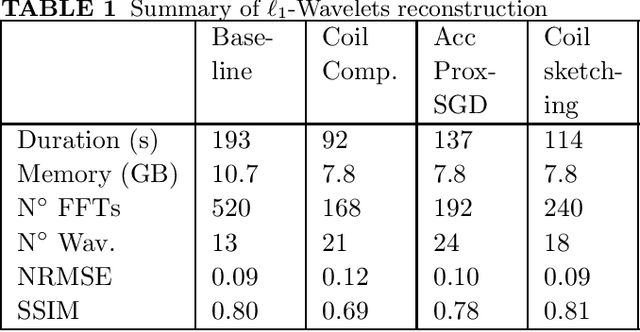
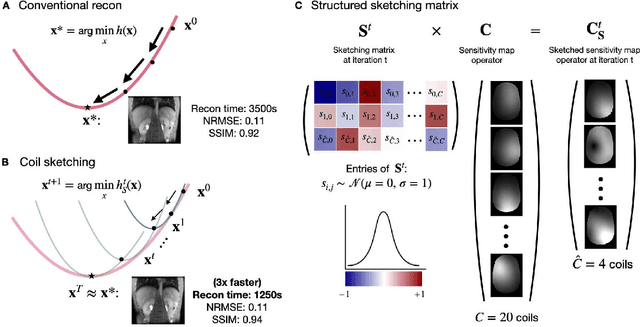
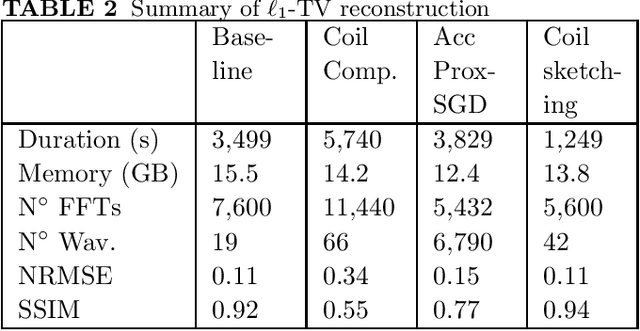
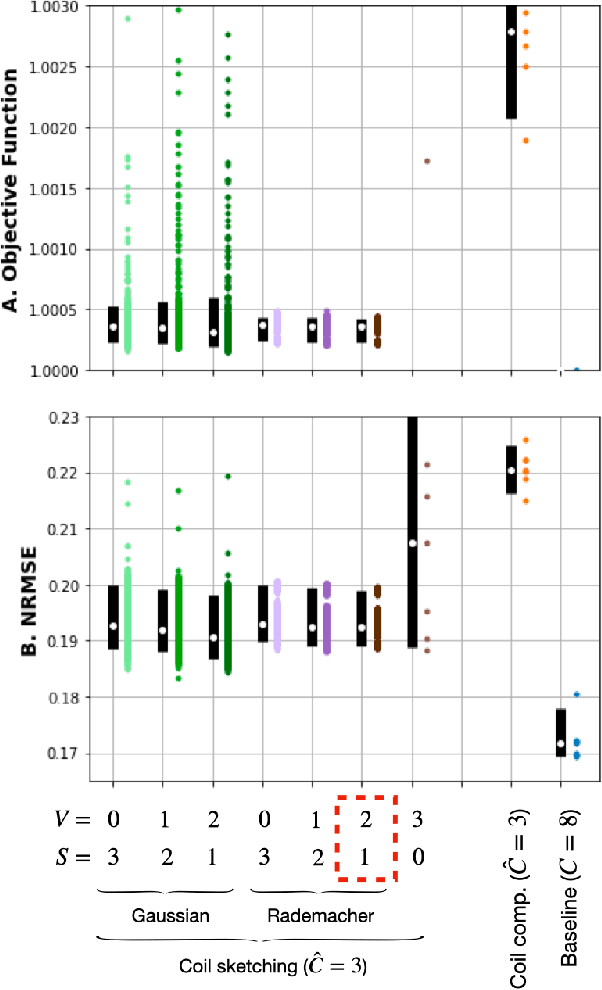
Purpose: Parallel imaging and compressed sensing reconstructions of large MRI datasets often have a prohibitive computational cost that bottlenecks clinical deployment, especially for 3D non-Cartesian acquisitions. One common approach is to reduce the number of coil channels actively used during reconstruction as in coil compression. While effective for Cartesian imaging, coil compression inherently loses signal energy, producing shading artifacts that compromise image quality for 3D non-Cartesian imaging. We propose coil sketching, a general and versatile method for computationally-efficient iterative MR image reconstruction. Theory and Methods: We based our method on randomized sketching algorithms, a type of large-scale optimization algorithms well established in the fields of machine learning and big data analysis. We adapt the sketching theory to the MRI reconstruction problem via a structured sketching matrix that, similar to coil compression, reduces the number of coils concurrently used during reconstruction, but unlike coil compression, is able to leverage energy from all coils. Results: First, we performed ablation experiments to validate the sketching matrix design on both Cartesian and non-Cartesian datasets. The resulting design yielded both improved computational efficiency and preserved signal-to-noise ratio (SNR) as measured by the inverse g-factor. Then, we verified the efficacy of our approach on high-dimensional non-Cartesian 3D cones datasets, where coil sketching yielded up to three-fold faster reconstructions with equivalent image quality. Conclusion: Coil sketching is a general and versatile reconstruction framework for computationally fast and memory-efficient reconstruction.
MPCHAT: Towards Multimodal Persona-Grounded Conversation
May 27, 2023
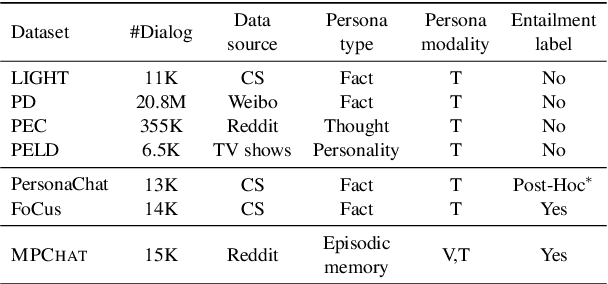
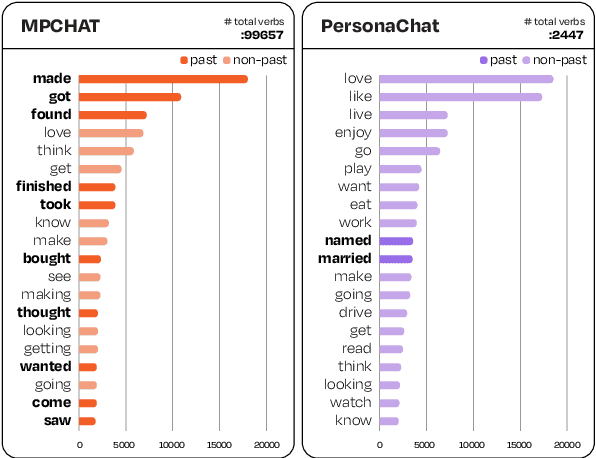
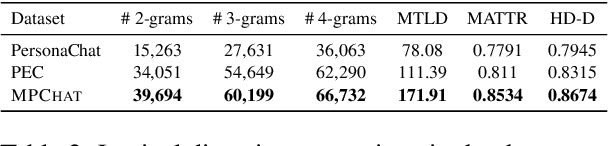
In order to build self-consistent personalized dialogue agents, previous research has mostly focused on textual persona that delivers personal facts or personalities. However, to fully describe the multi-faceted nature of persona, image modality can help better reveal the speaker's personal characteristics and experiences in episodic memory (Rubin et al., 2003; Conway, 2009). In this work, we extend persona-based dialogue to the multimodal domain and make two main contributions. First, we present the first multimodal persona-based dialogue dataset named MPCHAT, which extends persona with both text and images to contain episodic memories. Second, we empirically show that incorporating multimodal persona, as measured by three proposed multimodal persona-grounded dialogue tasks (i.e., next response prediction, grounding persona prediction, and speaker identification), leads to statistically significant performance improvements across all tasks. Thus, our work highlights that multimodal persona is crucial for improving multimodal dialogue comprehension, and our MPCHAT serves as a high-quality resource for this research.
Benchmarking Diverse-Modal Entity Linking with Generative Models
May 27, 2023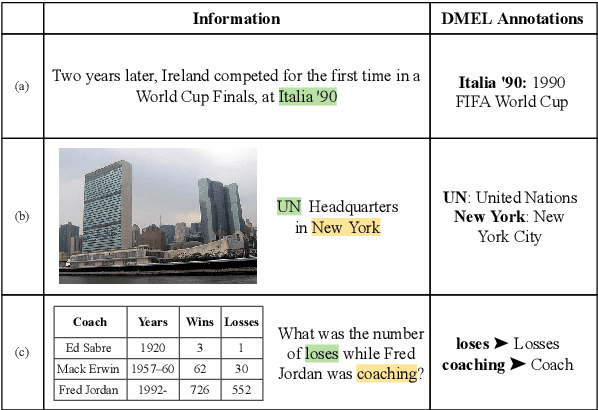
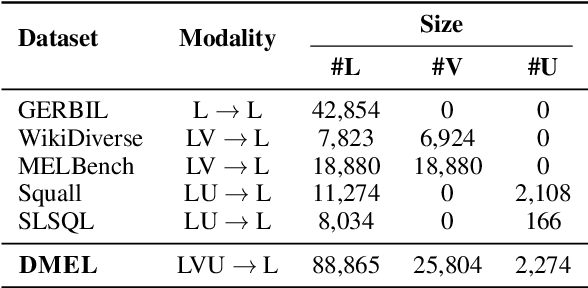
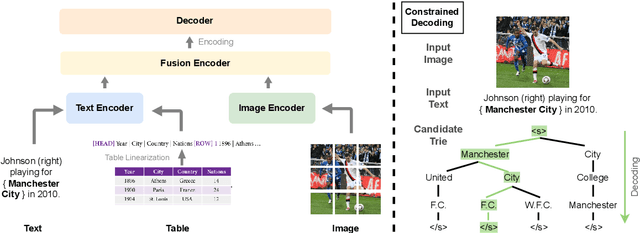
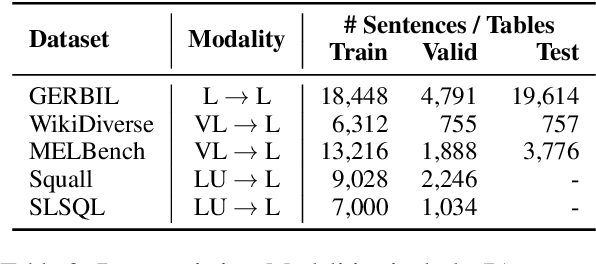
Entities can be expressed in diverse formats, such as texts, images, or column names and cell values in tables. While existing entity linking (EL) models work well on per modality configuration, such as text-only EL, visual grounding, or schema linking, it is more challenging to design a unified model for diverse modality configurations. To bring various modality configurations together, we constructed a benchmark for diverse-modal EL (DMEL) from existing EL datasets, covering all three modalities including text, image, and table. To approach the DMEL task, we proposed a generative diverse-modal model (GDMM) following a multimodal-encoder-decoder paradigm. Pre-training \Model with rich corpora builds a solid foundation for DMEL without storing the entire KB for inference. Fine-tuning GDMM builds a stronger DMEL baseline, outperforming state-of-the-art task-specific EL models by 8.51 F1 score on average. Additionally, extensive error analyses are conducted to highlight the challenges of DMEL, facilitating future research on this task.
Generative Steganographic Flow
May 10, 2023

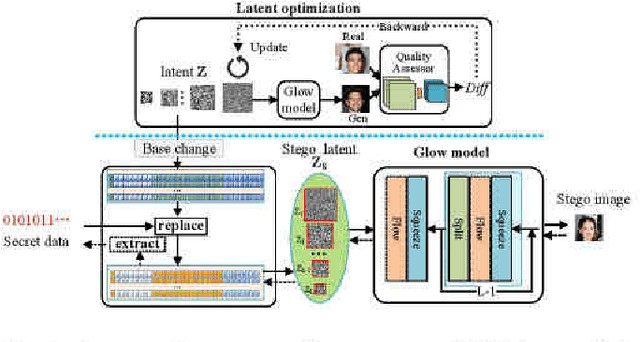

Generative steganography (GS) is a new data hiding manner, featuring direct generation of stego media from secret data. Existing GS methods are generally criticized for their poor performances. In this paper, we propose a novel flow based GS approach -- Generative Steganographic Flow (GSF), which provides direct generation of stego images without cover image. We take the stego image generation and secret data recovery process as an invertible transformation, and build a reversible bijective mapping between input secret data and generated stego images. In the forward mapping, secret data is hidden in the input latent of Glow model to generate stego images. By reversing the mapping, hidden data can be extracted exactly from generated stego images. Furthermore, we propose a novel latent optimization strategy to improve the fidelity of stego images. Experimental results show our proposed GSF has far better performances than SOTA works.
CIFAKE: Image Classification and Explainable Identification of AI-Generated Synthetic Images
Mar 24, 2023

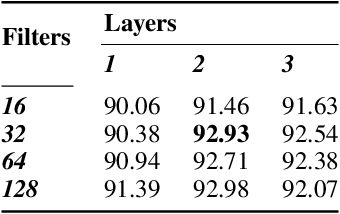
Recent technological advances in synthetic data have enabled the generation of images with such high quality that human beings cannot tell the difference between real-life photographs and Artificial Intelligence (AI) generated images. Given the critical necessity of data reliability and authentication, this article proposes to enhance our ability to recognise AI-generated images through computer vision. Initially, a synthetic dataset is generated that mirrors the ten classes of the already available CIFAR-10 dataset with latent diffusion which provides a contrasting set of images for comparison to real photographs. The model is capable of generating complex visual attributes, such as photorealistic reflections in water. The two sets of data present as a binary classification problem with regard to whether the photograph is real or generated by AI. This study then proposes the use of a Convolutional Neural Network (CNN) to classify the images into two categories; Real or Fake. Following hyperparameter tuning and the training of 36 individual network topologies, the optimal approach could correctly classify the images with 92.98% accuracy. Finally, this study implements explainable AI via Gradient Class Activation Mapping to explore which features within the images are useful for classification. Interpretation reveals interesting concepts within the image, in particular, noting that the actual entity itself does not hold useful information for classification; instead, the model focuses on small visual imperfections in the background of the images. The complete dataset engineered for this study, referred to as the CIFAKE dataset, is made publicly available to the research community for future work.