 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continual Learning with Strong Experience Replay
May 23, 2023
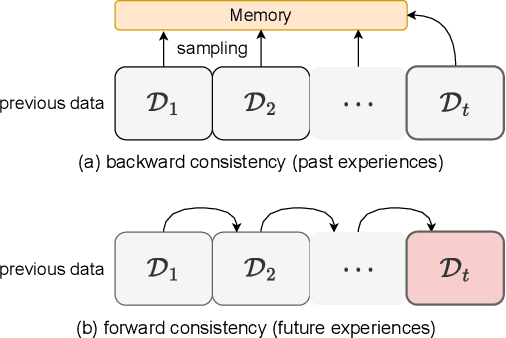
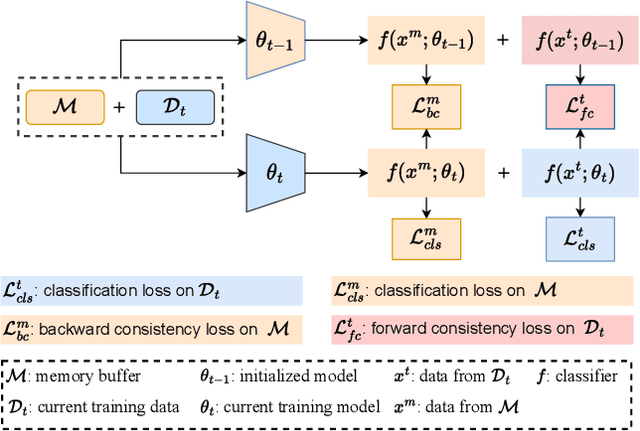
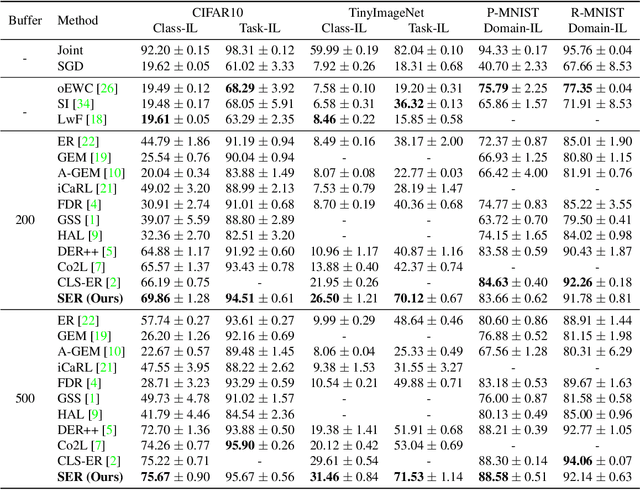
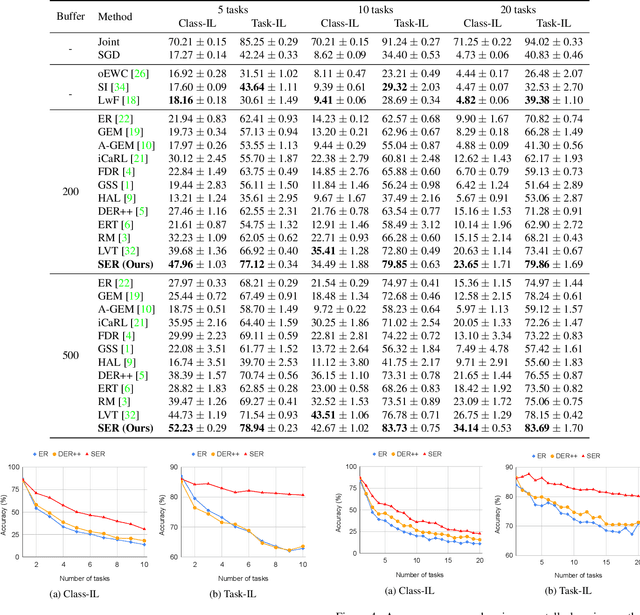
Continual Learning (CL) aims at incrementally learning new tasks without forgetting the knowledge acquired from old ones. Experience Replay (ER) is a simple and effective rehearsal-based strategy, which optimizes the model with current training data and a subset of old samples stored in a memory buffer. To further reduce forgetting, recent approaches extend ER with various techniques, such as model regularization and memory sampling. However, the prediction consistency between the new model and the old one on current training data has been seldom explored, resulting in less knowledge preserved when few previous samples are available. To address this issue, we propose a CL method with Strong Experience Replay (SER), which additionally utilizes future experiences mimicked on the current training data, besides distilling past experience from the memory buffer. In our method, the updated model will produce approximate outputs as its original ones, which can effectively preserve the acquired knowledge. Experimental results on multiple image classification datasets show that our SER method surpasses the state-of-the-art methods by a noticeable margin.
Aerial Image Object Detection With Vision Transformer Detector (ViTDet)
Jan 28, 2023
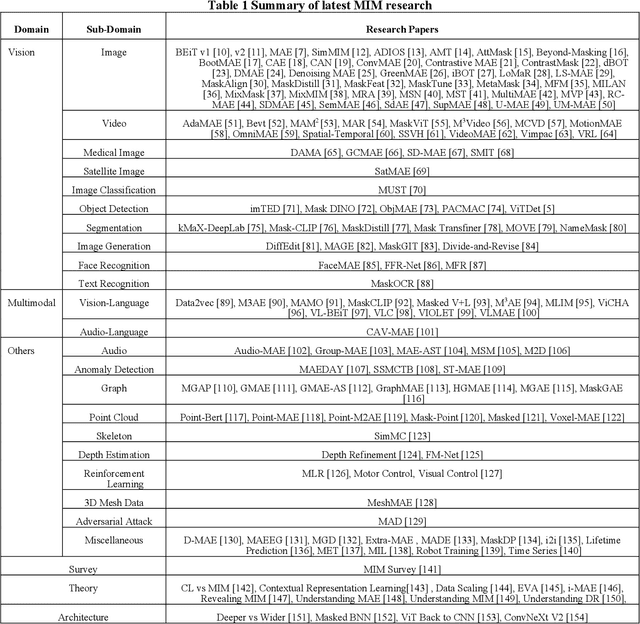
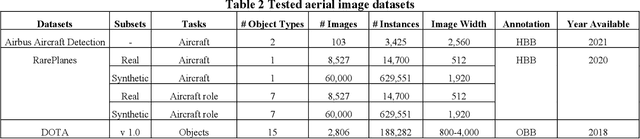
The past few years have seen an increased interest in aerial image object detection due to its critical value to large-scale geo-scientific research like environmental studies, urban planning, and intelligence monitoring. However, the task is very challenging due to the birds-eye view perspective, complex backgrounds, large and various image sizes, different appearances of objects, and the scarcity of well-annotated datasets. Recent advances in computer vision have shown promise tackling the challenge. Specifically, Vision Transformer Detector (ViTDet) was proposed to extract multi-scale features for object detection. The empirical study shows that ViTDet's simple design achieves good performance on natural scene images and can be easily embedded into any detector architecture. To date, ViTDet's potential benefit to challenging aerial image object detection has not been explored. Therefore, in our study, 25 experiments were carried out to evaluate the effectiveness of ViTDet for aerial image object detection on three well-known datasets: Airbus Aircraft, RarePlanes, and Dataset of Object DeTection in Aerial images (DOTA). Our results show that ViTDet can consistently outperform its convolutional neural network counterparts on horizontal bounding box (HBB) object detection by a large margin (up to 17% on average precision) and that it achieves the competitive performance for oriented bounding box (OBB) object detection. Our results also establish a baseline for future research.
Multi-Task Self-Supervised Learning for Image Segmentation Task
Feb 05, 2023

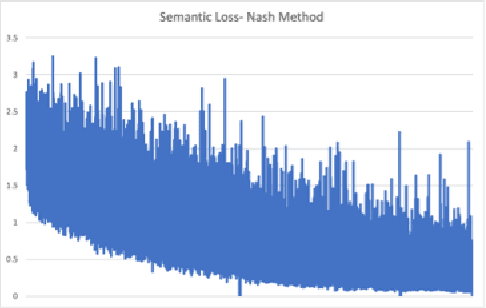

Thanks to breakthroughs in AI and Deep learning methodology, Computer vision techniques are rapidly improving. Most computer vision applications require sophisticated image segmentation to comprehend what is image and to make an analysis of each section easier. Training deep learning networks for semantic segmentation required a large amount of annotated data, which presents a major challenge in practice as it is expensive and labor-intensive to produce such data. The paper presents 1. Self-supervised techniques to boost semantic segmentation performance using multi-task learning with Depth prediction and Surface Normalization . 2. Performance evaluation of the different types of weighing techniques (UW, Nash-MTL) used for Multi-task learning. NY2D dataset was used for performance evaluation. According to our evaluation, the Nash-MTL method outperforms single task learning(Semantic Segmentation).
Efficient Deduplication and Leakage Detection in Large Scale Image Datasets with a focus on the CrowdAI Mapping Challenge Dataset
Apr 05, 2023



Recent advancements in deep learning and computer vision have led to widespread use of deep neural networks to extract building footprints from remote-sensing imagery. The success of such methods relies on the availability of large databases of high-resolution remote sensing images with high-quality annotations. The CrowdAI Mapping Challenge Dataset is one of these datasets that has been used extensively in recent years to train deep neural networks. This dataset consists of $ \sim\ $280k training images and $ \sim\ $60k testing images, with polygonal building annotations for all images. However, issues such as low-quality and incorrect annotations, extensive duplication of image samples, and data leakage significantly reduce the utility of deep neural networks trained on the dataset. Therefore, it is an imperative pre-condition to adopt a data validation pipeline that evaluates the quality of the dataset prior to its use. To this end, we propose a drop-in pipeline that employs perceptual hashing techniques for efficient de-duplication of the dataset and identification of instances of data leakage between training and testing splits. In our experiments, we demonstrate that nearly 250k($ \sim\ $90%) images in the training split were identical. Moreover, our analysis on the validation split demonstrates that roughly 56k of the 60k images also appear in the training split, resulting in a data leakage of 93%. The source code used for the analysis and de-duplication of the CrowdAI Mapping Challenge dataset is publicly available at https://github.com/yeshwanth95/CrowdAI_Hash_and_search .
VEIL: Vetting Extracted Image Labels from In-the-Wild Captions for Weakly-Supervised Object Detection
Mar 16, 2023

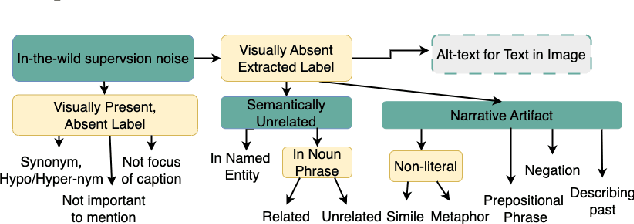
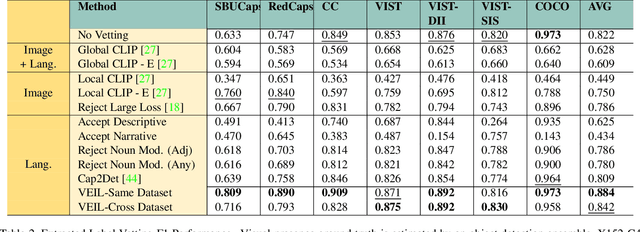
The use of large-scale vision-language datasets is limited for object detection due to the negative impact of label noise on localization. Prior methods have shown how such large-scale datasets can be used for pretraining, which can provide initial signal for localization, but is insufficient without clean bounding-box data for at least some categories. We propose a technique to "vet" labels extracted from noisy captions. Our method trains a classifier that predicts if an extracted label is actually present in the image or not. Our classifier generalizes across dataset boundaries and shows promise for generalizing across categories as well. We compare the classifier to eleven baselines on five datasets, and demonstrate that it can improve weakly-supervised detection without label vetting by 80% (16.0 to 29.1 mAP when evaluated on PASCAL VOC).
Learning Thin-Plate Spline Motion and Seamless Composition for Parallax-Tolerant Unsupervised Deep Image Stitching
Feb 16, 2023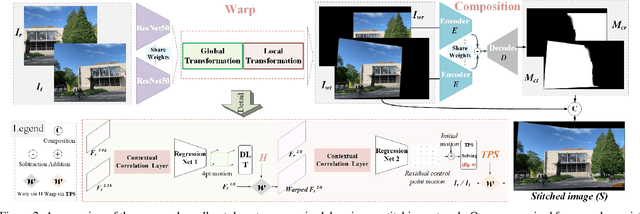
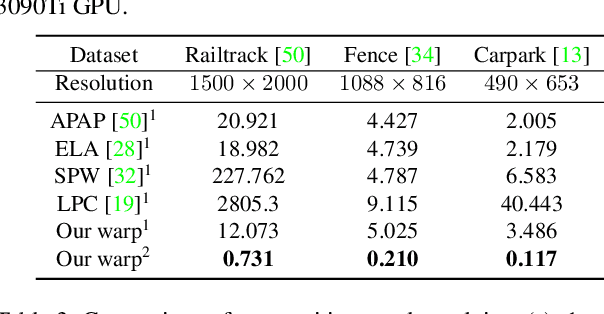

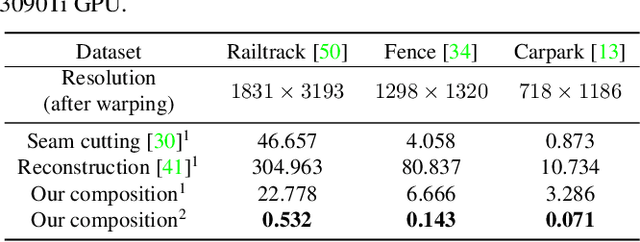
Traditional image stitching approaches tend to leverage increasingly complex geometric features (point, line, edge, etc.) for better performance. However, these hand-crafted features are only suitable for specific natural scenes with adequate geometric structures. In contrast, deep stitching schemes overcome the adverse conditions by adaptively learning robust semantic features, but they cannot handle large-parallax cases due to homography-based registration. To solve these issues, we propose UDIS++, a parallax-tolerant unsupervised deep image stitching technique. First, we propose a robust and flexible warp to model the image registration from global homography to local thin-plate spline motion. It provides accurate alignment for overlapping regions and shape preservation for non-overlapping regions by joint optimization concerning alignment and distortion. Subsequently, to improve the generalization capability, we design a simple but effective iterative strategy to enhance the warp adaption in cross-dataset and cross-resolution applications. Finally, to further eliminate the parallax artifacts, we propose to composite the stitched image seamlessly by unsupervised learning for seam-driven composition masks. Compared with existing methods, our solution is parallax-tolerant and free from laborious designs of complicated geometric features for specific scenes. Extensive experiments show our superiority over the SoTA methods, both quantitatively and qualitatively. The code will be available at https://github.com/nie-lang/UDIS2.
Representation Learning via Manifold Flattening and Reconstruction
May 12, 2023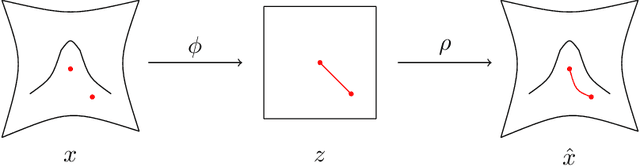
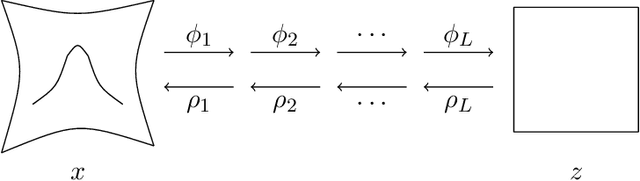
This work proposes an algorithm for explicitly constructing a pair of neural networks that linearize and reconstruct an embedded submanifold, from finite samples of this manifold. Our such-generated neural networks, called Flattening Networks (FlatNet), are theoretically interpretable, computationally feasible at scale, and generalize well to test data, a balance not typically found in manifold-based learning methods. We present empirical results and comparisons to other models on synthetic high-dimensional manifold data and 2D image data. Our code is publicly available.
Implicit Ray-Transformers for Multi-view Remote Sensing Image Segmentation
Mar 15, 2023



The mainstream CNN-based remote sensing (RS) image semantic segmentation approaches typically rely on massive labeled training data. Such a paradigm struggles with the problem of RS multi-view scene segmentation with limited labeled views due to the lack of considering 3D information within the scene. In this paper, we propose ''Implicit Ray-Transformer (IRT)'' based on Implicit Neural Representation (INR), for RS scene semantic segmentation with sparse labels (such as 4-6 labels per 100 images). We explore a new way of introducing multi-view 3D structure priors to the task for accurate and view-consistent semantic segmentation. The proposed method includes a two-stage learning process. In the first stage, we optimize a neural field to encode the color and 3D structure of the remote sensing scene based on multi-view images. In the second stage, we design a Ray Transformer to leverage the relations between the neural field 3D features and 2D texture features for learning better semantic representations. Different from previous methods that only consider 3D prior or 2D features, we incorporate additional 2D texture information and 3D prior by broadcasting CNN features to different point features along the sampled ray. To verify the effectiveness of the proposed method, we construct a challenging dataset containing six synthetic sub-datasets collected from the Carla platform and three real sub-datasets from Google Maps. Experiments show that the proposed method outperforms the CNN-based methods and the state-of-the-art INR-based segmentation methods in quantitative and qualitative metrics.
DNN-Compressed Domain Visual Recognition with Feature Adaptation
May 13, 2023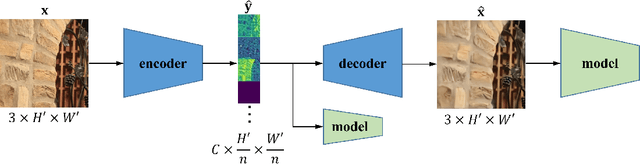
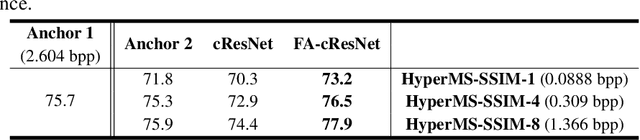
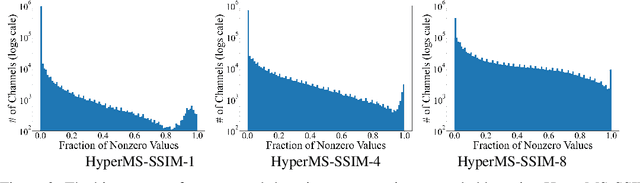

Learning-based image compression was shown to achieve a competitive performance with state-of-the-art transform-based codecs. This motivated the development of new learning-based visual compression standards such as JPEG-AI. Of particular interest to these emerging standards is the development of learning-based image compression systems targeting both humans and machines. This paper is concerned with learning-based compression schemes whose compressed-domain representations can be utilized to perform visual processing and computer vision tasks directly in the compressed domain. In our work, we adopt a learning-based compressed-domain classification framework for performing visual recognition using the compressed-domain latent representation at varying bit-rates. We propose a novel feature adaptation module integrating a lightweight attention model to adaptively emphasize and enhance the key features within the extracted channel-wise information. Also, we design an adaptation training strategy to utilize the pretrained pixel-domain weights. For comparison, in addition to the performance results that are obtained using our proposed latent-based compressed-domain method, we also present performance results using compressed but fully decoded images in the pixel domain as well as original uncompressed images. The obtained performance results show that our proposed compressed-domain classification model can distinctly outperform the existing compressed-domain classification models, and that it can also yield similar accuracy results with a much higher computational efficiency as compared to the pixel-domain models that are trained using fully decoded images.
Multi-object Video Generation from Single Frame Layouts
May 06, 2023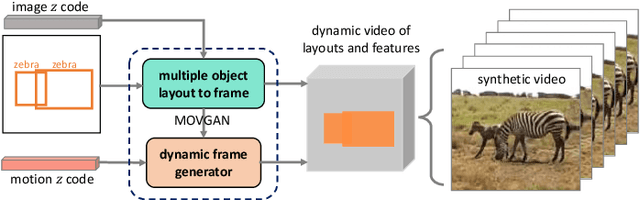
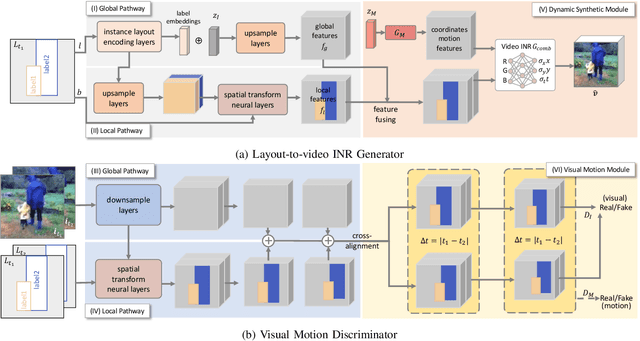

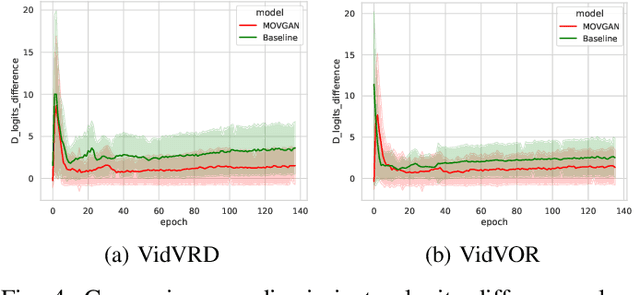
In this paper, we study video synthesis with emphasis on simplifying the generation conditions. Most existing video synthesis models or datasets are designed to address complex motions of a single object, lacking the ability of comprehensively understanding the spatio-temporal relationships among multiple objects. Besides, current methods are usually conditioned on intricate annotations (e.g. video segmentations) to generate new videos, being fundamentally less practical. These motivate us to generate multi-object videos conditioning exclusively on object layouts from a single frame. To solve above challenges and inspired by recent research on image generation from layouts, we have proposed a novel video generative framework capable of synthesizing global scenes with local objects, via implicit neural representations and layout motion self-inference. Our framework is a non-trivial adaptation from image generation methods, and is new to this field. In addition, our model has been evaluated on two widely-used video recognition benchmarks, demonstrating effectiveness compared to the baseline model.