 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bio-Inspired Simple Neural Network for Low-Light Image Restoration: A Minimalist Approach
May 03, 2023

In this study, we explore the potential of using a straightforward neural network inspired by the retina model to efficiently restore low-light images. The retina model imitates the neurophysiological principles and dynamics of various optical neurons. Our proposed neural network model reduces the computational overhead compared to traditional signal-processing models while achieving results similar to complex deep learning models from a subjective perceptual perspective. By directly simulating retinal neuron functionalities with neural networks, we not only avoid manual parameter optimization but also lay the groundwork for constructing artificial versions of specific neurobiological organizations.
Sex Detection in the Early Stage of Fertilized Chicken Eggs via Image Recognition
May 03, 2023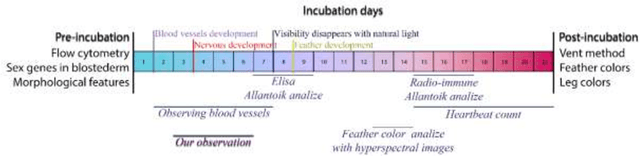
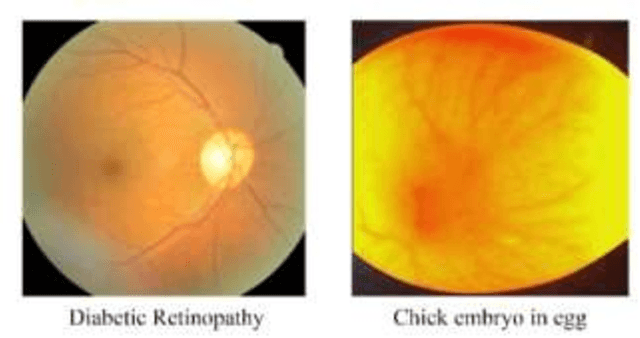

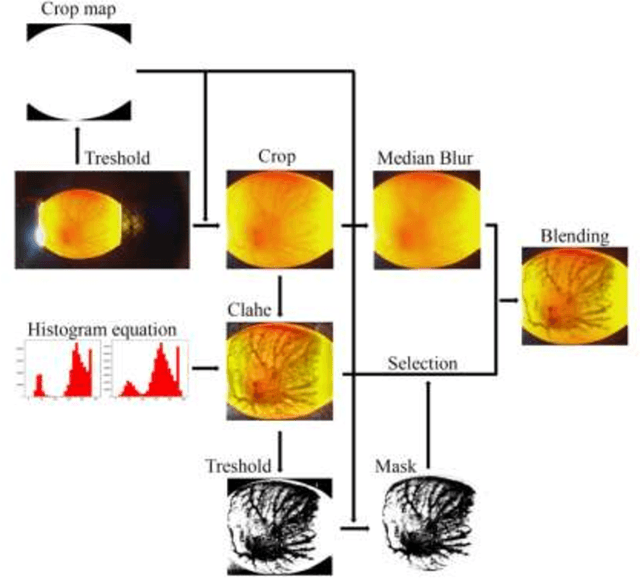
Culling newly hatched male chicks in industrial hatcheries poses a serious ethical problem. Both laying and broiler breeders need males, but it is a problem because they are produced more than needed. Being able to determine the sex of chicks in the egg at the beginning or early stage of incubation can eliminate ethical problems as well as many additional costs. When we look at the literature, the methods used are very costly, low in applicability, invasive, inadequate in accuracy, or too late to eliminate ethical problems. Considering the embryo's development, the earliest observed candidate feature for sex determination is blood vessels. Detection from blood vessels can eliminate ethical issues, and these vessels can be seen when light is shined into the egg until the first seven days. In this study, sex determination was made by morphological analysis from embryonic vascular images obtained in the first week when the light was shined into the egg using a standard camera without any invasive procedure to the egg.
* 8 pages, 4 figures, 1 table
Reference Guided Image Inpainting using Facial Attributes
Jan 19, 2023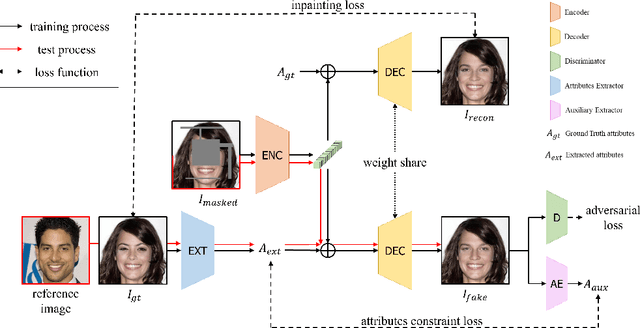
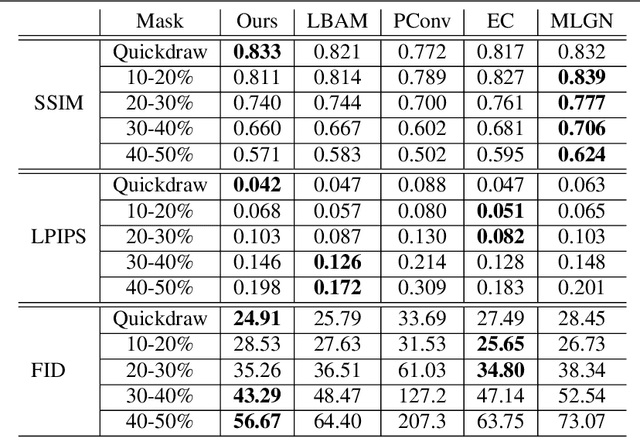


Image inpainting is a technique of completing missing pixels such as occluded region restoration, distracting objects removal, and facial completion. Among these inpainting tasks, facial completion algorithm performs face inpainting according to the user direction. Existing approaches require delicate and well controlled input by the user, thus it is difficult for an average user to provide the guidance sufficiently accurate for the algorithm to generate desired results. To overcome this limitation, we propose an alternative user-guided inpainting architecture that manipulates facial attributes using a single reference image as the guide. Our end-to-end model consists of attribute extractors for accurate reference image attribute transfer and an inpainting model to map the attributes realistically and accurately to generated images. We customize MS-SSIM loss and learnable bidirectional attention maps in which importance structures remain intact even with irregular shaped masks. Based on our evaluation using the publicly available dataset CelebA-HQ, we demonstrate that the proposed method delivers superior performance compared to some state-of-the-art methods specialized in inpainting tasks.
GazeSAM: What You See is What You Segment
Apr 26, 2023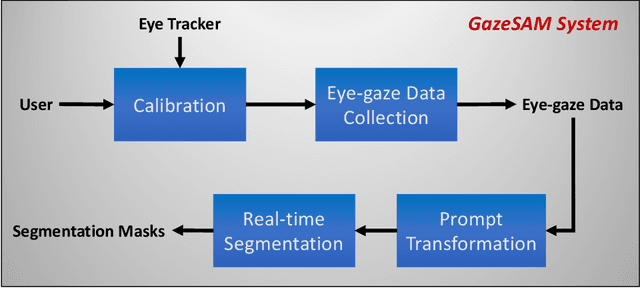
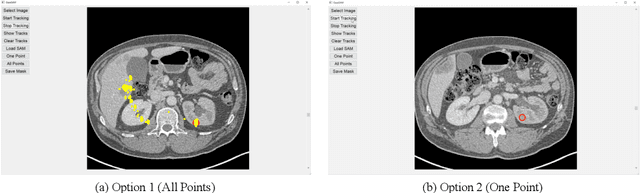
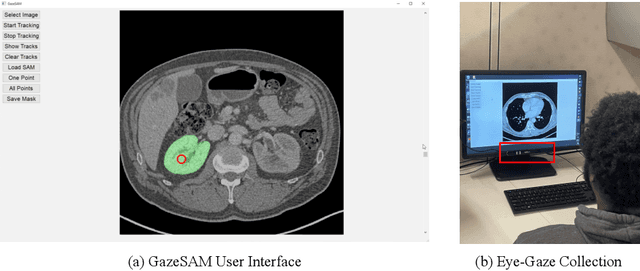
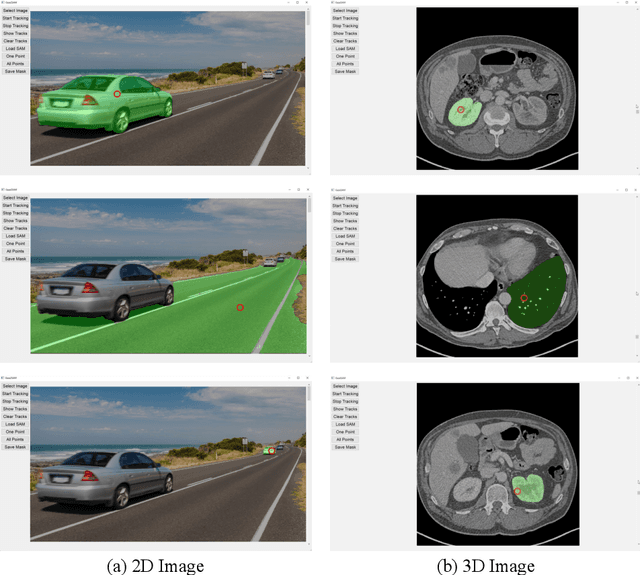
This study investigates the potential of eye-tracking technology and the Segment Anything Model (SAM) to design a collaborative human-computer interaction system that automates medical image segmentation. We present the \textbf{GazeSAM} system to enable radiologists to collect segmentation masks by simply looking at the region of interest during image diagnosis. The proposed system tracks radiologists' eye movement and utilizes the eye-gaze data as the input prompt for SAM, which automatically generates the segmentation mask in real time. This study is the first work to leverage the power of eye-tracking technology and SAM to enhance the efficiency of daily clinical practice. Moreover, eye-gaze data coupled with image and corresponding segmentation labels can be easily recorded for further advanced eye-tracking research. The code is available in \url{https://github.com/ukaukaaaa/GazeSAM}.
Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design
May 22, 2023
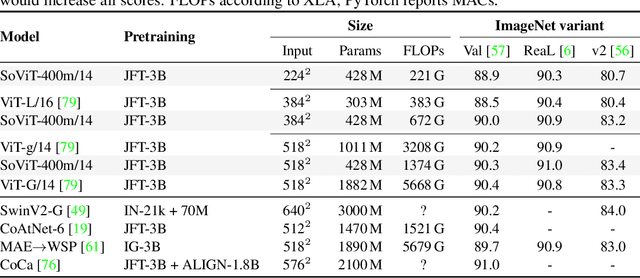

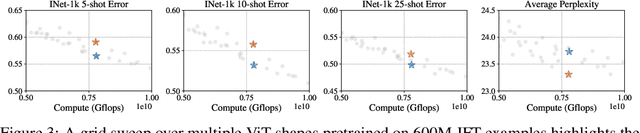
Scaling laws have been recently employed to derive compute-optimal model size (number of parameters) for a given compute duration. We advance and refine such methods to infer compute-optimal model shapes, such as width and depth, and successfully implement this in vision transformers. Our shape-optimized vision transformer, SoViT, achieves results competitive with models that exceed twice its size, despite being pre-trained with an equivalent amount of compute. For example, SoViT-400m/14 achieves 90.3% fine-tuning accuracy on ILSRCV2012, surpassing the much larger ViT-g/14 and approaching ViT-G/14 under identical settings, with also less than half the inference cost. We conduct a thorough evaluation across multiple tasks, such as image classification, captioning, VQA and zero-shot transfer, demonstrating the effectiveness of our model across a broad range of domains and identifying limitations. Overall, our findings challenge the prevailing approach of blindly scaling up vision models and pave a path for a more informed scaling.
End-to-End Stable Imitation Learning via Autonomous Neural Dynamic Policies
May 22, 2023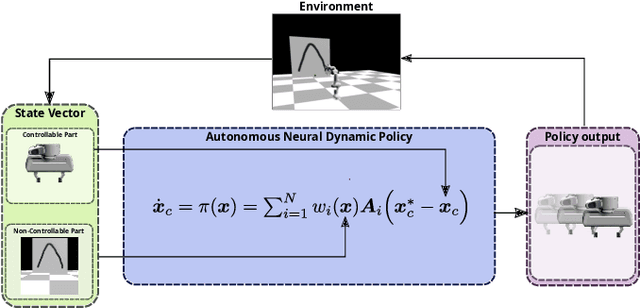
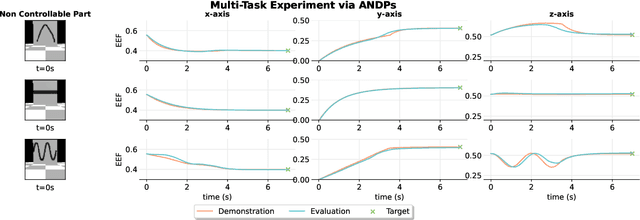
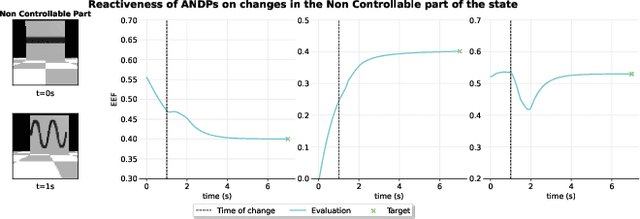
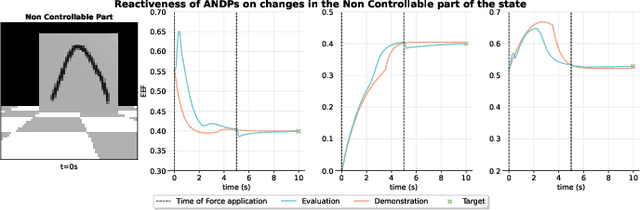
State-of-the-art sensorimotor learning algorithms offer policies that can often produce unstable behaviors, damaging the robot and/or the environment. Traditional robot learning, on the contrary, relies on dynamical system-based policies that can be analyzed for stability/safety. Such policies, however, are neither flexible nor generic and usually work only with proprioceptive sensor states. In this work, we bridge the gap between generic neural network policies and dynamical system-based policies, and we introduce Autonomous Neural Dynamic Policies (ANDPs) that: (a) are based on autonomous dynamical systems, (b) always produce asymptotically stable behaviors, and (c) are more flexible than traditional stable dynamical system-based policies. ANDPs are fully differentiable, flexible generic-policies that can be used in imitation learning setups while ensuring asymptotic stability. In this paper, we explore the flexibility and capacity of ANDPs in several imitation learning tasks including experiments with image observations. The results show that ANDPs combine the benefits of both neural network-based and dynamical system-based methods.
Feasibility of Transfer Learning: A Mathematical Framework
May 22, 2023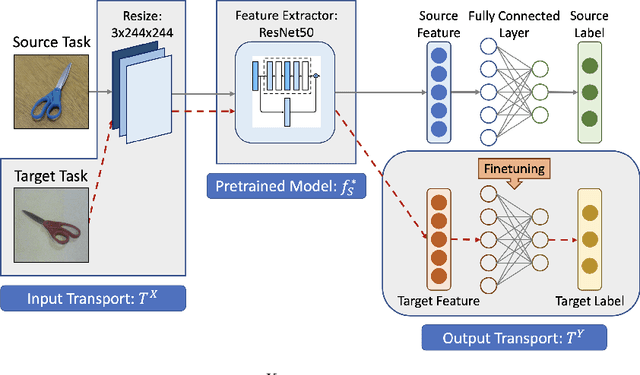
Transfer learning is a popular paradigm for utilizing existing knowledge from previous learning tasks to improve the performance of new ones. It has enjoyed numerous empirical successes and inspired a growing number of theoretical studies. This paper addresses the feasibility issue of transfer learning. It begins by establishing the necessary mathematical concepts and constructing a mathematical framework for transfer learning. It then identifies and formulates the three-step transfer learning procedure as an optimization problem, allowing for the resolution of the feasibility issue. Importantly, it demonstrates that under certain technical conditions, such as appropriate choice of loss functions and data sets, an optimal procedure for transfer learning exists. This study of the feasibility issue brings additional insights into various transfer learning problems. It sheds light on the impact of feature augmentation on model performance, explores potential extensions of domain adaptation, and examines the feasibility of efficient feature extractor transfer in image classification.
Style-Aware Contrastive Learning for Multi-Style Image Captioning
Jan 26, 2023
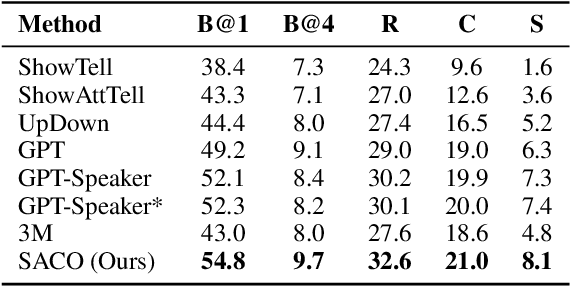
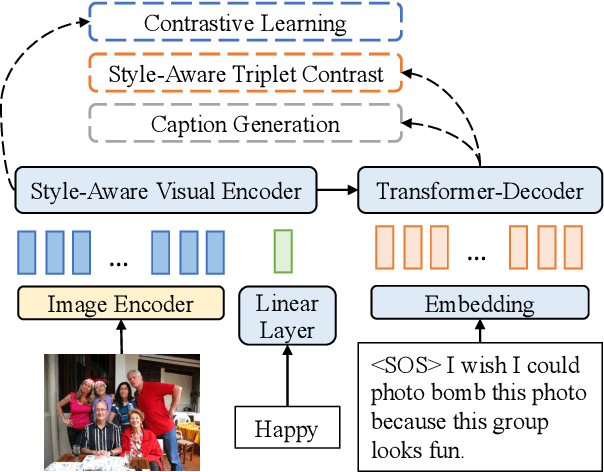
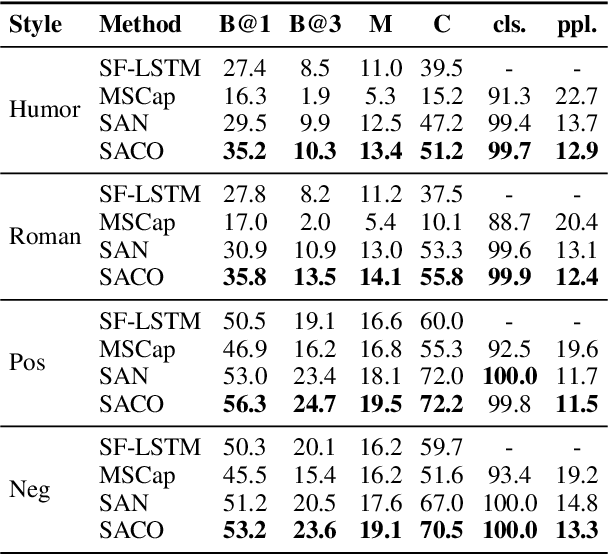
Existing multi-style image captioning methods show promising results in generating a caption with accurate visual content and desired linguistic style. However, existing methods overlook the relationship between linguistic style and visual content. To overcome this drawback, we propose style-aware contrastive learning for multi-style image captioning. First, we present a style-aware visual encoder with contrastive learning to mine potential visual content relevant to style. Moreover, we propose a style-aware triplet contrast objective to distinguish whether the image, style and caption matched. To provide positive and negative samples for contrastive learning, we present three retrieval schemes: object-based retrieval, RoI-based retrieval and triplet-based retrieval, and design a dynamic trade-off function to calculate retrieval scores. Experimental results demonstrate that our approach achieves state-of-the-art performance. In addition, we conduct an extensive analysis to verify the effectiveness of our method.
Implicit Neural Networks with Fourier-Feature Inputs for Free-breathing Cardiac MRI Reconstruction
May 11, 2023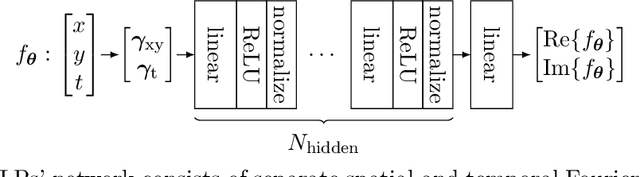
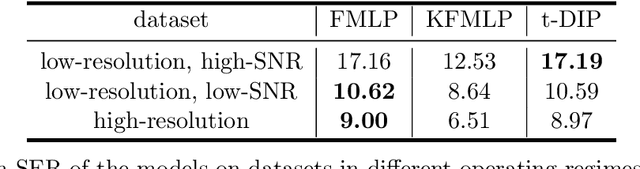
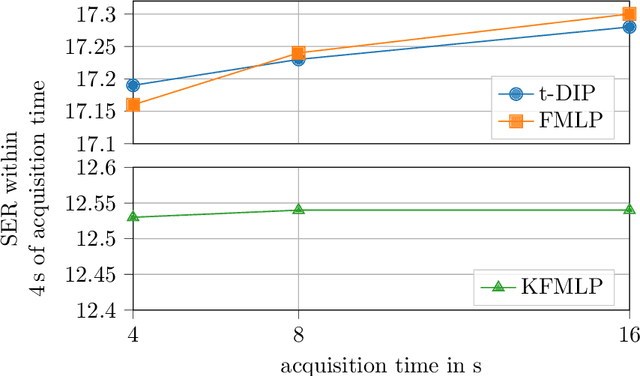
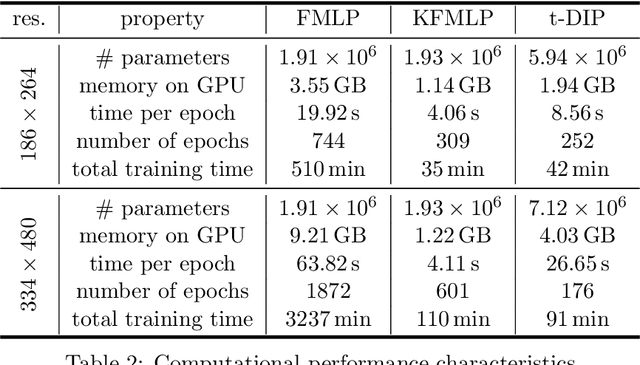
In this paper, we propose an approach for cardiac magnetic resonance imaging (MRI), which aims to reconstruct a real-time video of a beating heart from continuous highly under-sampled measurements. This task is challenging since the object to be reconstructed (the heart) is continuously changing during signal acquisition. To address this challenge, we represent the beating heart with an implicit neural network and fit the network so that the representation of the heart is consistent with the measurements. The network in the form of a multi-layer perceptron with Fourier-feature inputs acts as an effective signal prior and enables adjusting the regularization strength in both the spatial and temporal dimensions of the signal. We examine the proposed approach for 2D free-breathing cardiac real-time MRI in different operating regimes, i.e., for different image resolutions, slice thicknesses, and acquisition lengths. Our method achieves reconstruction quality on par with or slightly better than state-of-the-art untrained convolutional neural networks and superior image quality compared to a recent method that fits an implicit representation directly to Fourier-domain measurements. However, this comes at a higher computational cost. Our approach does not require any additional patient data or biosensors including electrocardiography, making it potentially applicable in a wide range of clinical scenarios.
Few-Shot Defect Image Generation via Defect-Aware Feature Manipulation
Mar 04, 2023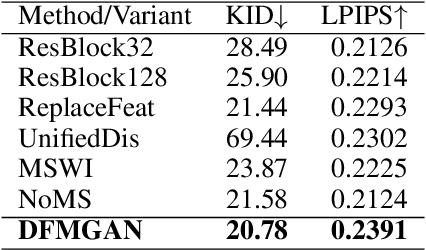

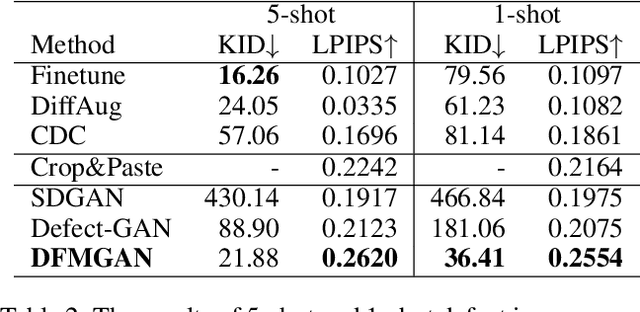

The performances of defect inspection have been severely hindered by insufficient defect images in industries, which can be alleviated by generating more samples as data augmentation. We propose the first defect image generation method in the challenging few-shot cases. Given just a handful of defect images and relatively more defect-free ones, our goal is to augment the dataset with new defect images. Our method consists of two training stages. First, we train a data-efficient StyleGAN2 on defect-free images as the backbone. Second, we attach defect-aware residual blocks to the backbone, which learn to produce reasonable defect masks and accordingly manipulate the features within the masked regions by training the added modules on limited defect images. Extensive experiments on MVTec AD dataset not only validate the effectiveness of our method in generating realistic and diverse defect images, but also manifest the benefits it brings to downstream defect inspection tasks. Codes are available at https://github.com/Ldhlwh/DFMGAN.