 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Securing Deep Generative Models with Universal Adversarial Signature
May 25, 2023
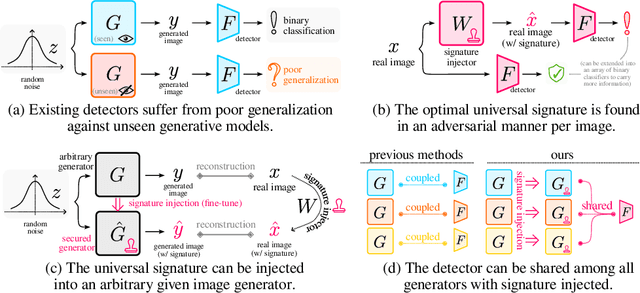
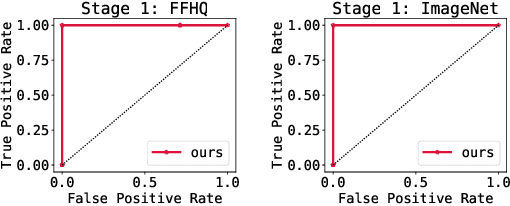


Recent advances in deep generative models have led to the development of methods capable of synthesizing high-quality, realistic images. These models pose threats to society due to their potential misuse. Prior research attempted to mitigate these threats by detecting generated images, but the varying traces left by different generative models make it challenging to create a universal detector capable of generalizing to new, unseen generative models. In this paper, we propose to inject a universal adversarial signature into an arbitrary pre-trained generative model, in order to make its generated contents more detectable and traceable. First, the imperceptible optimal signature for each image can be found by a signature injector through adversarial training. Subsequently, the signature can be incorporated into an arbitrary generator by fine-tuning it with the images processed by the signature injector. In this way, the detector corresponding to the signature can be reused for any fine-tuned generator for tracking the generator identity. The proposed method is validated on the FFHQ and ImageNet datasets with various state-of-the-art generative models, consistently showing a promising detection rate. Code will be made publicly available at \url{https://github.com/zengxianyu/genwm}.
Leveraging object detection for the identification of lung cancer
May 25, 2023
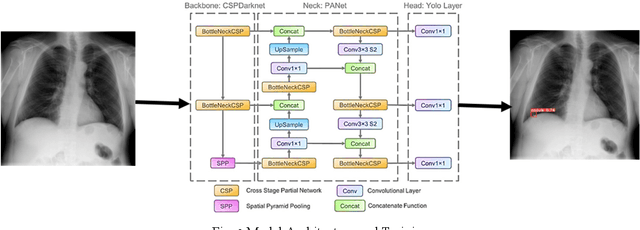
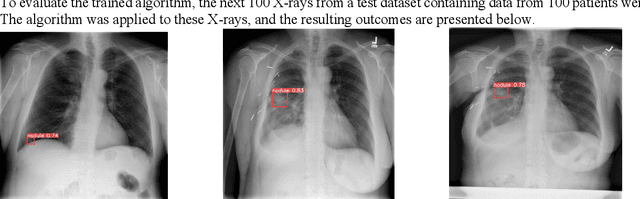
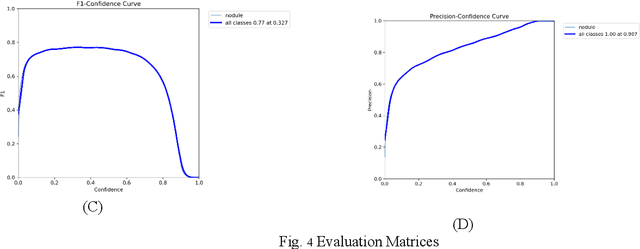
Lung cancer poses a significant global public health challenge, emphasizing the importance of early detection for improved patient outcomes. Recent advancements in deep learning algorithms have shown promising results in medical image analysis. This study aims to explore the application of object detection particularly YOLOv5, an advanced object identification system, in medical imaging for lung cancer identification. To train and evaluate the algorithm, a dataset comprising chest X-rays and corresponding annotations was obtained from Kaggle. The YOLOv5 model was employed to train an algorithm capable of detecting cancerous lung lesions. The training process involved optimizing hyperparameters and utilizing augmentation techniques to enhance the model's performance. The trained YOLOv5 model exhibited exceptional proficiency in identifying lung cancer lesions, displaying high accuracy and recall rates. It successfully pinpointed malignant areas in chest radiographs, as validated by a separate test set where it outperformed previous techniques. Additionally, the YOLOv5 model demonstrated computational efficiency, enabling real-time detection and making it suitable for integration into clinical procedures. This proposed approach holds promise in assisting radiologists in the early discovery and diagnosis of lung cancer, ultimately leading to prompt treatment and improved patient outcomes.
Triplet Knowledge Distillation
May 25, 2023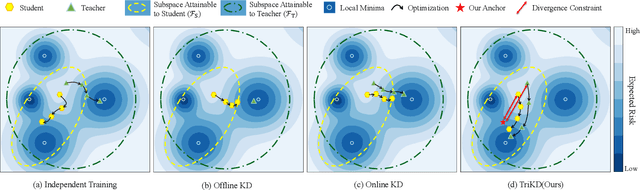
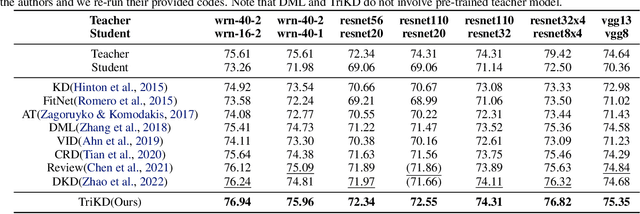
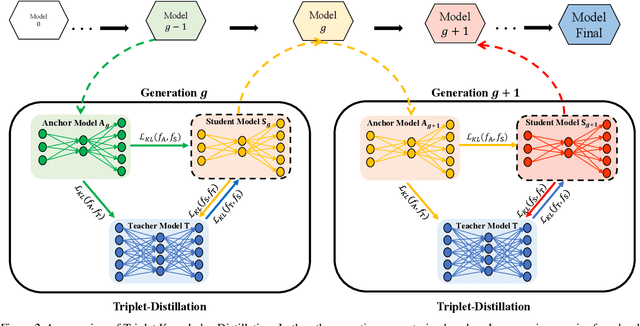

In Knowledge Distillation, the teacher is generally much larger than the student, making the solution of the teacher likely to be difficult for the student to learn. To ease the mimicking difficulty, we introduce a triplet knowledge distillation mechanism named TriKD. Besides teacher and student, TriKD employs a third role called anchor model. Before distillation begins, the pre-trained anchor model delimits a subspace within the full solution space of the target problem. Solutions within the subspace are expected to be easy targets that the student could mimic well. Distillation then begins in an online manner, and the teacher is only allowed to express solutions within the aforementioned subspace. Surprisingly, benefiting from accurate but easy-to-mimic hints, the student can finally perform well. After the student is well trained, it can be used as the new anchor for new students, forming a curriculum learning strategy. Our experiments on image classification and face recognition with various models clearly demonstrate the effectiveness of our method. Furthermore, the proposed TriKD is also effective in dealing with the overfitting issue. Moreover, our theoretical analysis supports the rationality of our triplet distillation.
Deep Neural Networks in Video Human Action Recognition: A Review
May 25, 2023

Currently, video behavior recognition is one of the most foundational tasks of computer vision. The 2D neural networks of deep learning are built for recognizing pixel-level information such as images with RGB, RGB-D, or optical flow formats, with the current increasingly wide usage of surveillance video and more tasks related to human action recognition. There are increasing tasks requiring temporal information for frames dependency analysis. The researchers have widely studied video-based recognition rather than image-based(pixel-based) only to extract more informative elements from geometry tasks. Our current related research addresses multiple novel proposed research works and compares their advantages and disadvantages between the derived deep learning frameworks rather than machine learning frameworks. The comparison happened between existing frameworks and datasets, which are video format data only. Due to the specific properties of human actions and the increasingly wide usage of deep neural networks, we collected all research works within the last three years between 2020 to 2022. In our article, the performance of deep neural networks surpassed most of the techniques in the feature learning and extraction tasks, especially video action recognition.
Solution existence, uniqueness, and stability of discrete basis sinograms in multispectral CT
May 05, 2023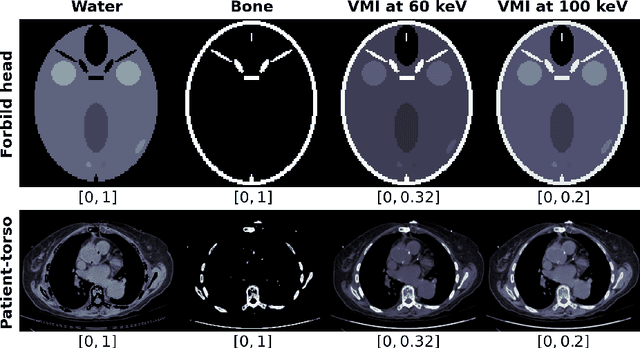
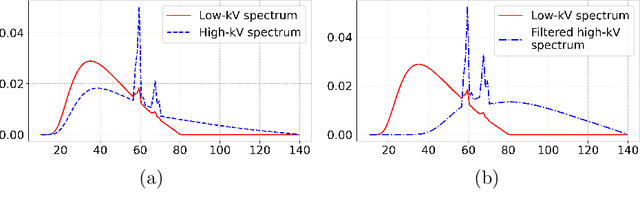
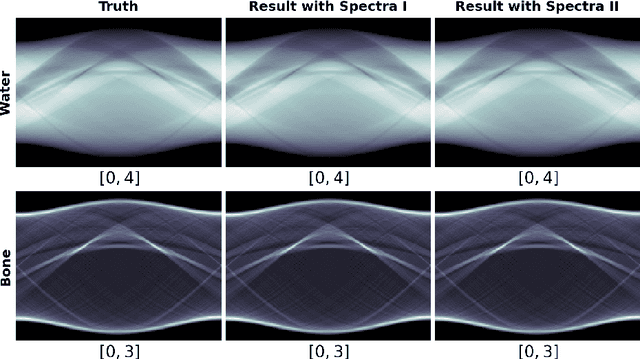
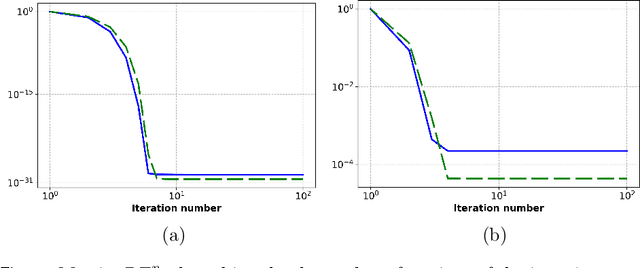
This work investigates conditions for quantitative image reconstruction in multispectral computed tomography (MSCT), which remains a topic of active research. In MSCT, one seeks to obtain from data the spatial distribution of linear attenuation coefficient, referred to as a virtual monochromatic image (VMI), at a given X-ray energy, within the subject imaged. As a VMI is decomposed often into a linear combination of basis images with known decomposition coefficients, the reconstruction of a VMI is thus tantamount to that of the basis images. An empirical, but highly effective, two-step data-domain-decomposition (DDD) method has been developed and used widely for quantitative image reconstruction in MSCT. In the two-step DDD method, step (1) estimates the so-called basis sinogram from data through solving a nonlinear transform, whereas step (2) reconstructs basis images from their basis sinograms estimated. Subsequently, a VMI can readily be obtained from the linear combination of basis images reconstructed. As step (2) involves the inversion of a straightforward linear system, step (1) is the key component of the DDD method in which a nonlinear system needs to be inverted for estimating the basis sinograms from data. In this work, we consider a {\it discrete} form of the nonlinear system in step (1), and then carry out theoretical and numerical analyses of conditions on the existence, uniqueness, and stability of a solution to the discrete nonlinear system for accurately estimating the discrete basis sinograms, leading to quantitative reconstruction of VMIs in MSCT.
Persistently Trained, Diffusion-assisted Energy-based Models
Apr 21, 2023
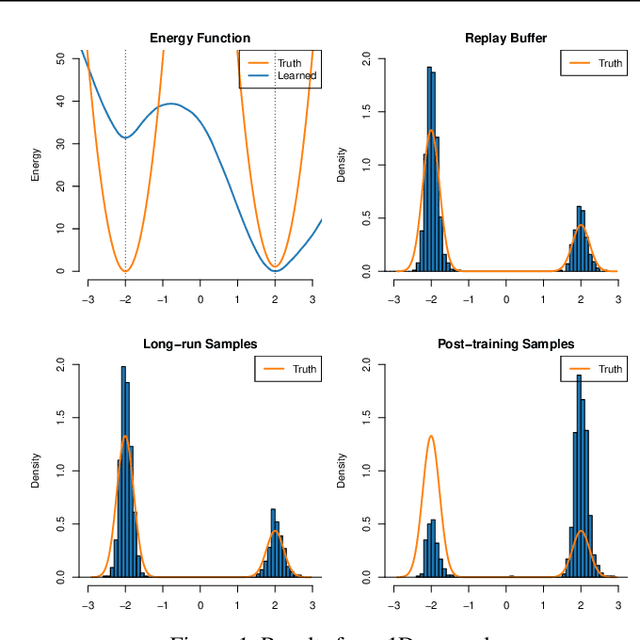
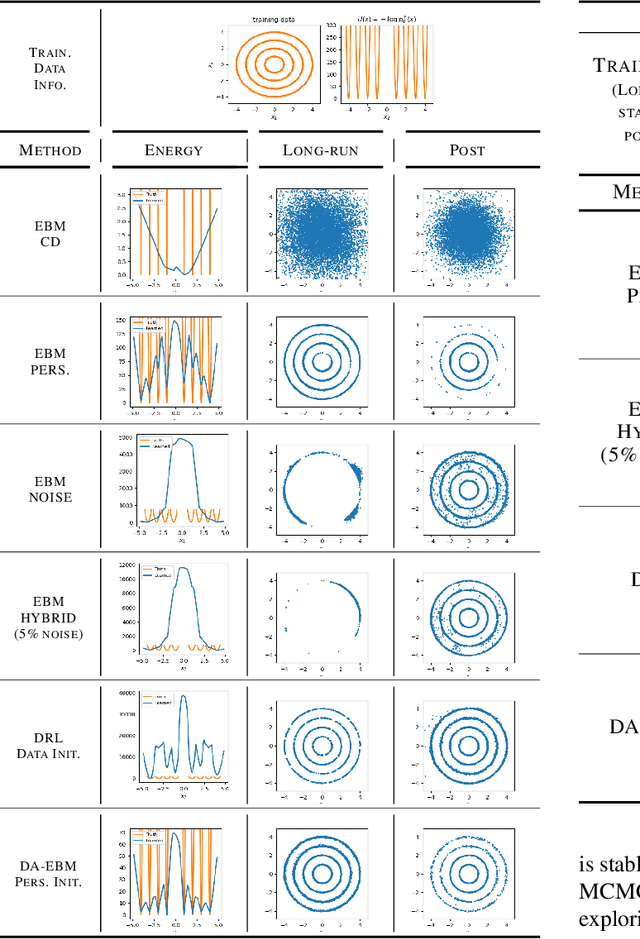
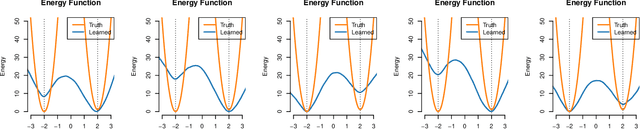
Maximum likelihood (ML) learning for energy-based models (EBMs) is challenging, partly due to non-convergence of Markov chain Monte Carlo.Several variations of ML learning have been proposed, but existing methods all fail to achieve both post-training image generation and proper density estimation. We propose to introduce diffusion data and learn a joint EBM, called diffusion assisted-EBMs, through persistent training (i.e., using persistent contrastive divergence) with an enhanced sampling algorithm to properly sample from complex, multimodal distributions. We present results from a 2D illustrative experiment and image experiments and demonstrate that, for the first time for image data, persistently trained EBMs can {\it simultaneously} achieve long-run stability, post-training image generation, and superior out-of-distribution detection.
Segmentation of fundus vascular images based on a dual-attention mechanism
May 05, 2023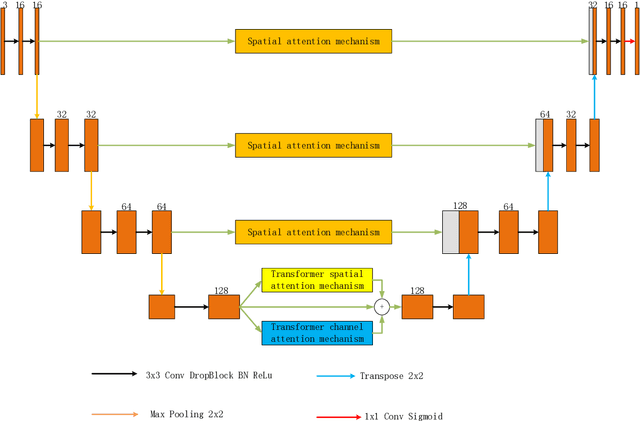
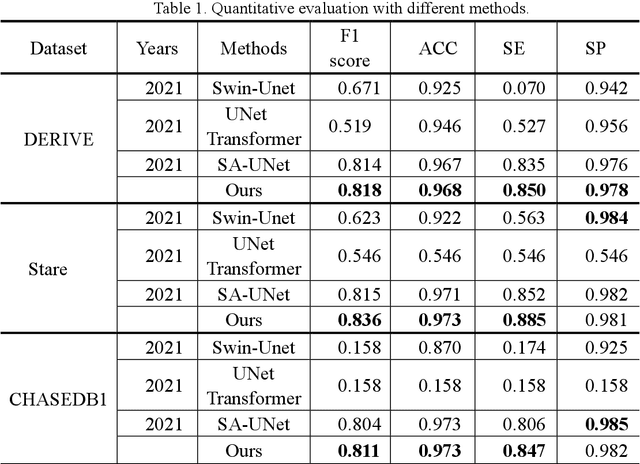
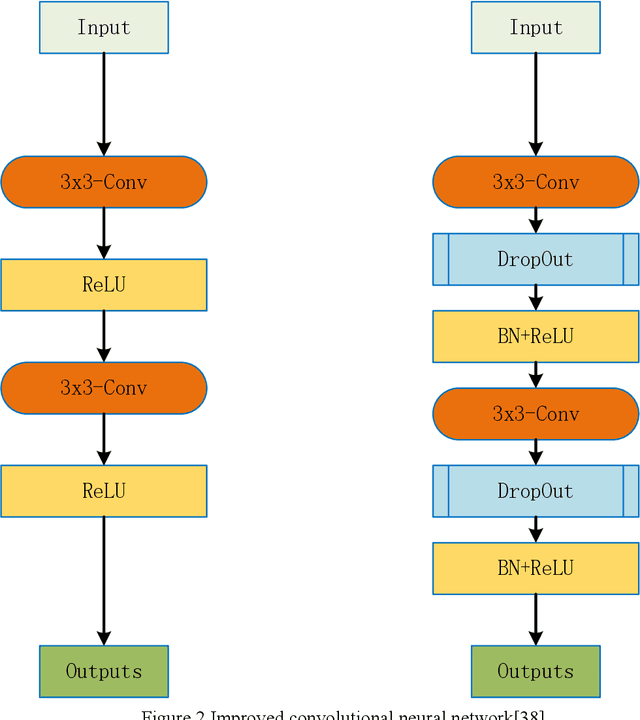
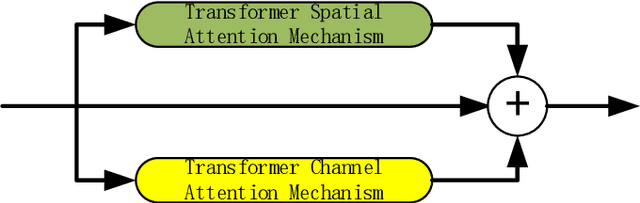
Accurately segmenting blood vessels in retinal fundus images is crucial in the early screening, diagnosing, and evaluating some ocular diseases. However, significant light variations and non-uniform contrast in these images make segmentation quite challenging. Thus, this paper employ an attention fusion mechanism that combines the channel attention and spatial attention mechanisms constructed by Transformer to extract information from retinal fundus images in both spatial and channel dimensions. To eliminate noise from the encoder image, a spatial attention mechanism is introduced in the skip connection. Moreover, a Dropout layer is employed to randomly discard some neurons, which can prevent overfitting of the neural network and improve its generalization performance. Experiments were conducted on publicly available datasets DERIVE, STARE, and CHASEDB1. The results demonstrate that our method produces satisfactory results compared to some recent retinal fundus image segmentation algorithms.
Learning Generalized Zero-Shot Learners for Open-Domain Image Geolocalization
Feb 01, 2023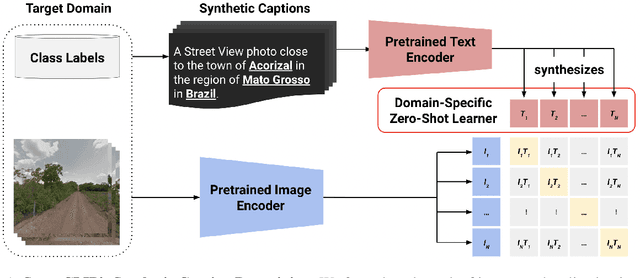
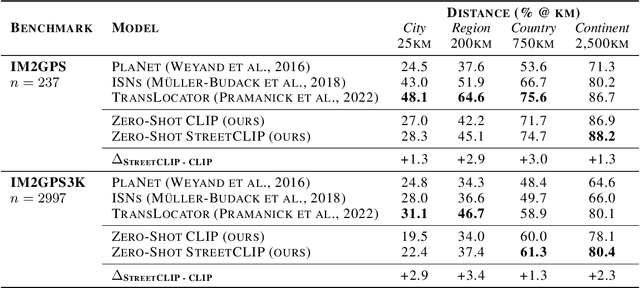
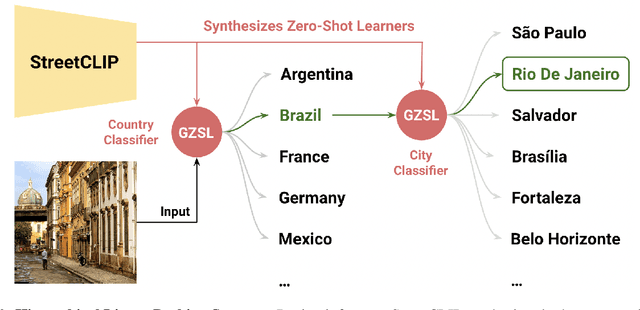

Image geolocalization is the challenging task of predicting the geographic coordinates of origin for a given photo. It is an unsolved problem relying on the ability to combine visual clues with general knowledge about the world to make accurate predictions across geographies. We present $\href{https://huggingface.co/geolocal/StreetCLIP}{\text{StreetCLIP}}$, a robust, publicly available foundation model not only achieving state-of-the-art performance on multiple open-domain image geolocalization benchmarks but also doing so in a zero-shot setting, outperforming supervised models trained on more than 4 million images. Our method introduces a meta-learning approach for generalized zero-shot learning by pretraining CLIP from synthetic captions, grounding CLIP in a domain of choice. We show that our method effectively transfers CLIP's generalized zero-shot capabilities to the domain of image geolocalization, improving in-domain generalized zero-shot performance without finetuning StreetCLIP on a fixed set of classes.
Delta Denoising Score
Apr 14, 2023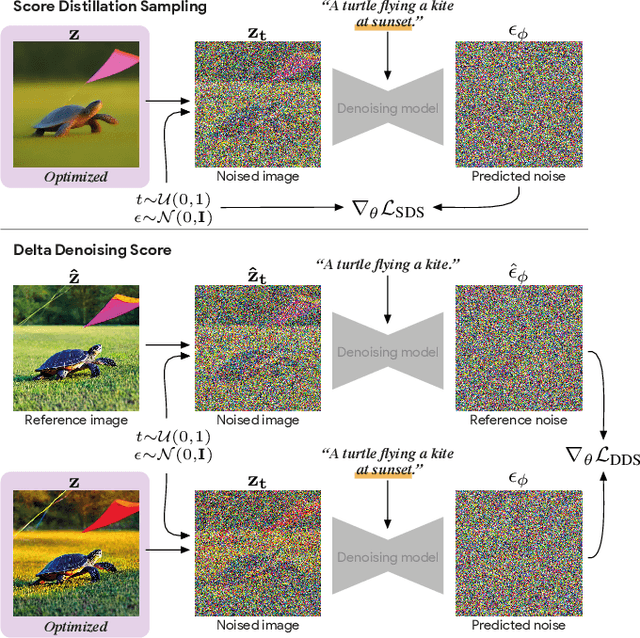
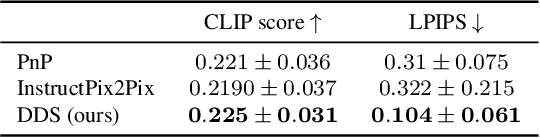


We introduce Delta Denoising Score (DDS), a novel scoring function for text-based image editing that guides minimal modifications of an input image towards the content described in a target prompt. DDS leverages the rich generative prior of text-to-image diffusion models and can be used as a loss term in an optimization problem to steer an image towards a desired direction dictated by a text. DDS utilizes the Score Distillation Sampling (SDS) mechanism for the purpose of image editing. We show that using only SDS often produces non-detailed and blurry outputs due to noisy gradients. To address this issue, DDS uses a prompt that matches the input image to identify and remove undesired erroneous directions of SDS. Our key premise is that SDS should be zero when calculated on pairs of matched prompts and images, meaning that if the score is non-zero, its gradients can be attributed to the erroneous component of SDS. Our analysis demonstrates the competence of DDS for text based image-to-image translation. We further show that DDS can be used to train an effective zero-shot image translation model. Experimental results indicate that DDS outperforms existing methods in terms of stability and quality, highlighting its potential for real-world applications in text-based image editing.
Automatic 3D Registration of Dental CBCT and Face Scan Data using 2D Projection images
May 17, 2023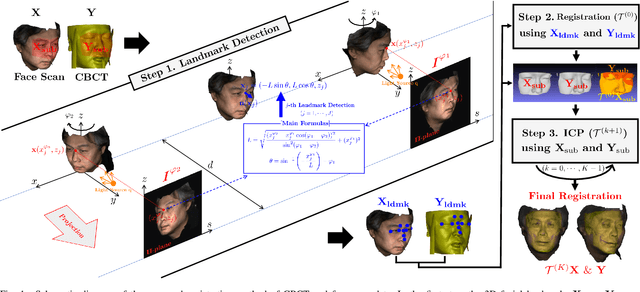
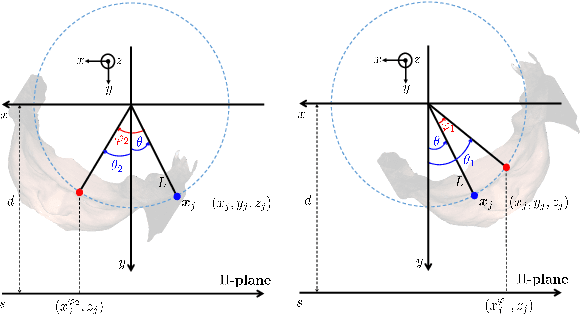
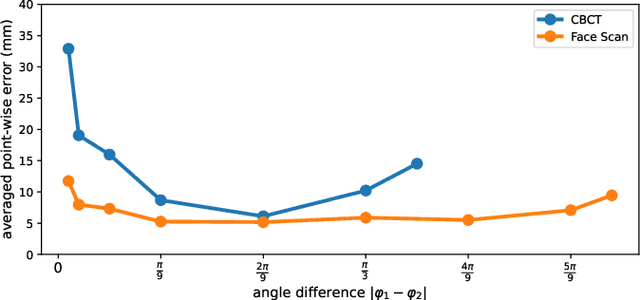

This paper presents a fully automatic registration method of dental cone-beam computed tomography (CBCT) and face scan data. It can be used for a digital platform of 3D jaw-teeth-face models in a variety of applications, including 3D digital treatment planning and orthognathic surgery. Difficulties in accurately merging facial scans and CBCT images are due to the different image acquisition methods and limited area of correspondence between the two facial surfaces. In addition, it is difficult to use machine learning techniques because they use face-related 3D medical data with radiation exposure, which are difficult to obtain for training. The proposed method addresses these problems by reusing an existing machine-learning-based 2D landmark detection algorithm in an open-source library and developing a novel mathematical algorithm that identifies paired 3D landmarks from knowledge of the corresponding 2D landmarks. A main contribution of this study is that the proposed method does not require annotated training data of facial landmarks because it uses a pre-trained facial landmark detection algorithm that is known to be robust and generalized to various 2D face image models. Note that this reduces a 3D landmark detection problem to a 2D problem of identifying the corresponding landmarks on two 2D projection images generated from two different projection angles. Here, the 3D landmarks for registration were selected from the sub-surfaces with the least geometric change under the CBCT and face scan environments. For the final fine-tuning of the registration, the Iterative Closest Point method was applied, which utilizes geometrical information around the 3D landmarks. The experimental results show that the proposed method achieved an averaged surface distance error of 0.74 mm for three pairs of CBCT and face scan datasets.