 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Do not trust what you trust: Miscalibration in Semi-supervised Learning
Mar 22, 2024
State-of-the-art semi-supervised learning (SSL) approaches rely on highly confident predictions to serve as pseudo-labels that guide the training on unlabeled samples. An inherent drawback of this strategy stems from the quality of the uncertainty estimates, as pseudo-labels are filtered only based on their degree of uncertainty, regardless of the correctness of their predictions. Thus, assessing and enhancing the uncertainty of network predictions is of paramount importance in the pseudo-labeling process. In this work, we empirically demonstrate that SSL methods based on pseudo-labels are significantly miscalibrated, and formally demonstrate the minimization of the min-entropy, a lower bound of the Shannon entropy, as a potential cause for miscalibration. To alleviate this issue, we integrate a simple penalty term, which enforces the logit distances of the predictions on unlabeled samples to remain low, preventing the network predictions to become overconfident. Comprehensive experiments on a variety of SSL image classification benchmarks demonstrate that the proposed solution systematically improves the calibration performance of relevant SSL models, while also enhancing their discriminative power, being an appealing addition to tackle SSL tasks.
SiMBA: Simplified Mamba-Based Architecture for Vision and Multivariate Time series
Mar 22, 2024Transformers have widely adopted attention networks for sequence mixing and MLPs for channel mixing, playing a pivotal role in achieving breakthroughs across domains. However, recent literature highlights issues with attention networks, including low inductive bias and quadratic complexity concerning input sequence length. State Space Models (SSMs) like S4 and others (Hippo, Global Convolutions, liquid S4, LRU, Mega, and Mamba), have emerged to address the above issues to help handle longer sequence lengths. Mamba, while being the state-of-the-art SSM, has a stability issue when scaled to large networks for computer vision datasets. We propose SiMBA, a new architecture that introduces Einstein FFT (EinFFT) for channel modeling by specific eigenvalue computations and uses the Mamba block for sequence modeling. Extensive performance studies across image and time-series benchmarks demonstrate that SiMBA outperforms existing SSMs, bridging the performance gap with state-of-the-art transformers. Notably, SiMBA establishes itself as the new state-of-the-art SSM on ImageNet and transfer learning benchmarks such as Stanford Car and Flower as well as task learning benchmarks as well as seven time series benchmark datasets. The project page is available on this website ~\url{https://github.com/badripatro/Simba}.
Self-Supervised Backbone Framework for Diverse Agricultural Vision Tasks
Mar 22, 2024Computer vision in agriculture is game-changing with its ability to transform farming into a data-driven, precise, and sustainable industry. Deep learning has empowered agriculture vision to analyze vast, complex visual data, but heavily rely on the availability of large annotated datasets. This remains a bottleneck as manual labeling is error-prone, time-consuming, and expensive. The lack of efficient labeling approaches inspired us to consider self-supervised learning as a paradigm shift, learning meaningful feature representations from raw agricultural image data. In this work, we explore how self-supervised representation learning unlocks the potential applicability to diverse agriculture vision tasks by eliminating the need for large-scale annotated datasets. We propose a lightweight framework utilizing SimCLR, a contrastive learning approach, to pre-train a ResNet-50 backbone on a large, unannotated dataset of real-world agriculture field images. Our experimental analysis and results indicate that the model learns robust features applicable to a broad range of downstream agriculture tasks discussed in the paper. Additionally, the reduced reliance on annotated data makes our approach more cost-effective and accessible, paving the way for broader adoption of computer vision in agriculture.
An In-Depth Analysis of Data Reduction Methods for Sustainable Deep Learning
Mar 22, 2024In recent years, Deep Learning has gained popularity for its ability to solve complex classification tasks, increasingly delivering better results thanks to the development of more accurate models, the availability of huge volumes of data and the improved computational capabilities of modern computers. However, these improvements in performance also bring efficiency problems, related to the storage of datasets and models, and to the waste of energy and time involved in both the training and inference processes. In this context, data reduction can help reduce energy consumption when training a deep learning model. In this paper, we present up to eight different methods to reduce the size of a tabular training dataset, and we develop a Python package to apply them. We also introduce a representativeness metric based on topology to measure how similar are the reduced datasets and the full training dataset. Additionally, we develop a methodology to apply these data reduction methods to image datasets for object detection tasks. Finally, we experimentally compare how these data reduction methods affect the representativeness of the reduced dataset, the energy consumption and the predictive performance of the model.
Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
Mar 22, 2024
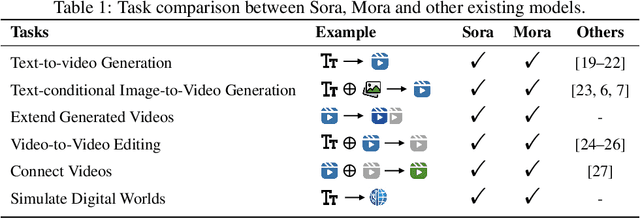
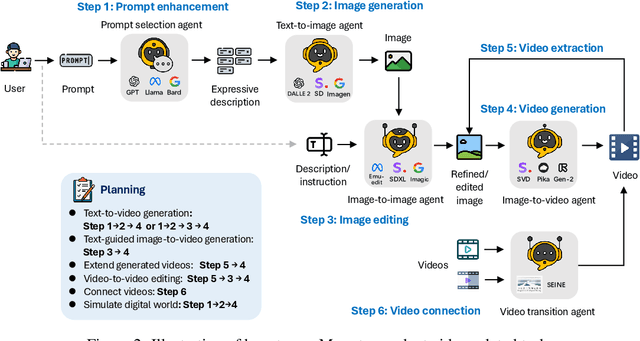
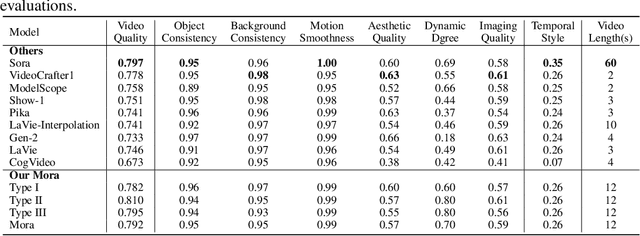
Sora is the first large-scale generalist video generation model that garnered significant attention across society. Since its launch by OpenAI in February 2024, no other video generation models have paralleled {Sora}'s performance or its capacity to support a broad spectrum of video generation tasks. Additionally, there are only a few fully published video generation models, with the majority being closed-source. To address this gap, this paper proposes a new multi-agent framework Mora, which incorporates several advanced visual AI agents to replicate generalist video generation demonstrated by Sora. In particular, Mora can utilize multiple visual agents and successfully mimic Sora's video generation capabilities in various tasks, such as (1) text-to-video generation, (2) text-conditional image-to-video generation, (3) extend generated videos, (4) video-to-video editing, (5) connect videos and (6) simulate digital worlds. Our extensive experimental results show that Mora achieves performance that is proximate to that of Sora in various tasks. However, there exists an obvious performance gap between our work and Sora when assessed holistically. In summary, we hope this project can guide the future trajectory of video generation through collaborative AI agents.
An edge detection-based deep learning approach for tear meniscus height measurement
Mar 23, 2024Automatic measurements of tear meniscus height (TMH) have been achieved by using deep learning techniques; however, annotation is significantly influenced by subjective factors and is both time-consuming and labor-intensive. In this paper, we introduce an automatic TMH measurement technique based on edge detection-assisted annotation within a deep learning framework. This method generates mask labels less affected by subjective factors with enhanced efficiency compared to previous annotation approaches. For improved segmentation of the pupil and tear meniscus areas, the convolutional neural network Inceptionv3 was first implemented as an image quality assessment model, effectively identifying higher-quality images with an accuracy of 98.224%. Subsequently, by using the generated labels, various algorithms, including Unet, ResUnet, Deeplabv3+FcnResnet101, Deeplabv3+FcnResnet50, FcnResnet50, and FcnResnet101 were trained, with Unet demonstrating the best performance. Finally, Unet was used for automatic pupil and tear meniscus segmentation to locate the center of the pupil and calculate TMH,respectively. An evaluation of the mask quality predicted by Unet indicated a Mean Intersection over Union of 0.9362, a recall of 0.9261, a precision of 0.9423, and an F1-Score of 0.9326. Additionally, the TMH predicted by the model was assessed, with the fitting curve represented as y= 0.982x-0.862, an overall correlation coefficient of r^2=0.961 , and an accuracy of 94.80% (237/250). In summary, the algorithm can automatically screen images based on their quality,segment the pupil and tear meniscus areas, and automatically measure TMH. Measurement results using the AI algorithm demonstrate a high level of consistency with manual measurements, offering significant support to clinical doctors in diagnosing dry eye disease.
DINOv2 based Self Supervised Learning For Few Shot Medical Image Segmentation
Mar 05, 2024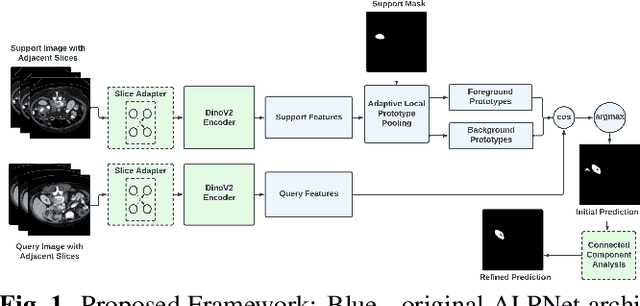
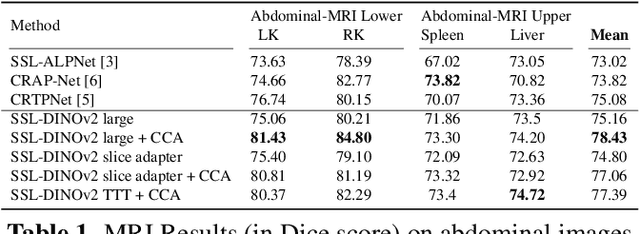
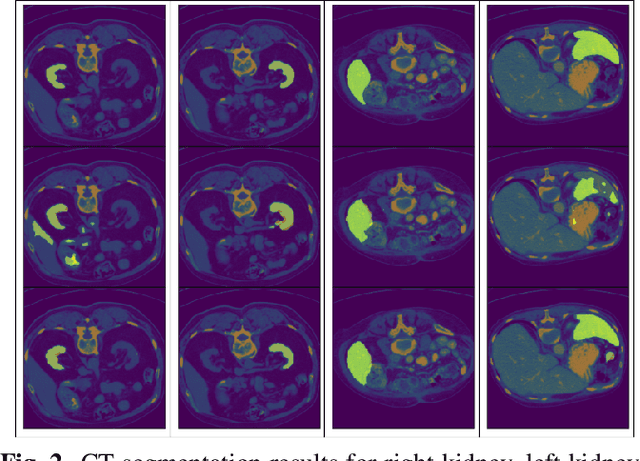
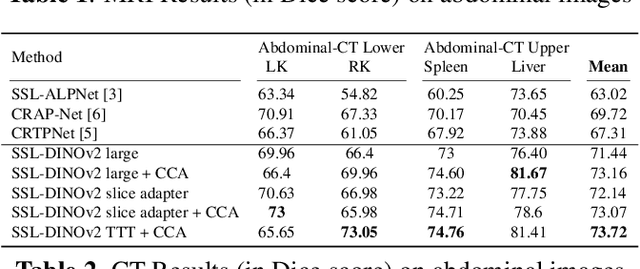
Deep learning models have emerged as the cornerstone of medical image segmentation, but their efficacy hinges on the availability of extensive manually labeled datasets and their adaptability to unforeseen categories remains a challenge. Few-shot segmentation (FSS) offers a promising solution by endowing models with the capacity to learn novel classes from limited labeled examples. A leading method for FSS is ALPNet, which compares features between the query image and the few available support segmented images. A key question about using ALPNet is how to design its features. In this work, we delve into the potential of using features from DINOv2, which is a foundational self-supervised learning model in computer vision. Leveraging the strengths of ALPNet and harnessing the feature extraction capabilities of DINOv2, we present a novel approach to few-shot segmentation that not only enhances performance but also paves the way for more robust and adaptable medical image analysis.
All in a Single Image: Large Multimodal Models are In-Image Learners
Feb 28, 2024This paper introduces a new in-context learning (ICL) mechanism called In-Image Learning (I$^2$L) that combines demonstration examples, visual cues, and instructions into a single image to enhance the capabilities of GPT-4V. Unlike previous approaches that rely on converting images to text or incorporating visual input into language models, I$^2$L consolidates all information into one image and primarily leverages image processing, understanding, and reasoning abilities. This has several advantages: it avoids inaccurate textual descriptions of complex images, provides flexibility in positioning demonstration examples, reduces the input burden, and avoids exceeding input limits by eliminating the need for multiple images and lengthy text. To further combine the strengths of different ICL methods, we introduce an automatic strategy to select the appropriate ICL method for a data example in a given task. We conducted experiments on MathVista and Hallusionbench to test the effectiveness of I$^2$L in complex multimodal reasoning tasks and mitigating language hallucination and visual illusion. Additionally, we explored the impact of image resolution, the number of demonstration examples, and their positions on the effectiveness of I$^2$L. Our code is publicly available at https://github.com/AGI-Edgerunners/IIL.
Image2Sentence based Asymmetrical Zero-shot Composed Image Retrieval
Mar 03, 2024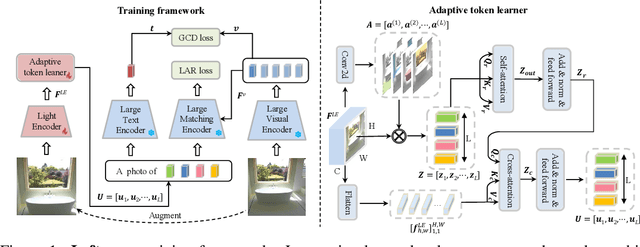
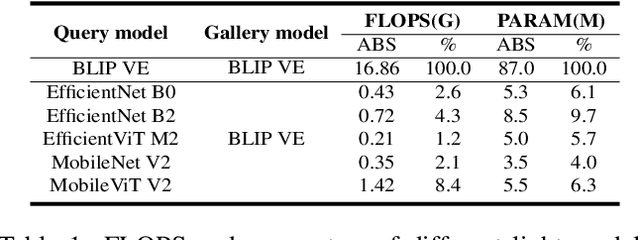
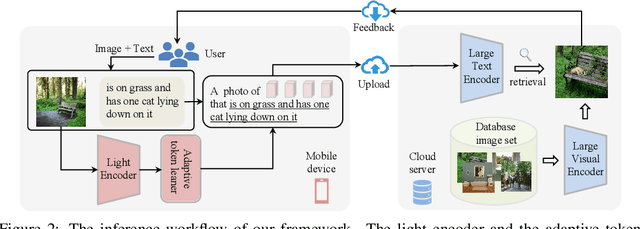
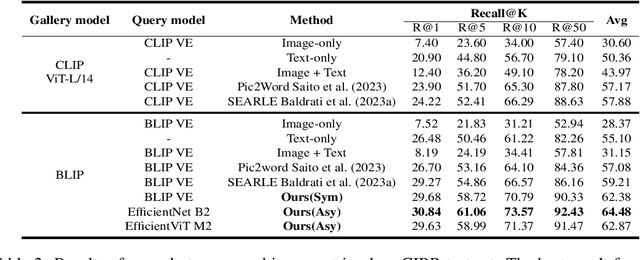
The task of composed image retrieval (CIR) aims to retrieve images based on the query image and the text describing the users' intent. Existing methods have made great progress with the advanced large vision-language (VL) model in CIR task, however, they generally suffer from two main issues: lack of labeled triplets for model training and difficulty of deployment on resource-restricted environments when deploying the large vision-language model. To tackle the above problems, we propose Image2Sentence based Asymmetric zero-shot composed image retrieval (ISA), which takes advantage of the VL model and only relies on unlabeled images for composition learning. In the framework, we propose a new adaptive token learner that maps an image to a sentence in the word embedding space of VL model. The sentence adaptively captures discriminative visual information and is further integrated with the text modifier. An asymmetric structure is devised for flexible deployment, in which the lightweight model is adopted for the query side while the large VL model is deployed on the gallery side. The global contrastive distillation and the local alignment regularization are adopted for the alignment between the light model and the VL model for CIR task. Our experiments demonstrate that the proposed ISA could better cope with the real retrieval scenarios and further improve retrieval accuracy and efficiency.
Augmented Reality based Simulated Data (ARSim) with multi-view consistency for AV perception networks
Mar 22, 2024Detecting a diverse range of objects under various driving scenarios is essential for the effectiveness of autonomous driving systems. However, the real-world data collected often lacks the necessary diversity presenting a long-tail distribution. Although synthetic data has been utilized to overcome this issue by generating virtual scenes, it faces hurdles such as a significant domain gap and the substantial efforts required from 3D artists to create realistic environments. To overcome these challenges, we present ARSim, a fully automated, comprehensive, modular framework designed to enhance real multi-view image data with 3D synthetic objects of interest. The proposed method integrates domain adaptation and randomization strategies to address covariate shift between real and simulated data by inferring essential domain attributes from real data and employing simulation-based randomization for other attributes. We construct a simplified virtual scene using real data and strategically place 3D synthetic assets within it. Illumination is achieved by estimating light distribution from multiple images capturing the surroundings of the vehicle. Camera parameters from real data are employed to render synthetic assets in each frame. The resulting augmented multi-view consistent dataset is used to train a multi-camera perception network for autonomous vehicles. Experimental results on various AV perception tasks demonstrate the superior performance of networks trained on the augmented dataset.