 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DDIPNet and DDIPNet+: Discriminant Deep Image Prior Networks for Remote Sensing Image Classification
Dec 20, 2022
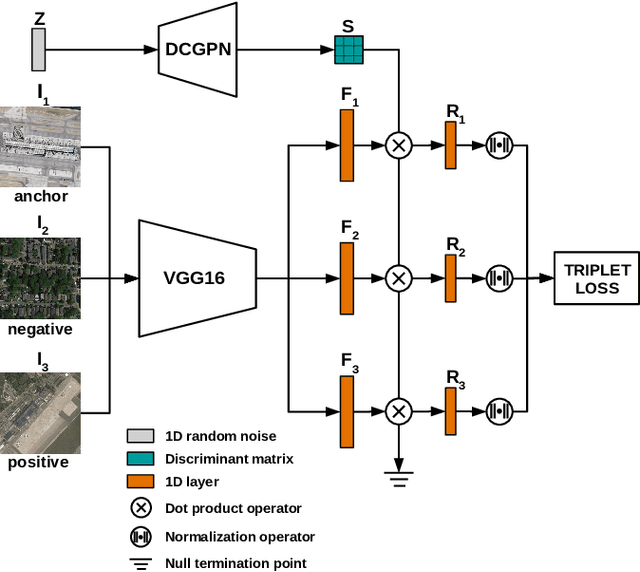
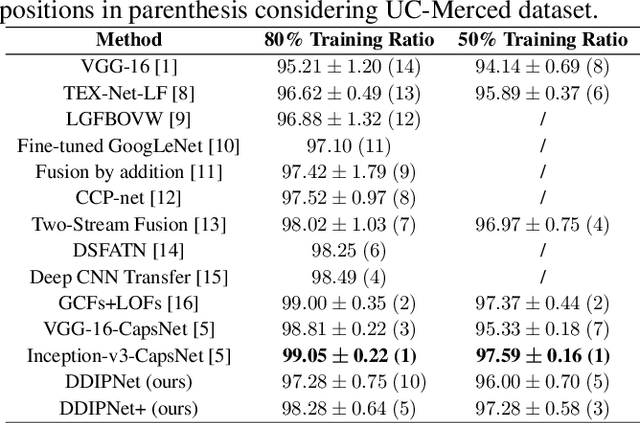
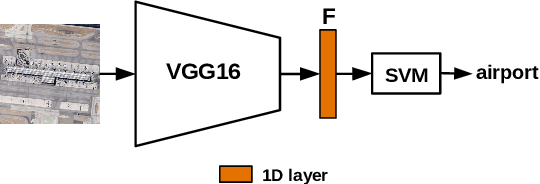
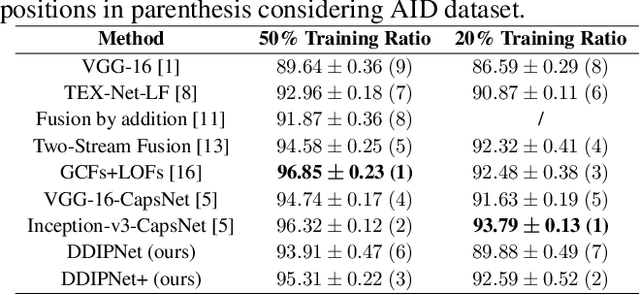
Research on remote sensing image classification significantly impacts essential human routine tasks such as urban planning and agriculture. Nowadays, the rapid advance in technology and the availability of many high-quality remote sensing images create a demand for reliable automation methods. The current paper proposes two novel deep learning-based architectures for image classification purposes, i.e., the Discriminant Deep Image Prior Network and the Discriminant Deep Image Prior Network+, which combine Deep Image Prior and Triplet Networks learning strategies. Experiments conducted over three well-known public remote sensing image datasets achieved state-of-the-art results, evidencing the effectiveness of using deep image priors for remote sensing image classification.
Image Compression with Product Quantized Masked Image Modeling
Dec 14, 2022
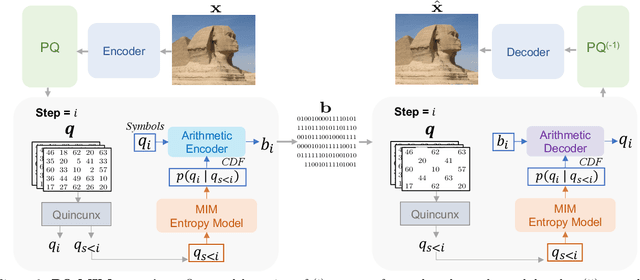
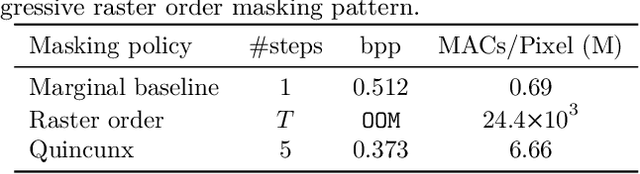
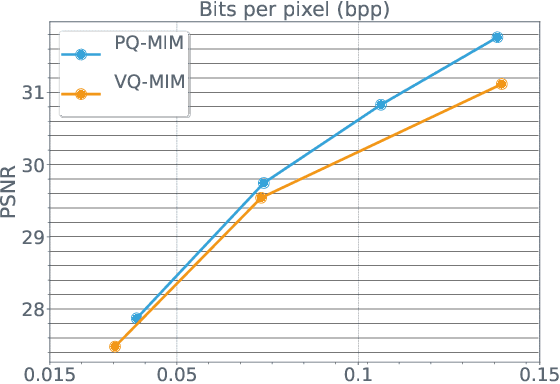
Recent neural compression methods have been based on the popular hyperprior framework. It relies on Scalar Quantization and offers a very strong compression performance. This contrasts from recent advances in image generation and representation learning, where Vector Quantization is more commonly employed. In this work, we attempt to bring these lines of research closer by revisiting vector quantization for image compression. We build upon the VQ-VAE framework and introduce several modifications. First, we replace the vanilla vector quantizer by a product quantizer. This intermediate solution between vector and scalar quantization allows for a much wider set of rate-distortion points: It implicitly defines high-quality quantizers that would otherwise require intractably large codebooks. Second, inspired by the success of Masked Image Modeling (MIM) in the context of self-supervised learning and generative image models, we propose a novel conditional entropy model which improves entropy coding by modelling the co-dependencies of the quantized latent codes. The resulting PQ-MIM model is surprisingly effective: its compression performance on par with recent hyperprior methods. It also outperforms HiFiC in terms of FID and KID metrics when optimized with perceptual losses (e.g. adversarial). Finally, since PQ-MIM is compatible with image generation frameworks, we show qualitatively that it can operate under a hybrid mode between compression and generation, with no further training or finetuning. As a result, we explore the extreme compression regime where an image is compressed into 200 bytes, i.e., less than a tweet.
AI in the Loop -- Functionalizing Fold Performance Disagreement to Monitor Automated Medical Image Segmentation Pipelines
May 15, 2023
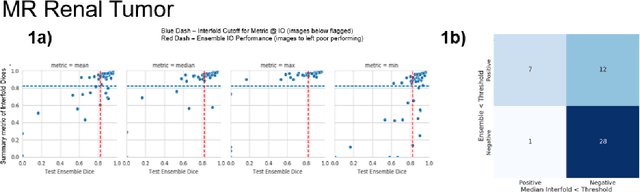
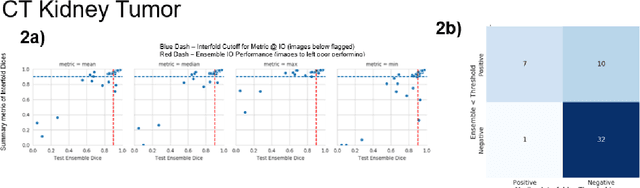
Methods for automatically flag poor performing-predictions are essential for safely implementing machine learning workflows into clinical practice and for identifying difficult cases during model training. We present a readily adoptable method using sub-models trained on different dataset folds, where their disagreement serves as a surrogate for model confidence. Thresholds informed by human interobserver values were used to determine whether a final ensemble model prediction would require manual review. In two different datasets (abdominal CT and MR predicting kidney tumors), our framework effectively identified low performing automated segmentations. Flagging images with a minimum Interfold test Dice score below human interobserver variability maximized the number of flagged images while ensuring maximum ensemble test Dice. When our internally trained model was applied to an external publicly available dataset (KiTS21), flagged images included smaller tumors than those observed in our internally trained dataset, demonstrating the methods robustness to flagging poor performing out-of-distribution input data. Comparing interfold sub-model disagreement against human interobserver values is an efficient way to approximate a model's epistemic uncertainty - its lack of knowledge due to insufficient relevant training data - a key functionality for adopting these applications in clinical practice.
Comparative study of Transformer and LSTM Network with attention mechanism on Image Captioning
Mar 05, 2023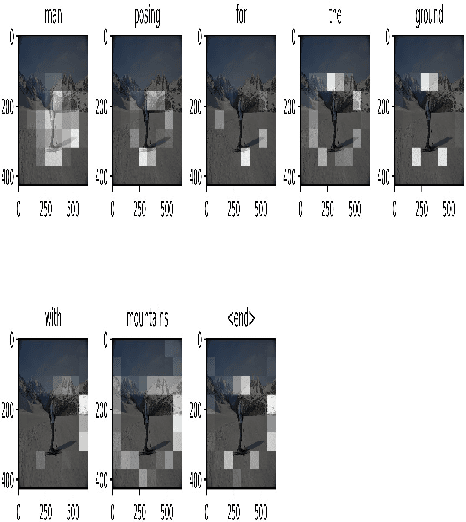
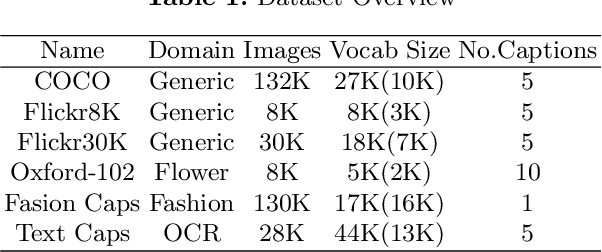
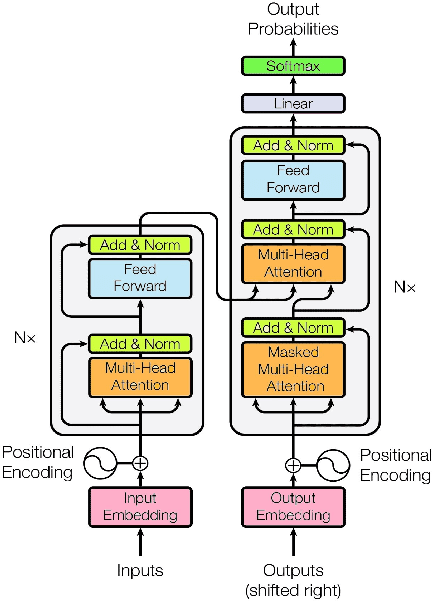
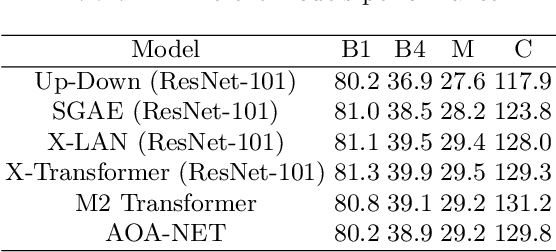
In a globalized world at the present epoch of generative intelligence, most of the manual labour tasks are automated with increased efficiency. This can support businesses to save time and money. A crucial component of generative intelligence is the integration of vision and language. Consequently, image captioning become an intriguing area of research. There have been multiple attempts by the researchers to solve this problem with different deep learning architectures, although the accuracy has increased, but the results are still not up to standard. This study buckles down to the comparison of Transformer and LSTM with attention block model on MS-COCO dataset, which is a standard dataset for image captioning. For both the models we have used pretrained Inception-V3 CNN encoder for feature extraction of the images. The Bilingual Evaluation Understudy score (BLEU) is used to checked the accuracy of caption generated by both models. Along with the transformer and LSTM with attention block models,CLIP-diffusion model, M2-Transformer model and the X-Linear Attention model have been discussed with state of the art accuracy.
A residual dense vision transformer for medical image super-resolution with segmentation-based perceptual loss fine-tuning
Feb 22, 2023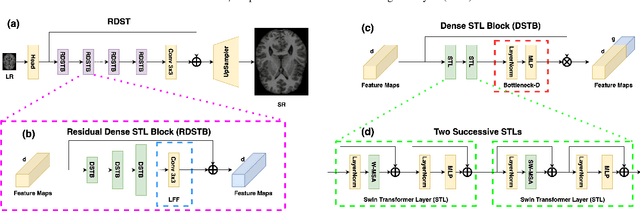
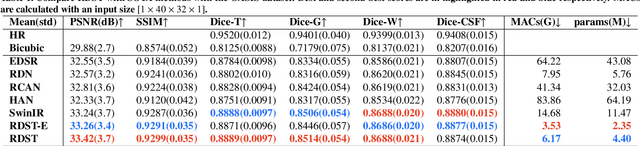
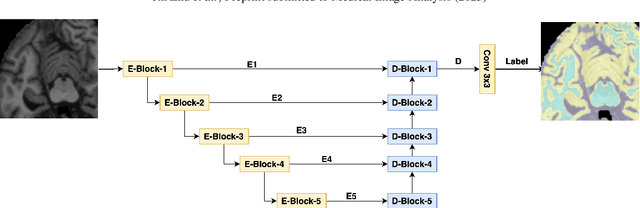

Super-resolution plays an essential role in medical imaging because it provides an alternative way to achieve high spatial resolutions and image quality with no extra acquisition costs. In the past few decades, the rapid development of deep neural networks has promoted super-resolution performance with novel network architectures, loss functions and evaluation metrics. Specifically, vision transformers dominate a broad range of computer vision tasks, but challenges still exist when applying them to low-level medical image processing tasks. This paper proposes an efficient vision transformer with residual dense connections and local feature fusion, aiming to achieve efficient single-image super-resolution (SISR) of medical modalities. Moreover, we implement a general-purpose perceptual loss with manual control for image quality improvements of desired aspects by incorporating prior knowledge of medical image segmentation. Compared with state-of-the-art methods on four public medical image datasets, the proposed method achieves the best PSNR scores of 6 modalities among seven modalities in total. It leads to an average improvement of $+0.09$ dB PSNR with only 38\% parameters of SwinIR. On the other hand, the segmentation-based perceptual loss increases $+0.14$ dB PSNR on average for SOTA methods, including CNNs and vision transformers. Additionally, we conduct comprehensive ablation studies to discuss potential factors for the superior performance of vision transformers over CNNs and the impacts of network and loss function components.
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Jun 05, 2023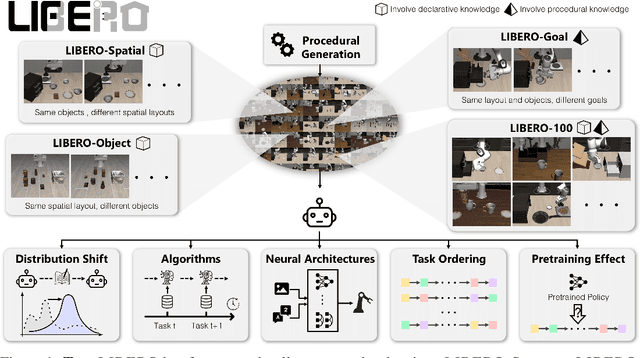
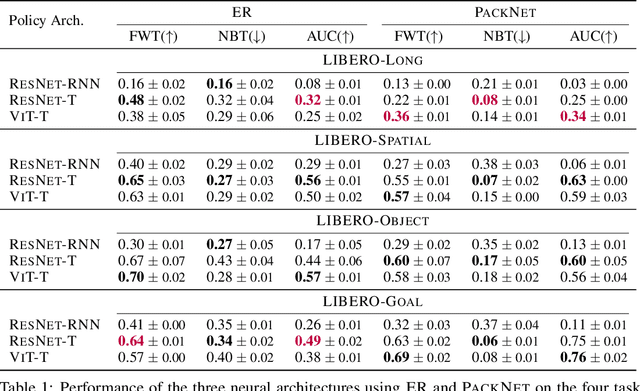
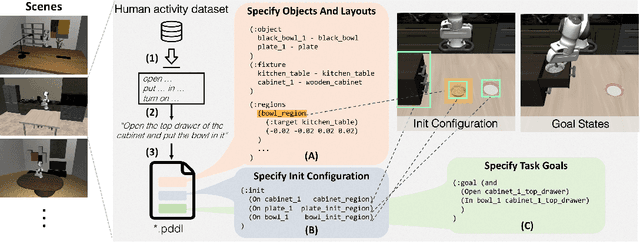
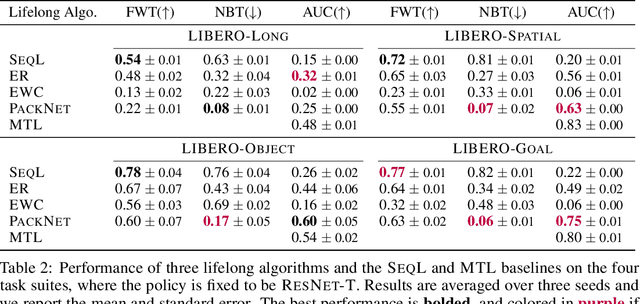
Lifelong learning offers a promising paradigm of building a generalist agent that learns and adapts over its lifespan. Unlike traditional lifelong learning problems in image and text domains, which primarily involve the transfer of declarative knowledge of entities and concepts, lifelong learning in decision-making (LLDM) also necessitates the transfer of procedural knowledge, such as actions and behaviors. To advance research in LLDM, we introduce LIBERO, a novel benchmark of lifelong learning for robot manipulation. Specifically, LIBERO highlights five key research topics in LLDM: 1) how to efficiently transfer declarative knowledge, procedural knowledge, or the mixture of both; 2) how to design effective policy architectures and 3) effective algorithms for LLDM; 4) the robustness of a lifelong learner with respect to task ordering; and 5) the effect of model pretraining for LLDM. We develop an extendible procedural generation pipeline that can in principle generate infinitely many tasks. For benchmarking purpose, we create four task suites (130 tasks in total) that we use to investigate the above-mentioned research topics. To support sample-efficient learning, we provide high-quality human-teleoperated demonstration data for all tasks. Our extensive experiments present several insightful or even unexpected discoveries: sequential finetuning outperforms existing lifelong learning methods in forward transfer, no single visual encoder architecture excels at all types of knowledge transfer, and naive supervised pretraining can hinder agents' performance in the subsequent LLDM. Check the website at https://libero-project.github.io for the code and the datasets.
Clinically Relevant Latent Space Embedding of Cancer Histopathology Slides through Variational Autoencoder Based Image Compression
Mar 23, 2023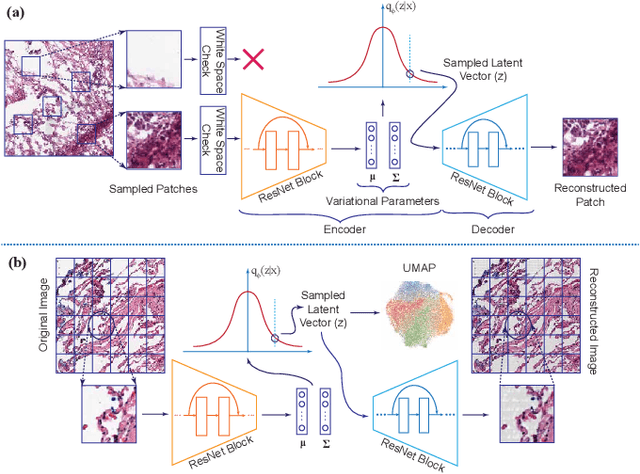
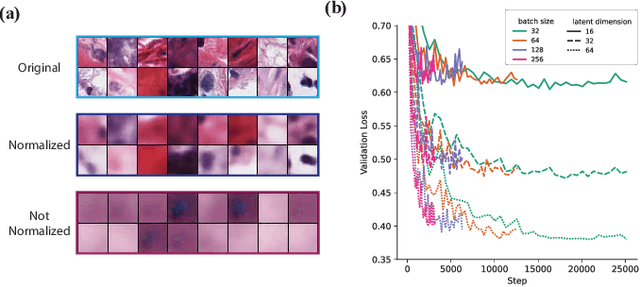

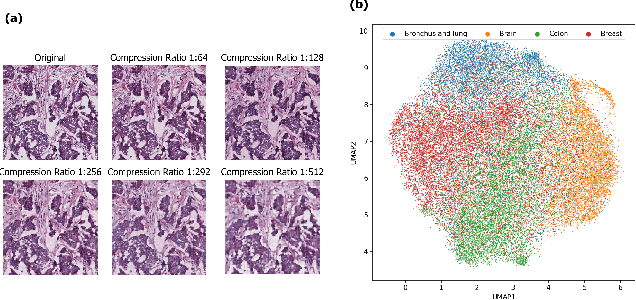
In this paper, we introduce a Variational Autoencoder (VAE) based training approach that can compress and decompress cancer pathology slides at a compression ratio of 1:512, which is better than the previously reported state of the art (SOTA) in the literature, while still maintaining accuracy in clinical validation tasks. The compression approach was tested on more common computer vision datasets such as CIFAR10, and we explore which image characteristics enable this compression ratio on cancer imaging data but not generic images. We generate and visualize embeddings from the compressed latent space and demonstrate how they are useful for clinical interpretation of data, and how in the future such latent embeddings can be used to accelerate search of clinical imaging data.
On-board Change Detection for Resource-efficient Earth Observation with LEO Satellites
May 17, 2023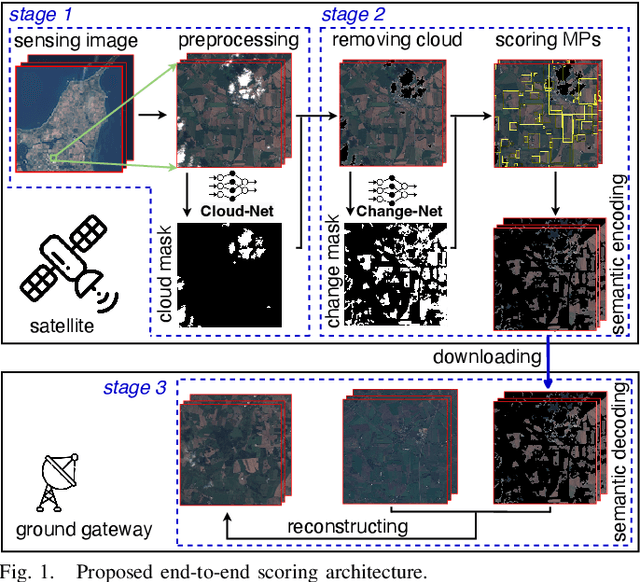
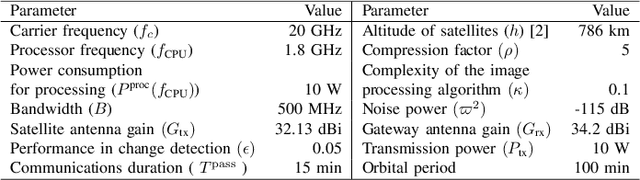
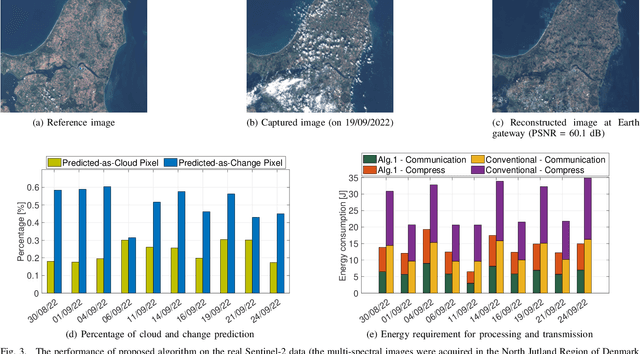
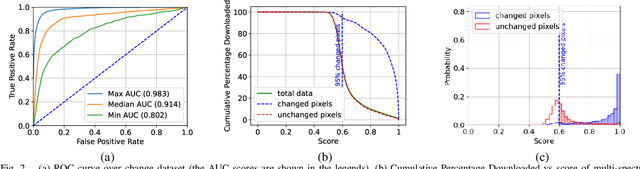
The amount of data generated by Earth observation satellites can be enormous, which poses a great challenge to the satellite-to-ground connections with limited rate. This paper considers problem of efficient downlink communication of multi-spectral satellite images for Earth observation using change detection. The proposed method for image processing consists of the joint design of cloud removal and change encoding, which can be seen as an instance of semantic communication, as it encodes important information, such as changed multi-spectral pixels (MPs), while aiming to minimize energy consumption. It comprises a three-stage end-to-end scoring mechanism that determines the importance of each MP before deciding its transmission. Specifically, the sensing image is (1) standardized, (2) passed through a high-performance cloud filtering via the Cloud-Net model, and (3) passed to the proposed scoring algorithm that uses Change-Net to identify MPs that have a high likelihood of being changed, compress them and forward the result to the ground station. The experimental results indicate that the proposed framework is effective in optimizing energy usage while preserving high-quality data transmission in satellite-based Earth observation applications.
Masked Image Modeling with Local Multi-Scale Reconstruction
Mar 09, 2023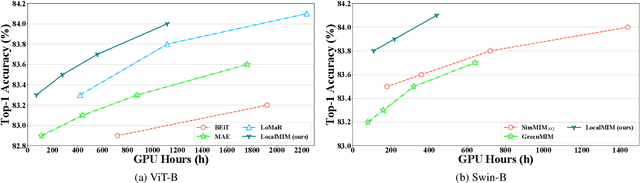
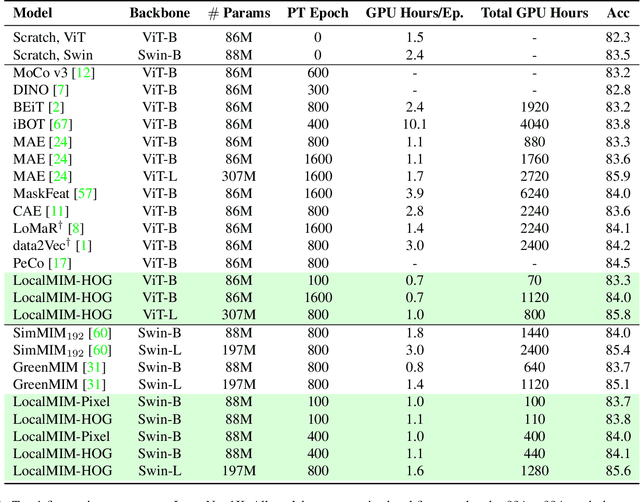
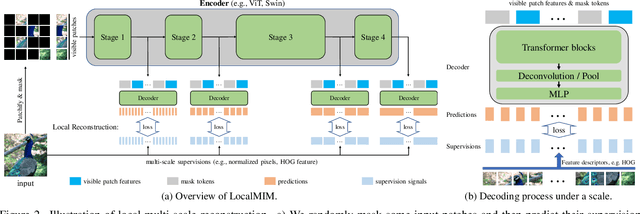
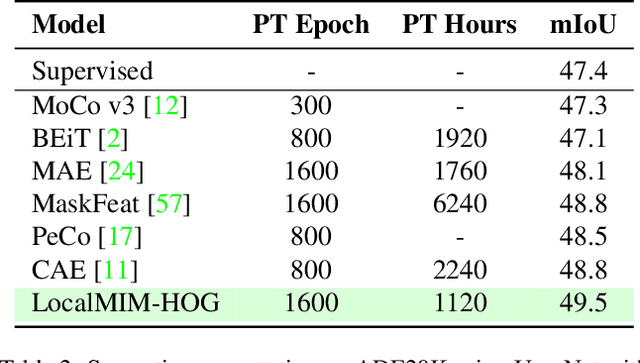
Masked Image Modeling (MIM) achieves outstanding success in self-supervised representation learning. Unfortunately, MIM models typically have huge computational burden and slow learning process, which is an inevitable obstacle for their industrial applications. Although the lower layers play the key role in MIM, existing MIM models conduct reconstruction task only at the top layer of encoder. The lower layers are not explicitly guided and the interaction among their patches is only used for calculating new activations. Considering the reconstruction task requires non-trivial inter-patch interactions to reason target signals, we apply it to multiple local layers including lower and upper layers. Further, since the multiple layers expect to learn the information of different scales, we design local multi-scale reconstruction, where the lower and upper layers reconstruct fine-scale and coarse-scale supervision signals respectively. This design not only accelerates the representation learning process by explicitly guiding multiple layers, but also facilitates multi-scale semantical understanding to the input. Extensive experiments show that with significantly less pre-training burden, our model achieves comparable or better performance on classification, detection and segmentation tasks than existing MIM models.
SF-FSDA: Source-Free Few-Shot Domain Adaptive Object Detection with Efficient Labeled Data Factory
Jun 07, 2023
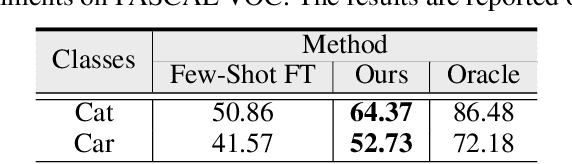
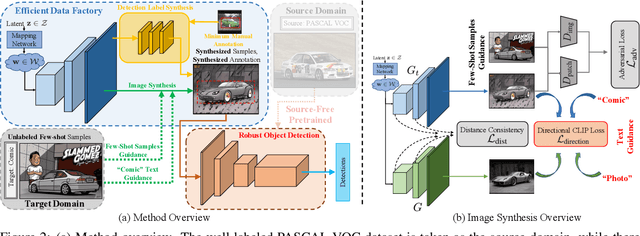
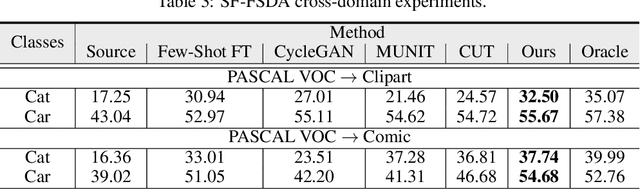
Domain adaptive object detection aims to leverage the knowledge learned from a labeled source domain to improve the performance on an unlabeled target domain. Prior works typically require the access to the source domain data for adaptation, and the availability of sufficient data on the target domain. However, these assumptions may not hold due to data privacy and rare data collection. In this paper, we propose and investigate a more practical and challenging domain adaptive object detection problem under both source-free and few-shot conditions, named as SF-FSDA. To overcome this problem, we develop an efficient labeled data factory based approach. Without accessing the source domain, the data factory renders i) infinite amount of synthesized target-domain like images, under the guidance of the few-shot image samples and text description from the target domain; ii) corresponding bounding box and category annotations, only demanding minimum human effort, i.e., a few manually labeled examples. On the one hand, the synthesized images mitigate the knowledge insufficiency brought by the few-shot condition. On the other hand, compared to the popular pseudo-label technique, the generated annotations from data factory not only get rid of the reliance on the source pretrained object detection model, but also alleviate the unavoidably pseudo-label noise due to domain shift and source-free condition. The generated dataset is further utilized to adapt the source pretrained object detection model, realizing the robust object detection under SF-FSDA. The experiments on different settings showcase that our proposed approach outperforms other state-of-the-art methods on SF-FSDA problem. Our codes and models will be made publicly available.