 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Brain-inspired learning in artificial neural networks: a review
May 18, 2023
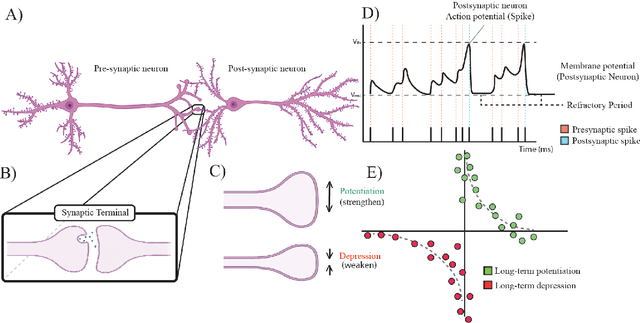
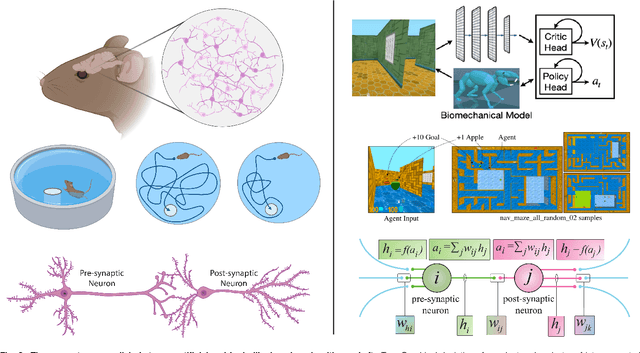
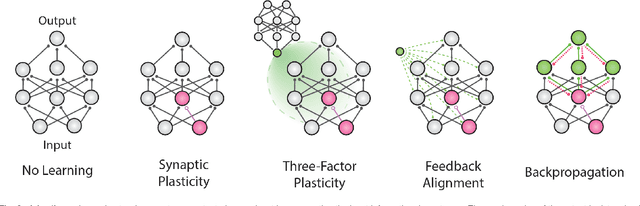
Artificial neural networks (ANNs) have emerged as an essential tool in machine learning, achieving remarkable success across diverse domains, including image and speech generation, game playing, and robotics. However, there exist fundamental differences between ANNs' operating mechanisms and those of the biological brain, particularly concerning learning processes. This paper presents a comprehensive review of current brain-inspired learning representations in artificial neural networks. We investigate the integration of more biologically plausible mechanisms, such as synaptic plasticity, to enhance these networks' capabilities. Moreover, we delve into the potential advantages and challenges accompanying this approach. Ultimately, we pinpoint promising avenues for future research in this rapidly advancing field, which could bring us closer to understanding the essence of intelligence.
Deep Image Fingerprint: Accurate And Low Budget Synthetic Image Detector
Mar 28, 2023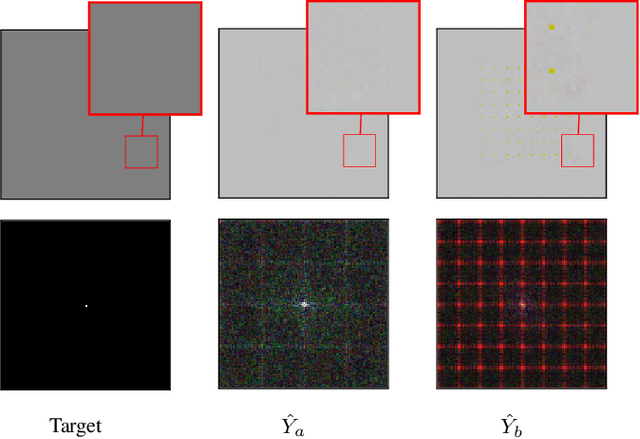
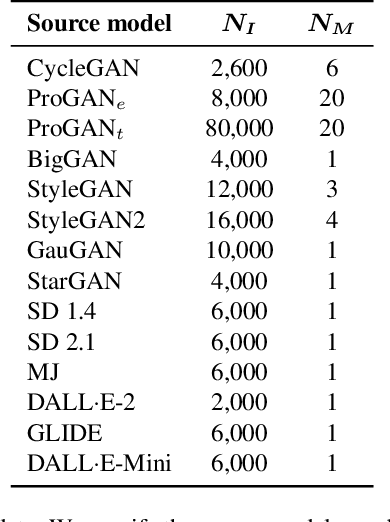
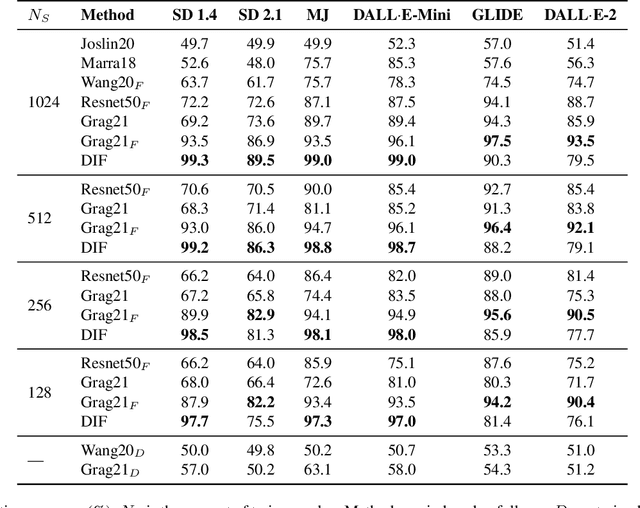
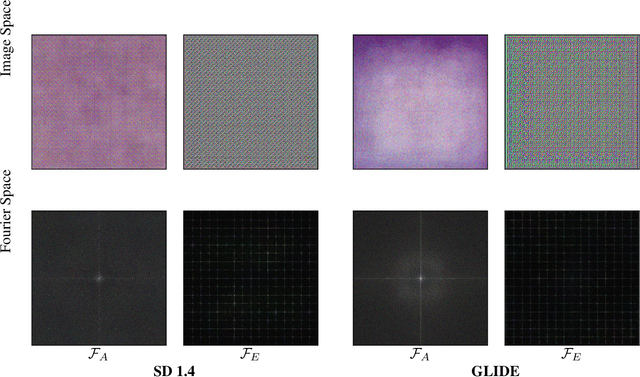
The generation of high-quality images has become widely accessible and is a rapidly evolving process. As a result, anyone can generate images that are indistinguishable from real ones. This leads to a wide range of applications, which also include malicious usage with deception in mind. Despite advances in detection techniques for generated images, a robust detection method still eludes us. In this work, we utilize the inductive bias of convolutional neural networks (CNNs) to develop a new detection method that requires a small amount of training samples and achieves accuracy that is on par or better than current state-of-the-art methods.
RSIR Transformer: Hierarchical Vision Transformer using Random Sampling Windows and Important Region Windows
Apr 27, 2023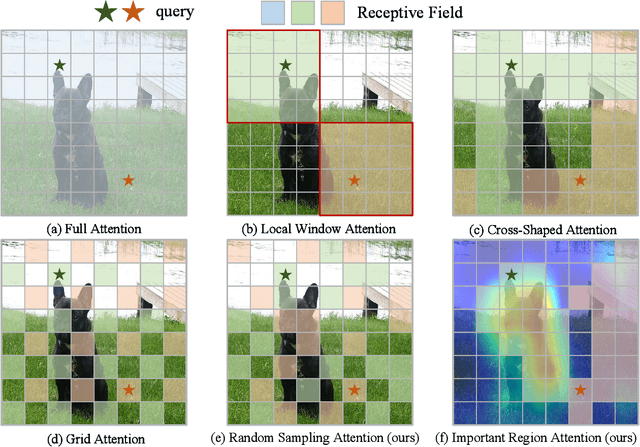
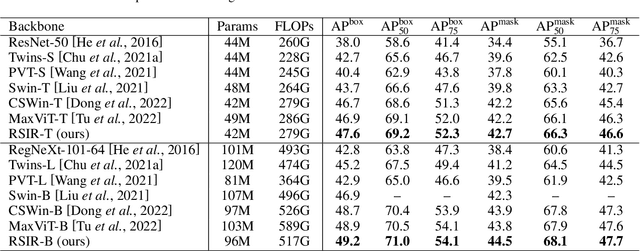
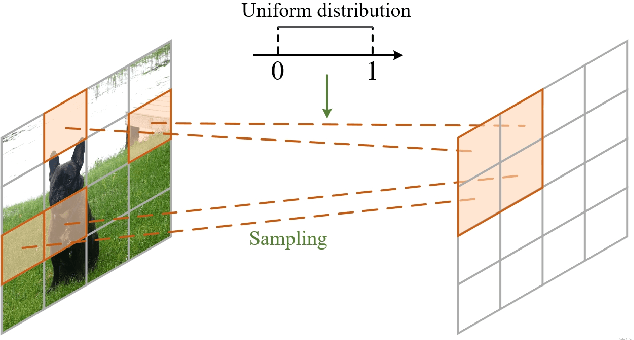
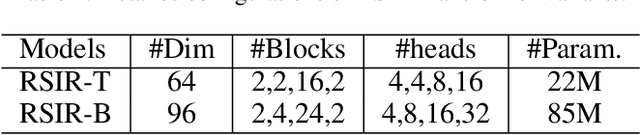
Recently, Transformers have shown promising performance in various vision tasks. However, the high costs of global self-attention remain challenging for Transformers, especially for high-resolution vision tasks. Local self-attention runs attention computation within a limited region for the sake of efficiency, resulting in insufficient context modeling as their receptive fields are small. In this work, we introduce two new attention modules to enhance the global modeling capability of the hierarchical vision transformer, namely, random sampling windows (RS-Win) and important region windows (IR-Win). Specifically, RS-Win sample random image patches to compose the window, following a uniform distribution, i.e., the patches in RS-Win can come from any position in the image. IR-Win composes the window according to the weights of the image patches in the attention map. Notably, RS-Win is able to capture global information throughout the entire model, even in earlier, high-resolution stages. IR-Win enables the self-attention module to focus on important regions of the image and capture more informative features. Incorporated with these designs, RSIR-Win Transformer demonstrates competitive performance on common vision tasks.
ConZIC: Controllable Zero-shot Image Captioning by Sampling-Based Polishing
Mar 09, 2023
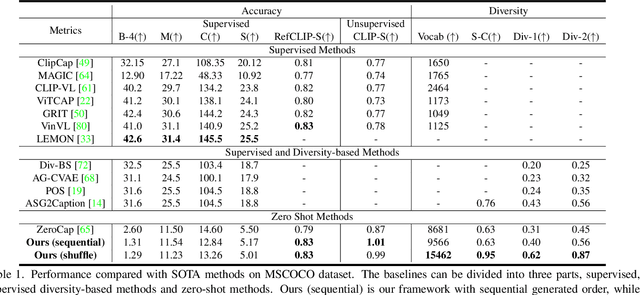
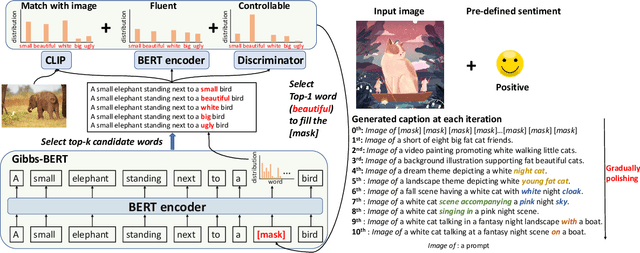
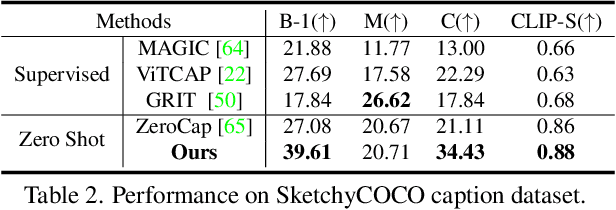
Zero-shot capability has been considered as a new revolution of deep learning, letting machines work on tasks without curated training data. As a good start and the only existing outcome of zero-shot image captioning (IC), ZeroCap abandons supervised training and sequentially searches every word in the caption using the knowledge of large-scale pretrained models. Though effective, its autoregressive generation and gradient-directed searching mechanism limit the diversity of captions and inference speed, respectively. Moreover, ZeroCap does not consider the controllability issue of zero-shot IC. To move forward, we propose a framework for Controllable Zero-shot IC, named ConZIC. The core of ConZIC is a novel sampling-based non-autoregressive language model named GibbsBERT, which can generate and continuously polish every word. Extensive quantitative and qualitative results demonstrate the superior performance of our proposed ConZIC for both zero-shot IC and controllable zero-shot IC. Especially, ConZIC achieves about 5x faster generation speed than ZeroCap, and about 1.5x higher diversity scores, with accurate generation given different control signals.
Hyperspectral Image Super Resolution with Real Unaligned RGB Guidance
Feb 13, 2023

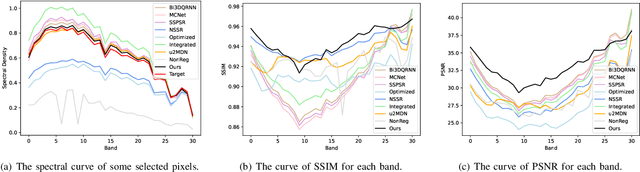
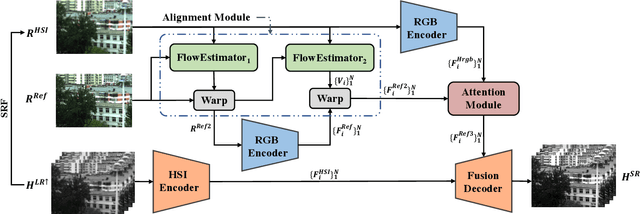
Fusion-based hyperspectral image (HSI) super-resolution has become increasingly prevalent for its capability to integrate high-frequency spatial information from the paired high-resolution (HR) RGB reference image. However, most of the existing methods either heavily rely on the accurate alignment between low-resolution (LR) HSIs and RGB images, or can only deal with simulated unaligned RGB images generated by rigid geometric transformations, which weakens their effectiveness for real scenes. In this paper, we explore the fusion-based HSI super-resolution with real RGB reference images that have both rigid and non-rigid misalignments. To properly address the limitations of existing methods for unaligned reference images, we propose an HSI fusion network with heterogenous feature extractions, multi-stage feature alignments, and attentive feature fusion. Specifically, our network first transforms the input HSI and RGB images into two sets of multi-scale features with an HSI encoder and an RGB encoder, respectively. The features of RGB reference images are then processed by a multi-stage alignment module to explicitly align the features of RGB reference with the LR HSI. Finally, the aligned features of RGB reference are further adjusted by an adaptive attention module to focus more on discriminative regions before sending them to the fusion decoder to generate the reconstructed HR HSI. Additionally, we collect a real-world HSI fusion dataset, consisting of paired HSI and unaligned RGB reference, to support the evaluation of the proposed model for real scenes. Extensive experiments are conducted on both simulated and our real-world datasets, and it shows that our method obtains a clear improvement over existing single-image and fusion-based super-resolution methods on quantitative assessment as well as visual comparison.
TextDiffuser: Diffusion Models as Text Painters
May 24, 2023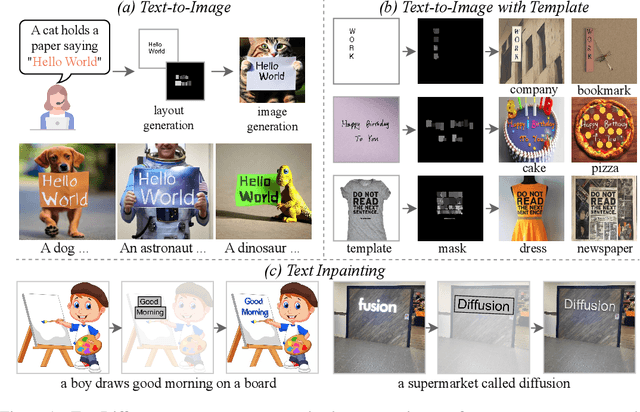
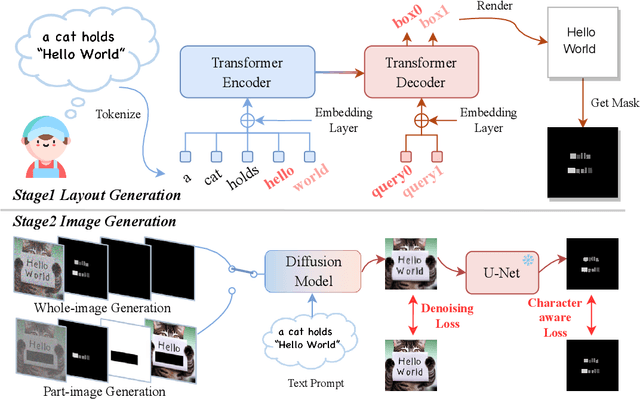
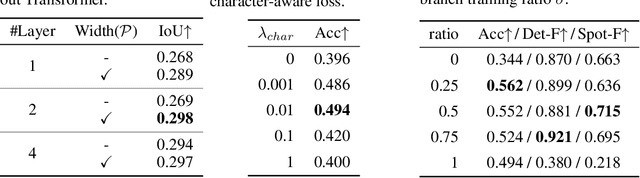

Diffusion models have gained increasing attention for their impressive generation abilities but currently struggle with rendering accurate and coherent text. To address this issue, we introduce TextDiffuser, focusing on generating images with visually appealing text that is coherent with backgrounds. TextDiffuser consists of two stages: first, a Transformer model generates the layout of keywords extracted from text prompts, and then diffusion models generate images conditioned on the text prompt and the generated layout. Additionally, we contribute the first large-scale text images dataset with OCR annotations, MARIO-10M, containing 10 million image-text pairs with text recognition, detection, and character-level segmentation annotations. We further collect the MARIO-Eval benchmark to serve as a comprehensive tool for evaluating text rendering quality. Through experiments and user studies, we show that TextDiffuser is flexible and controllable to create high-quality text images using text prompts alone or together with text template images, and conduct text inpainting to reconstruct incomplete images with text. The code, model, and dataset will be available at \url{https://aka.ms/textdiffuser}.
Prompt Evolution for Generative AI: A Classifier-Guided Approach
May 24, 2023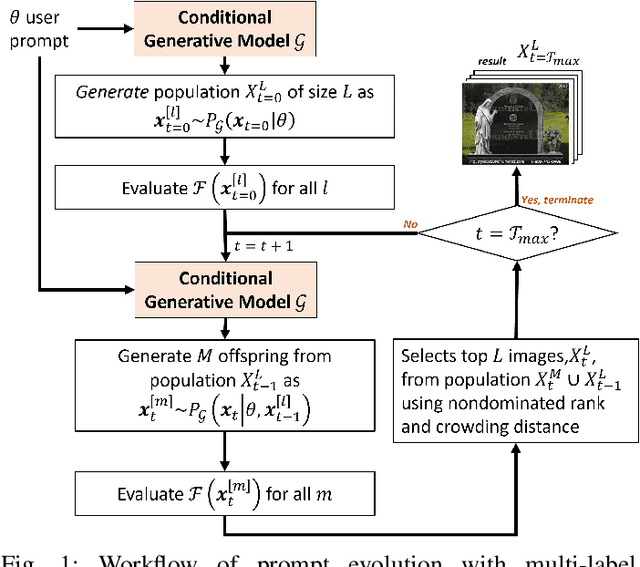
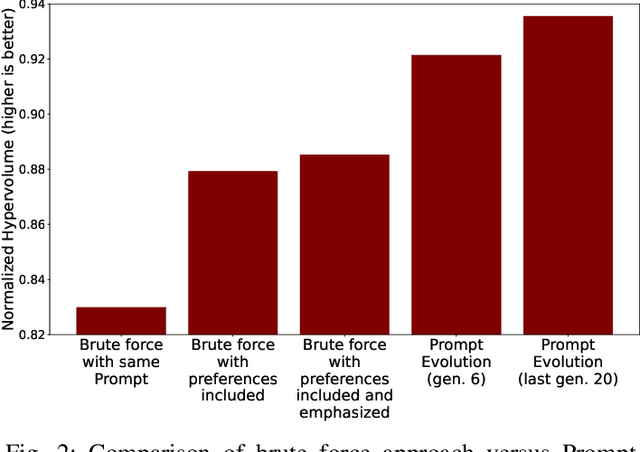
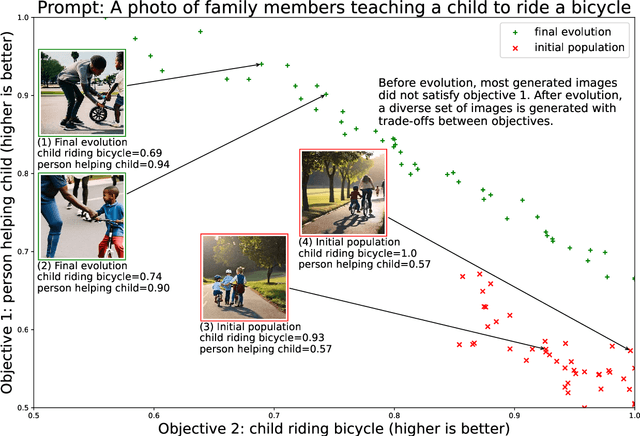

Synthesis of digital artifacts conditioned on user prompts has become an important paradigm facilitating an explosion of use cases with generative AI. However, such models often fail to connect the generated outputs and desired target concepts/preferences implied by the prompts. Current research addressing this limitation has largely focused on enhancing the prompts before output generation or improving the model's performance up front. In contrast, this paper conceptualizes prompt evolution, imparting evolutionary selection pressure and variation during the generative process to produce multiple outputs that satisfy the target concepts/preferences better. We propose a multi-objective instantiation of this broader idea that uses a multi-label image classifier-guided approach. The predicted labels from the classifiers serve as multiple objectives to optimize, with the aim of producing diversified images that meet user preferences. A novelty of our evolutionary algorithm is that the pre-trained generative model gives us implicit mutation operations, leveraging the model's stochastic generative capability to automate the creation of Pareto-optimized images more faithful to user preferences.
Cream: Visually-Situated Natural Language Understanding with Contrastive Reading Model and Frozen Large Language Models
May 24, 2023
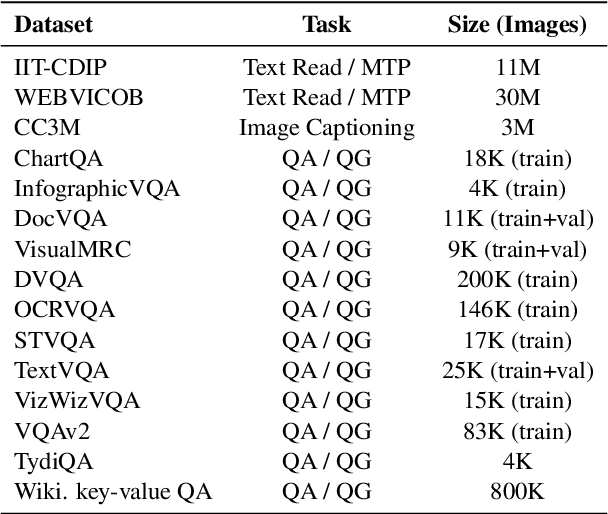
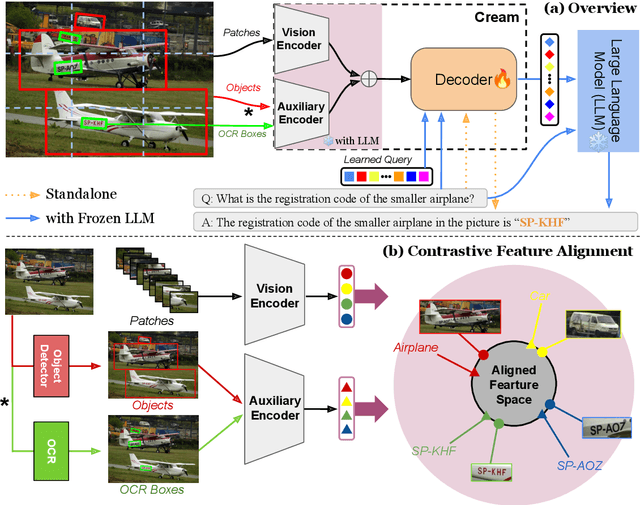

Advances in Large Language Models (LLMs) have inspired a surge of research exploring their expansion into the visual domain. While recent models exhibit promise in generating abstract captions for images and conducting natural conversations, their performance on text-rich images leaves room for improvement. In this paper, we propose the Contrastive Reading Model (Cream), a novel neural architecture designed to enhance the language-image understanding capability of LLMs by capturing intricate details typically overlooked by existing methods. Cream integrates vision and auxiliary encoders, complemented by a contrastive feature alignment technique, resulting in a more effective understanding of textual information within document images. Our approach, thus, seeks to bridge the gap between vision and language understanding, paving the way for more sophisticated Document Intelligence Assistants. Rigorous evaluations across diverse tasks, such as visual question answering on document images, demonstrate the efficacy of Cream as a state-of-the-art model in the field of visual document understanding. We provide our codebase and newly-generated datasets at https://github.com/naver-ai/cream
Text encoders are performance bottlenecks in contrastive vision-language models
May 24, 2023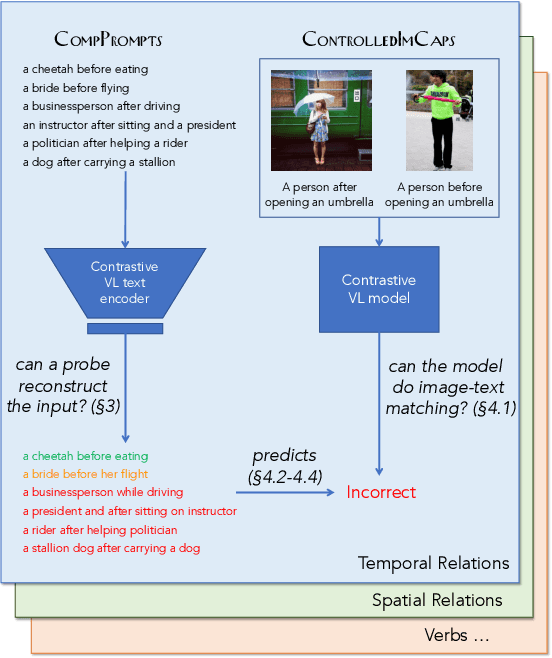
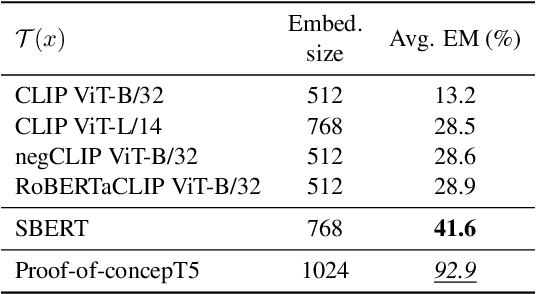
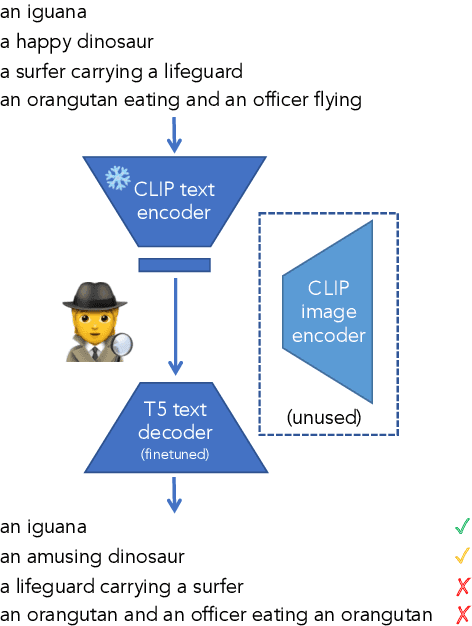
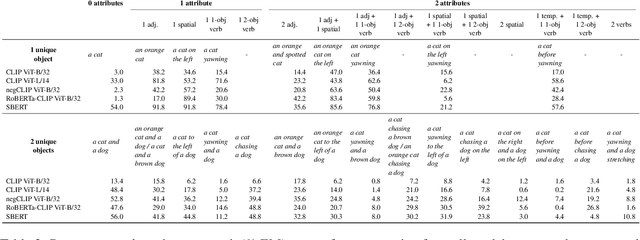
Performant vision-language (VL) models like CLIP represent captions using a single vector. How much information about language is lost in this bottleneck? We first curate CompPrompts, a set of increasingly compositional image captions that VL models should be able to capture (e.g., single object, to object+property, to multiple interacting objects). Then, we train text-only recovery probes that aim to reconstruct captions from single-vector text representations produced by several VL models. This approach doesn't require images, allowing us to test on a broader range of scenes compared to prior work. We find that: 1) CLIP's text encoder falls short on object relationships, attribute-object association, counting, and negations; 2) some text encoders work significantly better than others; and 3) text-only recovery performance predicts multi-modal matching performance on ControlledImCaps: a new evaluation benchmark we collect+release consisting of fine-grained compositional images+captions. Specifically -- our results suggest text-only recoverability is a necessary (but not sufficient) condition for modeling compositional factors in contrastive vision+language models. We release data+code.
Relating Implicit Bias and Adversarial Attacks through Intrinsic Dimension
May 24, 2023
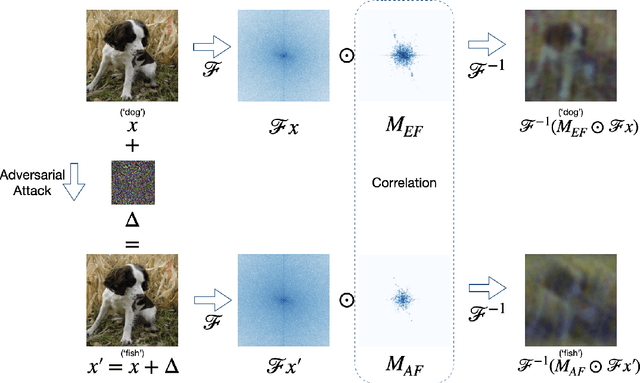
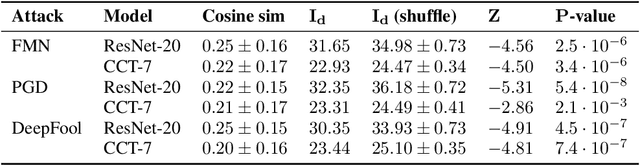

Despite their impressive performance in classification, neural networks are known to be vulnerable to adversarial attacks. These attacks are small perturbations of the input data designed to fool the model. Naturally, a question arises regarding the potential connection between the architecture, settings, or properties of the model and the nature of the attack. In this work, we aim to shed light on this problem by focusing on the implicit bias of the neural network, which refers to its inherent inclination to favor specific patterns or outcomes. Specifically, we investigate one aspect of the implicit bias, which involves the essential Fourier frequencies required for accurate image classification. We conduct tests to assess the statistical relationship between these frequencies and those necessary for a successful attack. To delve into this relationship, we propose a new method that can uncover non-linear correlations between sets of coordinates, which, in our case, are the aforementioned frequencies. By exploiting the entanglement between intrinsic dimension and correlation, we provide empirical evidence that the network bias in Fourier space and the target frequencies of adversarial attacks are closely tied.