 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Component-aware anomaly detection framework for adjustable and logical industrial visual inspection
May 15, 2023

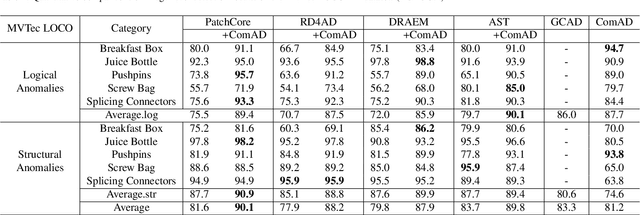


Industrial visual inspection aims at detecting surface defects in products during the manufacturing process. Although existing anomaly detection models have shown great performance on many public benchmarks, their limited adjustability and ability to detect logical anomalies hinder their broader use in real-world settings. To this end, in this paper, we propose a novel component-aware anomaly detection framework (ComAD) which can simultaneously achieve adjustable and logical anomaly detection for industrial scenarios. Specifically, we propose to segment images into multiple components based on a lightweight and nearly training-free unsupervised semantic segmentation model. Then, we design an interpretable logical anomaly detection model through modeling the metrological features of each component and their relationships. Despite its simplicity, our framework achieves state-of-the-art performance on image-level logical anomaly detection. Meanwhile, segmenting a product image into multiple components provides a novel perspective for industrial visual inspection, demonstrating great potential in model customization, noise resistance, and anomaly classification. The code will be available at https://github.com/liutongkun/ComAD.
A Novel Framework for Multimodal Named Entity Recognition with Multi-level Alignments
May 15, 2023
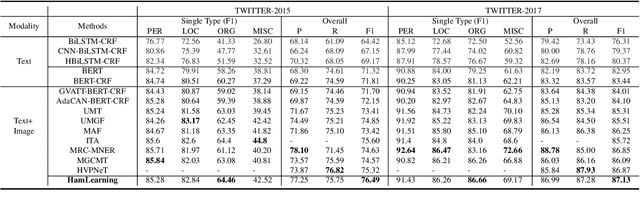
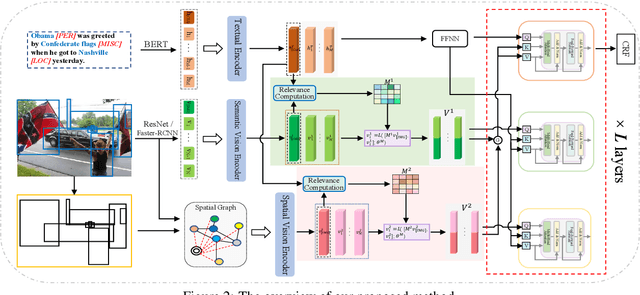
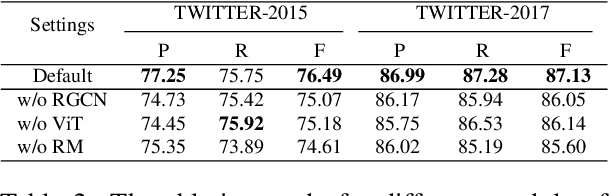
Mining structured knowledge from tweets using named entity recognition (NER) can be beneficial for many downstream applications such as recommendation and intention under standing. With tweet posts tending to be multimodal, multimodal named entity recognition (MNER) has attracted more attention. In this paper, we propose a novel approach, which can dynamically align the image and text sequence and achieve the multi-level cross-modal learning to augment textual word representation for MNER improvement. To be specific, our framework can be split into three main stages: the first stage focuses on intra-modality representation learning to derive the implicit global and local knowledge of each modality, the second evaluates the relevance between the text and its accompanying image and integrates different grained visual information based on the relevance, the third enforces semantic refinement via iterative cross-modal interactions and co-attention. We conduct experiments on two open datasets, and the results and detailed analysis demonstrate the advantage of our model.
STREAMLINE: Streaming Active Learning for Realistic Multi-Distributional Settings
May 18, 2023


Deep neural networks have consistently shown great performance in several real-world use cases like autonomous vehicles, satellite imaging, etc., effectively leveraging large corpora of labeled training data. However, learning unbiased models depends on building a dataset that is representative of a diverse range of realistic scenarios for a given task. This is challenging in many settings where data comes from high-volume streams, with each scenario occurring in random interleaved episodes at varying frequencies. We study realistic streaming settings where data instances arrive in and are sampled from an episodic multi-distributional data stream. Using submodular information measures, we propose STREAMLINE, a novel streaming active learning framework that mitigates scenario-driven slice imbalance in the working labeled data via a three-step procedure of slice identification, slice-aware budgeting, and data selection. We extensively evaluate STREAMLINE on real-world streaming scenarios for image classification and object detection tasks. We observe that STREAMLINE improves the performance on infrequent yet critical slices of the data over current baselines by up to $5\%$ in terms of accuracy on our image classification tasks and by up to $8\%$ in terms of mAP on our object detection tasks.
GRAN: Ghost Residual Attention Network for Single Image Super Resolution
Feb 28, 2023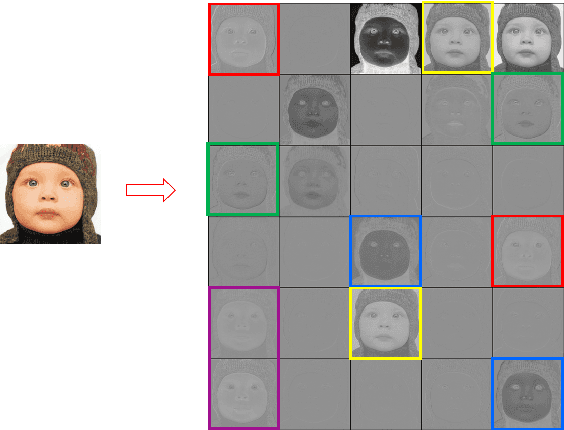
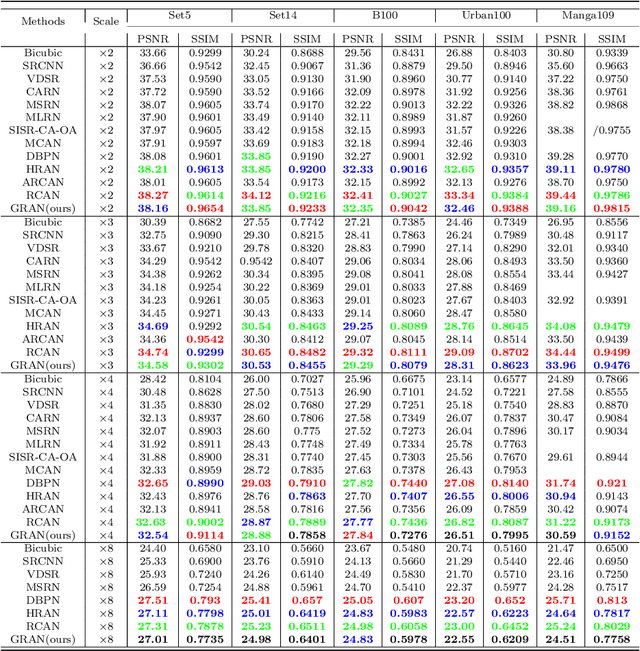
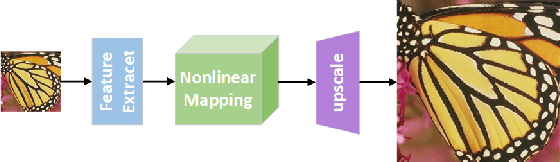

Recently, many works have designed wider and deeper networks to achieve higher image super-resolution performance. Despite their outstanding performance, they still suffer from high computational resources, preventing them from directly applying to embedded devices. To reduce the computation resources and maintain performance, we propose a novel Ghost Residual Attention Network (GRAN) for efficient super-resolution. This paper introduces Ghost Residual Attention Block (GRAB) groups to overcome the drawbacks of the standard convolutional operation, i.e., redundancy of the intermediate feature. GRAB consists of the Ghost Module and Channel and Spatial Attention Module (CSAM) to alleviate the generation of redundant features. Specifically, Ghost Module can reveal information underlying intrinsic features by employing linear operations to replace the standard convolutions. Reducing redundant features by the Ghost Module, our model decreases memory and computing resource requirements in the network. The CSAM pays more comprehensive attention to where and what the feature extraction is, which is critical to recovering the image details. Experiments conducted on the benchmark datasets demonstrate the superior performance of our method in both qualitative and quantitative. Compared to the baseline models, we achieve higher performance with lower computational resources, whose parameters and FLOPs have decreased by more than ten times.
Deeply Coupled Cross-Modal Prompt Learning
May 30, 2023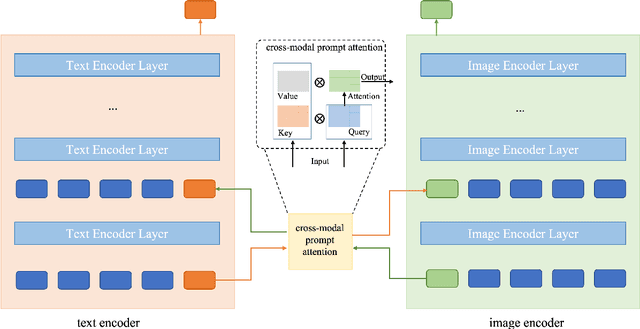
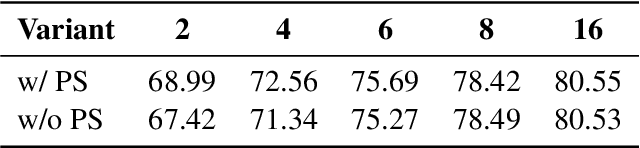
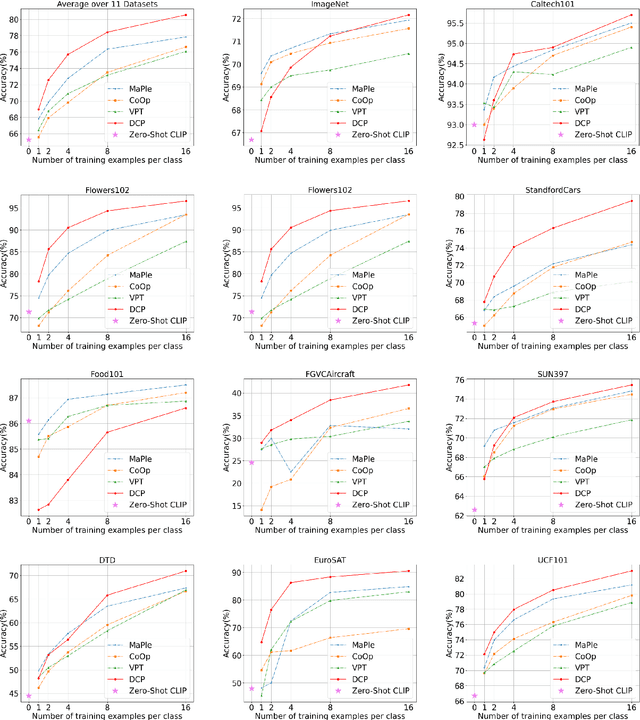
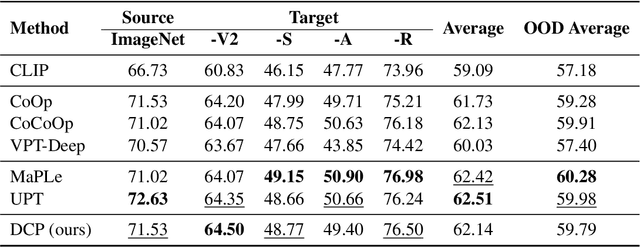
Recent advancements in multimodal foundation models (e.g., CLIP) have excelled in zero-shot generalization. Prompt tuning involved in the knowledge transfer from foundation models to downstream tasks has gained significant attention recently. Existing prompt-tuning methods in cross-modal learning, however, either solely focus on language branch, or learn vision-language interaction in a shallow mechanism. In this context, we propose a Deeply coupled Cross-modal Prompt learning (DCP) method based on CLIP. DCP flexibly accommodates the interplay between vision and language with a Cross-Modal Prompt Attention (CMPA) mechanism, which enables the mutual exchange of respective representation through a well-connected multi-head attention module progressively and strongly. We then conduct comprehensive few-shot learning experiments on 11 image classification datasets and analyze the robustness to domain shift as well. Thorough experimental analysis evidently demonstrates the superb few-shot generalization and compelling domain adaption capacity of a well-executed DCP. The code can be found at https://github.com/GingL/CMPA.
Quantum Convolutional Neural Networks for Multi-Channel Supervised Learning
May 30, 2023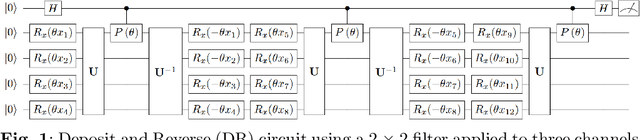
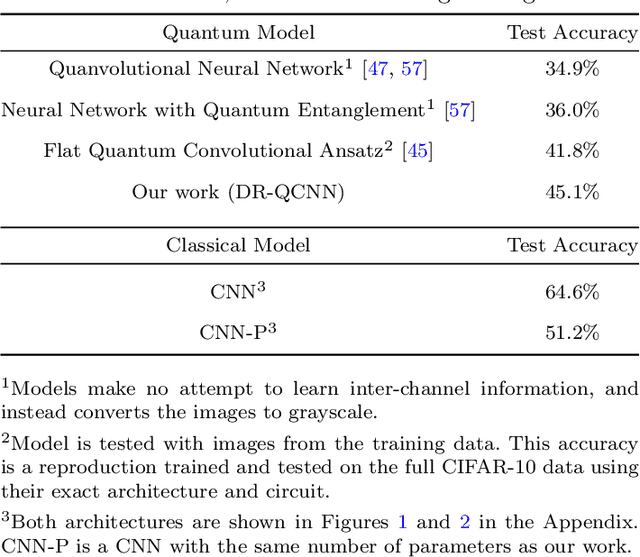
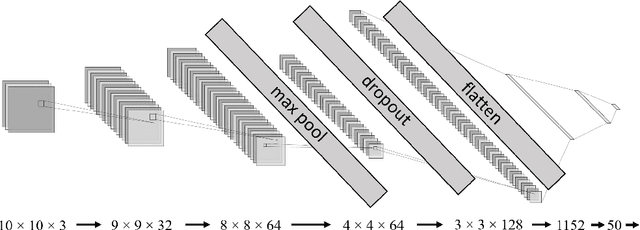
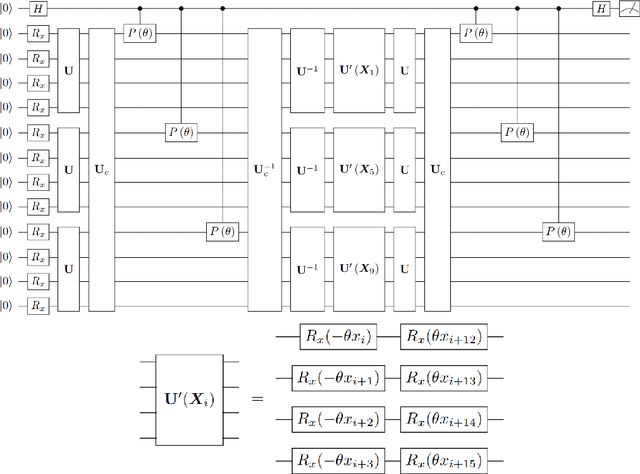
As the rapidly evolving field of machine learning continues to produce incredibly useful tools and models, the potential for quantum computing to provide speed up for machine learning algorithms is becoming increasingly desirable. In particular, quantum circuits in place of classical convolutional filters for image detection-based tasks are being investigated for the ability to exploit quantum advantage. However, these attempts, referred to as quantum convolutional neural networks (QCNNs), lack the ability to efficiently process data with multiple channels and therefore are limited to relatively simple inputs. In this work, we present a variety of hardware-adaptable quantum circuit ansatzes for use as convolutional kernels, and demonstrate that the quantum neural networks we report outperform existing QCNNs on classification tasks involving multi-channel data. We envision that the ability of these implementations to effectively learn inter-channel information will allow quantum machine learning methods to operate with more complex data. This work is available as open source at https://github.com/anthonysmaldone/QCNN-Multi-Channel-Supervised-Learning.
Budget-Aware Graph Convolutional Network Design using Probabilistic Magnitude Pruning
May 30, 2023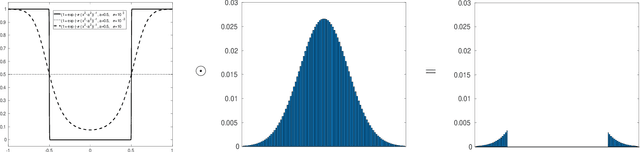
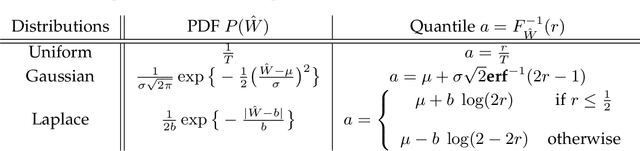

Graph convolutional networks (GCNs) are nowadays becoming mainstream in solving many image processing tasks including skeleton-based recognition. Their general recipe consists in learning convolutional and attention layers that maximize classification performances. With multi-head attention, GCNs are highly accurate but oversized, and their deployment on edge devices requires their pruning. Among existing methods, magnitude pruning (MP) is relatively effective but its design is clearly suboptimal as network topology selection and weight retraining are achieved independently. In this paper, we devise a novel lightweight GCN design dubbed as Probabilistic Magnitude Pruning (PMP) that jointly trains network topology and weights. Our method is variational and proceeds by aligning the weight distribution of the learned networks with an a priori distribution. This allows implementing any fixed pruning rate, and also enhancing the generalization performances of the designed lightweight GCNs. Extensive experiments conducted on the challenging task of skeleton-based recognition show a substantial gain of our lightweight GCNs particularly at very high pruning regimes.
Evaluating the feasibility of using Generative Models to generate Chest X-Ray Data
May 30, 2023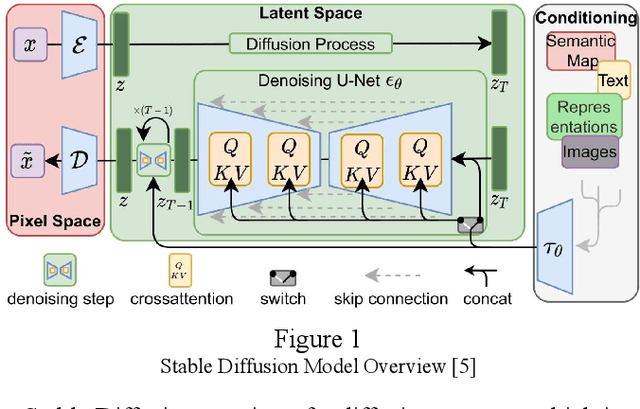
In this paper, we explore the feasibility of using generative models, specifically Progressive Growing GANs (PG-GANs) and Stable Diffusion fine-tuning, to generate synthetic chest X-ray images for medical diagnosis purposes. Due to ethical concerns, obtaining sufficient medical data for machine learning is a challenge, which our approach aims to address by synthesising more data. We utilised the Chest X-ray 14 dataset for our experiments and evaluated the performance of our models through qualitative and quantitative analysis. Our results show that the generated images are visually convincing and can be used to improve the accuracy of classification models. However, further work is needed to address issues such as overfitting and the limited availability of real data for training and testing. The potential of our approach to contribute to more effective medical diagnosis through deep learning is promising, and we believe that continued advancements in image generation technology will lead to even more promising results in the future.
Learning Non-Local Spatial-Angular Correlation for Light Field Image Super-Resolution
Feb 18, 2023
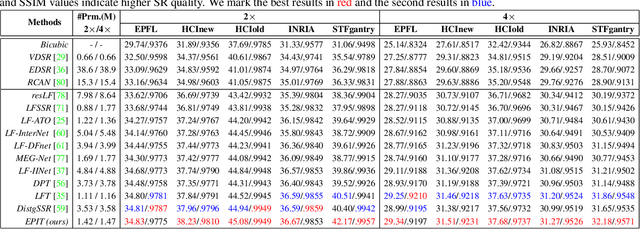
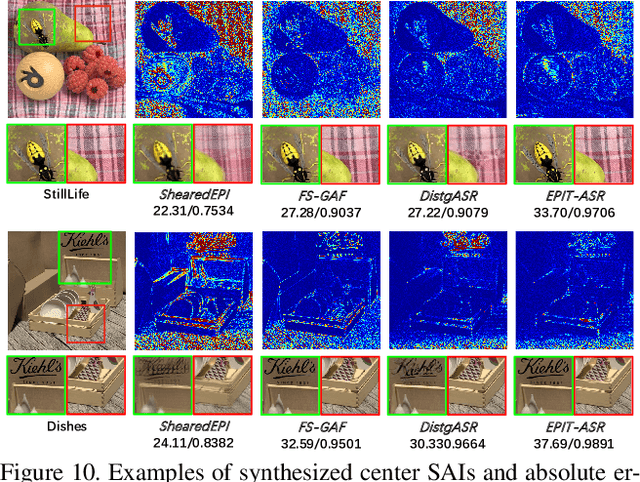
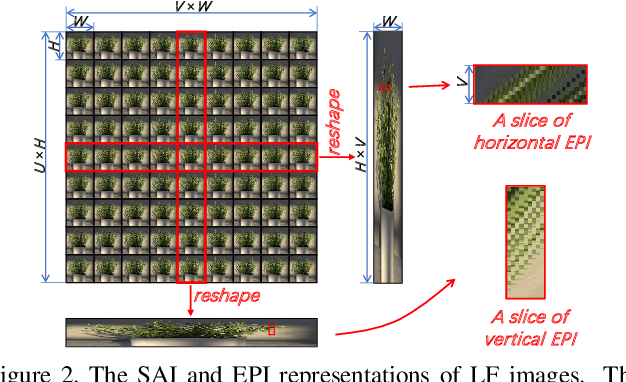
Exploiting spatial-angular correlation is crucial to light field (LF) image super-resolution (SR), but is highly challenging due to its non-local property caused by the disparities among LF images. Although many deep neural networks (DNNs) have been developed for LF image SR and achieved continuously improved performance, existing methods cannot well leverage the long-range spatial-angular correlation and thus suffer a significant performance drop when handling scenes with large disparity variations. In this paper, we propose a simple yet effective method to learn the non-local spatial-angular correlation for LF image SR. In our method, we adopt the epipolar plane image (EPI) representation to project the 4D spatial-angular correlation onto multiple 2D EPI planes, and then develop a Transformer network with repetitive self-attention operations to learn the spatial-angular correlation by modeling the dependencies between each pair of EPI pixels. Our method can fully incorporate the information from all angular views while achieving a global receptive field along the epipolar line. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Comparative results on five public datasets show that our method not only achieves state-of-the-art SR performance, but also performs robust to disparity variations. Code is publicly available at https://github.com/ZhengyuLiang24/EPIT.
Advances and Challenges in Multimodal Remote Sensing Image Registration
Feb 07, 2023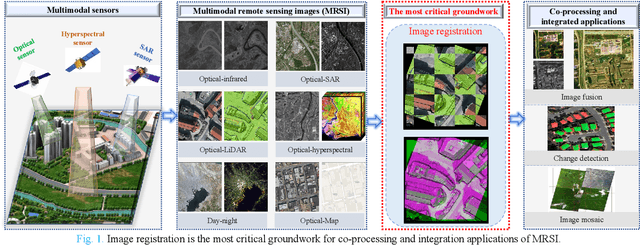
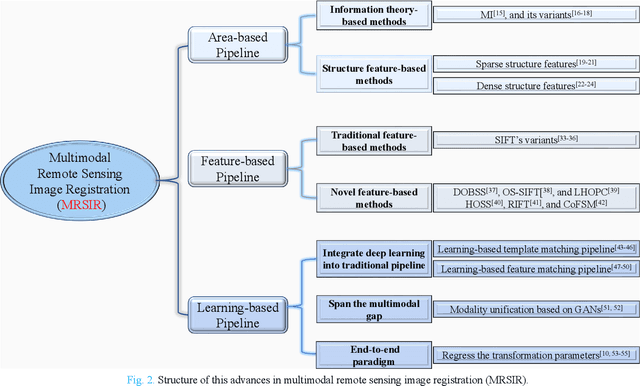
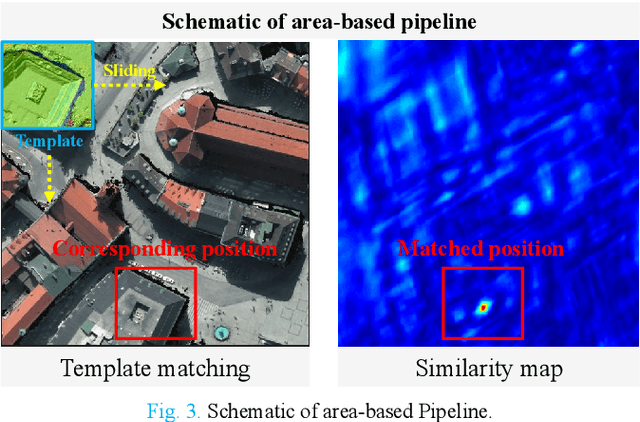

Over the past few decades, with the rapid development of global aerospace and aerial remote sensing technology, the types of sensors have evolved from the traditional monomodal sensors (e.g., optical sensors) to the new generation of multimodal sensors [e.g., multispectral, hyperspectral, light detection and ranging (LiDAR) and synthetic aperture radar (SAR) sensors]. These advanced devices can dynamically provide various and abundant multimodal remote sensing images with different spatial, temporal, and spectral resolutions according to different application requirements. Since then, it is of great scientific significance to carry out the research of multimodal remote sensing image registration, which is a crucial step for integrating the complementary information among multimodal data and making comprehensive observations and analysis of the Earths surface. In this work, we will present our own contributions to the field of multimodal image registration, summarize the advantages and limitations of existing multimodal image registration methods, and then discuss the remaining challenges and make a forward-looking prospect for the future development of the field.