 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analysing high resolution digital Mars images using machine learning
May 31, 2023
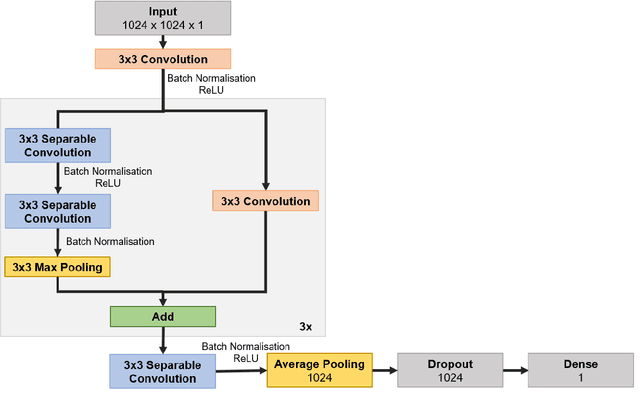


The search for ephemeral liquid water on Mars is an ongoing activity. After the recession of the seasonal polar ice cap on Mars, small water ice patches may be left behind in shady places due to the low thermal conductivity of the Martian surface and atmosphere. During late spring and early summer, these patches may be exposed to direct sunlight and warm up rapidly enough for the liquid phase to emerge. To see the spatial and temporal occurrence of such ice patches, optical images should be searched for and checked. Previously a manual image analysis was conducted on 110 images from the southern hemisphere, captured by the High Resolution Imaging Science Experiment (HiRISE) camera onboard the Mars Reconnaissance Orbiter space mission. Out of these, 37 images were identified with smaller ice patches, which were distinguishable by their brightness, colour and strong connection to local topographic shading. In this study, a convolutional neural network (CNN) is applied to find further images with potential water ice patches in the latitude band between -40{\deg} and -60{\deg}, where the seasonal retreat of the polar ice cap happens. Previously analysed HiRISE images are used to train the model, each was split into hundreds of pieces, expanding the training dataset to 6240 images. A test run conducted on 38 new HiRISE images indicates that the program can generally recognise small bright patches, however further training might be needed for more precise predictions.Using a CNN model may make it realistic to analyse all available surface images, aiding us in selecting areas for further investigation.
Evaluating Machine Learning Models with NERO: Non-Equivariance Revealed on Orbits
May 31, 2023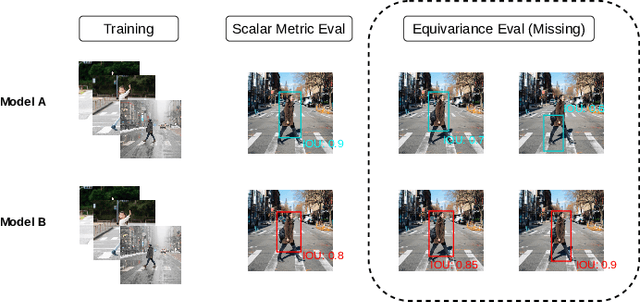
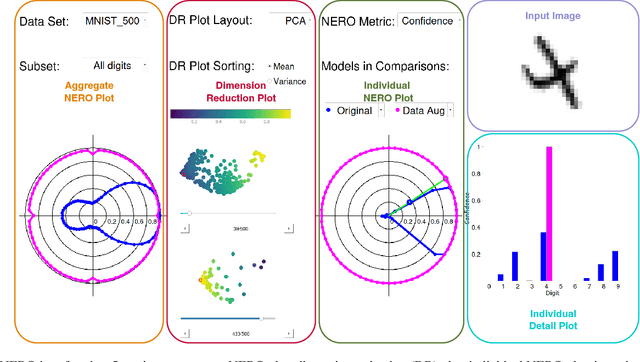
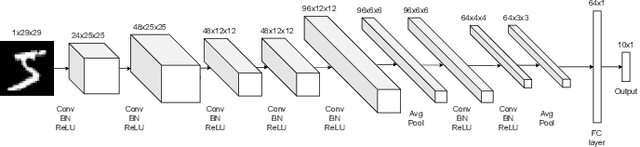
Proper evaluations are crucial for better understanding, troubleshooting, interpreting model behaviors and further improving model performance. While using scalar-based error metrics provides a fast way to overview model performance, they are often too abstract to display certain weak spots and lack information regarding important model properties, such as robustness. This not only hinders machine learning models from being more interpretable and gaining trust, but also can be misleading to both model developers and users. Additionally, conventional evaluation procedures often leave researchers unclear about where and how model fails, which complicates model comparisons and further developments. To address these issues, we propose a novel evaluation workflow, named Non-Equivariance Revealed on Orbits (NERO) Evaluation. The goal of NERO evaluation is to turn focus from traditional scalar-based metrics onto evaluating and visualizing models equivariance, closely capturing model robustness, as well as to allow researchers quickly investigating interesting or unexpected model behaviors. NERO evaluation is consist of a task-agnostic interactive interface and a set of visualizations, called NERO plots, which reveals the equivariance property of the model. Case studies on how NERO evaluation can be applied to multiple research areas, including 2D digit recognition, object detection, particle image velocimetry (PIV), and 3D point cloud classification, demonstrate that NERO evaluation can quickly illustrate different model equivariance, and effectively explain model behaviors through interactive visualizations of the model outputs. In addition, we propose consensus, an alternative to ground truths, to be used in NERO evaluation so that model equivariance can still be evaluated with new, unlabeled datasets.
Dissecting Arbitrary-scale Super-resolution Capability from Pre-trained Diffusion Generative Models
Jun 01, 2023
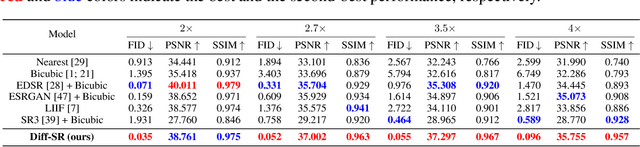
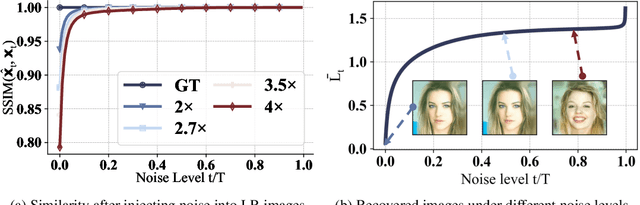
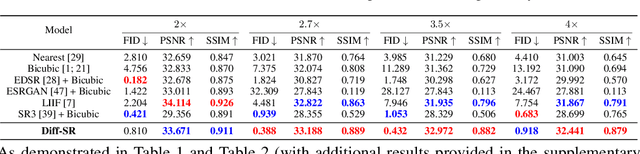
Diffusion-based Generative Models (DGMs) have achieved unparalleled performance in synthesizing high-quality visual content, opening up the opportunity to improve image super-resolution (SR) tasks. Recent solutions for these tasks often train architecture-specific DGMs from scratch, or require iterative fine-tuning and distillation on pre-trained DGMs, both of which take considerable time and hardware investments. More seriously, since the DGMs are established with a discrete pre-defined upsampling scale, they cannot well match the emerging requirements of arbitrary-scale super-resolution (ASSR), where a unified model adapts to arbitrary upsampling scales, instead of preparing a series of distinct models for each case. These limitations beg an intriguing question: can we identify the ASSR capability of existing pre-trained DGMs without the need for distillation or fine-tuning? In this paper, we take a step towards resolving this matter by proposing Diff-SR, a first ASSR attempt based solely on pre-trained DGMs, without additional training efforts. It is motivated by an exciting finding that a simple methodology, which first injects a specific amount of noise into the low-resolution images before invoking a DGM's backward diffusion process, outperforms current leading solutions. The key insight is determining a suitable amount of noise to inject, i.e., small amounts lead to poor low-level fidelity, while over-large amounts degrade the high-level signature. Through a finely-grained theoretical analysis, we propose the Perceptual Recoverable Field (PRF), a metric that achieves the optimal trade-off between these two factors. Extensive experiments verify the effectiveness, flexibility, and adaptability of Diff-SR, demonstrating superior performance to state-of-the-art solutions under diverse ASSR environments.
Controllable Motion Diffusion Model
Jun 01, 2023

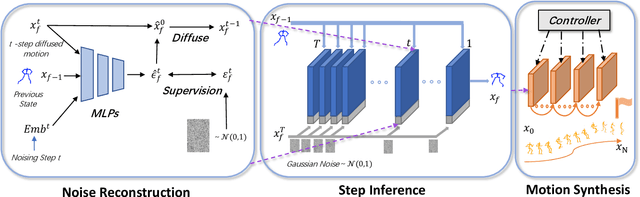

Generating realistic and controllable motions for virtual characters is a challenging task in computer animation, and its implications extend to games, simulations, and virtual reality. Recent studies have drawn inspiration from the success of diffusion models in image generation, demonstrating the potential for addressing this task. However, the majority of these studies have been limited to offline applications that target at sequence-level generation that generates all steps simultaneously. To enable real-time motion synthesis with diffusion models in response to time-varying control signals, we propose the framework of the Controllable Motion Diffusion Model (COMODO). Our framework begins with an auto-regressive motion diffusion model (A-MDM), which generates motion sequences step by step. In this way, simply using the standard DDPM algorithm without any additional complexity, our framework is able to generate high-fidelity motion sequences over extended periods with different types of control signals. Then, we propose our reinforcement learning-based controller and controlling strategies on top of the A-MDM model, so that our framework can steer the motion synthesis process across multiple tasks, including target reaching, joystick-based control, goal-oriented control, and trajectory following. The proposed framework enables the real-time generation of diverse motions that react adaptively to user commands on-the-fly, thereby enhancing the overall user experience. Besides, it is compatible with the inpainting-based editing methods and can predict much more diverse motions without additional fine-tuning of the basic motion generation models. We conduct comprehensive experiments to evaluate the effectiveness of our framework in performing various tasks and compare its performance against state-of-the-art methods.
Using generative AI to investigate medical imagery models and datasets
Jun 01, 2023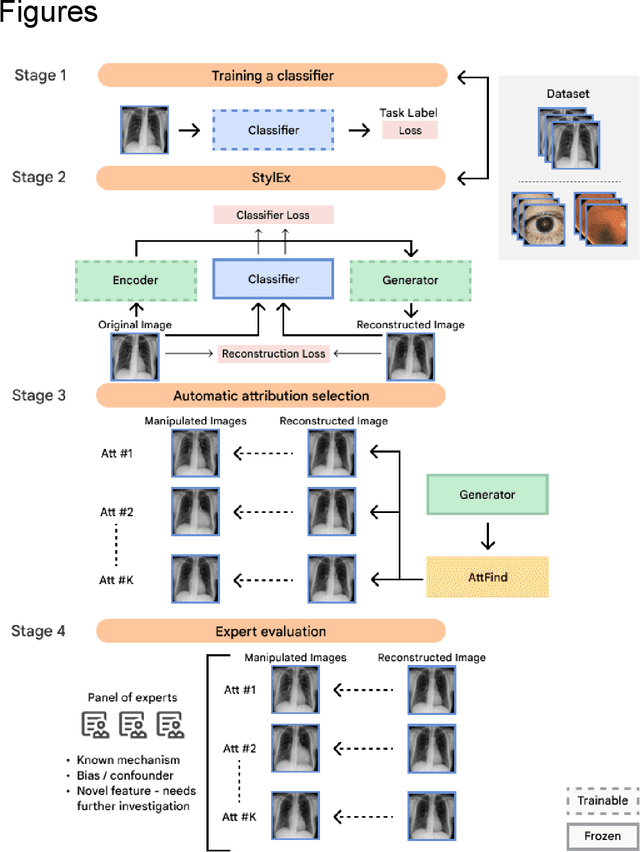
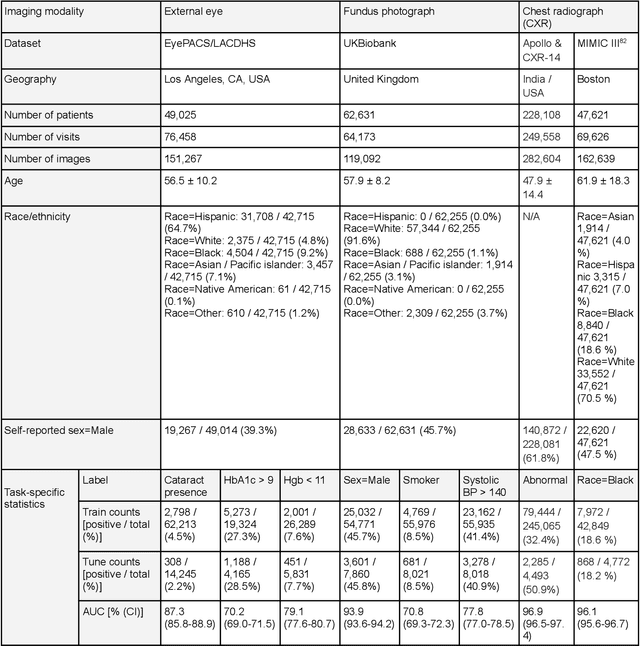
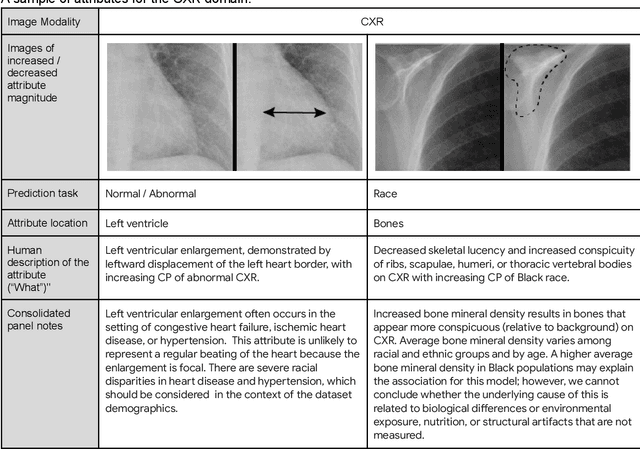
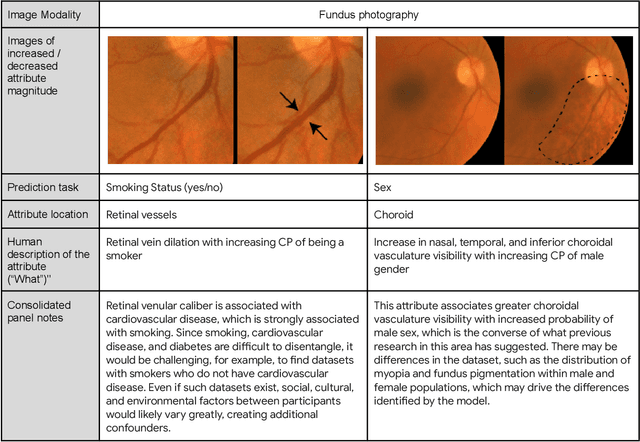
AI models have shown promise in many medical imaging tasks. However, our ability to explain what signals these models have learned is severely lacking. Explanations are needed in order to increase the trust in AI-based models, and could enable novel scientific discovery by uncovering signals in the data that are not yet known to experts. In this paper, we present a method for automatic visual explanations leveraging team-based expertise by generating hypotheses of what visual signals in the images are correlated with the task. We propose the following 4 steps: (i) Train a classifier to perform a given task (ii) Train a classifier guided StyleGAN-based image generator (StylEx) (iii) Automatically detect and visualize the top visual attributes that the classifier is sensitive towards (iv) Formulate hypotheses for the underlying mechanisms, to stimulate future research. Specifically, we present the discovered attributes to an interdisciplinary panel of experts so that hypotheses can account for social and structural determinants of health. We demonstrate results on eight prediction tasks across three medical imaging modalities: retinal fundus photographs, external eye photographs, and chest radiographs. We showcase examples of attributes that capture clinically known features, confounders that arise from factors beyond physiological mechanisms, and reveal a number of physiologically plausible novel attributes. Our approach has the potential to enable researchers to better understand, improve their assessment, and extract new knowledge from AI-based models. Importantly, we highlight that attributes generated by our framework can capture phenomena beyond physiology or pathophysiology, reflecting the real world nature of healthcare delivery and socio-cultural factors. Finally, we intend to release code to enable researchers to train their own StylEx models and analyze their predictive tasks.
Spatial and Modal Optimal Transport for Fast Cross-Modal MRI Reconstruction
May 04, 2023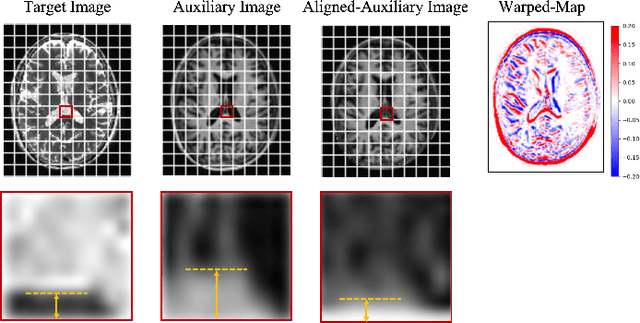
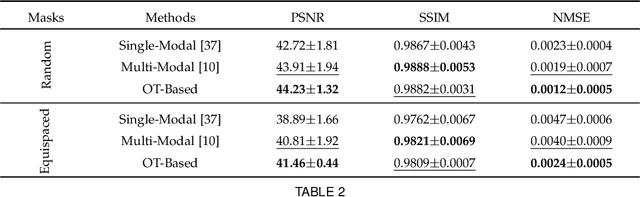
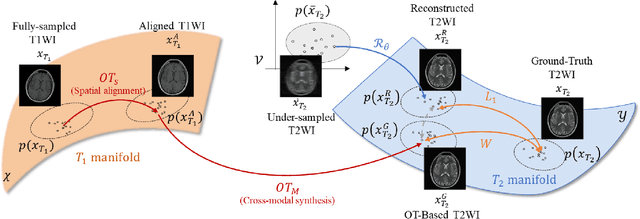
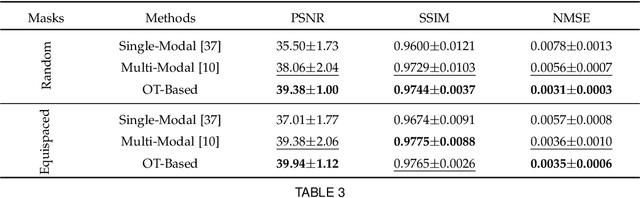
Multi-modal Magnetic Resonance Imaging (MRI) plays an important role in clinical medicine. However, the acquisitions of some modalities, such as the T2-weighted modality, need a long time and they are always accompanied by motion artifacts. On the other hand, the T1-weighted image (T1WI) shares the same underlying information with T2-weighted image (T2WI), which needs a shorter scanning time. Therefore, in this paper we accelerate the acquisition of the T2WI by introducing the auxiliary modality (T1WI). Concretely, we first reconstruct high-quality T2WIs with under-sampled T2WIs. Here, we realize fast T2WI reconstruction by reducing the sampling rate in the k-space. Second, we establish a cross-modal synthesis task to generate the synthetic T2WIs for guiding better T2WI reconstruction. Here, we obtain the synthetic T2WIs by decomposing the whole cross-modal generation mapping into two OT processes, the spatial alignment mapping on the T1 image manifold and the cross-modal synthesis mapping from aligned T1WIs to T2WIs. It overcomes the negative transfer caused by the spatial misalignment. Then, we prove the reconstruction and the synthesis tasks are well complementary. Finally, we compare it with state-of-the-art approaches on an open dataset FastMRI and an in-house dataset to testify the validity of the proposed method.
Learning Better Contrastive View from Radiologist's Gaze
May 15, 2023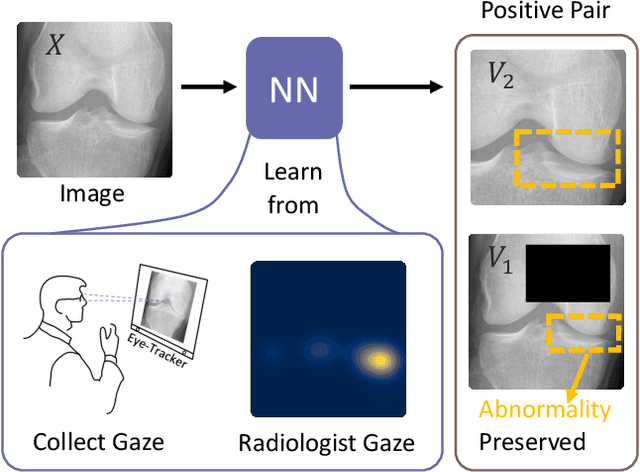
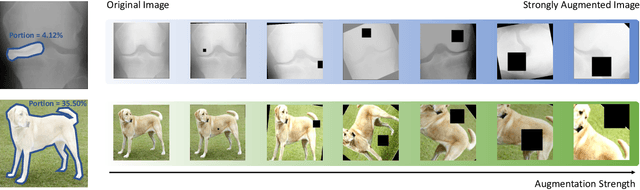
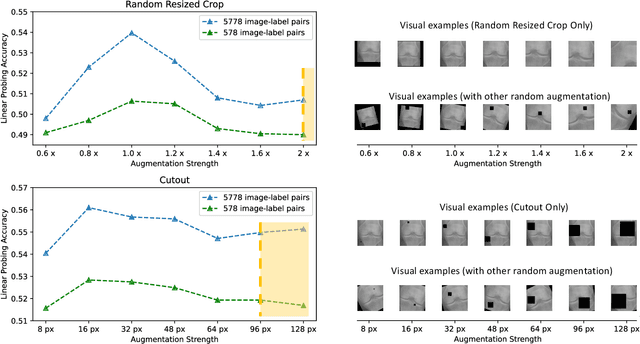
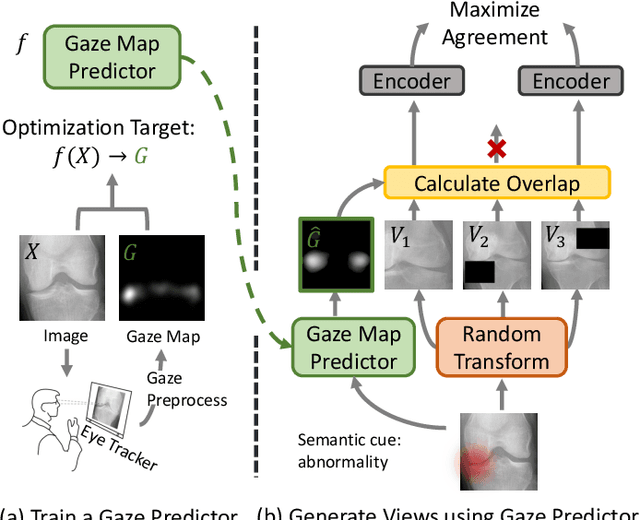
Recent self-supervised contrastive learning methods greatly benefit from the Siamese structure that aims to minimizing distances between positive pairs. These methods usually apply random data augmentation to input images, expecting the augmented views of the same images to be similar and positively paired. However, random augmentation may overlook image semantic information and degrade the quality of augmented views in contrastive learning. This issue becomes more challenging in medical images since the abnormalities related to diseases can be tiny, and are easy to be corrupted (e.g., being cropped out) in the current scheme of random augmentation. In this work, we first demonstrate that, for widely-used X-ray images, the conventional augmentation prevalent in contrastive pre-training can affect the performance of the downstream diagnosis or classification tasks. Then, we propose a novel augmentation method, i.e., FocusContrast, to learn from radiologists' gaze in diagnosis and generate contrastive views for medical images with guidance from radiologists' visual attention. Specifically, we track the gaze movement of radiologists and model their visual attention when reading to diagnose X-ray images. The learned model can predict visual attention of the radiologists given a new input image, and further guide the attention-aware augmentation that hardly neglects the disease-related abnormalities. As a plug-and-play and framework-agnostic module, FocusContrast consistently improves state-of-the-art contrastive learning methods of SimCLR, MoCo, and BYOL by 4.0~7.0% in classification accuracy on a knee X-ray dataset.
Revisiting Implicit Neural Representations in Low-Level Vision
Apr 20, 2023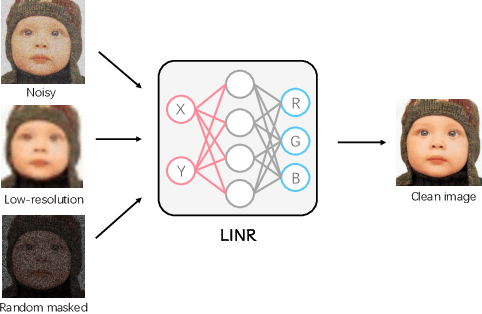
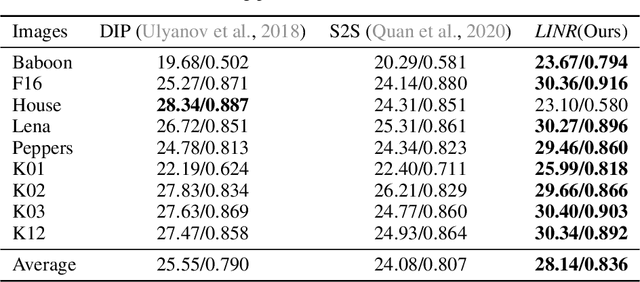
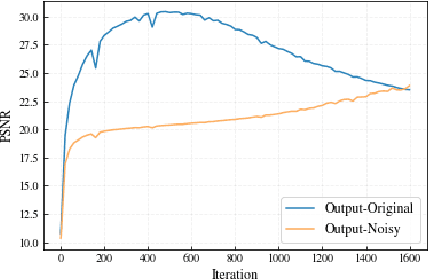

Implicit Neural Representation (INR) has been emerging in computer vision in recent years. It has been shown to be effective in parameterising continuous signals such as dense 3D models from discrete image data, e.g. the neural radius field (NeRF). However, INR is under-explored in 2D image processing tasks. Considering the basic definition and the structure of INR, we are interested in its effectiveness in low-level vision problems such as image restoration. In this work, we revisit INR and investigate its application in low-level image restoration tasks including image denoising, super-resolution, inpainting, and deblurring. Extensive experimental evaluations suggest the superior performance of INR in several low-level vision tasks with limited resources, outperforming its counterparts by over 2dB. Code and models are available at https://github.com/WenTXuL/LINR
BiRT: Bio-inspired Replay in Vision Transformers for Continual Learning
May 08, 2023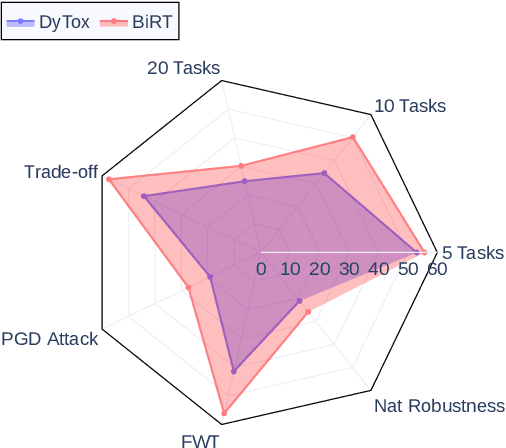
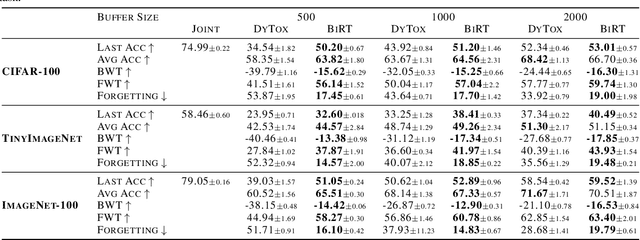
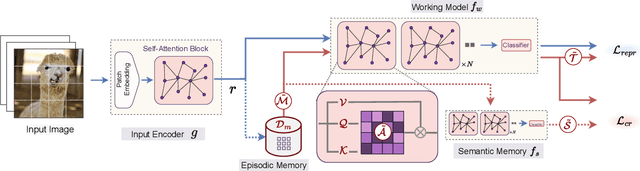
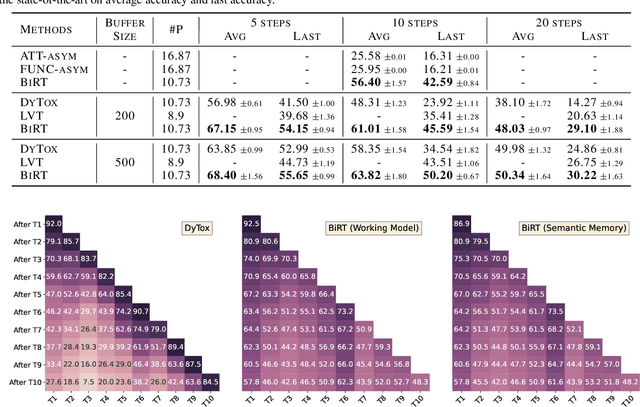
The ability of deep neural networks to continually learn and adapt to a sequence of tasks has remained challenging due to catastrophic forgetting of previously learned tasks. Humans, on the other hand, have a remarkable ability to acquire, assimilate, and transfer knowledge across tasks throughout their lifetime without catastrophic forgetting. The versatility of the brain can be attributed to the rehearsal of abstract experiences through a complementary learning system. However, representation rehearsal in vision transformers lacks diversity, resulting in overfitting and consequently, performance drops significantly compared to raw image rehearsal. Therefore, we propose BiRT, a novel representation rehearsal-based continual learning approach using vision transformers. Specifically, we introduce constructive noises at various stages of the vision transformer and enforce consistency in predictions with respect to an exponential moving average of the working model. Our method provides consistent performance gain over raw image and vanilla representation rehearsal on several challenging CL benchmarks, while being memory efficient and robust to natural and adversarial corruptions.
PVT-SSD: Single-Stage 3D Object Detector with Point-Voxel Transformer
May 11, 2023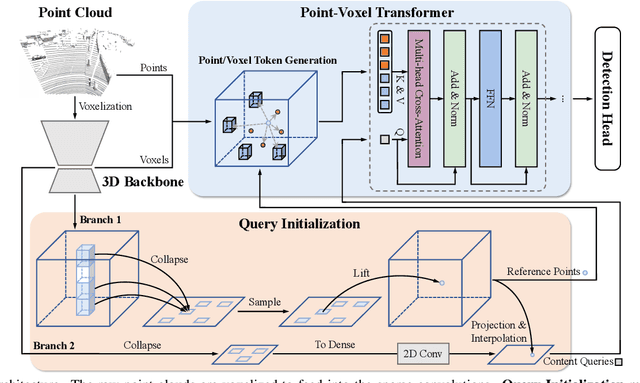
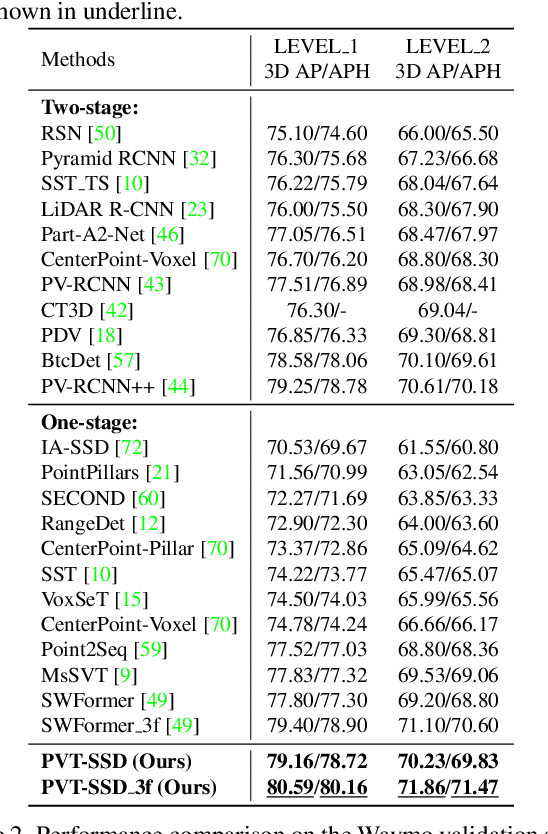
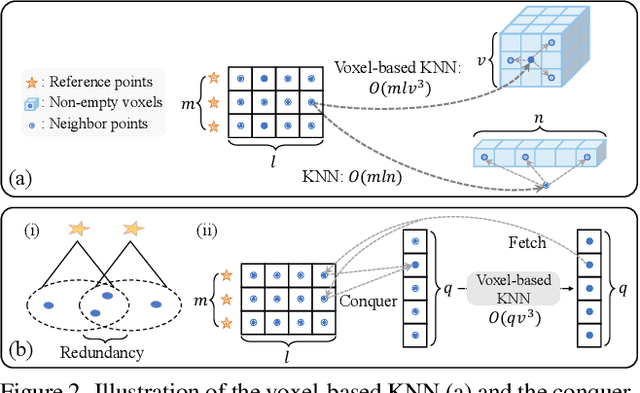
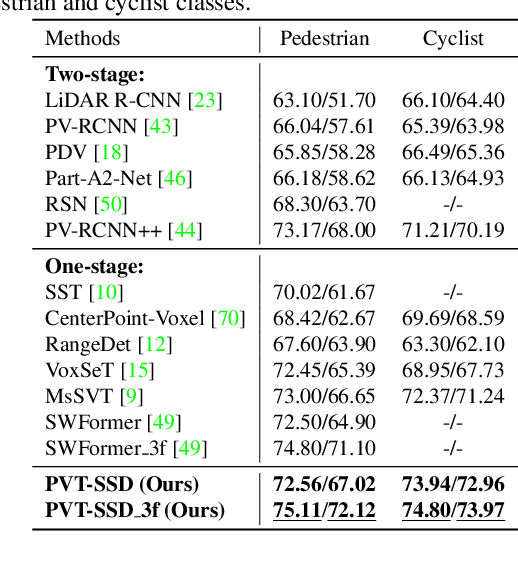
Recent Transformer-based 3D object detectors learn point cloud features either from point- or voxel-based representations. However, the former requires time-consuming sampling while the latter introduces quantization errors. In this paper, we present a novel Point-Voxel Transformer for single-stage 3D detection (PVT-SSD) that takes advantage of these two representations. Specifically, we first use voxel-based sparse convolutions for efficient feature encoding. Then, we propose a Point-Voxel Transformer (PVT) module that obtains long-range contexts in a cheap manner from voxels while attaining accurate positions from points. The key to associating the two different representations is our introduced input-dependent Query Initialization module, which could efficiently generate reference points and content queries. Then, PVT adaptively fuses long-range contextual and local geometric information around reference points into content queries. Further, to quickly find the neighboring points of reference points, we design the Virtual Range Image module, which generalizes the native range image to multi-sensor and multi-frame. The experiments on several autonomous driving benchmarks verify the effectiveness and efficiency of the proposed method. Code will be available at https://github.com/Nightmare-n/PVT-SSD.