 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Low-Rank Rescaled Vision Transformer Fine-Tuning: A Residual Design Approach
Mar 28, 2024
Parameter-efficient fine-tuning for pre-trained Vision Transformers aims to adeptly tailor a model to downstream tasks by learning a minimal set of new adaptation parameters while preserving the frozen majority of pre-trained parameters. Striking a balance between retaining the generalizable representation capacity of the pre-trained model and acquiring task-specific features poses a key challenge. Currently, there is a lack of focus on guiding this delicate trade-off. In this study, we approach the problem from the perspective of Singular Value Decomposition (SVD) of pre-trained parameter matrices, providing insights into the tuning dynamics of existing methods. Building upon this understanding, we propose a Residual-based Low-Rank Rescaling (RLRR) fine-tuning strategy. This strategy not only enhances flexibility in parameter tuning but also ensures that new parameters do not deviate excessively from the pre-trained model through a residual design. Extensive experiments demonstrate that our method achieves competitive performance across various downstream image classification tasks, all while maintaining comparable new parameters. We believe this work takes a step forward in offering a unified perspective for interpreting existing methods and serves as motivation for the development of new approaches that move closer to effectively considering the crucial trade-off mentioned above. Our code is available at \href{https://github.com/zstarN70/RLRR.git}{https://github.com/zstarN70/RLRR.git}.
OAKINK2: A Dataset of Bimanual Hands-Object Manipulation in Complex Task Completion
Mar 28, 2024
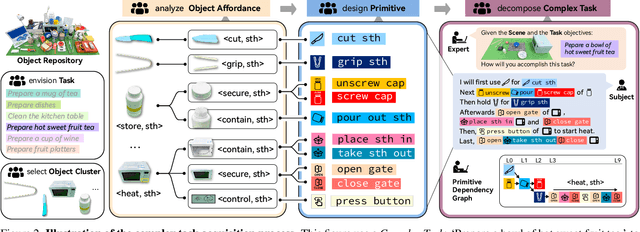

We present OAKINK2, a dataset of bimanual object manipulation tasks for complex daily activities. In pursuit of constructing the complex tasks into a structured representation, OAKINK2 introduces three level of abstraction to organize the manipulation tasks: Affordance, Primitive Task, and Complex Task. OAKINK2 features on an object-centric perspective for decoding the complex tasks, treating them as a sequence of object affordance fulfillment. The first level, Affordance, outlines the functionalities that objects in the scene can afford, the second level, Primitive Task, describes the minimal interaction units that humans interact with the object to achieve its affordance, and the third level, Complex Task, illustrates how Primitive Tasks are composed and interdependent. OAKINK2 dataset provides multi-view image streams and precise pose annotations for the human body, hands and various interacting objects. This extensive collection supports applications such as interaction reconstruction and motion synthesis. Based on the 3-level abstraction of OAKINK2, we explore a task-oriented framework for Complex Task Completion (CTC). CTC aims to generate a sequence of bimanual manipulation to achieve task objectives. Within the CTC framework, we employ Large Language Models (LLMs) to decompose the complex task objectives into sequences of Primitive Tasks and have developed a Motion Fulfillment Model that generates bimanual hand motion for each Primitive Task. OAKINK2 datasets and models are available at https://oakink.net/v2.
BiTT: Bi-directional Texture Reconstruction of Interacting Two Hands from a Single Image
Mar 13, 2024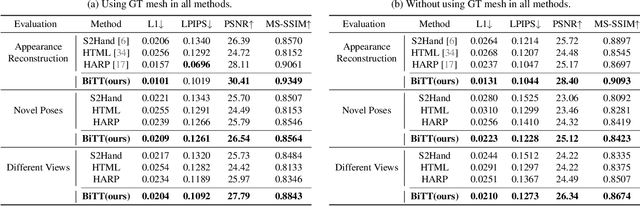
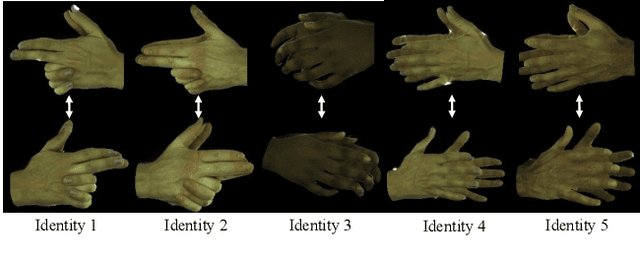
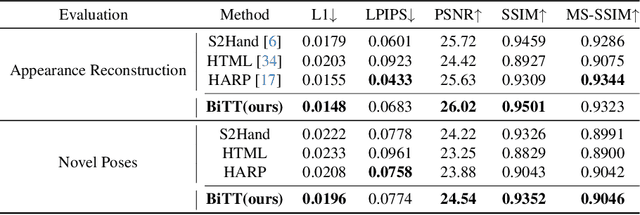
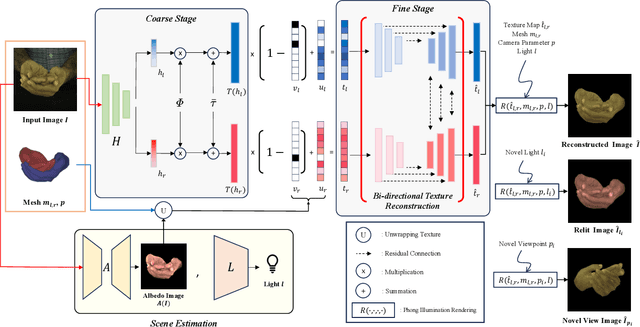
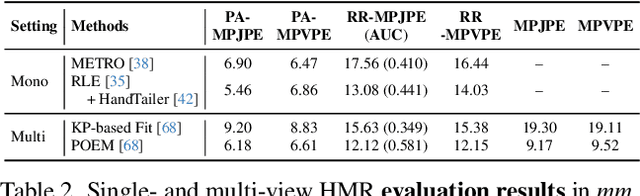
Creating personalized hand avatars is important to offer a realistic experience to users on AR / VR platforms. While most prior studies focused on reconstructing 3D hand shapes, some recent work has tackled the reconstruction of hand textures on top of shapes. However, these methods are often limited to capturing pixels on the visible side of a hand, requiring diverse views of the hand in a video or multiple images as input. In this paper, we propose a novel method, BiTT(Bi-directional Texture reconstruction of Two hands), which is the first end-to-end trainable method for relightable, pose-free texture reconstruction of two interacting hands taking only a single RGB image, by three novel components: 1)\ bi-directional (left $\leftrightarrow$ right) texture reconstruction using the texture symmetry of left / right hands, 2) utilizing a texture parametric model for hand texture recovery, and 3)\ the overall coarse-to-fine stage pipeline for reconstructing personalized texture of two interacting hands. BiTT first estimates the scene light condition and albedo image from an input image, then reconstructs the texture of both hands through the texture parametric model and bi-directional texture reconstructor. In experiments using InterHand2.6M and RGB2Hands datasets, our method significantly outperforms state-of-the-art hand texture reconstruction methods quantitatively and qualitatively. The code is available at https://github.com/yunminjin2/BiTT
Conditional Wasserstein Distances with Applications in Bayesian OT Flow Matching
Mar 27, 2024In inverse problems, many conditional generative models approximate the posterior measure by minimizing a distance between the joint measure and its learned approximation. While this approach also controls the distance between the posterior measures in the case of the Kullback--Leibler divergence, this is in general not hold true for the Wasserstein distance. In this paper, we introduce a conditional Wasserstein distance via a set of restricted couplings that equals the expected Wasserstein distance of the posteriors. Interestingly, the dual formulation of the conditional Wasserstein-1 flow resembles losses in the conditional Wasserstein GAN literature in a quite natural way. We derive theoretical properties of the conditional Wasserstein distance, characterize the corresponding geodesics and velocity fields as well as the flow ODEs. Subsequently, we propose to approximate the velocity fields by relaxing the conditional Wasserstein distance. Based on this, we propose an extension of OT Flow Matching for solving Bayesian inverse problems and demonstrate its numerical advantages on an inverse problem and class-conditional image generation.
Visually Guided Generative Text-Layout Pre-training for Document Intelligence
Mar 27, 2024Prior study shows that pre-training techniques can boost the performance of visual document understanding (VDU), which typically requires models to gain abilities to perceive and reason both document texts and layouts (e.g., locations of texts and table-cells). To this end, we propose visually guided generative text-layout pre-training, named ViTLP. Given a document image, the model optimizes hierarchical language and layout modeling objectives to generate the interleaved text and layout sequence. In addition, to address the limitation of processing long documents by Transformers, we introduce a straightforward yet effective multi-segment generative pre-training scheme, facilitating ViTLP to process word-intensive documents of any length. ViTLP can function as a native OCR model to localize and recognize texts of document images. Besides, ViTLP can be effectively applied to various downstream VDU tasks. Extensive experiments show that ViTLP achieves competitive performance over existing baselines on benchmark VDU tasks, including information extraction, document classification, and document question answering.
Semi-Supervised Learning for Deep Causal Generative Models
Mar 27, 2024Developing models that can answer questions of the form "How would $x$ change if $y$ had been $z$?" is fundamental for advancing medical image analysis. Training causal generative models that address such counterfactual questions, though, currently requires that all relevant variables have been observed and that corresponding labels are available in training data. However, clinical data may not have complete records for all patients and state of the art causal generative models are unable to take full advantage of this. We thus develop, for the first time, a semi-supervised deep causal generative model that exploits the causal relationships between variables to maximise the use of all available data. We explore this in the setting where each sample is either fully labelled or fully unlabelled, as well as the more clinically realistic case of having different labels missing for each sample. We leverage techniques from causal inference to infer missing values and subsequently generate realistic counterfactuals, even for samples with incomplete labels.
A Recommender System for NFT Collectibles with Item Feature
Mar 27, 2024Recommender systems have been actively studied and applied in various domains to deal with information overload. Although there are numerous studies on recommender systems for movies, music, and e-commerce, comparatively less attention has been paid to the recommender system for NFTs despite the continuous growth of the NFT market. This paper presents a recommender system for NFTs that utilizes a variety of data sources, from NFT transaction records to external item features, to generate precise recommendations that cater to individual preferences. We develop a data-efficient graph-based recommender system to efficiently capture the complex relationship between each item and users and generate node(item) embeddings which incorporate both node feature information and graph structure. Furthermore, we exploit inputs beyond user-item interactions, such as image feature, text feature, and price feature. Numerical experiments verify the performance of the graph-based recommender system improves significantly after utilizing all types of item features as side information, thereby outperforming all other baselines.
Illicit object detection in X-ray images using Vision Transformers
Mar 27, 2024Illicit object detection is a critical task performed at various high-security locations, including airports, train stations, subways, and ports. The continuous and tedious work of examining thousands of X-ray images per hour can be mentally taxing. Thus, Deep Neural Networks (DNNs) can be used to automate the X-ray image analysis process, improve efficiency and alleviate the security officers' inspection burden. The neural architectures typically utilized in relevant literature are Convolutional Neural Networks (CNNs), with Vision Transformers (ViTs) rarely employed. In order to address this gap, this paper conducts a comprehensive evaluation of relevant ViT architectures on illicit item detection in X-ray images. This study utilizes both Transformer and hybrid backbones, such as SWIN and NextViT, and detectors, such as DINO and RT-DETR. The results demonstrate the remarkable accuracy of the DINO Transformer detector in the low-data regime, the impressive real-time performance of YOLOv8, and the effectiveness of the hybrid NextViT backbone.
A Survey on Large Language Models from Concept to Implementation
Mar 27, 2024Recent advancements in Large Language Models (LLMs), particularly those built on Transformer architectures, have significantly broadened the scope of natural language processing (NLP) applications, transcending their initial use in chatbot technology. This paper investigates the multifaceted applications of these models, with an emphasis on the GPT series. This exploration focuses on the transformative impact of artificial intelligence (AI) driven tools in revolutionizing traditional tasks like coding and problem-solving, while also paving new paths in research and development across diverse industries. From code interpretation and image captioning to facilitating the construction of interactive systems and advancing computational domains, Transformer models exemplify a synergy of deep learning, data analysis, and neural network design. This survey provides an in-depth look at the latest research in Transformer models, highlighting their versatility and the potential they hold for transforming diverse application sectors, thereby offering readers a comprehensive understanding of the current and future landscape of Transformer-based LLMs in practical applications.
Enhancing Adversarial Training with Prior Knowledge Distillation for Robust Image Compression
Mar 11, 2024
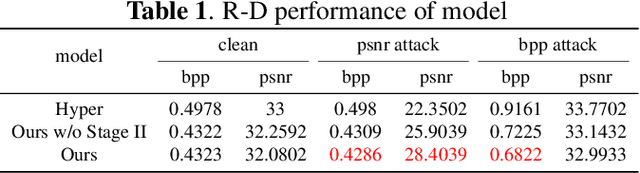
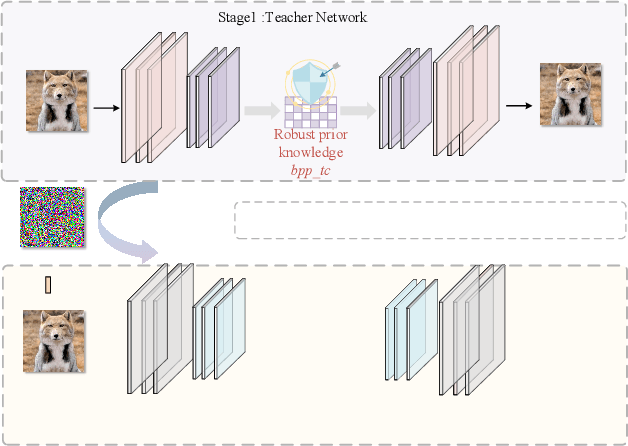
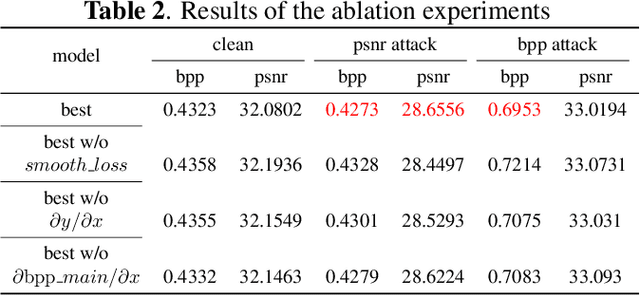
Deep neural network-based image compression (NIC) has achieved excellent performance, but NIC method models have been shown to be susceptible to backdoor attacks. Adversarial training has been validated in image compression models as a common method to enhance model robustness. However, the improvement effect of adversarial training on model robustness is limited. In this paper, we propose a prior knowledge-guided adversarial training framework for image compression models. Specifically, first, we propose a gradient regularization constraint for training robust teacher models. Subsequently, we design a knowledge distillation based strategy to generate a priori knowledge from the teacher model to the student model for guiding adversarial training. Experimental results show that our method improves the reconstruction quality by about 9dB when the Kodak dataset is elected as the backdoor attack object for psnr attack. Compared with Ma2023, our method has a 5dB higher PSNR output at high bitrate points.