 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Representing Noisy Image Without Denoising
Jan 18, 2023
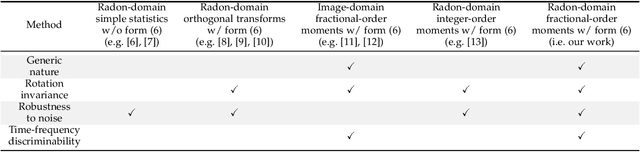
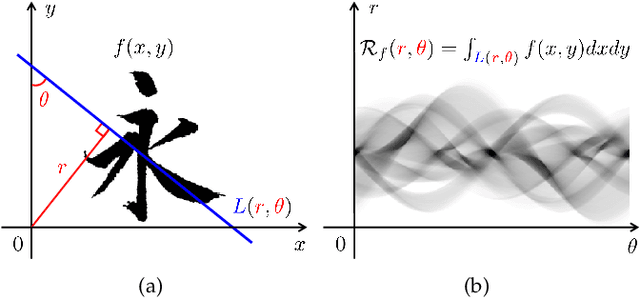
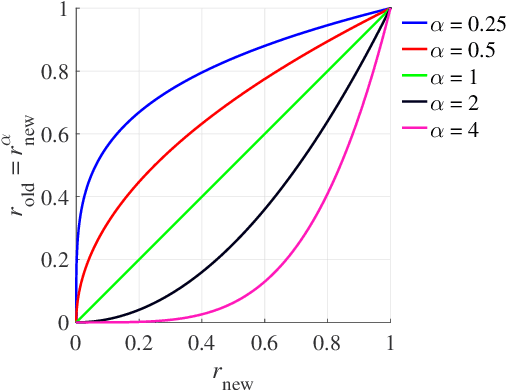
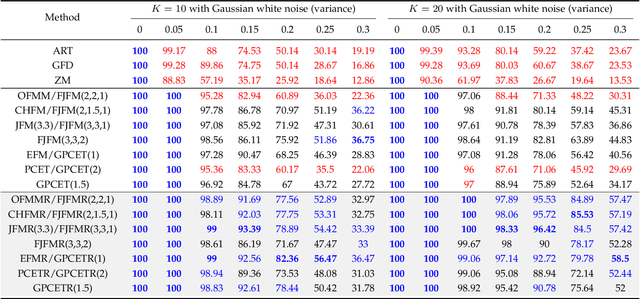
A long-standing topic in artificial intelligence is the effective recognition of patterns from noisy images. In this regard, the recent data-driven paradigm considers 1) improving the representation robustness by adding noisy samples in training phase (i.e., data augmentation) or 2) pre-processing the noisy image by learning to solve the inverse problem (i.e., image denoising). However, such methods generally exhibit inefficient process and unstable result, limiting their practical applications. In this paper, we explore a non-learning paradigm that aims to derive robust representation directly from noisy images, without the denoising as pre-processing. Here, the noise-robust representation is designed as Fractional-order Moments in Radon space (FMR), with also beneficial properties of orthogonality and rotation invariance. Unlike earlier integer-order methods, our work is a more generic design taking such classical methods as special cases, and the introduced fractional-order parameter offers time-frequency analysis capability that is not available in classical methods. Formally, both implicit and explicit paths for constructing the FMR are discussed in detail. Extensive simulation experiments and an image security application are provided to demonstrate the uniqueness and usefulness of our FMR, especially for noise robustness, rotation invariance, and time-frequency discriminability.
DeepFocus: Fast focus and astigmatism correction for electron microscopy
May 08, 2023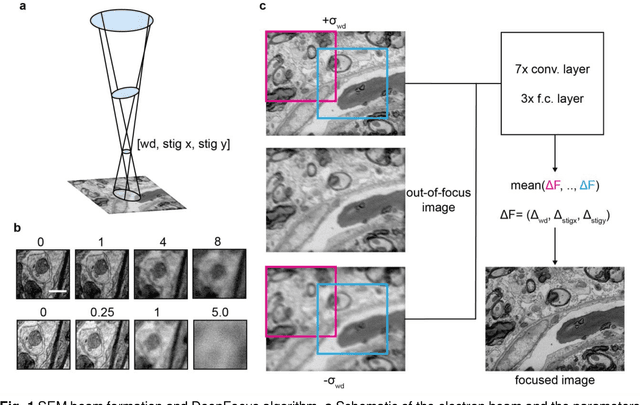
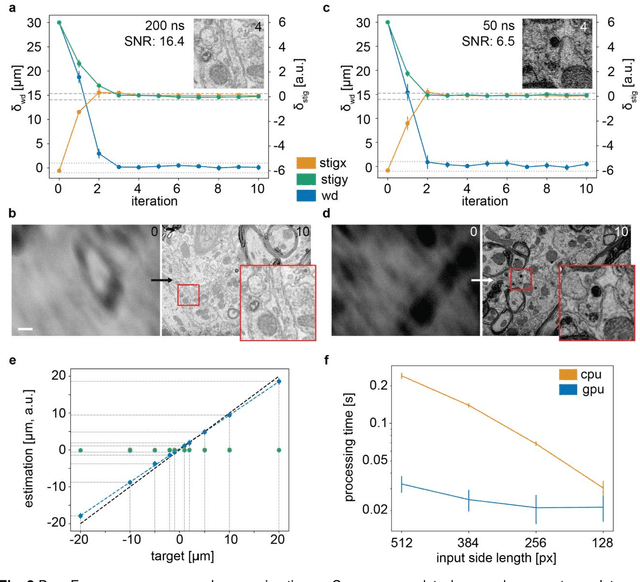
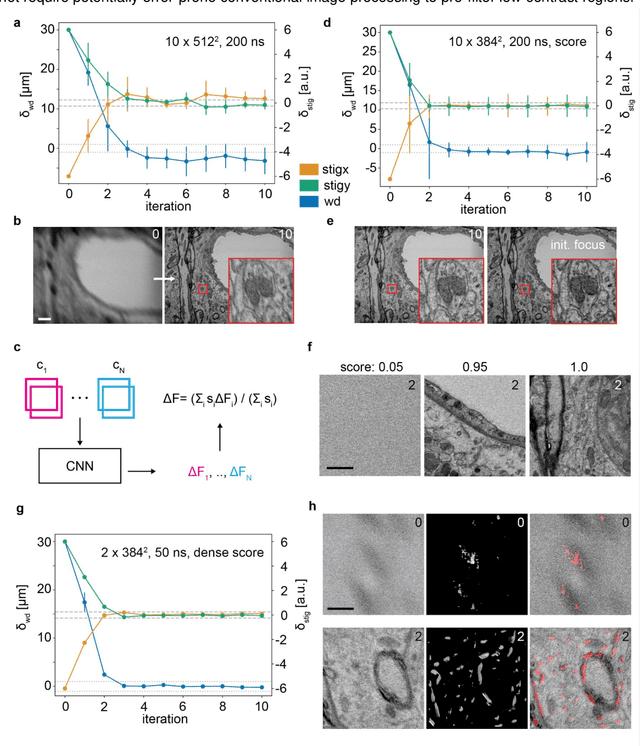
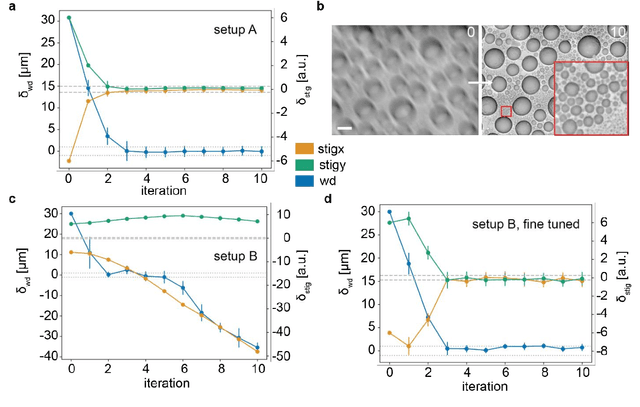
High-throughput 2D and 3D scanning electron microscopy, which relies on automation and dependable control algorithms, requires high image quality with minimal human intervention. Classical focus and astigmatism correction algorithms attempt to explicitly model image formation and subsequently aberration correction. Such models often require parameter adjustments by experts when deployed to new microscopes, challenging samples, or imaging conditions to prevent unstable convergence, making them hard to use in practice or unreliable. Here, we introduce DeepFocus, a purely data-driven method for aberration correction in scanning electron microscopy. DeepFocus works under very low signal-to-noise ratio conditions, reduces processing times by more than an order of magnitude compared to the state-of-the-art method, rapidly converges within a large aberration range, and is easily recalibrated to different microscopes or challenging samples.
Learning Combinatorial Prompts for Universal Controllable Image Captioning
Mar 11, 2023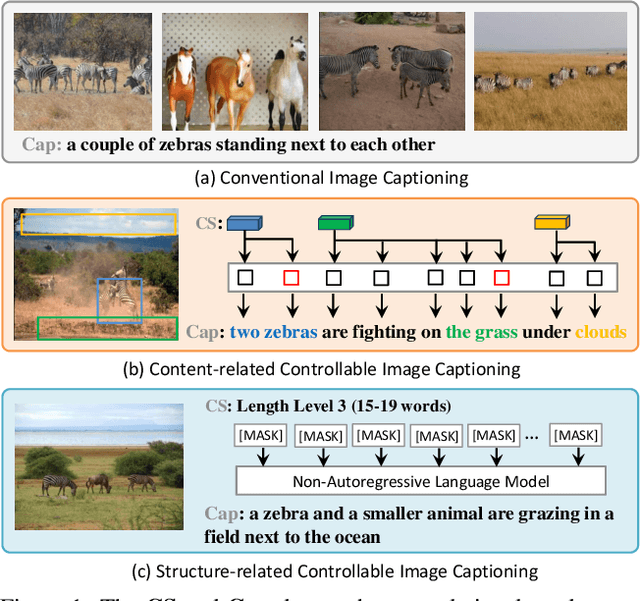
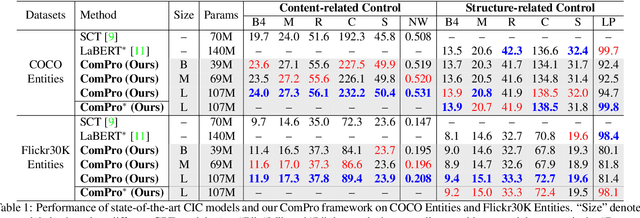
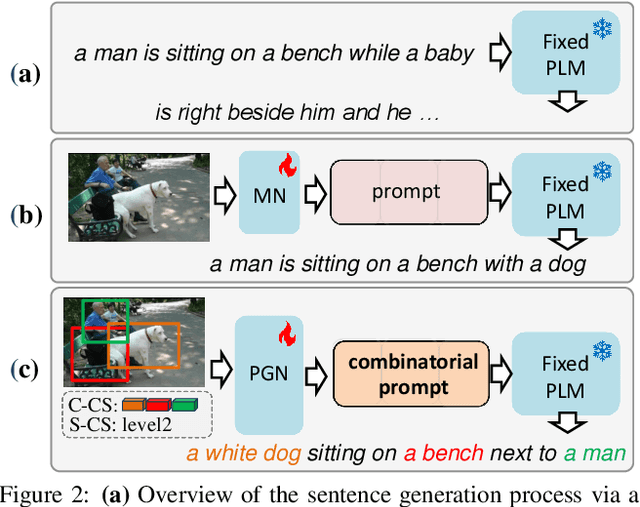
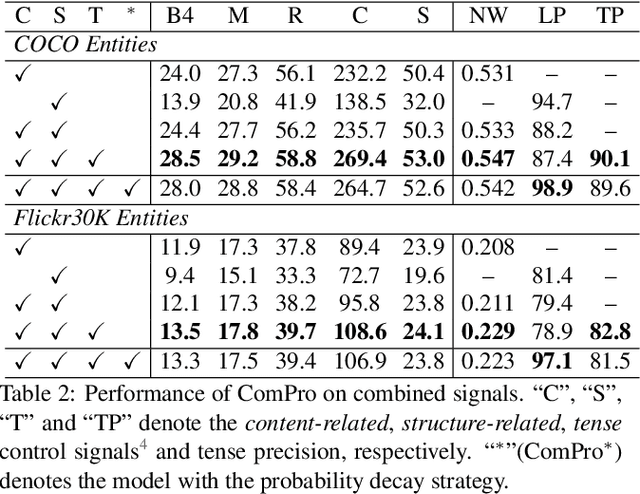
Controllable Image Captioning (CIC) -- generating natural language descriptions about images under the guidance of given control signals -- is one of the most promising directions towards next-generation captioning systems. Till now, various kinds of control signals for CIC have been proposed, ranging from content-related control to structure-related control. However, due to the format and target gaps of different control signals, all existing CIC works (or architectures) only focus on one certain control signal, and overlook the human-like combinatorial ability. By ``combinatorial", we mean that our humans can easily meet multiple needs (or constraints) simultaneously when generating descriptions. To this end, we propose a novel prompt-based framework for CIC by learning Combinatorial Prompts, dubbed as ComPro. Specifically, we directly utilize a pretrained language model GPT-2 as our language model, which can help to bridge the gap between different signal-specific CIC architectures. Then, we reformulate the CIC as a prompt-guide sentence generation problem, and propose a new lightweight prompt generation network to generate the combinatorial prompts for different kinds of control signals. For different control signals, we further design a new mask attention mechanism to realize the prompt-based CIC. Due to its simplicity, our ComPro can easily be extended to more complex combined control signals by concatenating these prompts. Extensive experiments on two prevalent CIC benchmarks have verified the effectiveness and efficiency of our ComPro on both single and combined control signals.
Towards Versatile and Efficient Visual Knowledge Injection into Pre-trained Language Models with Cross-Modal Adapters
May 12, 2023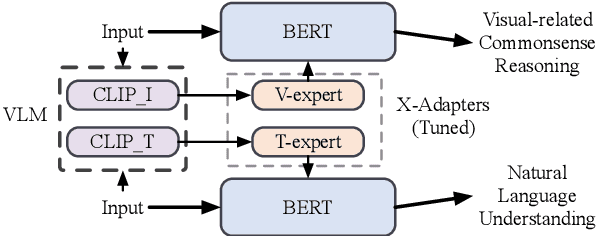
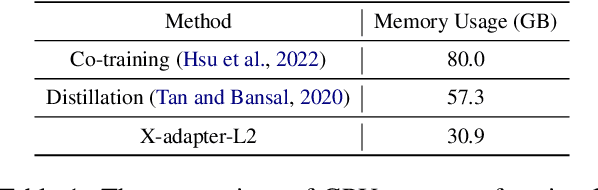
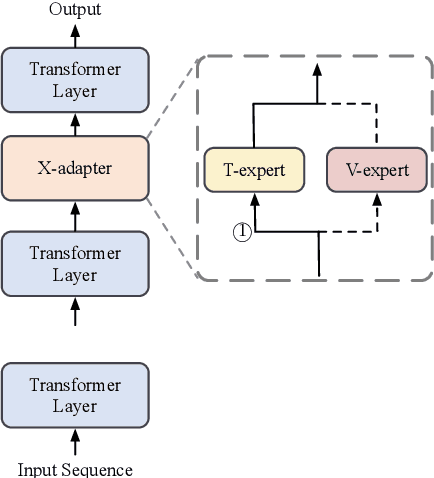

Humans learn language via multi-modal knowledge. However, due to the text-only pre-training scheme, most existing pre-trained language models (PLMs) are hindered from the multi-modal information. To inject visual knowledge into PLMs, existing methods incorporate either the text or image encoder of vision-language models (VLMs) to encode the visual information and update all the original parameters of PLMs for knowledge fusion. In this paper, we propose a new plug-and-play module, X-adapter, to flexibly leverage the aligned visual and textual knowledge learned in pre-trained VLMs and efficiently inject them into PLMs. Specifically, we insert X-adapters into PLMs, and only the added parameters are updated during adaptation. To fully exploit the potential in VLMs, X-adapters consist of two sub-modules, V-expert and T-expert, to fuse VLMs' image and text representations, respectively. We can opt for activating different sub-modules depending on the downstream tasks. Experimental results show that our method can significantly improve the performance on object-color reasoning and natural language understanding (NLU) tasks compared with PLM baselines.
Content-based jewellery item retrieval using the local region-based histograms
May 12, 2023
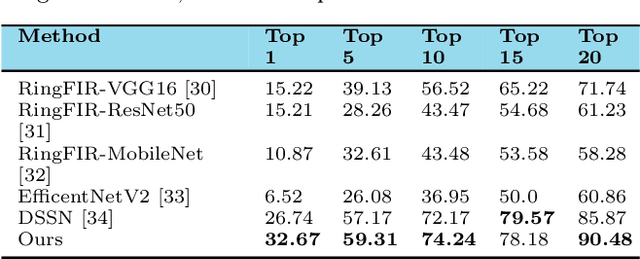

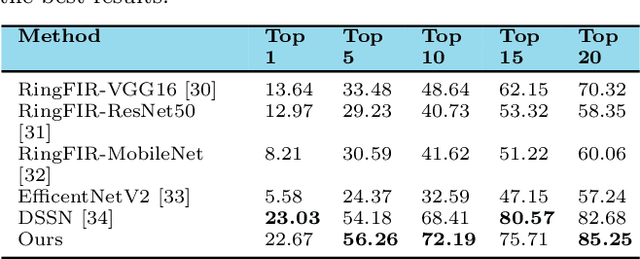
Jewellery item retrieval is regularly used to find what people want on online marketplaces using a sample query reference image. Considering recent developments, due to the simultaneous nature of various jewelry items, various jewelry goods' occlusion in images or visual streams, as well as shape deformation, content-based jewellery item retrieval (CBJIR) still has limitations whenever it pertains to visual searching in the actual world. This article proposed a content-based jewellery item retrieval method using the local region-based histograms in HSV color space. Using five local regions, our novel jewellery classification module extracts the specific feature vectors from the query image. The jewellery classification module is also applied to the jewellery database to extract feature vectors. Finally, the similarity score is matched between the database and query features vectors to retrieve the jewellery items from the database. The proposed method performance is tested on publicly available jewellery item retrieval datasets, i.e. ringFIR and Fashion Product Images dataset. The experimental results demonstrate the dominance of the proposed method over the baseline methods for retrieving desired jewellery products.
Super-Resolution of License Plate Images Using Attention Modules and Sub-Pixel Convolution Layers
May 27, 2023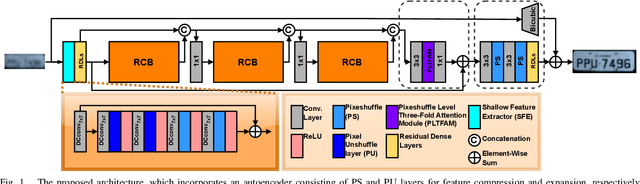
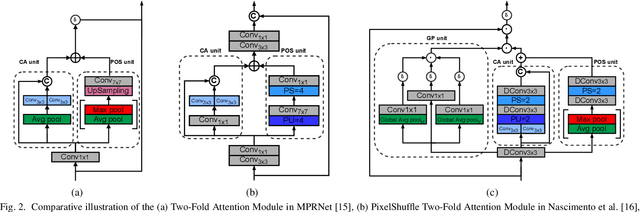


Recent years have seen significant developments in the field of License Plate Recognition (LPR) through the integration of deep learning techniques and the increasing availability of training data. Nevertheless, reconstructing license plates (LPs) from low-resolution (LR) surveillance footage remains challenging. To address this issue, we introduce a Single-Image Super-Resolution (SISR) approach that integrates attention and transformer modules to enhance the detection of structural and textural features in LR images. Our approach incorporates sub-pixel convolution layers (also known as PixelShuffle) and a loss function that uses an Optical Character Recognition (OCR) model for feature extraction. We trained the proposed architecture on synthetic images created by applying heavy Gaussian noise to high-resolution LP images from two public datasets, followed by bicubic downsampling. As a result, the generated images have a Structural Similarity Index Measure (SSIM) of less than 0.10. Our results show that our approach for reconstructing these low-resolution synthesized images outperforms existing ones in both quantitative and qualitative measures. Our code is publicly available at https://github.com/valfride/lpr-rsr-ext/
Concept Decomposition for Visual Exploration and Inspiration
May 31, 2023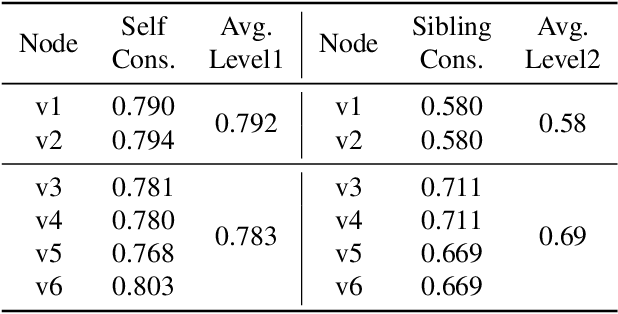
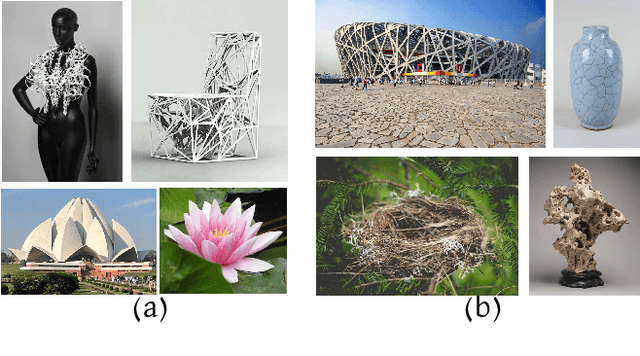

A creative idea is often born from transforming, combining, and modifying ideas from existing visual examples capturing various concepts. However, one cannot simply copy the concept as a whole, and inspiration is achieved by examining certain aspects of the concept. Hence, it is often necessary to separate a concept into different aspects to provide new perspectives. In this paper, we propose a method to decompose a visual concept, represented as a set of images, into different visual aspects encoded in a hierarchical tree structure. We utilize large vision-language models and their rich latent space for concept decomposition and generation. Each node in the tree represents a sub-concept using a learned vector embedding injected into the latent space of a pretrained text-to-image model. We use a set of regularizations to guide the optimization of the embedding vectors encoded in the nodes to follow the hierarchical structure of the tree. Our method allows to explore and discover new concepts derived from the original one. The tree provides the possibility of endless visual sampling at each node, allowing the user to explore the hidden sub-concepts of the object of interest. The learned aspects in each node can be combined within and across trees to create new visual ideas, and can be used in natural language sentences to apply such aspects to new designs.
Towards a Robust Framework for NeRF Evaluation
May 31, 2023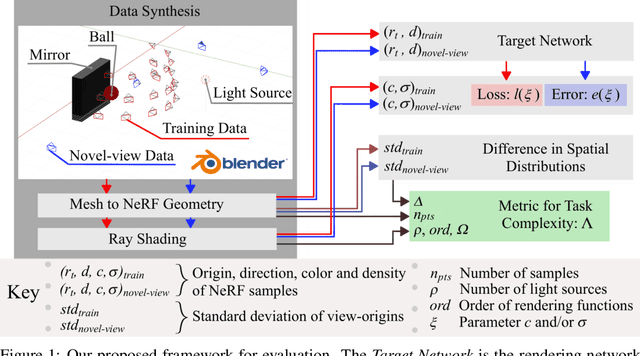

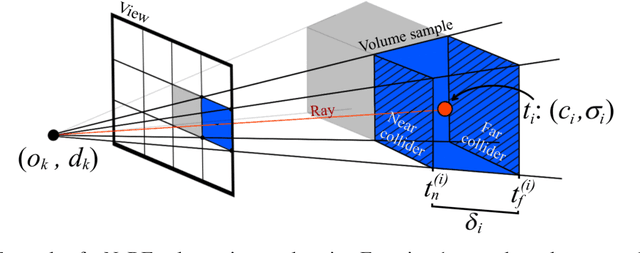
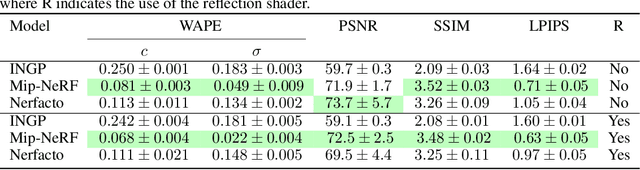
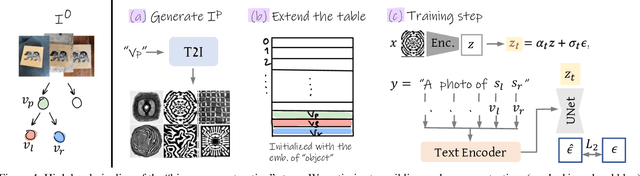
Neural Radiance Field (NeRF) research has attracted significant attention recently, with 3D modelling, virtual/augmented reality, and visual effects driving its application. While current NeRF implementations can produce high quality visual results, there is a conspicuous lack of reliable methods for evaluating them. Conventional image quality assessment methods and analytical metrics (e.g. PSNR, SSIM, LPIPS etc.) only provide approximate indicators of performance since they generalise the ability of the entire NeRF pipeline. Hence, in this paper, we propose a new test framework which isolates the neural rendering network from the NeRF pipeline and then performs a parametric evaluation by training and evaluating the NeRF on an explicit radiance field representation. We also introduce a configurable approach for generating representations specifically for evaluation purposes. This employs ray-casting to transform mesh models into explicit NeRF samples, as well as to "shade" these representations. Combining these two approaches, we demonstrate how different "tasks" (scenes with different visual effects or learning strategies) and types of networks (NeRFs and depth-wise implicit neural representations (INRs)) can be evaluated within this framework. Additionally, we propose a novel metric to measure task complexity of the framework which accounts for the visual parameters and the distribution of the spatial data. Our approach offers the potential to create a comparative objective evaluation framework for NeRF methods.
LOWA: Localize Objects in the Wild with Attributes
May 31, 2023

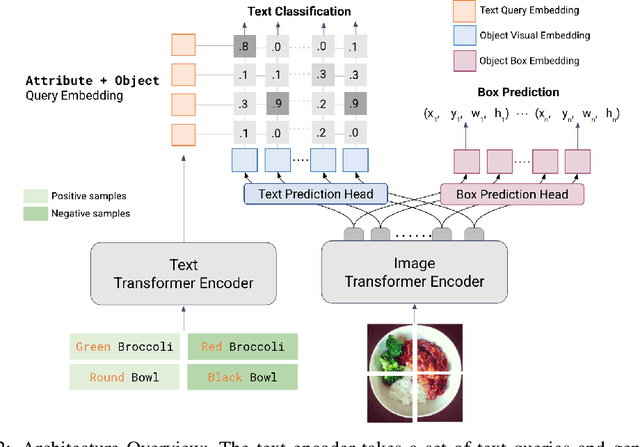
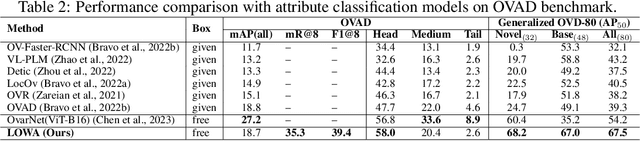
We present LOWA, a novel method for localizing objects with attributes effectively in the wild. It aims to address the insufficiency of current open-vocabulary object detectors, which are limited by the lack of instance-level attribute classification and rare class names. To train LOWA, we propose a hybrid vision-language training strategy to learn object detection and recognition with class names as well as attribute information. With LOWA, users can not only detect objects with class names, but also able to localize objects by attributes. LOWA is built on top of a two-tower vision-language architecture and consists of a standard vision transformer as the image encoder and a similar transformer as the text encoder. To learn the alignment between visual and text inputs at the instance level, we train LOWA with three training steps: object-level training, attribute-aware learning, and free-text joint training of objects and attributes. This hybrid training strategy first ensures correct object detection, then incorporates instance-level attribute information, and finally balances the object class and attribute sensitivity. We evaluate our model performance of attribute classification and attribute localization on the Open-Vocabulary Attribute Detection (OVAD) benchmark and the Visual Attributes in the Wild (VAW) dataset, and experiments indicate strong zero-shot performance. Ablation studies additionally demonstrate the effectiveness of each training step of our approach.
A Universal Latent Fingerprint Enhancer Using Transformers
May 31, 2023
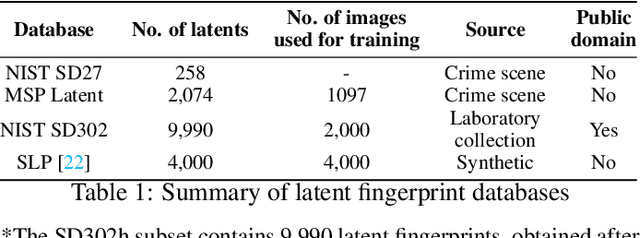

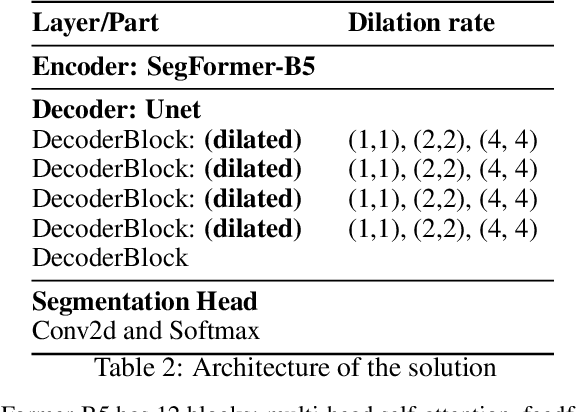
Forensic science heavily relies on analyzing latent fingerprints, which are crucial for criminal investigations. However, various challenges, such as background noise, overlapping prints, and contamination, make the identification process difficult. Moreover, limited access to real crime scene and laboratory-generated databases hinders the development of efficient recognition algorithms. This study aims to develop a fast method, which we call ULPrint, to enhance various latent fingerprint types, including those obtained from real crime scenes and laboratory-created samples, to boost fingerprint recognition system performance. In closed-set identification accuracy experiments, the enhanced image was able to improve the performance of the MSU-AFIS from 61.56\% to 75.19\% in the NIST SD27 database, from 67.63\% to 77.02\% in the MSP Latent database, and from 46.90\% to 52.12\% in the NIST SD302 database. Our contributions include (1) the development of a two-step latent fingerprint enhancement method that combines Ridge Segmentation with UNet and Mix Visual Transformer (MiT) SegFormer-B5 encoder architecture, (2) the implementation of multiple dilated convolutions in the UNet architecture to capture intricate, non-local patterns better and enhance ridge segmentation, and (3) the guided blending of the predicted ridge mask with the latent fingerprint. This novel approach, ULPrint, streamlines the enhancement process, addressing challenges across diverse latent fingerprint types to improve forensic investigations and criminal justice outcomes.