 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HSCNet++: Hierarchical Scene Coordinate Classification and Regression for Visual Localization with Transformer
May 05, 2023
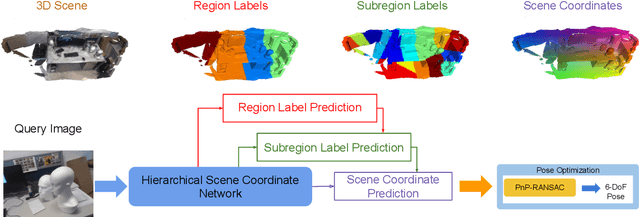
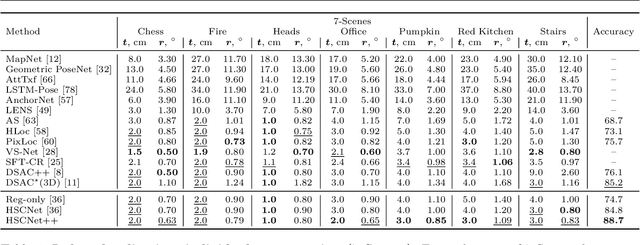
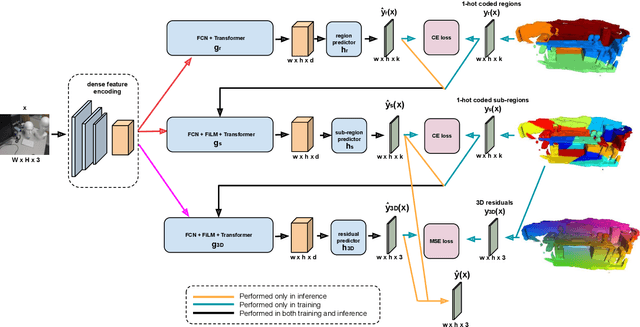
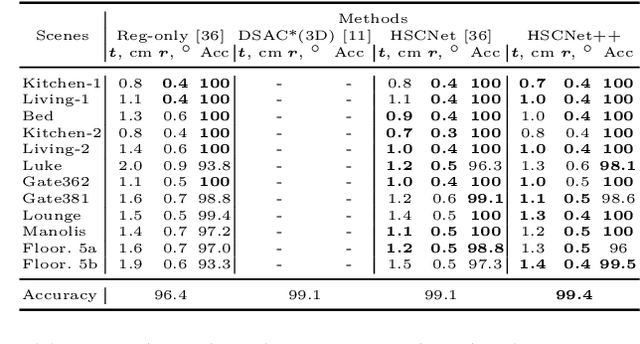
Visual localization is critical to many applications in computer vision and robotics. To address single-image RGB localization, state-of-the-art feature-based methods match local descriptors between a query image and a pre-built 3D model. Recently, deep neural networks have been exploited to regress the mapping between raw pixels and 3D coordinates in the scene, and thus the matching is implicitly performed by the forward pass through the network. However, in a large and ambiguous environment, learning such a regression task directly can be difficult for a single network. In this work, we present a new hierarchical scene coordinate network to predict pixel scene coordinates in a coarse-to-fine manner from a single RGB image. The proposed method, which is an extension of HSCNet, allows us to train compact models which scale robustly to large environments. It sets a new state-of-the-art for single-image localization on the 7-Scenes, 12 Scenes, Cambridge Landmarks datasets, and the combined indoor scenes.
Devil is in the Queries: Advancing Mask Transformers for Real-world Medical Image Segmentation and Out-of-Distribution Localization
Apr 01, 2023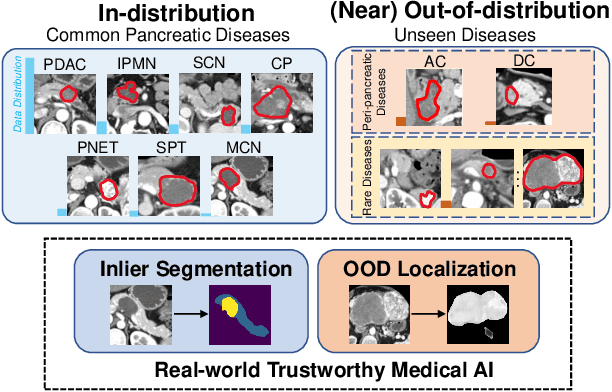
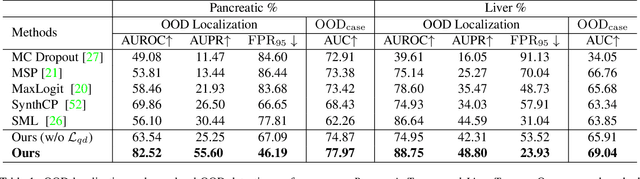
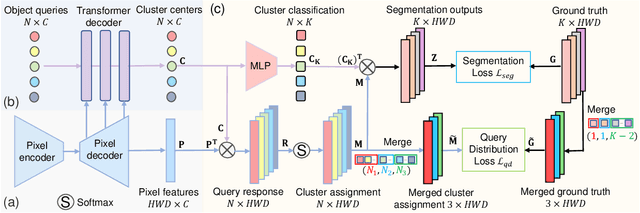

Real-world medical image segmentation has tremendous long-tailed complexity of objects, among which tail conditions correlate with relatively rare diseases and are clinically significant. A trustworthy medical AI algorithm should demonstrate its effectiveness on tail conditions to avoid clinically dangerous damage in these out-of-distribution (OOD) cases. In this paper, we adopt the concept of object queries in Mask Transformers to formulate semantic segmentation as a soft cluster assignment. The queries fit the feature-level cluster centers of inliers during training. Therefore, when performing inference on a medical image in real-world scenarios, the similarity between pixels and the queries detects and localizes OOD regions. We term this OOD localization as MaxQuery. Furthermore, the foregrounds of real-world medical images, whether OOD objects or inliers, are lesions. The difference between them is less than that between the foreground and background, possibly misleading the object queries to focus redundantly on the background. Thus, we propose a query-distribution (QD) loss to enforce clear boundaries between segmentation targets and other regions at the query level, improving the inlier segmentation and OOD indication. Our proposed framework is tested on two real-world segmentation tasks, i.e., segmentation of pancreatic and liver tumors, outperforming previous state-of-the-art algorithms by an average of 7.39% on AUROC, 14.69% on AUPR, and 13.79% on FPR95 for OOD localization. On the other hand, our framework improves the performance of inlier segmentation by an average of 5.27% DSC when compared with the leading baseline nnUNet.
Doubly Robust Self-Training
Jun 01, 2023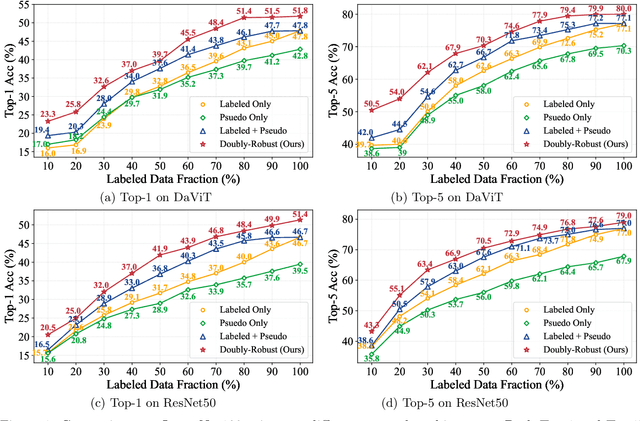
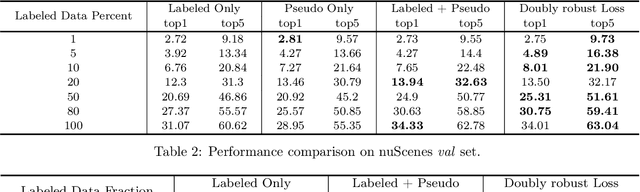
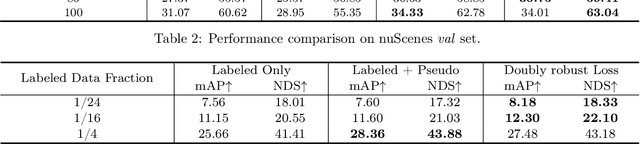
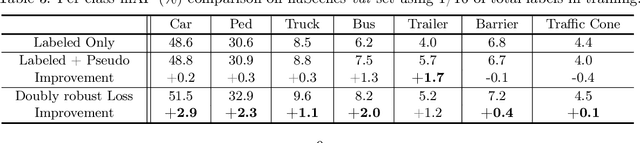
Self-training is an important technique for solving semi-supervised learning problems. It leverages unlabeled data by generating pseudo-labels and combining them with a limited labeled dataset for training. The effectiveness of self-training heavily relies on the accuracy of these pseudo-labels. In this paper, we introduce doubly robust self-training, a novel semi-supervised algorithm that provably balances between two extremes. When the pseudo-labels are entirely incorrect, our method reduces to a training process solely using labeled data. Conversely, when the pseudo-labels are completely accurate, our method transforms into a training process utilizing all pseudo-labeled data and labeled data, thus increasing the effective sample size. Through empirical evaluations on both the ImageNet dataset for image classification and the nuScenes autonomous driving dataset for 3D object detection, we demonstrate the superiority of the doubly robust loss over the standard self-training baseline.
Overcoming Language Bias in Remote Sensing Visual Question Answering via Adversarial Training
Jun 01, 2023
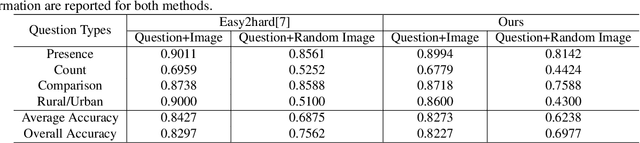
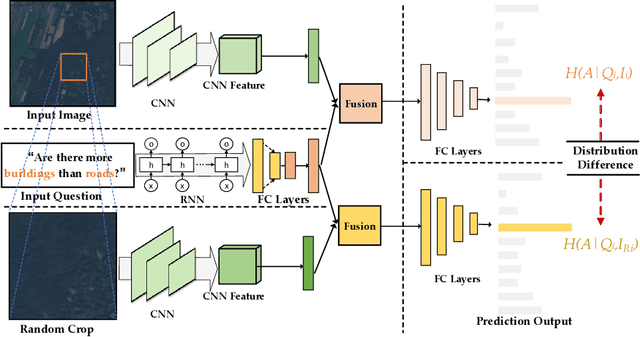
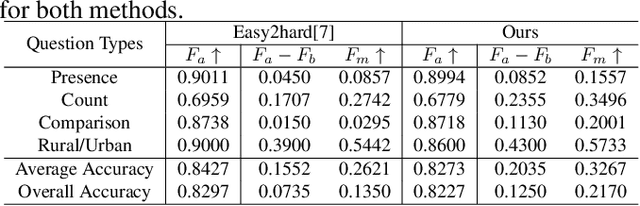
The Visual Question Answering (VQA) system offers a user-friendly interface and enables human-computer interaction. However, VQA models commonly face the challenge of language bias, resulting from the learned superficial correlation between questions and answers. To address this issue, in this study, we present a novel framework to reduce the language bias of the VQA for remote sensing data (RSVQA). Specifically, we add an adversarial branch to the original VQA framework. Based on the adversarial branch, we introduce two regularizers to constrain the training process against language bias. Furthermore, to evaluate the performance in terms of language bias, we propose a new metric that combines standard accuracy with the performance drop when incorporating question and random image information. Experimental results demonstrate the effectiveness of our method. We believe that our method can shed light on future work for reducing language bias on the RSVQA task.
Discriminative Deep Feature Visualization for Explainable Face Recognition
Jun 01, 2023

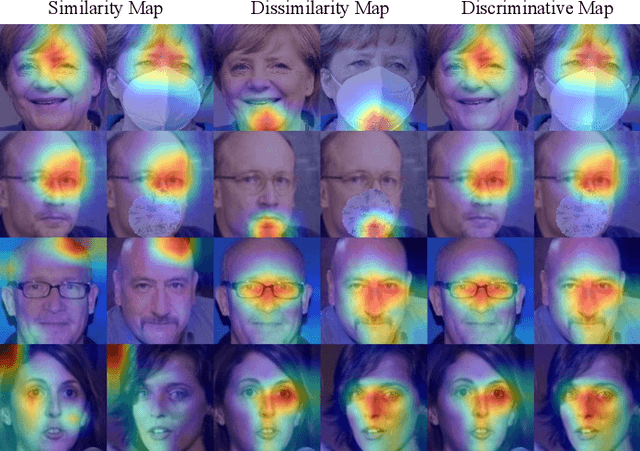
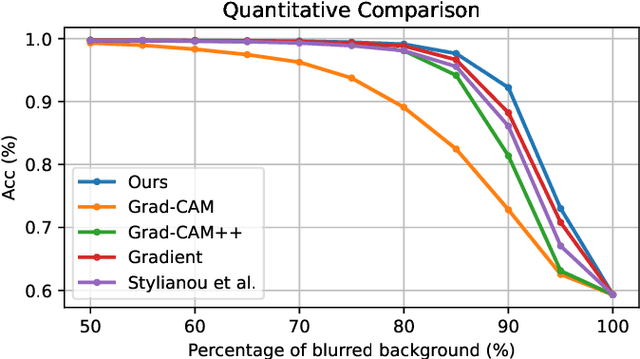
Despite the huge success of deep convolutional neural networks in face recognition (FR) tasks, current methods lack explainability for their predictions because of their "black-box" nature. In recent years, studies have been carried out to give an interpretation of the decision of a deep FR system. However, the affinity between the input facial image and the extracted deep features has not been explored. This paper contributes to the problem of explainable face recognition by first conceiving a face reconstruction-based explanation module, which reveals the correspondence between the deep feature and the facial regions. To further interpret the decision of an FR model, a novel visual saliency explanation algorithm has been proposed. It provides insightful explanation by producing visual saliency maps that represent similar and dissimilar regions between input faces. A detailed analysis has been presented for the generated visual explanation to show the effectiveness of the proposed method.
Blind Omnidirectional Image Quality Assessment: Integrating Local Statistics and Global Semantics
Feb 24, 2023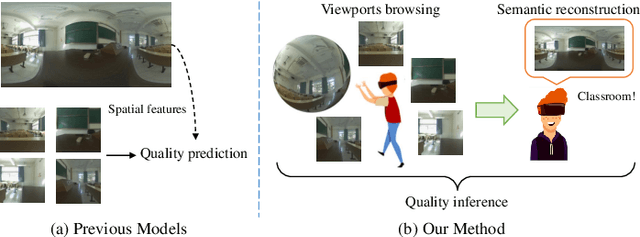
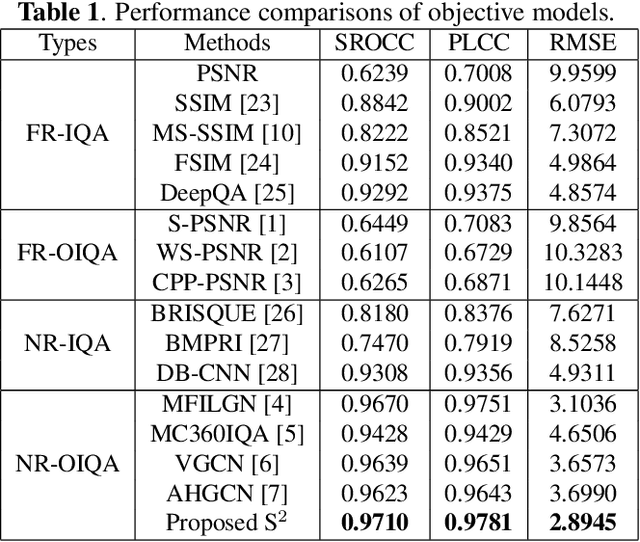
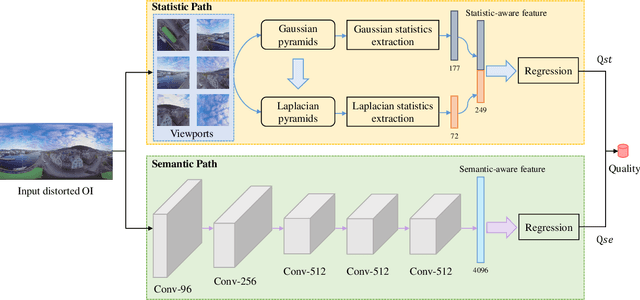
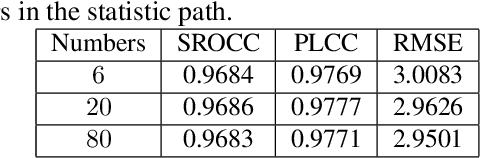
Omnidirectional image quality assessment (OIQA) aims to predict the perceptual quality of omnidirectional images that cover the whole 180$\times$360$^{\circ}$ viewing range of the visual environment. Here we propose a blind/no-reference OIQA method named S$^2$ that bridges the gap between low-level statistics and high-level semantics of omnidirectional images. Specifically, statistic and semantic features are extracted in separate paths from multiple local viewports and the hallucinated global omnidirectional image, respectively. A quality regression along with a weighting process is then followed that maps the extracted quality-aware features to a perceptual quality prediction. Experimental results demonstrate that the proposed S$^2$ method offers highly competitive performance against state-of-the-art methods.
QuickSRNet: Plain Single-Image Super-Resolution Architecture for Faster Inference on Mobile Platforms
Mar 08, 2023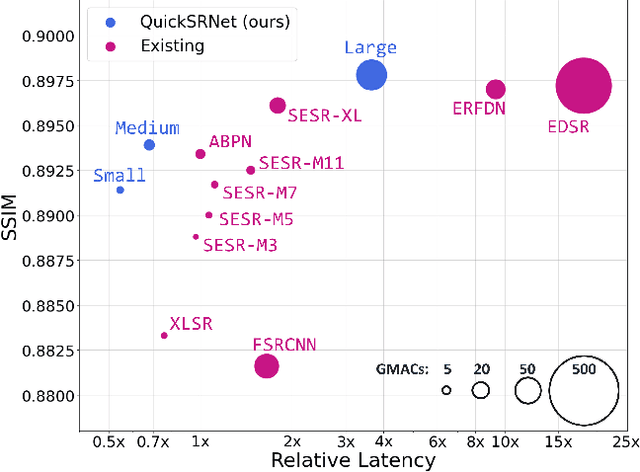
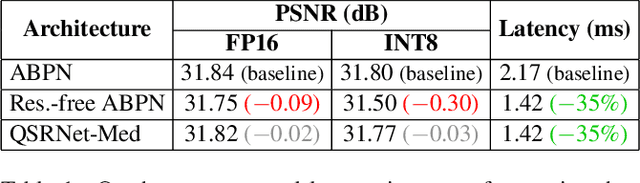

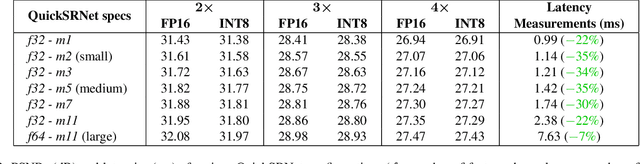
In this work, we present QuickSRNet, an efficient super-resolution architecture for real-time applications on mobile platforms. Super-resolution clarifies, sharpens, and upscales an image to higher resolution. Applications such as gaming and video playback along with the ever-improving display capabilities of TVs, smartphones, and VR headsets are driving the need for efficient upscaling solutions. While existing deep learning-based super-resolution approaches achieve impressive results in terms of visual quality, enabling real-time DL-based super-resolution on mobile devices with compute, thermal, and power constraints is challenging. To address these challenges, we propose QuickSRNet, a simple yet effective architecture that provides better accuracy-to-latency trade-offs than existing neural architectures for single-image super resolution. We present training tricks to speed up existing residual-based super-resolution architectures while maintaining robustness to quantization. Our proposed architecture produces 1080p outputs via 2x upscaling in 2.2 ms on a modern smartphone, making it ideal for high-fps real-time applications.
Evaluation of Extra Pixel Interpolation with Mask Processing for Medical Image Segmentation with Deep Learning
Feb 22, 2023
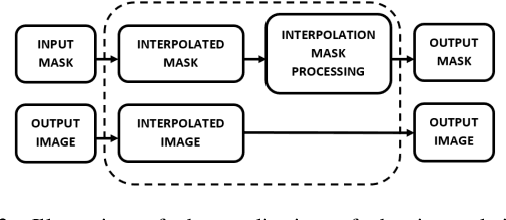
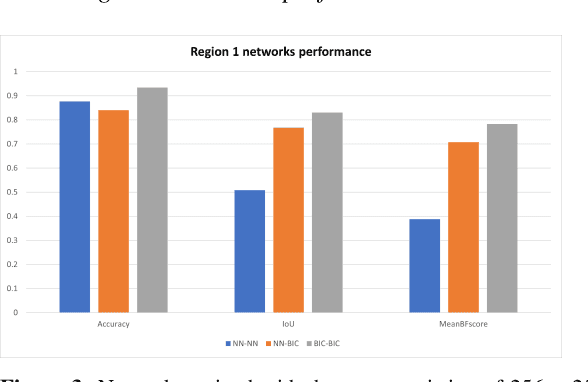
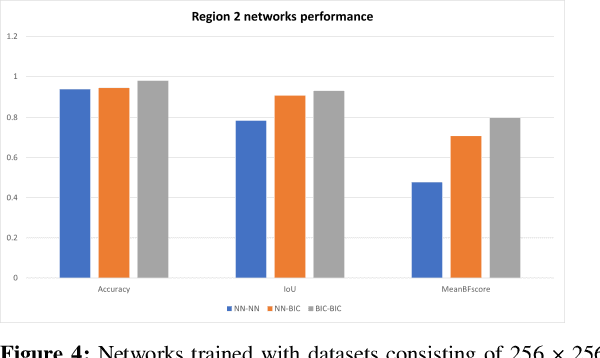
In this study, the author evaluated the use of an extra pixel interpolation algorithm with mask processing versus non-extra pixel interpolation algorithm when interpolating training dataset images and masks for medical image segmentation with deep learning. The author also examined scenarios of interpolating dataset images and masks using different algorithms: extra pixel for interpolating dataset images and non-extra pixel for interpolating dataset masks. The evaluation outcomes revealed that training on datasets consisting of images and masks both interpolated using the extra pixel bicubic interpolation (BIC) resulted in better segmentation accuracy compared to using either the non-extra pixel nearest neighbor interpolation (NN) or BIC for dataset images and NN for dataset masks. Specifically, the evaluation revealed that the BIC-BIC network was a 8.9578 % (with image size 256 x 256) and a 1.0496 % (with image size 384 x 384) increase of NN-NN network compared to the NN-BIC network which was a 8.3127 % (with image size 256 x 256) and a 0.2887 % (with image size 384 x 384) increase of NN-NN network.
SSSegmenation: An Open Source Supervised Semantic Segmentation Toolbox Based on PyTorch
May 26, 2023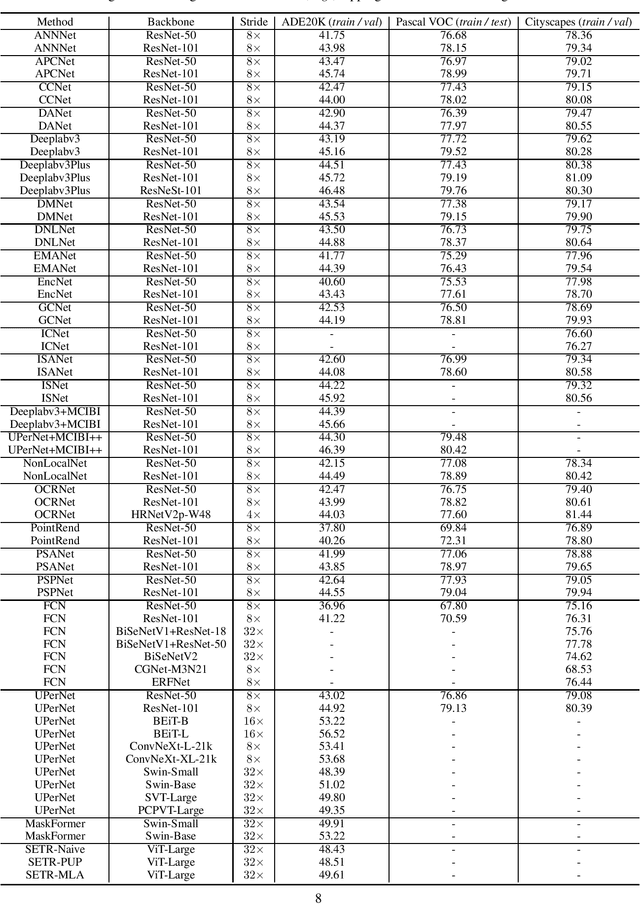
This paper presents SSSegmenation, which is an open source supervised semantic image segmentation toolbox based on PyTorch. The design of this toolbox is motivated by MMSegmentation while it is easier to use because of fewer dependencies and achieves superior segmentation performance under a comparable training and testing setup. Moreover, the toolbox also provides plenty of trained weights for popular and contemporary semantic segmentation methods, including Deeplab, PSPNet, OCRNet, MaskFormer, \emph{etc}. We expect that this toolbox can contribute to the future development of semantic segmentation. Codes and model zoos are available at \href{https://github.com/SegmentationBLWX/sssegmentation/}{SSSegmenation}.
HiFA: High-fidelity Text-to-3D with Advanced Diffusion Guidance
May 31, 2023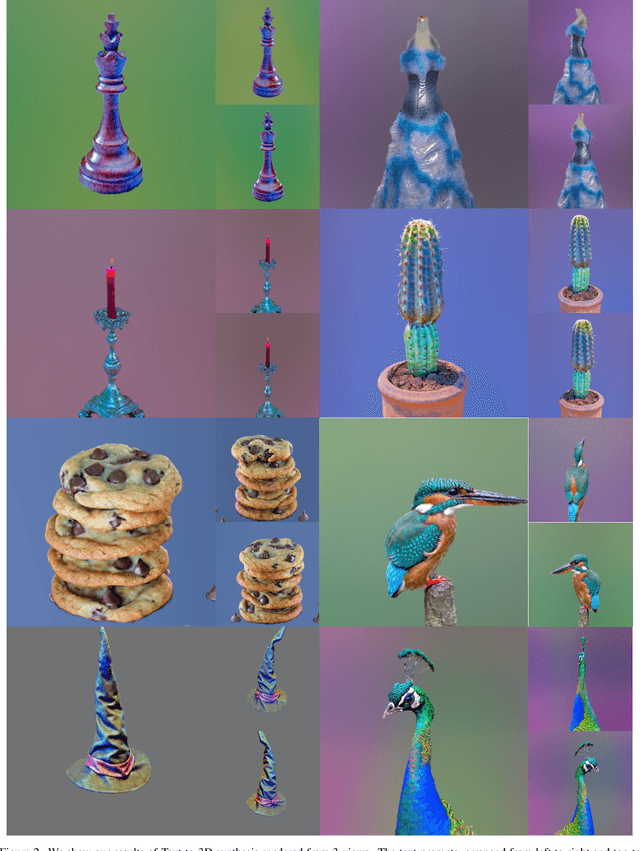
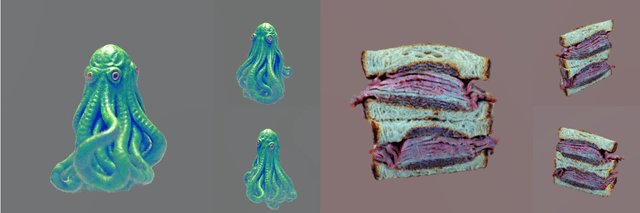

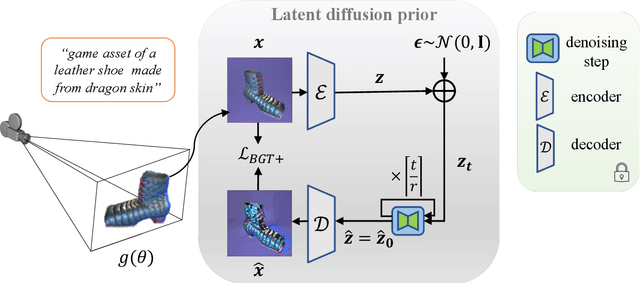
Automatic text-to-3D synthesis has achieved remarkable advancements through the optimization of 3D models. Existing methods commonly rely on pre-trained text-to-image generative models, such as diffusion models, providing scores for 2D renderings of Neural Radiance Fields (NeRFs) and being utilized for optimizing NeRFs. However, these methods often encounter artifacts and inconsistencies across multiple views due to their limited understanding of 3D geometry. To address these limitations, we propose a reformulation of the optimization loss using the diffusion prior. Furthermore, we introduce a novel training approach that unlocks the potential of the diffusion prior. To improve 3D geometry representation, we apply auxiliary depth supervision for NeRF-rendered images and regularize the density field of NeRFs. Extensive experiments demonstrate the superiority of our method over prior works, resulting in advanced photo-realism and improved multi-view consistency.