 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Jun 01, 2023


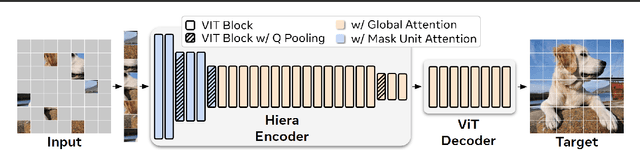
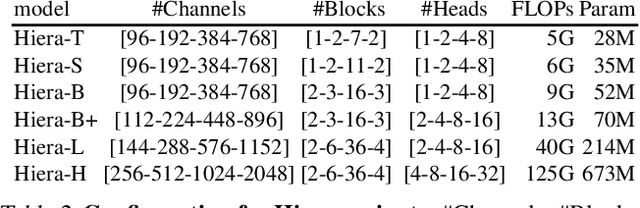
Modern hierarchical vision transformers have added several vision-specific components in the pursuit of supervised classification performance. While these components lead to effective accuracies and attractive FLOP counts, the added complexity actually makes these transformers slower than their vanilla ViT counterparts. In this paper, we argue that this additional bulk is unnecessary. By pretraining with a strong visual pretext task (MAE), we can strip out all the bells-and-whistles from a state-of-the-art multi-stage vision transformer without losing accuracy. In the process, we create Hiera, an extremely simple hierarchical vision transformer that is more accurate than previous models while being significantly faster both at inference and during training. We evaluate Hiera on a variety of tasks for image and video recognition. Our code and models are available at https://github.com/facebookresearch/hiera.
Correspondence-Free Domain Alignment for Unsupervised Cross-Domain Image Retrieval
Feb 13, 2023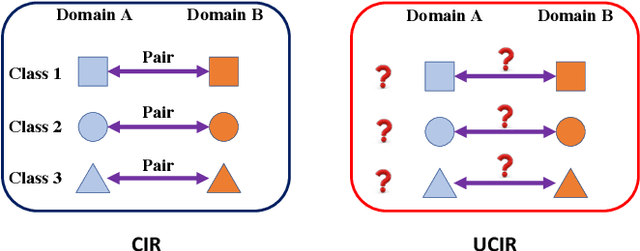
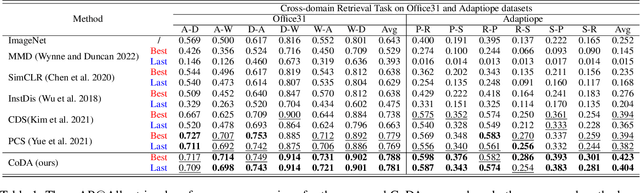
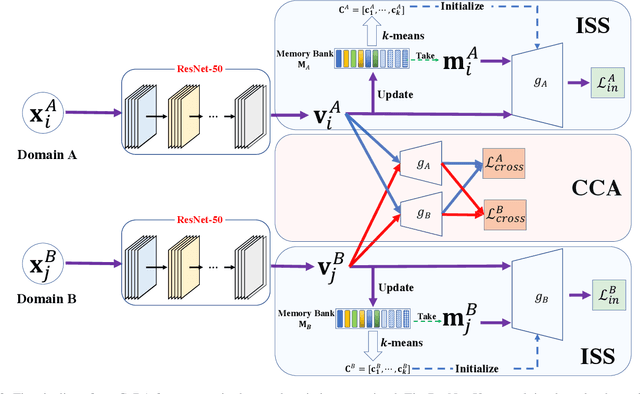
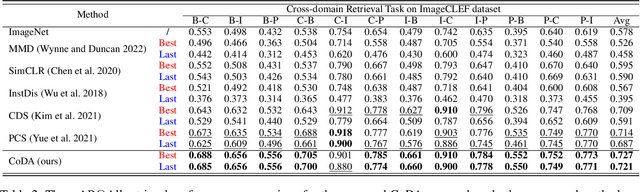
Cross-domain image retrieval aims at retrieving images across different domains to excavate cross-domain classificatory or correspondence relationships. This paper studies a less-touched problem of cross-domain image retrieval, i.e., unsupervised cross-domain image retrieval, considering the following practical assumptions: (i) no correspondence relationship, and (ii) no category annotations. It is challenging to align and bridge distinct domains without cross-domain correspondence. To tackle the challenge, we present a novel Correspondence-free Domain Alignment (CoDA) method to effectively eliminate the cross-domain gap through In-domain Self-matching Supervision (ISS) and Cross-domain Classifier Alignment (CCA). To be specific, ISS is presented to encapsulate discriminative information into the latent common space by elaborating a novel self-matching supervision mechanism. To alleviate the cross-domain discrepancy, CCA is proposed to align distinct domain-specific classifiers. Thanks to the ISS and CCA, our method could encode the discrimination into the domain-invariant embedding space for unsupervised cross-domain image retrieval. To verify the effectiveness of the proposed method, extensive experiments are conducted on four benchmark datasets compared with six state-of-the-art methods.
The Tunnel Effect: Building Data Representations in Deep Neural Networks
May 31, 2023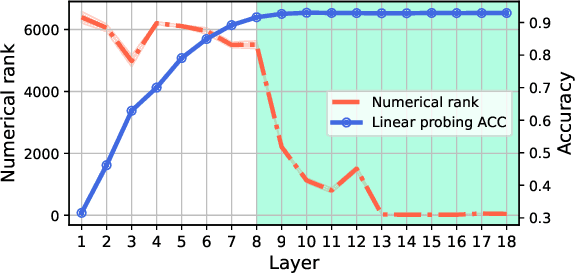
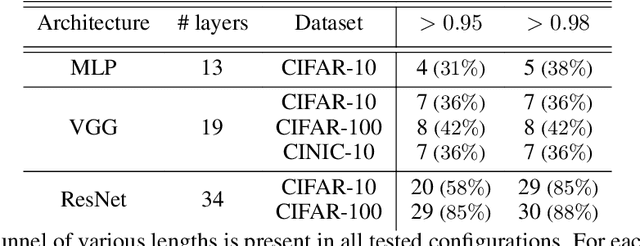
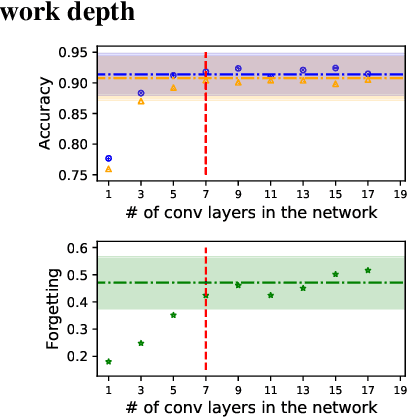
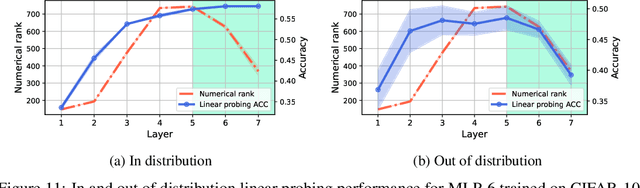
Deep neural networks are widely known for their remarkable effectiveness across various tasks, with the consensus that deeper networks implicitly learn more complex data representations. This paper shows that sufficiently deep networks trained for supervised image classification split into two distinct parts that contribute to the resulting data representations differently. The initial layers create linearly-separable representations, while the subsequent layers, which we refer to as \textit{the tunnel}, compress these representations and have a minimal impact on the overall performance. We explore the tunnel's behavior through comprehensive empirical studies, highlighting that it emerges early in the training process. Its depth depends on the relation between the network's capacity and task complexity. Furthermore, we show that the tunnel degrades out-of-distribution generalization and discuss its implications for continual learning.
Image to Sphere: Learning Equivariant Features for Efficient Pose Prediction
Feb 27, 2023
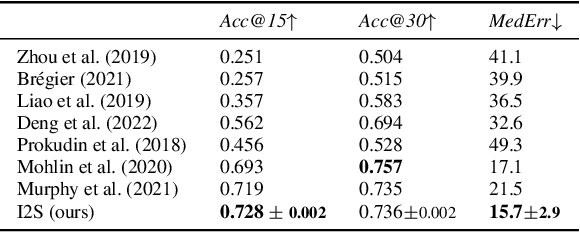
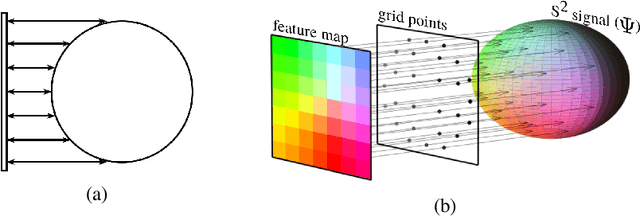
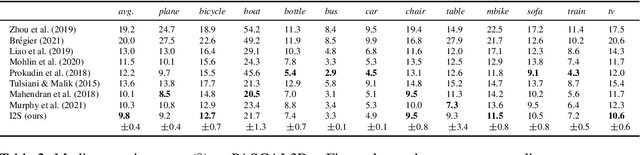
Predicting the pose of objects from a single image is an important but difficult computer vision problem. Methods that predict a single point estimate do not predict the pose of objects with symmetries well and cannot represent uncertainty. Alternatively, some works predict a distribution over orientations in $\mathrm{SO}(3)$. However, training such models can be computation- and sample-inefficient. Instead, we propose a novel mapping of features from the image domain to the 3D rotation manifold. Our method then leverages $\mathrm{SO}(3)$ equivariant layers, which are more sample efficient, and outputs a distribution over rotations that can be sampled at arbitrary resolution. We demonstrate the effectiveness of our method at object orientation prediction, and achieve state-of-the-art performance on the popular PASCAL3D+ dataset. Moreover, we show that our method can model complex object symmetries, without any modifications to the parameters or loss function. Code is available at https://dmklee.github.io/image2sphere.
Improving Scene Text Image Super-Resolution via Dual Prior Modulation Network
Feb 21, 2023
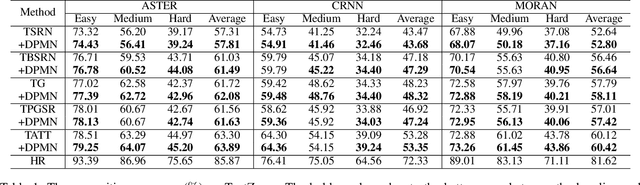

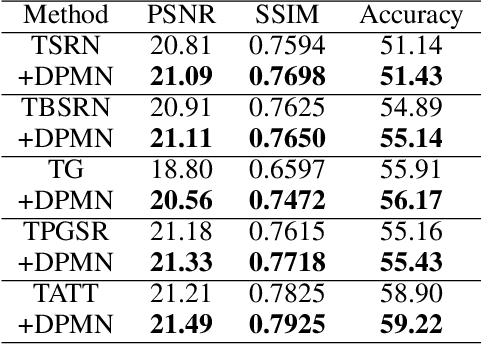
Scene text image super-resolution (STISR) aims to simultaneously increase the resolution and legibility of the text images, and the resulting images will significantly affect the performance of downstream tasks. Although numerous progress has been made, existing approaches raise two crucial issues: (1) They neglect the global structure of the text, which bounds the semantic determinism of the scene text. (2) The priors, e.g., text prior or stroke prior, employed in existing works, are extracted from pre-trained text recognizers. That said, such priors suffer from the domain gap including low resolution and blurriness caused by poor imaging conditions, leading to incorrect guidance. Our work addresses these gaps and proposes a plug-and-play module dubbed Dual Prior Modulation Network (DPMN), which leverages dual image-level priors to bring performance gain over existing approaches. Specifically, two types of prior-guided refinement modules, each using the text mask or graphic recognition result of the low-quality SR image from the preceding layer, are designed to improve the structural clarity and semantic accuracy of the text, respectively. The following attention mechanism hence modulates two quality-enhanced images to attain a superior SR result. Extensive experiments validate that our method improves the image quality and boosts the performance of downstream tasks over five typical approaches on the benchmark. Substantial visualizations and ablation studies demonstrate the advantages of the proposed DPMN. Code is available at: https://github.com/jdfxzzy/DPMN.
STAIR: Learning Sparse Text and Image Representation in Grounded Tokens
Feb 08, 2023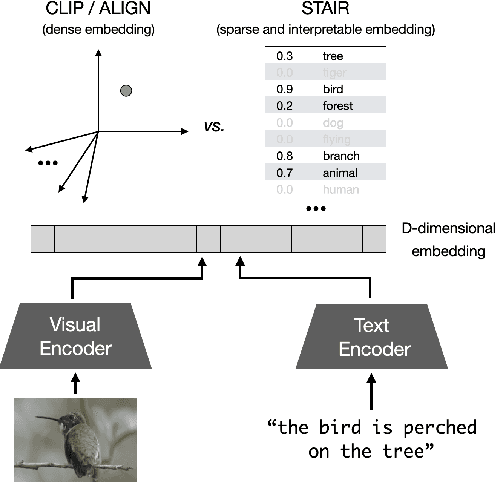

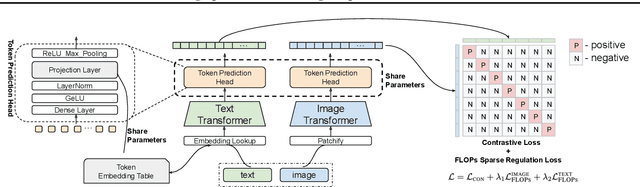

Image and text retrieval is one of the foundational tasks in the vision and language domain with multiple real-world applications. State-of-the-art approaches, e.g. CLIP, ALIGN, represent images and texts as dense embeddings and calculate the similarity in the dense embedding space as the matching score. On the other hand, sparse semantic features like bag-of-words models are more interpretable, but believed to suffer from inferior accuracy than dense representations. In this work, we show that it is possible to build a sparse semantic representation that is as powerful as, or even better than, dense presentations. We extend the CLIP model and build a sparse text and image representation (STAIR), where the image and text are mapped to a sparse token space. Each token in the space is a (sub-)word in the vocabulary, which is not only interpretable but also easy to integrate with existing information retrieval systems. STAIR model significantly outperforms a CLIP model with +$4.9\%$ and +$4.3\%$ absolute Recall@1 improvement on COCO-5k text$\rightarrow$image and image$\rightarrow$text retrieval respectively. It also achieved better performance on both of ImageNet zero-shot and linear probing compared to CLIP.
OPE-SR: Orthogonal Position Encoding for Designing a Parameter-free Upsampling Module in Arbitrary-scale Image Super-Resolution
Mar 02, 2023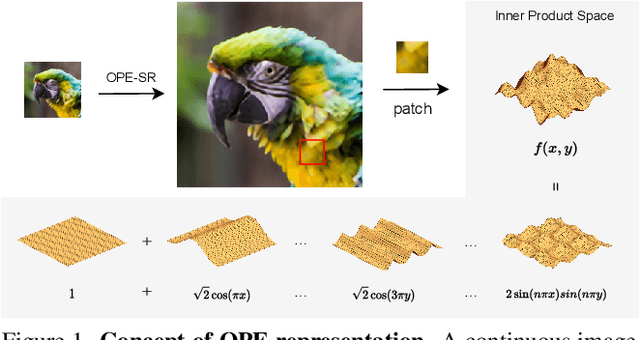

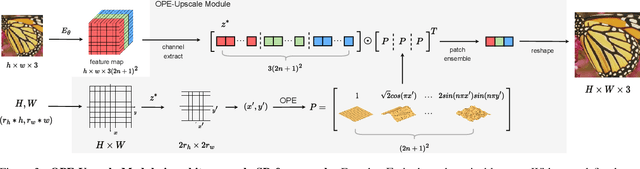
Implicit neural representation (INR) is a popular approach for arbitrary-scale image super-resolution (SR), as a key component of INR, position encoding improves its representation ability. Motivated by position encoding, we propose orthogonal position encoding (OPE) - an extension of position encoding - and an OPE-Upscale module to replace the INR-based upsampling module for arbitrary-scale image super-resolution. Same as INR, our OPE-Upscale Module takes 2D coordinates and latent code as inputs; however it does not require training parameters. This parameter-free feature allows the OPE-Upscale Module to directly perform linear combination operations to reconstruct an image in a continuous manner, achieving an arbitrary-scale image reconstruction. As a concise SR framework, our method has high computing efficiency and consumes less memory comparing to the state-of-the-art (SOTA), which has been confirmed by extensive experiments and evaluations. In addition, our method has comparable results with SOTA in arbitrary scale image super-resolution. Last but not the least, we show that OPE corresponds to a set of orthogonal basis, justifying our design principle.
Learning to Imagine: Visually-Augmented Natural Language Generation
Jun 04, 2023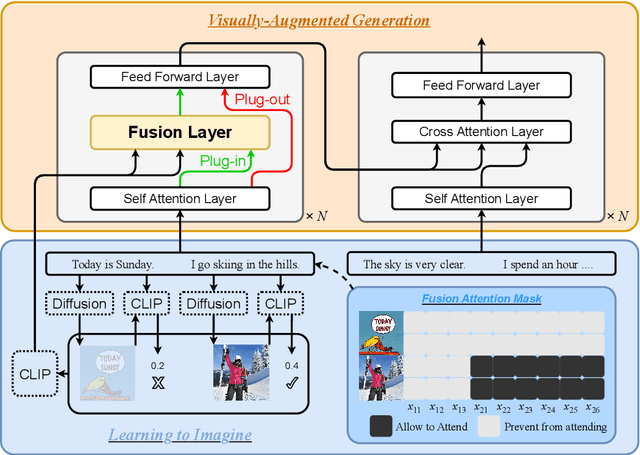
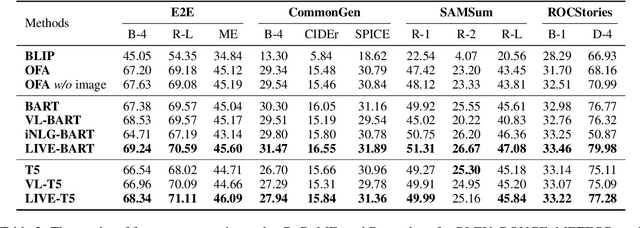
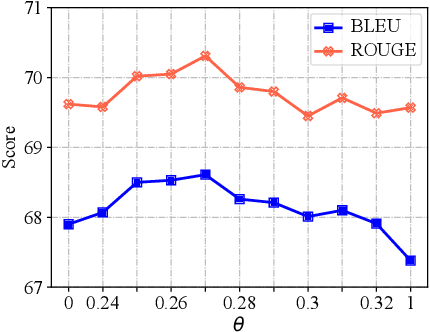
People often imagine relevant scenes to aid in the writing process. In this work, we aim to utilize visual information for composition in the same manner as humans. We propose a method, LIVE, that makes pre-trained language models (PLMs) Learn to Imagine for Visuallyaugmented natural language gEneration. First, we imagine the scene based on the text: we use a diffusion model to synthesize high-quality images conditioned on the input texts. Second, we use CLIP to determine whether the text can evoke the imagination in a posterior way. Finally, our imagination is dynamic, and we conduct synthesis for each sentence rather than generate only one image for an entire paragraph. Technically, we propose a novel plug-and-play fusion layer to obtain visually-augmented representations for each text. Our vision-text fusion layer is compatible with Transformerbased architecture. We have conducted extensive experiments on four generation tasks using BART and T5, and the automatic results and human evaluation demonstrate the effectiveness of our proposed method. We will release the code, model, and data at the link: https://github.com/RUCAIBox/LIVE.
ReliableSwap: Boosting General Face Swapping Via Reliable Supervision
Jun 08, 2023Almost all advanced face swapping approaches use reconstruction as the proxy task, i.e., supervision only exists when the target and source belong to the same person. Otherwise, lacking pixel-level supervision, these methods struggle for source identity preservation. This paper proposes to construct reliable supervision, dubbed cycle triplets, which serves as the image-level guidance when the source identity differs from the target one during training. Specifically, we use face reenactment and blending techniques to synthesize the swapped face from real images in advance, where the synthetic face preserves source identity and target attributes. However, there may be some artifacts in such a synthetic face. To avoid the potential artifacts and drive the distribution of the network output close to the natural one, we reversely take synthetic images as input while the real face as reliable supervision during the training stage of face swapping. Besides, we empirically find that the existing methods tend to lose lower-face details like face shape and mouth from the source. This paper additionally designs a FixerNet, providing discriminative embeddings of lower faces as an enhancement. Our face swapping framework, named ReliableSwap, can boost the performance of any existing face swapping network with negligible overhead. Extensive experiments demonstrate the efficacy of our ReliableSwap, especially in identity preservation. The project page is https://reliable-swap.github.io/.
Accurate Gigapixel Crowd Counting by Iterative Zooming and Refinement
May 16, 2023
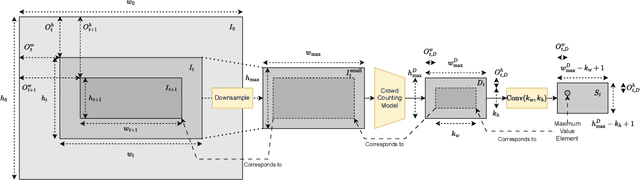

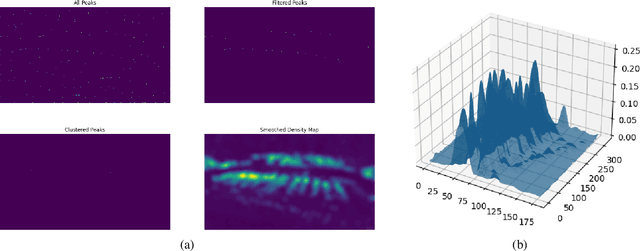
The increasing prevalence of gigapixel resolutions has presented new challenges for crowd counting. Such resolutions are far beyond the memory and computation limits of current GPUs, and available deep neural network architectures and training procedures are not designed for such massive inputs. Although several methods have been proposed to address these challenges, they are either limited to downsampling the input image to a small size, or borrowing from other gigapixel tasks, which are not tailored for crowd counting. In this paper, we propose a novel method called GigaZoom, which iteratively zooms into the densest areas of the image and refines coarser density maps with finer details. Through experiments, we show that GigaZoom obtains the state-of-the-art for gigapixel crowd counting and improves the accuracy of the next best method by 42%.