 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Non-Log-Concave and Nonsmooth Sampling via Langevin Monte Carlo Algorithms
May 25, 2023
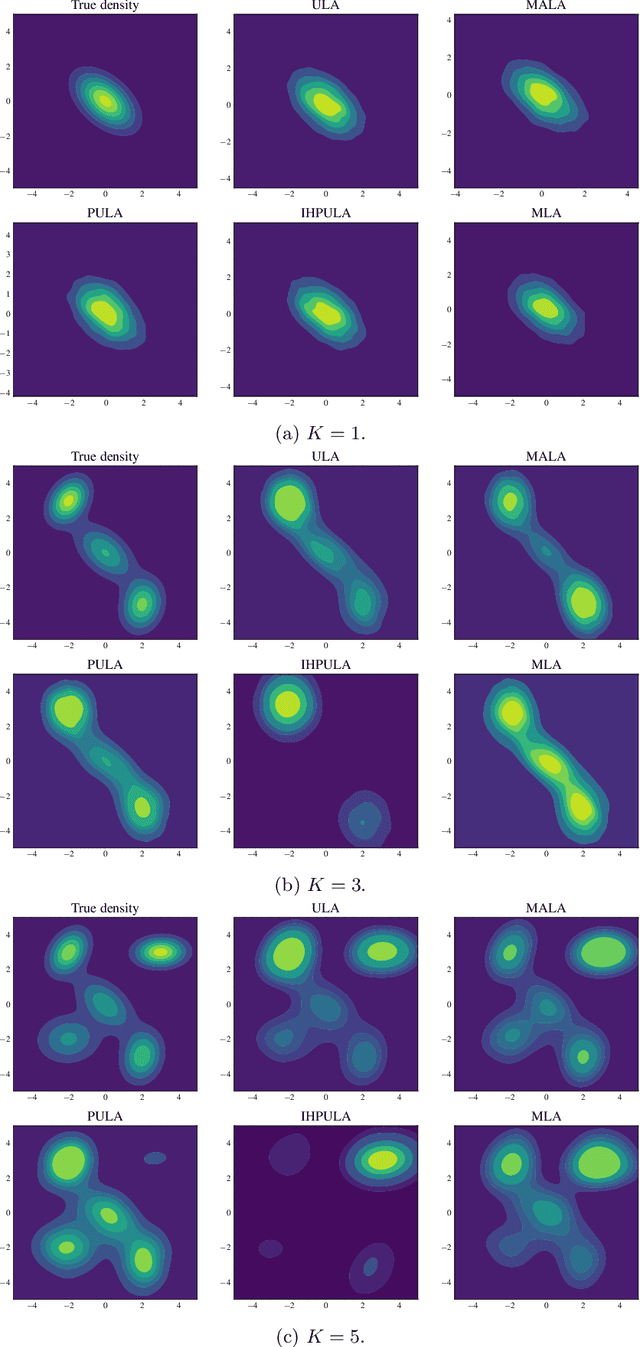
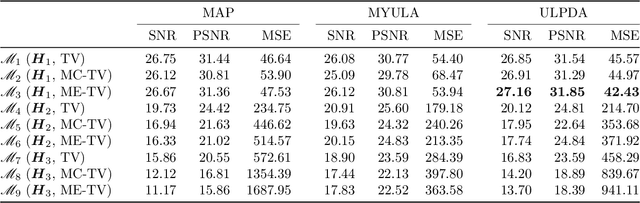
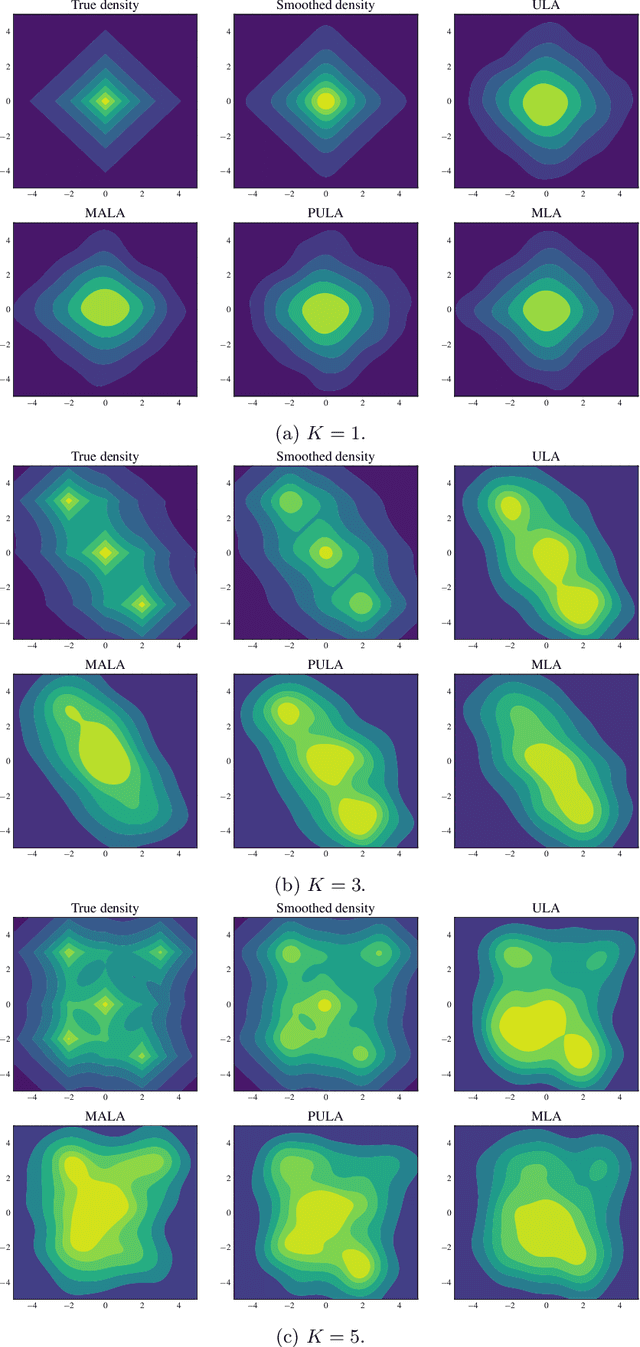
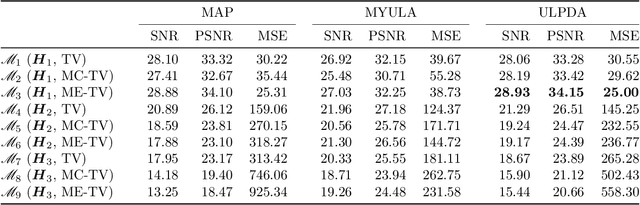
We study the problem of approximate sampling from non-log-concave distributions, e.g., Gaussian mixtures, which is often challenging even in low dimensions due to their multimodality. We focus on performing this task via Markov chain Monte Carlo (MCMC) methods derived from discretizations of the overdamped Langevin diffusions, which are commonly known as Langevin Monte Carlo algorithms. Furthermore, we are also interested in two nonsmooth cases for which a large class of proximal MCMC methods have been developed: (i) a nonsmooth prior is considered with a Gaussian mixture likelihood; (ii) a Laplacian mixture distribution. Such nonsmooth and non-log-concave sampling tasks arise from a wide range of applications to Bayesian inference and imaging inverse problems such as image deconvolution. We perform numerical simulations to compare the performance of most commonly used Langevin Monte Carlo algorithms.
Rectifying Group Irregularities in Explanations for Distribution Shift
May 25, 2023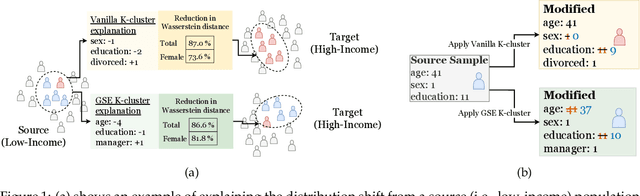

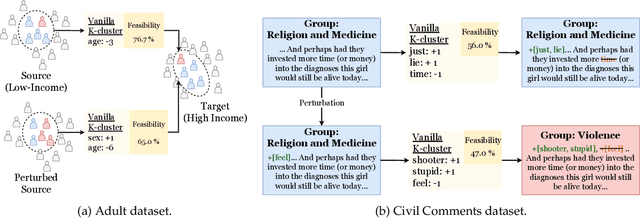
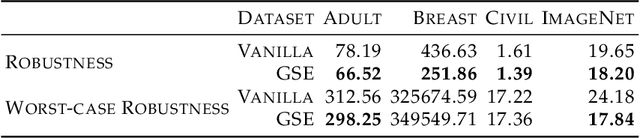
It is well-known that real-world changes constituting distribution shift adversely affect model performance. How to characterize those changes in an interpretable manner is poorly understood. Existing techniques to address this problem take the form of shift explanations that elucidate how to map samples from the original distribution toward the shifted one by reducing the disparity between these two distributions. However, these methods can introduce group irregularities, leading to explanations that are less feasible and robust. To address these issues, we propose Group-aware Shift Explanations (GSE), a method that produces interpretable explanations by leveraging worst-group optimization to rectify group irregularities. We demonstrate how GSE not only maintains group structures, such as demographic and hierarchical subpopulations, but also enhances feasibility and robustness in the resulting explanations in a wide range of tabular, language, and image settings.
The Curse of Recursion: Training on Generated Data Makes Models Forget
May 31, 2023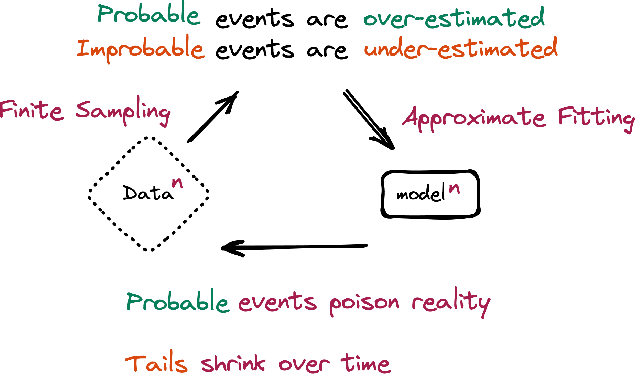
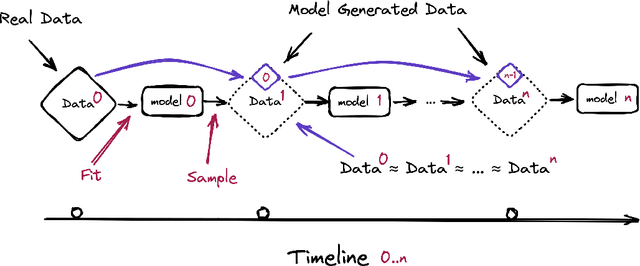
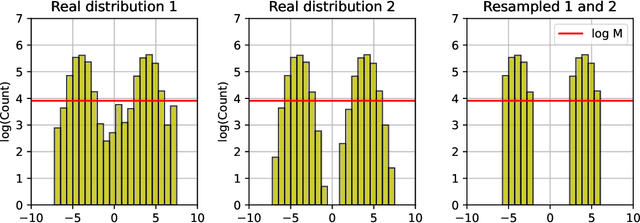
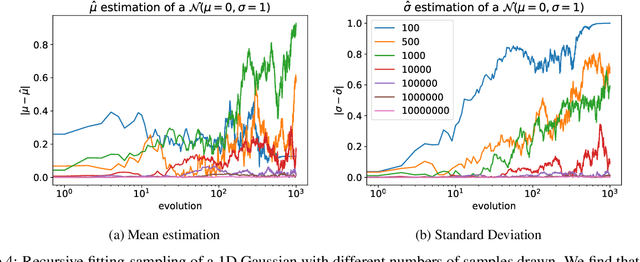
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
Fast-SNN: Fast Spiking Neural Network by Converting Quantized ANN
May 31, 2023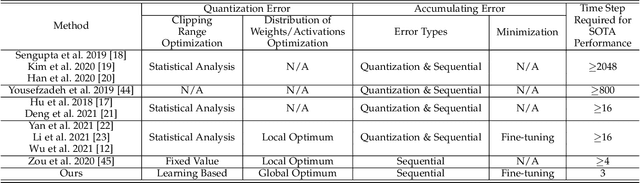
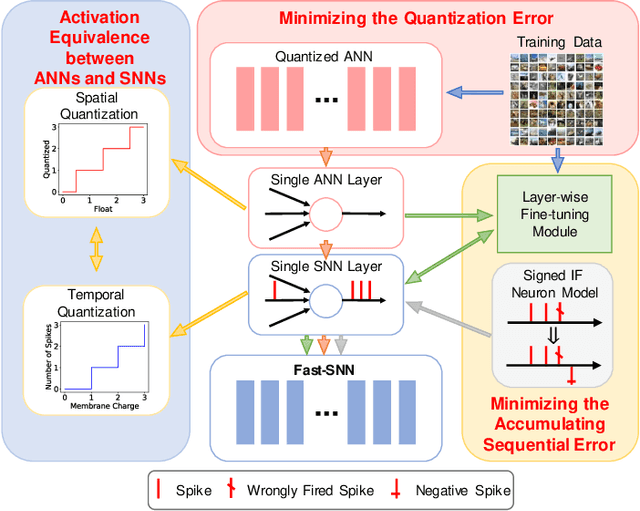
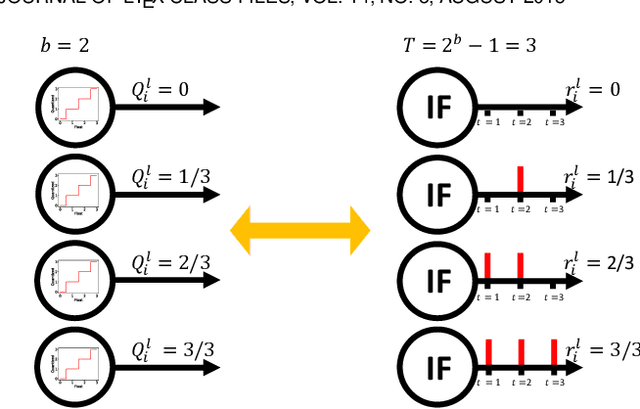
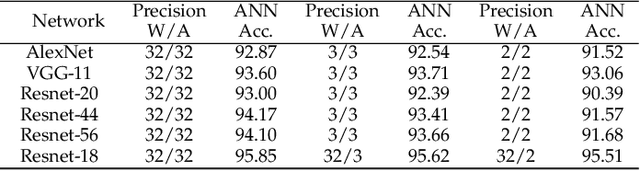
Spiking neural networks (SNNs) have shown advantages in computation and energy efficiency over traditional artificial neural networks (ANNs) thanks to their event-driven representations. SNNs also replace weight multiplications in ANNs with additions, which are more energy-efficient and less computationally intensive. However, it remains a challenge to train deep SNNs due to the discrete spike function. A popular approach to circumvent this challenge is ANN-to-SNN conversion. However, due to the quantization error and accumulating error, it often requires lots of time steps (high inference latency) to achieve high performance, which negates SNN's advantages. To this end, this paper proposes Fast-SNN that achieves high performance with low latency. We demonstrate the equivalent mapping between temporal quantization in SNNs and spatial quantization in ANNs, based on which the minimization of the quantization error is transferred to quantized ANN training. With the minimization of the quantization error, we show that the sequential error is the primary cause of the accumulating error, which is addressed by introducing a signed IF neuron model and a layer-wise fine-tuning mechanism. Our method achieves state-of-the-art performance and low latency on various computer vision tasks, including image classification, object detection, and semantic segmentation. Codes are available at: https://github.com/yangfan-hu/Fast-SNN.
Self-supervised Vision Transformers for 3D Pose Estimation of Novel Objects
May 31, 2023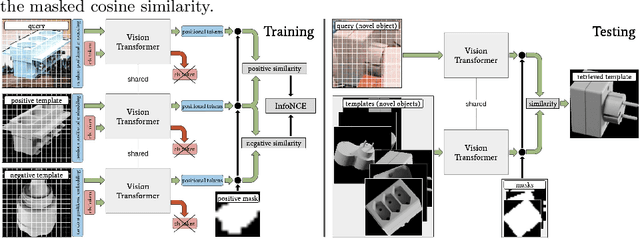
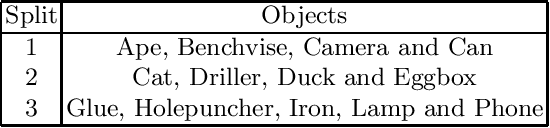
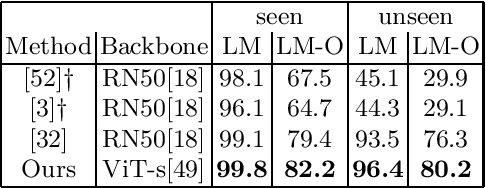
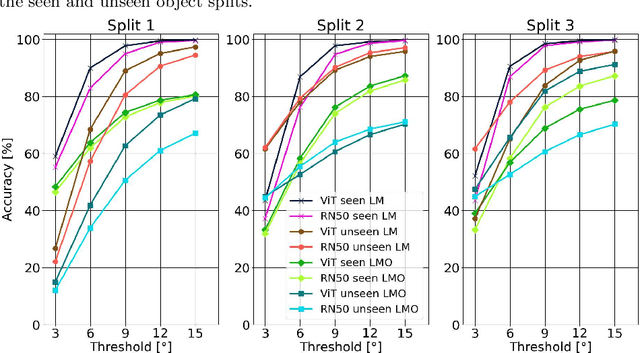
Object pose estimation is important for object manipulation and scene understanding. In order to improve the general applicability of pose estimators, recent research focuses on providing estimates for novel objects, that is objects unseen during training. Such works use deep template matching strategies to retrieve the closest template connected to a query image. This template retrieval implicitly provides object class and pose. Despite the recent success and improvements of Vision Transformers over CNNs for many vision tasks, the state of the art uses CNN-based approaches for novel object pose estimation. This work evaluates and demonstrates the differences between self-supervised CNNs and Vision Transformers for deep template matching. In detail, both types of approaches are trained using contrastive learning to match training images against rendered templates of isolated objects. At test time, such templates are matched against query images of known and novel objects under challenging settings, such as clutter, occlusion and object symmetries, using masked cosine similarity. The presented results not only demonstrate that Vision Transformers improve in matching accuracy over CNNs, but also that for some cases pre-trained Vision Transformers do not need fine-tuning to do so. Furthermore, we highlight the differences in optimization and network architecture when comparing these two types of network for deep template matching.
A Unified Framework for U-Net Design and Analysis
May 31, 2023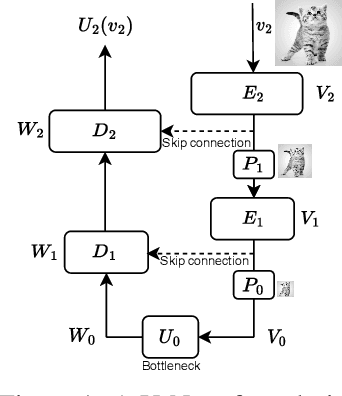
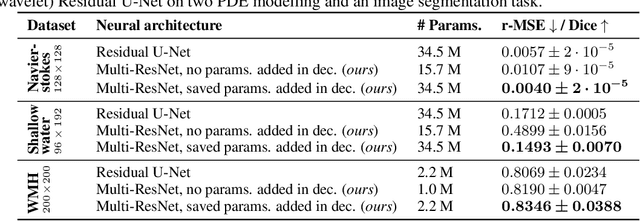
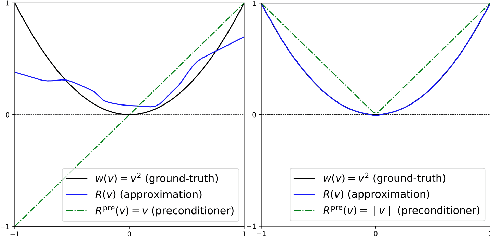

U-Nets are a go-to, state-of-the-art neural architecture across numerous tasks for continuous signals on a square such as images and Partial Differential Equations (PDE), however their design and architecture is understudied. In this paper, we provide a framework for designing and analysing general U-Net architectures. We present theoretical results which characterise the role of the encoder and decoder in a U-Net, their high-resolution scaling limits and their conjugacy to ResNets via preconditioning. We propose Multi-ResNets, U-Nets with a simplified, wavelet-based encoder without learnable parameters. Further, we show how to design novel U-Net architectures which encode function constraints, natural bases, or the geometry of the data. In diffusion models, our framework enables us to identify that high-frequency information is dominated by noise exponentially faster, and show how U-Nets with average pooling exploit this. In our experiments, we demonstrate how Multi-ResNets achieve competitive and often superior performance compared to classical U-Nets in image segmentation, PDE surrogate modelling, and generative modelling with diffusion models. Our U-Net framework paves the way to study the theoretical properties of U-Nets and design natural, scalable neural architectures for a multitude of problems beyond the square.
IconShop: Text-Based Vector Icon Synthesis with Autoregressive Transformers
Apr 27, 2023
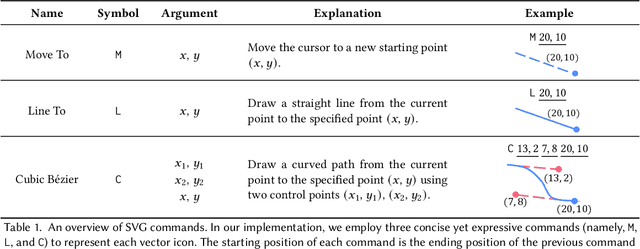
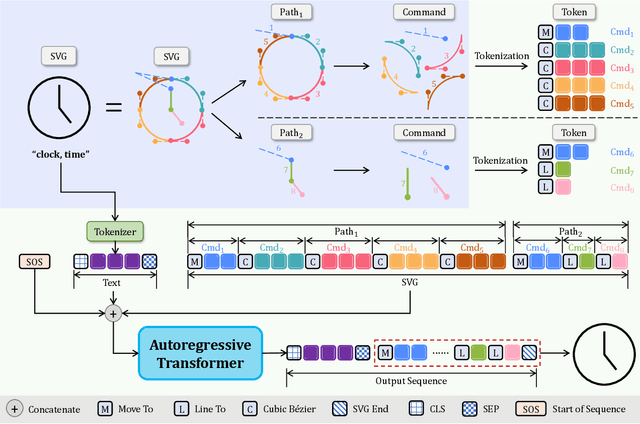
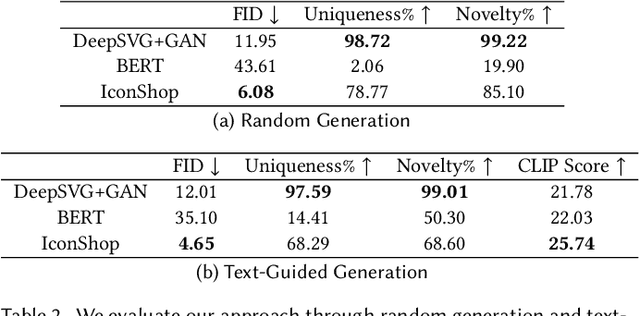
Scalable Vector Graphics (SVG) is a prevalent vector image format with good support for interactivity and animation. Despite such appealing characteristics, it is generally challenging for users to create their own SVG content because of the long learning curve to comprehend SVG grammars or acquaint themselves with professional editing software. Recent progress in text-to-image generation has inspired researchers to explore image-based icon synthesis (i.e., text -> raster image -> vector image) via differential rendering and language-based icon synthesis (i.e., text -> vector image script) via the "zero-shot" capabilities of large language models. However, these methods may suffer from several limitations regarding generation quality, diversity, flexibility, and speed. In this paper, we introduce IconShop, a text-guided vector icon synthesis method using an autoregressive transformer. The key to success of our approach is to sequentialize and tokenize the SVG paths (and textual descriptions) into a uniquely decodable command sequence. With such a single sequence as input, we are able to fully exploit the sequence learning power of autoregressive transformers, while enabling various icon synthesis and manipulation tasks. Through standard training to predict the next token on a large-scale icon dataset accompanied by textural descriptions, the proposed IconShop consistently exhibits better icon synthesis performance than existing image-based and language-based methods both quantitatively (using the FID and CLIP score) and qualitatively (through visual inspection). Meanwhile, we observe a dramatic improvement in generation diversity, which is supported by objective measures (Uniqueness and Novelty). More importantly, we demonstrate the flexibility of IconShop with two novel icon manipulation tasks - text-guided icon infilling, and text-combined icon synthesis.
NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion
Feb 20, 2023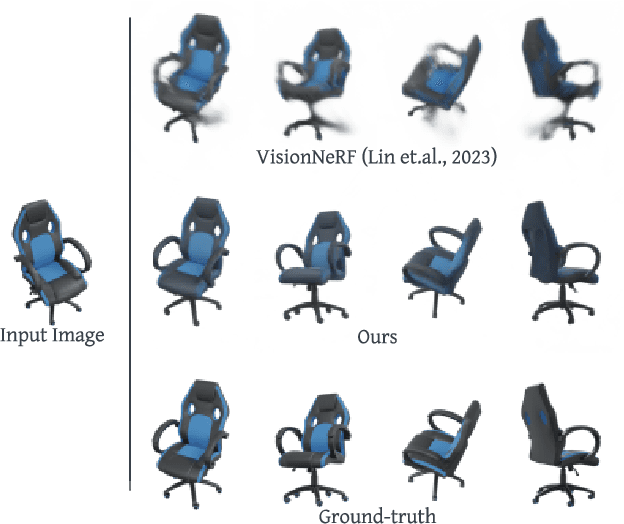
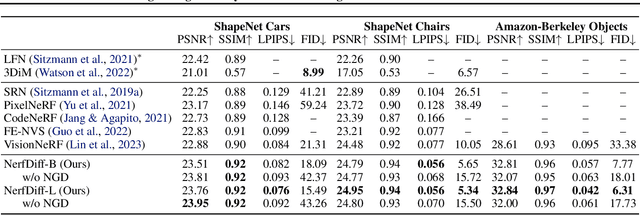
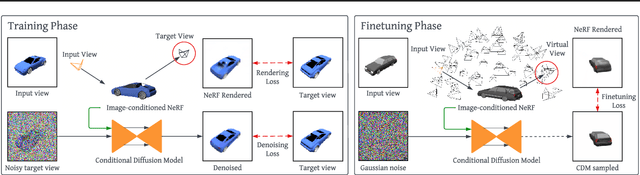
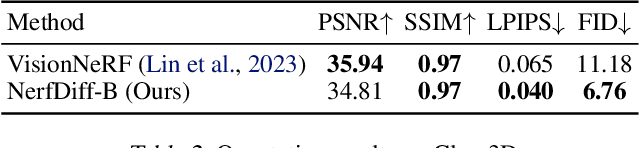
Novel view synthesis from a single image requires inferring occluded regions of objects and scenes whilst simultaneously maintaining semantic and physical consistency with the input. Existing approaches condition neural radiance fields (NeRF) on local image features, projecting points to the input image plane, and aggregating 2D features to perform volume rendering. However, under severe occlusion, this projection fails to resolve uncertainty, resulting in blurry renderings that lack details. In this work, we propose NerfDiff, which addresses this issue by distilling the knowledge of a 3D-aware conditional diffusion model (CDM) into NeRF through synthesizing and refining a set of virtual views at test time. We further propose a novel NeRF-guided distillation algorithm that simultaneously generates 3D consistent virtual views from the CDM samples, and finetunes the NeRF based on the improved virtual views. Our approach significantly outperforms existing NeRF-based and geometry-free approaches on challenging datasets, including ShapeNet, ABO, and Clevr3D.
Applications of Machine Learning in Detecting Afghan Fake Banknotes
May 24, 2023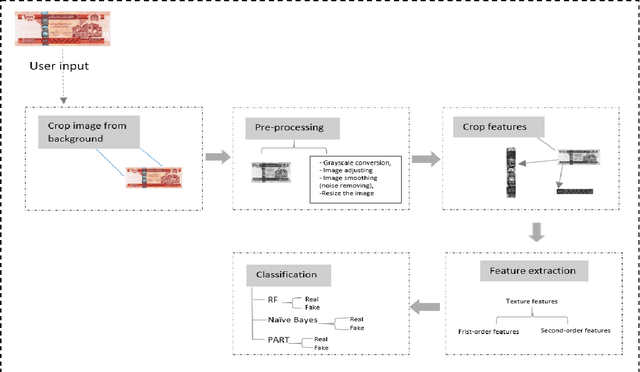


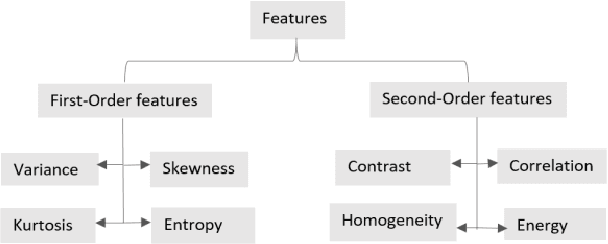
Fake currency, unauthorized imitation money lacking government approval, constitutes a form of fraud. Particularly in Afghanistan, the prevalence of fake currency poses significant challenges and detrimentally impacts the economy. While banks and commercial establishments employ authentication machines, the public lacks access to such systems, necessitating a program that can detect counterfeit banknotes accessible to all. This paper introduces a method using image processing to identify counterfeit Afghan banknotes by analyzing specific security features. Extracting first and second order statistical features from input images, the WEKA machine learning tool was employed to construct models and perform classification with Random Forest, PART, and Na\"ive Bayes algorithms. The Random Forest algorithm achieved exceptional accuracy of 99% in detecting fake Afghan banknotes, indicating the efficacy of the proposed method as a solution for identifying counterfeit currency.
Coil Sketching for computationally-efficient MR iterative reconstruction
May 10, 2023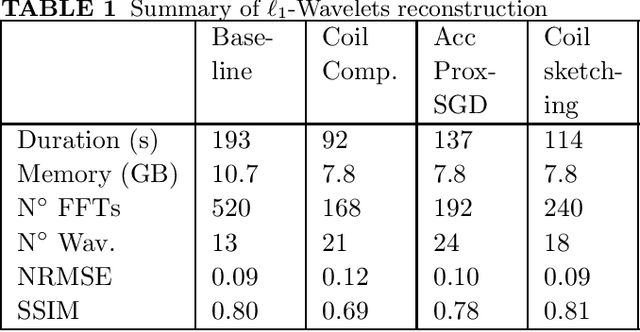
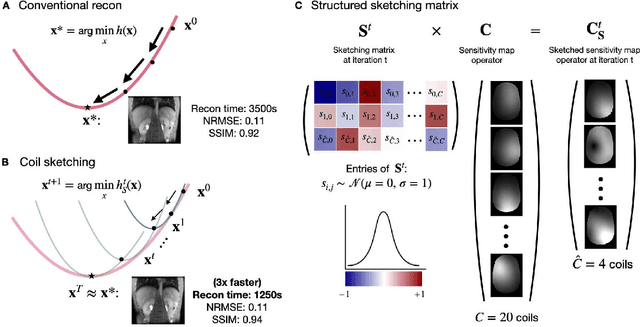
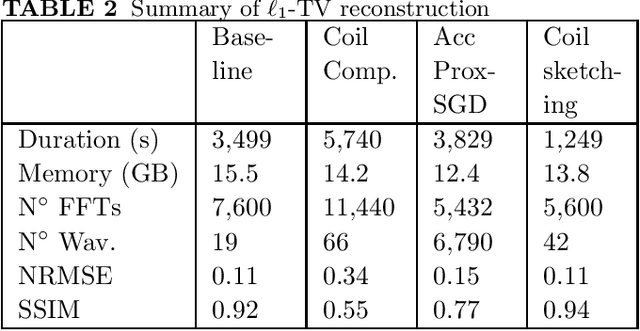
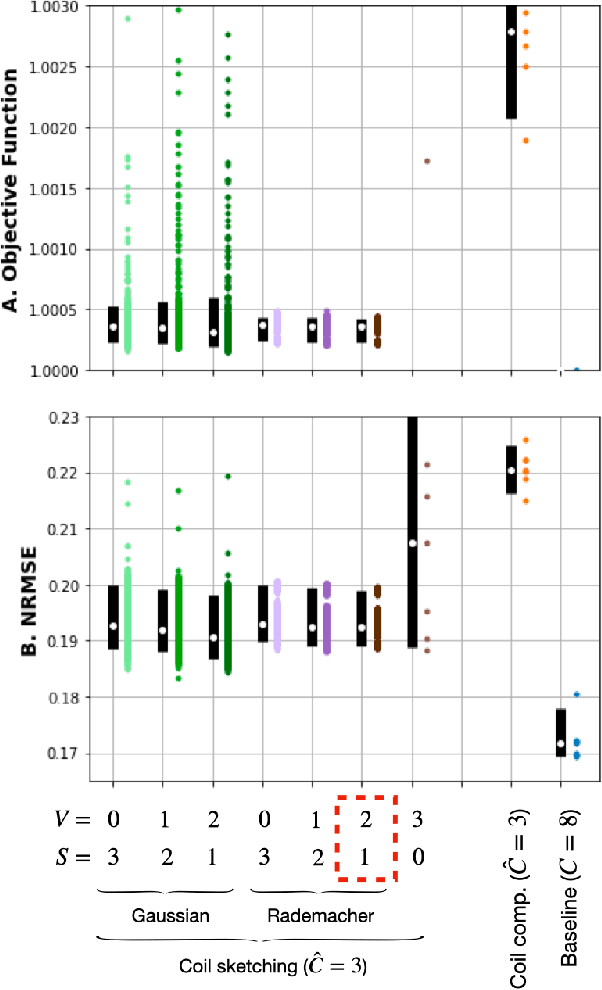
Purpose: Parallel imaging and compressed sensing reconstructions of large MRI datasets often have a prohibitive computational cost that bottlenecks clinical deployment, especially for 3D non-Cartesian acquisitions. One common approach is to reduce the number of coil channels actively used during reconstruction as in coil compression. While effective for Cartesian imaging, coil compression inherently loses signal energy, producing shading artifacts that compromise image quality for 3D non-Cartesian imaging. We propose coil sketching, a general and versatile method for computationally-efficient iterative MR image reconstruction. Theory and Methods: We based our method on randomized sketching algorithms, a type of large-scale optimization algorithms well established in the fields of machine learning and big data analysis. We adapt the sketching theory to the MRI reconstruction problem via a structured sketching matrix that, similar to coil compression, reduces the number of coils concurrently used during reconstruction, but unlike coil compression, is able to leverage energy from all coils. Results: First, we performed ablation experiments to validate the sketching matrix design on both Cartesian and non-Cartesian datasets. The resulting design yielded both improved computational efficiency and preserved signal-to-noise ratio (SNR) as measured by the inverse g-factor. Then, we verified the efficacy of our approach on high-dimensional non-Cartesian 3D cones datasets, where coil sketching yielded up to three-fold faster reconstructions with equivalent image quality. Conclusion: Coil sketching is a general and versatile reconstruction framework for computationally fast and memory-efficient reconstruction.