 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Computational 3D topographic microscopy from terabytes of data per sample
Jun 05, 2023
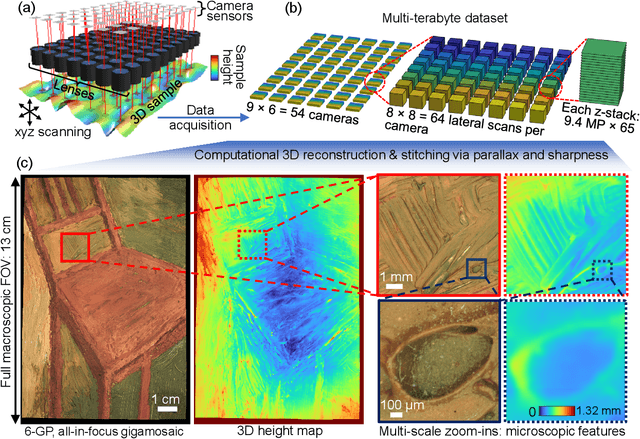

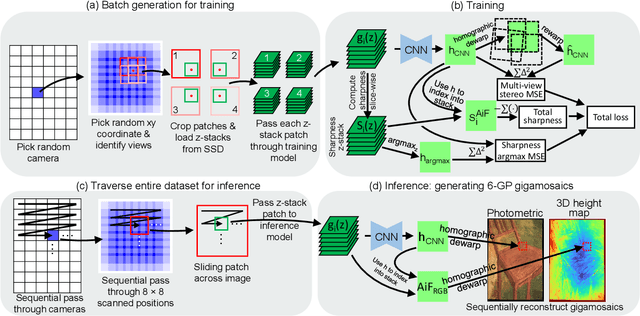
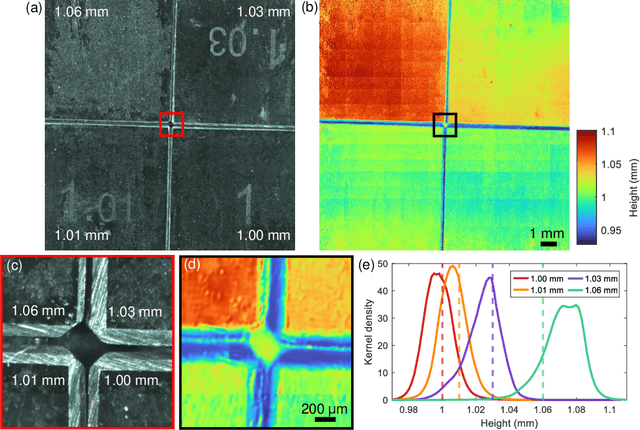
We present a large-scale computational 3D topographic microscope that enables 6-gigapixel profilometric 3D imaging at micron-scale resolution across $>$110 cm$^2$ areas over multi-millimeter axial ranges. Our computational microscope, termed STARCAM (Scanning Topographic All-in-focus Reconstruction with a Computational Array Microscope), features a parallelized, 54-camera architecture with 3-axis translation to capture, for each sample of interest, a multi-dimensional, 2.1-terabyte (TB) dataset, consisting of a total of 224,640 9.4-megapixel images. We developed a self-supervised neural network-based algorithm for 3D reconstruction and stitching that jointly estimates an all-in-focus photometric composite and 3D height map across the entire field of view, using multi-view stereo information and image sharpness as a focal metric. The memory-efficient, compressed differentiable representation offered by the neural network effectively enables joint participation of the entire multi-TB dataset during the reconstruction process. To demonstrate the broad utility of our new computational microscope, we applied STARCAM to a variety of decimeter-scale objects, with applications ranging from cultural heritage to industrial inspection.
A quality assurance framework for real-time monitoring of deep learning segmentation models in radiotherapy
May 19, 2023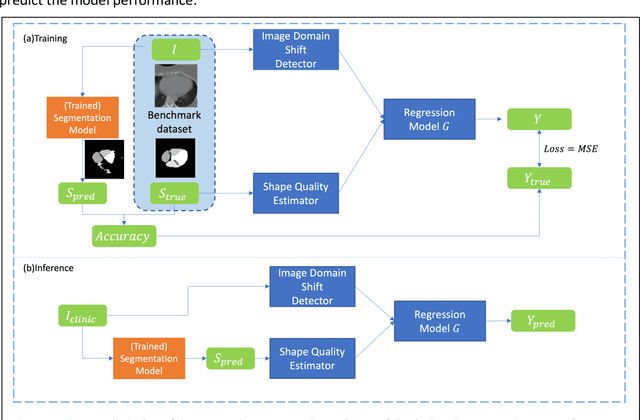

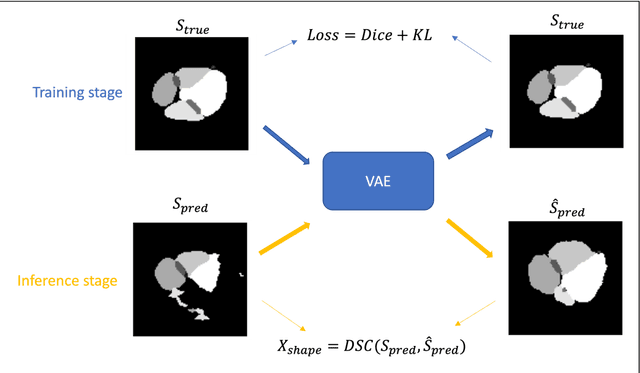
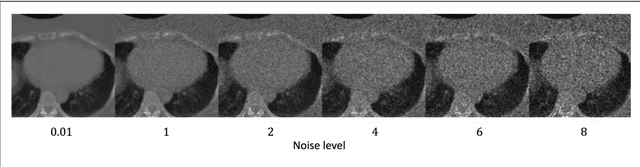
To safely deploy deep learning models in the clinic, a quality assurance framework is needed for routine or continuous monitoring of input-domain shift and the models' performance without ground truth contours. In this work, cardiac substructure segmentation was used as an example task to establish a QA framework. A benchmark dataset consisting of Computed Tomography (CT) images along with manual cardiac delineations of 241 patients were collected, including one 'common' image domain and five 'uncommon' domains. Segmentation models were tested on the benchmark dataset for an initial evaluation of model capacity and limitations. An image domain shift detector was developed by utilizing a trained Denoising autoencoder (DAE) and two hand-engineered features. Another Variational Autoencoder (VAE) was also trained to estimate the shape quality of the auto-segmentation results. Using the extracted features from the image/segmentation pair as inputs, a regression model was trained to predict the per-patient segmentation accuracy, measured by Dice coefficient similarity (DSC). The framework was tested across 19 segmentation models to evaluate the generalizability of the entire framework. As results, the predicted DSC of regression models achieved a mean absolute error (MAE) ranging from 0.036 to 0.046 with an averaged MAE of 0.041. When tested on the benchmark dataset, the performances of all segmentation models were not significantly affected by scanning parameters: FOV, slice thickness and reconstructions kernels. For input images with Poisson noise, CNN-based segmentation models demonstrated a decreased DSC ranging from 0.07 to 0.41, while the transformer-based model was not significantly affected.
JOINEDTrans: Prior Guided Multi-task Transformer for Joint Optic Disc/Cup Segmentation and Fovea Detection
May 19, 2023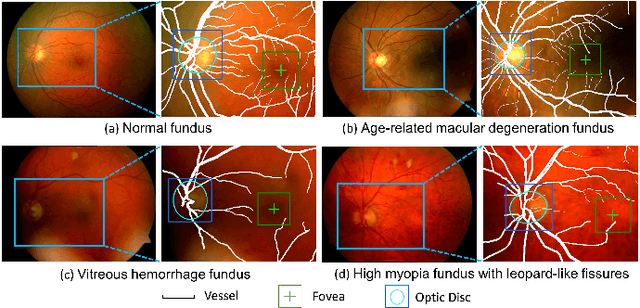
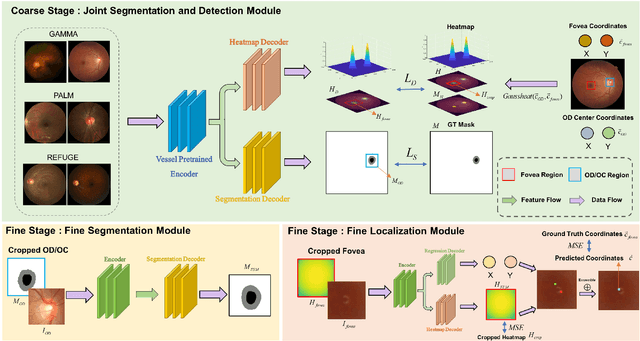
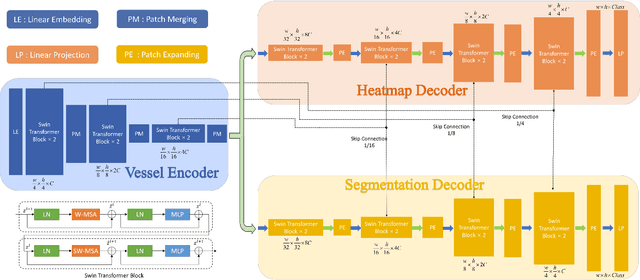
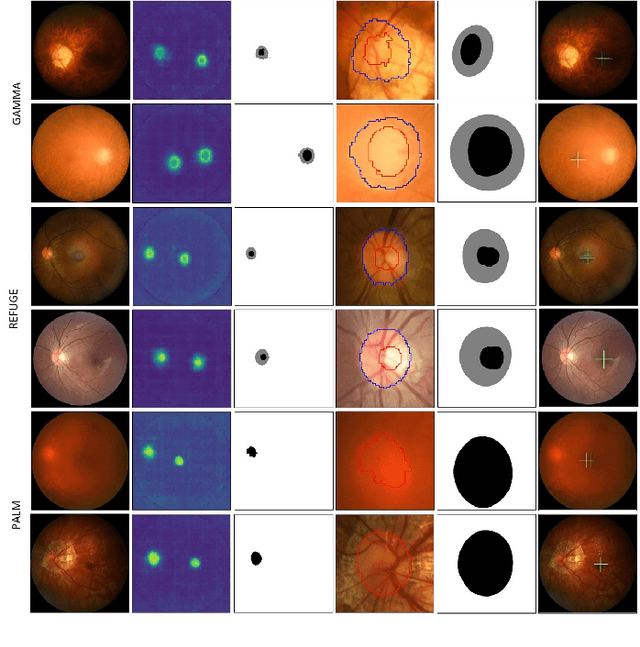
Deep learning-based image segmentation and detection models have largely improved the efficiency of analyzing retinal landmarks such as optic disc (OD), optic cup (OC), and fovea. However, factors including ophthalmic disease-related lesions and low image quality issues may severely complicate automatic OD/OC segmentation and fovea detection. Most existing works treat the identification of each landmark as a single task, and take into account no prior information. To address these issues, we propose a prior guided multi-task transformer framework for joint OD/OC segmentation and fovea detection, named JOINEDTrans. JOINEDTrans effectively combines various spatial features of the fundus images, relieving the structural distortions induced by lesions and other imaging issues. It contains a segmentation branch and a detection branch. To be noted, we employ an encoder pretrained in a vessel segmentation task to effectively exploit the positional relationship among vessel, OD/OC, and fovea, successfully incorporating spatial prior into the proposed JOINEDTrans framework. There are a coarse stage and a fine stage in JOINEDTrans. In the coarse stage, OD/OC coarse segmentation and fovea heatmap localization are obtained through a joint segmentation and detection module. In the fine stage, we crop regions of interest for subsequent refinement and use predictions obtained in the coarse stage to provide additional information for better performance and faster convergence. Experimental results demonstrate that JOINEDTrans outperforms existing state-of-the-art methods on the publicly available GAMMA, REFUGE, and PALM fundus image datasets. We make our code available at https://github.com/HuaqingHe/JOINEDTrans
Towards Few-shot Entity Recognition in Document Images: A Graph Neural Network Approach Robust to Image Manipulation
May 24, 2023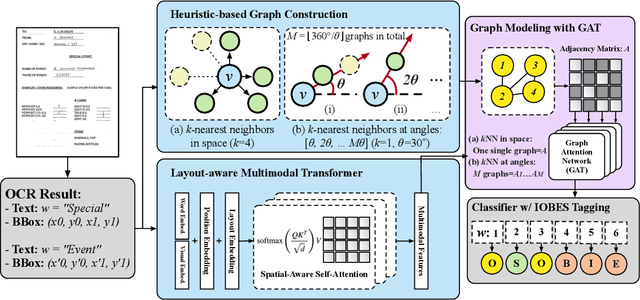

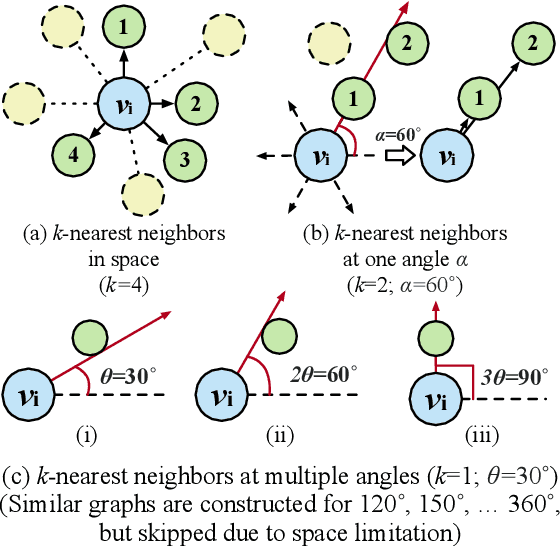
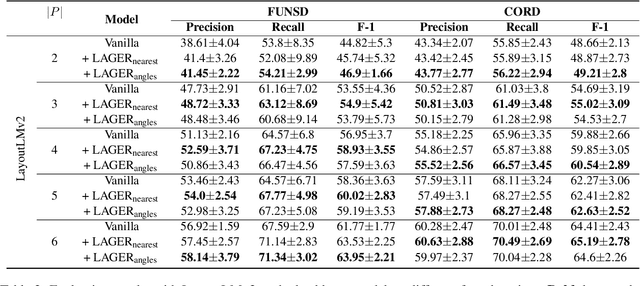
Recent advances of incorporating layout information, typically bounding box coordinates, into pre-trained language models have achieved significant performance in entity recognition from document images. Using coordinates can easily model the absolute position of each token, but they might be sensitive to manipulations in document images (e.g., shifting, rotation or scaling), especially when the training data is limited in few-shot settings. In this paper, we propose to further introduce the topological adjacency relationship among the tokens, emphasizing their relative position information. Specifically, we consider the tokens in the documents as nodes and formulate the edges based on the topological heuristics from the k-nearest bounding boxes. Such adjacency graphs are invariant to affine transformations including shifting, rotations and scaling. We incorporate these graphs into the pre-trained language model by adding graph neural network layers on top of the language model embeddings, leading to a novel model LAGER. Extensive experiments on two benchmark datasets show that LAGER significantly outperforms strong baselines under different few-shot settings and also demonstrate better robustness to manipulations.
Patch Network for medical image Segmentation
Feb 23, 2023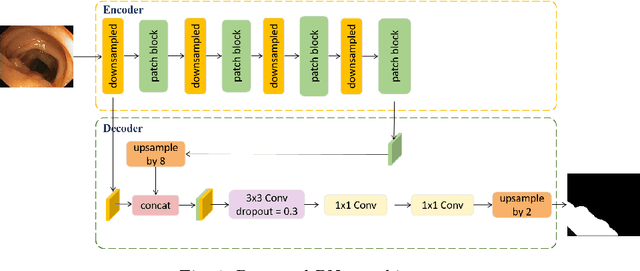
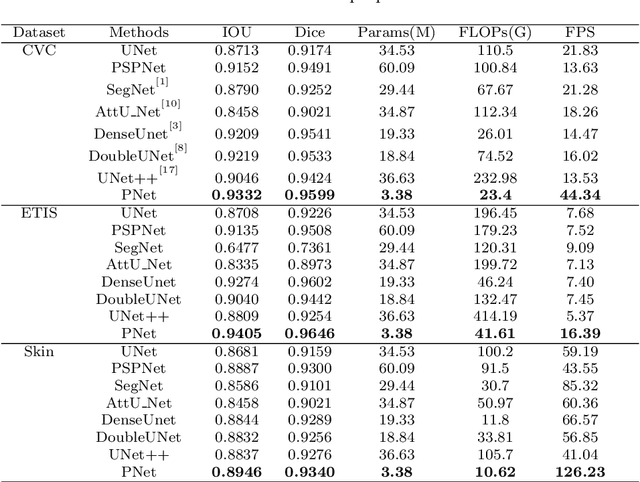
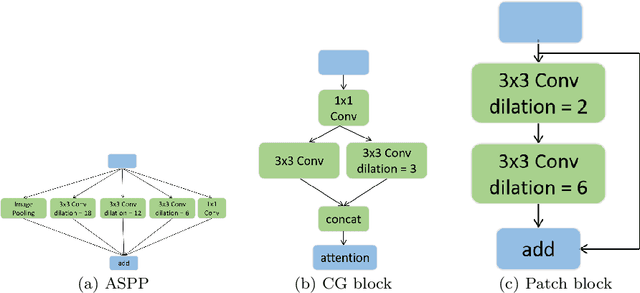

Accurate and fast segmentation of medical images is clinically essential, yet current research methods include convolutional neural networks with fast inference speed but difficulty in learning image contextual features, and transformer with good performance but high hardware requirements. In this paper, we present a Patch Network (PNet) that incorporates the Swin Transformer notion into a convolutional neural network, allowing it to gather richer contextual information while achieving the balance of speed and accuracy. We test our PNet on Polyp(CVC-ClinicDB and ETIS- LaribPolypDB), Skin(ISIC-2018 Skin lesion segmentation challenge dataset) segmentation datasets. Our PNet achieves SOTA performance in both speed and accuracy.
Adaptive Supervised PatchNCE Loss for Learning H&E-to-IHC Stain Translation with Inconsistent Groundtruth Image Pairs
Mar 10, 2023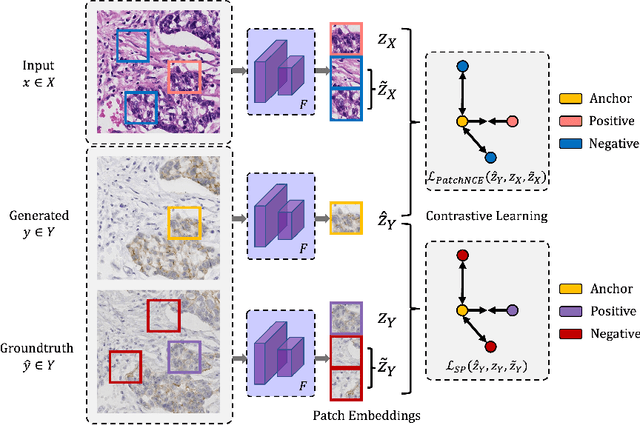
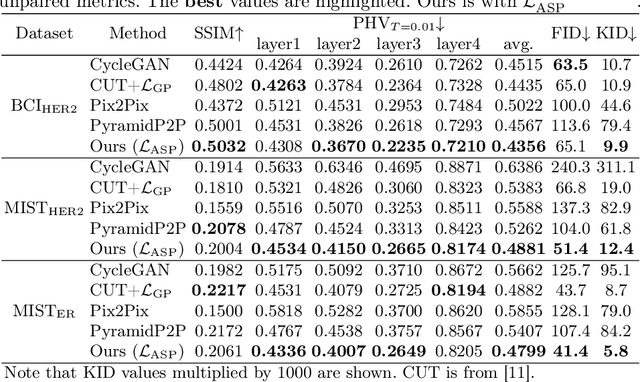
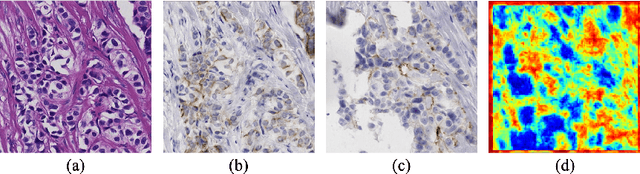
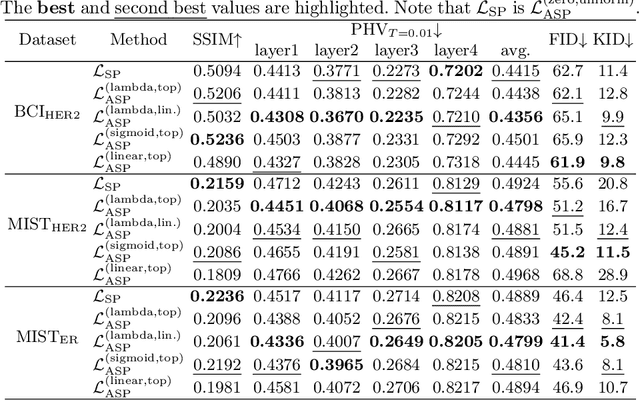
Immunohistochemical (IHC) staining highlights the molecular information critical to diagnostics in tissue samples. However, compared to H&E staining, IHC staining can be much more expensive in terms of both labor and the laboratory equipment required. This motivates recent research that demonstrates that the correlations between the morphological information present in the H&E-stained slides and the molecular information in the IHC-stained slides can be used for H&E-to-IHC stain translation. However, due to a lack of pixel-perfect H&E-IHC groundtruth pairs, most existing methods have resorted to relying on expert annotations. To remedy this situation, we present a new loss function, Adaptive Supervised PatchNCE (ASP), to directly deal with the input to target inconsistencies in a proposed H&E-to-IHC image-to-image translation framework. The ASP loss is built upon a patch-based contrastive learning criterion, named Supervised PatchNCE (SP), and augments it further with weight scheduling to mitigate the negative impact of noisy supervision. Lastly, we introduce the Multi-IHC Stain Translation (MIST) dataset, which contains aligned H&E-IHC patches for 4 different IHC stains critical to breast cancer diagnosis. In our experiment, we demonstrate that our proposed method outperforms existing image-to-image translation methods for stain translation to multiple IHC stains. All of our code and datasets are available at https://github.com/lifangda01/AdaptiveSupervisedPatchNCE.
Fine-grained Cross-modal Fusion based Refinement for Text-to-Image Synthesis
Feb 17, 2023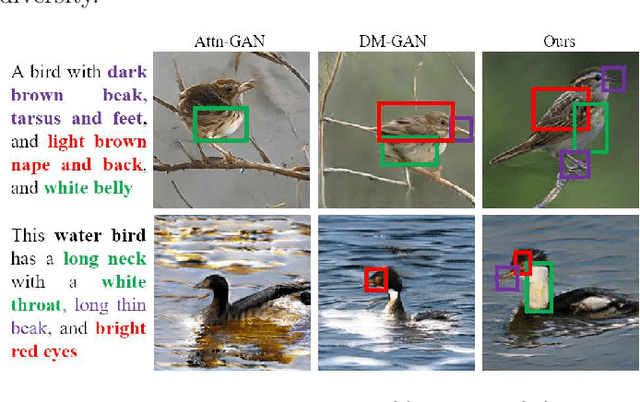
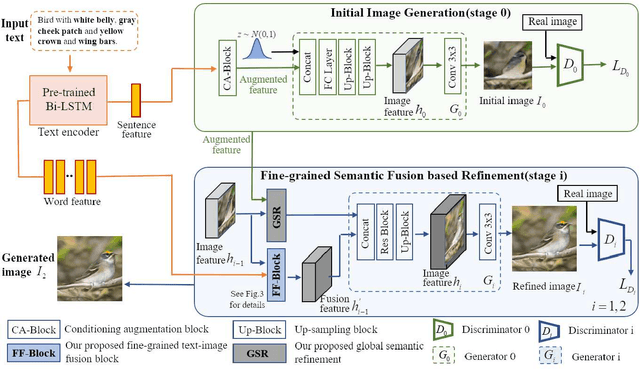
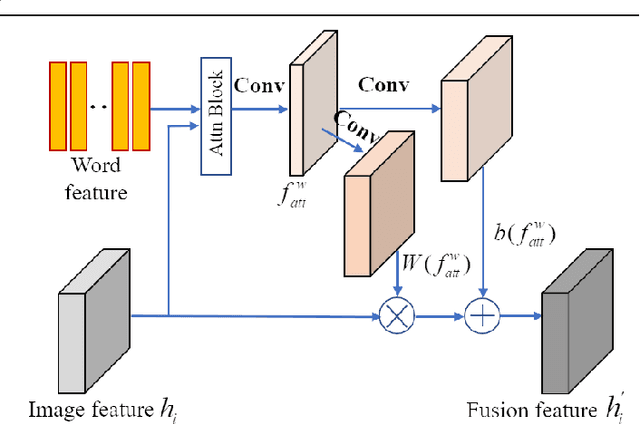

Text-to-image synthesis refers to generating visual-realistic and semantically consistent images from given textual descriptions. Previous approaches generate an initial low-resolution image and then refine it to be high-resolution. Despite the remarkable progress, these methods are limited in fully utilizing the given texts and could generate text-mismatched images, especially when the text description is complex. We propose a novel Fine-grained text-image Fusion based Generative Adversarial Networks, dubbed FF-GAN, which consists of two modules: Fine-grained text-image Fusion Block (FF-Block) and Global Semantic Refinement (GSR). The proposed FF-Block integrates an attention block and several convolution layers to effectively fuse the fine-grained word-context features into the corresponding visual features, in which the text information is fully used to refine the initial image with more details. And the GSR is proposed to improve the global semantic consistency between linguistic and visual features during the refinement process. Extensive experiments on CUB-200 and COCO datasets demonstrate the superiority of FF-GAN over other state-of-the-art approaches in generating images with semantic consistency to the given texts.Code is available at https://github.com/haoranhfut/FF-GAN.
PanoContext-Former: Panoramic Total Scene Understanding with a Transformer
May 21, 2023
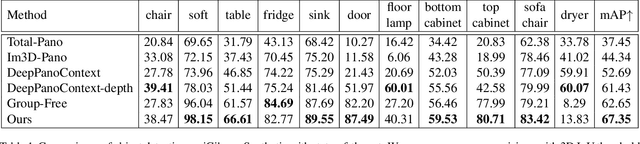
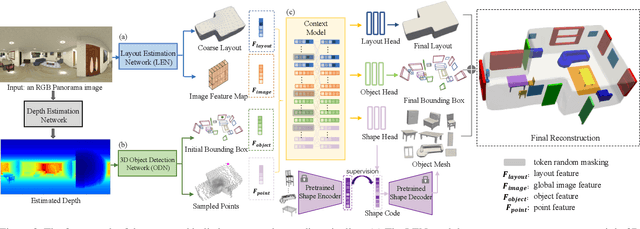

Panoramic image enables deeper understanding and more holistic perception of $360^\circ$ surrounding environment, which can naturally encode enriched scene context information compared to standard perspective image. Previous work has made lots of effort to solve the scene understanding task in a bottom-up form, thus each sub-task is processed separately and few correlations are explored in this procedure. In this paper, we propose a novel method using depth prior for holistic indoor scene understanding which recovers the objects' shapes, oriented bounding boxes and the 3D room layout simultaneously from a single panorama. In order to fully utilize the rich context information, we design a transformer-based context module to predict the representation and relationship among each component of the scene. In addition, we introduce a real-world dataset for scene understanding, including photo-realistic panoramas, high-fidelity depth images, accurately annotated room layouts, and oriented object bounding boxes and shapes. Experiments on the synthetic and real-world datasets demonstrate that our method outperforms previous panoramic scene understanding methods in terms of both layout estimation and 3D object detection.
DreamPaint: Few-Shot Inpainting of E-Commerce Items for Virtual Try-On without 3D Modeling
May 02, 2023

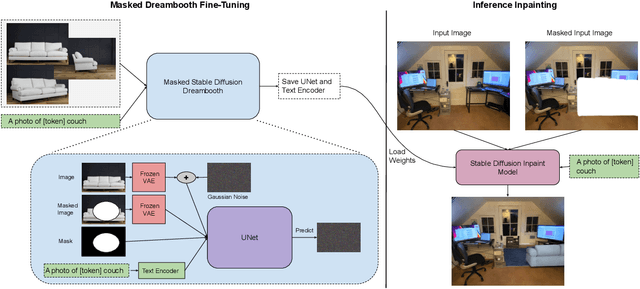

We introduce DreamPaint, a framework to intelligently inpaint any e-commerce product on any user-provided context image. The context image can be, for example, the user's own image for virtual try-on of clothes from the e-commerce catalog on themselves, the user's room image for virtual try-on of a piece of furniture from the e-commerce catalog in their room, etc. As opposed to previous augmented-reality (AR)-based virtual try-on methods, DreamPaint does not use, nor does it require, 3D modeling of neither the e-commerce product nor the user context. Instead, it directly uses 2D images of the product as available in product catalog database, and a 2D picture of the context, for example taken from the user's phone camera. The method relies on few-shot fine tuning a pre-trained diffusion model with the masked latents (e.g., Masked DreamBooth) of the catalog images per item, whose weights are then loaded on a pre-trained inpainting module that is capable of preserving the characteristics of the context image. DreamPaint allows to preserve both the product image and the context (environment/user) image without requiring text guidance to describe the missing part (product/context). DreamPaint also allows to intelligently infer the best 3D angle of the product to place at the desired location on the user context, even if that angle was previously unseen in the product's reference 2D images. We compare our results against both text-guided and image-guided inpainting modules and show that DreamPaint yields superior performance in both subjective human study and quantitative metrics.
Ray-Patch: An Efficient Decoder for Light Field Transformers
May 16, 2023In this paper we propose the Ray-Patch decoder, a novel model to efficiently query transformers to decode implicit representations into target views. Our Ray-Patch decoding reduces the computational footprint up to two orders of magnitude compared to previous models, without losing global attention, and hence maintaining specific task metrics. The key idea of our novel decoder is to split the target image into a set of patches, then querying the transformer for each patch to extract a set of feature vectors, which are finally decoded into the target image using convolutional layers. Our experimental results quantify the effectiveness of our method, specifically the notable boost in rendering speed and equal specific task metrics for different baselines and datasets.