 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Is a Video worth $n\times n$ Images? A Highly Efficient Approach to Transformer-based Video Question Answering
May 16, 2023
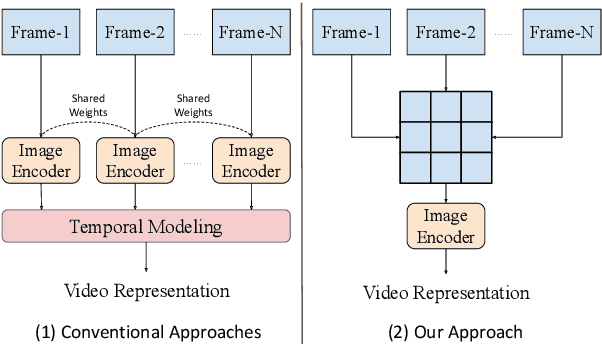
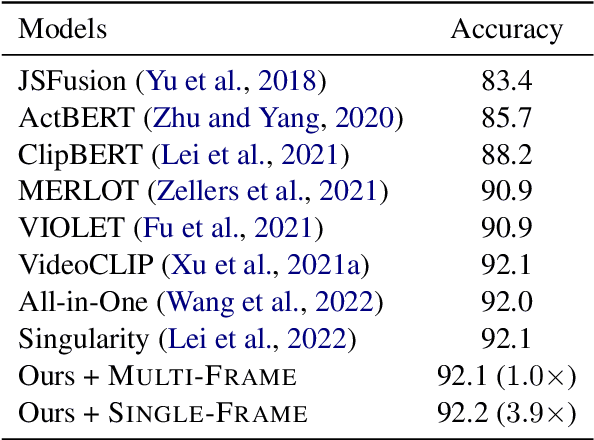
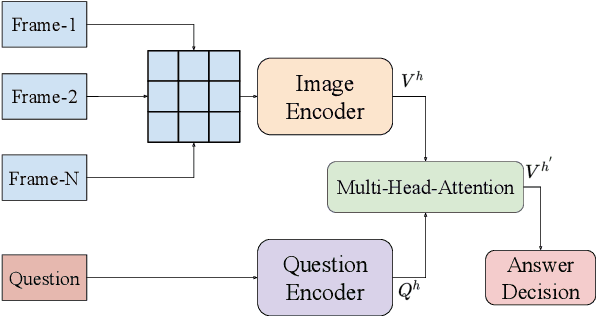
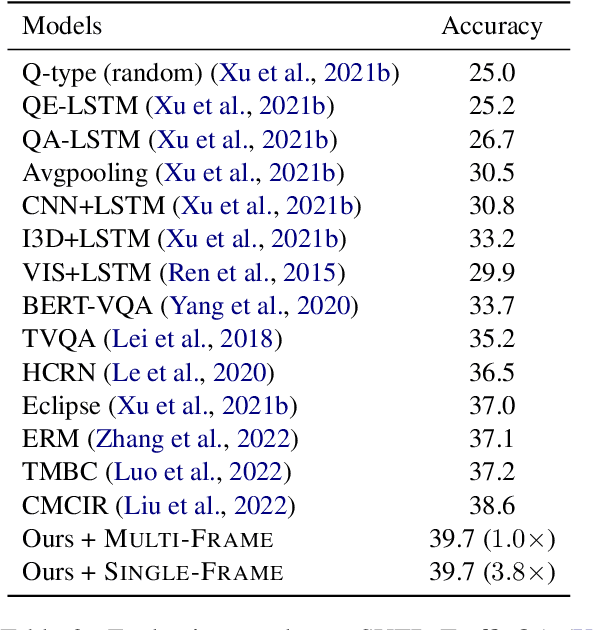
Conventional Transformer-based Video Question Answering (VideoQA) approaches generally encode frames independently through one or more image encoders followed by interaction between frames and question. However, such schema would incur significant memory use and inevitably slow down the training and inference speed. In this work, we present a highly efficient approach for VideoQA based on existing vision-language pre-trained models where we concatenate video frames to a $n\times n$ matrix and then convert it to one image. By doing so, we reduce the use of the image encoder from $n^{2}$ to $1$ while maintaining the temporal structure of the original video. Experimental results on MSRVTT and TrafficQA show that our proposed approach achieves state-of-the-art performance with nearly $4\times$ faster speed and only 30% memory use. We show that by integrating our approach into VideoQA systems we can achieve comparable, even superior, performance with a significant speed up for training and inference. We believe the proposed approach can facilitate VideoQA-related research by reducing the computational requirements for those who have limited access to budgets and resources. Our code will be made publicly available for research use.
Semantic Segmentation by Semantic Proportions
May 24, 2023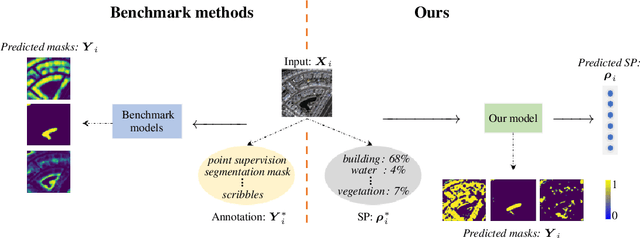
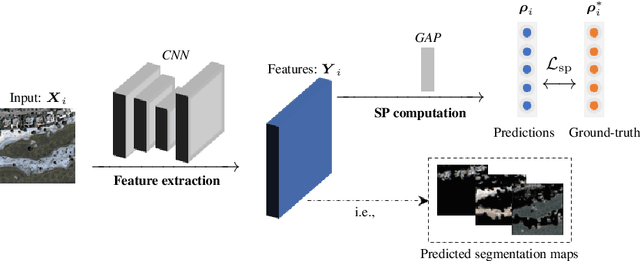
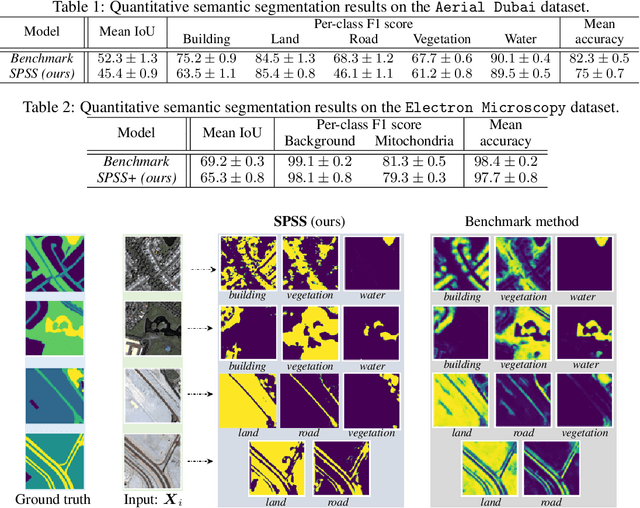
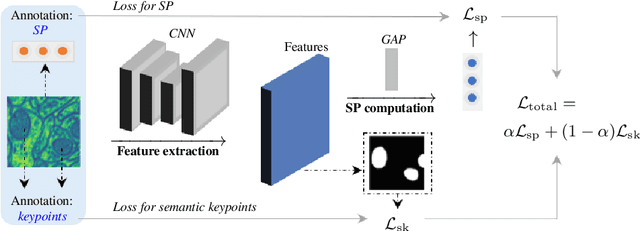
Semantic segmentation is a critical task in computer vision that aims to identify and classify individual pixels in an image, with numerous applications for example autonomous driving and medical image analysis. However, semantic segmentation can be super challenging particularly due to the need for large amounts of annotated data. Annotating images is a time-consuming and costly process, often requiring expert knowledge and significant effort. In this paper, we propose a novel approach for semantic segmentation by eliminating the need of ground-truth segmentation maps. Instead, our approach requires only the rough information of individual semantic class proportions, shortened as semantic proportions. It greatly simplifies the data annotation process and thus will significantly reduce the annotation time and cost, making it more feasible for large-scale applications. Moreover, it opens up new possibilities for semantic segmentation tasks where obtaining the full ground-truth segmentation maps may not be feasible or practical. Extensive experimental results demonstrate that our approach can achieve comparable and sometimes even better performance against the benchmark method that relies on the ground-truth segmentation maps. Utilising semantic proportions suggested in this work offers a promising direction for future research in the field of semantic segmentation.
Reinforcement Learning finetuned Vision-Code Transformer for UI-to-Code Generation
May 24, 2023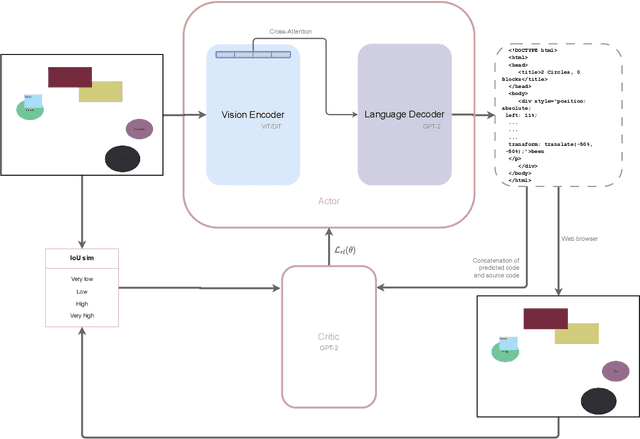
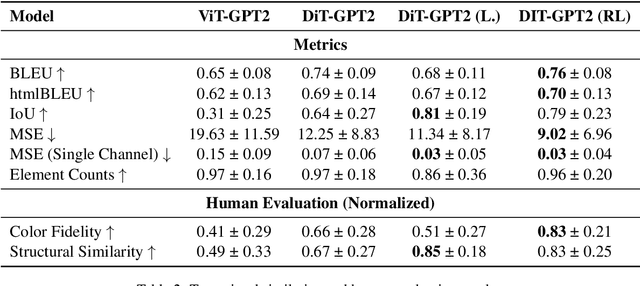
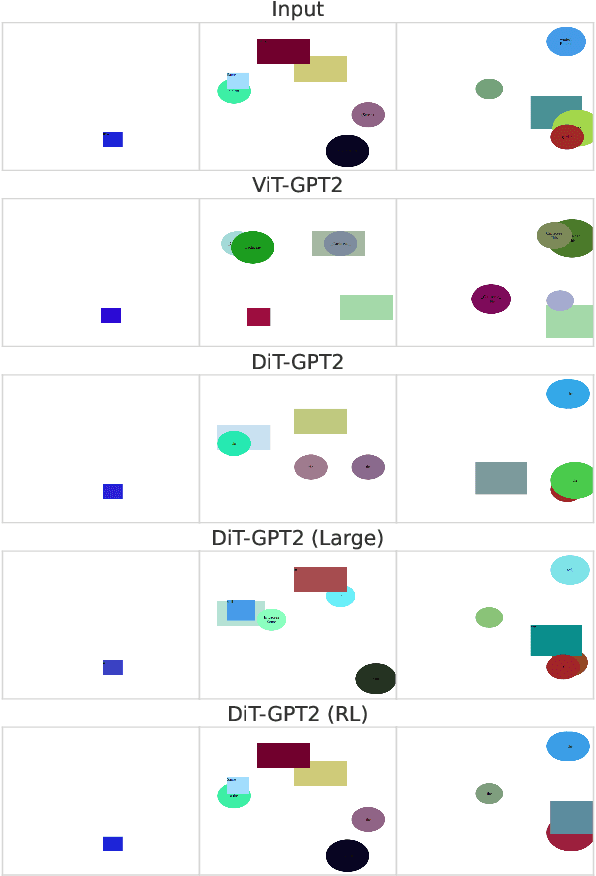
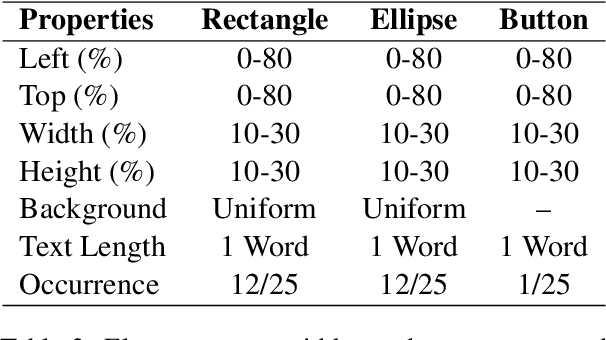
Automated HTML/CSS code generation from screenshots is an important yet challenging problem with broad applications in website development and design. In this paper, we present a novel vision-code transformer approach that leverages an Encoder-Decoder architecture as well as explore actor-critic fine-tuning as a method for improving upon the baseline. For this purpose, two image encoders are compared: Vision Transformer (ViT) and Document Image Transformer (DiT). We propose an end-to-end pipeline that can generate high-quality code snippets directly from screenshots, streamlining the website creation process for developers. To train and evaluate our models, we created a synthetic dataset of 30,000 unique pairs of code and corresponding screenshots. We evaluate the performance of our approach using a combination of automated metrics such as MSE, BLEU, IoU, and a novel htmlBLEU score, where our models demonstrated strong performance. We establish a strong baseline with the DiT-GPT2 model and show that actor-critic can be used to improve IoU score from the baseline of 0.64 to 0.79 and lower MSE from 12.25 to 9.02. We achieved similar performance as when using larger models, with much lower computational cost.
Bi-parametric prostate MR image synthesis using pathology and sequence-conditioned stable diffusion
Mar 03, 2023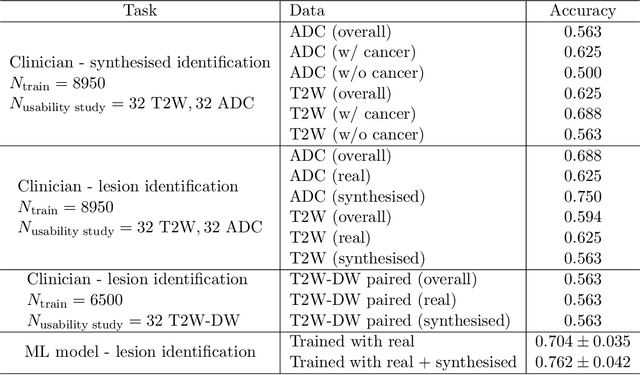

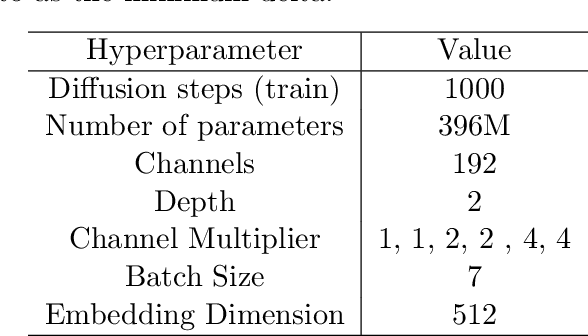
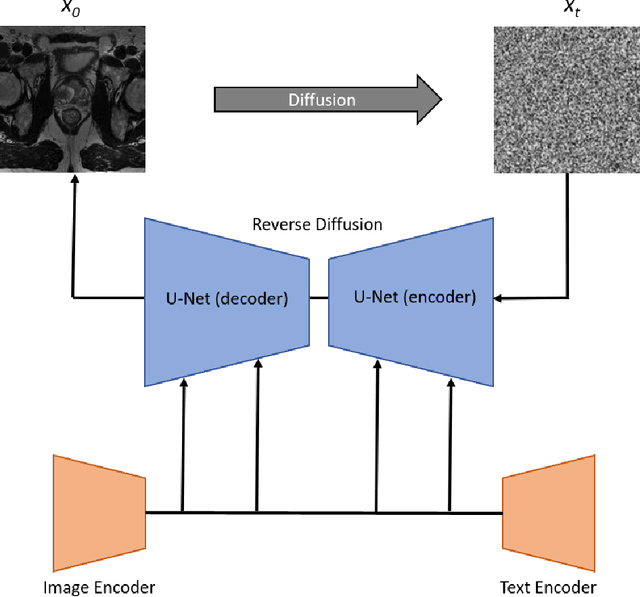
We propose an image synthesis mechanism for multi-sequence prostate MR images conditioned on text, to control lesion presence and sequence, as well as to generate paired bi-parametric images conditioned on images e.g. for generating diffusion-weighted MR from T2-weighted MR for paired data, which are two challenging tasks in pathological image synthesis. Our proposed mechanism utilises and builds upon the recent stable diffusion model by proposing image-based conditioning for paired data generation. We validate our method using 2D image slices from real suspected prostate cancer patients. The realism of the synthesised images is validated by means of a blind expert evaluation for identifying real versus fake images, where a radiologist with 4 years experience reading urological MR only achieves 59.4% accuracy across all tested sequences (where chance is 50%). For the first time, we evaluate the realism of the generated pathology by blind expert identification of the presence of suspected lesions, where we find that the clinician performs similarly for both real and synthesised images, with a 2.9 percentage point difference in lesion identification accuracy between real and synthesised images, demonstrating the potentials in radiological training purposes. Furthermore, we also show that a machine learning model, trained for lesion identification, shows better performance (76.2% vs 70.4%, statistically significant improvement) when trained with real data augmented by synthesised data as opposed to training with only real images, demonstrating usefulness for model training.
From Patches to Objects: Exploiting Spatial Reasoning for Better Visual Representations
May 21, 2023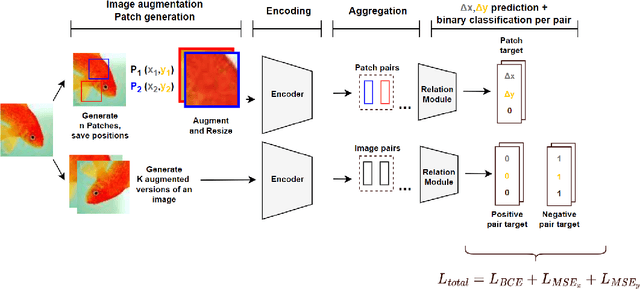

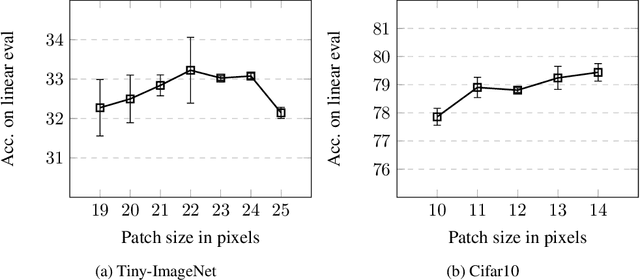
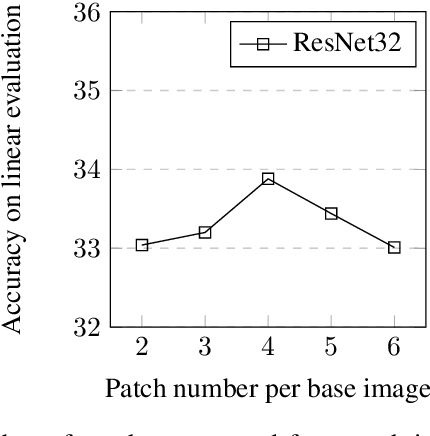
As the field of deep learning steadily transitions from the realm of academic research to practical application, the significance of self-supervised pretraining methods has become increasingly prominent. These methods, particularly in the image domain, offer a compelling strategy to effectively utilize the abundance of unlabeled image data, thereby enhancing downstream tasks' performance. In this paper, we propose a novel auxiliary pretraining method that is based on spatial reasoning. Our proposed method takes advantage of a more flexible formulation of contrastive learning by introducing spatial reasoning as an auxiliary task for discriminative self-supervised methods. Spatial Reasoning works by having the network predict the relative distances between sampled non-overlapping patches. We argue that this forces the network to learn more detailed and intricate internal representations of the objects and the relationships between their constituting parts. Our experiments demonstrate substantial improvement in downstream performance in linear evaluation compared to similar work and provide directions for further research into spatial reasoning.
Better "CMOS" Produces Clearer Images: Learning Space-Variant Blur Estimation for Blind Image Super-Resolution
Apr 07, 2023
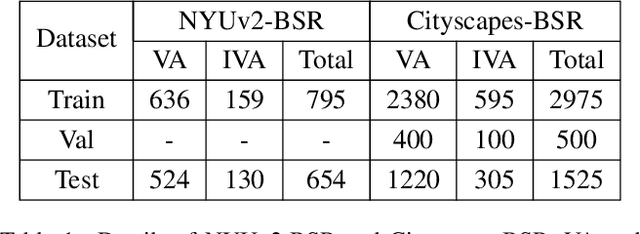

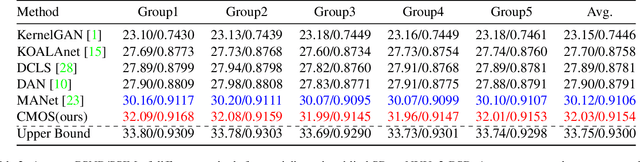
Most of the existing blind image Super-Resolution (SR) methods assume that the blur kernels are space-invariant. However, the blur involved in real applications are usually space-variant due to object motion, out-of-focus, etc., resulting in severe performance drop of the advanced SR methods. To address this problem, we firstly introduce two new datasets with out-of-focus blur, i.e., NYUv2-BSR and Cityscapes-BSR, to support further researches of blind SR with space-variant blur. Based on the datasets, we design a novel Cross-MOdal fuSion network (CMOS) that estimate both blur and semantics simultaneously, which leads to improved SR results. It involves a feature Grouping Interactive Attention (GIA) module to make the two modalities interact more effectively and avoid inconsistency. GIA can also be used for the interaction of other features because of the universality of its structure. Qualitative and quantitative experiments compared with state-of-the-art methods on above datasets and real-world images demonstrate the superiority of our method, e.g., obtaining PSNR/SSIM by +1.91/+0.0048 on NYUv2-BSR than MANet.
Multi-source adversarial transfer learning based on similar source domains with local features
May 30, 2023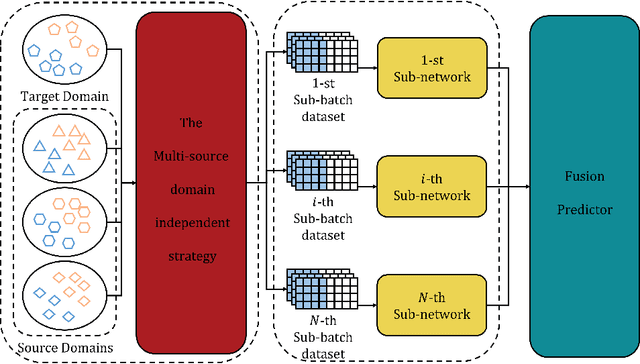

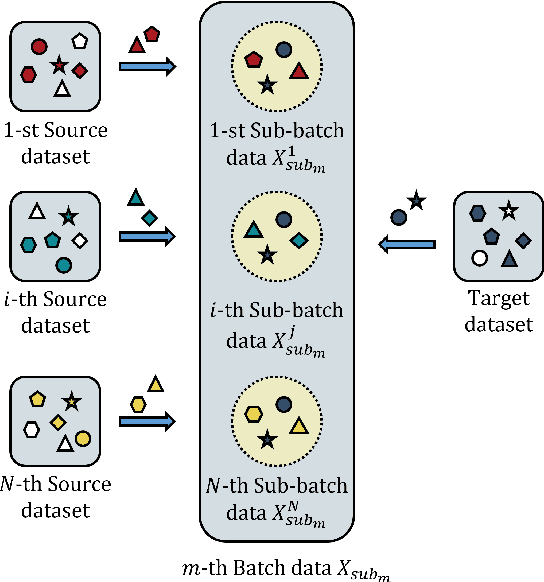
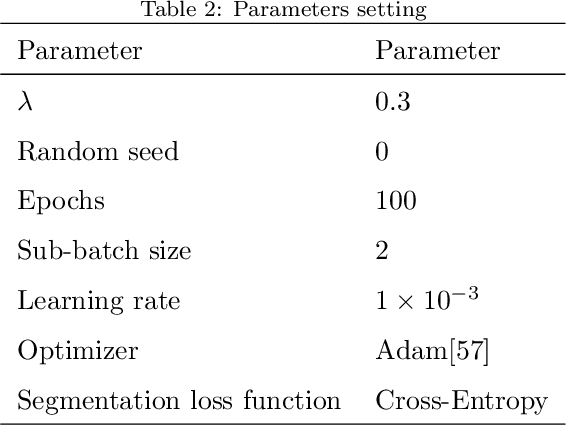
Transfer learning leverages knowledge from other domains and has been successful in many applications. Transfer learning methods rely on the overall similarity of the source and target domains. However, in some cases, it is impossible to provide an overall similar source domain, and only some source domains with similar local features can be provided. Can transfer learning be achieved? In this regard, we propose a multi-source adversarial transfer learning method based on local feature similarity to the source domain to handle transfer scenarios where the source and target domains have only local similarities. This method extracts transferable local features between a single source domain and the target domain through a sub-network. Specifically, the feature extractor of the sub-network is induced by the domain discriminator to learn transferable knowledge between the source domain and the target domain. The extracted features are then weighted by an attention module to suppress non-transferable local features while enhancing transferable local features. In order to ensure that the data from the target domain in different sub-networks in the same batch is exactly the same, we designed a multi-source domain independent strategy to provide the possibility for later local feature fusion to complete the key features required. In order to verify the effectiveness of the method, we made the dataset "Local Carvana Image Masking Dataset". Applying the proposed method to the image segmentation task of the proposed dataset achieves better transfer performance than other multi-source transfer learning methods. It is shown that the designed transfer learning method is feasible for transfer scenarios where the source and target domains have only local similarities.
Operational Neural Networks for Efficient Hyperspectral Single-Image Super-Resolution
Mar 29, 2023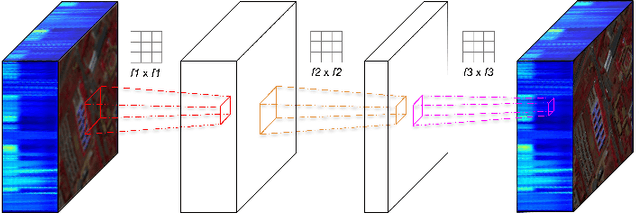
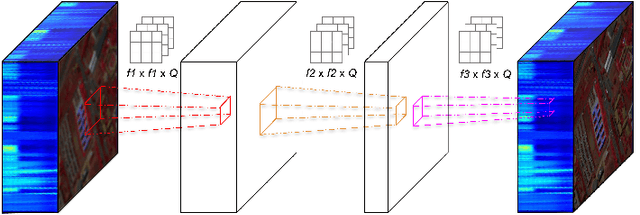
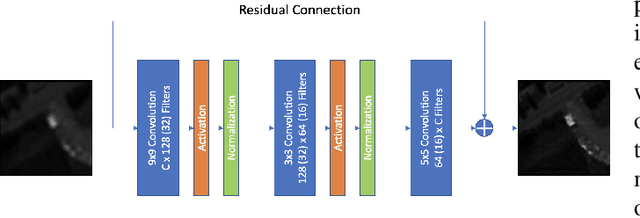

Hyperspectral Imaging is a crucial tool in remote sensing which captures far more spectral information than standard color images. However, the increase in spectral information comes at the cost of spatial resolution. Super-resolution is a popular technique where the goal is to generate a high-resolution version of a given low-resolution input. The majority of modern super-resolution approaches use convolutional neural networks. However, convolution itself is a linear operation and the networks rely on the non-linear activation functions after each layer to provide the necessary non-linearity to learn the complex underlying function. This means that convolutional neural networks tend to be very deep to achieve the desired results. Recently, self-organized operational neural networks have been proposed that aim to overcome this limitation by replacing the convolutional filters with learnable non-linear functions through the use of MacLaurin series expansions. This work focuses on extending the convolutional filters of a popular super-resolution model to more powerful operational filters to enhance the model performance on hyperspectral images. We also investigate the effects that residual connections and different normalization types have on this type of enhanced network. Despite having fewer parameters than their convolutional network equivalents, our results show that operational neural networks achieve superior super-resolution performance on small hyperspectral image datasets.
Freehand 2D Ultrasound Probe Calibration for Image Fusion with 3D MRI/CT
Mar 14, 2023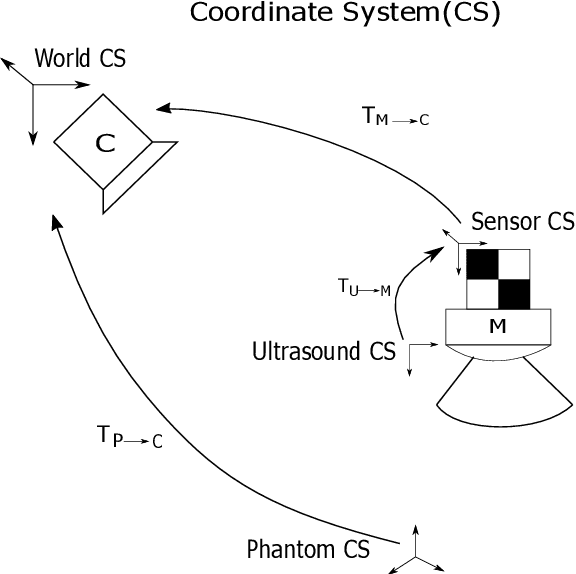
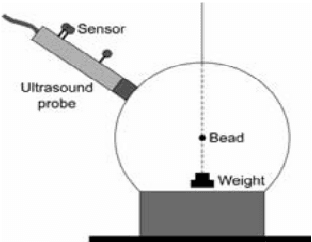
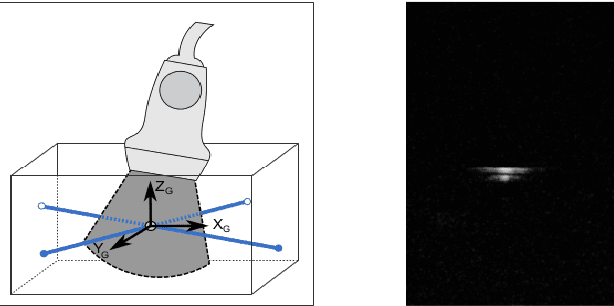
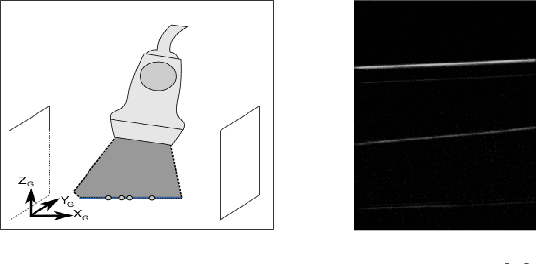
The aim of this work is to implement a simple freehand ultrasound (US) probe calibration technique. This will enable us to visualize US image data during surgical procedures using augmented reality. The performance of the system was evaluated with different experiments using two different pose estimation techniques. A near-millimeter accuracy can be achieved with the proposed approach. The developed system is cost-effective, simple and rapid with low calibration error
Interpretable and Explainable Logical Policies via Neurally Guided Symbolic Abstraction
Jun 02, 2023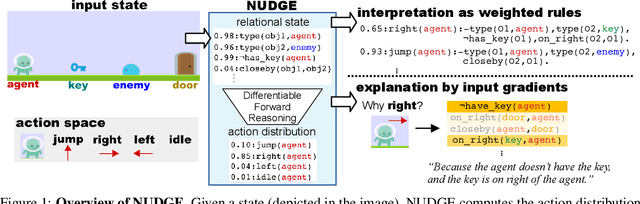
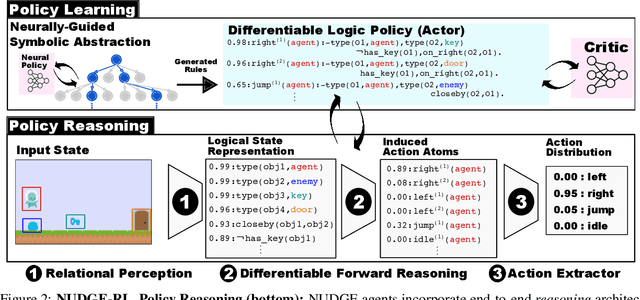
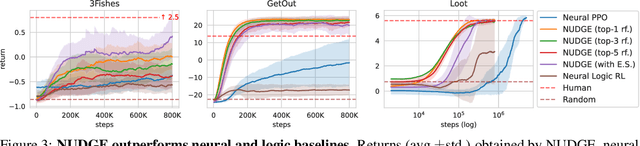

The limited priors required by neural networks make them the dominating choice to encode and learn policies using reinforcement learning (RL). However, they are also black-boxes, making it hard to understand the agent's behaviour, especially when working on the image level. Therefore, neuro-symbolic RL aims at creating policies that are interpretable in the first place. Unfortunately, interpretability is not explainability. To achieve both, we introduce Neurally gUided Differentiable loGic policiEs (NUDGE). NUDGE exploits trained neural network-based agents to guide the search of candidate-weighted logic rules, then uses differentiable logic to train the logic agents. Our experimental evaluation demonstrates that NUDGE agents can induce interpretable and explainable policies while outperforming purely neural ones and showing good flexibility to environments of different initial states and problem sizes.