 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boosting Transferability in Vision-Language Attacks via Diversification along the Intersection Region of Adversarial Trajectory
Mar 19, 2024
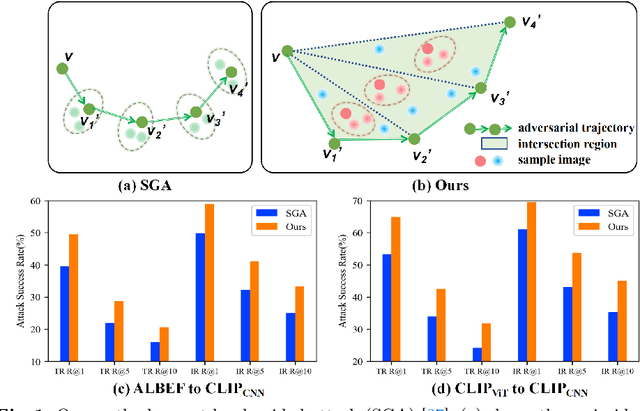


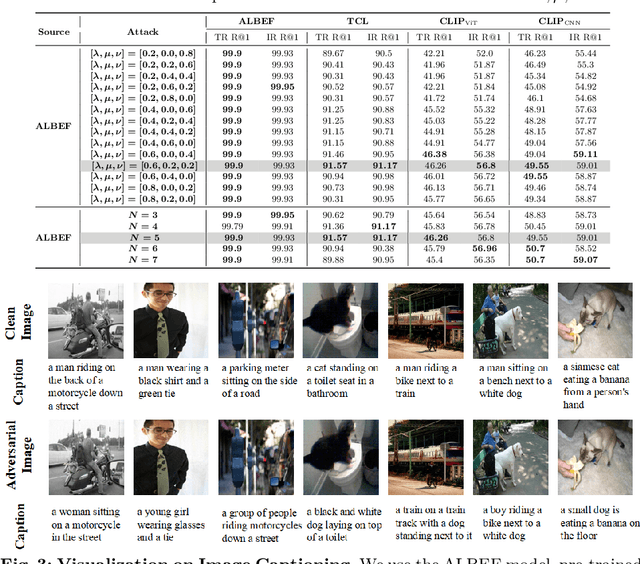
Vision-language pre-training (VLP) models exhibit remarkable capabilities in comprehending both images and text, yet they remain susceptible to multimodal adversarial examples (AEs). Strengthening adversarial attacks and uncovering vulnerabilities, especially common issues in VLP models (e.g., high transferable AEs), can stimulate further research on constructing reliable and practical VLP models. A recent work (i.e., Set-level guidance attack) indicates that augmenting image-text pairs to increase AE diversity along the optimization path enhances the transferability of adversarial examples significantly. However, this approach predominantly emphasizes diversity around the online adversarial examples (i.e., AEs in the optimization period), leading to the risk of overfitting the victim model and affecting the transferability. In this study, we posit that the diversity of adversarial examples towards the clean input and online AEs are both pivotal for enhancing transferability across VLP models. Consequently, we propose using diversification along the intersection region of adversarial trajectory to expand the diversity of AEs. To fully leverage the interaction between modalities, we introduce text-guided adversarial example selection during optimization. Furthermore, to further mitigate the potential overfitting, we direct the adversarial text deviating from the last intersection region along the optimization path, rather than adversarial images as in existing methods. Extensive experiments affirm the effectiveness of our method in improving transferability across various VLP models and downstream vision-and-language tasks (e.g., Image-Text Retrieval(ITR), Visual Grounding(VG), Image Captioning(IC)).
OV9D: Open-Vocabulary Category-Level 9D Object Pose and Size Estimation
Mar 19, 2024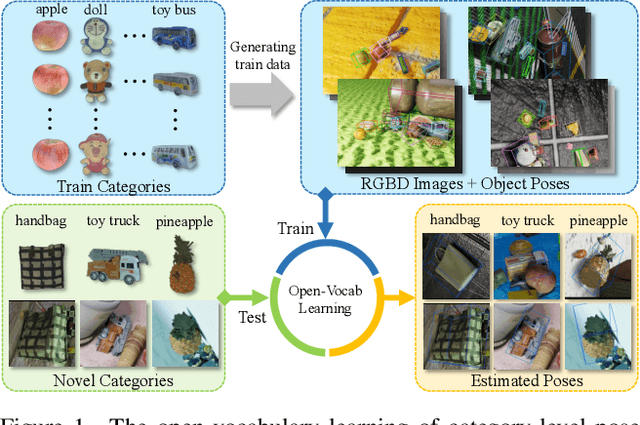
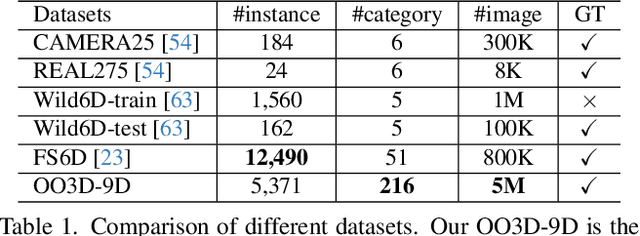

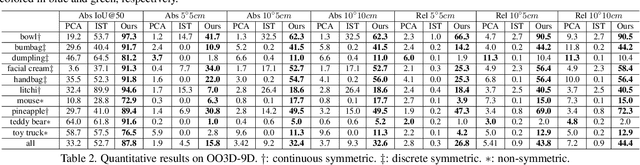
This paper studies a new open-set problem, the open-vocabulary category-level object pose and size estimation. Given human text descriptions of arbitrary novel object categories, the robot agent seeks to predict the position, orientation, and size of the target object in the observed scene image. To enable such generalizability, we first introduce OO3D-9D, a large-scale photorealistic dataset for this task. Derived from OmniObject3D, OO3D-9D is the largest and most diverse dataset in the field of category-level object pose and size estimation. It includes additional annotations for the symmetry axis of each category, which help resolve symmetric ambiguity. Apart from the large-scale dataset, we find another key to enabling such generalizability is leveraging the strong prior knowledge in pre-trained visual-language foundation models. We then propose a framework built on pre-trained DinoV2 and text-to-image stable diffusion models to infer the normalized object coordinate space (NOCS) maps of the target instances. This framework fully leverages the visual semantic prior from DinoV2 and the aligned visual and language knowledge within the text-to-image diffusion model, which enables generalization to various text descriptions of novel categories. Comprehensive quantitative and qualitative experiments demonstrate that the proposed open-vocabulary method, trained on our large-scale synthesized data, significantly outperforms the baseline and can effectively generalize to real-world images of unseen categories. The project page is at https://ov9d.github.io.
Language-Based Depth Hints for Monocular Depth Estimation
Mar 22, 2024Monocular depth estimation (MDE) is inherently ambiguous, as a given image may result from many different 3D scenes and vice versa. To resolve this ambiguity, an MDE system must make assumptions about the most likely 3D scenes for a given input. These assumptions can be either explicit or implicit. In this work, we demonstrate the use of natural language as a source of an explicit prior about the structure of the world. The assumption is made that human language encodes the likely distribution in depth-space of various objects. We first show that a language model encodes this implicit bias during training, and that it can be extracted using a very simple learned approach. We then show that this prediction can be provided as an explicit source of assumption to an MDE system, using an off-the-shelf instance segmentation model that provides the labels used as the input to the language model. We demonstrate the performance of our method on the NYUD2 dataset, showing improvement compared to the baseline and to random controls.
Towards Automatic Abdominal MRI Organ Segmentation: Leveraging Synthesized Data Generated From CT Labels
Mar 22, 2024Deep learning has shown great promise in the ability to automatically annotate organs in magnetic resonance imaging (MRI) scans, for example, of the brain. However, despite advancements in the field, the ability to accurately segment abdominal organs remains difficult across MR. In part, this may be explained by the much greater variability in image appearance and severely limited availability of training labels. The inherent nature of computed tomography (CT) scans makes it easier to annotate, resulting in a larger availability of expert annotations for the latter. We leverage a modality-agnostic domain randomization approach, utilizing CT label maps to generate synthetic images on-the-fly during training, further used to train a U-Net segmentation network for abdominal organs segmentation. Our approach shows comparable results compared to fully-supervised segmentation methods trained on MR data. Our method results in Dice scores of 0.90 (0.08) and 0.91 (0.08) for the right and left kidney respectively, compared to a pretrained nnU-Net model yielding 0.87 (0.20) and 0.91 (0.03). We will make our code publicly available.
Generalizable Two-Branch Framework for Image Class-Incremental Learning
Mar 09, 2024Deep neural networks often severely forget previously learned knowledge when learning new knowledge. Various continual learning (CL) methods have been proposed to handle such a catastrophic forgetting issue from different perspectives and achieved substantial improvements.In this paper, a novel two-branch continual learning framework is proposed to further enhance most existing CL methods. Specifically, the main branch can be any existing CL model and the newly introduced side branch is a lightweight convolutional network. The output of each main branch block is modulated by the output of the corresponding side branch block. Such a simple two-branch model can then be easily implemented and learned with the vanilla optimization setting without whistles and bells.Extensive experiments with various settings on multiple image datasets show that the proposed framework yields consistent improvements over state-of-the-art methods.
Unveiling Ancient Maya Settlements Using Aerial LiDAR Image Segmentation
Mar 09, 2024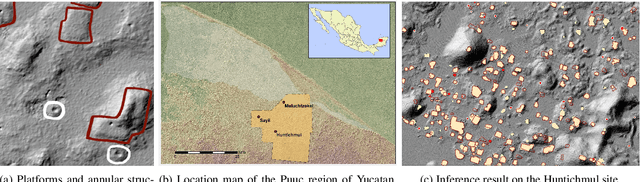

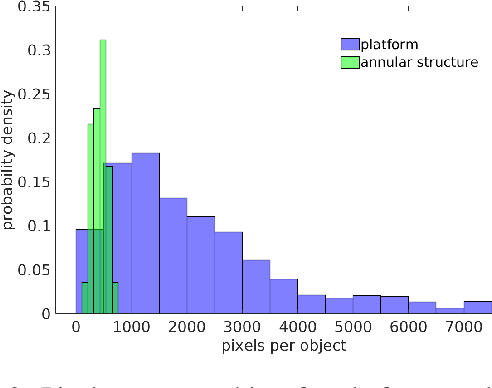
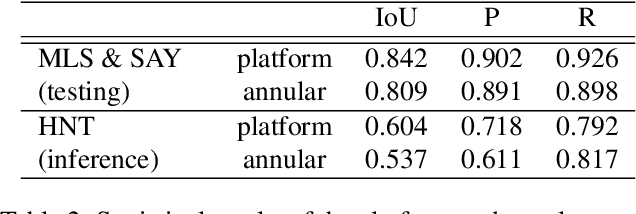
Manual identification of archaeological features in LiDAR imagery is labor-intensive, costly, and requires archaeological expertise. This paper shows how recent advancements in deep learning (DL) present efficient solutions for accurately segmenting archaeological structures in aerial LiDAR images using the YOLOv8 neural network. The proposed approach uses novel pre-processing of the raw LiDAR data and dataset augmentation methods to produce trained YOLOv8 networks to improve accuracy, precision, and recall for the segmentation of two important Maya structure types: annular structures and platforms. The results show an IoU performance of 0.842 for platforms and 0.809 for annular structures which outperform existing approaches. Further, analysis via domain experts considers the topological consistency of segmented regions and performance vs. area providing important insights. The approach automates time-consuming LiDAR image labeling which significantly accelerates accurate analysis of historical landscapes.
TexDreamer: Towards Zero-Shot High-Fidelity 3D Human Texture Generation
Mar 19, 2024
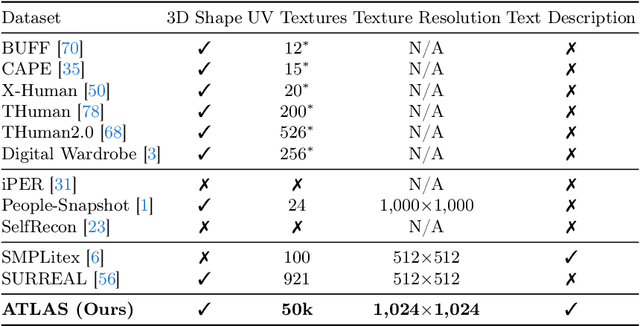
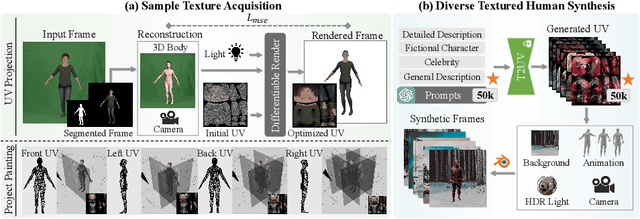
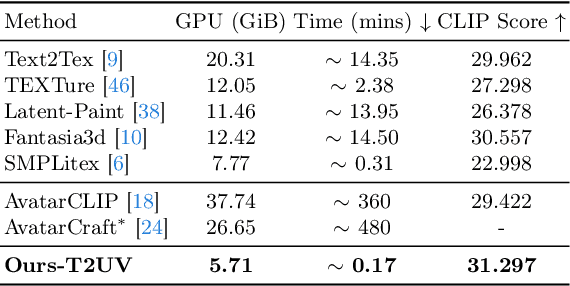
Texturing 3D humans with semantic UV maps remains a challenge due to the difficulty of acquiring reasonably unfolded UV. Despite recent text-to-3D advancements in supervising multi-view renderings using large text-to-image (T2I) models, issues persist with generation speed, text consistency, and texture quality, resulting in data scarcity among existing datasets. We present TexDreamer, the first zero-shot multimodal high-fidelity 3D human texture generation model. Utilizing an efficient texture adaptation finetuning strategy, we adapt large T2I model to a semantic UV structure while preserving its original generalization capability. Leveraging a novel feature translator module, the trained model is capable of generating high-fidelity 3D human textures from either text or image within seconds. Furthermore, we introduce ArTicuLated humAn textureS (ATLAS), the largest high-resolution (1024 X 1024) 3D human texture dataset which contains 50k high-fidelity textures with text descriptions.
How to Handle Sketch-Abstraction in Sketch-Based Image Retrieval?
Mar 11, 2024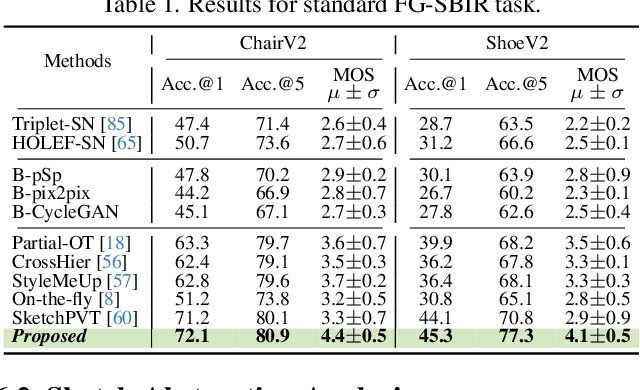
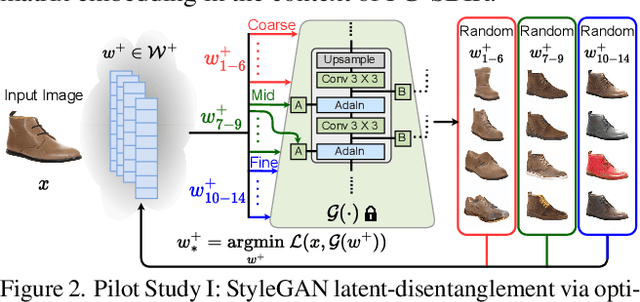
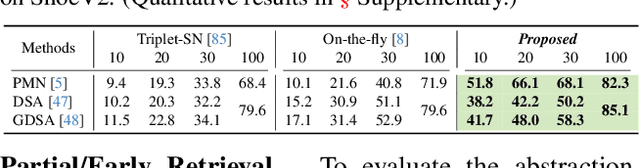
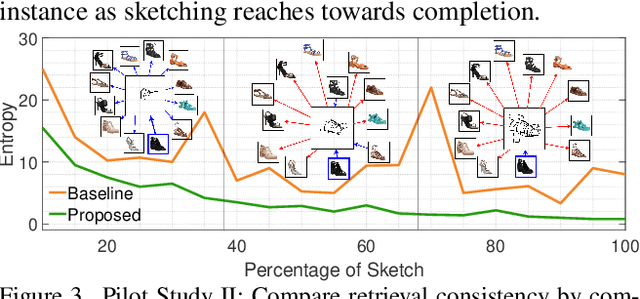
In this paper, we propose a novel abstraction-aware sketch-based image retrieval framework capable of handling sketch abstraction at varied levels. Prior works had mainly focused on tackling sub-factors such as drawing style and order, we instead attempt to model abstraction as a whole, and propose feature-level and retrieval granularity-level designs so that the system builds into its DNA the necessary means to interpret abstraction. On learning abstraction-aware features, we for the first-time harness the rich semantic embedding of pre-trained StyleGAN model, together with a novel abstraction-level mapper that deciphers the level of abstraction and dynamically selects appropriate dimensions in the feature matrix correspondingly, to construct a feature matrix embedding that can be freely traversed to accommodate different levels of abstraction. For granularity-level abstraction understanding, we dictate that the retrieval model should not treat all abstraction-levels equally and introduce a differentiable surrogate Acc.@q loss to inject that understanding into the system. Different to the gold-standard triplet loss, our Acc.@q loss uniquely allows a sketch to narrow/broaden its focus in terms of how stringent the evaluation should be - the more abstract a sketch, the less stringent (higher $q$). Extensive experiments depict our method to outperform existing state-of-the-arts in standard SBIR tasks along with challenging scenarios like early retrieval, forensic sketch-photo matching, and style-invariant retrieval.
LightM-UNet: Mamba Assists in Lightweight UNet for Medical Image Segmentation
Mar 11, 2024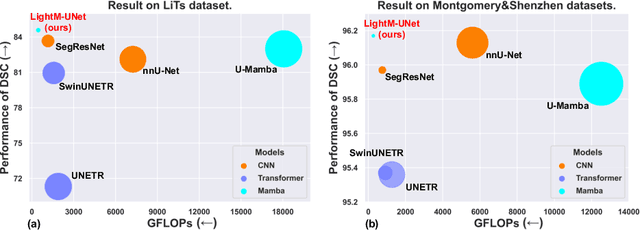
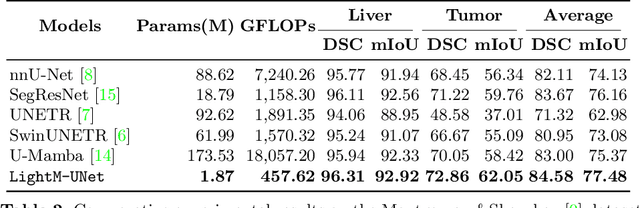
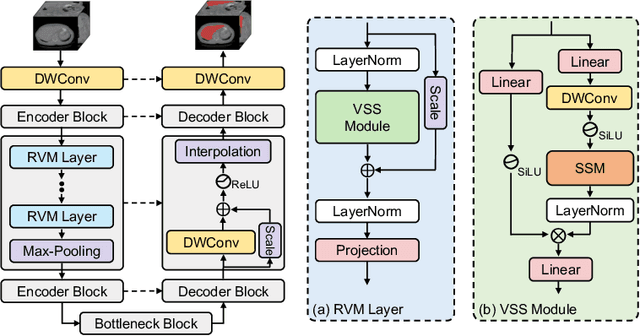
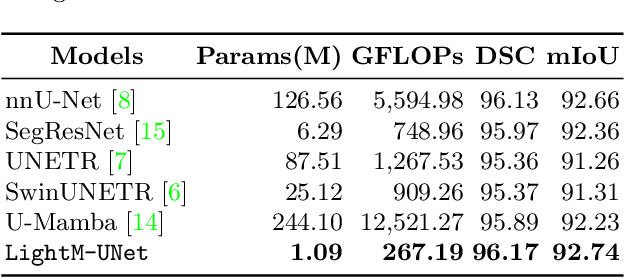
UNet and its variants have been widely used in medical image segmentation. However, these models, especially those based on Transformer architectures, pose challenges due to their large number of parameters and computational loads, making them unsuitable for mobile health applications. Recently, State Space Models (SSMs), exemplified by Mamba, have emerged as competitive alternatives to CNN and Transformer architectures. Building upon this, we employ Mamba as a lightweight substitute for CNN and Transformer within UNet, aiming at tackling challenges stemming from computational resource limitations in real medical settings. To this end, we introduce the Lightweight Mamba UNet (LightM-UNet) that integrates Mamba and UNet in a lightweight framework. Specifically, LightM-UNet leverages the Residual Vision Mamba Layer in a pure Mamba fashion to extract deep semantic features and model long-range spatial dependencies, with linear computational complexity. Extensive experiments conducted on two real-world 2D/3D datasets demonstrate that LightM-UNet surpasses existing state-of-the-art literature. Notably, when compared to the renowned nnU-Net, LightM-UNet achieves superior segmentation performance while drastically reducing parameter and computation costs by 116x and 21x, respectively. This highlights the potential of Mamba in facilitating model lightweighting. Our code implementation is publicly available at https://github.com/MrBlankness/LightM-UNet.
Impart: An Imperceptible and Effective Label-Specific Backdoor Attack
Mar 18, 2024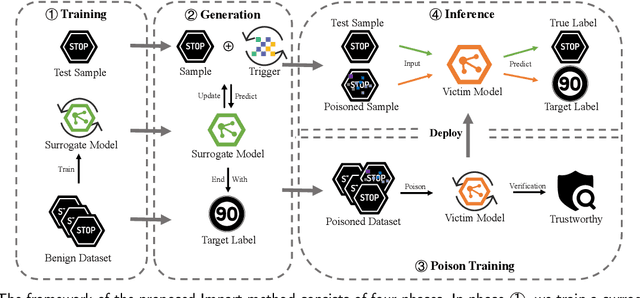

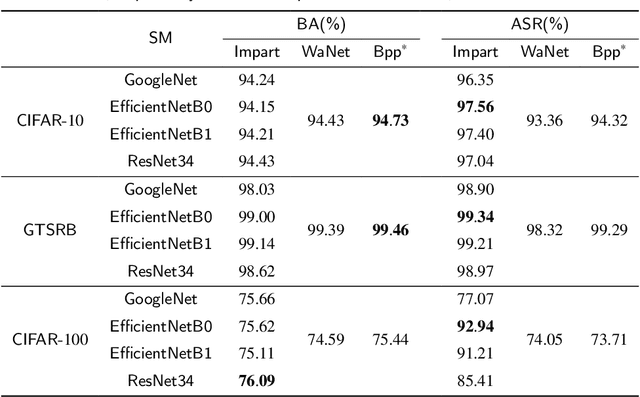
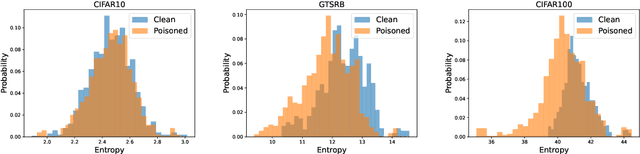
Backdoor attacks have been shown to impose severe threats to real security-critical scenarios. Although previous works can achieve high attack success rates, they either require access to victim models which may significantly reduce their threats in practice, or perform visually noticeable in stealthiness. Besides, there is still room to improve the attack success rates in the scenario that different poisoned samples may have different target labels (a.k.a., the all-to-all setting). In this study, we propose a novel imperceptible backdoor attack framework, named Impart, in the scenario where the attacker has no access to the victim model. Specifically, in order to enhance the attack capability of the all-to-all setting, we first propose a label-specific attack. Different from previous works which try to find an imperceptible pattern and add it to the source image as the poisoned image, we then propose to generate perturbations that align with the target label in the image feature by a surrogate model. In this way, the generated poisoned images are attached with knowledge about the target class, which significantly enhances the attack capability.