 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RelPose++: Recovering 6D Poses from Sparse-view Observations
May 08, 2023
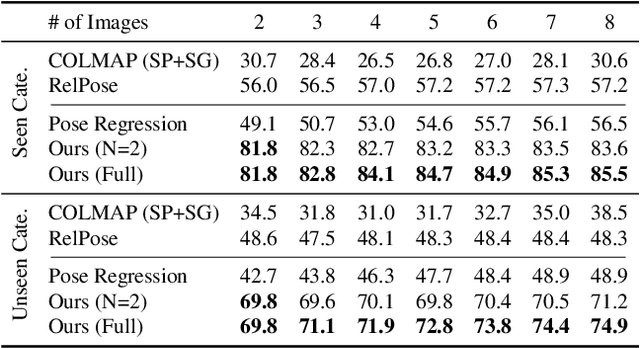
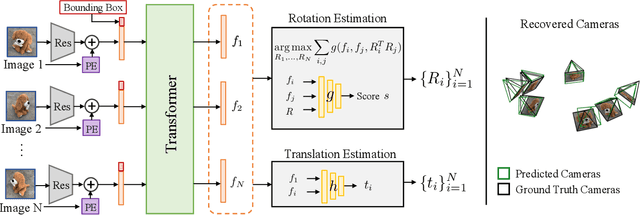
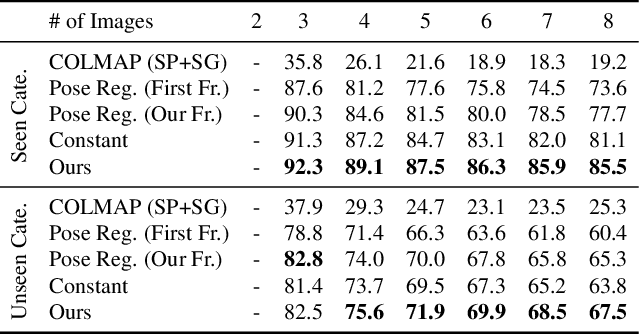
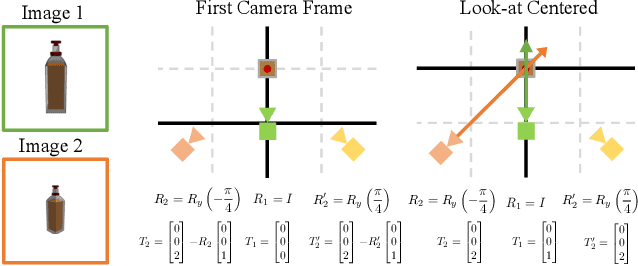
We address the task of estimating 6D camera poses from sparse-view image sets (2-8 images). This task is a vital pre-processing stage for nearly all contemporary (neural) reconstruction algorithms but remains challenging given sparse views, especially for objects with visual symmetries and texture-less surfaces. We build on the recent RelPose framework which learns a network that infers distributions over relative rotations over image pairs. We extend this approach in two key ways; first, we use attentional transformer layers to process multiple images jointly, since additional views of an object may resolve ambiguous symmetries in any given image pair (such as the handle of a mug that becomes visible in a third view). Second, we augment this network to also report camera translations by defining an appropriate coordinate system that decouples the ambiguity in rotation estimation from translation prediction. Our final system results in large improvements in 6D pose prediction over prior art on both seen and unseen object categories and also enables pose estimation and 3D reconstruction for in-the-wild objects.
AI in the Loop -- Functionalizing Fold Performance Disagreement to Monitor Automated Medical Image Segmentation Pipelines
May 15, 2023
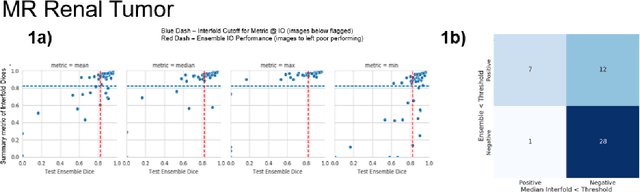
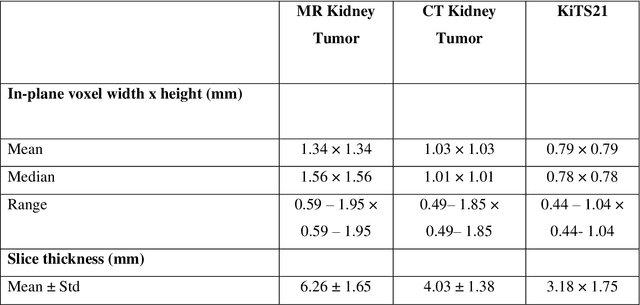
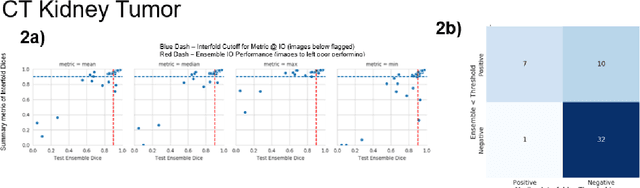
Methods for automatically flag poor performing-predictions are essential for safely implementing machine learning workflows into clinical practice and for identifying difficult cases during model training. We present a readily adoptable method using sub-models trained on different dataset folds, where their disagreement serves as a surrogate for model confidence. Thresholds informed by human interobserver values were used to determine whether a final ensemble model prediction would require manual review. In two different datasets (abdominal CT and MR predicting kidney tumors), our framework effectively identified low performing automated segmentations. Flagging images with a minimum Interfold test Dice score below human interobserver variability maximized the number of flagged images while ensuring maximum ensemble test Dice. When our internally trained model was applied to an external publicly available dataset (KiTS21), flagged images included smaller tumors than those observed in our internally trained dataset, demonstrating the methods robustness to flagging poor performing out-of-distribution input data. Comparing interfold sub-model disagreement against human interobserver values is an efficient way to approximate a model's epistemic uncertainty - its lack of knowledge due to insufficient relevant training data - a key functionality for adopting these applications in clinical practice.
A Uniform Confidence Phenomenon in Deep Learning and its Implications for Calibration
Jun 01, 2023
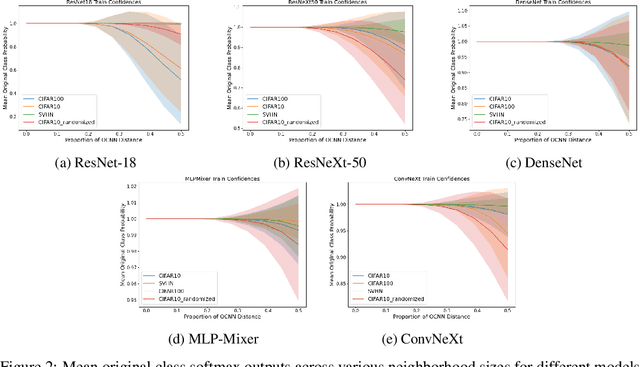
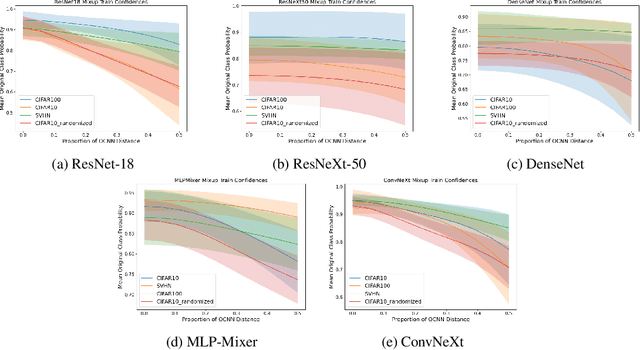
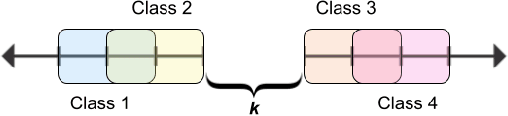
Despite the impressive generalization capabilities of deep neural networks, they have been repeatedly shown to poorly estimate their predictive uncertainty - in other words, they are frequently overconfident when they are wrong. Fixing this issue is known as model calibration, and has consequently received much attention in the form of modified training schemes and post-training calibration procedures. In this work, we present a significant hurdle to the calibration of modern models: deep neural networks have large neighborhoods of almost certain confidence around their training points. We demonstrate in our experiments that this phenomenon consistently arises (in the context of image classification) across many model and dataset pairs. Furthermore, we prove that when this phenomenon holds, for a large class of data distributions with overlaps between classes, it is not possible to obtain a model that is asymptotically better than random (with respect to calibration) even after applying the standard post-training calibration technique of temperature scaling. On the other hand, we also prove that it is possible to circumvent this defect by changing the training process to use a modified loss based on the Mixup data augmentation technique.
Fourier Analysis on Robustness of Graph Convolutional Neural Networks for Skeleton-based Action Recognition
May 29, 2023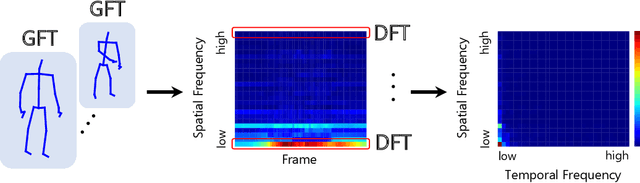
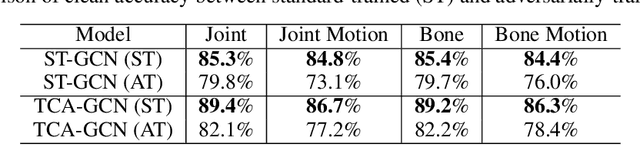
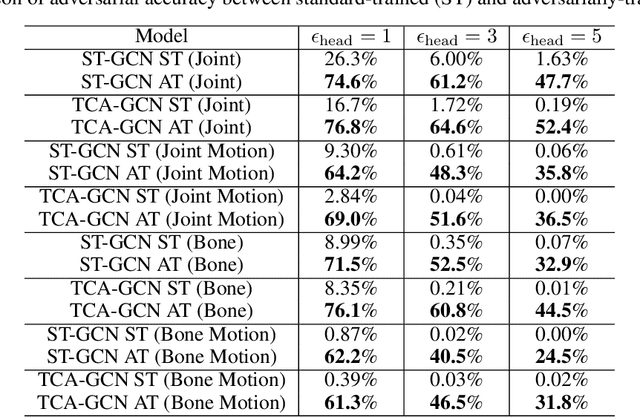
Using Fourier analysis, we explore the robustness and vulnerability of graph convolutional neural networks (GCNs) for skeleton-based action recognition. We adopt a joint Fourier transform (JFT), a combination of the graph Fourier transform (GFT) and the discrete Fourier transform (DFT), to examine the robustness of adversarially-trained GCNs against adversarial attacks and common corruptions. Experimental results with the NTU RGB+D dataset reveal that adversarial training does not introduce a robustness trade-off between adversarial attacks and low-frequency perturbations, which typically occurs during image classification based on convolutional neural networks. This finding indicates that adversarial training is a practical approach to enhancing robustness against adversarial attacks and common corruptions in skeleton-based action recognition. Furthermore, we find that the Fourier approach cannot explain vulnerability against skeletal part occlusion corruption, which highlights its limitations. These findings extend our understanding of the robustness of GCNs, potentially guiding the development of more robust learning methods for skeleton-based action recognition.
Hierarchical Neural Memory Network for Low Latency Event Processing
May 29, 2023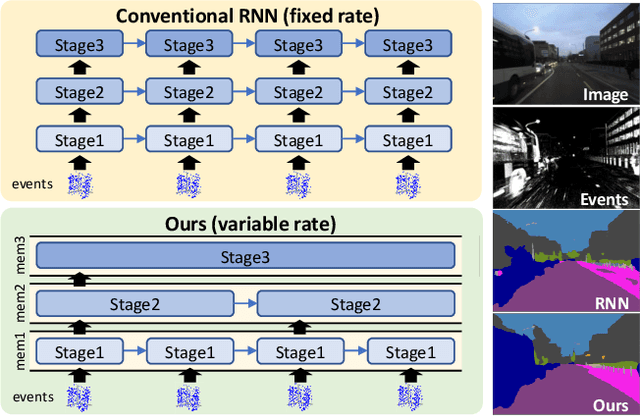
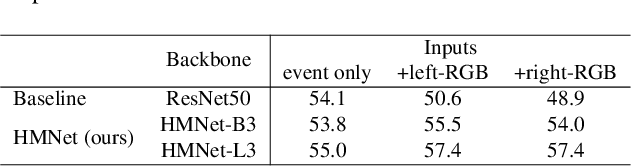
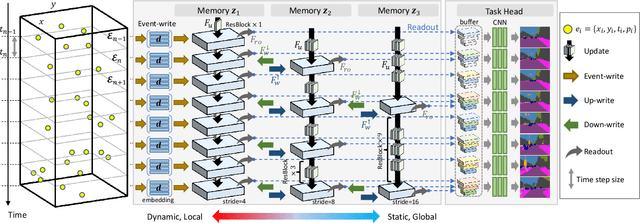
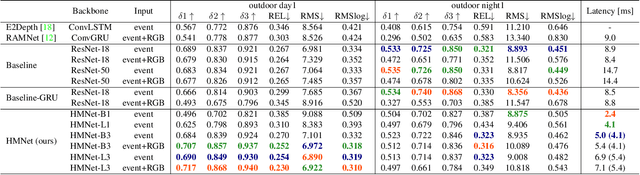
This paper proposes a low latency neural network architecture for event-based dense prediction tasks. Conventional architectures encode entire scene contents at a fixed rate regardless of their temporal characteristics. Instead, the proposed network encodes contents at a proper temporal scale depending on its movement speed. We achieve this by constructing temporal hierarchy using stacked latent memories that operate at different rates. Given low latency event steams, the multi-level memories gradually extract dynamic to static scene contents by propagating information from the fast to the slow memory modules. The architecture not only reduces the redundancy of conventional architectures but also exploits long-term dependencies. Furthermore, an attention-based event representation efficiently encodes sparse event streams into the memory cells. We conduct extensive evaluations on three event-based dense prediction tasks, where the proposed approach outperforms the existing methods on accuracy and latency, while demonstrating effective event and image fusion capabilities. The code is available at https://hamarh.github.io/hmnet/
Pedestrian detection with high-resolution event camera
May 29, 2023
Despite the dynamic development of computer vision algorithms, the implementation of perception and control systems for autonomous vehicles such as drones and self-driving cars still poses many challenges. A video stream captured by traditional cameras is often prone to problems such as motion blur or degraded image quality due to challenging lighting conditions. In addition, the frame rate - typically 30 or 60 frames per second - can be a limiting factor in certain scenarios. Event cameras (DVS -- Dynamic Vision Sensor) are a potentially interesting technology to address the above mentioned problems. In this paper, we compare two methods of processing event data by means of deep learning for the task of pedestrian detection. We used a representation in the form of video frames, convolutional neural networks and asynchronous sparse convolutional neural networks. The results obtained illustrate the potential of event cameras and allow the evaluation of the accuracy and efficiency of the methods used for high-resolution (1280 x 720 pixels) footage.
Pix2Repair: Implicit Shape Restoration from Images
May 29, 2023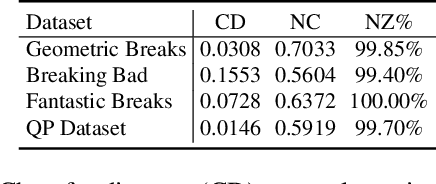
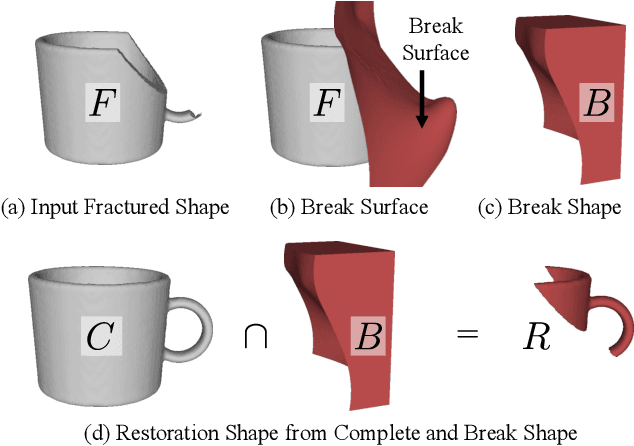
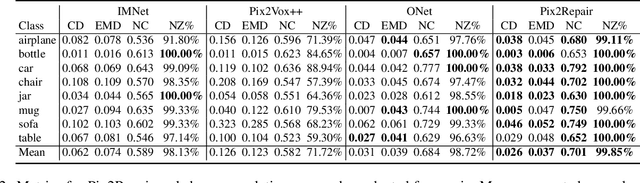

We present Pix2Repair, an automated shape repair approach that generates restoration shapes from images to repair fractured objects. Prior repair approaches require a high-resolution watertight 3D mesh of the fractured object as input. Input 3D meshes must be obtained using expensive 3D scanners, and scanned meshes require manual cleanup, limiting accessibility and scalability. Pix2Repair takes an image of the fractured object as input and automatically generates a 3D printable restoration shape. We contribute a novel shape function that deconstructs a latent code representing the fractured object into a complete shape and a break surface. We show restorations for synthetic fractures from the Geometric Breaks and Breaking Bad datasets, and cultural heritage objects from the QP dataset, and for real fractures from the Fantastic Breaks dataset. We overcome challenges in restoring axially symmetric objects by predicting view-centered restorations. Our approach outperforms shape completion approaches adapted for shape repair in terms of chamfer distance, earth mover's distance, normal consistency, and percent restorations generated.
3DTeethSeg'22: 3D Teeth Scan Segmentation and Labeling Challenge
May 29, 2023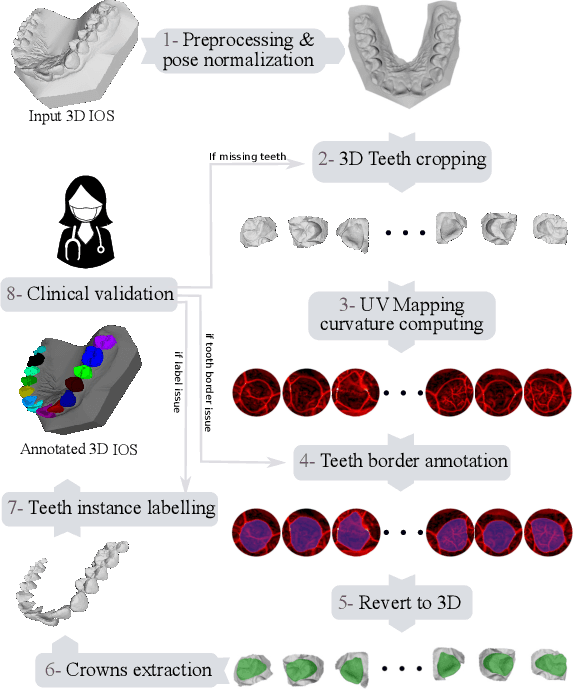
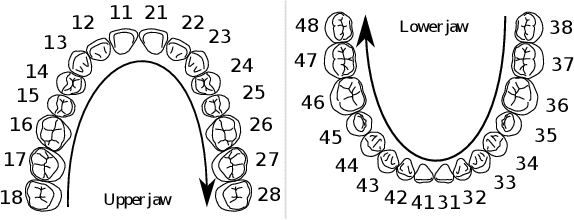
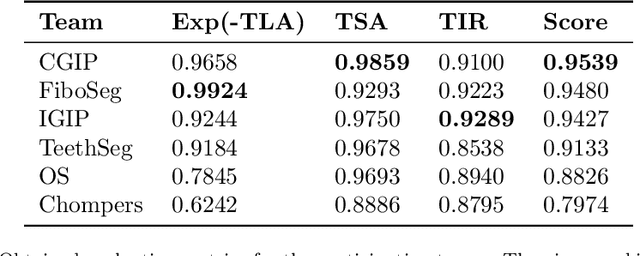
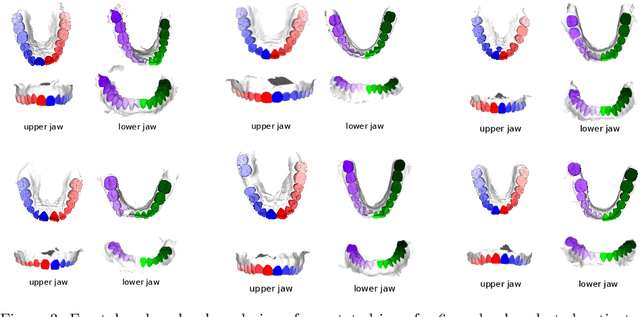
Teeth localization, segmentation, and labeling from intra-oral 3D scans are essential tasks in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, developing automated algorithms for teeth analysis presents significant challenges due to variations in dental anatomy, imaging protocols, and limited availability of publicly accessible data. To address these challenges, the 3DTeethSeg'22 challenge was organized in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) in 2022, with a call for algorithms tackling teeth localization, segmentation, and labeling from intraoral 3D scans. A dataset comprising a total of 1800 scans from 900 patients was prepared, and each tooth was individually annotated by a human-machine hybrid algorithm. A total of 6 algorithms were evaluated on this dataset. In this study, we present the evaluation results of the 3DTeethSeg'22 challenge. The 3DTeethSeg'22 challenge code can be accessed at: https://github.com/abenhamadou/3DTeethSeg22_challenge
SFT-KD-Recon: Learning a Student-friendly Teacher for Knowledge Distillation in Magnetic Resonance Image Reconstruction
Apr 11, 2023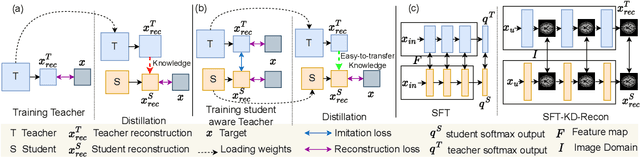
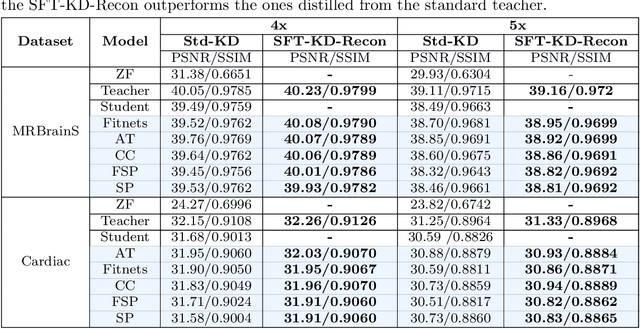
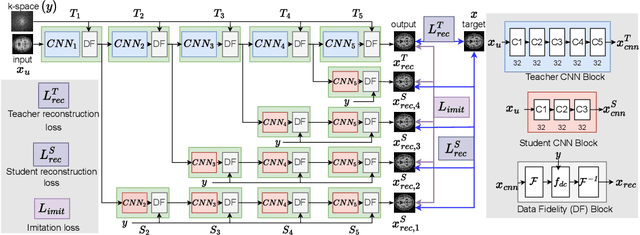
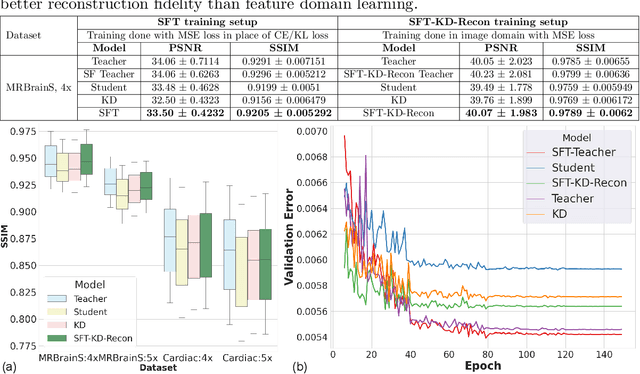
Deep cascaded architectures for magnetic resonance imaging (MRI) acceleration have shown remarkable success in providing high-quality reconstruction. However, as the number of cascades increases, the improvements in reconstruction tend to become marginal, indicating possible excess model capacity. Knowledge distillation (KD) is an emerging technique to compress these models, in which a trained deep teacher network is used to distill knowledge to a smaller student network such that the student learns to mimic the behavior of the teacher. Most KD methods focus on effectively training the student with a pre-trained teacher unaware of the student model. We propose SFT-KD-Recon, a student-friendly teacher training approach along with the student as a prior step to KD to make the teacher aware of the structure and capacity of the student and enable aligning the representations of the teacher with the student. In SFT, the teacher is jointly trained with the unfolded branch configurations of the student blocks using three loss terms - teacher-reconstruction loss, student-reconstruction loss, and teacher-student imitation loss, followed by KD of the student. We perform extensive experiments for MRI acceleration in 4x and 5x under-sampling on the brain and cardiac datasets on five KD methods using the proposed approach as a prior step. We consider the DC-CNN architecture and setup teacher as D5C5 (141765 parameters), and student as D3C5 (49285 parameters), denoting a compression of 2.87:1. Results show that (i) our approach consistently improves the KD methods with improved reconstruction performance and image quality, and (ii) the student distilled using our approach is competitive with the teacher, with the performance gap reduced from 0.53 dB to 0.03 dB.
An Evaluation of Non-Contrastive Self-Supervised Learning for Federated Medical Image Analysis
Mar 09, 2023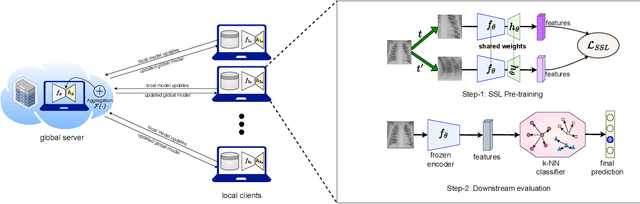
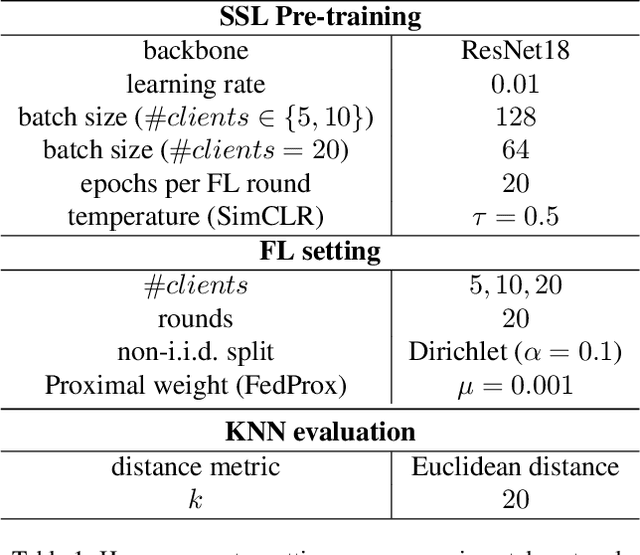
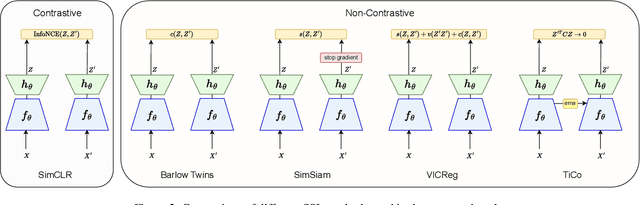

Privacy and annotation bottlenecks are two major issues that profoundly affect the practicality of machine learning-based medical image analysis. Although significant progress has been made in these areas, these issues are not yet fully resolved. In this paper, we seek to tackle these concerns head-on and systematically explore the applicability of non-contrastive self-supervised learning (SSL) algorithms under federated learning (FL) simulations for medical image analysis. We conduct thorough experimentation of recently proposed state-of-the-art non-contrastive frameworks under standard FL setups. With the SoTA Contrastive Learning algorithm, SimCLR as our comparative baseline, we benchmark the performances of our 4 chosen non-contrastive algorithms under non-i.i.d. data conditions and with a varying number of clients. We present a holistic evaluation of these techniques on 6 standardized medical imaging datasets. We further analyse different trends inferred from the findings of our research, with the aim to find directions for further research based on ours. To the best of our knowledge, ours is the first to perform such a thorough analysis of federated self-supervised learning for medical imaging. All of our source code will be made public upon acceptance of the paper.